Document Intelligence-indelingsmodel
Belangrijk
- Openbare preview-versies van Document Intelligence bieden vroegtijdige toegang tot functies die actief zijn in ontwikkeling.
- Functies, benaderingen en processen kunnen veranderen, vóór algemene beschikbaarheid (GA), op basis van feedback van gebruikers.
- De openbare preview-versie van Document Intelligence-clientbibliotheken is standaard ingesteld op REST API-versie 2024-02-29-preview.
- Openbare preview-versie 2024-02-29-preview is momenteel alleen beschikbaar in de volgende Azure-regio's:
- VS - oost
- VS - west 2
- Europa -west
Deze inhoud is van toepassing op:![]() v4.0 (preview) | Vorige versies:
v4.0 (preview) | Vorige versies:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Deze inhoud is van toepassing op:![]() v3.1 (GA) | Nieuwste versie:
v3.1 (GA) | Nieuwste versie:![]() v4.0 (preview) | Vorige versies:
v4.0 (preview) | Vorige versies:![]() v3.0
v3.0![]() v2.1
v2.1
Deze inhoud is van toepassing op:![]() v3.0 (GA) | Nieuwste versies:
v3.0 (GA) | Nieuwste versies:![]() v4.0 (preview)
v4.0 (preview)![]() v3.1 | Vorige versie:
v3.1 | Vorige versie:![]() v2.1
v2.1
Deze inhoud is van toepassing op:![]() v2.1 | Nieuwste versie:
v2.1 | Nieuwste versie:![]() v4.0 (preview)
v4.0 (preview)
Document Intelligence-indelingsmodel is een geavanceerde machine learning-API voor documentanalyse die beschikbaar is in de Document Intelligence-cloud. Hiermee kunt u documenten in verschillende indelingen opnemen en gestructureerde gegevensweergaven van de documenten retourneren. Het combineert een verbeterde versie van onze krachtige OCR-mogelijkheden (Optical Character Recognition) met deep learning-modellen om tekst, tabellen, selectiemarkeringen en documentstructuur te extraheren.
Analyse van documentindeling
De indelingsanalyse van documentstructuur is het analyseren van een document om interessegebieden en hun onderlinge relaties te extraheren. Het doel is om tekst en structurele elementen van de pagina te extraheren om betere semantische begripsmodellen te maken. Er zijn twee typen rollen in een documentindeling:
- Geometrische rollen: Tekst, tabellen, afbeeldingen en selectiemarkeringen zijn voorbeelden van geometrische rollen.
- Logische rollen: Titels, koppen en voetteksten zijn voorbeelden van logische rollen van teksten.
In de volgende afbeelding ziet u de typische onderdelen in een afbeelding van een voorbeeldpagina.

Ontwikkelingsopties
Document Intelligence v4.0 (2024-02-29-preview, 2023-10-31-preview) ondersteunt de volgende hulpprogramma's, toepassingen en bibliotheken:
| Functie | Resources | Model-id |
|---|---|---|
| Indelingsmodel | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
vooraf gedefinieerde indeling |
Document Intelligence v3.1 ondersteunt de volgende hulpprogramma's, toepassingen en bibliotheken:
| Functie | Resources | Model-id |
|---|---|---|
| Indelingsmodel | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
vooraf gedefinieerde indeling |
Document Intelligence v3.0 ondersteunt de volgende hulpprogramma's, toepassingen en bibliotheken:
| Functie | Resources | Model-id |
|---|---|---|
| Indelingsmodel | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
vooraf gedefinieerde indeling |
Document Intelligence v2.1 ondersteunt de volgende hulpprogramma's, toepassingen en bibliotheken:
| Functie | Resources |
|---|---|
| Indelingsmodel | • Hulpprogramma voor documentinformatielabels• REST API • Sdk voor clientbibliotheek• Document Intelligence Docker-container |
Vereisten voor invoer
Geef voor de beste resultaten één duidelijke foto of een hoogwaardige scan per document op.
Ondersteunde bestandsindelingen:
Model PDF Afbeelding:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) en HTMLRead ✔ ✔ ✔ Indeling ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Algemeen document ✔ ✔ Vooraf gebouwd ✔ ✔ Aangepaste extractie ✔ ✔ Aangepaste classificatie ✔ ✔ ✔ (2024-02-29-preview) Voor PDF en TIFF kunnen maximaal 2000 pagina's worden verwerkt (met een abonnement op de gratis laag worden alleen de eerste twee pagina's verwerkt).
De bestandsgrootte voor het analyseren van documenten is 500 MB voor betaalde (S0) laag en 4 MB gratis (F0).
De afmetingen van de afbeelding moeten tussen 50 x 50 pixels en 10.000 pixels x 10.000 pixels zijn.
Als uw PDF's zijn vergrendeld met een wachtwoord, moet u de vergrendeling verwijderen voordat u ze indient.
De minimale hoogte van de tekst die moet worden geëxtraheerd, is 12 pixels voor een afbeelding van 1024 x 768 pixels. Deze dimensie komt overeen met ongeveer
8-punttekst op 150 punten per inch (DPI).Voor aangepaste modeltraining is het maximum aantal pagina's voor trainingsgegevens 500 voor het aangepaste sjabloonmodel en 50.000 voor het aangepaste neurale model.
Voor het trainen van aangepaste extractiemodellen is de totale grootte van trainingsgegevens 50 MB voor het sjabloonmodel en 1G-MB voor het neurale model.
Voor het trainen van aangepast classificatiemodel is
1GBde totale grootte van trainingsgegevens maximaal 10.000 pagina's.
- Ondersteunde bestandsindelingen: JPEG, PNG, PDF en TIFF.
- Ondersteund aantal pagina's: voor PDF en TIFF worden maximaal 2000 pagina's verwerkt. Voor abonnees van de gratis laag worden alleen de eerste twee pagina's verwerkt.
- Ondersteunde bestandsgrootte: de bestandsgrootte moet kleiner zijn dan 50 MB en afmetingen ten minste 50 x 50 pixels en maximaal 10.000 x 10.000 pixels.
