Uitschalen van Azure Analysis Services
Met uitschalen kunnen clientquery's worden gedistribueerd tussen meerdere queryreplica's in een querygroep, waardoor reactietijden tijdens hoge queryworkloads worden verminderd. U kunt de verwerking ook scheiden van de querygroep, zodat clientquery's niet nadelig worden beïnvloed door verwerkingsbewerkingen. Uitschalen kan worden geconfigureerd in Azure Portal of met behulp van de Analysis Services REST API.
Uitschalen is beschikbaar voor servers in de prijscategorie Standaard. Queryreplica's worden gefactureerd tegen hetzelfde tarief als uw server. Alle queryreplica's worden gemaakt in dezelfde regio als uw server. Het aantal queryreplica's dat u kunt configureren, wordt beperkt door de regio waarin uw server zich bevindt. Zie Beschikbaarheid per regio voor meer informatie. Uitschalen verhoogt niet de hoeveelheid beschikbaar geheugen voor uw server. Om het geheugen te vergroten, moet u uw abonnement upgraden.
Waarom uitschalen?
In een typische serverimplementatie fungeert één server als zowel de verwerkingsserver als de queryserver. Als het aantal clientquery's voor modellen op uw server groter is dan de QPU (Query Processing Units) voor het plan van uw server, of als de modelverwerking op hetzelfde moment plaatsvindt als hoge queryworkloads, kunnen de prestaties afnemen.
Met uitschalen kunt u een querygroep maken met maximaal zeven queryreplicaresources (acht totaal, inclusief uw primaire server). U kunt het aantal replica's in de querypool schalen om op kritieke momenten te voldoen aan QPU-vereisten en u kunt op elk gewenst moment een verwerkingsserver scheiden van de querypool.
Ongeacht het aantal queryreplica's dat u in een querygroep hebt, worden verwerkingsworkloads niet verdeeld over queryreplica's. De primaire server fungeert als de verwerkingsserver. Queryreplica's dienen alleen query's voor de modeldatabases die zijn gesynchroniseerd tussen de primaire server en elke replica in de querygroep.
Wanneer u uitschaalt, kan het tot vijf minuten duren voordat nieuwe queryreplica's incrementeel worden toegevoegd aan de querygroep. Wanneer alle nieuwe queryreplica's actief zijn, worden nieuwe clientverbindingen verdeeld over resources in de querygroep. Bestaande clientverbindingen worden niet gewijzigd van de resource waaraan ze momenteel zijn verbonden. Wanneer u inschaalt, worden bestaande clientverbindingen met een querygroepresource die uit de querygroep wordt verwijderd, beëindigd. Clients kunnen opnieuw verbinding maken met een resterende querygroepresource.
Hoe het werkt
Wanneer u de eerste keer uitschalen configureert, worden modeldatabases op uw primaire server automatisch gesynchroniseerd met nieuwe replica's in een nieuwe querygroep. Automatische synchronisatie vindt slechts één keer plaats. Tijdens automatische synchronisatie worden de gegevensbestanden van de primaire server (versleuteld at rest in blob-opslag) gekopieerd naar een tweede locatie, ook versleuteld in rest in blob-opslag. Replica's in de querygroep worden vervolgens gehydrateerd met gegevens uit de tweede set bestanden.
Hoewel een automatische synchronisatie alleen wordt uitgevoerd wanneer u een server voor de eerste keer uitschaalt, kunt u ook een handmatige synchronisatie uitvoeren. Synchronisatie zorgt ervoor dat gegevens op replica's in de querygroep overeenkomen met die van de primaire server. Bij het verwerken (vernieuwen) van modellen op de primaire server moet er een synchronisatie worden uitgevoerd nadat de verwerking is voltooid. Met deze synchronisatie worden bijgewerkte gegevens uit de bestanden van de primaire server in blobopslag gekopieerd naar de tweede set bestanden. Replica's in de querygroep worden vervolgens gehydrateerd met bijgewerkte gegevens uit de tweede set bestanden in blobopslag.
