Richtlijnen voor caching
Caching (in de cache opslaan van gegevens) is een veelvoorkomende techniek die als doel heeft de prestaties en schaalbaarheid van een systeem te verbeteren. Hiermee worden gegevens in de cache opgeslagen door tijdelijk veelgebruikte gegevens te kopiëren naar snelle opslag die zich dicht bij de toepassing bevindt. Als deze snelle gegevensopslag zich dichter bij de toepassing bevindt dan de oorspronkelijke bron, dan kan caching de reactietijden voor clienttoepassingen significant verbeteren doordat er meer gegevens kunnen worden verwerkt.
Caching is het meest effectief wanneer een clientexemplaren herhaaldelijk dezelfde gegevens lezen, met name als alle volgende voorwaarden van toepassing zijn op het oorspronkelijke gegevensarchief:
- Het blijft relatief statisch.
- De gegevensopslag is traag vergeleken met de snelheid van de cache.
- De gegevensopslag is onderhevig aan een hoog conflictenniveau.
- Het is ver weg wanneer netwerklatentie ertoe kan leiden dat de toegang traag is.
Caching in gedistribueerde toepassingen
Gedistribueerde toepassingen implementeren doorgaans een of beide van de volgende strategieën bij het opslaan van gegevens in de cache:
- Ze gebruiken een privécache, waarbij gegevens lokaal worden bewaard op de computer waarop een exemplaar van een toepassing of service wordt uitgevoerd.
- Ze gebruiken een gedeelde cache, die fungeert als een gemeenschappelijke bron die toegankelijk is voor meerdere processen en machines.
In beide gevallen kan caching worden uitgevoerd aan de clientzijde en aan de serverzijde. Caching aan de clientzijde wordt uitgevoerd door het proces dat de gebruikersinterface voor een systeem biedt, zoals een webbrowser of bureaubladtoepassing. Caching aan de serverzijde wordt uitgevoerd door het proces dat de zakelijke services levert die extern worden uitgevoerd.
Privécaching
Het meest eenvoudige type cache is een in-memory archief. Deze bevindt zich in de adresruimte van één proces en wordt rechtstreeks geopend door de code die in dat proces wordt uitgevoerd. Dit type cache is snel toegankelijk. Het kan ook een effectieve manier bieden voor het opslaan van bescheiden hoeveelheden statische gegevens. De grootte van een cache wordt doorgaans beperkt door de hoeveelheid geheugen die beschikbaar is op de computer waarop het proces wordt gehost.
Als u meer informatie in de cache wilt opslaan dan fysiek mogelijk is in het geheugen, kunt u gegevens in de cache naar het lokale bestandssysteem schrijven. Dit proces verloopt langzamer dan gegevens die in het geheugen zijn opgeslagen, maar het moet nog steeds sneller en betrouwbaarder zijn dan het ophalen van gegevens in een netwerk.
Als u meerdere exemplaren van een toepassing hebt die dit model gelijktijdig gebruikt, heeft elk toepassingsexemplaar een eigen onafhankelijke cache met een eigen kopie van de gegevens.
U kunt een cache beschouwen als een momentopname van de oorspronkelijke gegevens op een bepaald moment in het verleden. Als deze gegevens niet statisch zijn, is het waarschijnlijk dat verschillende toepassingsexemplaren verschillende versies van de gegevens in hun cache bevatten. Daarom kan dezelfde query die door deze exemplaren wordt uitgevoerd, verschillende resultaten retourneren, zoals wordt weergegeven in afbeelding 1.
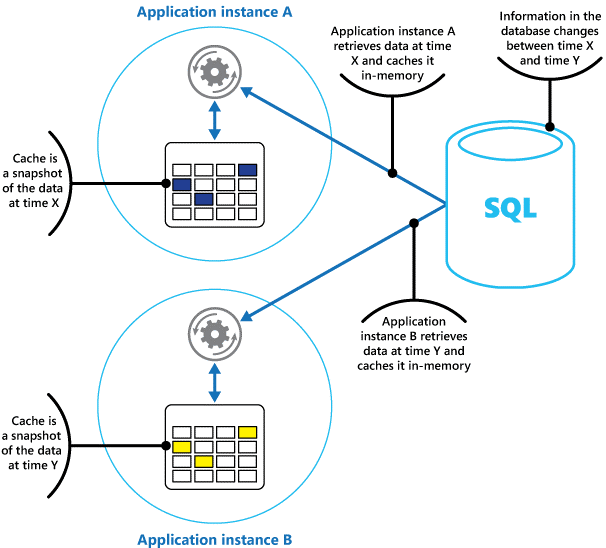
Afbeelding 1: Een cache in het geheugen gebruiken in verschillende exemplaren van een toepassing.
Gedeelde caching
Als u een gedeelde cache gebruikt, kan dit helpen bij het verlichten van problemen die gegevens in elke cache kunnen verschillen, wat kan gebeuren met cacheopslag in het geheugen. Gedeelde caching zorgt ervoor dat verschillende toepassingsexemplaren dezelfde weergave van gegevens in de cache zien. De cache wordt op een afzonderlijke locatie gevonden, die doorgaans wordt gehost als onderdeel van een afzonderlijke service, zoals wordt weergegeven in afbeelding 2.
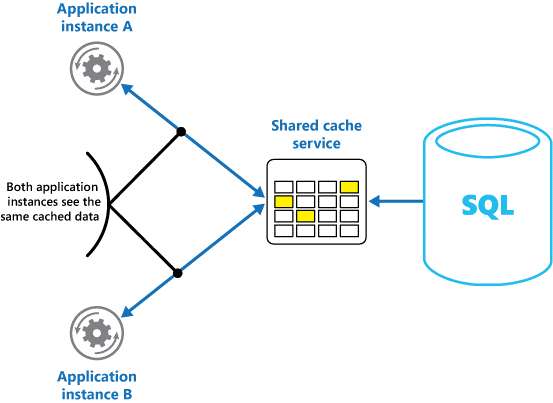
Afbeelding 2: Een gedeelde cache gebruiken.
Een belangrijk voordeel van de benadering voor gedeelde caching is de schaalbaarheid die het biedt. Veel gedeelde cacheservices worden geïmplementeerd met behulp van een cluster servers en software gebruiken om de gegevens transparant over het cluster te verdelen. Een toepassingsexemplaren verzenden gewoon een aanvraag naar de cacheservice. De onderliggende infrastructuur bepaalt de locatie van de gegevens in de cache in het cluster. U kunt de cache eenvoudig schalen door meer servers toe te voegen.
Er zijn twee belangrijkste nadelen van de benadering voor gedeelde caching:
- De cache is langzamer voor toegang omdat deze niet langer lokaal wordt bewaard voor elk toepassingsexemplaren.
- De vereiste voor het implementeren van een afzonderlijke cacheservice kan complexiteit aan de oplossing toevoegen.
Overwegingen voor het gebruik van caching
In de volgende secties worden de overwegingen voor het ontwerpen en gebruiken van een cache gedetailleerder beschreven.
Bepalen wanneer gegevens in de cache moeten worden opgeslagen
Caching kan de prestaties, schaalbaarheid en beschikbaarheid aanzienlijk verbeteren. Hoe meer gegevens u hebt en hoe groter het aantal gebruikers dat toegang nodig heeft tot deze gegevens, hoe groter de voordelen van caching worden. Caching vermindert de latentie en conflicten die zijn gekoppeld aan het verwerken van grote hoeveelheden gelijktijdige aanvragen in het oorspronkelijke gegevensarchief.
Een database kan bijvoorbeeld een beperkt aantal gelijktijdige verbindingen ondersteunen. Door gegevens op te halen uit een gedeelde cache, in plaats van de onderliggende database, kan een clienttoepassing toegang krijgen tot deze gegevens, zelfs als het aantal beschikbare verbindingen momenteel uitgeput is. Als de database niet beschikbaar is, kunnen clienttoepassingen bovendien mogelijk doorgaan met behulp van de gegevens die in de cache zijn opgeslagen.
