Antipatroon Front-end bezet
Het uitvoeren van asynchroon werk aan een groot aantal achtergrond-threads kan tot gevolg hebben dat er onvoldoende CPU-tijd resteert voor andere gelijktijdige taken of resources, waardoor de reactietijden onaanvaardbaar laag worden.
Beschrijving van het probleem
Resource-intensieve taken kunnen de reactietijd voor aanvragen van gebruikers verlengen en zo hoge latentie veroorzaken. Een manier om de reactietijden te verbeteren, is door een resource-intensieve taak te offloaden naar een afzonderlijke thread. Met deze benadering kan de toepassing responsief blijven tijdens verwerking op de achtergrond. Taken die in een achtergrond-thread worden uitgevoerd, verbruiken echter nog steeds resources. Als er te veel van deze taken zijn, kan dit tot gevolg hebben dat er onvoldoende CPU-tijd resteert voor threads die aanvragen afhandelen.
Notitie
De term resource is veelomvattend en kan verwijzen naar CPU-gebruik, geheugenbezetting, en netwerk- of schijf-I/O.
Dit probleem treedt meestal op wanneer een toepassing is ontwikkeld als een monolithisch stuk code, met alle bedrijfslogica gecombineerd in één laag die wordt gedeeld met de presentatielaag.
Hier is een voorbeeld met ASP.NET waarin het probleem duidelijk wordt. U vindt het complete voorbeeld hier.
public class WorkInFrontEndController : ApiController
{
[HttpPost]
[Route("api/workinfrontend")]
public HttpResponseMessage Post()
{
new Thread(() =>
{
//Simulate processing
Thread.SpinWait(Int32.MaxValue / 100);
}).Start();
return Request.CreateResponse(HttpStatusCode.Accepted);
}
}
public class UserProfileController : ApiController
{
[HttpGet]
[Route("api/userprofile/{id}")]
public UserProfile Get(int id)
{
//Simulate processing
return new UserProfile() { FirstName = "Alton", LastName = "Hudgens" };
}
}
De methode
Postin de controllerWorkInFrontEndimplementeert een HTTP POST-bewerking. Deze bewerking simuleert een langlopende, CPU-intensieve taak. Het werk wordt uitgevoerd in een afzonderlijke thread, in een poging om de POST-bewerking snel te kunnen voltooien.De methode
Getin de controllerUserProfileimplementeert een HTTP GET-bewerking. Deze methode is veel minder CPU-intensief.
De resourcevereisten van de methode Post vormen het grootste probleem. Hoewel het werk in een achtergrond-thread wordt geplaatst, kan het werk nog steeds erg veel CPU-resources verbruiken. Deze resources worden gedeeld met andere bewerkingen die worden uitgevoerd door andere gelijktijdige gebruikers. Als een gemiddeld aantal gebruikers deze aanvraag op hetzelfde moment verzendt, zullen de algehele prestaties waarschijnlijk afnemen, waardoor alle bewerkingen worden vertraagd. Gebruikers kunnen bijvoorbeeld aanzienlijke latentie ondervinden in de methode Get.
Het probleem oplossen
Verplaats processen die veel resources verbruiken naar een afzonderlijke back-end.
Met deze aanpak worden resource-intensieve taken door de front-end in een berichtenwachtrij geplaatst. De taken worden vervolgens door de back-end overgenomen voor asynchrone verwerking. De wachtrij fungeert ook als een load-leveler, door aanvragen te bufferen voor de back-end. Als de wachtrij te lang wordt, kunt u automatisch schalen configureren om de back-end uit te schalen.
Hier ziet u een aangepaste versie van de vorige code. In deze versie wordt door de methode Post een bericht in een Service Bus-wachtrij gezet.
public class WorkInBackgroundController : ApiController
{
private static readonly QueueClient QueueClient;
private static readonly string QueueName;
private static readonly ServiceBusQueueHandler ServiceBusQueueHandler;
public WorkInBackgroundController()
{
var serviceBusConnectionString = ...;
QueueName = ...;
ServiceBusQueueHandler = new ServiceBusQueueHandler(serviceBusConnectionString);
QueueClient = ServiceBusQueueHandler.GetQueueClientAsync(QueueName).Result;
}
[HttpPost]
[Route("api/workinbackground")]
public async Task<long> Post()
{
return await ServiceBusQueueHandler.AddWorkLoadToQueueAsync(QueueClient, QueueName, 0);
}
}
De back-end haalt berichten op uit de Service Bus-wachtrij en voert de verwerking uit.
