Een aangepast model trainen met het hulpprogramma Voorbeeldlabels
Deze inhoud is van toepassing op:![]() v2.1.
v2.1.
Tip
- Voor een verbeterde ervaring en geavanceerde modelkwaliteit kunt u Document Intelligence v3.0 Studio gebruiken.
- V3.0 Studio ondersteunt elk model dat is getraind met v2.1 gelabelde gegevens.
- Raadpleeg de API-migratiehandleiding voor gedetailleerde informatie over het migreren van v2.1 naar v3.0.
- Bekijk onze quickstarts voor REST API of C#, Java, JavaScript of Python SDK om aan de slag te gaan met V3.0.
In dit artikel gebruikt u de Document Intelligence REST API met het hulpprogramma Voorbeeldlabels om een aangepast model te trainen met handmatig gelabelde gegevens.
Vereisten
U hebt de volgende resources nodig om dit project te voltooien:
- Azure-abonnement: Krijg een gratis abonnement
- Zodra u uw Azure-abonnement hebt, maakt u een Document Intelligence-resource in Azure Portal om uw sleutel en eindpunt op te halen. Nadat de app is geïmplementeerd, selecteert u Ga naar resource.
- U hebt de sleutel en het eindpunt nodig van de resource die u maakt om uw toepassing te verbinden met de Document Intelligence-API. U plakt uw sleutel en eindpunt verderop in de code in de quickstart.
- U kunt de gratis prijscategorie (
F0) gebruiken om de service uit te proberen, en later upgraden naar een betaalde laag voor productie.
- Een set van minimaal zes formulieren van hetzelfde type. U gebruikt deze gegevens om het model te trainen en een formulier te testen. U kunt een voorbeeldgegevensverzameling gebruiken voor deze quickstart (download en extraheer sample_data.zip). Upload de trainingsbestanden naar de hoofdmap van een Blob Storage-container in een Azure Storage-account met een standaardprestatielaag.
Een Document Intelligence-resource maken
Ga naar Azure Portal en maak een nieuwe Document Intelligence-resource . Geef in het deelvenster Maken de volgende gegevens op:
| Projectdetails | Beschrijving |
|---|---|
| Abonnement | Selecteer het Azure-abonnement waaraan toegang is verleend. |
| Resourcegroep | De Azure-resourcegroep die uw resource bevat. U kunt een nieuwe groep maken of deze toevoegen aan een bestaande groep. |
| Regio | De locatie van uw Azure AI-servicesresource. Verschillende locaties kunnen latentie veroorzaken, maar deze hebben geen invloed op de beschikbaarheid van de runtime van uw resource. |
| Naam | Een beschrijvende naam voor de resource. U kunt het beste een beschrijvende naam gebruiken, bijvoorbeeld MyNameFormRecognizer. |
| Prijscategorie | De kosten van uw resource zijn afhankelijk van de prijscategorie die u kiest en van uw gebruik. Zie Prijsopgaven voor API's voor meer informatie. |
| Beoordelen en maken | Selecteer de knop Beoordelen en maken om uw resource te implementeren in Azure Portal. |
De sleutel en het eindpunt ophalen
Wanneer uw Document Intelligence-resource is geïmplementeerd, zoekt en selecteert u deze in de lijst Alle resources in de portal. Uw sleutel en eindpunt bevinden zich op de pagina Sleutel en eindpunt van de resource, onder Resourcebeheer. Sla beide op een tijdelijke locatie op voordat u verdergaat.
Probeer het zelf
Probeer het hulpprogramma Document Intelligence Sample Labeling online uit:
U hebt een Azure-abonnement nodig (maak er gratis een) en een Document Intelligence-resource-eindpunt en -sleutel om de Document Intelligence-service uit te proberen.
Het hulpprogramma Voorbeeldlabeling instellen
Notitie
Als uw opslaggegevens zich achter een VNet of firewall bevinden, moet u het hulpprogramma Voor documentinformatievoorbeeldlabels achter uw VNet of firewall implementeren en toegang verlenen door een door het systeem toegewezen beheerde identiteit te maken.
U gebruikt de Docker-engine om het hulpprogramma Voorbeeldlabeling uit te voeren. Volg deze stappen om de Docker-container in te stellen. Zie het Docker-overzicht voor een inleiding tot de basisprincipes van Docker en containers.
Tip
Het OCR-voorbeeldhulpprogramma voor labelen is ook beschikbaar als een opensourceproject op GitHub. Het hulpprogramma is een TypeScript-webtoepassing die is gebouwd met React + Redux. Zie de opslagplaats OCR Form Labeling Tool (OCR-voorbeeldhulpprogramma voor labelen) voor meer informatie of als u een bijdrage wilt leveren. Als u het hulpprogramma online wilt uitproberen, gaat u naar de website van het hulpprogramma Document Intelligence-voorbeeldlabels.
Installeer eerst Docker op een hostcomputer. In deze handleiding ziet u hoe u lokale computer als host gebruikt. Als u een Docker-hostingservice in Azure wilt gebruiken, raadpleegt u de handleiding Het voorbeeldhulpprogramma voor labelen implementeren.
De hostcomputer moet voldoen aan de volgende hardwarevereisten:
Container Minimaal Aanbevolen Voorbeeldhulpprogramma voor labelen 2kerngeheugen, 4 GB geheugen4kerngeheugen, 8 GB geheugenInstalleer Docker op uw computer door de juiste instructies te volgen voor uw besturingssysteem:
Haal de container met het voorbeeldhulpprogramma voor labelen op met de
docker pullopdracht.docker pull mcr.microsoft.com/azure-cognitive-services/custom-form/labeltool:latest-2.1U bent nu klaar om de container met
docker runuit te voeren.docker run -it -p 3000:80 mcr.microsoft.com/azure-cognitive-services/custom-form/labeltool:latest-2.1 eula=acceptMet deze opdracht maakt u het voorbeeldhulpprogramma voor labelen beschikbaar via een webbrowser. Ga naar
http://localhost:3000.
Notitie
U kunt ook documenten labelen en modellen trainen met behulp van de Document Intelligence REST API. Als u wilt trainen en analyseren met de REST API, raadpleegt u Trainen met labels met behulp van de REST API en Python.
Invoergegevens instellen
Zorg er eerst voor dat alle trainingsdocumenten dezelfde indeling hebben. Als u formulieren in meerdere indelingen hebt, kunt u deze op basis van hun gemeenschappelijke indeling in submappen ordenen. Wanneer u traint, moet u de API omleiden naar een submap.