Wanneer u een volgende uitschaalbewerking uitvoert, bijvoorbeeld door het aantal replica's in de querygroep te verhogen van twee tot vijf, worden de nieuwe replica's gehydrateerd met gegevens uit de tweede set bestanden in blobopslag. Er is geen synchronisatie. Als u vervolgens een synchronisatie uitvoert na uitschalen, worden de nieuwe replica's in de querygroep tweemaal gehydrateerd: een redundante hydratatie. Wanneer u een volgende uitschaalbewerking uitvoert, is het belangrijk om rekening te houden met:
Voer een synchronisatie uit vóór de uitschaalbewerking om redundante hydratatie van de toegevoegde replica's te voorkomen. Gelijktijdige synchronisatie- en uitschaalbewerkingen die tegelijkertijd worden uitgevoerd, zijn niet toegestaan.
Wanneer u zowel verwerkings - als uitschaalbewerkingen automatiseert, is het belangrijk om eerst gegevens op de primaire server te verwerken, vervolgens een synchronisatie uit te voeren en vervolgens de uitschaalbewerking uit te voeren. Deze reeks zorgt voor minimale impact op QPU- en geheugenbronnen.
Tijdens uitschaalbewerkingen zijn alle servers in de querygroep, inclusief de primaire server, tijdelijk offline.
Synchronisatie is toegestaan, zelfs als er geen replica's in de querygroep aanwezig zijn. Als u uitschaalt van nul naar een of meer replica's met nieuwe gegevens uit een verwerkingsbewerking op de primaire server, voert u eerst de synchronisatie uit zonder replica's in de querygroep en schaalt u vervolgens uit. Synchroniseren voordat u uitschaalt, voorkomt redundante hydratatie van de zojuist toegevoegde replica's.
Wanneer u een modeldatabase van de primaire server verwijdert, wordt deze niet automatisch verwijderd uit replica's in de querygroep. U moet een synchronisatiebewerking uitvoeren met behulp van de PowerShell-opdracht Sync-AzAnalysisServicesInstance, die de bestanden voor die database verwijderd uit de gedeelde blobopslaglocatie van de replica en vervolgens de modeldatabase op de replica's in de querypool verwijdert. Als u wilt bepalen of er een modeldatabase bestaat op replica's in de querygroep, maar niet op de primaire server, controleert u of de verwerkingsserver gescheiden is van de instelling van de querygroep op Ja. Gebruik vervolgens SQL Server Management Studio (SSMS) om verbinding te maken met de primaire server met behulp van de
:rwkwalificatie om te zien of de database bestaat. Maak vervolgens verbinding met replica's in de querygroep door verbinding te maken zonder de:rwkwalificatie om te zien of dezelfde database ook bestaat. Als de database bestaat op replica's in de querygroep, maar niet op de primaire server, voert u een synchronisatiebewerking uit.Wanneer u de naam van een database op de primaire server wijzigt, is er nog een stap nodig om ervoor te zorgen dat de database correct wordt gesynchroniseerd met replica's. Voer na het wijzigen van de naam een synchronisatie uit met behulp van de opdracht Sync-AzAnalysisServicesInstance die de
-Databaseparameter met de oude databasenaam opgeeft. Met deze synchronisatie worden de database en bestanden met de oude naam verwijderd uit replica's. Voer vervolgens een andere synchronisatie uit die de-Databaseparameter opgeeft met de nieuwe databasenaam. Met de tweede synchronisatie wordt de zojuist genoemde database gekopieerd naar de tweede set bestanden en worden alle replica's gehydrateerd. Deze synchronisaties kunnen niet worden uitgevoerd met behulp van de opdracht Model synchroniseren in de portal.
Synchronisatiemodus
Queryreplica's worden standaard volledig gerehydrateerd, niet incrementeel. Rehydratatie vindt plaats in fasen. Ze worden losgekoppeld en twee tegelijk gekoppeld (ervan uitgaande dat er ten minste drie replica's zijn) om ervoor te zorgen dat ten minste één replica online wordt gehouden voor query's op elk gewenst moment. In sommige gevallen moeten clients mogelijk opnieuw verbinding maken met een van de onlinereplica's terwijl dit proces plaatsvindt. Met behulp van de instelling ReplicaSyncMode kunt u nu de synchronisatie van queryreplica's parallel opgeven. Parallelle synchronisatie biedt de volgende voordelen:
- Aanzienlijke vermindering van de synchronisatietijd.
- Gegevens tussen replica's zijn waarschijnlijk consistenter tijdens het synchronisatieproces.