Overweeg om gegevens die regelmatig worden gelezen, maar regelmatig worden gewijzigd (bijvoorbeeld gegevens met een hoger deel van leesbewerkingen dan schrijfbewerkingen). We raden u echter niet aan om de cache te gebruiken als gezaghebbende opslag van kritieke informatie. Zorg er in plaats daarvan voor dat alle wijzigingen die uw toepassing zich niet kan veroorloven, altijd worden opgeslagen in een permanent gegevensarchief. Als de cache niet beschikbaar is, kan uw toepassing nog steeds blijven werken met behulp van het gegevensarchief en verliest u geen belangrijke informatie.
Bepalen hoe gegevens effectief worden opgeslagen in de cache
De sleutel voor het effectief gebruiken van een cache ligt bij het bepalen van de meest geschikte gegevens voor cache en het opslaan ervan op het juiste moment. De gegevens kunnen op aanvraag worden toegevoegd aan de cache wanneer deze voor het eerst worden opgehaald door een toepassing. De toepassing moet de gegevens slechts eenmaal ophalen uit het gegevensarchief en dat er aan de volgende toegang kan worden voldaan met behulp van de cache.
Een cache kan ook vooraf gedeeltelijk of volledig worden gevuld met gegevens, meestal wanneer de toepassing wordt gestart (een benadering die seeding wordt genoemd). Het is echter mogelijk niet raadzaam om seeding voor een grote cache te implementeren, omdat deze benadering plotselinge, hoge belasting kan opleggen aan het oorspronkelijke gegevensarchief wanneer de toepassing wordt uitgevoerd.
Vaak kan een analyse van gebruikspatronen u helpen om te bepalen of u een cache volledig of gedeeltelijk wilt invullen en om de gegevens te kiezen die moeten worden opgeslagen in de cache. U kunt de cache bijvoorbeeld seeden met de statische gebruikersprofielgegevens voor klanten die de toepassing regelmatig gebruiken (misschien elke dag), maar niet voor klanten die de toepassing slechts één keer per week gebruiken.
Caching werkt doorgaans goed met gegevens die onveranderbaar zijn of die niet vaak worden gewijzigd. Voorbeelden hiervan zijn referentie-informatie, zoals product- en prijsinformatie in een e-commercetoepassing, of gedeelde statische resources die kostbaar zijn om te bouwen. Sommige of al deze gegevens kunnen tijdens het opstarten van de toepassing in de cache worden geladen om de vraag op resources te minimaliseren en de prestaties te verbeteren. Mogelijk wilt u ook een achtergrondproces hebben waarmee de referentiegegevens in de cache periodiek worden bijgewerkt om ervoor te zorgen dat deze up-to-datum is. Of het achtergrondproces kan de cache vernieuwen wanneer de verwijzingsgegevens worden gewijzigd.
Caching is minder handig voor dynamische gegevens, hoewel er enkele uitzonderingen zijn op deze overweging (zie de sectie Cache zeer dynamische gegevens verderop in dit artikel voor meer informatie). Wanneer de oorspronkelijke gegevens regelmatig worden gewijzigd, wordt de informatie in de cache snel verlopen of vermindert de overhead van het synchroniseren van de cache met het oorspronkelijke gegevensarchief de effectiviteit van caching.
Een cache hoeft de volledige gegevens voor een entiteit niet op te nemen. Als een gegevensitem bijvoorbeeld een object met meerdere waarden vertegenwoordigt, zoals een bankklant met een naam, adres en rekeningsaldo, kunnen sommige van deze elementen statisch blijven, zoals de naam en het adres. Andere elementen, zoals het rekeningsaldo, zijn mogelijk dynamischer. In deze situaties kan het handig zijn om de statische delen van de gegevens in de cache op te plaatsen en alleen de resterende gegevens op te halen (of te berekenen) wanneer deze nodig zijn.
Het is raadzaam om prestatietests en gebruiksanalyses uit te voeren om te bepalen of het vooraf invullen of laden van de cache op aanvraag, of een combinatie van beide, geschikt is. De beslissing moet zijn gebaseerd op de volatiliteit en het gebruikspatroon van de gegevens. Cachegebruik en prestatieanalyse zijn belangrijk in toepassingen die zware belastingen tegenkomen en zeer schaalbaar moeten zijn. In zeer schaalbare scenario's kunt u de cache bijvoorbeeld seeden om de belasting van het gegevensarchief op piekmomenten te verminderen.
Caching kan ook worden gebruikt om herhalende berekeningen te voorkomen terwijl de toepassing wordt uitgevoerd. Als een bewerking gegevens transformeert of een ingewikkelde berekening uitvoert, kunnen de resultaten van de bewerking in de cache worden opgeslagen. Als dezelfde berekening later is vereist, kan de toepassing gewoon de resultaten uit de cache ophalen.
Een toepassing kan gegevens wijzigen die in een cache zijn opgeslagen. We raden u echter aan om de cache te zien als een tijdelijk gegevensarchief dat op elk gewenst moment kan verdwijnen. Sla geen waardevolle gegevens alleen op in de cache; zorg ervoor dat u ook de informatie in het oorspronkelijke gegevensarchief onderhoudt. Dit betekent dat als de cache niet beschikbaar is, u de kans op gegevensverlies minimaliseert.
Zeer dynamische gegevens in cache opslaan
Wanneer u snel veranderende informatie opslaat in een permanent gegevensarchief, kan dit een overhead voor het systeem betekenen. Denk bijvoorbeeld aan een apparaat dat voortdurend de status of een andere meting rapporteert. Als een toepassing ervoor kiest om deze gegevens niet in de cache op te slaan op basis dat de gegevens in de cache bijna altijd verouderd zijn, kan dezelfde overweging waar zijn bij het opslaan en ophalen van deze gegevens uit het gegevensarchief. In de tijd die nodig is om deze gegevens op te slaan en op te halen, zijn deze mogelijk gewijzigd.
In een dergelijke situatie kunt u rekening houden met de voordelen van het rechtstreeks opslaan van de dynamische informatie in de cache in plaats van in het permanente gegevensarchief. Als de gegevens niet kritiek zijn en geen controle vereist, maakt het niet uit of de incidentele wijziging verloren gaat.
Verloop van gegevens in een cache beheren
In de meeste gevallen zijn gegevens die in een cache zijn opgeslagen een kopie van gegevens die in het oorspronkelijke gegevensarchief zijn opgeslagen. De gegevens in het oorspronkelijke gegevensarchief kunnen veranderen nadat deze in de cache zijn opgeslagen, waardoor de gegevens in de cache verlopen. Met veel cachesystemen kunt u de cache zo configureren dat gegevens verlopen en de periode verkorten waarvoor gegevens mogelijk verouderd zijn.
Wanneer de gegevens in de cache verlopen, worden deze verwijderd uit de cache en moet de toepassing de gegevens ophalen uit het oorspronkelijke gegevensarchief (de zojuist opgehaalde gegevens kunnen weer in de cache worden geplaatst). U kunt een standaardverloopbeleid instellen wanneer u de cache configureert. In veel cacheservices kunt u ook de verloopperiode voor afzonderlijke objecten instellen wanneer u ze programmatisch opslaat in de cache. Met sommige caches kunt u de verloopperiode opgeven als een absolute waarde of als een schuifwaarde die ervoor zorgt dat het item uit de cache wordt verwijderd als het niet binnen de opgegeven tijd wordt geopend. Met deze instelling wordt een verloopbeleid voor de hele cache overschreven, maar alleen voor de opgegeven objecten.
Opmerking
Houd rekening met de verloopperiode voor de cache en de objecten die deze zorgvuldig bevat. Als u deze te kort maakt, verlopen objecten te snel en vermindert u de voordelen van het gebruik van de cache. Als u de periode te lang maakt, loopt u het risico dat de gegevens verlopen.