public async Task RunAsync(CancellationToken cancellationToken)
{
this._queueClient.OnMessageAsync(
// This lambda is invoked for each message received.
async (receivedMessage) =>
{
try
{
// Simulate processing of message
Thread.SpinWait(Int32.MaxValue / 1000);
await receivedMessage.CompleteAsync();
}
catch
{
receivedMessage.Abandon();
}
});
}
Overwegingen
- Met deze benadering wordt wel wat complexiteit toegevoegd aan de toepassing. Zo moeten berichten veilig in de wachtrij worden geplaatst en eruit worden verwijderd om te voorkomen dat aanvragen in het geval van een storing verloren gaan.
- De toepassing wordt afhankelijk van een extra service voor de berichtenwachtrij.
- De verwerkingsomgeving moet voldoende schaalbaar zijn om de verwachte werkbelasting te kunnen verwerken en te voldoen aan de vereiste doorvoersnelheden.
- Hoewel met deze aanpak de algehele prestaties zullen verbeteren, kan het langer duren om de taken te verwerken die naar de back-end worden verplaatst.
Het probleem vaststellen
Een hoge latentie bij de uitvoering van resource-intensieve taken kan wijzen op een bezette front-end. Eindgebruikers melden waarschijnlijk uitgebreide reactietijden of fouten die worden veroorzaakt door time-outs van services. Deze fouten kunnen ook HTTP 500-fouten (interne server) of HTTP 503-fouten (service niet beschikbaar) retourneren. Raadpleeg de gebeurtenislogboeken van de webserver, die waarschijnlijk meer gedetailleerde informatie over de oorzaken en omstandigheden van de fouten bevatten.
U kunt de volgende stappen uitvoeren om dit probleem te identificeren:
- Monitor de processen van het productiesysteem om vast te stellen wanneer de respons langer duurt.
- Bekijk de telemetriegegevens voor deze momenten om te bepalen welke combinatie van bewerkingen wordt uitgevoerd en welke resources hiervoor worden gebruikt.
- Relateer de slechte responstijden aan de volumes en combinaties van bewerkingen die op die momenten plaatsvinden.
- Voer voor elke verdachte bewerking een belastingstest uit om vast te stellen welke bewerkingen resources verbruiken waardoor voor andere bewerkingen onvoldoende CPU-tijd resteert.
- Bekijk de broncode voor deze bewerkingen om te bepalen waarom ze tot overmatig resourceverbruik leiden.
Voorbeeld van diagnose
In de volgende secties worden deze stappen toegepast op de voorbeeldtoepassing die eerder is beschreven.
Punten van vertraging identificeren
Instrumenteer elke methode om voor elke aanvraag de duur en verbruikte resources te bepalen. Monitor de toepassing vervolgens terwijl deze in productie is. Hiermee kunt u een algemeen beeld krijgen van de manier waarop aanvragen met elkaar concurreren. Tijdens perioden van hoge belasting zullen traag uitgevoerde, resource-intensieve aanvragen waarschijnlijk invloed hebben op andere bewerkingen. Dit kunt u vaststellen door het systeem te monitoren en de momenten van prestatievermindering te noteren.
