Wat is trefwoordherkenning?
Met trefwoordherkenning wordt een woord of korte woordgroep in een audiostream gedetecteerd. Deze techniek wordt ook wel trefwoordspotting genoemd.
De meest voorkomende use case van trefwoordherkenning is spraakactivering van virtuele assistenten. 'Hey Cortana' is bijvoorbeeld het trefwoord voor de Cortana-assistent. Bij het herkennen van het trefwoord wordt een scenariospecifieke actie uitgevoerd. Voor scenario's met virtuele assistenten is spraakherkenning van audio die volgt op het trefwoord.
Over het algemeen luisteren virtuele assistenten altijd. Trefwoordherkenning fungeert als een privacygrens voor de gebruiker. Een trefwoordvereiste fungeert als een poort die voorkomt dat niet-gerelateerde gebruikersaudio het lokale apparaat naar de cloud oversteekt.
Trefwoordherkenning wordt geïmplementeerd als een systeem met meerdere fases om nauwkeurigheid, latentie en rekenkundige complexiteit te verdelen. Voor alle fasen buiten de eerste fase wordt audio alleen verwerkt als de fase voorafgaand aan de fase het trefwoord van belang herkent.
Het huidige systeem is ontworpen met meerdere fasen die de rand en cloud omvatten:
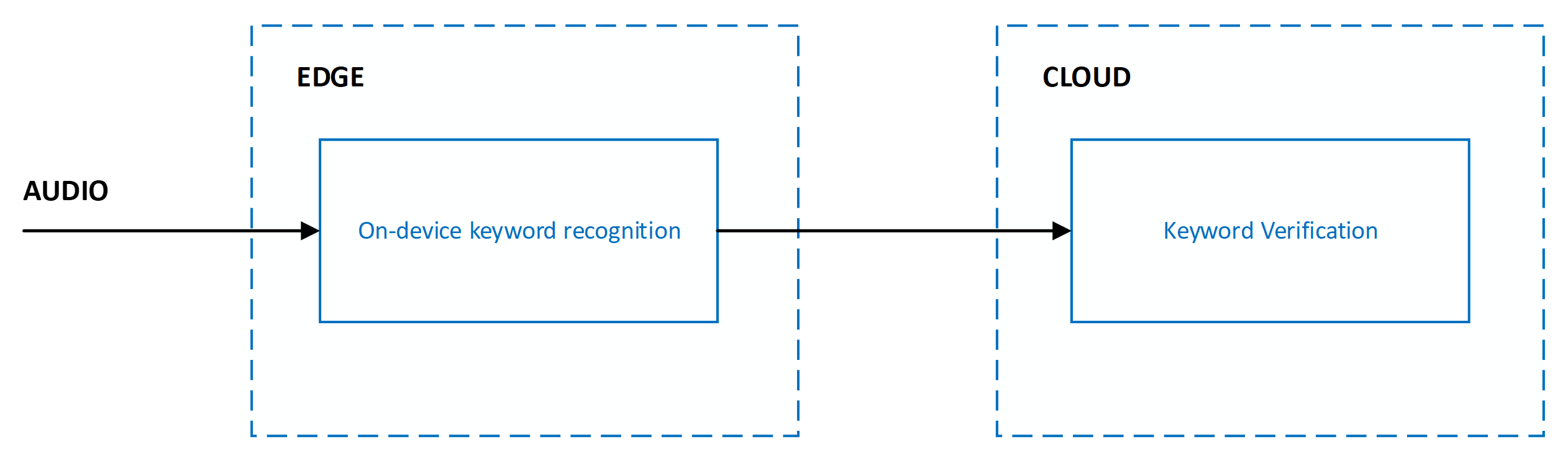
Nauwkeurigheid van trefwoordherkenning wordt gemeten via de volgende metrische gegevens:
- Juiste acceptatiesnelheid: meet het vermogen van het systeem om het trefwoord te herkennen dat door een gebruiker wordt gesproken. Het juiste acceptpercentage wordt ook wel de werkelijke positieve rente genoemd.
- False accept rate: meet de mogelijkheid van het systeem om audio uit te filteren die niet het trefwoord is dat door een gebruiker wordt gesproken. De false accept rate wordt ook wel de fout-positieve snelheid genoemd.