Het is ook mogelijk dat de cache vol raakt als gegevens gedurende lange tijd blijven wonen. In dit geval kunnen aanvragen voor het toevoegen van nieuwe items aan de cache ertoe leiden dat sommige items geforceerd worden verwijderd in een proces dat ook wel verwijdering wordt genoemd. Cacheservices verwijderen doorgaans gegevens op basis van minst recent gebruikte (LRU), maar u kunt dit beleid meestal overschrijven en voorkomen dat items worden verwijderd. Als u deze benadering echter gebruikt, loopt u het risico dat u het geheugen overschrijdt dat beschikbaar is in de cache. Een toepassing die probeert een item aan de cache toe te voegen, mislukt met een uitzondering.
Sommige caching-implementaties bieden mogelijk extra verwijderingsbeleid. Er zijn verschillende soorten verwijderingsbeleidsregels. Deze omvatten:
- Een meest recent gebruikt beleid (in de verwachting dat de gegevens niet opnieuw vereist zijn).
- Een first-in-first-out beleid (oudste gegevens worden eerst verwijderd).
- Een expliciet verwijderingsbeleid op basis van een geactiveerde gebeurtenis (zoals de gegevens die worden gewijzigd).
Gegevens in een cache aan de clientzijde ongeldig maken
Gegevens die in een cache aan de clientzijde worden bewaard, worden over het algemeen beschouwd als buiten het bereik van de service die de gegevens aan de client levert. Een service kan een client niet rechtstreeks dwingen om gegevens toe te voegen aan of te verwijderen uit een cache aan de clientzijde.
Dit betekent dat het mogelijk is voor een client die gebruikmaakt van een slecht geconfigureerde cache om verouderde informatie te blijven gebruiken. Als het verloopbeleid van de cache bijvoorbeeld niet correct wordt geïmplementeerd, kan een client verouderde gegevens gebruiken die lokaal in de cache worden opgeslagen wanneer de informatie in de oorspronkelijke gegevensbron is gewijzigd.
Als u een webtoepassing bouwt die gegevens via een HTTP-verbinding bedient, kunt u impliciet afdwingen dat een webclient (zoals een browser of webproxy) de meest recente informatie ophaalt. U kunt dit doen als een resource wordt bijgewerkt door een wijziging in de URI van die resource. Webclients gebruiken doorgaans de URI van een resource als de sleutel in de cache aan de clientzijde, dus als de URI wordt gewijzigd, negeert de webclient eventuele eerder in de cache opgeslagen versies van een resource en haalt de nieuwe versie op.
Gelijktijdigheid beheren in een cache
Caches zijn vaak ontworpen om te worden gedeeld door meerdere exemplaren van een toepassing. Elk toepassingsexemplaren kunnen gegevens in de cache lezen en wijzigen. Daarom zijn dezelfde gelijktijdigheidsproblemen die zich voordoen met een gedeeld gegevensarchief ook van toepassing op een cache. In een situatie waarin een toepassing gegevens moet wijzigen die in de cache zijn opgeslagen, moet u er mogelijk voor zorgen dat updates die zijn aangebracht door één exemplaar van de toepassing, de wijzigingen die door een ander exemplaar zijn aangebracht, niet overschrijven.
Afhankelijk van de aard van de gegevens en de kans op botsingen, kunt u een van de volgende twee benaderingen gebruiken voor gelijktijdigheid:
- Optimistisch. Direct voordat de gegevens worden bijgewerkt, controleert de toepassing of de gegevens in de cache zijn gewijzigd sinds deze zijn opgehaald. Als de gegevens nog steeds hetzelfde zijn, kan de wijziging worden aangebracht. Anders moet de toepassing beslissen of deze moet worden bijgewerkt. (De bedrijfslogica die deze beslissing aanstuurt, is toepassingsspecifiek.) Deze methode is geschikt voor situaties waarin updates niet vaak voorkomen of wanneer conflicten waarschijnlijk niet voorkomen.
- Pessimistisch. Wanneer de gegevens worden opgehaald, vergrendelt de toepassing deze in de cache om te voorkomen dat een ander exemplaar deze wijzigt. Dit proces zorgt ervoor dat conflicten niet kunnen optreden, maar ze kunnen ook andere exemplaren blokkeren die dezelfde gegevens moeten verwerken. Pessimistische gelijktijdigheid kan van invloed zijn op de schaalbaarheid van een oplossing en wordt alleen aanbevolen voor bewerkingen met korte levensduur. Deze aanpak kan geschikt zijn voor situaties waarin conflicten waarschijnlijker zijn, met name als een toepassing meerdere items in de cache bijwerken en ervoor moet zorgen dat deze wijzigingen consistent worden toegepast.
Hoge beschikbaarheid en schaalbaarheid implementeren en prestaties verbeteren
Vermijd het gebruik van een cache als de primaire opslagplaats met gegevens; dit is de rol van het oorspronkelijke gegevensarchief waaruit de cache wordt gevuld. Het oorspronkelijke gegevensarchief is verantwoordelijk voor het garanderen van de persistentie van de gegevens.
Wees voorzichtig met het niet introduceren van kritieke afhankelijkheden van de beschikbaarheid van een gedeelde cacheservice in uw oplossingen. Een toepassing moet kunnen blijven functioneren als de service die de gedeelde cache biedt niet beschikbaar is. De toepassing moet niet meer reageren of mislukken terwijl wordt gewacht totdat de cacheservice is hervat.
Daarom moet de toepassing worden voorbereid om de beschikbaarheid van de cacheservice te detecteren en terug te vallen naar het oorspronkelijke gegevensarchief als de cache niet toegankelijk is. Het Circuit-Breaker-patroon is handig voor het afhandelen van dit scenario. De service die de cache biedt, kan worden hersteld en zodra deze beschikbaar is, kan de cache opnieuw worden ingevuld omdat gegevens worden gelezen uit het oorspronkelijke gegevensarchief, na een strategie zoals het cache-aside-patroon.
De schaalbaarheid van het systeem kan echter worden beïnvloed als de toepassing terugvalt op het oorspronkelijke gegevensarchief wanneer de cache tijdelijk niet beschikbaar is. Terwijl het gegevensarchief wordt hersteld, kan het oorspronkelijke gegevensarchief worden overspoeld met aanvragen voor gegevens, wat resulteert in time-outs en mislukte verbindingen.
Overweeg om een lokale, persoonlijke cache te implementeren in elk exemplaar van een toepassing, samen met de gedeelde cache waartoe alle toepassingsexemplaren toegang hebben. Wanneer de toepassing een item ophaalt, kan het eerst in de lokale cache worden gecontroleerd, vervolgens in de gedeelde cache en ten slotte in het oorspronkelijke gegevensarchief. De lokale cache kan worden gevuld met behulp van de gegevens in de gedeelde cache of in de database als de gedeelde cache niet beschikbaar is.
Deze aanpak vereist een zorgvuldige configuratie om te voorkomen dat de lokale cache te verouderd wordt ten opzichte van de gedeelde cache. De lokale cache fungeert echter als buffer als de gedeelde cache niet bereikbaar is. In afbeelding 3 ziet u deze structuur.
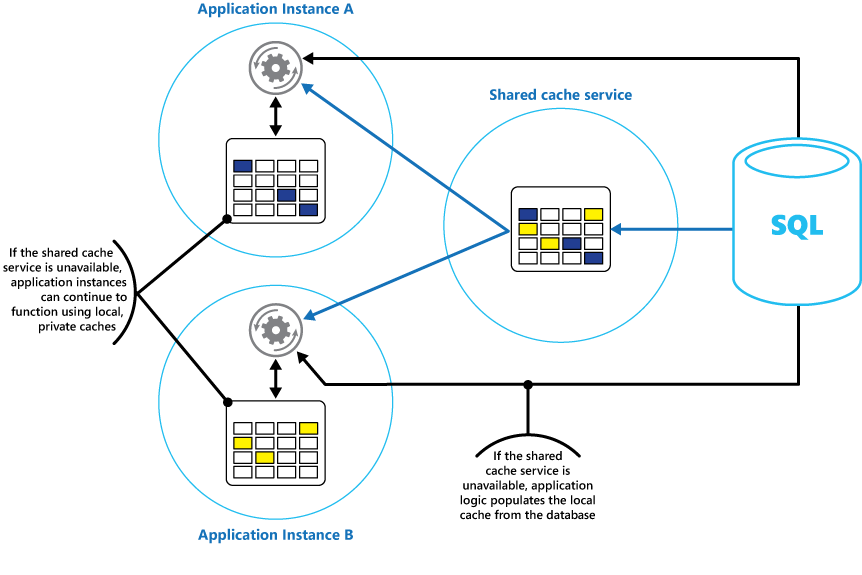
Afbeelding 3: Een lokale privécache gebruiken met een gedeelde cache.