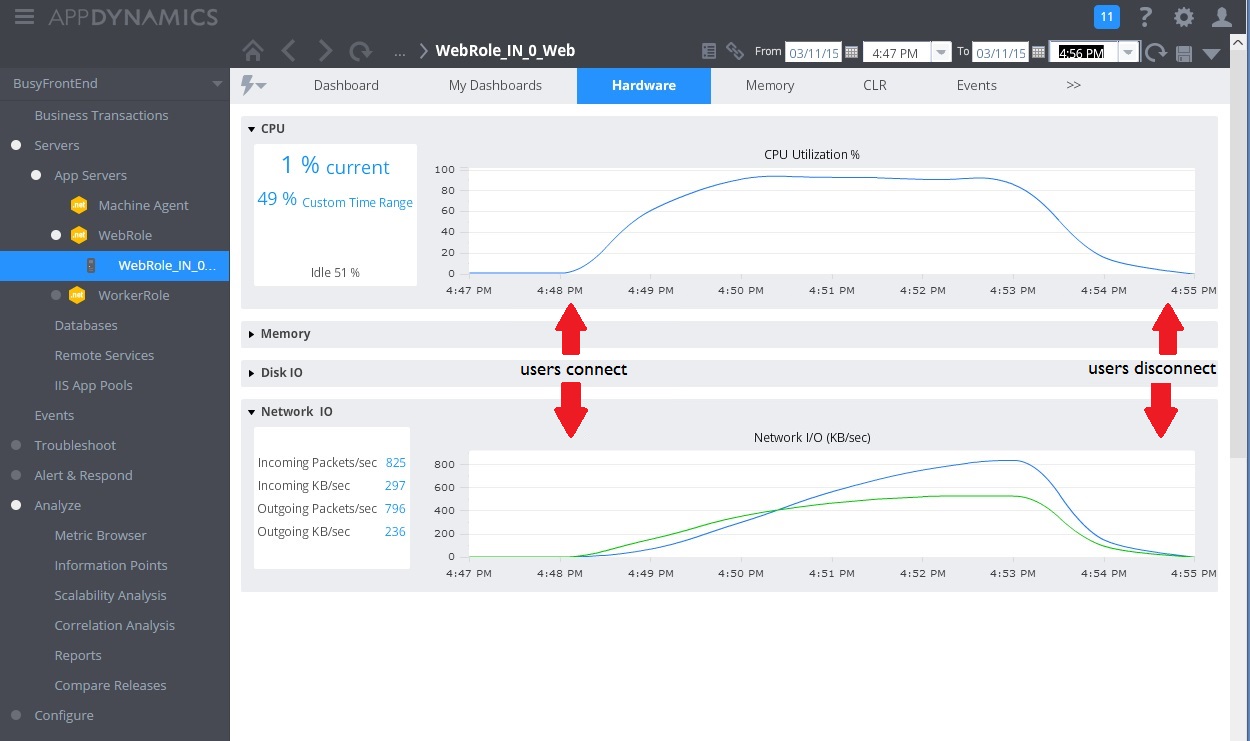
In de volgende afbeelding ziet u een dashboard voor monitoring. (We gebruikten AppDynamics voor onze tests.) In eerste instantie heeft het systeem lichte belasting. Vervolgens beginnen gebruikers de GET-methode UserProfile aan te vragen. De prestaties zijn redelijk goed totdat andere gebruikers aanvragen gaan versturen voor de POST-methode WorkInFrontEnd. Op dat moment worden de responstijden aanzienlijk langer (eerste pijl). De responstijden verbeteren pas weer nadat het aantal aanvragen voor de controller WorkInFrontEnd afneemt (tweede pijl).
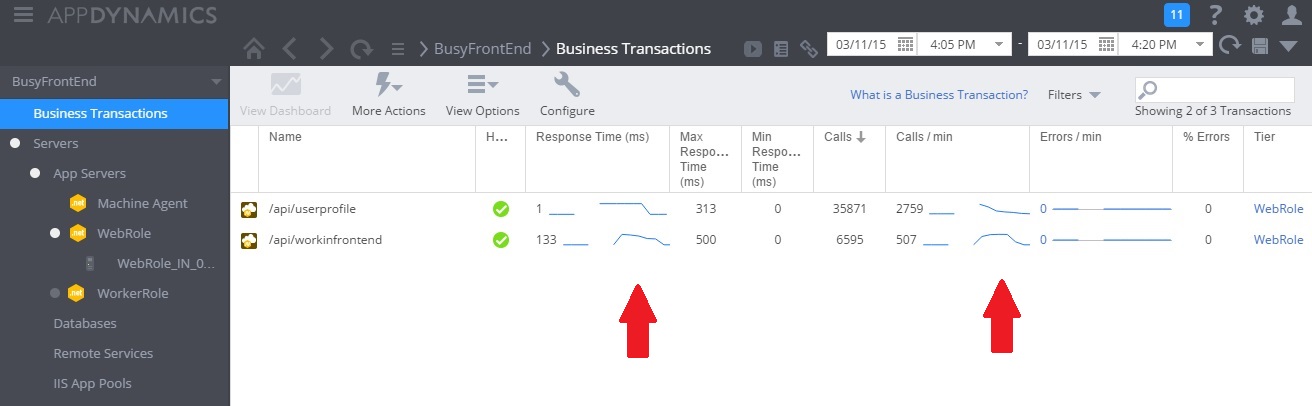
Telemetriegegevens onderzoeken en correlaties vinden
In de volgende afbeelding ziet u enkele van de verzamelde metrische gegevens voor het monitoren van resourcegebruik tijdens hetzelfde interval. In eerste instantie zijn er maar een paar gebruikers in het systeem. Naarmate er meer gebruikers verbinding maken, loopt het CPU-gebruik sterk op (100%). U ziet ook dat de netwerk-I/O eerst evenredig oploopt met het toenemende CPU-gebruik. Als het CPU-gebruik echter een piek heeft bereikt, neemt de netwerk-I/O weer af. Dat komt doordat het systeem slechts een relatief klein aantal aanvragen tegelijk kan verwerken zodra de CPU-capaciteit is bereikt. Op het moment dat gebruikers de verbinding verbreken, neemt de CPU-belasting af.