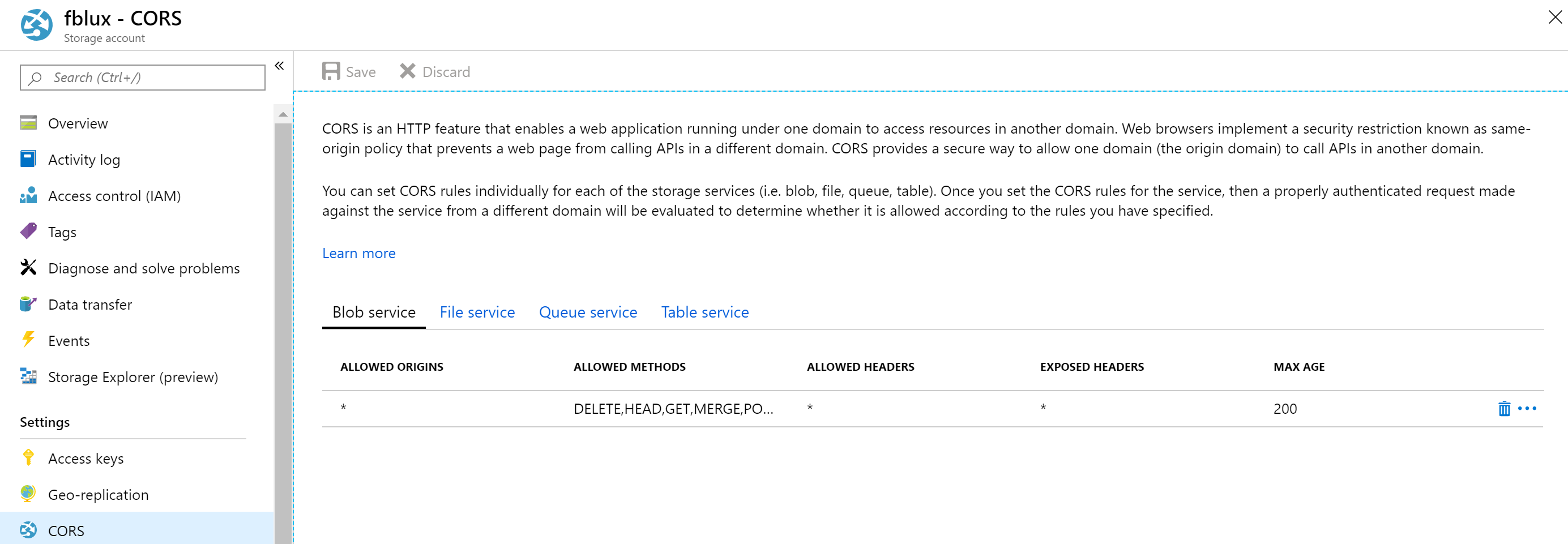
Delen van resources voor meerdere domeinen (CORS) configureren
Schakel CORS in voor uw opslagaccount. Selecteer uw opslagaccount in Azure Portal en kies vervolgens het CORS-tabblad in het linkerdeelvenster. Vul in de onderste regel de volgende waarden in. Selecteer Opslaan bovenaan.
- Toegestane oorsprongen = *
- Toegestane methoden = [alles selecteren]
- Toegestane headers = *
- Zichtbare headers = *
- Maximumleeftijd = 200
Verbinding maken naar het voorbeeldhulpprogramma voor labelen
Het hulpprogramma Voorbeeldlabeling maakt verbinding met een bron (uw oorspronkelijke geüploade formulieren) en een doel (gemaakte labels en uitvoergegevens).
Verbindingen kunnen worden projectbreed worden ingesteld en gedeeld. Ze maken gebruik van een uitbreidbaar providermodel, zodat u eenvoudig nieuwe bron-/doelproviders kunt toevoegen.
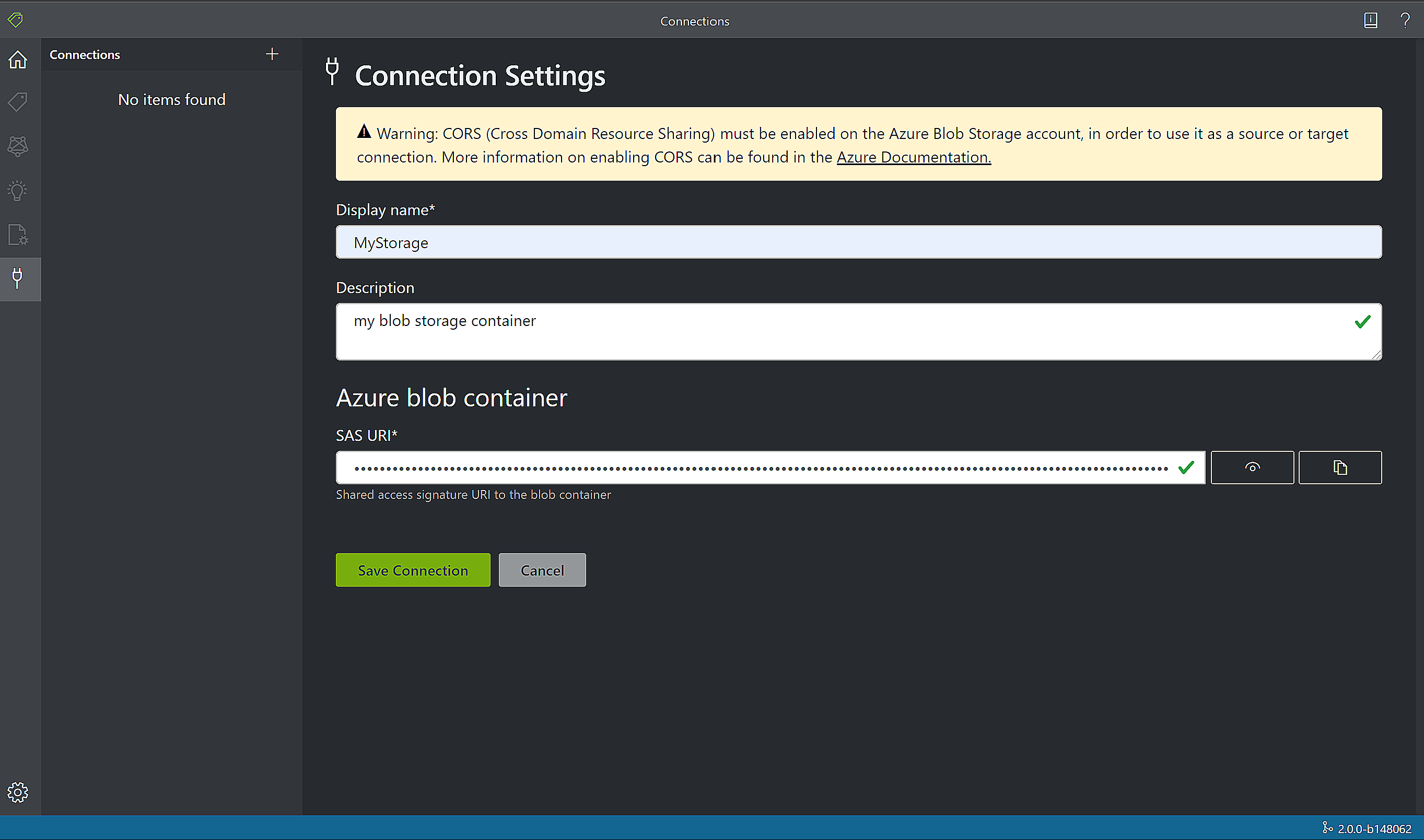
Als u een nieuwe verbinding wilt maken, selecteert u het pictogram Nieuwe Verbinding maken ions (plug) in de linkernavigatiebalk.