Ter ondersteuning van grote caches die relatief langlopende gegevens bevatten, bieden sommige cacheservices een optie voor hoge beschikbaarheid waarmee automatische failover wordt geïmplementeerd als de cache niet beschikbaar is. Deze benadering omvat doorgaans het repliceren van de gegevens in de cache die zijn opgeslagen op een primaire cacheserver naar een secundaire cacheserver en overschakelen naar de secundaire server als de primaire server mislukt of de verbinding is verbroken.
Om de latentie te verminderen die is gekoppeld aan het schrijven naar meerdere bestemmingen, kan de replicatie naar de secundaire server asynchroon optreden wanneer gegevens naar de cache op de primaire server worden geschreven. Deze benadering leidt tot de mogelijkheid dat bepaalde gegevens in de cache verloren kunnen gaan als er een fout opgetreden is, maar het aandeel van deze gegevens moet klein zijn, vergeleken met de totale grootte van de cache.
Als een gedeelde cache groot is, kan het nuttig zijn om de gegevens in de cache te partitioneren over knooppunten om de kans op conflicten te verminderen en de schaalbaarheid te verbeteren. Veel gedeelde caches bieden ondersteuning voor de mogelijkheid om dynamisch knooppunten toe te voegen (en te verwijderen) en de gegevens opnieuw te verdelen over partities. Deze benadering kan betrekking hebben op clustering, waarbij de verzameling knooppunten wordt gepresenteerd aan clienttoepassingen als een naadloze, enkele cache. Intern worden de gegevens echter verspreid over knooppunten na een vooraf gedefinieerde distributiestrategie waarmee de belasting gelijkmatig wordt verdeeld. Zie richtlijnen voor gegevenspartitionering voor meer informatie over mogelijke partitioneringsstrategieën.
Clustering kan ook de beschikbaarheid van de cache verhogen. Als een knooppunt mislukt, is de rest van de cache nog steeds toegankelijk. Clustering wordt vaak gebruikt in combinatie met replicatie en failover. Elk knooppunt kan worden gerepliceerd en de replica kan snel online worden gebracht als het knooppunt uitvalt.
Veel lees- en schrijfbewerkingen hebben waarschijnlijk betrekking op enkele gegevenswaarden of -objecten. Soms kan het echter nodig zijn om grote hoeveelheden gegevens snel op te slaan of op te halen. Het seeden van een cache kan bijvoorbeeld betrekking hebben op het schrijven van honderden of duizenden items naar de cache. Een toepassing moet mogelijk ook een groot aantal gerelateerde items ophalen uit de cache als onderdeel van dezelfde aanvraag.
Veel grootschalige caches bieden batchbewerkingen voor deze doeleinden. Hierdoor kan een clienttoepassing een groot aantal items in één aanvraag verpakken en de overhead verminderen die is gekoppeld aan het uitvoeren van een groot aantal kleine aanvragen.
Cache en uiteindelijke consistentie
Het cache-aside-patroon werkt alleen als het exemplaar van de toepassing dat de cache vult, toegang heeft tot de meest recente en consistente versie van de gegevens. In een systeem dat uiteindelijke consistentie implementeert (zoals een gerepliceerd gegevensarchief), is dit mogelijk niet het geval.
Een exemplaar van een toepassing kan een gegevensitem wijzigen en de in de cache opgeslagen versie van dat item ongeldig maken. Een ander exemplaar van de toepassing kan proberen dit item te lezen uit een cache, waardoor een cache ontbreekt, zodat de gegevens uit het gegevensarchief worden gelezen en toegevoegd aan de cache. Als het gegevensarchief echter niet volledig is gesynchroniseerd met de andere replica's, kan het toepassingsexemplaren de cache lezen en vullen met de oude waarde.
Zie de primer gegevensconsistentie voor meer informatie over het verwerken van gegevensconsistentie.
In de cache opgeslagen gegevens beveiligen
Ongeacht de cacheservice die u gebruikt, kunt u overwegen hoe u de gegevens die in de cache zijn opgeslagen, kunt beveiligen tegen onbevoegde toegang. Er zijn twee belangrijke aandachtspunten:
- De privacy van de gegevens in de cache.
- De privacy van gegevens tijdens het stromen tussen de cache en de toepassing die gebruikmaakt van de cache.
Om gegevens in de cache te beveiligen, kan de cacheservice een verificatiemechanisme implementeren waarvoor toepassingen het volgende moeten opgeven:
- Welke identiteiten toegang hebben tot gegevens in de cache.
- Welke bewerkingen (lezen en schrijven) deze identiteiten mogen uitvoeren.
Om de overhead te verminderen die is gekoppeld aan het lezen en schrijven van gegevens, kan die identiteit, nadat aan een identiteit schrijf- of leestoegang tot de cache is verleend, alle gegevens in de cache gebruiken.
Als u de toegang tot subsets van de gegevens in de cache wilt beperken, kunt u een van de volgende handelingen uitvoeren:
- Splits de cache op in partities (met behulp van verschillende cacheservers) en geef alleen toegang tot identiteiten voor de partities die ze mogen gebruiken.
- Versleutel de gegevens in elke subset met behulp van verschillende sleutels en geef alleen de versleutelingssleutels op voor identiteiten die toegang moeten hebben tot elke subset. Een clienttoepassing kan mogelijk nog steeds alle gegevens in de cache ophalen, maar kan alleen de gegevens ontsleutelen waarvoor deze de sleutels bevat.
U moet de gegevens ook beveiligen terwijl deze in en uit de cache stromen. Hiervoor bent u afhankelijk van de beveiligingsfuncties van de netwerkinfrastructuur die clienttoepassingen gebruiken om verbinding te maken met de cache. Als de cache wordt geïmplementeerd met behulp van een on-site-server binnen dezelfde organisatie die als host fungeert voor de clienttoepassingen, hoeft u mogelijk geen extra stappen uit te voeren voor de isolatie van het netwerk zelf. Als de cache zich op afstand bevindt en een TCP- of HTTP-verbinding via een openbaar netwerk (zoals internet) vereist, kunt u overwegen SSL te implementeren.
Overwegingen voor het implementeren van caching in Azure
Azure Cache voor Redis is een implementatie van de open source Redis-cache die wordt uitgevoerd als een service in een Azure-datacenter. Het biedt een cachingservice die toegankelijk is vanuit elke Azure-toepassing, ongeacht of de toepassing wordt geïmplementeerd als een cloudservice, een website of binnen een virtuele Azure-machine. Caches kunnen worden gedeeld door clienttoepassingen met de juiste toegangssleutel.
Azure Cache voor Redis is een krachtige cachingoplossing die beschikbaarheid, schaalbaarheid en beveiliging biedt. Het wordt doorgaans uitgevoerd als een service verspreid over een of meer toegewezen machines. Er wordt geprobeerd zoveel mogelijk informatie op te slaan in het geheugen om snelle toegang te garanderen. Deze architectuur is bedoeld om lage latentie en hoge doorvoer te bieden door de noodzaak om trage I/O-bewerkingen uit te voeren.
Azure Cache voor Redis is compatibel met veel van de verschillende API's die worden gebruikt door clienttoepassingen. Als u bestaande toepassingen hebt die al gebruikmaken van Azure Cache voor Redis die on-premises worden uitgevoerd, biedt Azure Cache voor Redis een snel migratiepad voor caching in de cloud.