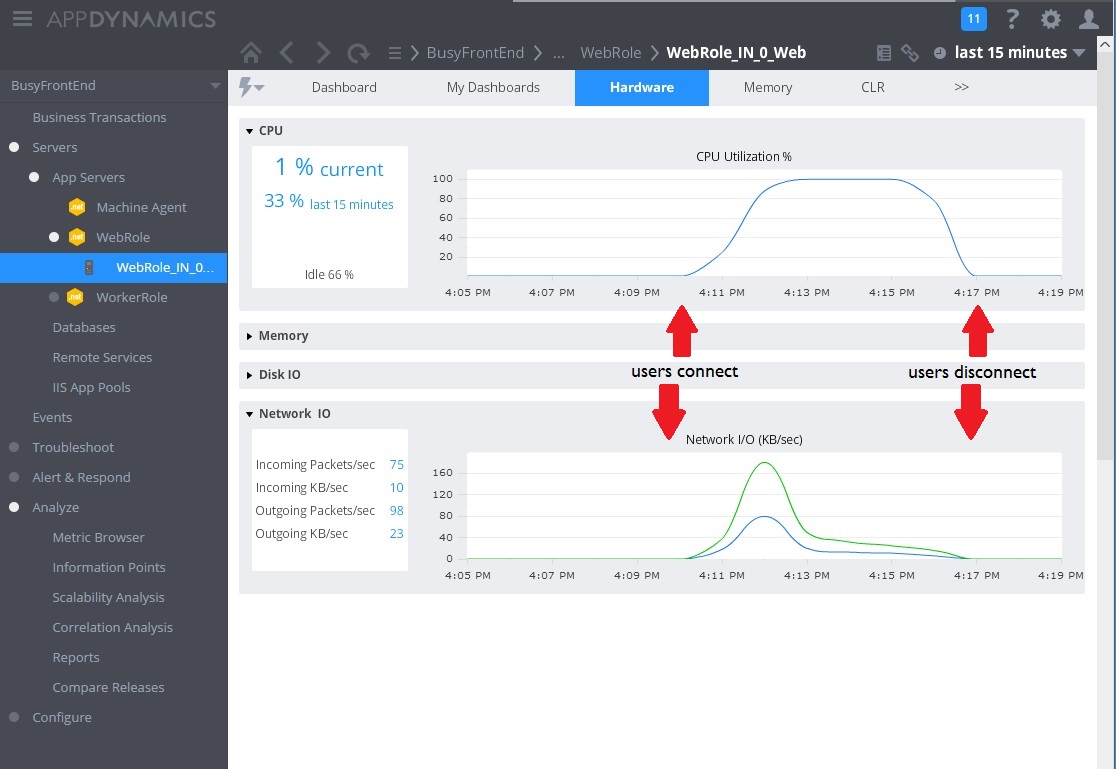
Op dit moment lijkt het alsof de methode Post in de controller WorkInFrontEnd de aangewezen kandidaat is voor nader onderzoek. Aanvullend werk in een testomgeving is nodig om deze hypothese te bevestigen.
Belastingstests uitvoeren
De volgende stap is het uitvoeren van tests in een gecontroleerde omgeving. Voer bijvoorbeeld een reeks belastingstests uit waarbij u steeds een aanvraag weglaat om te kijken wat dat voor effect heeft.