Vul de velden in met de volgende waarden:
Weergavenaam: de weergavenaam van de verbinding.
Beschrijving: de beschrijving van het project.
SAS-URL: de Shared Access Signature-URL (SAS-URL) van de Azure Blob Storage-container. Als u de SAS-URL voor uw aangepaste modeltrainingsgegevens wilt ophalen, gaat u naar uw opslagresource in Azure Portal en selecteert u het tabblad Storage Explorer . Navigeer naar uw container, klik met de rechtermuisknop en selecteer Handtekening voor gedeelde toegang ophalen. Het is belangrijk dat u de SAS voor uw container ophaalt, niet voor het opslagaccount zelf. Zorg ervoor dat de machtigingen Lezen, Schrijven, Verwijderen en Lijst zijn ingeschakeld en klik op Maken. Kopieer vervolgens de waarde in de sectie URL naar een tijdelijke locatie. Deze moet de notatie
https://<storage account>.blob.core.windows.net/<container name>?<SAS value>hebben.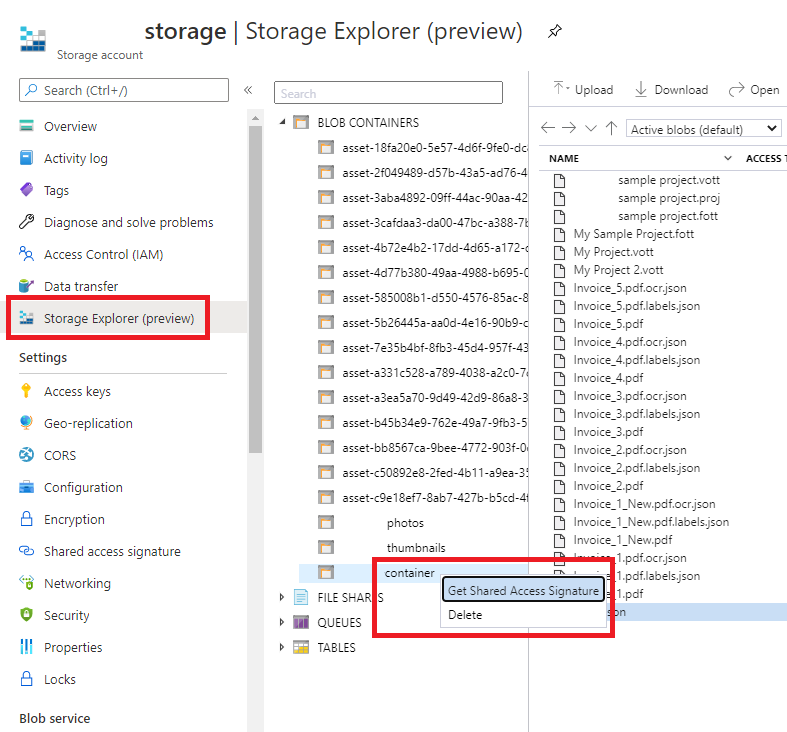
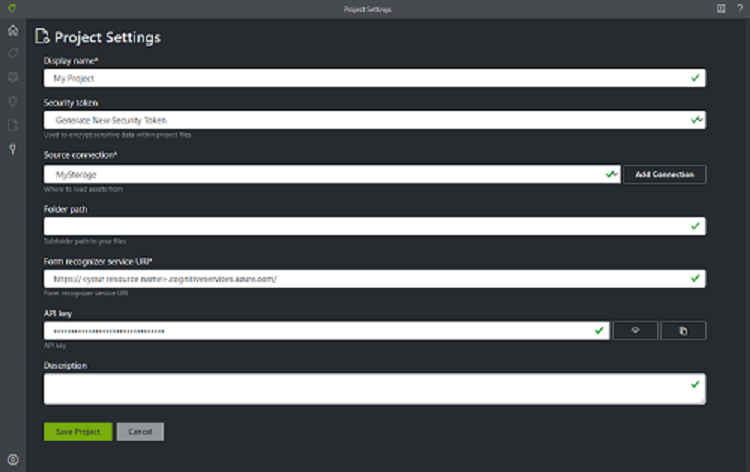
Een nieuw project maken
In het hulpprogramma Voorbeeldlabels worden uw configuraties en instellingen opgeslagen in projecten. Maak een nieuw project en vul de velden in met de volgende waarden:
- Weergavenaam : de weergavenaam van het project
- Beveiligingstoken : sommige projectinstellingen kunnen gevoelige waarden bevatten, zoals sleutels of andere gedeelde geheimen. Elk project genereert een beveiligingstoken dat kan worden gebruikt voor het versleutelen/ontsleutelen van gevoelige projectinstellingen. U vindt beveiligingstokens in de toepassings-Instellingen door het tandwielpictogram onderaan de linkernavigatiebalk te selecteren.
- Bronverbinding: de Azure Blob Storage-verbinding die u in de vorige stap hebt gemaakt en die u voor dit project wilt gebruiken.
- Mappad: optioneel: als uw bronformulieren zich in een map in de Blobcontainer bevinden, geeft u de naam van de map hier op
- Document Intelligence Service-URI : de URL van uw Document Intelligence-eindpunt.
- Sleutel : uw Document Intelligence-sleutel.
- Beschrijving: optioneel: projectbeschrijving
Formulieren labelen
Wanneer u een project maakt of opent, wordt hoofdvenster van de tageditor geopend. De tageditor bestaat uit drie delen:
- Een formaat van het deelvenster v3.0 met een door de bronverbinding te schuiven lijst met formulieren.
- Het hoofdvenster van de tageditor waarmee u labels kunt toepassen.
- Het deelvenster van de tageditor waarmee gebruikers labels kunnen wijzigen, vergrendelen, opnieuw ordenen en verwijderen.
Tekst en tabellen identificeren
Selecteer Indeling uitvoeren voor niet-bekeken documenten in het linkerdeelvenster om de tekst- en tabelindelingsgegevens voor elk document op te halen. Met het labelprogramma worden begrenzingsvakken rond elk tekstelement tekend.
In het hulpprogramma voor labelen ziet u ook welke tabellen automatisch zijn geëxtraheerd. Selecteer het tabel-/rasterpictogram aan de linkerkant van het document om de geëxtraheerde tabel weer te geven. In deze quickstart, omdat de inhoud van de tabel automatisch wordt geëxtraheerd, geven we geen label aan de inhoud van de tabel, maar vertrouwen we liever op de geautomatiseerde extractie.
