Aangepaste modellen: nauwkeurigheid en betrouwbaarheidsscores
Deze inhoud is van toepassing op:![]() v4.0 (preview)
v4.0 (preview)![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Notitie
- Aangepaste neurale modellen bieden geen nauwkeurigheidsscores tijdens de training.
- Betrouwbaarheidsscores voor tabellen, tabelrijen en tabelcellen zijn beschikbaar vanaf de API-versie 2024-02-29-preview voor aangepaste modellen.
Aangepaste sjabloonmodellen genereren een geschatte nauwkeurigheidsscore wanneer ze worden getraind. Documenten die zijn geanalyseerd met een aangepast model, leveren een betrouwbaarheidsscore op voor geëxtraheerde velden. In dit artikel leert u hoe u nauwkeurigheids- en betrouwbaarheidsscores en aanbevolen procedures voor het gebruik van deze scores interpreteert om de nauwkeurigheid en betrouwbaarheidsresultaten te verbeteren.
Nauwkeurigheidsscores
De uitvoer van een build aangepaste modelbewerking (v3.0) of train (v2.1) bevat de geschatte nauwkeurigheidsscore. Deze score vertegenwoordigt de mogelijkheid van het model om de gelabelde waarde nauwkeurig te voorspellen in een visueel vergelijkbaar document.
Het nauwkeurigheidswaardebereik is een percentage tussen 0% (laag) en 100% (hoog). De geschatte nauwkeurigheid wordt berekend door een aantal verschillende combinaties van de trainingsgegevens uit te voeren om de gelabelde waarden te voorspellen.
Aangepast model voor Document Intelligence Studio
getraind (factuur)
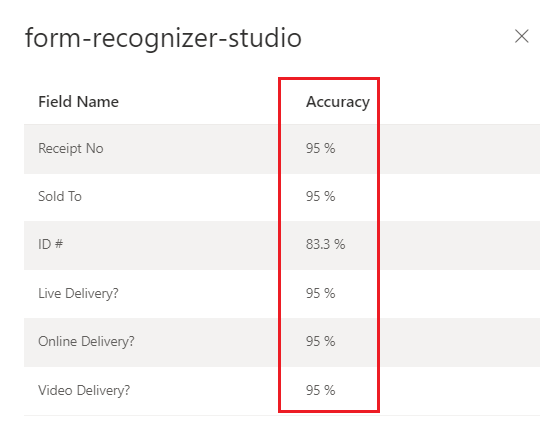
Betrouwbaarheidsscores
Notitie
- Tabel-, rij- en celvertrouwensscores zijn nu opgenomen in de API-versie 2024-02-29-preview.
- Betrouwbaarheidsscores voor tabelcellen van aangepaste modellen worden toegevoegd aan de API vanaf de API 2024-02-29-preview-API.
Resultaten van document intelligence-analyse retourneren een geschatte betrouwbaarheid voor voorspelde woorden, sleutel-waardeparen, selectiemarkeringen, regio's en handtekeningen. Momenteel retourneren niet alle documentvelden een betrouwbaarheidsscore.
Veldvertrouwen geeft een geschatte waarschijnlijkheid aan tussen 0 en 1 dat de voorspelling juist is. Een betrouwbaarheidswaarde van 0,95 (95%) geeft bijvoorbeeld aan dat de voorspelling waarschijnlijk 19 van de 20 keer juist is. Voor scenario's waarbij nauwkeurigheid kritiek is, kan het vertrouwen worden gebruikt om te bepalen of de voorspelling automatisch moet worden geaccepteerd of een vlag moet worden toegevoegd voor menselijke beoordeling.
Document Intelligence Studio
: vooraf samengesteld factuurmodel geanalyseerd
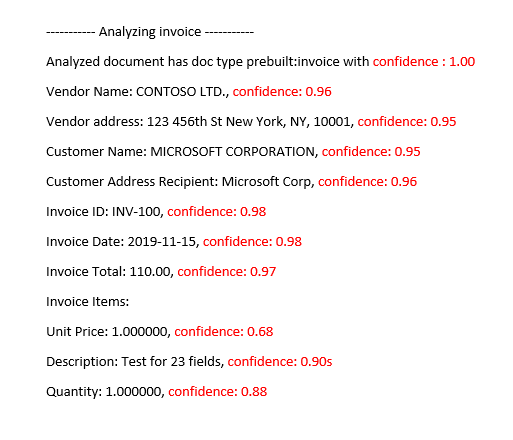
Nauwkeurigheids- en betrouwbaarheidsscores interpreteren voor aangepaste modellen
Wanneer u de betrouwbaarheidsscore van een aangepast model interpreteert, moet u rekening houden met alle betrouwbaarheidsscores die door het model worden geretourneerd. Laten we beginnen met een lijst met alle betrouwbaarheidsscores.