Het doel is om het juiste acceptatiepercentage te maximaliseren terwijl de foutieve acceptatiesnelheid wordt geminimaliseerd. Het huidige systeem is ontworpen om een trefwoord of woordgroep te detecteren die wordt voorafgegaan door een korte hoeveelheid stilte. Het detecteren van een trefwoord in het midden van een zin of uiting wordt niet ondersteund.
Aangepast trefwoord voor apparaatmodellen
Met de portal aangepast trefwoord in Speech Studio kunt u modellen voor trefwoordherkenning genereren die aan de rand worden uitgevoerd door een woord of korte woordgroep op te geven. U kunt uw trefwoordmodel verder personaliseren door de juiste uitspraak te kiezen.
Prijzen
Er zijn geen kosten verbonden aan het gebruik van aangepast trefwoord voor het genereren van modellen, waaronder basic- en geavanceerde modellen. Er zijn ook geen kosten verbonden aan het uitvoeren van modellen op het apparaat met de Speech SDK wanneer deze worden gebruikt met andere functies van de Speech-service, zoals spraak-naar-tekst.
Typen modellen
U kunt aangepast trefwoord gebruiken om twee typen apparaatmodellen te genereren voor elk trefwoord.
| Modeltype | Beschrijving |
|---|---|
| Basis | Het meest geschikt voor demo- of snelle prototypedoeleinden. Modellen worden gegenereerd met een gemeenschappelijk basismodel en het kan tot 15 minuten duren voordat ze klaar zijn. Modellen hebben mogelijk geen optimale nauwkeurigheidskenmerken. |
| Geavanceerd | Het meest geschikt voor productintegratiedoeleinden. Modellen worden gegenereerd met aanpassing van een gemeenschappelijk basismodel met behulp van gesimuleerde trainingsgegevens om de nauwkeurigheidskenmerken te verbeteren. Het kan tot 48 uur duren voordat modellen gereed zijn. |
Notitie
U kunt een lijst weergeven met regio's die ondersteuning bieden voor het geavanceerde modeltype in de ondersteuningsdocumentatie voor trefwoordherkenningsregio's.
Voor geen van beide modellen moet u trainingsgegevens uploaden. Aangepast trefwoord verwerkt gegevensgeneratie en modeltraining volledig.
Uitspraak
Wanneer u een nieuw model maakt, genereert aangepast trefwoord automatisch mogelijke uitspraken van het opgegeven trefwoord. U kunt naar elke uitspraak luisteren en alle variaties kiezen die nauw overeenkomen met de manier waarop gebruikers het trefwoord verwachten te zeggen. Alle andere uitspraken mogen niet worden geselecteerd.
Het is belangrijk dat u bewust bent van de uitspraken die u selecteert om de beste nauwkeurigheidskenmerken te garanderen. Als u bijvoorbeeld meer uitspraken kiest dan u nodig hebt, krijgt u mogelijk hogere false accept-tarieven. Als u te weinig uitspraken kiest, waarbij niet alle verwachte variaties worden behandeld, krijgt u mogelijk lagere juiste geaccepteerde tarieven.
Modellen testen
Nadat aangepast trefwoord modellen op het apparaat hebben gegenereerd, kunnen de modellen rechtstreeks in de portal worden getest. U kunt de portal gebruiken om rechtstreeks in uw browser te spreken en resultaten van trefwoordherkenning op te halen.
Trefwoordverificatie
Verificatie van trefwoorden is een cloudservice die het effect van onwaar accepteert van on-device-modellen met robuuste modellen die worden uitgevoerd in Azure. Afstemmen of trainen is niet vereist om trefwoordverificatie te laten werken met uw trefwoord. Incrementele modelupdates worden voortdurend geïmplementeerd in de service om de nauwkeurigheid en latentie te verbeteren en zijn transparant voor clienttoepassingen.
Prijzen
Verificatie van trefwoorden wordt altijd gebruikt in combinatie met spraak-naar-tekst. Er zijn geen kosten verbonden aan het gebruik van trefwoordverificatie buiten de kosten van spraak-naar-tekst.