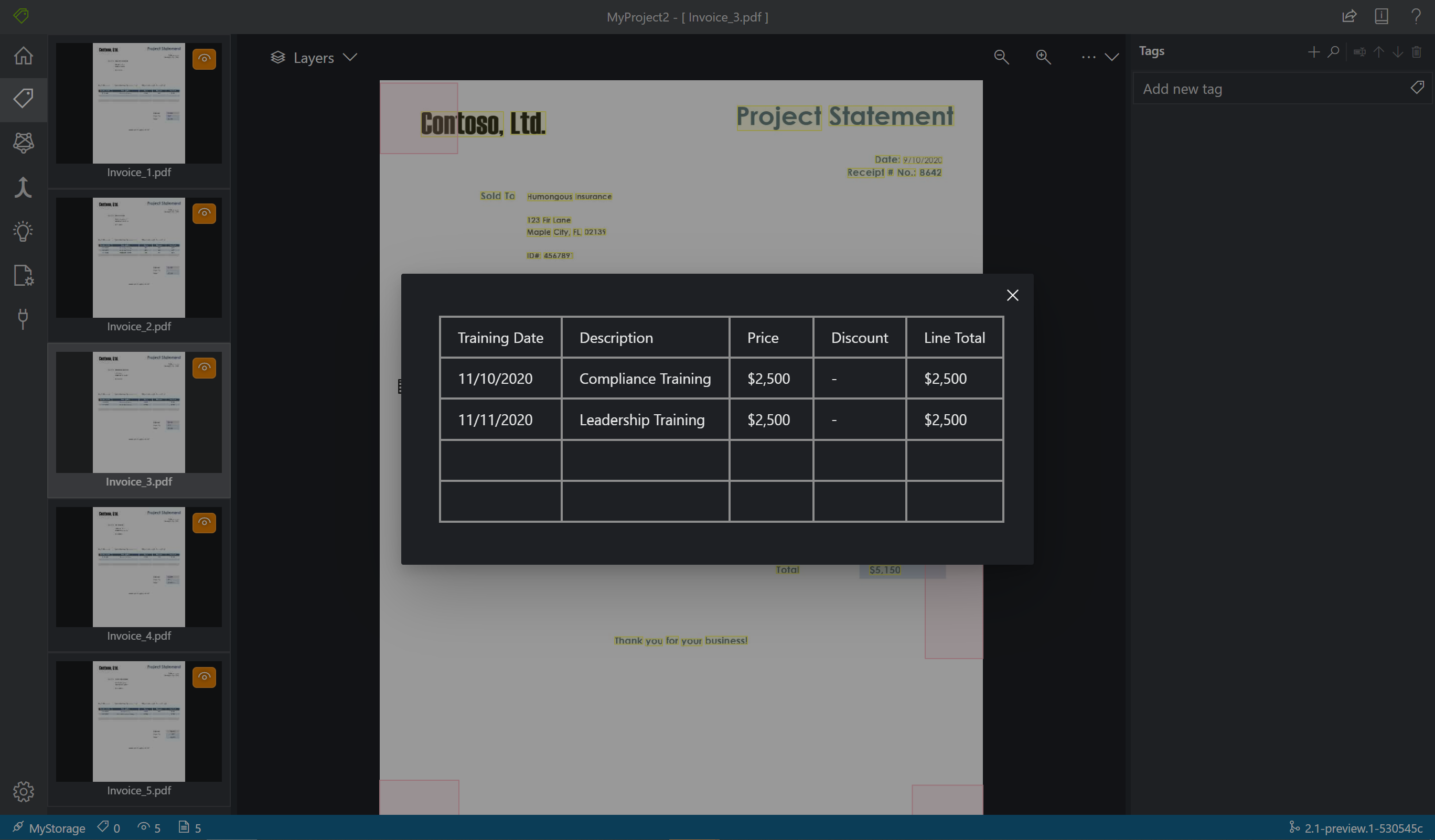
Als in v2.1 geen waarde is ingevuld in uw trainingsdocument, kunt u een vak tekenen waarin de waarde moet staan. Gebruik tekengebied in de linkerbovenhoek van het venster om de regio taggable te maken.
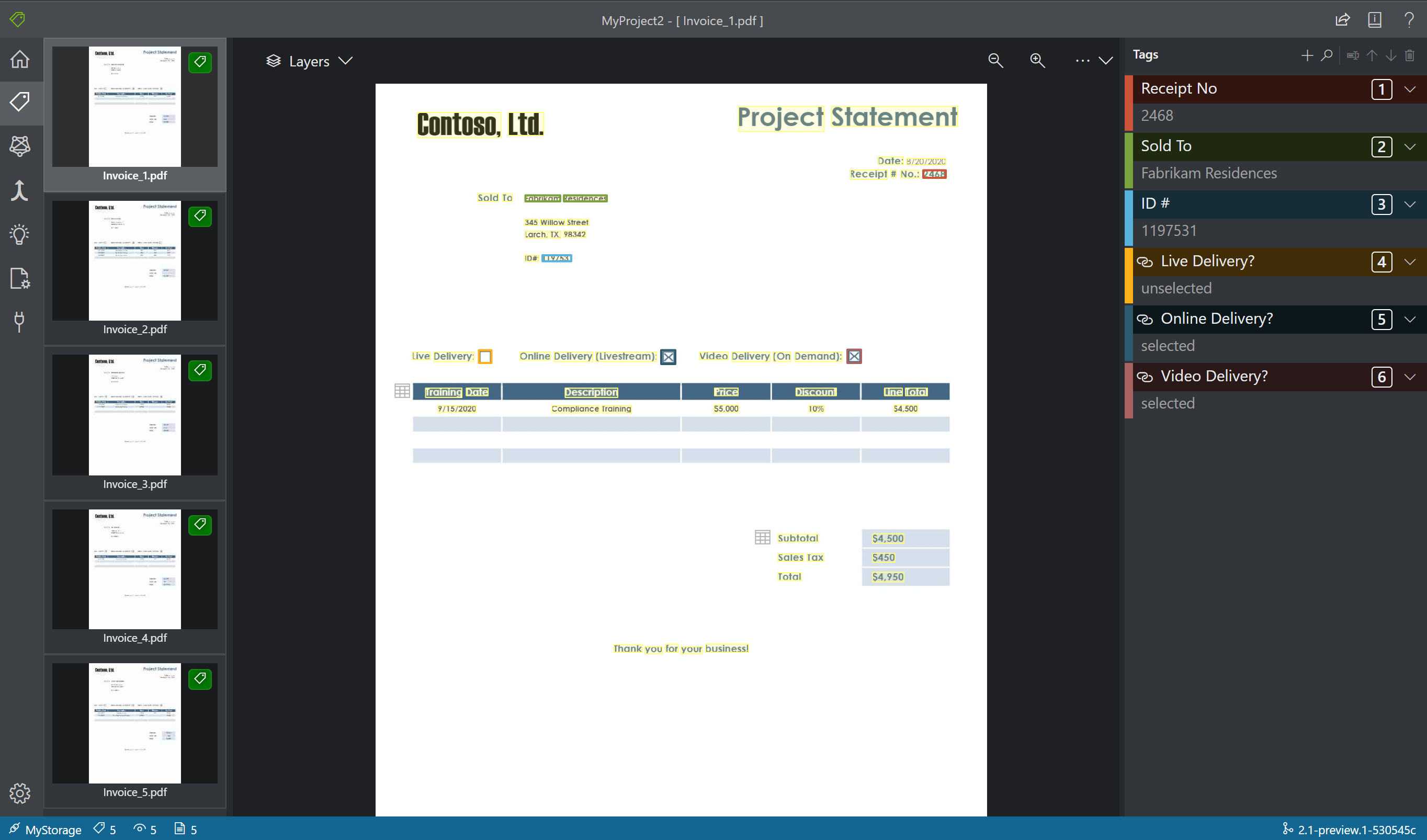
Labels op tekst toepassen
Vervolgens maakt u tags (labels) en past u deze toe op de tekstelementen die u wilt analyseren in het model.