- Databases worden tijdens het synchronisatieproces online gehouden op alle replica's, waardoor gebruikers niet opnieuw verbinding hoeven te maken.
- De cache in het geheugen wordt incrementeel bijgewerkt met alleen de gewijzigde gegevens, die sneller kunnen zijn dan het volledig reactiveren van het model.
ReplicaSyncMode instellen
Gebruik SSMS om ReplicaSyncMode in geavanceerde eigenschappen in te stellen. Mogelijke waarden zijn:
-
1(standaard): Rehydratatie van volledige replicadatabases in fasen (incrementeel). -
2: Geoptimaliseerde synchronisatie parallel.
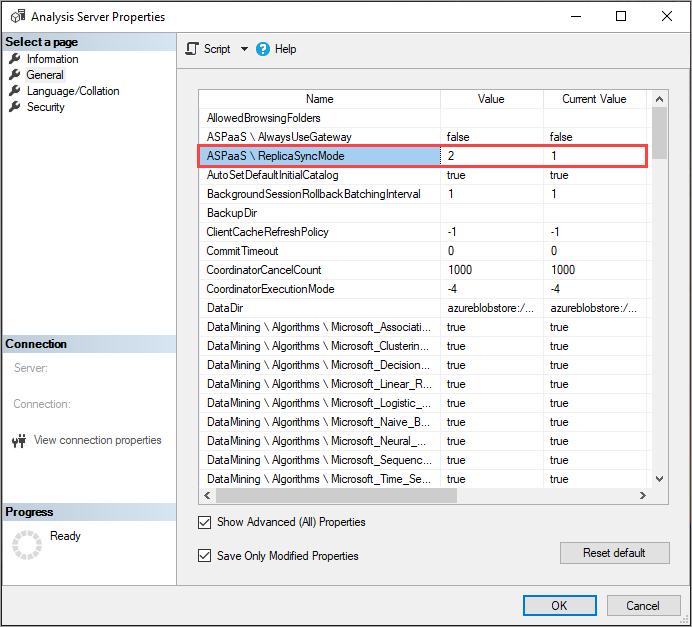
Bij het instellen van ReplicaSyncMode=2, afhankelijk van de hoeveelheid cache die moet worden bijgewerkt, kan er meer geheugen worden verbruikt door de queryreplica's. Als u de database online wilt houden en beschikbaar wilt houden voor query's, afhankelijk van de hoeveelheid gegevens die is gewijzigd, kan de bewerking maximaal het dubbele geheugen op de replica vereisen, omdat zowel de oude als de nieuwe segmenten tegelijkertijd in het geheugen worden bewaard. Replicaknooppunten hebben dezelfde geheugentoewijzing als het primaire knooppunt en er is normaal gesproken extra geheugen op het primaire knooppunt voor vernieuwingsbewerkingen. Het kan dus onwaarschijnlijk zijn dat de replica's onvoldoende geheugen bevatten. Daarnaast is het veelvoorkomende scenario dat de database incrementeel wordt bijgewerkt op het primaire knooppunt, en daarom moet de vereiste voor het dubbele geheugen ongebruikelijk zijn. Als er tijdens de synchronisatiebewerking een fout met onvoldoende geheugen optreedt, wordt opnieuw geprobeerd met behulp van de standaardtechniek (twee tegelijk koppelen/loskoppelen).
Verwerking scheiden van querygroep
Voor maximale prestaties voor zowel verwerkings- als querybewerkingen kunt u ervoor kiezen om uw verwerkingsserver te scheiden van de querygroep. Wanneer deze worden gescheiden, worden nieuwe clientverbindingen alleen toegewezen aan queryreplica's in de querygroep. Als verwerkingsbewerkingen slechts een korte tijd in beslag nemen, kunt u ervoor kiezen om de verwerkingsserver alleen te scheiden van de querygroep voor de hoeveelheid tijd die nodig is om verwerkings- en synchronisatiebewerkingen uit te voeren en deze vervolgens weer op te nemen in de querygroep. Het kan vijf minuten duren voordat de bewerking is voltooid door de verwerkingsserver van de querygroep te scheiden of deze weer toe te voegen aan de querygroep.