Aan de slag met het indelingsmodel
Bekijk hoe gegevens, waaronder tekst, tabellen, tabelkoppen, selectiemarkeringen en structuurgegevens worden geëxtraheerd uit documenten met behulp van Document Intelligence. U hebt de volgende resources nodig:
Een Azure-abonnement: u kunt er gratis een maken.
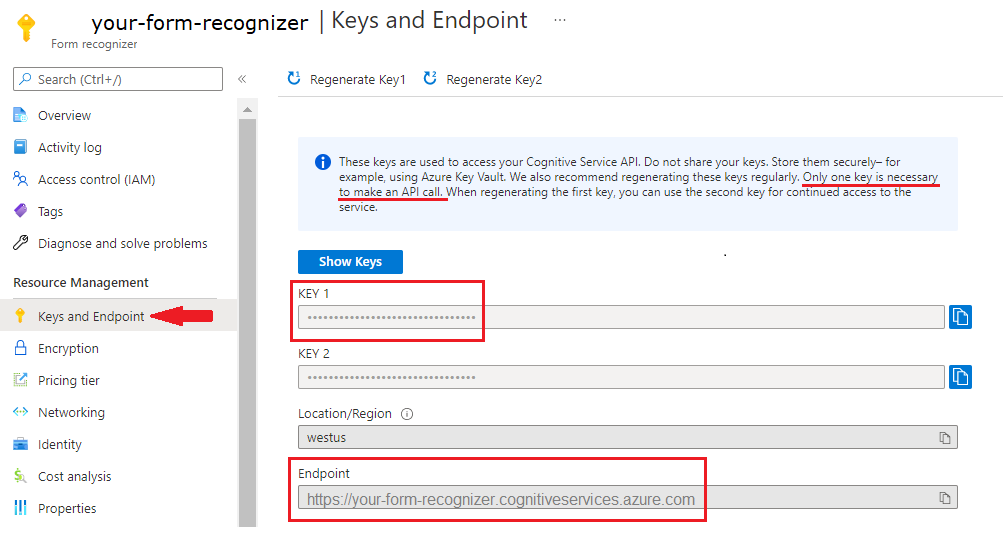
Een Document Intelligence-exemplaar in Azure Portal. U kunt de gratis prijscategorie (
F0) gebruiken om de service te proberen. Nadat uw resource is geïmplementeerd, selecteert u Ga naar de resource om uw sleutel en eindpunt op te halen.
Notitie
Document Intelligence Studio is beschikbaar met v3.0-API's en latere versies.
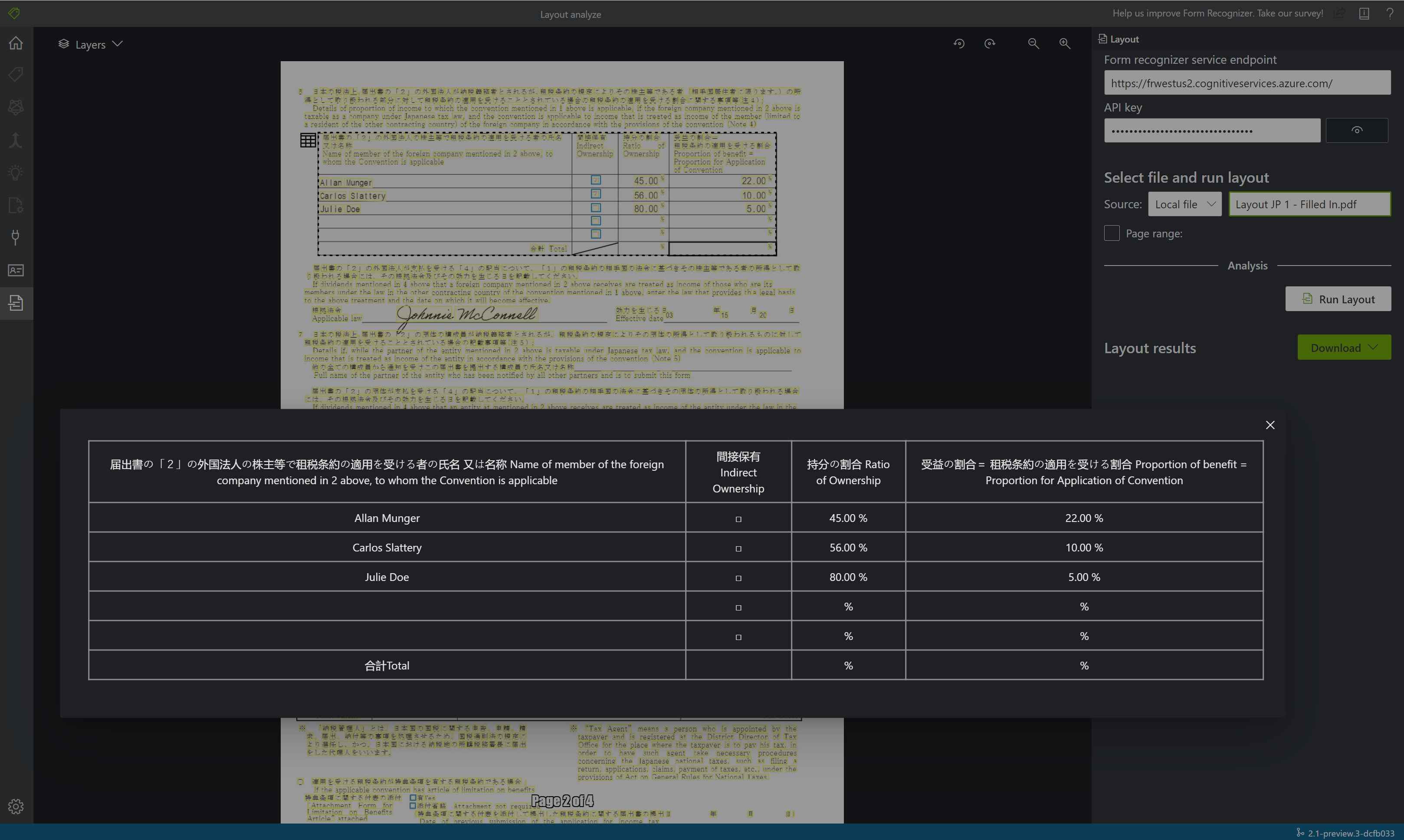
Voorbeelddocument verwerkt met Document Intelligence Studio
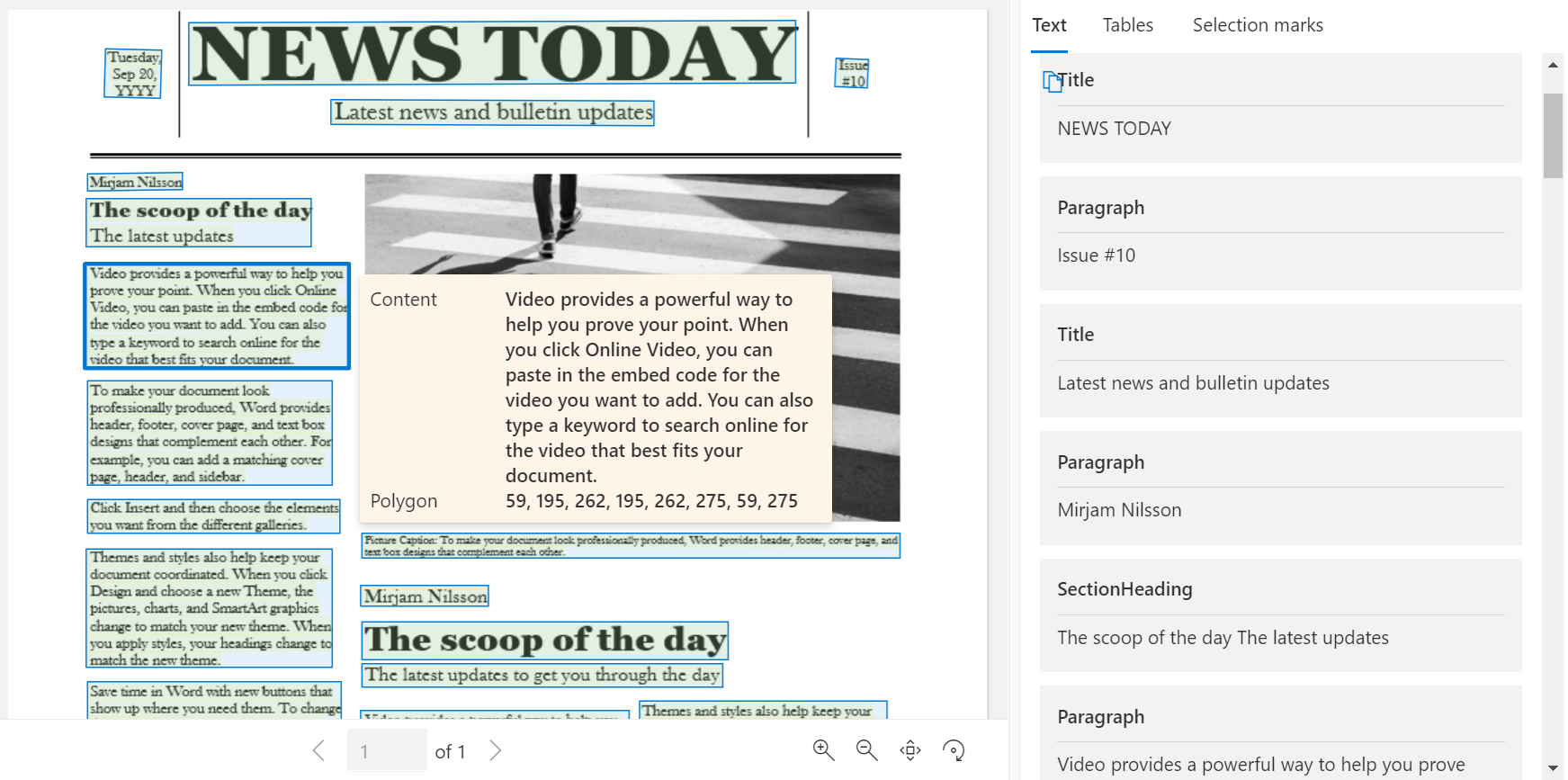
Selecteer Indeling op de startpagina van Document Intelligence Studio.
U kunt het voorbeelddocument analyseren of uw eigen bestanden uploaden.
Selecteer de knop Analyse uitvoeren en configureer indien nodig de opties analyseren:

Document Intelligence-voorbeeldhulpprogramma voor labelen
Navigeer naar het voorbeeldhulpprogramma Document Intelligence.
Selecteer Op de startpagina van het voorbeeldhulpprogramma de optie Indeling gebruiken om tekst, tabellen en selectiemarkeringen op te halen.
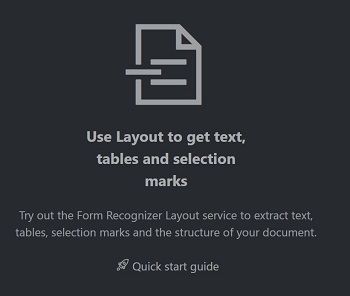
Plak in het veld Eindpunt van de Document Intelligence-service het eindpunt dat u hebt verkregen met uw Document Intelligence-abonnement.
Plak in het sleutelveld de sleutel die u hebt verkregen uit uw Document Intelligence-resource.
Selecteer in het veld Bron de URL in de vervolgkeuzelijst U kunt ons voorbeelddocument gebruiken:
Selecteer de knop Ophalen .
Selecteer Indeling uitvoeren. Met het hulpprogramma Document Intelligence-voorbeeldlabels wordt de
Analyze LayoutAPI aangeroepen om het document te analyseren.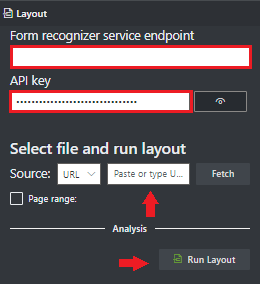
Bekijk de resultaten: bekijk de gemarkeerde geëxtraheerde tekst, gedetecteerde selectiemarkeringen en gedetecteerde tabellen.