Functies van Redis
Redis is meer dan een eenvoudige cacheserver. Het biedt een gedistribueerde in-memory database met een uitgebreide opdrachtenset die ondersteuning biedt voor veel algemene scenario's. Deze worden verderop in dit document beschreven in de sectie Redis-caching gebruiken. In deze sectie vindt u een overzicht van enkele van de belangrijkste functies die Redis biedt.
Redis als een in-memory database
Redis ondersteunt zowel lees- als schrijfbewerkingen. In Redis kunnen schrijfbewerkingen worden beveiligd tegen systeemfouten door periodiek op te slaan in een lokaal momentopnamebestand of in een alleen-toevoegen-logboekbestand. Deze situatie is niet het geval in veel caches, die als transitief gegevensarchieven moeten worden beschouwd.
Alle schrijfbewerkingen zijn asynchroon en blokkeren clients niet om gegevens te lezen en te schrijven. Wanneer Redis wordt uitgevoerd, worden de gegevens uit het momentopname- of logboekbestand gelezen en gebruikt om de cache in het geheugen samen te stellen. Zie Redis persistentie op de Website van Redis voor meer informatie.
Opmerking
Redis garandeert niet dat alle schrijfbewerkingen worden opgeslagen als er sprake is van een catastrofale fout, maar in het slechtste geval verliest u slechts een paar seconden aan gegevens. Een cache is niet bedoeld als gezaghebbende gegevensbron en is de verantwoordelijkheid van de toepassingen die gebruikmaken van de cache om ervoor te zorgen dat kritieke gegevens worden opgeslagen in een geschikt gegevensarchief. Zie het cache-aside-patroon voor meer informatie.
Redis-gegevenstypen
Redis is een sleutel-waardearchief, waar waarden eenvoudige typen of complexe gegevensstructuren kunnen bevatten, zoals hashes, lijsten en sets. Het ondersteunt een set atomische bewerkingen op deze gegevenstypen. Sleutels kunnen permanent of gelabeld zijn met een beperkte time-to-live, waarna de sleutel en de bijbehorende waarde automatisch uit de cache worden verwijderd. Ga naar de pagina Een inleiding tot Redis-gegevenstypen en abstracties op de Redis-website voor meer informatie over Redis-sleutels en -waarden.
Redis-replicatie en clustering
Redis ondersteunt primaire/onderliggende replicatie om de beschikbaarheid te garanderen en doorvoer te onderhouden. Schrijfbewerkingen naar een primair Redis-knooppunt worden gerepliceerd naar een of meer onderliggende knooppunten. Leesbewerkingen kunnen worden uitgevoerd door de primaire of een van de onderliggende elementen.
Als u een netwerkpartitie hebt, kunnen ondergeschikten gegevens blijven verwerken en vervolgens transparant opnieuw synchroniseren met de primaire wanneer de verbinding opnieuw tot stand is gebracht. Ga naar de pagina Replicatie op de Redis-website voor meer informatie.
Redis biedt ook clustering, waarmee u transparant gegevens kunt partitioneren in shards over servers en de belasting kunt verspreiden. Deze functie verbetert de schaalbaarheid, omdat nieuwe Redis-servers kunnen worden toegevoegd en de gegevens opnieuw kunnen worden gepartitioneerd naarmate de grootte van de cache toeneemt.
Bovendien kan elke server in het cluster worden gerepliceerd met behulp van primaire/onderliggende replicatie. Dit zorgt voor beschikbaarheid voor elk knooppunt in het cluster. Ga naar de zelfstudiepagina van het Redis-cluster op de Redis-website voor meer informatie over clustering en sharding.
Redis-geheugengebruik
Een Redis-cache heeft een eindige grootte die afhankelijk is van de resources die beschikbaar zijn op de hostcomputer. Wanneer u een Redis-server configureert, kunt u de maximale hoeveelheid geheugen opgeven die kan worden gebruikt. U kunt ook een sleutel in een Redis-cache zo configureren dat deze een verlooptijd heeft, waarna deze automatisch uit de cache wordt verwijderd. Deze functie kan helpen voorkomen dat de cache in het geheugen wordt gevuld met oude of verouderde gegevens.
Naarmate het geheugen vol raakt, kunnen Sleutels en hun waarden automatisch worden verwijderd door een aantal beleidsregels te volgen. De standaardwaarde is LRU (minst recent gebruikt), maar u kunt ook andere beleidsregels selecteren, zoals het willekeurig verwijderen van sleutels of het uitschakelen van verwijderingen (in dat geval wordt geprobeerd items aan de cache toe te voegen als deze vol is). De pagina Redis gebruiken als een LRU-cache biedt meer informatie.
Redis-transacties en -batches
Met Redis kan een clienttoepassing een reeks bewerkingen verzenden die gegevens in de cache lezen en schrijven als een atomische transactie. Alle opdrachten in de transactie worden gegarandeerd sequentieel uitgevoerd en er worden geen opdrachten die door andere gelijktijdige clients worden uitgegeven, tussen beide gekruist.
Dit zijn echter geen echte transacties als een relationele database deze zou uitvoeren. Transactieverwerking bestaat uit twee fasen: de eerste is wanneer de opdrachten in de wachtrij worden geplaatst en de tweede is wanneer de opdrachten worden uitgevoerd. Tijdens de wachtrijfase van de opdracht worden de opdrachten die de transactie vormen door de client verzonden. Als er op dit moment een fout optreedt (zoals een syntaxisfout of het verkeerde aantal parameters), weigert Redis om de hele transactie te verwerken en te verwijderen.
Tijdens de uitvoeringsfase voert Redis elke opdracht in de wachtrij uit. Als een opdracht mislukt tijdens deze fase, gaat Redis verder met de volgende opdracht in de wachtrij en wordt de effecten van opdrachten die al zijn uitgevoerd, niet teruggedraaid. Deze vereenvoudigde vorm van transacties helpt bij het onderhouden van prestaties en het voorkomen van prestatieproblemen die worden veroorzaakt door conflicten.
Redis implementeert een vorm van optimistische vergrendeling om te helpen bij het onderhouden van consistentie. Ga naar de pagina Transacties op de Redis-website voor gedetailleerde informatie over transacties en vergrendelingen met Redis.
Redis biedt ook ondersteuning voor niet-transactionele batchverwerking van aanvragen. Met het Redis-protocol dat clients gebruiken om opdrachten naar een Redis-server te verzenden, kan een client een reeks bewerkingen verzenden als onderdeel van dezelfde aanvraag. Dit kan helpen om pakketfragmentatie op het netwerk te verminderen. Wanneer de batch wordt verwerkt, wordt elke opdracht uitgevoerd. Als een van deze opdrachten ongeldig is, worden deze geweigerd (wat niet gebeurt met een transactie), maar worden de resterende opdrachten uitgevoerd. Er is ook geen garantie over de volgorde waarin de opdrachten in de batch worden verwerkt.
Redis-beveiliging
Redis is uitsluitend gericht op het bieden van snelle toegang tot gegevens en is ontworpen om te worden uitgevoerd in een vertrouwde omgeving die alleen toegankelijk is voor vertrouwde clients. Redis ondersteunt een beperkt beveiligingsmodel op basis van wachtwoordverificatie. (Het is mogelijk om verificatie volledig te verwijderen, hoewel dit niet wordt aanbevolen.)
Alle geverifieerde clients delen hetzelfde globale wachtwoord en hebben toegang tot dezelfde resources. Als u uitgebreidere aanmeldingsbeveiliging nodig hebt, moet u uw eigen beveiligingslaag voor de Redis-server implementeren en moeten alle clientaanvragen via deze extra laag worden doorgegeven. Redis mag niet rechtstreeks worden blootgesteld aan niet-vertrouwde of niet-geverifieerde clients.
U kunt de toegang tot opdrachten beperken door ze uit te schakelen of de naam ervan te wijzigen (en door alleen bevoegde clients met de nieuwe namen op te geven).