- Gebruik eerst het deelvenster van de tageditor om de labels te maken die u wilt identificeren.
- Selecteer + deze optie om een nieuwe tag te maken.
- Voer de naam van het label in.
- Druk op Enter om het label op te slaan.
- Selecteer in de hoofdeditor woorden uit de gemarkeerde tekstelementen of een regio waarin u hebt getekend.
- Selecteer de tag die u wilt toepassen of druk op de bijbehorende toetsenbordtoets. De numerieke toetsen zijn toegewezen als sneltoetsen voor de eerste tien labels. U kunt de volgorde van de labels wijzigen met behulp van de pijlen omhoog en omlaag in het tageditorvenster.
- Volg deze stappen om ten minste vijf formulieren te labelen.
Tip
Houd rekening met de volgende tips wanneer u uw formulieren labelt:
- U kunt slechts één label per geselecteerd tekstelement toepassen.
- Elk label kan slechts eenmaal per pagina worden toegepast. Als een waarde meerdere keren op hetzelfde formulier wordt weergegeven, maakt u voor elk exemplaar verschillende labels. Bijvoorbeeld: factuur 1, factuur 2, enzovoort.
- Een label kan niet op meerdere pagina's worden toegepast.
- De labelwaarden zijn zoals ze op het formulier worden weergegeven. Splits geen waarde in twee delen met twee verschillende labels. Zo moet bijvoorbeeld een adresveld met één label worden gelabeld, ook als het meerdere regels omvat.
- Neem geen sleutels op in uw getagde velden, alleen de waarden.
- Tabelgegevens moeten automatisch worden gedetecteerd en worden beschikbaar in het laatste JSON-uitvoerbestand. Als het model echter niet alle tabelgegevens detecteert, kunt u deze velden ook handmatig labelen. Label elke cel in de tabel met een ander label. Als uw formulieren tabellen met een wisselend aantal rijen bevatten, moet u ervoor zorgen dat u ten minste één formulier met de grootste mogelijke tabel labelt.
- Gebruik de knoppen rechts van de + om uw labels te zoeken, een nieuwe naam te geven, opnieuw in te delen en te verwijderen.
- Als u een toegepast label wilt verwijderen zonder het label zelf te verwijderen, selecteert u de gemarkeerde rechthoek in de documentweergave en drukt u op de verwijdertoets.
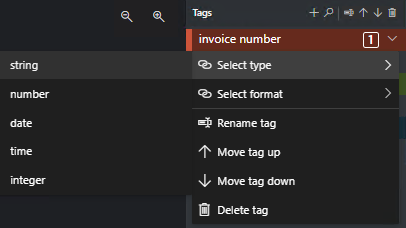
Typen labelwaarden opgeven
U kunt het verwachte gegevenstype voor elke tag instellen. Open het contextmenu rechts van een label en selecteer een type in het menu. Met deze functie kan het detectie-algoritme veronderstellingen maken die de nauwkeurigheid van de tekstdetectie verbeteren. Het zorgt er ook voor dat de gedetecteerde waarden worden geretourneerd in een gestandaardiseerde indeling in de uiteindelijke JSON-uitvoer. Informatie over waardetypen wordt opgeslagen in het bestand fields.json, op hetzelfde pad als uw labelbestanden.
De volgende waardetypen en variaties worden momenteel ondersteund:
string- standaard,
no-whitespaces,alphanumeric
- standaard,
number- standaard,
currency - Opgemaakt als een drijvende-kommawaarde.
- Voorbeeld: 1234.98 op het document is opgemaakt in 1234.98 op de uitvoer
- standaard,
date- standaard,
dmy,mdy,ymd
- standaard,
timeinteger- Opgemaakt als een geheel getal.
- Voorbeeld: 1234.98 in het document is opgemaakt in 123498 in de uitvoer.
selectionMark
Notitie
Zie de volgende regels voor de datumnotatie:
U moet een indeling (dmy, mdy, ymd) opgeven voor de datumnotatie.
De volgende tekens kunnen worden gebruikt als datumscheidingstekens: , - / . \. Witruimte kan niet als scheidingsteken worden gebruikt. Bijvoorbeeld:
- 01,01,2020
- 01-01-2020
- 01-01-2020
De dag en de maand kunnen elk worden geschreven als een of twee cijfers en het jaar kan uit twee of vier cijfers bestaan:
- 1-1-2020
- 01-1-20
Als een datumreeks uit acht cijfers bestaat, is het scheidingsteken optioneel:
- 01012020
- 01-01-2020
De maand kan ook worden geschreven als de volledige of korte naam. Als de naam wordt gebruikt, zijn scheidingstekens optioneel. Deze notatie wordt echter mogelijk minder nauwkeurig herkend dan andere.