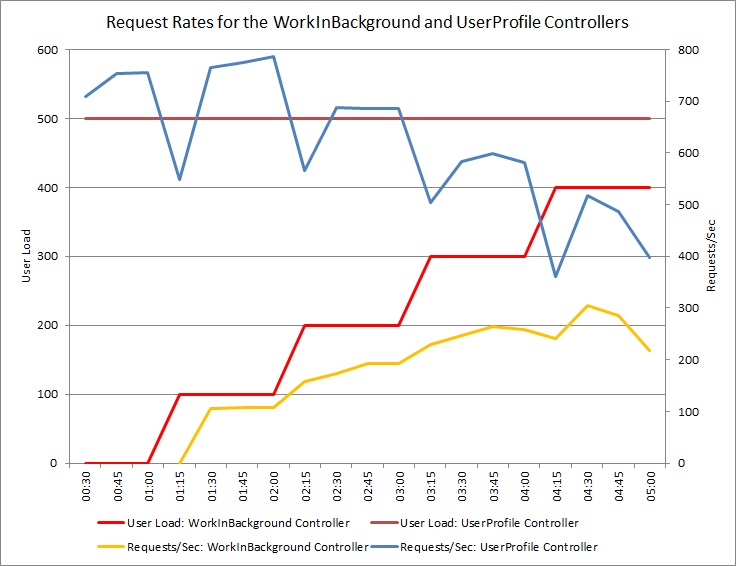
In het diagram hieronder ziet u de resultaten van een belastingstest die is uitgevoerd op een identieke implementatie van de cloudservice uit de eerdere tests. In de test is een constante belasting van 500 gebruikers gebruikt die de bewerking Get uitvoeren in de controller UserProfile, samen met een stapsgewijs toenemende belasting van gebruikers die de bewerking Post uitvoeren in de controller WorkInFrontEnd.
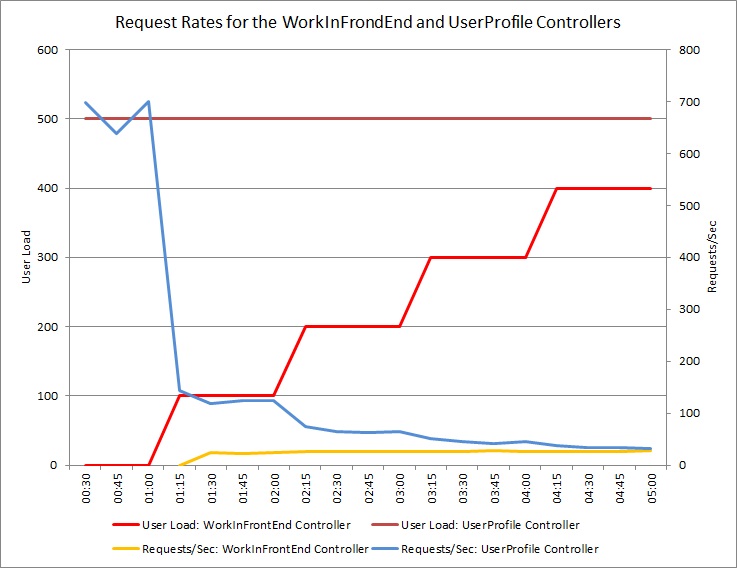
In eerste instantie wordt de belasting niet geleidelijk opgevoerd, wat inhoudt dat alleen actieve gebruikers de UserProfile-aanvragen uitvoeren. Het systeem kan ongeveer 500 aanvragen per seconde verwerken. Na 60 seconden neemt de belasting toe met 100 extra gebruikers die POST-verzoeken gaan versturen naar de controller WorkInFrontEnd. Bijna onmiddellijk zakt de werkbelasting die wordt verzonden naar de controller UserProfile naar ongeveer 150 aanvragen per seconde. Dit komt door de manier waarop de belastingstest wordt uitgevoerd. Er wordt namelijk gewacht op een antwoord voordat de volgende aanvraag wordt verzonden, dus hoe langer het duurt om een antwoord te ontvangen des te lager het aantal verwerkte aanvragen.
Naarmate meer gebruikers POST-verzoeken versturen naar de controller WorkInFrontEnd, wordt de responstijd van de controller UserProfile steeds langer. Houd er echter rekening mee dat het aantal aanvragen dat door de WorkInFrontEnd controller wordt verwerkt, relatief constant blijft. De verzadiging van het systeem wordt duidelijk als de algehele frequentie van beide aanvragen constant op een lage limiet blijft hangen.
