Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Met Azure AI Custom Translator kunt u een vertaalsysteem bouwen dat overeenkomt met uw bedrijfs-, branche- en domeinspecifieke terminologie en -stijl. Het trainen en implementeren van een aangepast systeem is eenvoudig en vereist geen programmeervaardigheden. Het aangepaste vertaalsysteem integreert naadloos in uw bestaande toepassingen, werkstromen en websites en is beschikbaar in Azure via dezelfde cloudgebaseerde Microsoft Text Translation API-service die elke dag miljarden vertalingen mogelijk maakt.
Met het platform kunnen gebruikers aangepaste vertaalsystemen bouwen en publiceren van en naar het Engels. Custom Translator ondersteunt meer dan 60 talen die rechtstreeks zijn toegewezen aan de talen die beschikbaar zijn voor neurale machinevertaling (NMT). Zie De taalondersteuning van Translator voor een volledige lijst.
Is een aangepast vertaalmodel de juiste keuze voor mij?
Een goed getraind aangepast vertaalmodel biedt nauwkeurigere domeinspecifieke vertalingen, omdat het afhankelijk is van eerder vertaalde documenten in het domein om voorkeursvertalingen te leren. Translator gebruikt deze termen en woordgroepen in context om vloeiende vertalingen in de doeltaal te produceren en tegelijkertijd contextafhankelijke grammatica te respecteren.
Voor het trainen van een volledig aangepast vertaalmodel is een aanzienlijke hoeveelheid gegevens vereist. Als u niet ten minste 10.000 zinnen met eerder getrainde documenten hebt, kunt u geen volledig vertaalmodel trainen. U kunt echter een model met alleen woordenlijst trainen of de standaard vertalingen van hoge kwaliteit gebruiken die beschikbaar zijn met de Tekstomzettings-API.
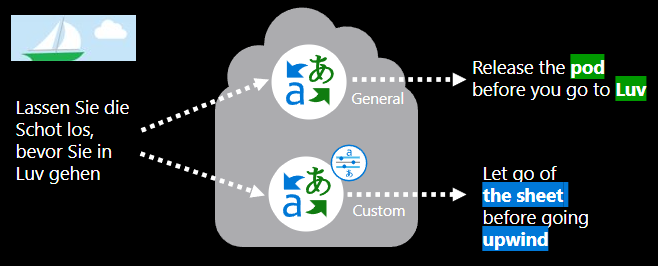
Wat houdt het trainen van een aangepast vertaalmodel in?
Voor het bouwen van een aangepast vertaalmodel is het volgende vereist:
Inzicht in uw use-case.
Het verkrijgen van vertaalde gegevens in het domein (bij voorkeur door mensen vertaald).
Kwaliteit van vertaling of doeltaalvertalingen beoordelen.
Hoe kan ik mijn use-case evalueren?
Het duidelijk maken van uw use-case en hoe succes eruitziet, is de eerste stap in de richting van het sourcen van vakkundige trainingsgegevens. Hier volgen enkele overwegingen:
Is het gewenste resultaat opgegeven en hoe wordt dit gemeten?
Is uw bedrijfsdomein geïdentificeerd?
Hebt u zinnen in het domein met vergelijkbare terminologie en stijl?
Heeft uw use-case betrekking op meerdere domeinen? Zo ja, moet u één vertaalsysteem of meerdere systemen bouwen?
Hebt u vereisten die van invloed zijn op de regionale gegevenslocatie in rust en in transit?
Bevinden de doelgebruikers zich in een of meer regio's?
Hoe moet ik mijn gegevens bronen?
Het zoeken naar kwaliteitsgegevens in het domein is vaak een uitdagende taak die varieert op basis van gebruikersclassificatie. Hier volgen enkele vragen die u kunt stellen wanneer u evalueert welke gegevens beschikbaar zijn voor u:
Beschikt uw bedrijf over eerdere vertaalgegevens die u kunt gebruiken? Ondernemingen hebben vaak een schat aan vertaalgegevens verzameld over vele jaren van het gebruik van menselijke vertaling.
Hebt u een enorme hoeveelheid mono-bedrijfsgegevens? Monogegevens zijn gegevens in slechts één taal. Zo ja, kunt u vertalingen voor deze gegevens verkrijgen?
Kunt u onlineportals verkennen om bronzinnen te verzamelen en doelzinnen te synthetiseren?
Wat moet ik gebruiken voor trainingsmateriaal?
| Bron | Functie | Regels die moeten worden gevolgd |
|---|---|---|
| Tweetalige trainingsdocumenten | Het systeem leert uw terminologie en stijl. | Wees vrij. Menselijke vertaling in het domein is beter dan automatische vertaling. Voeg documenten toe en verwijder deze zodra u gaat en probeer de BLEU-score te verbeteren. |
| Documenten afstemmen | Hiermee traint u de parameters voor neurale machinevertaling. | Wees strikt. Stel ze zo op dat ze in de toekomst optimaal representatief zijn voor wat u in de toekomst gaat vertalen. |
| Documenten testen | Bereken de BLEU-score. | Wees strikt. Testdocumenten opstellen om in de toekomst optimaal representatief te zijn voor wat u in de toekomst wilt vertalen. |
| Woordgroepenwoordenlijst | Dwingt de gegeven vertaling 100% van de tijd af. | Wees beperkend. Een woordgroepswoordenlijst is hoofdlettergevoelig en een woord of woordgroep die wordt vermeld, wordt vertaald op de manier die u opgeeft. In veel gevallen is het beter om geen woordenlijst te gebruiken en het systeem te laten leren. |
| Zinswoordenlijst | Dwingt de gegeven vertaling 100% van de tijd af. | Wees strikt. Een zinswoordenlijst is hoofdlettergevoelig en geschikt voor algemene korte zinnen in een domein. De volledige verzonden zin moet overeenkomen met de bronwoordenlijstvermelding om een woordenlijst te vinden. Als slechts een deel van de zin overeenkomt, komt de vermelding niet overeen. |
Wat is een BLEU-score?
BLEU (Tweetalige Evaluatie Understudy) is een algoritme voor het evalueren van de precisie of nauwkeurigheid van tekst die van de ene taal naar de andere wordt vertaald. Azure AI Custom Translator maakt gebruik van de metrische GEGEVENS VAN BLUE ALS één manier om de nauwkeurigheid van de vertaling over te brengen.
Een BLEU-score is een getal tussen nul en 100. Een score van nul geeft een vertaling van lage kwaliteit aan waarbij niets in de vertaling overeenkomt met de verwijzing. Een score van 100 geeft een perfecte vertaling aan die identiek is aan de verwijzing. Het is niet nodig om een score van 100 te bereiken - een BLEU-score tussen 40 en 60 geeft een hoogwaardige vertaling aan.
Wat gebeurt er als ik geen afstemmings- of testgegevens verzend?
Het afstemmen en testen van zinnen is optimaal representatief voor wat u in de toekomst wilt vertalen. Als u geen afstemmings- of testgegevens verzendt, sluit Azure AI Custom Translator automatisch zinnen uit van uw trainingsdocumenten om te gebruiken als afstemmings- en testgegevens.
| Door systeem gegenereerd | Handmatige selectie |
|---|---|
| Gemakkelijk. | Hiermee kunt u afstemmen op uw toekomstige behoeften. |
| Goed, als u weet dat uw trainingsgegevens representatief zijn voor wat u van plan bent om te vertalen. | Biedt meer vrijheid om uw trainingsgegevens op te stellen. |
| Eenvoudig opnieuw uitvoeren wanneer u het domein vergroot of verkleint. | Biedt meer gegevens en betere domeindekking. |
| Hiermee wijzigt u elke trainingsuitvoering. | Blijft statisch ten opzichte van herhaalde trainingsuitvoeringen |
Hoe wordt trainingsmateriaal verwerkt door Azure AI Custom Translator?
Ter voorbereiding op training ondergaan documenten een reeks verwerkings- en filterstappen. Kennis van het filterproces kan helpen bij het begrijpen van het aantal weergegeven zinnen en de stappen die u kunt nemen om trainingsdocumenten voor te bereiden voor training met Azure AI Custom Translator. De filterstappen zijn als volgt:
Uitlijning van zinnen
Als uw document zich niet in
XLIFF,XLSXTMXofALIGNin de indeling bevindt, worden de zinnen van uw bron- en doeldocumenten in Azure AI Custom Translator uitgelijnd op elkaar, zin-per-zin. Translator voert geen documentuitlijning uit. Het volgt uw naamconventie voor de documenten om een overeenkomend document in de andere taal te vinden. In de brontekst probeert Azure AI Custom Translator de bijbehorende zin in de doeltaal te vinden. Er wordt gebruikgemaakt van documentmarkeringen zoals ingesloten HTML-tags om u te helpen bij de uitlijning.Als u een grote discrepantie ziet tussen het aantal zinnen in de bron- en doeldocumenten, kan het brondocument niet parallel zijn of niet worden uitgelijnd. Het document paren met een groot verschil (>10%) aan zinnen aan elke zijde geven een tweede blik om er zeker van te zijn dat ze inderdaad parallel zijn.
Gegevensextractie afstemmen en testen
Het afstemmen en testen van gegevens is optioneel. Als u het niet opgeeft, verwijdert het systeem een geschikt percentage uit uw trainingsdocumenten om te gebruiken voor het afstemmen en testen. De verwijdering vindt dynamisch plaats als onderdeel van het trainingsproces. Omdat deze stap plaatsvindt als onderdeel van de training, worden uw geüploade documenten niet beïnvloed. U kunt het laatste aantal gebruikte zinnen zien voor elke gegevenscategorie( training, afstemming, testen en woordenlijst) op de pagina Modeldetails nadat de training is geslaagd.
Lengtefilter
- Hiermee verwijdert u zinnen met slechts één woord aan beide zijden.
- Hiermee verwijdert u zinnen met meer dan 100 woorden aan beide zijden. Chinees, Japans, Koreaans zijn vrijgesteld.
- Hiermee verwijdert u zinnen met minder dan drie tekens. Chinees, Japans, Koreaans zijn vrijgesteld.
- Hiermee verwijdert u zinnen met meer dan 2000 tekens voor Chinees, Japans, Koreaans.
- Hiermee verwijdert u zinnen met minder dan 1% alfanumerieke tekens.
- Hiermee verwijdert u woordenlijstvermeldingen met meer dan 50 woorden.
Witruimte
- Vervangt elke reeks witruimtetekens, inclusief tabs en CR/LF-reeksen door één spatieteken.
- Hiermee verwijdert u voorloop- of volgruimte in de zin.
Interpunctie van zin beëindigen
Vervangt meerdere interpunctietekens voor zinnen door één exemplaar. Japanse karakternormalisatie.
Converteert letters en cijfers met volledige breedte naar tekens met halve breedte.
Niet-gescaped XML-tags
Transformeert niet-gescaped tags in escape-tags:
Etiket Wordt < & Lt; > & Gt; & & Amp; Ongeldige tekens
Azure AI Custom Translator verwijdert zinnen die Unicode-teken U+FFFD bevatten. Het teken U+FFFD geeft een mislukte coderingsomzetting aan.
Welke stappen moet ik uitvoeren voordat ik gegevens upload?
- Zinnen met ongeldige codering verwijderen.
- Unicode-besturingstekens verwijderen.
- Zinnen uitlijnen (bron-naar-doel), indien haalbaar.
- Verwijder bron- en doelzinnen die niet overeenkomen met de bron- en doeltalen.
- Wanneer bron- en doelzinnen gemengde talen hebben, moet u ervoor zorgen dat niet-vertaalde woorden opzettelijk zijn, bijvoorbeeld namen van organisaties en producten.
- Vermijd lesfouten voor uw model door ervoor te zorgen dat grammatica en typografie juist zijn.
- Eén bronzin toewijzen aan één doelzin. Hoewel ons trainingsproces bron- en doellijnen met meerdere zinnen verwerkt, is een-op-een-toewijzing een best practice.
Hoe kan ik de resultaten evalueren?
Nadat uw model is getraind, kunt u de BLAUW-score van het model en de basislijnmodel-BLAUW-score bekijken op de pagina met modeldetails. We gebruiken dezelfde set testgegevens om zowel de BLEU-score van het model als de BASISLIJN-SCORE VAN HET MODEL TE genereren. Deze gegevens helpen u bij het nemen van een weloverwogen beslissing over welk model beter zou zijn voor uw use-case.