QPU-gebruik bewaken
Als u wilt bepalen of uitschalen voor uw server nodig is, controleert u de metrische servergegevens in Azure Portal. Als uw QPU regelmatig maximaal is, betekent dit dat het aantal query's voor uw modellen de QPU-limiet voor uw abonnement overschrijdt. De metrische waarde voor de wachtrijlengte van de querygroep neemt ook toe wanneer het aantal query's in de wachtrij van de querythreadpool de beschikbare QPU overschrijdt.
Een andere goede metriek die u kunt bekijken, is gemiddeld QPU per ServerResourceType. Deze metrische waarde vergelijkt de gemiddelde QPU voor de primaire server met de querygroep.
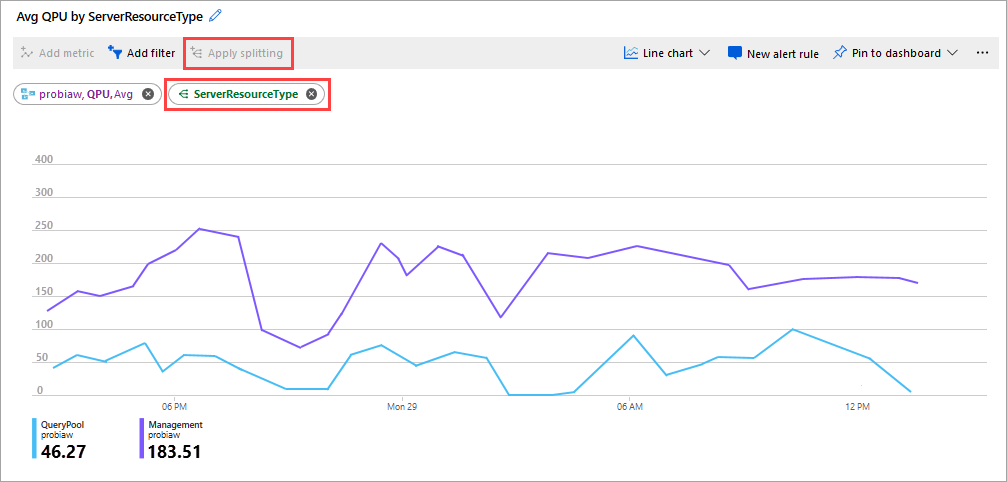
QPU configureren op ServerResourceType
- Klik in een lijndiagram met metrische gegevens op Metrische gegevens toevoegen.
- Selecteer uw server in RESOURCE en selecteer vervolgens in METRIC NAMESPACE, analysis Services standard metrics, then in METRIC, select QPU, and then in AGGREGATION, select Avg.
- Klik op Splitsen toepassen.
- Selecteer ServerResourceType in VALUES.
Gedetailleerde logboekregistratie van diagnostische gegevens
Gebruik Azure Monitor-logboeken voor gedetailleerdere diagnostische gegevens over uitgeschaalde serverresources. Met logboeken kunt u Log Analytics-query's gebruiken om QPU en geheugen op server en replica uit te splitsen. Zie Logboeken analyseren in Log Analytics-werkruimte voor meer informatie. Zie voorbeeldquery's voor Kusto-voorbeeldquery's.
Uitschalen configureren
In Azure Portal
Klik in de portal op Uitschalen. Gebruik de schuifregelaar om het aantal queryreplicaservers te selecteren. Het aantal replica's dat u kiest, is naast uw bestaande server.
Selecteer ja als u de verwerkingsserver van de querygroep wilt uitsluiten van queryservers. Clientverbindingen die gebruikmaken van de standaard-verbindingsreeks (zonder
:rw) worden omgeleid naar replica's in de querygroep.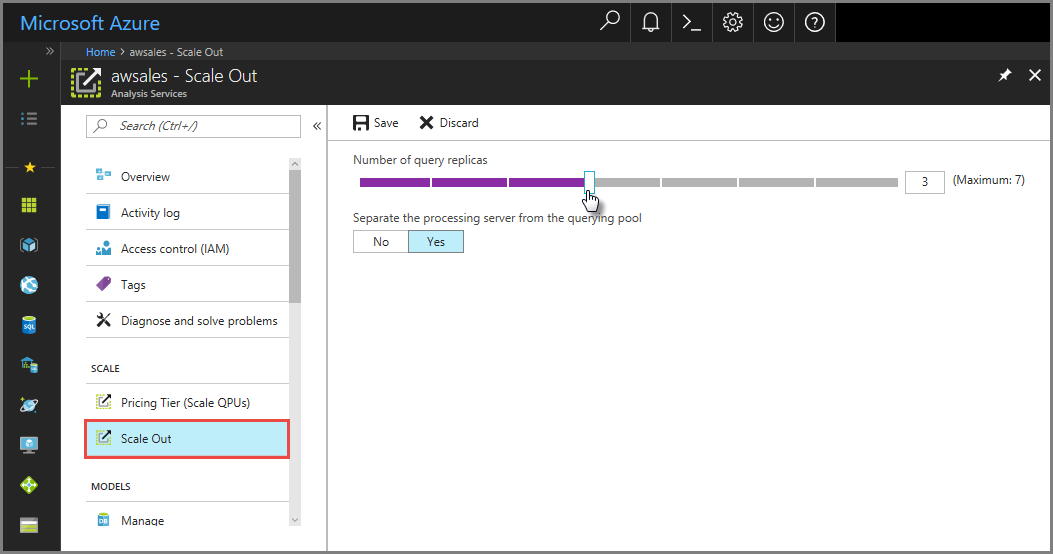
Klik op Opslaan om de nieuwe queryreplicaservers in te richten.
Wanneer u uitschalen voor een server de eerste keer configureert, worden modellen op uw primaire server automatisch gesynchroniseerd met replica's in de querygroep. Automatische synchronisatie vindt slechts één keer plaats wanneer u voor het eerst uitschalen naar een of meer replica's configureert. Volgende wijzigingen in het aantal replica's op dezelfde server activeren geen andere automatische synchronisatie. Automatische synchronisatie vindt niet opnieuw plaats, zelfs niet als u de server instelt op nul replica's en vervolgens opnieuw schaalt naar een willekeurig aantal replica's.
Synchroniseren
Synchronisatiebewerkingen moeten handmatig of met behulp van de REST API worden uitgevoerd.
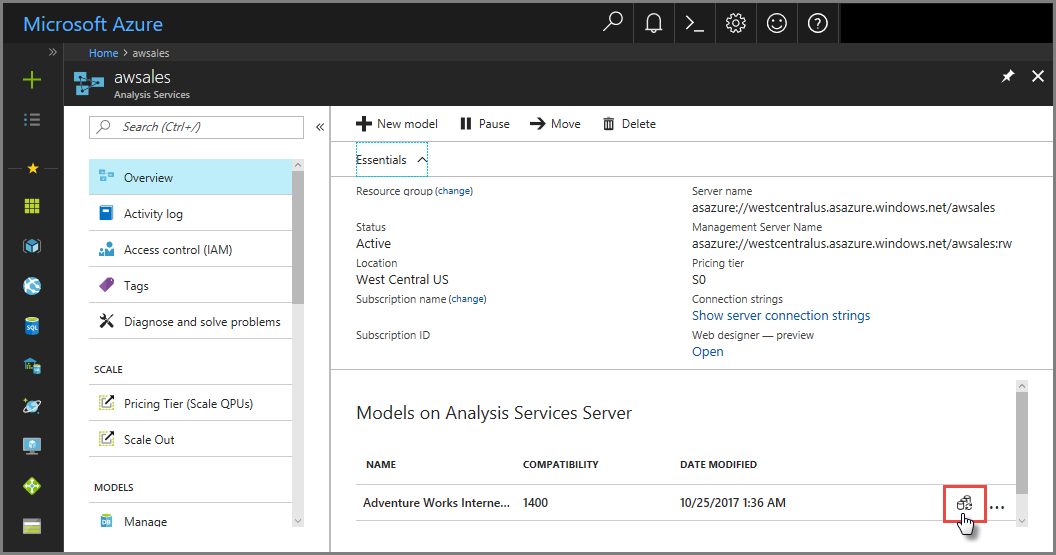
In Azure Portal
In overzichtsmodel >synchroniseren model.>
REST-API
Gebruik de synchronisatiebewerking .