Trefwoordverificatie en spraak naar tekst
Wanneer verificatie van trefwoorden wordt gebruikt, is deze altijd in combinatie met spraak-naar-tekst. Beide services worden parallel uitgevoerd, wat betekent dat audio naar beide services wordt verzonden voor gelijktijdige verwerking.
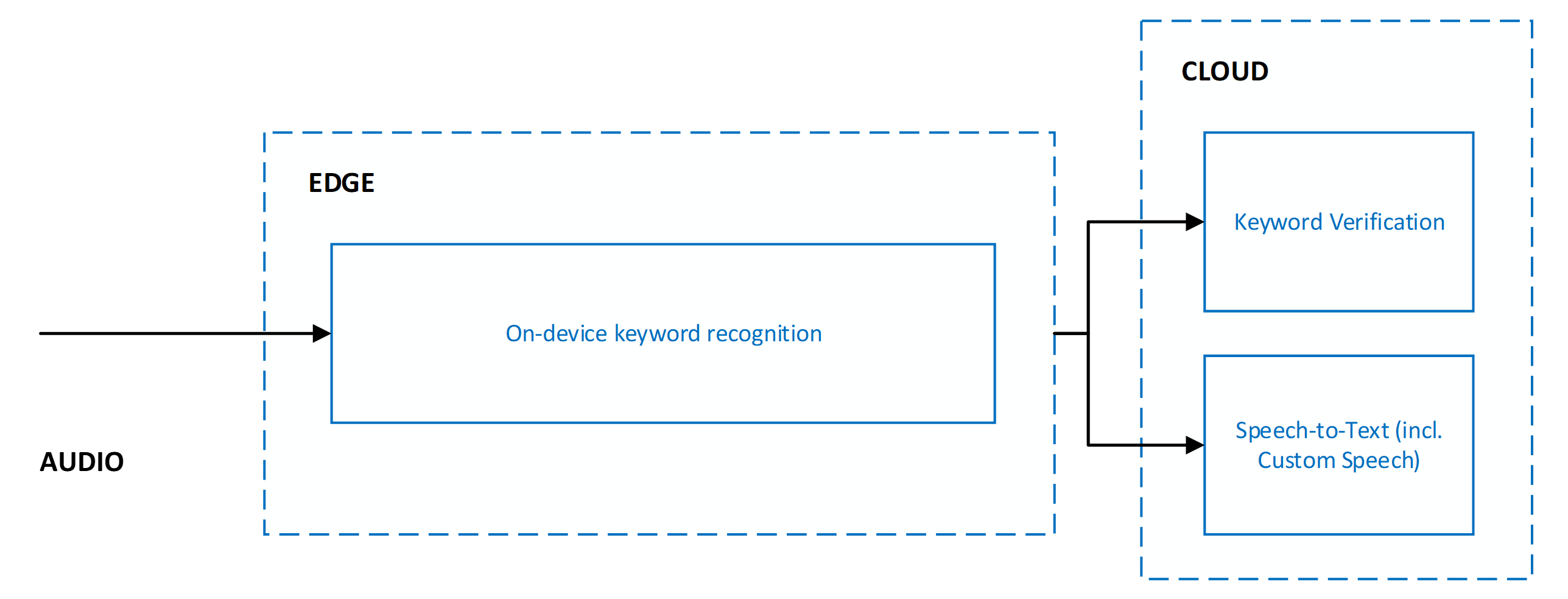
Het parallel uitvoeren van trefwoordverificatie en spraak naar tekst levert de volgende voordelen op:
- Geen andere latentie voor spraak-naar-tekstresultaten: parallelle uitvoering betekent dat trefwoordverificatie geen latentie toevoegt. De client ontvangt zo snel spraak-naar-tekstresultaten. Als de verificatie van trefwoorden bepaalt dat het trefwoord niet aanwezig was in de audio, wordt spraak-naar-tekstverwerking beëindigd. Deze actie beschermt tegen onnodige spraak naar tekstverwerking. Netwerk- en cloudmodelverwerking verhoogt de door de gebruiker waargenomen latentie van spraakactivering. Zie Aanbevelingen en richtlijnen voor meer informatie.