{kind=link}
Ondersteunde talen en landinstellingen
Zie onze pagina Taalondersteuning: documentanalysemodellen voor een volledige lijst met ondersteunde talen.
Document Intelligence v2.1 ondersteunt de volgende hulpprogramma's, toepassingen en bibliotheken:
| Functie | Resources |
|---|---|
| Indelings-API |
Gegevensextractie
Met het indelingsmodel worden tekst, selectiemarkeringen, tabellen, alinea's en alineatypen (roles) uit uw documenten geëxtraheerd.
Notitie
Versies 2024-02-29-preview, 2023-10-31-previewen later ondersteunen Microsoft Office-bestanden (DOCX, XLSX, PPTX) en HTML-bestanden. De volgende functies worden niet ondersteund:
- Er zijn geen hoeken, breedte/hoogte en eenheid voor elk paginaobject.
- Voor elk gedetecteerd object is er geen begrenzings- of begrenzingsregio.
- Paginabereik (
pages) wordt niet ondersteund als parameter. - Geen
linesobject.
Pagina's
De verzameling pagina's is een lijst met pagina's in het document. Elke pagina wordt opeenvolgend in het document weergegeven en bevat de richtingshoek die aangeeft of de pagina wordt gedraaid en de breedte en hoogte (afmetingen in pixels). De pagina-eenheden in de modeluitvoer worden berekend zoals weergegeven:
| Bestandsindeling | Berekende pagina-eenheid | Totaal aantal pagina's |
|---|---|---|
| Afbeeldingen (JPEG/JPG, PNG, BMP, HEIF) | Elke afbeelding = 1 pagina-eenheid | Totaal aantal afbeeldingen |
| Elke pagina in de PDF = 1 pagina-eenheid | Totaal aantal pagina's in het PDF-bestand | |
| TIFF | Elke afbeelding in de TIFF = 1 pagina-eenheid | Totaal aantal afbeeldingen in de TIFF |
| Word (DOCX) | Maximaal 3000 tekens = 1 pagina-eenheid, ingesloten of gekoppelde afbeeldingen worden niet ondersteund | Totaal aantal pagina's van maximaal 3000 tekens per pagina |
| Excel (XLSX) | Elk werkblad = 1 pagina-eenheid, ingesloten of gekoppelde afbeeldingen wordt niet ondersteund | Totaal aantal werkbladen |
| PowerPoint (PPTX) | Elke dia = 1 pagina-eenheid, ingesloten of gekoppelde afbeeldingen wordt niet ondersteund | Totaal aantal dia's |
| HTML | Maximaal 3000 tekens = 1 pagina-eenheid, ingesloten of gekoppelde afbeeldingen worden niet ondersteund | Totaal aantal pagina's van maximaal 3000 tekens per pagina |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
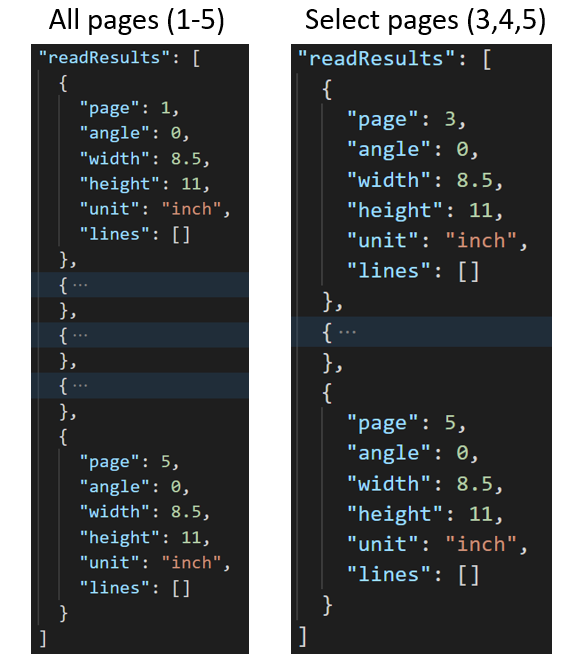
Geselecteerde pagina's uit documenten extraheren
Voor grote documenten met meerdere pagina's gebruikt u de pages queryparameter om specifieke paginanummers of paginabereiken aan te geven voor tekstextractie.
Leden
Met het indelingsmodel worden alle geïdentificeerde tekstblokken in de verzameling geëxtraheerd als een object op het paragraphs hoogste niveau onder analyzeResults. Elke vermelding in deze verzameling vertegenwoordigt een tekstblok en bevat de geëxtraheerde tekst alscontenten de begrenzingscoördinaten polygon . De span informatie verwijst naar het tekstfragment in de eigenschap op het hoogste niveau content die de volledige tekst uit het document bevat.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Alinearollen
Met de nieuwe op machine learning gebaseerde paginaobjectdetectie worden logische rollen geëxtraheerd, zoals titels, sectiekoppen, paginakopteksten, paginavoetteksten en meer. Met het Document Intelligence-indelingsmodel worden bepaalde tekstblokken in de paragraphs verzameling toegewezen met hun gespecialiseerde rol of type dat door het model wordt voorspeld. Ze worden het beste gebruikt met ongestructureerde documenten om inzicht te verkrijgen in de indeling van de geëxtraheerde inhoud voor een uitgebreidere semantische analyse. De volgende alinearollen worden ondersteund:
| Voorspelde rol | Beschrijving | Ondersteunde bestandstypen |
|---|---|---|
title |
De hoofdkoppen op de pagina | pdf, image, docx, pptx, xlsx, html |
sectionHeading |
Een of meer subkoppen op de pagina | pdf, image, docx, xlsx, html |
footnote |
Tekst onder aan de pagina | pdf, afbeelding |
pageHeader |
Tekst aan de bovenrand van de pagina | pdf, afbeelding, docx |
pageFooter |
Tekst aan de onderkant van de pagina | pdf, afbeelding, docx, pptx, html |
pageNumber |
Paginanummer | pdf, afbeelding |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Tekst, regels en woorden
Het documentindelingsmodel in Document Intelligence extraheert tekst in afdruk- en handgeschreven stijl als lines en words. De styles verzameling bevat een handgeschreven stijl voor lijnen als deze worden gedetecteerd, samen met de spanten die verwijzen naar de bijbehorende tekst. Deze functie is van toepassing op ondersteunde handgeschreven talen.