- 01-jan-2020
- 01jan2020
- 01 jan 2020
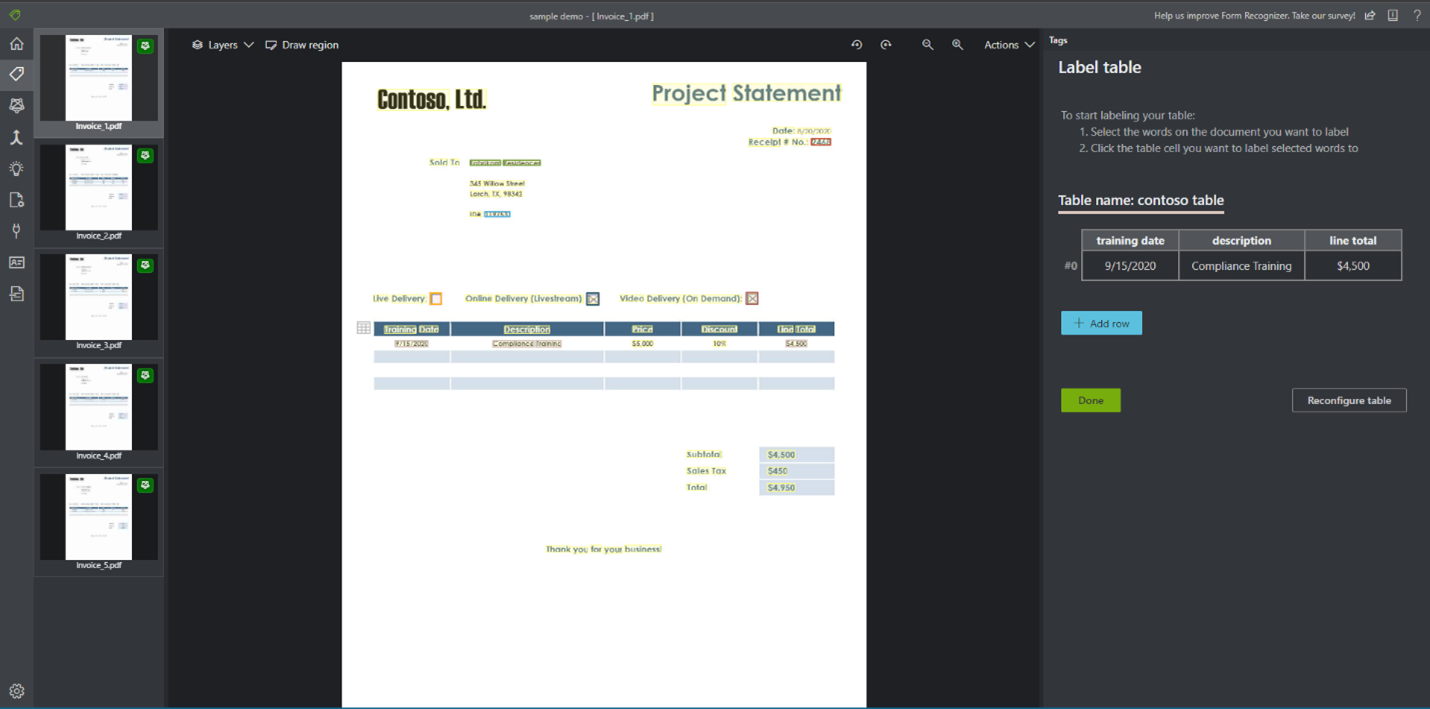
Labeltabellen (alleen v2.1)
Soms lenen uw gegevens zich misschien beter voor het labelen als een tabel in plaats van sleutel-waardeparen. In dit geval kunt u een tabeltag maken door een nieuwe tabeltag toe te voegen. Geef op of de tabel een vast aantal rijen of een variabel aantal rijen heeft, afhankelijk van het document en het schema definieert.
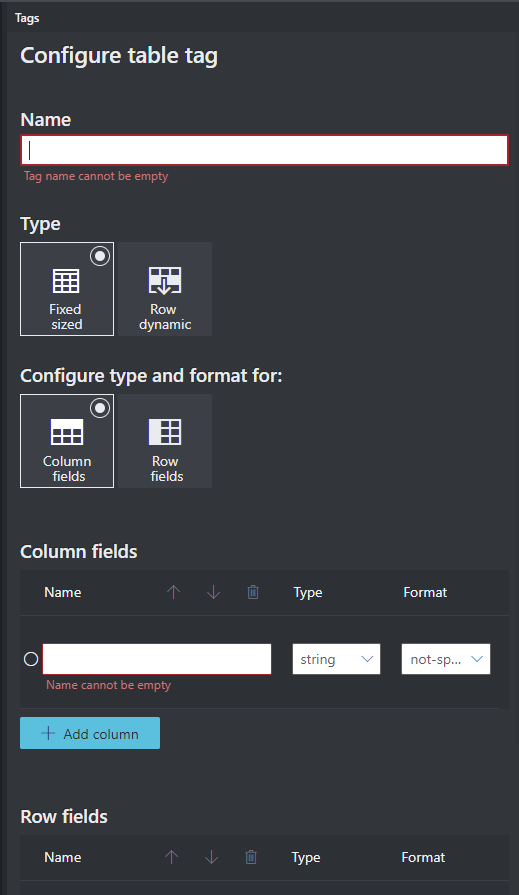
Nadat u de tabeltag hebt gedefinieerd, tagt u de celwaarden.
Aangepast model trainen
Kies het pictogram Trainen in het linkerdeelvenster om de pagina Training te openen. Selecteer vervolgens de knop Trainen om het model te trainen. Zodra het trainingsproces is voltooid, ziet u de volgende informatie:
- Model-id: de id van het model dat is gemaakt en getraind. Elke trainingsaanroep maakt een nieuw model met een eigen id. Kopieer deze tekenreeks naar een veilige locatie; u hebt deze nodig als u voorspellingsoproepen wilt uitvoeren via de REST API of clientbibliotheekhandleiding.
- Gemiddelde nauwkeurigheid: de gemiddelde nauwkeurigheid van het model. U kunt de nauwkeurigheid van het model verbeteren door meer formulieren toe te voegen en te labelen en vervolgens opnieuw te trainen om een nieuw model te maken. We raden u aan te beginnen met het labelen van vijf formulieren en indien nodig meer formulieren toe te voegen.
- De lijst met labels en de geschatte nauwkeurigheid per label.
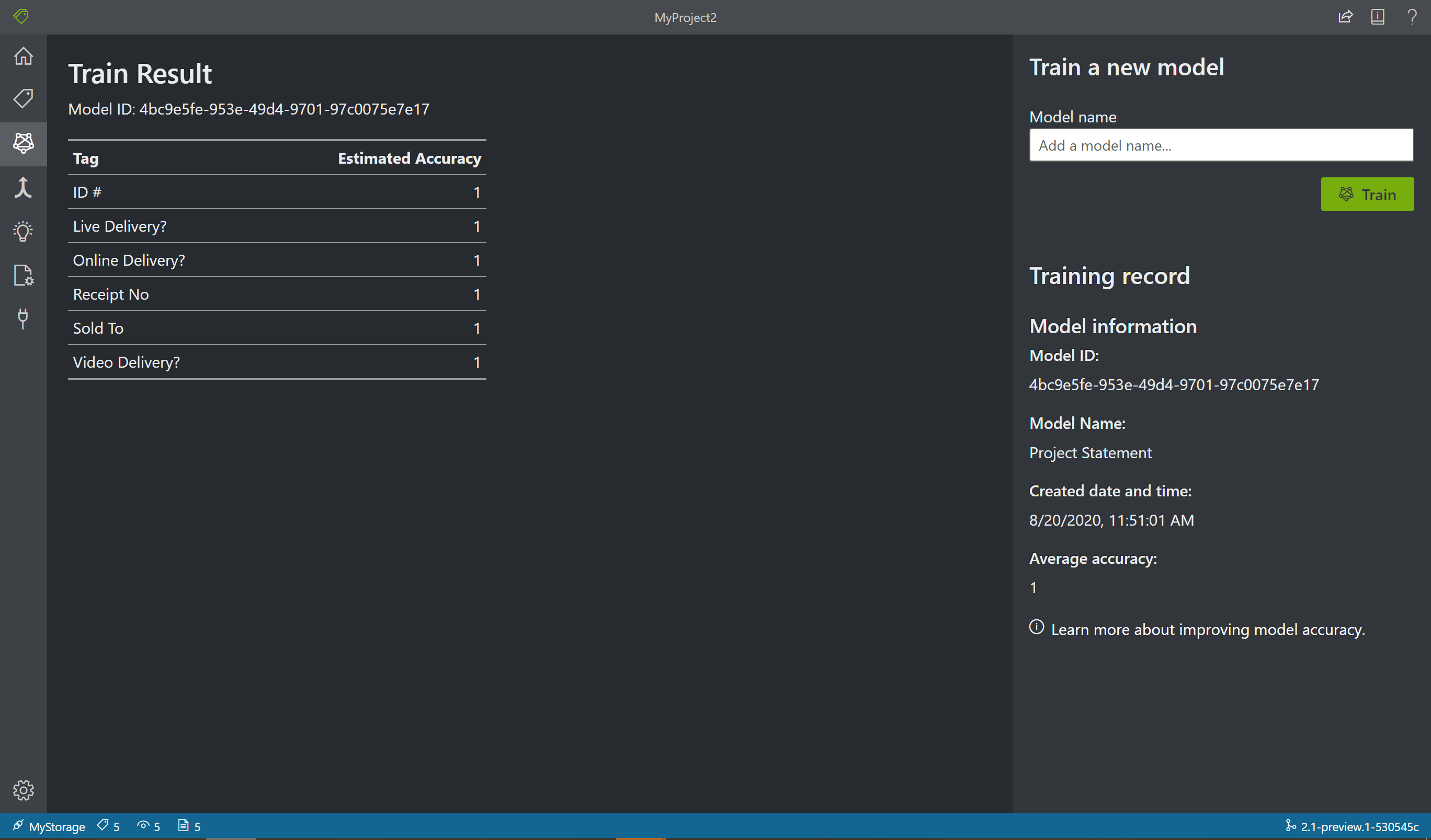
Nadat de training is voltooid, bekijkt u de waarde Gemiddelde nauwkeurigheid. Als deze laag is, moet u meer invoerdocumenten toevoegen en de labelstappen herhalen. De documenten die u al hebt gelabeld, blijven in de projectindex staan.