Redis ondersteunt geen enkele vorm van gegevensversleuteling, dus alle codering moet worden uitgevoerd door clienttoepassingen. Daarnaast biedt Redis geen vorm van transportbeveiliging. Als u gegevens wilt beveiligen terwijl deze via het netwerk stromen, raden we u aan een SSL-proxy te implementeren.
Ga voor meer informatie naar de redis-beveiligingspagina op de Redis-website.
Opmerking
Azure Cache voor Redis biedt een eigen beveiligingslaag waarmee clients verbinding maken. De onderliggende Redis-servers worden niet blootgesteld aan het openbare netwerk.
Azure Redis-cache
Azure Cache voor Redis biedt toegang tot Redis-servers die worden gehost in een Azure-datacenter. Het fungeert als een gevel die toegangsbeheer en beveiliging biedt. U kunt een cache inrichten met behulp van Azure Portal.
De portal biedt een aantal vooraf gedefinieerde configuraties. Deze variëren van een cache van 53 GB die wordt uitgevoerd als een toegewezen service die SSL-communicatie (voor privacy) en hoofd-/ondergeschikte replicatie ondersteunt met een SLA (Service Level Agreement) van 99,9% beschikbaarheid, tot een cache van 250 MB zonder replicatie (geen beschikbaarheidsgaranties) die wordt uitgevoerd op gedeelde hardware.
Met behulp van Azure Portal kunt u ook het verwijderingsbeleid van de cache configureren en de toegang tot de cache beheren door gebruikers toe te voegen aan de opgegeven rollen. Deze rollen, die de bewerkingen definiëren die leden kunnen uitvoeren, omvatten Eigenaar, Inzender en Lezer. Leden van de rol Eigenaar hebben bijvoorbeeld volledige controle over de cache (inclusief beveiliging) en de inhoud, leden van de rol Inzender kunnen gegevens lezen en schrijven in de cache en leden van de rol Lezer kunnen alleen gegevens ophalen uit de cache.
De meeste beheertaken worden uitgevoerd via Azure Portal. Daarom zijn veel van de beheeropdrachten die beschikbaar zijn in de standaardversie van Redis niet beschikbaar, inclusief de mogelijkheid om de configuratie programmatisch te wijzigen, de Redis-server af te sluiten, extra ondergeschikten te configureren of gegevens geforceerd op schijf op te slaan.
Azure Portal bevat een handige grafische weergave waarmee u de prestaties van de cache kunt bewaken. U kunt bijvoorbeeld het aantal verbindingen bekijken dat wordt gemaakt, het aantal aanvragen dat wordt uitgevoerd, het volume van lees- en schrijfbewerkingen en het aantal cachetreffers versus cachemissers. Met behulp van deze informatie kunt u de effectiviteit van de cache bepalen en indien nodig overschakelen naar een andere configuratie of het verwijderingsbeleid wijzigen.
Daarnaast kunt u waarschuwingen maken waarmee e-mailberichten naar een beheerder worden verzonden als een of meer kritieke metrische gegevens buiten een verwacht bereik vallen. U kunt bijvoorbeeld een beheerder waarschuwen als het aantal gemiste caches een opgegeven waarde in het afgelopen uur overschrijdt, omdat dit betekent dat de cache mogelijk te klein is of dat gegevens te snel worden verwijderd.
U kunt ook het CPU-, geheugen- en netwerkgebruik voor de cache bewaken.
Voor meer informatie en voorbeelden die laten zien hoe u een Azure Cache voor Redis maakt en configureert, gaat u naar de pagina Lap rond Azure Cache voor Redis in de Azure-blog.
Sessiestatus en HTML-uitvoer opslaan in cache
Als u ASP.NET webtoepassingen bouwt die worden uitgevoerd met behulp van Azure-webrollen, kunt u sessiestatusgegevens en HTML-uitvoer opslaan in een Azure Cache voor Redis. Met de sessiestatusprovider voor Azure Cache voor Redis kunt u sessiegegevens delen tussen verschillende exemplaren van een ASP.NET-webtoepassing. Dit is erg handig in situaties waarin client-serveraffiniteit niet beschikbaar is en de cachegegevens in het geheugen niet geschikt zijn.
Het gebruik van de sessiestatusprovider met Azure Cache voor Redis biedt verschillende voordelen, waaronder:
- Sessiestatus delen met een groot aantal exemplaren van ASP.NET webtoepassingen.
- Verbeterde schaalbaarheid bieden.
- Ondersteuning voor beheerde, gelijktijdige toegang tot dezelfde sessiestatusgegevens voor meerdere lezers en één schrijver.
- Compressie gebruiken om geheugen te besparen en de netwerkprestaties te verbeteren.
Zie ASP.NET sessiestatusprovider voor Azure Cache voor Redis voor meer informatie.
Opmerking
Gebruik de sessiestatusprovider voor Azure Cache voor Redis niet met ASP.NET toepassingen die buiten de Azure-omgeving worden uitgevoerd. De latentie van toegang tot de cache van buiten Azure kan de prestatievoordelen van het opslaan van gegevens in de cache elimineren.
Op dezelfde manier kunt u met de uitvoercacheprovider voor Azure Cache voor Redis de HTTP-antwoorden opslaan die zijn gegenereerd door een ASP.NET-webtoepassing. Het gebruik van de uitvoercacheprovider met Azure Cache voor Redis kan de reactietijden verbeteren van toepassingen die complexe HTML-uitvoer genereren. Toepassingsexemplaren die vergelijkbare antwoorden genereren, kunnen gebruikmaken van de gedeelde uitvoerfragmenten in de cache in plaats van deze HTML-uitvoer afresh te genereren. Zie ASP.NET uitvoercacheprovider voor Azure Cache voor Redis voor meer informatie.
Een aangepaste Redis-cache bouwen
Azure Cache voor Redis fungeert als een gevel voor de onderliggende Redis-servers. Als u een geavanceerde configuratie nodig hebt die niet wordt gedekt door de Azure Redis-cache (zoals een cache die groter is dan 53 GB), kunt u uw eigen Redis-servers bouwen en hosten met behulp van Azure Virtual Machines.
Dit is een mogelijk complex proces omdat u mogelijk meerdere VM's moet maken om te fungeren als primaire en onderliggende knooppunten als u replicatie wilt implementeren. Als u bovendien een cluster wilt maken, hebt u meerdere primaries en onderliggende servers nodig. Een minimale geclusterde replicatietopologie die een hoge mate van beschikbaarheid en schaalbaarheid biedt, bestaat uit ten minste zes VM's die zijn georganiseerd als drie paren primaire/onderliggende servers (een cluster moet ten minste drie primaire knooppunten bevatten).
Elk primair/ondergeschikt paar moet zich dicht bij elkaar bevinden om de latentie te minimaliseren. Elke set paren kan echter worden uitgevoerd in verschillende Azure-datacenters die zich in verschillende regio's bevinden, als u gegevens in de cache wilt zoeken in de buurt van de toepassingen die deze waarschijnlijk zullen gebruiken. Zie Redis uitvoeren op een CentOS Linux-VM in Azure voor een voorbeeld van het bouwen en configureren van een Redis-knooppunt dat wordt uitgevoerd als een Azure-VM.
Opmerking
Als u uw eigen Redis-cache op deze manier implementeert, bent u verantwoordelijk voor het bewaken, beheren en beveiligen van de service.
Partitioneren van een Redis-cache
Het partitioneren van de cache omvat het splitsen van de cache op meerdere computers. Deze structuur biedt u verschillende voordelen ten opzichte van het gebruik van één cacheserver, waaronder:
- Het maken van een cache die veel groter is dan kan worden opgeslagen op één server.
- Gegevens distribueren over servers, waardoor de beschikbaarheid wordt verbeterd. Als één server mislukt of niet toegankelijk wordt, zijn de gegevens die deze bevat niet beschikbaar, maar kunnen de gegevens op de resterende servers nog steeds worden geopend. Voor een cache is dit niet cruciaal omdat de gegevens in de cache slechts een tijdelijke kopie zijn van de gegevens die in een database zijn opgeslagen. Gegevens in de cache op een server die ontoegankelijk worden, kunnen in de cache op een andere server worden opgeslagen.