De broncode analyseren
Als laatste is het belangrijk om naar de broncode te kijken. Het ontwikkelteam was zich er blijkbaar van bewust dat de methode Post een aanzienlijke hoeveelheid tijd in beslag kan nemen en heeft daarom in de oorspronkelijke implementatie gekozen voor een afzonderlijke thread. Hiermee was het directe probleem opgelost, omdat de methode Post niet werd geblokkeerd in afwachting van het voltooien van een langlopende taak.
Het werk dat echter door deze methode wordt uitgevoerd, verbruikt nog steeds CPU, geheugen en andere resources. De keuze om dit proces asynchroon te laten uitvoeren, kan in de praktijk nadelig zijn voor de prestaties, aangezien gebruikers een groot aantal van deze bewerkingen tegelijk kunnen triggeren, op een niet-gecontroleerde manier. Er is een limiet aan het aantal threads dat een server kan uitvoeren. Als deze limiet is bereikt, zal in de toepassing waarschijnlijk een uitzondering optreden op het moment dat er wordt geprobeerd een nieuwe thread te starten.
Notitie
Dit betekent niet dat asynchrone bewerkingen altijd moeten worden vermeden. Zo is een asynchrone await op een netwerkaanroep bijvoorbeeld de aanbevolen procedure. (Zie de Synchrone I/O-antipatroon .) Het probleem hier is dat CPU-intensief werk is voortgekomen op een andere thread.
De oplossing implementeren en het resultaat controleren
In de volgende afbeelding ziet u prestatiegegevens nadat de oplossing is geïmplementeerd. De belasting is vergelijkbaar met die hierboven, maar de responstijden voor de controller UserProfile zijn nu veel beter. Het aantal aanvragen is over dezelfde periode gestegen van 2.759 naar 23.565.
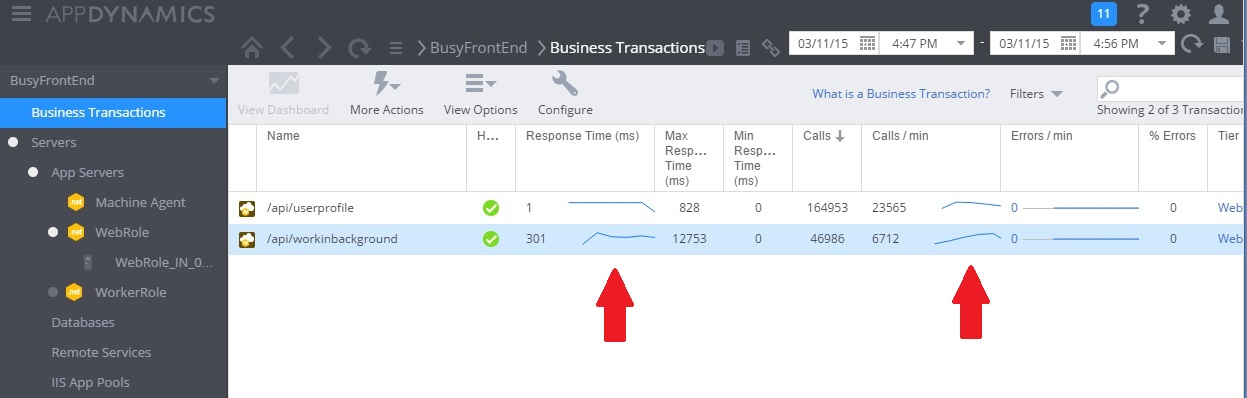
U ziet dat de controller WorkInBackground ook veel meer aanvragen heeft verwerkt. In dit geval kan echter geen directe vergelijking worden gemaakt omdat het werk dat wordt uitgevoerd in deze controller heel anders is dan in de oorspronkelijke code. In de nieuwe versie wordt alleen een aanvraag in de wachtrij gezet en wordt geen tijdrovende berekening uitgevoerd. Het belangrijkste is punt is dat bij deze methode niet meer het hele systeem slechter gaat presteren als de belasting toeneemt.
De waarden voor het CPU- en netwerkgebruik laten ook de verbeterde prestaties zien. Het CPU-gebruik heeft nooit 100% bereikt en het aantal verwerkte netwerkaanvragen is veel groter dan eerder en werd pas lager op het moment dat de werkbelasting ging zakken.
In het volgende diagram ziet u de resultaten van een belastingstest. Het totale aantal verwerkte aanvragen is aanzienlijk verbeterd in vergelijking met eerdere tests.
Verwante informatie
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor