Documentverwerkingsmodellen
Belangrijk
- Openbare preview-versies van Document Intelligence bieden vroegtijdige toegang tot functies die actief zijn in ontwikkeling.
- Functies, benaderingen en processen kunnen veranderen, vóór algemene beschikbaarheid (GA), op basis van feedback van gebruikers.
- De openbare preview-versie van Document Intelligence-clientbibliotheken is standaard ingesteld op REST API-versie 2024-02-29-preview.
- Openbare preview-versie 2024-02-29-preview is momenteel alleen beschikbaar in de volgende Azure-regio's:
- VS - oost
- VS - west 2
- Europa -west
Deze inhoud is van toepassing op:![]() v4.0 (preview) | Vorige versies:
v4.0 (preview) | Vorige versies:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Deze inhoud is van toepassing op:![]() v3.1 (GA) | Nieuwste versie:
v3.1 (GA) | Nieuwste versie:![]() v4.0 (preview) | Vorige versies:
v4.0 (preview) | Vorige versies:![]() v3.0
v3.0![]() v2.1
v2.1
Deze inhoud is van toepassing op:![]() v3.0 (GA) | Nieuwste versies:
v3.0 (GA) | Nieuwste versies:![]() v4.0 (preview)
v4.0 (preview)![]() v3.1 | Vorige versie:
v3.1 | Vorige versie:![]() v2.1
v2.1
Deze inhoud is van toepassing op:![]() v2.1 | Nieuwste versie:
v2.1 | Nieuwste versie:![]() v4.0 (preview)
v4.0 (preview)
Azure AI Document Intelligence ondersteunt een groot aantal modellen waarmee u intelligente documentverwerking kunt toevoegen aan uw apps en stromen. U kunt een vooraf samengesteld domeinspecifiek model gebruiken of een aangepast model trainen dat is afgestemd op uw specifieke bedrijfsbehoefte en gebruiksvoorbeelden. Document Intelligence kan worden gebruikt met de REST API of Python-, C#-, Java- en JavaScript-clientbibliotheken.
Overzicht van modellen
In de volgende tabel ziet u de beschikbare modellen voor elke huidige preview en stabiele API:
| Modeltype | Model | • 2024-02-29-preview & opsommingsteken 2023-10-31-preview |
2023-07-31 (GA) | 2022-08-31 (GA) | v2.1 (GA) |
|---|---|---|---|---|---|
| Modellen voor documentanalyse | Lezen | ✔️ | ✔️ | ✔️ | N.v.t. |
| Modellen voor documentanalyse | Indeling | ✔️ | ✔️ | ✔️ | ✔️ |
| Modellen voor documentanalyse | Algemeen document | verplaatst naar indeling** | ✔️ | ✔️ | N.v.t. |
| Vooraf samengestelde modellen | Contract | ✔️ | ✔️ | N.v.t. | N.v.t. |
| Vooraf samengestelde modellen | Ziekteverzekeringskaart | ✔️ | ✔️ | ✔️ | N.v.t. |
| Vooraf samengestelde modellen | Id-document | ✔️ | ✔️ | ✔️ | ✔️ |
| Vooraf samengestelde modellen | Factuur | ✔️ | ✔️ | ✔️ | ✔️ |
| Vooraf samengestelde modellen | Ontvangst | ✔️ | ✔️ | ✔️ | ✔️ |
| Vooraf samengestelde modellen | US 1040 Tax* | ✔️ | ✔️ | N.v.t. | N.v.t. |
| Vooraf samengestelde modellen | US 1098 Tax* | ✔️ | N.v.t. | n.v.t. | N.v.t. |
| Vooraf samengestelde modellen | US 1099 Tax* | ✔️ | N.v.t. | n.v.t. | N.v.t. |
| Vooraf samengestelde modellen | Amerikaanse W2-belasting | ✔️ | ✔️ | ✔️ | N.v.t. |
| Vooraf samengestelde modellen | US Mortgage 1003 URLA | ✔️ | N.v.t. | n.v.t. | N.v.t. |
| Vooraf samengestelde modellen | US Mortgage 1008 Summary | ✔️ | N.v.t. | n.v.t. | N.v.t. |
| Vooraf samengestelde modellen | Openbaarmaking van de sluiting van de Amerikaanse hypotheek | ✔️ | N.v.t. | n.v.t. | N.v.t. |
| Vooraf samengestelde modellen | Huwelijksakte | ✔️ | N.v.t. | n.v.t. | N.v.t. |
| Vooraf samengestelde modellen | Creditcard | ✔️ | N.v.t. | n.v.t. | N.v.t. |
| Vooraf samengestelde modellen | Visitekaartje | deprecated | ✔️ | ✔️ | ✔️ |
| Aangepast classificatiemodel | Aangepaste classificatie | ✔️ | ✔️ | N.v.t. | N.v.t. |
| Aangepast extractiemodel | Aangepaste neurale | ✔️ | ✔️ | ✔️ | N.v.t. |
| Aangepastextractiemodel | Aangepaste sjabloon | ✔️ | ✔️ | ✔️ | ✔️ |
| Aangepast extractiemodel | Aangepast samengesteld | ✔️ | ✔️ | ✔️ | ✔️ |
| Alle modellen | Mogelijkheden voor invoegtoepassingen | ✔️ | ✔️ | N.v.t. | N.v.t. |
* - Bevat submodellen. Bekijk de modelspecifieke informatie voor ondersteunde variaties en subtypen.
| Mogelijkheid voor invoegtoepassingen | Invoegtoepassing/gratis | • 2024-02-29-preview &opsommingsteken [2023-10-31-preview](/rest/api/aiservices/operation-groups?view=rest-aiservices-2024-02-29-preview&preserve-view=true |
2023-07-31 (GA) |
2022-08-31 (GA) |
v2.1 (GA) |
|---|---|---|---|---|---|
| Extractie van lettertype-eigenschap | Add-on | ✔️ | ✔️ | N.v.t. | N.v.t. |
| Formuleextractie | Add-on | ✔️ | ✔️ | N.v.t. | N.v.t. |
| Extractie met hoge resolutie | Add-on | ✔️ | ✔️ | N.v.t. | N.v.t. |
| Streepjescode-extractie | Gratis | ✔️ | ✔️ | N.v.t. | N.v.t. |
| Taaldetectie | Gratis | ✔️ | ✔️ | N.v.t. | N.v.t. |
| Sleutel-waardeparen | Gratis | ✔️ | N.v.t. | n.v.t. | N.v.t. |
| Queryvelden | Add-on* | ✔️ | N.v.t. | n.v.t. | N.v.t. |
Modelanalysefuncties
| Model-id | Inhoudsextractie | Queryvelden | Leden | Alinearollen | Selectiemarkeringen | Tabellen | Sleutel-waardeparen | Talen | Barcodes | Documentanalyse | Formules* | Lettertype voor stijl* | Hoge resolutie* |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| vooraf gedefinieerde leesbewerking | ✓ | O | O | O | O | O | |||||||