Voor Microsoft Word, Excel, PowerPoint en HTML halen documentinformatieversies 2024-02-29-preview en 2023-10-31-preview-indelingsmodel alle ingesloten tekst op. Teksten worden geëxtraheerd als woorden en alinea's. Ingesloten afbeeldingen worden niet ondersteund.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
Handgeschreven stijl voor tekstregels
Het antwoord omvat het classificeren of elke tekstregel een handschriftstijl heeft of niet, samen met een betrouwbaarheidsscore. Voor meer informatie. Zie handgeschreven taalondersteuning. In het volgende voorbeeld ziet u een voorbeeld van een JSON-fragment.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Als u de mogelijkheid voor de invoegtoepassing lettertype/stijl inschakelt, krijgt u ook het resultaat lettertype/stijl als onderdeel van het styles object.
Selectiemarkeringen
Met het indelingsmodel worden ook selectiemarkeringen uit documenten geëxtraheerd. Geëxtraheerde selectiemarkeringen worden weergegeven in de pages verzameling voor elke pagina. Ze bevatten de begrenzing polygon, confidenceen selectie state (selected/unselected). De tekstweergave (dat wil gezegd :selected: en :unselected) wordt ook opgenomen als de beginindex (offset) en length die verwijst naar de eigenschap op het hoogste niveau content die de volledige tekst uit het document bevat.
{
"selectionMarks": [
{
"state": "unselected",
"polygon": [],
"confidence": 0.995,
"span": {
"offset": 1421,
"length": 12
}
}
]
}
Tabellen
Het extraheren van tabellen is een belangrijke vereiste voor het verwerken van documenten met grote hoeveelheden gegevens die doorgaans zijn opgemaakt als tabellen. Het indelingsmodel extraheert tabellen in de pageResults sectie van de JSON-uitvoer. Geëxtraheerde tabelgegevens bevatten het aantal kolommen en rijen, rijspanne en kolomspanne. Elke cel met de begrenzingsveelhoek wordt samen met informatie weergegeven, ongeacht of het gebied wordt herkend als een columnHeader of niet. Het model ondersteunt het extraheren van tabellen die worden gedraaid. Elke tabelcel bevat de rij- en kolomindex en begrenzingspogoncoördinaten. Voor de celtekst voert het model de informatie uit die de span beginindex (offset) bevat. Het model voert ook de length inhoud op het hoogste niveau uit die de volledige tekst uit het document bevat.
Notitie
Tabel wordt niet ondersteund als het invoerbestand XLSX is.
{
"tables": [
{
"rowCount": 9,
"columnCount": 4,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"columnSpan": 4,
"content": "(In millions, except earnings per share)",
"boundingRegions": [],
"spans": []
},
]
}
]
}
Aantekeningen (alleen beschikbaar in 2023-02-28-preview API.)
Het indelingsmodel extraheert aantekeningen in documenten, zoals controles en kruisingen. Het antwoord bevat het soort aantekening, samen met een betrouwbaarheidsscore en begrenzingsveelhoek.
{
"pages": [
{
"annotations": [
{
"kind": "cross",
"polygon": [...],
"confidence": 1
}
]
}
]
}
Uitvoer naar markdown-indeling
De Indelings-API kan de geëxtraheerde tekst uitvoeren in markdown-indeling. Gebruik de outputContentFormat=markdown opdracht om de uitvoerindeling in Markdown op te geven. De markdown-inhoud wordt uitgevoerd als onderdeel van de content sectie.
"analyzeResult": {
"apiVersion": "2024-02-29-preview",
"modelId": "prebuilt-layout",
"contentFormat": "markdown",
"content": "# CONTOSO LTD...",
}
Cijfers
Afbeeldingen (grafieken, afbeeldingen) in documenten spelen een cruciale rol bij het aanvullen en verbeteren van de tekstuele inhoud, waardoor visuele weergaven worden geboden die helpen bij het begrijpen van complexe informatie. Het afbeeldingsobject dat door het indelingsmodel wordt gedetecteerd, heeft belangrijke eigenschappen, zoals boundingRegions (de ruimtelijke locaties van de afbeelding op de documentpagina's, inclusief het paginanummer en de veelhoekcoördinaten die de grens van de afbeelding aangeven), spans (details van de tekst die betrekking heeft op de afbeelding, waarbij de offsets en lengten binnen de tekst van het document worden opgegeven. Deze verbinding helpt bij het koppelen van de afbeelding aan de relevante tekstcontext( elements de id's voor tekstelementen of alinea's in het document die gerelateerd zijn aan of beschrijven de afbeelding) en caption of er een is.
{
"figures": [
{
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15",
...
],
"caption": {
"content": "Here is a figure with some text",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15"
]
}
}
]
}
Secties
Hiërarchische documentstructuuranalyse is cruciaal bij het organiseren, begrijpen en verwerken van uitgebreide documenten. Deze aanpak is essentieel voor het semantisch segmenteren van lange documenten om het begrip te verbeteren, navigatie te vergemakkelijken en het ophalen van informatie te verbeteren. De komst van Het ophalen van Augmented Generation (RAG) in documentgeneratieve AI onderstreept de betekenis van hiërarchische documentstructuuranalyse. Het indelingsmodel ondersteunt secties en subsecties in de uitvoer, waarmee de relatie tussen secties en objecten in elke sectie wordt geïdentificeerd. De hiërarchische structuur wordt in elements elke sectie onderhouden. U kunt uitvoer gebruiken om de Markdown-indeling te gebruiken om eenvoudig de secties en subsecties in Markdown op te halen.