Een model synchroniseren
POST https://<region>.asazure.windows.net/servers/<servername>:rw/models/<modelname>/sync
Synchronisatiestatus ophalen
GET https://<region>.asazure.windows.net/servers/<servername>/models/<modelname>/sync
Statuscodes retourneren:
| Code | Beschrijving |
|---|---|
| -1 | Ongeldig |
| 0 | Repliceren |
| 1 | Rehydrateren |
| 2 | Voltooid |
| 3 | Mislukt |
| 4 | Finaliseren |
Powershell
Notitie
Het wordt aanbevolen de Azure Az PowerShell-module te gebruiken om te communiceren met Azure. Zie Azure PowerShell installeren om aan de slag te gaan. Raadpleeg Azure PowerShell migreren van AzureRM naar Az om te leren hoe u naar de Azure PowerShell-module migreert.
Voordat u PowerShell gebruikt, moet u de meest recente Azure PowerShell-module installeren of bijwerken.
Gebruik Sync-AzAnalysisServicesInstance om synchronisatie uit te voeren.
Gebruik Set-AzAnalysisServicesServer om het aantal queryreplica's in te stellen. Geef de optionele -ReadonlyReplicaCount parameter op.
Gebruik Set-AzAnalysisServicesServer om de verwerkingsserver van de querygroep te scheiden. Geef de optionele -DefaultConnectionMode parameter op die moet worden gebruikt Readonly.
Zie Een service-principal gebruiken met de Module Az.AnalysisServices voor meer informatie.
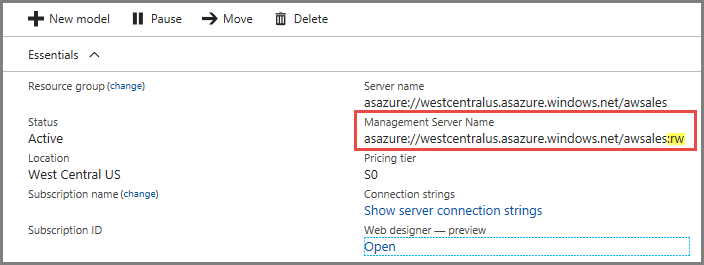
Connecties
Op de overzichtspagina van uw server zijn er twee servernamen. Als u de uitschaal voor een server nog niet hebt geconfigureerd, werken beide servernamen op dezelfde wijze. Zodra u uitschalen voor een server hebt geconfigureerd, moet u de juiste servernaam opgeven, afhankelijk van het verbindingstype.
Gebruik servernaam voor clientverbindingen van eindgebruikers, zoals Power BI Desktop, Excel en aangepaste apps.
Gebruik voor SSMS, Visual Studio en verbindingsreeks s in PowerShell, Azure Function-apps en AMO de naam van de beheerserver. De naam van de beheerserver bevat een speciale :rw kwalificatie (read-write). Alle verwerkingsbewerkingen vinden plaats op de (primaire) beheerserver.
Omhoog schalen, omlaag schalen versus uitschalen
U kunt de prijscategorie op een server wijzigen met meerdere replica's. Dezelfde prijscategorie is van toepassing op alle replica's. Een schaalbewerking brengt eerst alle replica's tegelijk omlaag en brengt vervolgens alle replica's in de nieuwe prijscategorie weer.
Problemen oplossen
Probleem: gebruikers krijgen een foutbericht dat de servernaam< van het serverexemplaren> niet kan vinden in de verbindingsmodus ReadOnly.
Oplossing: Wanneer u de verwerkingsserver van de optie Querygroep scheiden selecteert, worden clientverbindingen met behulp van de standaard-verbindingsreeks (zonder:rw) omgeleid naar querygroepreplica's. Als replica's in de querygroep nog niet online zijn omdat de synchronisatie nog niet is voltooid, kunnen omgeleide clientverbindingen mislukken. Als u mislukte verbindingen wilt voorkomen, moeten er ten minste twee servers in de querygroep zijn bij het uitvoeren van een synchronisatie. Elke server wordt afzonderlijk gesynchroniseerd terwijl anderen online blijven. Als u ervoor kiest om de verwerkingsserver tijdens de verwerking niet in de querygroep te hebben, kunt u deze verwijderen uit de pool voor verwerking en deze vervolgens weer toevoegen aan de pool nadat de verwerking is voltooid, maar voordat de synchronisatie is voltooid. Gebruik metrische gegevens over geheugen en QPU om de synchronisatiestatus te bewaken.