| vooraf gedefinieerde indeling | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | ||
| vooraf samengesteld document | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | |
| vooraf samengestelde businessCard | ✓ | ✓ | ✓ | ||||||||||
| vooraf samengesteld contract | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||
| prebuilt-healthInsuranceCard.us | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| vooraf samengesteld-idDocument | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| vooraf samengestelde factuur | ✓ | ✓ | ✓ | ✓ | O | O | O | ✓ | O | O | O | ||
| vooraf samengestelde ontvangstbevestiging | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-marriageCertificate.us | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| vooraf gedefinieerde creditCard | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| vooraf samengestelde hypotheek.us.1003 | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| vooraf samengestelde hypotheek.us.1008 | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| vooraf samengestelde hypotheek.us.closingDisclosure | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.w2 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1098 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1098E | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1098T | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1099(variaties) | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1040(variaties) | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| { customModelName } | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O |
✓ - IngeschakeldE
O - Optioneel
* - Premium-functies kosten
Invoegtoepassing* - Queryvelden zijn anders geprijsd dan de andere invoegtoepassingsfuncties. Zie prijzen voor meer informatie.
| Model | Beschrijving |
|---|---|
| Modellen voor documentanalyse | |
| OCR lezen | Extraheer afdruk- en handgeschreven tekst, inclusief woorden, locaties en gedetecteerde talen. |
| Indelingsanalyse | Extraheer tekst- en documentindelingselementen zoals tabellen, selectiemarkeringen, titels, sectiekoppen en meer. |
| Vooraf gemaakte modellen | |
| Ziekteverzekeringskaart | Automatiseer gezondheidszorgprocessen door verzekeraar, lid, recept, groepsnummer en andere belangrijke informatie uit amerikaanse zorgverzekeringskaarten te extraheren. |
| Amerikaanse belastingdocumentmodellen | Amerikaanse belastingformulieren verwerken om werknemers, werkgever, loon en andere informatie te extraheren. |
| Documentmodellen voor Amerikaanse hypotheek | Verwerk Amerikaanse hypotheekformulieren voor het extraheren van lening- en eigenschapsgegevens van de kredietnemer. |
| Contract | Overeenkomst- en partijgegevens extraheren. |
| Factuur | Automatiseer facturen. |
| Ontvangst | Ontvangstgegevens extraheren uit ontvangstbevestigingen. |
| Identiteitsdocument (id) | Identiteitsvelden (ID) extraheren uit amerikaanse rijbewijs's en internationale paspoorten. |
| Visitekaartje | Scan visitekaartjes om belangrijke velden en gegevens in uw toepassingen te extraheren. |
| Aangepaste modellen | |
| Aangepast model (overzicht) | Gegevens extraheren uit formulieren en documenten die specifiek zijn voor uw bedrijf. Aangepaste modellen worden getraind voor uw afzonderlijke gegevens en gebruiksvoorbeelden. |
| Aangepaste extractiemodellen | ● Aangepaste sjabloonmodellen maken gebruik van lay-out cues om waarden uit documenten te extraheren en zijn geschikt voor het extraheren van velden uit zeer gestructureerde documenten met gedefinieerde visuele sjablonen. ● Aangepaste neurale modellen worden getraind op verschillende documenttypen om velden te extraheren uit gestructureerde, semi-gestructureerde en ongestructureerde documenten. |
| Aangepast classificatiemodel | Het aangepaste classificatiemodel kan elke pagina in een invoerbestand classificeren om de documenten binnen te identificeren en kan ook meerdere documenten of meerdere exemplaren van één document in een invoerbestand identificeren. |
| Samengestelde modellen | Combineer verschillende aangepaste modellen tot één model om de verwerking van diverse documenttypen te automatiseren met één samengesteld model. |
Voor alle modellen, met uitzondering van het visitekaartjesmodel, biedt Document Intelligence nu ondersteuning voor invoegtoepassingsmogelijkheden om geavanceerdere analyses mogelijk te maken. Deze optionele mogelijkheden kunnen worden ingeschakeld en uitgeschakeld, afhankelijk van het scenario van de documentextractie. Er zijn zeven mogelijkheden voor invoegtoepassingen beschikbaar voor de 2023-07-31 (GA) en latere API-versie:
ocrHighResolutionformulasstyleFontbarcodeslanguageskeyValuePairs(2024-02-29-preview, 2023-10-31-preview)queryFields(2024-02-29-preview, 2023-10-31-preview)Not available with the US.Tax models
Modelgegevens
In deze sectie wordt de uitvoer beschreven die u van elk model kunt verwachten. Houd er rekening mee dat u de uitvoer van de meeste modellen kunt uitbreiden met invoegtoepassingsfuncties.
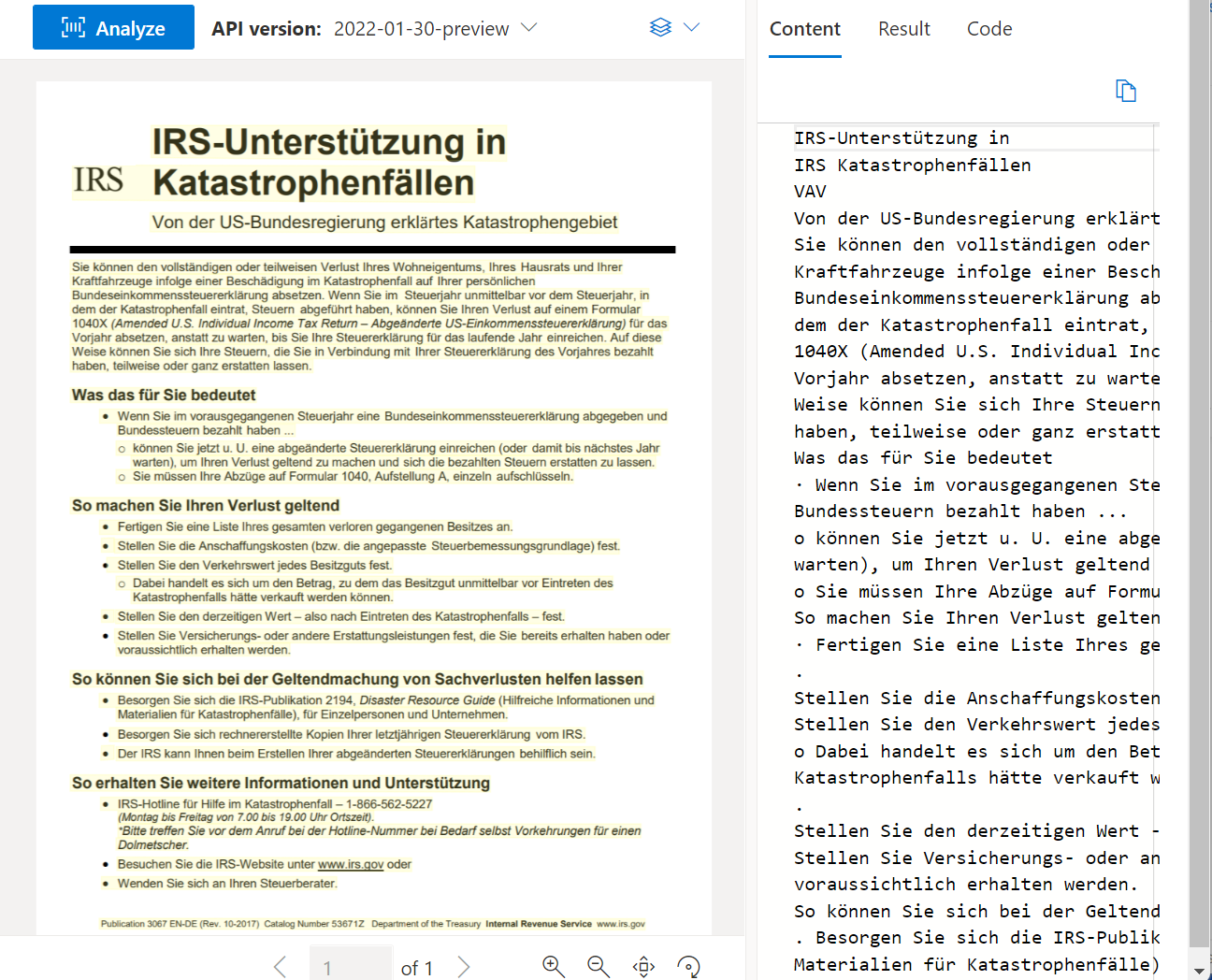
OCR lezen

Met de Read-API worden regels, woorden, hun locaties, gedetecteerde talen en handgeschreven stijl geanalyseerd en geëxtraheerd, indien gedetecteerd.
Voorbeelddocument dat is verwerkt met behulp van Document Intelligence Studio:
Indelingsanalyse

Het model indelingsanalyse analyseert en extraheert tekst, tabellen, selectiemarkeringen en andere structuurelementen, zoals titels, sectiekoppen, paginakoppen, paginavoetteksten en meer.
Voorbeelddocument dat is verwerkt met behulp van Document Intelligence Studio:
Ziekteverzekeringskaart
![]()
Het model van de gezondheidsverzekeringskaart combineert krachtige OCR-mogelijkheden (Optical Character Recognition) met deep learning-modellen om belangrijke informatie uit amerikaanse gezondheidsverzekeringskaarten te analyseren en te extraheren.
Voorbeeld van een amerikaanse gezondheidsverzekeringskaart die is verwerkt met Document Intelligence Studio:

Amerikaanse belastingdocumenten

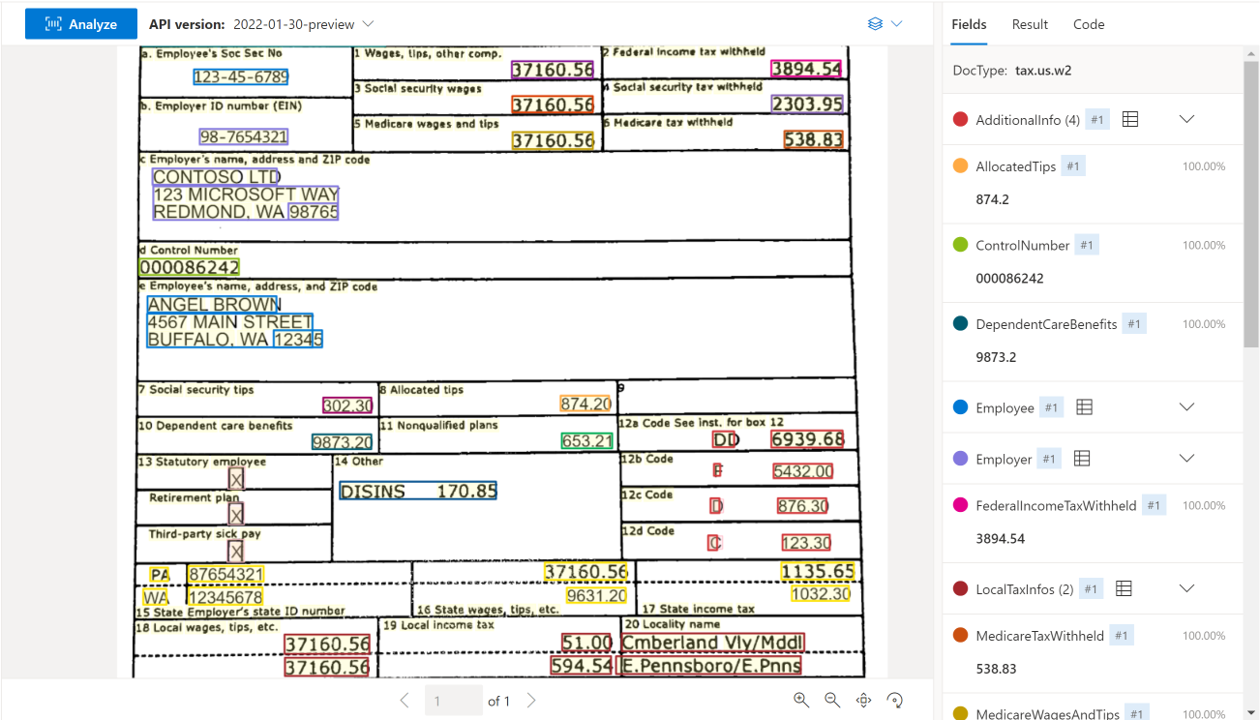
De Amerikaanse belastingdocumentmodellen analyseren en extraheren belangrijke velden en regelitems uit een selecte groep belastingdocumenten. De API ondersteunt de analyse van Amerikaanse belastingdocumenten in de Engelse taal van verschillende indelingen en kwaliteit, waaronder door de telefoon vastgelegde afbeeldingen, gescande documenten en digitale PDF-bestanden. De volgende modellen worden momenteel ondersteund:
| Model | Beschrijving | Model-id |
|---|---|---|
| Amerikaanse belasting W-2 | Belastingplichtige compensatiegegevens extraheren. | prebuilt-tax.us.W-2 |
| Amerikaanse belasting 1040 | Extraheer hypotheekrentegegevens. | prebuilt-tax.us.1040(variaties) |
| Amerikaanse belasting 1098 | Extraheer hypotheekrentegegevens. | prebuilt-tax.us.1098(variaties) |
| Amerikaanse belasting 1099 | Extraheer inkomsten ontvangen uit andere bronnen dan werkgever. | prebuilt-tax.us.1099(variaties) |
Voorbeeld van een W-2-document dat is verwerkt met Document Intelligence Studio:
Amerikaanse hypotheekdocumenten