{
"sections": [
{
"spans": [],
"elements": [
"/paragraphs/0",
"/sections/1",
"/sections/2",
"/sections/5"
]
},
...
}
Uitvoer van natuurlijke leesvolgorde (alleen Latijns)
U kunt de volgorde opgeven waarin de tekstregels worden uitgevoerd met de readingOrder queryparameter. Gebruik natural deze functie voor een meer mensvriendelijke uitvoer van leesvolgorde, zoals wordt weergegeven in het volgende voorbeeld. Deze functie wordt alleen ondersteund voor Latijnse talen.

Paginanummers of bereiken selecteren voor tekstextractie
Voor grote documenten met meerdere pagina's gebruikt u de pages queryparameter om specifieke paginanummers of paginabereiken aan te geven voor tekstextractie. In het volgende voorbeeld ziet u een document met 10 pagina's, met tekst die voor beide gevallen is geëxtraheerd: alle pagina's (1-10) en geselecteerde pagina's (3-6).
De bewerking Resultaat van indeling Ophalen analyseren
De tweede stap is het aanroepen van de bewerking Get Analyze Layout Result . Deze bewerking wordt gebruikt als invoer van de resultaat-id die de Analyze Layout bewerking heeft gemaakt. Het retourneert een JSON-antwoord dat een statusveld bevat met de volgende mogelijke waarden.
| Veld | Type | Mogelijke waarden |
|---|---|---|
| status | tekenreeks | notStarted: De analysebewerking is niet gestart.running: De analysebewerking wordt uitgevoerd.failed: de analysebewerking is mislukt.succeeded: de analysebewerking is voltooid. |
Roep deze bewerking iteratief aan totdat deze de succeeded waarde retourneert. Gebruik een interval van 3 tot 5 seconden om te voorkomen dat de aanvragen per seconde (RPS) worden overschreden.
Wanneer het statusveld de succeeded waarde heeft, bevat het JSON-antwoord de geëxtraheerde indeling, tekst, tabellen en selectiemarkeringen. De geëxtraheerde gegevens omvatten geëxtraheerde tekstregels en woorden, begrenzingsvakken, tekstweergave met handgeschreven indicaties, tabellen en selectiemarkeringen met geselecteerde/niet-geselecteerde aangegeven markeringen.
Handgeschreven classificatie voor tekstregels (alleen Latijns)
Het antwoord omvat het classificeren of elke tekstregel een handschriftstijl heeft of niet, samen met een betrouwbaarheidsscore. Deze functie wordt alleen ondersteund voor Latijnse talen. In het volgende voorbeeld ziet u de handgeschreven classificatie voor de tekst in de afbeelding.

Voorbeeld van JSON-uitvoer
Het antwoord op de bewerking Resultaat van indeling Ophalen analyseren is een gestructureerde weergave van het document met alle geëxtraheerde informatie. Zie hier voor een voorbeelddocumentbestand en de uitvoer van de indeling met gestructureerde uitvoervoorbeelden.
De JSON-uitvoer bestaat uit twee delen:
readResultshet knooppunt bevat alle herkende tekst en selectiemarkering. De hiërarchie van de tekstpresentatie is pagina, vervolgens regel en vervolgens afzonderlijke woorden.pageResultshet knooppunt bevat de tabellen en cellen die zijn geëxtraheerd met hun begrenzingsvakken, betrouwbaarheid en een verwijzing naar de regels en woorden in het veld readResults.
Voorbeelduitvoer
Sms verzenden
Met de Indelings-API wordt tekst geëxtraheerd uit documenten en afbeeldingen met meerdere teksthoeken en kleuren. Het accepteert foto's van documenten, faxen, afgedrukte en/of handgeschreven (alleen Engelstalige) tekst en gemengde modi. Tekst wordt geëxtraheerd met informatie over regels, woorden, begrenzingsvakken, betrouwbaarheidsscores en stijl (handgeschreven of andere). Alle tekstinformatie wordt opgenomen in de readResults sectie van de JSON-uitvoer.
Tabellen met kopteksten
Indelings-API extraheert tabellen in de pageResults sectie van de JSON-uitvoer. Documenten kunnen worden gescand, gefotografeerd of gedigitaliseerd. Tabellen kunnen complex zijn met samengevoegde cellen of kolommen, met of zonder randen, en met oneven hoeken. Geëxtraheerde tabelgegevens bevatten het aantal kolommen en rijen, rijspanne en kolomspanne. Elke cel met het begrenzingsvak wordt uitgevoerd, samen met of het gebied wordt herkend als onderdeel van een koptekst of niet. Het voorspelde koptekstcellen van het model kunnen meerdere rijen omvatten en zijn niet noodzakelijkerwijs de eerste rijen in een tabel. Ze werken ook met gedraaide tabellen. Elke tabelcel bevat ook de volledige tekst met verwijzingen naar de afzonderlijke woorden in de readResults sectie.