- De belasting over servers spreiden, waardoor de prestaties en schaalbaarheid worden verbeterd.
- Geolocatie van gegevens dicht bij de gebruikers die er toegang toe hebben, waardoor latentie wordt verminderd.
Voor een cache is sharding de meest voorkomende vorm van partitioneren. In deze strategie is elke partitie (of shard) een Redis-cache op zichzelf. Gegevens worden omgeleid naar een specifieke partitie met behulp van shardinglogica, die verschillende benaderingen kunnen gebruiken om de gegevens te distribueren. Het Sharding-patroon biedt meer informatie over het implementeren van sharding.
Als u partitionering in een Redis-cache wilt implementeren, kunt u een van de volgende methoden gebruiken:
- Queryroutering aan de serverzijde. In deze techniek verzendt een clienttoepassing een aanvraag naar een van de Redis-servers die de cache vormen (waarschijnlijk de dichtstbijzijnde server). Elke Redis-server slaat metagegevens op die de partitie beschrijft die deze bevat en bevat ook informatie over welke partities zich op andere servers bevinden. De Redis-server onderzoekt de clientaanvraag. Als het lokaal kan worden opgelost, wordt de aangevraagde bewerking uitgevoerd. Anders wordt de aanvraag doorgestuurd naar de juiste server. Dit model wordt geïmplementeerd door Redis-clustering en wordt uitgebreid beschreven op de zelfstudiepagina van het Redis-cluster op de Redis-website . Redis-clustering is transparant voor clienttoepassingen en extra Redis-servers kunnen worden toegevoegd aan het cluster (en de opnieuw gepartitioneerde gegevens) zonder dat u de clients opnieuw hoeft te configureren.
- Partitionering aan de clientzijde. In dit model bevat de clienttoepassing logica (mogelijk in de vorm van een bibliotheek) waarmee aanvragen worden gerouteerd naar de juiste Redis-server. Deze benadering kan worden gebruikt met Azure Cache voor Redis. Maak meerdere Azure Cache voor Redis (één voor elke gegevenspartitie) en implementeer de logica aan de clientzijde waarmee de aanvragen naar de juiste cache worden gerouteerd. Als het partitioneringsschema wordt gewijzigd (als er bijvoorbeeld extra Azure Cache voor Redis wordt gemaakt), moeten clienttoepassingen mogelijk opnieuw worden geconfigureerd.
- Door proxy ondersteunde partitionering. In dit schema verzenden clienttoepassingen aanvragen naar een tussenliggende proxyservice die begrijpt hoe de gegevens worden gepartitioneerd en stuurt de aanvraag vervolgens naar de juiste Redis-server. Deze benadering kan ook worden gebruikt met Azure Cache voor Redis; de proxyservice kan worden geïmplementeerd als een Azure-cloudservice. Deze benadering vereist een extra complexiteitsniveau voor het implementeren van de service en aanvragen kunnen langer duren dan het gebruik van partitionering aan de clientzijde.
De pagina Partitionering: het splitsen van gegevens tussen meerdere Redis-exemplaren op de Redis-website biedt meer informatie over het implementeren van partitionering met Redis.
Redis-cacheclienttoepassingen implementeren
Redis ondersteunt clienttoepassingen die zijn geschreven in talloze programmeertalen. Als u nieuwe toepassingen bouwt met behulp van .NET Framework, raden we u aan de clientbibliotheek StackExchange.Redis te gebruiken. Deze bibliotheek biedt een .NET Framework-objectmodel waarmee de details worden geabstraheerd voor het maken van verbinding met een Redis-server, het verzenden van opdrachten en het ontvangen van antwoorden. Het is beschikbaar in Visual Studio als een NuGet-pakket. U kunt dezelfde bibliotheek gebruiken om verbinding te maken met een Azure Cache voor Redis of een aangepaste Redis-cache die wordt gehost op een virtuele machine.
Als u verbinding wilt maken met een Redis-server, gebruikt u de statische Connect methode van de ConnectionMultiplexer klasse. De verbinding die met deze methode wordt gemaakt, is ontworpen om gedurende de levensduur van de clienttoepassing te worden gebruikt en dezelfde verbinding kan worden gebruikt door meerdere gelijktijdige threads. Maak niet opnieuw verbinding en verbreek de verbinding niet telkens wanneer u een Redis-bewerking uitvoert, omdat dit de prestaties kan verminderen.
U kunt de verbindingsparameters opgeven, zoals het adres van de Redis-host en het wachtwoord. Als u Azure Cache voor Redis gebruikt, is het wachtwoord de primaire of secundaire sleutel die wordt gegenereerd voor Azure Cache voor Redis met behulp van Azure Portal.
Nadat u verbinding hebt gemaakt met de Redis-server, kunt u een ingang verkrijgen in de Redis-database die fungeert als de cache. De Redis-verbinding biedt de GetDatabase methode om dit te doen. Vervolgens kunt u items ophalen uit de cache en gegevens opslaan in de cache met behulp van de StringGet en StringSet methoden. Deze methoden verwachten een sleutel als parameter en retourneren het item in de cache met een overeenkomende waarde (StringGet) of voeg het item toe aan de cache met deze sleutel (StringSet).
Afhankelijk van de locatie van de Redis-server kunnen veel bewerkingen enige latentie veroorzaken terwijl een aanvraag naar de server wordt verzonden en er een antwoord naar de client wordt geretourneerd. De StackExchange-bibliotheek biedt asynchrone versies van veel van de methoden die beschikbaar worden gesteld om clienttoepassingen te helpen responsief te blijven. Deze methoden ondersteunen het Asynchrone patroon op basis van taken in .NET Framework.
In het volgende codefragment ziet u een methode met de naam RetrieveItem. Het illustreert een implementatie van het cache-aside-patroon op basis van Redis en de StackExchange-bibliotheek. De methode gebruikt een tekenreekssleutelwaarde en probeert het bijbehorende item op te halen uit de Redis-cache door de StringGetAsync methode aan te roepen (de asynchrone versie van StringGet).
Als het item niet wordt gevonden, wordt het opgehaald uit de onderliggende gegevensbron met behulp van de GetItemFromDataSourceAsync methode (dit is een lokale methode en geen onderdeel van de StackExchange-bibliotheek). Deze wordt vervolgens toegevoegd aan de cache met behulp van de StringSetAsync methode, zodat deze de volgende keer sneller kan worden opgehaald.
// Connect to the Azure Redis cache
ConfigurationOptions config = new ConfigurationOptions();
config.EndPoints.Add("<your DNS name>.redis.cache.windows.net");
config.Password = "<Redis cache key from management portal>";
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase cache = redisHostConnection.GetDatabase();
...
private async Task<string> RetrieveItem(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await cache.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue == null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await cache.StringSetAsync(itemKey, itemValue);
}
// Return the item
return itemValue;
}
De StringGet methoden en StringSet methoden zijn niet beperkt tot het ophalen of opslaan van tekenreekswaarden. Ze kunnen elk item nemen dat wordt geserialiseerd als een matrix van bytes. Als u een .NET-object wilt opslaan, kunt u het serialiseren als een bytestream en de StringSet methode gebruiken om het naar de cache te schrijven.