Tip
U kunt het trainingsproces ook uitvoeren met een REST API-aanroep. Zie Trainen met labels met behulp van Python voor meer informatie over hoe u dit doet.
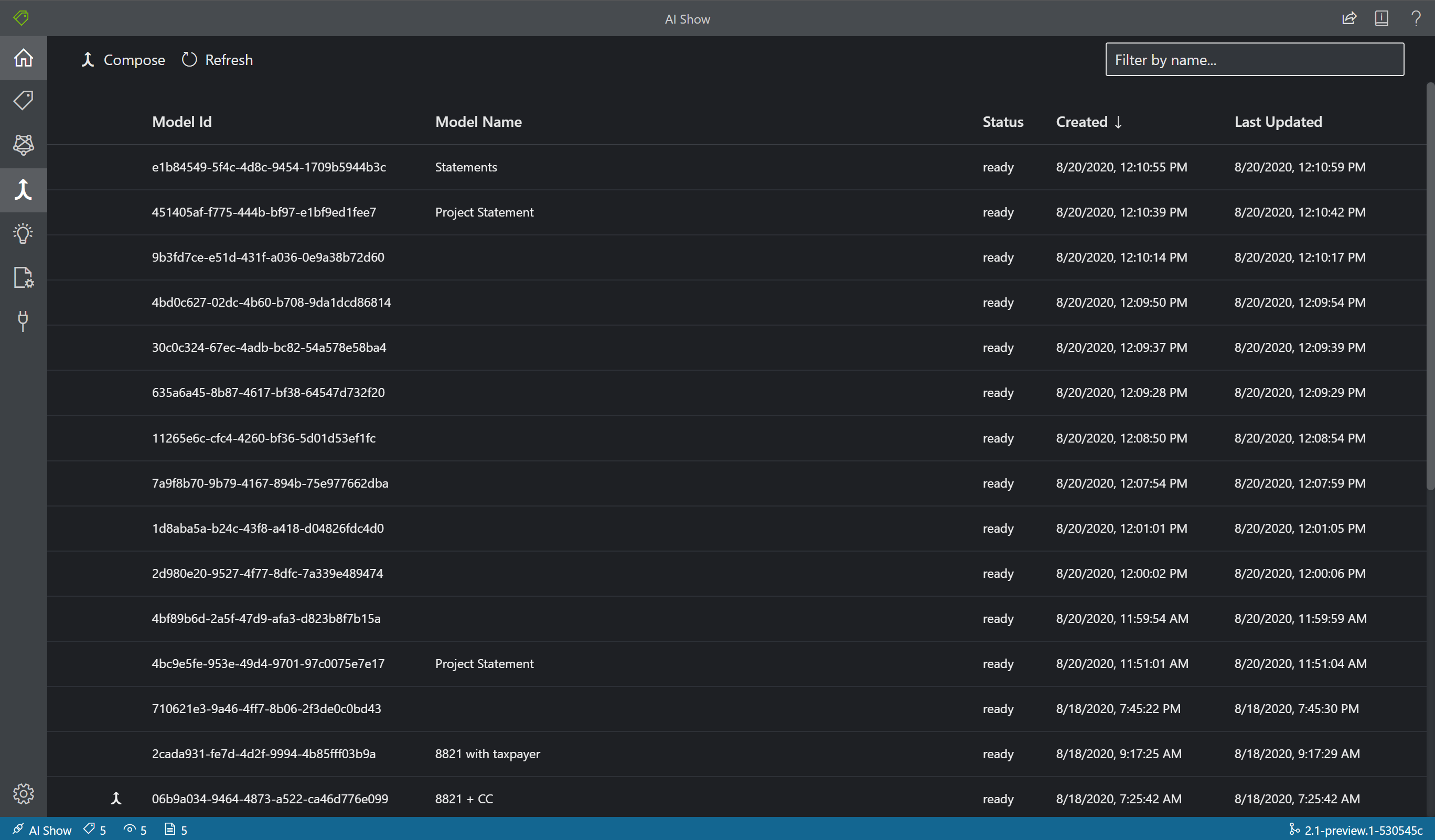
Getrainde modellen samenstellen
Met Model opstellen kunt u maximaal 200 modellen samenstellen tot één model-id. Wanneer u Analyseren aanroept met het samengestelde modelID, classificeert Document Intelligence het formulier dat u hebt verzonden, kiest u het beste overeenkomende model en retourneert u vervolgens resultaten voor dat model. Deze bewerking is handig wanneer binnenkomende formulieren tot een van de verschillende sjablonen kunnen behoren.
- Als u modellen wilt opstellen in het hulpmiddel Voorbeeldlabels, selecteert u het pictogram Model opstellen (pijl samenvoegen) in de navigatiebalk.
- Selecteer de modellen die u samen wilt opstellen. Modellen met het pijlenpictogram zijn al samengesteld.
- Kies de knop Opstellen. Geef in het pop-upvenster uw nieuwe samengestelde model een naam en selecteer Opstellen.
- Wanneer de bewerking is voltooid, wordt het zojuist samengestelde model weergegeven in de lijst.