In de Amerikaanse hypotheekdocumentmodellen worden belangrijke velden geanalyseerd en geëxtraheerd, waaronder gegevens van de kredietnemer, lening en eigenschap uit een selecte groep hypotheekdocumenten. De API ondersteunt de analyse van Amerikaanse hypotheekdocumenten in de Engelse taal van verschillende indelingen en kwaliteit, waaronder door de telefoon vastgelegde afbeeldingen, gescande documenten en digitale PDF-bestanden. De volgende modellen worden momenteel ondersteund:
| Model | Beschrijving | Model-id |
|---|---|---|
| 1003 Gebruiksrechtovereenkomst (EULA) | Extraheer lening, kredietnemer, eigenschapsgegevens. | vooraf samengestelde hypotheek.us.1003 |
| 1008 Samenvattingsdocument | Extraheren van kredietnemer, verkoper, onroerend goed, hypotheek- en onderschrijfgegevens. | vooraf samengestelde hypotheek.us.1008 |
| Openbaarmaking sluiten | Extraheren sluiten, transactiekosten en leningsgegevens. | vooraf samengestelde hypotheek.us.closingDisclosure |
| Huwelijksakte | Gegevens over huwelijk extraheren voor gemeenschappelijke aanvragers van leningen. | prebuilt-marriageCertificate |
| Amerikaanse belasting W-2 | Extraheer belastingcompensatiegegevens voor inkomstenverificatie. | prebuilt-tax.us.W-2 |
Voorbeeld van openbaarmakingsdocument sluiten dat is verwerkt met Behulp van Document Intelligence Studio:

Contract
![]()
Het contractmodel analyseert en extraheert belangrijke velden en regelitems uit contractuele overeenkomsten, waaronder partijen, jurisdicties, contract-id en titel. Het model ondersteunt momenteel engelse contractdocumenten.
Voorbeeldcontract verwerkt met Document Intelligence Studio:

Factuur

Het factuurmodel automatiseert de verwerking van facturen om de klantnaam, het factuuradres, de einddatum en het verschuldigde bedrag, regelitems en andere sleutelgegevens te extraheren. Op dit moment ondersteunt het model facturen Engels, Spaans, Duits, Frans, Italiaans, Portugees en Nederlands.
Voorbeeldfactuur verwerkt met Document Intelligence Studio:

Ontvangstbewijs

Gebruik het ontvangstbewijsmodel om verkoopbevestigingen te scannen op verkoopbewijzen voor verkoopnaam, datums, regelitems, hoeveelheden en totalen van afgedrukte en handgeschreven ontvangstbewijzen. De versie v3.0 ondersteunt ook verwerking van hotelbevestigingen met één pagina.
Voorbeeldbevestiging verwerkt met Document Intelligence Studio:

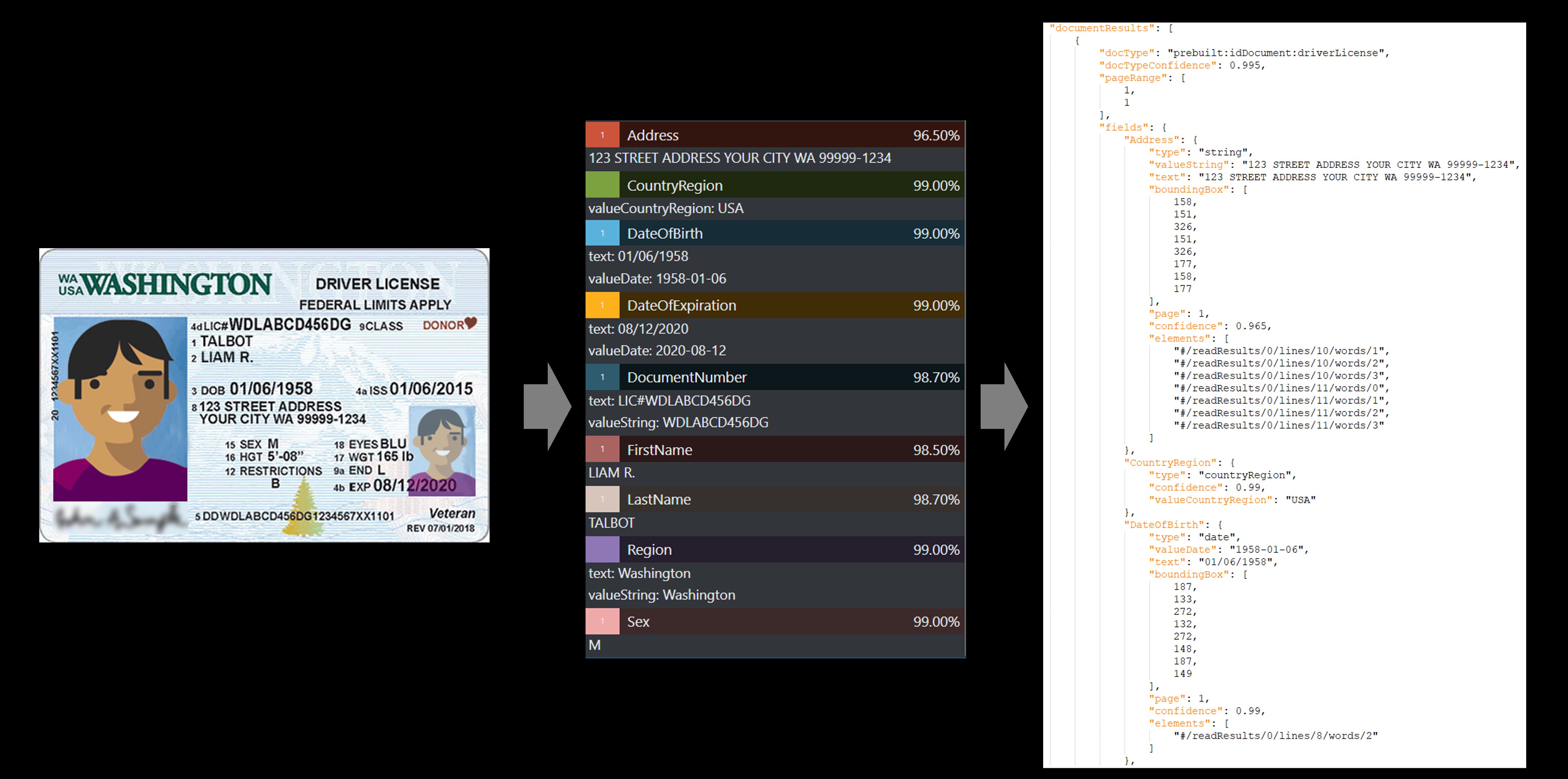
Identiteitsdocument (id)

Gebruik het identiteitsdocumentmodel (ID) voor het verwerken van amerikaanse rijbewijs's (alle 50 staten en district van Columbia) en biografische pagina's van internationale paspoorten (met uitzondering van visum en andere reisdocumenten) om belangrijke velden te extraheren.
Voorbeeld van een U.S. Driver's License verwerkt met Document Intelligence Studio:

Huwelijksakte
![]()
Gebruik het huwelijkscertificaatmodel om Amerikaanse huwelijkscertificaten te verwerken om belangrijke velden te extraheren, waaronder de individuen, datum en locatie.
Voorbeeld van een Amerikaans huwelijkscertificaat dat is verwerkt met Document Intelligence Studio:

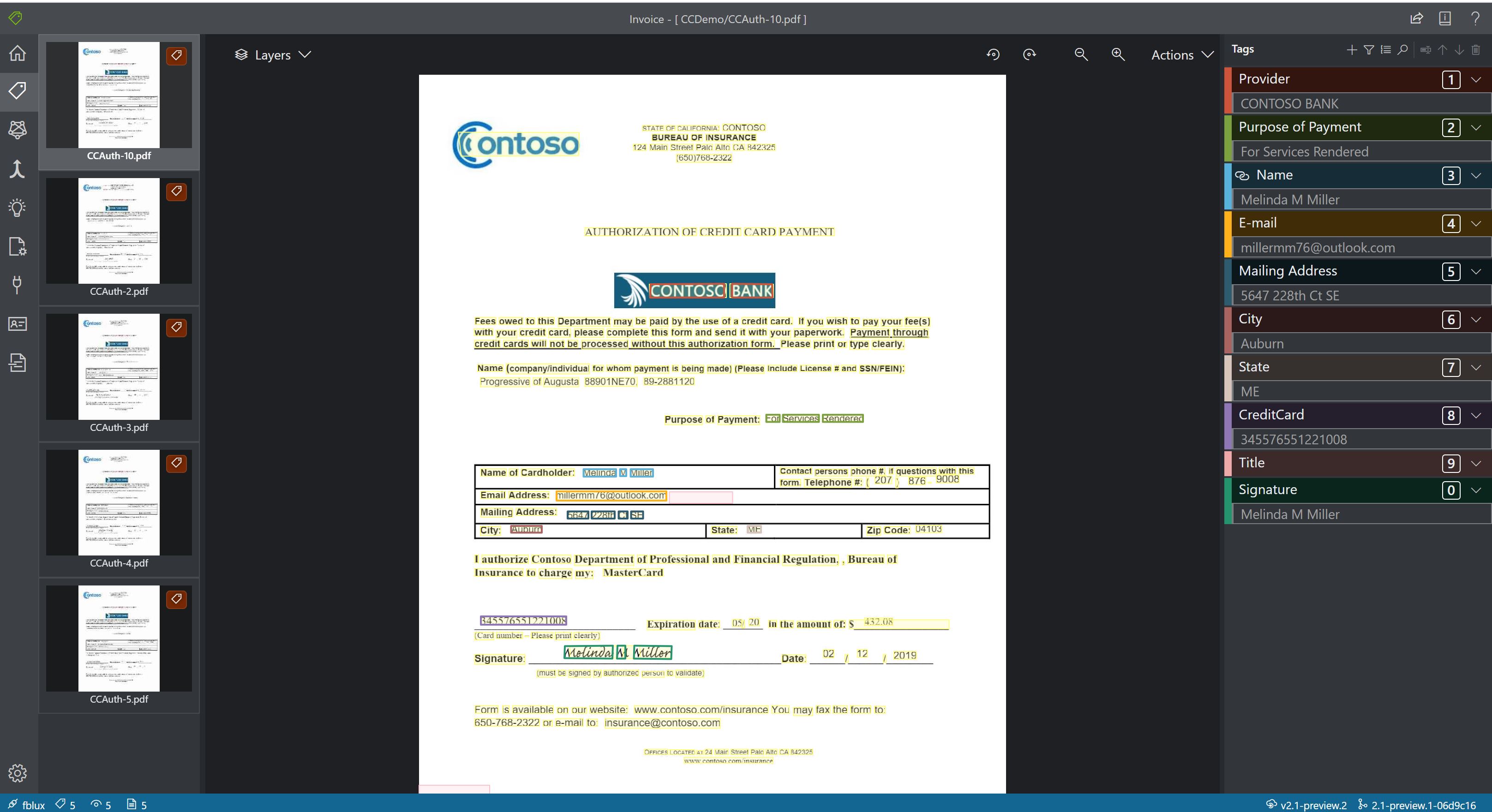
Creditcard
![]()
Gebruik het creditcardmodel om creditcards en betaalkaarten te verwerken om sleutelvelden te extraheren.
Voorbeeld van creditcard verwerkt met Document Intelligence Studio:

Aangepaste modellen

Aangepaste modellen kunnen breed worden geclassificeerd in twee typen. Aangepaste classificatiemodellen die ondersteuning bieden voor classificatie van een 'documenttype' en aangepaste extractiemodellen waarmee een gedefinieerd schema uit een specifiek documenttype kan worden geëxtraheerd.

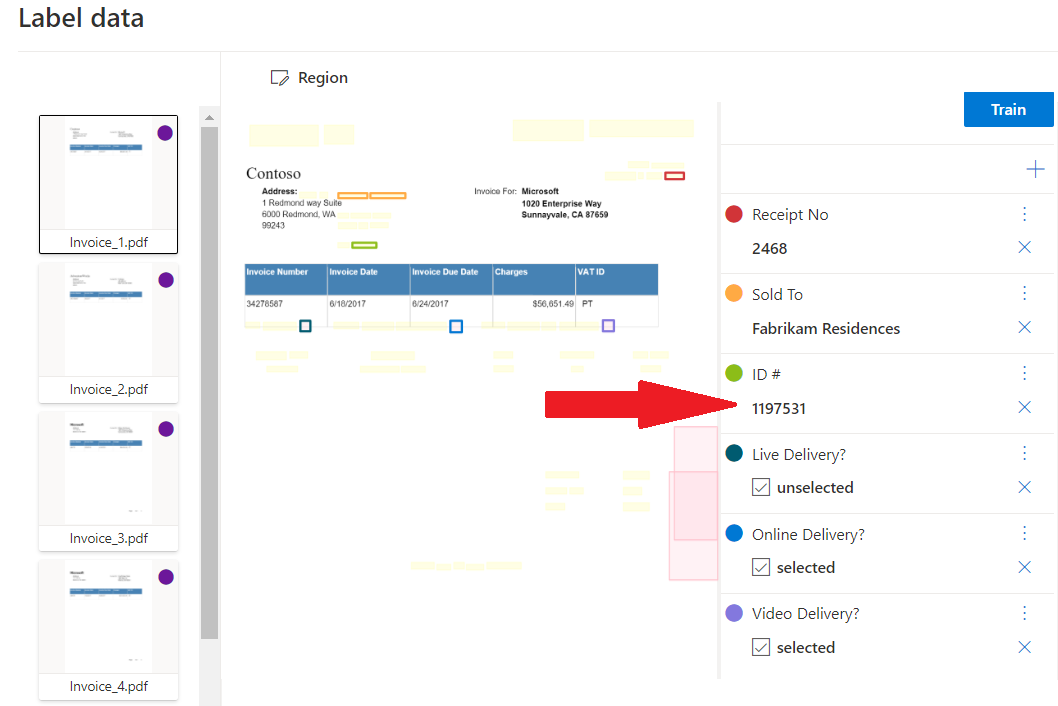
Aangepaste documentmodellen analyseren en extraheren gegevens uit formulieren en documenten die specifiek zijn voor uw bedrijf. Ze worden getraind om formuliervelden binnen uw afzonderlijke inhoud te herkennen en sleutel-waardeparen en tabelgegevens te extraheren. U hebt slechts één voorbeeld van het formuliertype nodig om aan de slag te gaan.
Versie v3.0 aangepast model ondersteunt handtekeningdetectie in aangepaste sjabloon (formulier) en tabellen op meerdere pagina's in zowel sjabloon- als neurale modellen.
Voorbeeld van een aangepaste sjabloon die is verwerkt met Document Intelligence Studio:
Aangepaste extractie

Aangepast extractiemodel kan een van de twee typen zijn, een aangepaste sjabloon of een aangepast neuraal model. Als u een aangepast extractiemodel wilt maken, labelt u een gegevensset met documenten met de waarden die u wilt ophalen en traint u het model op de gelabelde gegevensset. U hebt slechts vijf voorbeelden van hetzelfde formulier of documenttype nodig om aan de slag te gaan.
Voorbeeld van aangepaste extractie verwerkt met Document Intelligence Studio:

Aangepaste classificatie

Met het aangepaste classificatiemodel kunt u het documenttype identificeren voordat u het extractiemodel aanroept. Het classificatiemodel is beschikbaar vanaf de 2023-07-31 (GA) API. Voor het trainen van een aangepast classificatiemodel zijn ten minste twee afzonderlijke klassen en minimaal vijf voorbeelden per klasse vereist.
Samengestelde modellen
Er wordt een samengesteld model gemaakt door een verzameling aangepaste modellen te maken en deze toe te wijzen aan één model dat is gebouwd op basis van uw formuliertypen. U kunt meerdere aangepaste modellen toewijzen aan een samengesteld model dat wordt aangeroepen met één model-id. U kunt maximaal 200 getrainde aangepaste modellen toewijzen aan één samengesteld model.
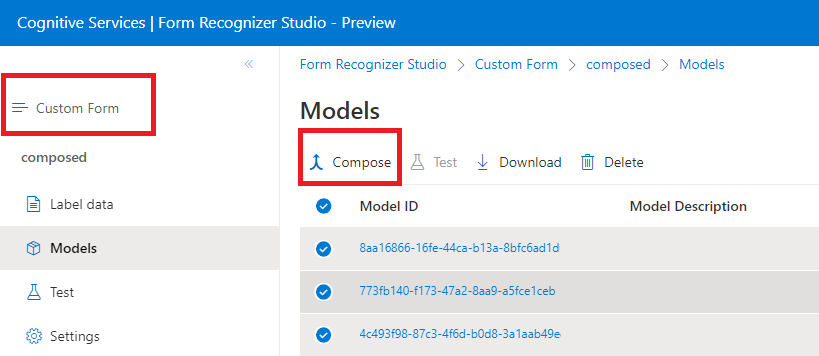
Dialoogvenster Samengesteld model in Document Intelligence Studio:
Vereisten voor invoer
Geef voor de beste resultaten één duidelijke foto of een hoogwaardige scan per document op.
Ondersteunde bestandsindelingen:
Model PDF Afbeelding:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) en HTMLRead ✔ ✔ ✔ Indeling ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Algemeen document ✔ ✔ Vooraf gebouwd ✔ ✔ Aangepaste extractie ✔ ✔ Aangepaste classificatie ✔ ✔ ✔ (2024-02-29-preview) Voor PDF en TIFF kunnen maximaal 2000 pagina's worden verwerkt (met een abonnement op de gratis laag worden alleen de eerste twee pagina's verwerkt).
De bestandsgrootte voor het analyseren van documenten is 500 MB voor betaalde (S0) laag en 4 MB gratis (F0).
De afmetingen van de afbeelding moeten tussen 50 x 50 pixels en 10.000 pixels x 10.000 pixels zijn.
Als uw PDF's zijn vergrendeld met een wachtwoord, moet u de vergrendeling verwijderen voordat u ze indient.
De minimale hoogte van de tekst die moet worden geëxtraheerd, is 12 pixels voor een afbeelding van 1024 x 768 pixels. Deze dimensie komt overeen met ongeveer
8-punttekst op 150 punten per inch (DPI).Voor aangepaste modeltraining is het maximum aantal pagina's voor trainingsgegevens 500 voor het aangepaste sjabloonmodel en 50.000 voor het aangepaste neurale model.
Voor het trainen van aangepaste extractiemodellen is de totale grootte van trainingsgegevens 50 MB voor het sjabloonmodel en 1G-MB voor het neurale model.
Voor het trainen van aangepast classificatiemodel is
1GBde totale grootte van trainingsgegevens maximaal 10.000 pagina's.
Notitie
Het hulpprogramma Voorbeeldlabeling biedt geen ondersteuning voor de BMP-bestandsindeling. Dit is een beperking van het hulpprogramma niet van de Document Intelligence-service.
Versiemigratie
Meer informatie over het gebruik van Document Intelligence v3.0 in uw toepassingen door onze Document Intelligence v3.1-migratiehandleiding te volgen
| Model | Beschrijving |
|---|---|
| Documentanalyse | |
| Indeling | Tekst- en indelingsgegevens extraheren uit documenten. |
| Voorgebouwde | |
| Factuur | Belangrijke informatie extraheren uit Engelse en Spaanse facturen. |
| Ontvangst | Belangrijke informatie extraheren uit Engelse ontvangstbewijzen. |
| Id-document | Haal belangrijke informatie op uit amerikaanse rijbewijs's en internationale paspoorten. |
| Visitekaartje | Belangrijke informatie extraheren uit Engelse visitekaartjes. |
| Aangepast | |
| Aangepast | Gegevens extraheren uit formulieren en documenten die specifiek zijn voor uw bedrijf. Aangepaste modellen worden getraind voor uw afzonderlijke gegevens en gebruiksvoorbeelden. |
| Samengesteld uit | Stel een verzameling aangepaste modellen samen en wijs ze toe aan één model dat is gebouwd op basis van uw formuliertypen. |
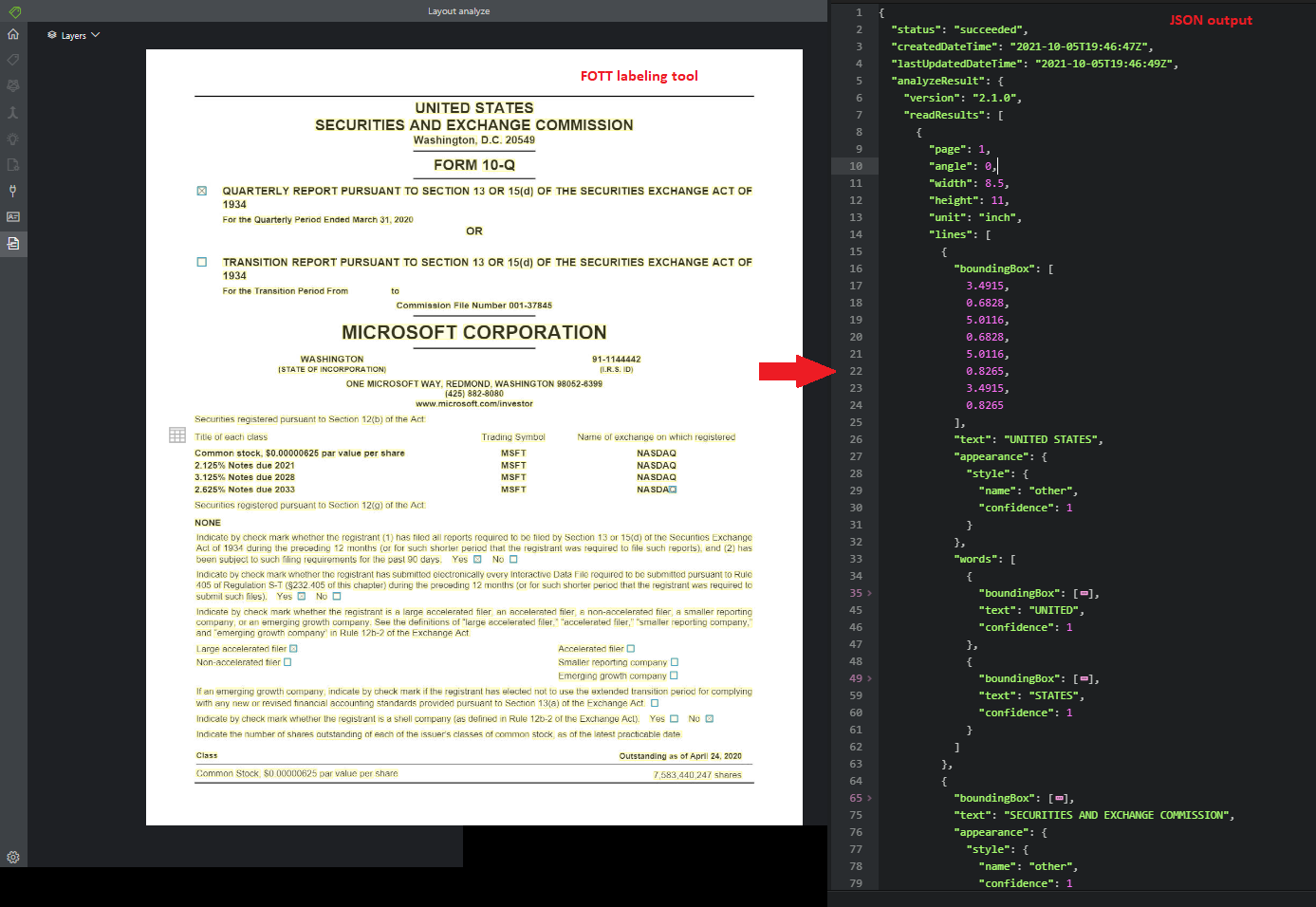
Indeling
De Layout-API analyseert en extraheert tekst, tabellen en kopteksten, selectiemarkeringen en structuurinformatie uit documenten.
Voorbeelddocument dat is verwerkt met behulp van het hulpprogramma Voorbeeldlabels:
Factuur
Het factuurmodel analyseert en extraheert belangrijke informatie uit verkoopfacturen. De API analyseert facturen in verschillende indelingen en extraheert belangrijke informatie, zoals klantnaam, factuuradres, vervaldatum en verschuldigd bedrag.
Voorbeeldfactuur verwerkt met behulp van het voorbeeldhulpprogramma voor labelen:

Ontvangstbewijs
- Het ontvangstbewijsmodel analyseert en extraheert belangrijke informatie uit afgedrukte en handgeschreven verkoopbevestigingen.
Voorbeeldbevestiging verwerkt met voorbeeldhulpprogramma voor labelen:
Id-document
Het id-documentmodel analyseert en extraheert belangrijke informatie uit de volgende documenten:
U.S. Driver's Licenses (alle 50 staten en District of Columbia)
Biografische pagina's van internationale paspoorten (met uitzondering van visum en andere reisdocumenten). De API analyseert identiteitsdocumenten en extraheert
Voorbeeld van een U.S. Driver's License verwerkt met behulp van het voorbeeldhulpprogramma voor labelen:
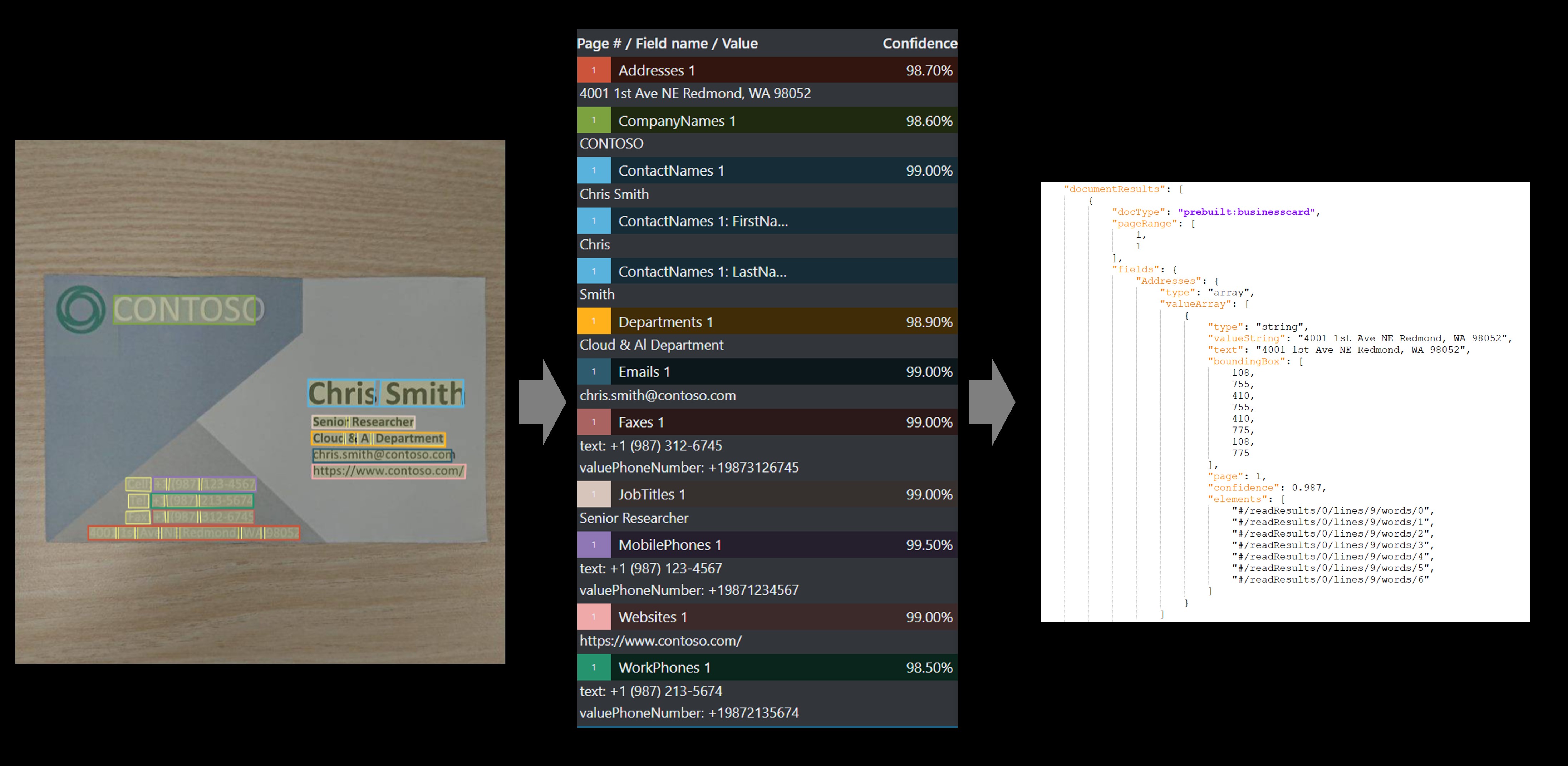
Visitekaartje
Het visitekaartjesmodel analyseert en extraheert belangrijke informatie uit visitekaartjesafbeeldingen.
Voorbeeld van visitekaartje dat is verwerkt met behulp van het voorbeeldhulpprogramma Voor labelen:
Aangepast telefoonnummer
- Aangepaste modellen analyseren en extraheren gegevens uit formulieren en documenten die specifiek zijn voor uw bedrijf. De API is een machine learning-programma dat is getraind om formuliervelden binnen uw afzonderlijke inhoud te herkennen en sleutel-waardeparen en tabelgegevens te extraheren. U hebt slechts vijf voorbeelden van hetzelfde formuliertype nodig om aan de slag te gaan en uw aangepaste model kan worden getraind met of zonder gelabelde gegevenssets.
Voorbeeld van aangepaste modelverwerking met behulp van het hulpprogramma Voorbeeldlabeling:
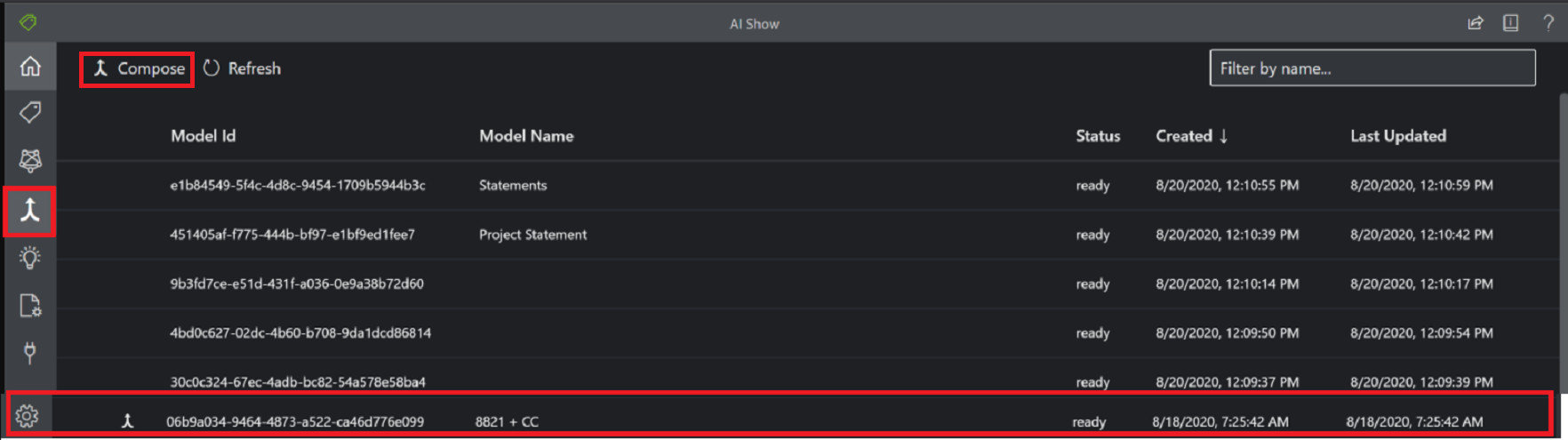
Samengesteld aangepast model
Er wordt een samengesteld model gemaakt door een verzameling aangepaste modellen te maken en deze toe te wijzen aan één model dat is gebouwd op basis van uw formuliertypen. U kunt meerdere aangepaste modellen toewijzen aan een samengesteld model dat wordt aangeroepen met één model-id. U kunt maximaal 100 getrainde aangepaste modellen toewijzen aan één samengesteld model.
Dialoogvenster Samengesteld model met behulp van het hulpprogramma Voorbeeld van labelen:
Gegevensextractie modelleren
| Model | Tekstextractie | Taaldetectie | Selectiemarkeringen | Tabellen | Leden | Alinearollen | Sleutel-waardeparen | Velden |
|---|---|---|---|---|---|---|---|---|
| Indeling | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Factuur | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Ontvangst | ✓ | ✓ | ✓ | |||||
| Id-document | ✓ | ✓ | ✓ | |||||
| Visitekaartje | ✓ | ✓ | ✓ | |||||