- Geforceerd trefwoordvoorvoegsel in spraak naar tekstresultaten: Spraak naar tekstverwerking zorgt ervoor dat de resultaten die naar de client worden verzonden, worden voorafgegaan door het trefwoord. Dit gedrag zorgt voor een grotere nauwkeurigheid in de spraak naar tekstresultaten voor spraak die volgt op het trefwoord.
- Verhoogde time-out voor spraak naar tekst: vanwege de verwachte aanwezigheid van het trefwoord aan het begin van de audio, staat spraak-naar-tekst een langere pauze van maximaal vijf seconden na het trefwoord toe voordat het einde van de spraak wordt bepaald en wordt spraak naar tekstverwerking beëindigd. Dit gedrag zorgt ervoor dat de gebruikerservaring correct wordt verwerkt voor gefaseerde opdrachten (opdracht voor trefwoord><onderbreken<>>) en gekoppelde opdrachten (<trefwoordopdracht>><).<
Overwegingen voor trefwoordverificatie en latentie
Voor elke aanvraag voor de service retourneert de verificatie van trefwoorden een van de twee antwoorden: geaccepteerd of geweigerd. De verwerkingslatentie varieert, afhankelijk van de lengte van het trefwoord en de lengte van het audiosegment dat naar verwachting het trefwoord bevat. De verwerkingslatentie omvat geen netwerkkosten tussen de client- en Speech-services.
| Antwoord op trefwoordverificatie | Beschrijving |
|---|---|
| Geaccepteerd | Geeft aan dat de service geloofde dat het trefwoord aanwezig was in de audiostream die is opgegeven als onderdeel van de aanvraag. |
| Afgewezen | Geeft aan dat de service geloofde dat het trefwoord niet aanwezig was in de audiostream die is opgegeven als onderdeel van de aanvraag. |
Geweigerde gevallen leveren vaak hogere latenties op omdat de service meer audio verwerkt dan geaccepteerde aanvragen. Verificatie van trefwoorden verwerkt standaard een maximum van twee seconden audio om naar het trefwoord te zoeken. Als het trefwoord niet binnen twee seconden wordt gevonden, treedt er een time-out op van de service en wordt een geweigerd antwoord op de client signalen weergegeven.
Trefwoordverificatie gebruiken met apparaatmodellen van aangepast trefwoord
De Speech SDK maakt naadloos gebruik mogelijk van on-device-modellen die worden gegenereerd met behulp van aangepast trefwoord met trefwoordverificatie en spraak-naar-tekst. Het verwerkt het volgende transparant:
- Audio-gating naar trefwoordverificatie en spraakherkenning op basis van het resultaat van een model op het apparaat.
- Het trefwoord doorgeven aan trefwoordverificatie.
- Het communiceren van alle metagegevens naar de cloud voor het organiseren van het end-to-end scenario.
U hoeft geen configuratieparameters expliciet op te geven. Alle benodigde informatie wordt automatisch geëxtraheerd uit het on-device-model dat wordt gegenereerd door een aangepast trefwoord.
In de voorbeelden en zelfstudies die hier zijn gekoppeld, ziet u hoe u de Speech SDK gebruikt:
- Voorbeelden van spraakassistenten op GitHub
- Zelfstudie: Uw assistent die is gebouwd met behulp van Azure AI Bot Service inschakelen met de C# Speech SDK
Speech SDK-integratie en -scenario's
Met de Speech SDK kunt u eenvoudig gebruikmaken van gepersonaliseerde op apparaten gegenereerde modellen voor trefwoordherkenning die zijn gegenereerd met aangepaste trefwoord- en trefwoordverificatie. Om ervoor te zorgen dat aan uw productbehoeften kan worden voldaan, ondersteunt de SDK de volgende twee scenario's:
| Scenario | Beschrijving | Voorbeelden |
|---|---|---|
| End-to-end trefwoordherkenning met spraak-naar-tekst | Het meest geschikt voor producten die gebruikmaken van een aangepast trefwoordmodel op het apparaat van aangepast trefwoord met trefwoordverificatie en spraak-naar-tekst. Dit scenario is het meest voorkomende. | |
| Offline trefwoordherkenning | Het meest geschikt voor producten zonder netwerkconnectiviteit die gebruikmaken van een aangepast trefwoordmodel op het apparaat op basis van aangepast trefwoord. |