- Betrouwbaarheidsscore van documenttype: het betrouwbaarheidstype van het document is een indicator van het geanalyseerde document lijkt op documenten in de trainingsgegevensset. Wanneer het betrouwbaarheidstype van het document laag is, wijst dit op sjabloon- of structurele variaties in het geanalyseerde document. Als u het vertrouwen van het documenttype wilt verbeteren, labelt u een document met die specifieke variatie en voegt u het toe aan uw trainingsgegevensset. Zodra het model opnieuw is getraind, moet het beter zijn uitgerust om die klasse van variaties te verwerken.
- Betrouwbaarheid op veldniveau: elk geëxtraheerd veld heeft een bijbehorende betrouwbaarheidsscore. Deze score weerspiegelt het vertrouwen van het model op de positie van de geëxtraheerde waarde. Tijdens het evalueren van betrouwbaarheidsscores moet u ook kijken naar het onderliggende extractievertrouwen om een uitgebreid vertrouwen te genereren voor het geëxtraheerde resultaat. Evalueer de
OCRresultaten voor tekstextractie of selectiemarkeringen, afhankelijk van het veldtype om een samengestelde betrouwbaarheidsscore voor het veld te genereren. - Word-betrouwbaarheidsscore Elk woord dat in het document is geëxtraheerd, heeft een bijbehorende betrouwbaarheidsscore. De score vertegenwoordigt het vertrouwen van de transcriptie. De paginamatrix bevat een matrix met woorden en elk woord heeft een bijbehorende span- en betrouwbaarheidsscore. De geëxtraheerde waarden van het aangepaste veld komen overeen met de reeks geëxtraheerde woorden.
- Betrouwbaarheidsscore van selectiemarkeringen: De paginamatrix bevat ook een matrix met selectiemarkeringen. Elke selectiemarkering heeft een betrouwbaarheidsscore die het vertrouwen van de selectiemarkering en de detectie van de selectiestatus vertegenwoordigt. Wanneer een gelabeld veld een selectiemarkering heeft, is de aangepaste veldselectie in combinatie met het betrouwbaarheidsvertrouwen van de selectiemarkering een nauwkeurige weergave van de algehele betrouwbaarheidsnauwkeurigheid.
In de volgende tabel ziet u hoe u zowel de nauwkeurigheid als betrouwbaarheidsscores interpreteert om de prestaties van uw aangepaste model te meten.
| Nauwkeurigheid | Betrouwbaarheid | Resultaat |
|---|---|---|
| Hoog | Hoog | • Het model presteert goed met de gelabelde sleutels en documentindelingen. • U hebt een evenwichtige trainingsgegevensset. |
| Hoog | Beperkt | • Het geanalyseerde document lijkt anders dan de trainingsgegevensset. • Het model zou profiteren van hertraining met ten minste vijf meer gelabelde documenten. • Deze resultaten kunnen ook duiden op een indelingsvariatie tussen de trainingsgegevensset en het geanalyseerde document. Overweeg een nieuw model toe te voegen. |
| Laag | Hoog | • Dit resultaat is het meest onwaarschijnlijk. • Voor lage nauwkeurigheidsscores voegt u meer gelabelde gegevens toe of splitst u visueel afzonderlijke documenten in meerdere modellen. |
| Beperkt | Beperkt | • Voeg meer gelabelde gegevens toe. • Splits visueel afzonderlijke documenten in meerdere modellen. |
Betrouwbaarheid van tabellen, rijen en cellen
Met de toevoeging van tabel-, rij- en celvertrouwen met de 2024-02-29-preview API zijn hier enkele veelgestelde vragen die u moeten helpen bij het interpreteren van de tabel-, rij- en celscores:
V: Is het mogelijk om een hoge betrouwbaarheidsscore voor cellen te zien, maar een lage betrouwbaarheidsscore voor de rij?
A: Ja. De verschillende niveaus van tabelvertrouwen (cel, rij en tabel) zijn bedoeld om de juistheid van een voorspelling op dat specifieke niveau vast te leggen. Een correct voorspelde cel die deel uitmaakt van een rij met andere mogelijke gemiste cellen zou een hoge celvertrouwen hebben, maar het vertrouwen van de rij moet laag zijn. Op dezelfde manier zou een juiste rij in een tabel met uitdagingen met andere rijen een hoge rijvertrouwen hebben, terwijl het algehele vertrouwen van de tabel laag zou zijn.
V: Wat is de verwachte betrouwbaarheidsscore wanneer cellen worden samengevoegd? Omdat een samenvoeging resulteert in het aantal kolommen dat moet worden gewijzigd, hoe worden scores beïnvloed?
A: Ongeacht het type tabel, is de verwachting voor samengevoegde cellen dat ze lagere betrouwbaarheidswaarden moeten hebben. Bovendien moet de cel die ontbreekt (omdat deze is samengevoegd met een aangrenzende cel) ook waarde hebben NULL met een lagere betrouwbaarheid. Hoeveel lager deze waarden kunnen zijn, is afhankelijk van de trainingsgegevensset, de algemene trend van zowel samengevoegde als ontbrekende cellen met lagere scores.
V: Wat is de betrouwbaarheidsscore wanneer een waarde optioneel is? Moet u een cel met een NULL waarde en een hoge betrouwbaarheidsscore verwachten als de waarde ontbreekt?
A: Als uw trainingsgegevensset representatief is voor de optioneelheid van cellen, helpt het model te weten hoe vaak een waarde in de trainingsset wordt weergegeven en dus wat u kunt verwachten tijdens deductie. Deze functie wordt gebruikt bij het berekenen van het vertrouwen van een voorspelling of om helemaal geen voorspelling te doen (NULL). U zou een leeg veld met een hoge betrouwbaarheid moeten verwachten voor ontbrekende waarden die meestal ook leeg zijn in de trainingsset.
V: Hoe worden betrouwbaarheidsscores beïnvloed als een veld optioneel is en niet aanwezig of gemist is? Is de verwachting dat de betrouwbaarheidsscore die vraag beantwoordt?
A: Wanneer een waarde ontbreekt in een rij, heeft de cel een NULL waarde en betrouwbaarheid toegewezen. Een hoge betrouwbaarheidsscore zou hier moeten betekenen dat de modelvoorspelling (of er geen waarde is) waarschijnlijk juist is. Een lage score zou daarentegen meer onzekerheid van het model moeten signaleren (en dus de mogelijkheid van een fout, zoals de waarde die wordt gemist).
V: Wat moet de verwachting zijn voor betrouwbaarheid van cellen en rijvertrouwen bij het extraheren van een tabel met meerdere pagina's met een rij die is verdeeld over pagina's?
A: Verwacht dat de betrouwbaarheid van de cel hoog is en dat het rijvertrouwen mogelijk lager is dan rijen die niet zijn gesplitst. Het aandeel gesplitste rijen in de trainingsgegevensset kan van invloed zijn op de betrouwbaarheidsscore. Over het algemeen ziet een gesplitste rij er anders uit dan de andere rijen in de tabel (het model is dus minder zeker dat het juist is).
V: Voor tabellen op meerdere pagina's met rijen die correct eindigen en beginnen bij de paginagrenzen, is het juist om ervan uit te gaan dat betrouwbaarheidsscores consistent zijn tussen pagina's?
A: Ja. Omdat rijen er vergelijkbaar uitzien in vorm en inhoud, ongeacht waar ze zich in het document bevinden (of op welke pagina), moeten hun respectieve betrouwbaarheidsscores consistent zijn.
V: Wat is de beste manier om de nieuwe betrouwbaarheidsscores te gebruiken?
A: Bekijk alle niveaus van tabelvertrouwen die beginnen met een benadering van boven naar beneden: begin met het controleren van het vertrouwen van een tabel als geheel, zoom vervolgens in op het rijniveau en kijk naar afzonderlijke rijen en kijk ten slotte naar betrouwbaarheid op celniveau. Afhankelijk van het type tabel zijn er een aantal dingen van opmerking:
Voor vaste tabellen legt het vertrouwen op celniveau al behoorlijk wat informatie vast over de juistheid van dingen. Dit betekent dat het eenvoudigweg doorlopen van elke cel en het bekijken van het vertrouwen ervan voldoende kan zijn om de kwaliteit van de voorspelling te bepalen. Voor dynamische tabellen zijn de niveaus bedoeld om op elkaar te bouwen, zodat de top-to-bottom-benadering belangrijker is.
Hoge modelnauwkeurigheid garanderen
Afwijkingen in de visuele structuur van uw documenten zijn van invloed op de nauwkeurigheid van uw model. Gerapporteerde nauwkeurigheidsscores kunnen inconsistent zijn wanneer de geanalyseerde documenten verschillen van de documenten die worden gebruikt in de training. Houd er rekening mee dat een documentenset er vergelijkbaar uit kan zien wanneer deze door mensen wordt bekeken, maar niet hetzelfde lijkt als een AI-model. Om te volgen, is een lijst met de aanbevolen procedures voor trainingsmodellen met de hoogste nauwkeurigheid. Volgens deze richtlijnen moet een model met een hogere nauwkeurigheid en betrouwbaarheidsscores worden geproduceerd tijdens de analyse en het aantal documenten verminderen dat is gemarkeerd voor menselijke beoordeling.
Zorg ervoor dat alle variaties van een document zijn opgenomen in de trainingsgegevensset. Variaties omvatten verschillende indelingen, bijvoorbeeld digitale versus gescande PDF-bestanden.
Voeg ten minste vijf voorbeelden van elk type toe aan de trainingsgegevensset als u verwacht dat het model beide typen PDF-documenten analyseert.
Scheid visueel verschillende documenttypen om verschillende modellen te trainen.
- Als u in de regel alle door de gebruiker ingevoerde waarden verwijdert en de documenten er ongeveer als volgt uitzien, moet u meer trainingsgegevens toevoegen aan het bestaande model.
- Als de documenten niet hetzelfde zijn, splitst u uw trainingsgegevens op in verschillende mappen en traint u een model voor elke variatie. Vervolgens kunt u de verschillende variaties in één model samenstellen.
Zorg ervoor dat u geen overbodige labels hebt.
Zorg ervoor dat handtekening- en regiolabels de omringende tekst niet bevatten.