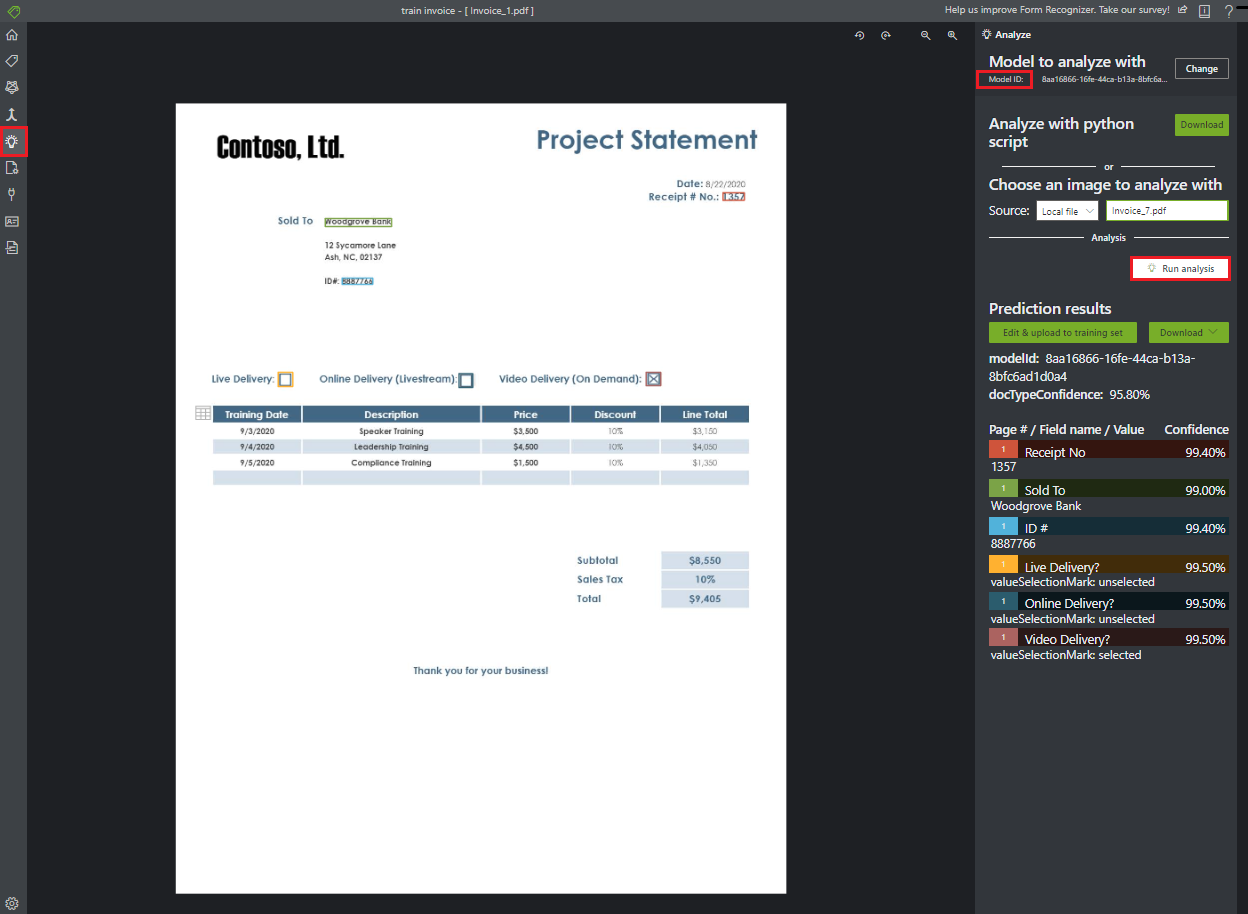
Een formulier analyseren
Selecteer het pictogram Analyseren op de navigatiebalk om uw model te testen. Selecteer het lokale bronbestand. Blader naar een bestand en selecteer een bestand in de voorbeeldgegevensset die u in de testmap hebt uitgepakt. Kies vervolgens de knop Analyse uitvoeren om sleutel-/waardeparen, tekst- en tabellenvoorspellingen voor het formulier op te halen. Het hulpprogramma past tags toe in begrenzingsvakken en rapporteert het vertrouwen van elke tag.
Tip
U kunt de analyse-API ook met een REST-aanroep uitvoeren. Zie Trainen met labels met behulp van Python voor meer informatie over hoe u dit doet.
Resultaten verbeteren
Afhankelijk van de gerapporteerde nauwkeurigheid kunt u meer trainingen uitvoeren om het model te verbeteren. Nadat u een voorspelling hebt uitgevoerd, kunt u de betrouwbaarheidswaarden voor elk toegepast label bekijken. Als de gemiddelde nauwkeurigheidstrainingswaarde hoog is, maar de betrouwbaarheidsscores laag zijn (of de resultaten onjuist zijn), voegt u het voorspellingsbestand toe aan de trainingsset, labelt u het en traint u het opnieuw.
De gerapporteerde gemiddelde nauwkeurigheid, betrouwbaarheidsscores en werkelijke nauwkeurigheid kunnen inconsistent zijn wanneer de geanalyseerde documenten verschillen van documenten die in de training worden gebruikt. Vergeet niet dat sommige documenten er voor een persoon hetzelfde uit kunnen zien maar voor een AI-model kunnen verschillen. Stel u traint met een formuliertype dat twee variaties kent, terwijl de trainingsset uit 20% van variatie A en 80% van variatie B bestaat. Tijdens de voorspelling zijn de betrouwbaarheidsscores voor documenten van variatie A hoogstwaarschijnlijk lager.
Een project opslaan en later hervatten
Als u het project op een ander tijdstip of in een andere browser wilt hervatten, moet u het beveiligingstoken van het project opslaan en later opnieuw invoeren.
Projectreferenties ophalen
Ga naar de pagina met projectinstellingen (schuifregelaar) en noteer de naam van het beveiligingstoken. Ga vervolgens naar uw toepassingsinstellingen (tandwielpictogram), waarin alle beveiligingstokens in uw huidige browserexemplaar worden weergegeven. Zoek het beveiligingstoken van uw project en kopieer de naam en sleutelwaarde naar een veilige locatie.
Projectreferenties herstellen
Als u uw project wilt hervatten, moet u eerst een verbinding maken met dezelfde Blob Storage-container. Herhaal de stappen om dit te doen. Ga vervolgens naar de pagina met toepassingsinstellingen (tandwielpictogram) en kijk of het beveiligingstoken van uw project aanwezig is. Als dat niet het geval is, voegt u een nieuw beveiligingstoken toe en kopieert u de naam en de sleutel van het token uit de vorige stap. Selecteer Opslaan om uw instellingen te behouden.
Een project hervatten
Ga ten slotte naar de hoofdpagina (huispictogram) en selecteer Cloudproject openen. Selecteer vervolgens de blob-opslagverbinding en selecteer het bestand van .fott uw project. De toepassing laadt alle instellingen van het project omdat deze het beveiligingstoken heeft.
Volgende stappen
In deze quickstart hebt u geleerd hoe u het hulpprogramma Document Intelligence Sample Labeling kunt gebruiken om een model te trainen met handmatig gelabelde gegevens. Als u uw eigen hulpprogramma wilt bouwen voor het labelen van trainingsgegevens, gebruikt u de REST API's die het trainen met gelabelde gegevens verwerken.