| Aangepast formulier | ✓ | ✓ | ✓ | ✓ | ✓ |
Vereisten voor invoer
Geef voor de beste resultaten één duidelijke foto of een hoogwaardige scan per document op.
Ondersteunde bestandsindelingen:
Model PDF Afbeelding:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) en HTMLRead ✔ ✔ ✔ Indeling ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Algemeen document ✔ ✔ Vooraf gebouwd ✔ ✔ Aangepaste extractie ✔ ✔ Aangepaste classificatie ✔ ✔ ✔ (2024-02-29-preview) Voor PDF en TIFF kunnen maximaal 2000 pagina's worden verwerkt (met een abonnement op de gratis laag worden alleen de eerste twee pagina's verwerkt).
De bestandsgrootte voor het analyseren van documenten is 500 MB voor betaalde (S0) laag en 4 MB gratis (F0).
De afmetingen van de afbeelding moeten tussen 50 x 50 pixels en 10.000 pixels x 10.000 pixels zijn.
Als uw PDF's zijn vergrendeld met een wachtwoord, moet u de vergrendeling verwijderen voordat u ze indient.
De minimale hoogte van de tekst die moet worden geëxtraheerd, is 12 pixels voor een afbeelding van 1024 x 768 pixels. Deze dimensie komt overeen met ongeveer
8-punttekst op 150 punten per inch (DPI).Voor aangepaste modeltraining is het maximum aantal pagina's voor trainingsgegevens 500 voor het aangepaste sjabloonmodel en 50.000 voor het aangepaste neurale model.
Voor het trainen van aangepaste extractiemodellen is de totale grootte van trainingsgegevens 50 MB voor het sjabloonmodel en 1G-MB voor het neurale model.
Voor het trainen van aangepast classificatiemodel is
1GBde totale grootte van trainingsgegevens maximaal 10.000 pagina's.
Notitie
Het hulpprogramma Voorbeeldlabeling biedt geen ondersteuning voor de BMP-bestandsindeling. Dit is een beperking van het hulpprogramma niet van de Document Intelligence-service.
Versiemigratie
U kunt leren hoe u Document Intelligence v3.0 in uw toepassingen kunt gebruiken door onze Document Intelligence v3.1-migratiehandleiding te volgen
Volgende stappen
Probeer uw eigen formulieren en documenten te verwerken met Document Intelligence Studio.
Voltooi een quickstart voor Document Intelligence en ga aan de slag met het maken van een app voor documentverwerking in de ontwikkeltaal van uw keuze.
Probeer uw eigen formulieren en documenten te verwerken met het hulpprogramma Document Intelligence Sample Labeling.
Voltooi een quickstart voor Document Intelligence en ga aan de slag met het maken van een app voor documentverwerking in de ontwikkeltaal van uw keuze.