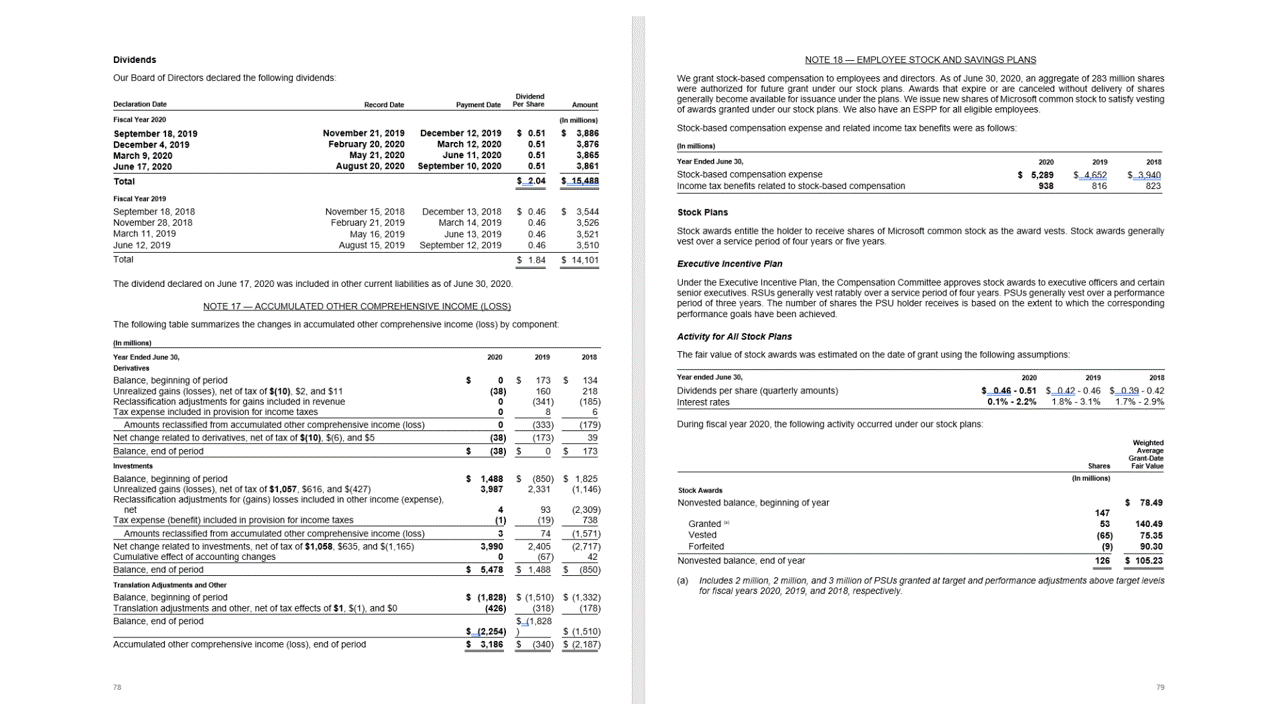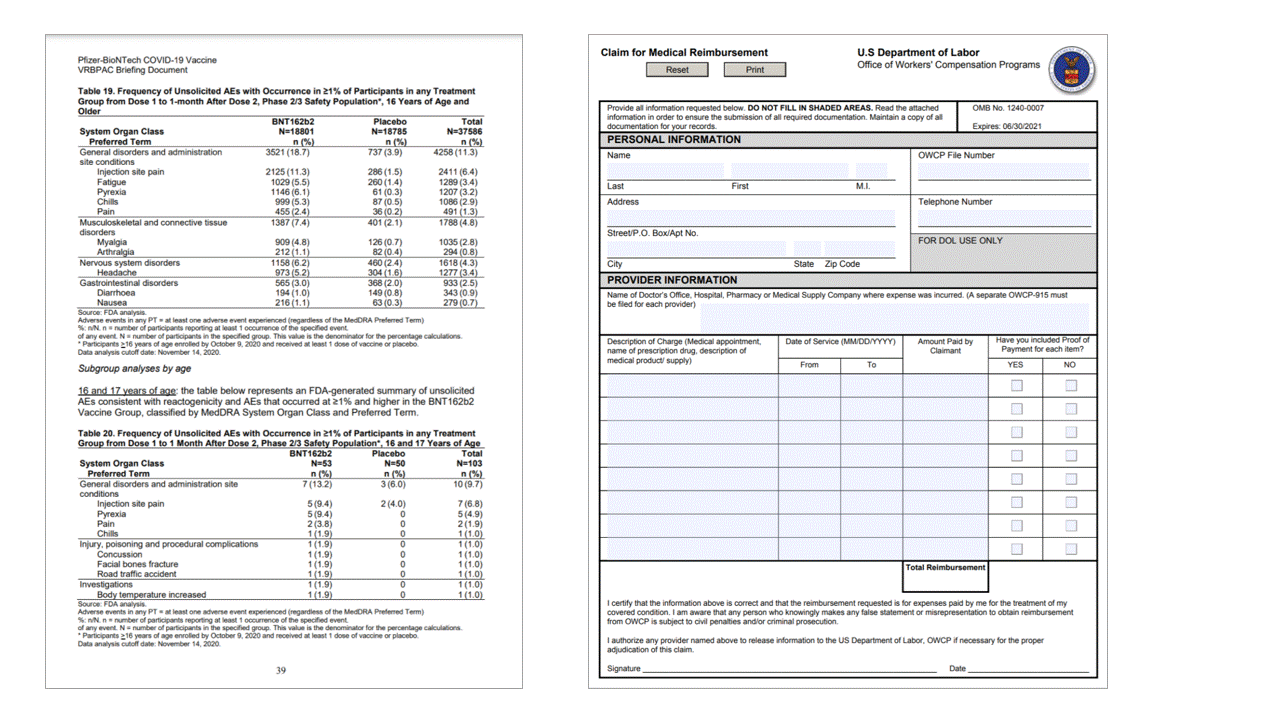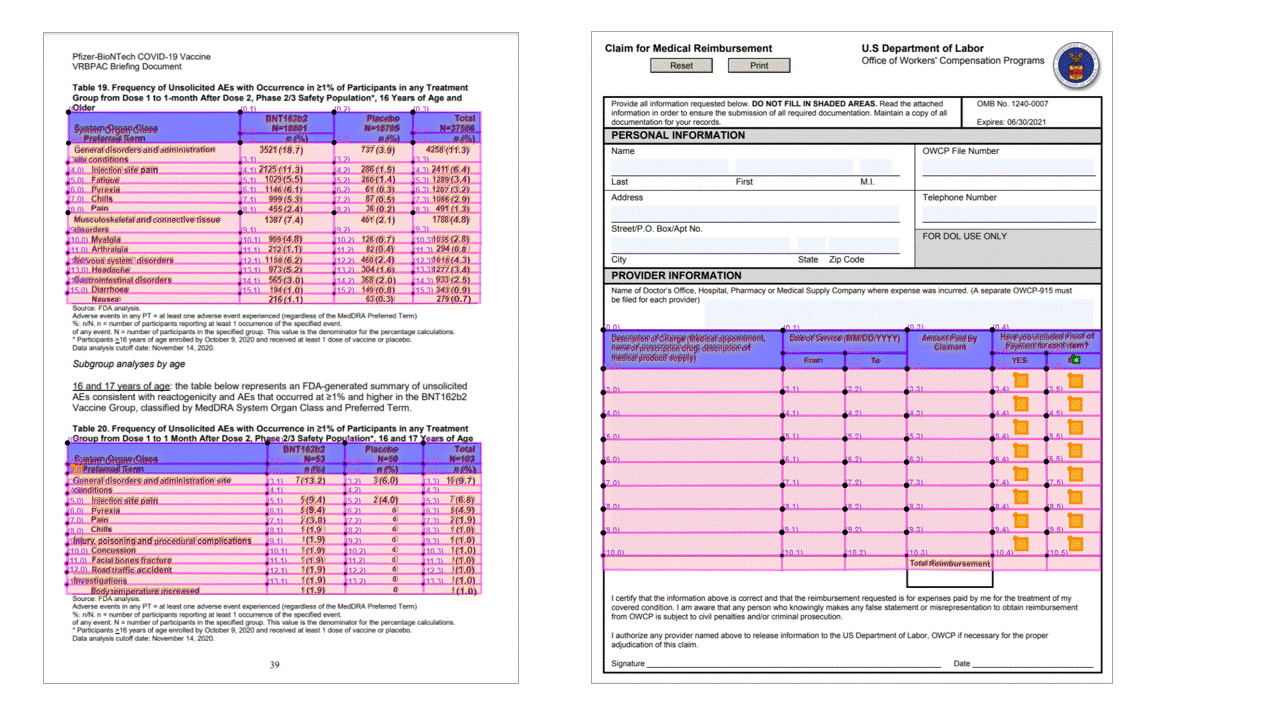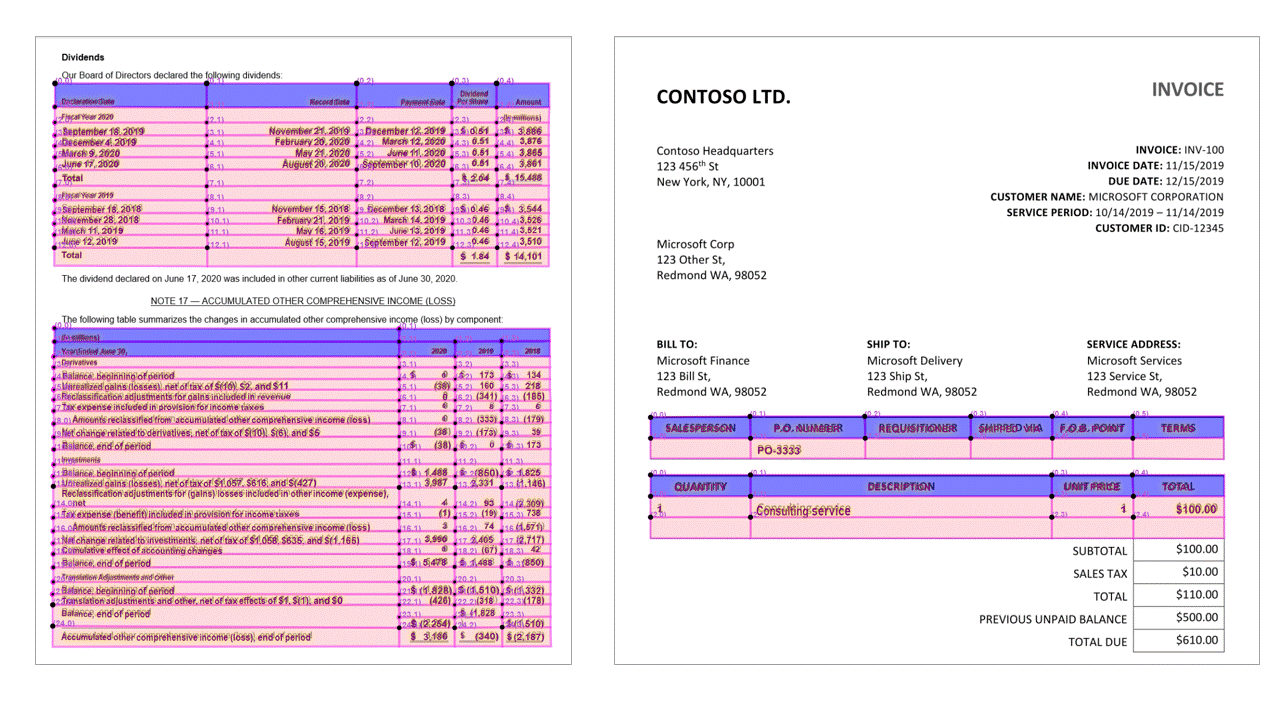
Selectiemarkeringen
Met de Indelings-API worden ook selectiemarkeringen uit documenten geëxtraheerd. Uitgepakte selectiemarkeringen bevatten het begrenzingsvak, betrouwbaarheid en status (geselecteerd/uitgeschakeld). Informatie over selectiemarkeringen wordt geëxtraheerd in de readResults sectie van de JSON-uitvoer.
Migratiehandleiding
- Volg onze migratiehandleiding voor Document Intelligence v3.1 voor meer informatie over het gebruik van de versie v3.1 in uw toepassingen en werkstromen.
Volgende stappen
Meer informatie over het verwerken van uw eigen formulieren en documenten met Document Intelligence Studio.
Voltooi een quickstart voor Document Intelligence en ga aan de slag met het maken van een app voor documentverwerking in de ontwikkeltaal van uw keuze.
Meer informatie over het verwerken van uw eigen formulieren en documenten met het hulpprogramma Document Intelligence-voorbeeldlabels.
Voltooi een quickstart voor Document Intelligence en ga aan de slag met het maken van een app voor documentverwerking in de ontwikkeltaal van uw keuze.