Op dezelfde manier kunt u een object uit de cache lezen met behulp van de StringGet methode en het deserialiseren als een .NET-object. De volgende code toont een set extensiemethoden voor de IDatabase-interface (de GetDatabase methode van een Redis-verbinding retourneert een IDatabase object) en een aantal voorbeeldcode die gebruikmaakt van deze methoden voor het lezen en schrijven van een BlogPost object naar de cache:
public static class RedisCacheExtensions
{
public static async Task<T> GetAsync<T>(this IDatabase cache, string key)
{
return Deserialize<T>(await cache.StringGetAsync(key));
}
public static async Task<object> GetAsync(this IDatabase cache, string key)
{
return Deserialize<object>(await cache.StringGetAsync(key));
}
public static async Task SetAsync(this IDatabase cache, string key, object value)
{
await cache.StringSetAsync(key, Serialize(value));
}
static byte[] Serialize(object o)
{
byte[] objectDataAsStream = null;
if (o != null)
{
var jsonString = JsonSerializer.Serialize(o);
objectDataAsStream = Encoding.ASCII.GetBytes(jsonString);
}
return objectDataAsStream;
}
static T Deserialize<T>(byte[] stream)
{
T result = default(T);
if (stream != null)
{
var jsonString = Encoding.ASCII.GetString(stream);
result = JsonSerializer.Deserialize<T>(jsonString);
}
return result;
}
}
De volgende code illustreert een methode met de naam RetrieveBlogPost die gebruikmaakt van deze extensiemethoden voor het lezen en schrijven van een serialiseerbare BlogPost object naar de cache volgens het cache-aside-patroon:
// The BlogPost type
public class BlogPost
{
private HashSet<string> tags;
public BlogPost(int id, string title, int score, IEnumerable<string> tags)
{
this.Id = id;
this.Title = title;
this.Score = score;
this.tags = new HashSet<string>(tags);
}
public int Id { get; set; }
public string Title { get; set; }
public int Score { get; set; }
public ICollection<string> Tags => this.tags;
}
...
private async Task<BlogPost> RetrieveBlogPost(string blogPostKey)
{
BlogPost blogPost = await cache.GetAsync<BlogPost>(blogPostKey);
if (blogPost == null)
{
blogPost = await GetBlogPostFromDataSourceAsync(blogPostKey);
await cache.SetAsync(blogPostKey, blogPost);
}
return blogPost;
}
Redis ondersteunt pipelining van opdrachten als een clienttoepassing meerdere asynchrone aanvragen verzendt. Redis kan de aanvragen met dezelfde verbinding multiplexen in plaats van opdrachten in een strikte volgorde te ontvangen en erop te reageren.
Deze aanpak helpt om de latentie te verminderen door efficiënter gebruik te maken van het netwerk. In het volgende codefragment ziet u een voorbeeld waarmee de details van twee klanten gelijktijdig worden opgehaald. De code verzendt twee aanvragen en voert vervolgens een andere verwerking (niet weergegeven) uit voordat de resultaten worden ontvangen. De Wait methode van het cacheobject is vergelijkbaar met de .NET Framework-methode Task.Wait :
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
var task1 = cache.StringGetAsync("customer:1");
var task2 = cache.StringGetAsync("customer:2");
...
var customer1 = cache.Wait(task1);
var customer2 = cache.Wait(task2);
Zie de documentatie voor Azure Cache voor Redis voor meer informatie over het schrijven van clienttoepassingen die de Azure Cache voor Redis kunnen gebruiken. Meer informatie is ook beschikbaar op StackExchange.Redis.
De pagina Pijplijnen en multiplexers op dezelfde website biedt meer informatie over asynchrone bewerkingen en pipelining met Redis en de StackExchange-bibliotheek.
Redis-caching gebruiken
Het eenvoudigste gebruik van Redis voor cachingproblemen is sleutel-waardeparen waarbij de waarde een niet-geïnterpreteerde tekenreeks is van willekeurige lengte die binaire gegevens kan bevatten. (Het is in feite een matrix van bytes die als een tekenreeks kunnen worden behandeld). Dit scenario is geïllustreerd in de sectie Redis Cache-clienttoepassingen implementeren eerder in dit artikel.
Houd er rekening mee dat sleutels ook niet-geïnterpreteerde gegevens bevatten, zodat u binaire informatie als sleutel kunt gebruiken. Hoe langer de sleutel is, hoe meer ruimte nodig is om op te slaan en hoe langer het duurt om opzoekbewerkingen uit te voeren. Ontwerp uw keyspace zorgvuldig en gebruik zinvolle (maar niet uitgebreide) sleutels voor bruikbaarheid en onderhoud.
Gebruik bijvoorbeeld gestructureerde sleutels zoals 'customer:100' om de sleutel voor de klant te vertegenwoordigen met id 100 in plaats van '100'. Met dit schema kunt u eenvoudig onderscheid maken tussen waarden die verschillende gegevenstypen opslaan. U kunt bijvoorbeeld ook de sleutel 'orders:100' gebruiken om de sleutel voor de order weer te geven met id 100.
Naast eendimensionale binaire tekenreeksen kan een waarde in een Redis-sleutel-waardepaar ook meer gestructureerde informatie bevatten, waaronder lijsten, sets (gesorteerd en ongesorteerd) en hashes. Redis biedt een uitgebreide opdrachtenset die deze typen kan bewerken en veel van deze opdrachten zijn beschikbaar voor .NET Framework-toepassingen via een clientbibliotheek zoals StackExchange. De pagina Een inleiding tot Redis-gegevenstypen en abstracties op de Redis-website biedt een gedetailleerder overzicht van deze typen en de opdrachten die u kunt gebruiken om ze te bewerken.
In deze sectie vindt u een overzicht van enkele veelvoorkomende use cases voor deze gegevenstypen en opdrachten.
Atomische en batchbewerkingen uitvoeren
Redis ondersteunt een reeks atomische get-and-set-bewerkingen voor tekenreekswaarden. Deze bewerkingen verwijderen de mogelijke racerisico's die kunnen optreden bij het gebruik van afzonderlijke GET en SET opdrachten. De beschikbare bewerkingen zijn onder andere:
INCR,INCRBY,DECRenDECRBY, waarmee atomische incrementele en degradatiebewerkingen worden uitgevoerd voor numerieke geheel getalwaarden. De StackExchange-bibliotheek biedt overbelaste versies van deIDatabase.StringIncrementAsyncenIDatabase.StringDecrementAsyncmethoden om deze bewerkingen uit te voeren en de resulterende waarde te retourneren die is opgeslagen in de cache. In het volgende codefragment ziet u hoe u deze methoden gebruikt:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... await cache.StringSetAsync("data:counter", 99); ... long oldValue = await cache.StringIncrementAsync("data:counter"); // Increment by 1 (the default) // oldValue should be 100 long newValue = await cache.StringDecrementAsync("data:counter", 50); // Decrement by 50 // newValue should be 50GETSET, waarmee de waarde wordt opgehaald die is gekoppeld aan een sleutel en deze wijzigt in een nieuwe waarde. De StackExchange-bibliotheek maakt deze bewerking beschikbaar via deIDatabase.StringGetSetAsyncmethode. In het onderstaande codefragment ziet u een voorbeeld van deze methode. Deze code retourneert de huidige waarde die is gekoppeld aan de sleutel 'data:counter' uit het vorige voorbeeld. Vervolgens wordt de waarde voor deze sleutel teruggezet op nul, allemaal als onderdeel van dezelfde bewerking:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... string oldValue = await cache.StringGetSetAsync("data:counter", 0);MGETenMSET, waarmee een reeks tekenreekswaarden als één bewerking kan worden geretourneerd of gewijzigd. DeIDatabase.StringGetAsyncenIDatabase.StringSetAsyncmethoden worden overbelast om deze functionaliteit te ondersteunen, zoals wordt weergegeven in het volgende voorbeeld:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... // Create a list of key-value pairs var keysAndValues = new List<KeyValuePair<RedisKey, RedisValue>>() { new KeyValuePair<RedisKey, RedisValue>("data:key1", "value1"), new KeyValuePair<RedisKey, RedisValue>("data:key99", "value2"), new KeyValuePair<RedisKey, RedisValue>("data:key322", "value3") }; // Store the list of key-value pairs in the cache cache.StringSet(keysAndValues.ToArray()); ... // Find all values that match a list of keys RedisKey[] keys = { "data:key1", "data:key99", "data:key322"}; // values should contain { "value1", "value2", "value3" } RedisValue[] values = cache.StringGet(keys);
U kunt ook meerdere bewerkingen combineren tot één Redis-transactie, zoals beschreven in de sectie Redis-transacties en batches eerder in dit artikel. De StackExchange-bibliotheek biedt ondersteuning voor transacties via de ITransaction interface.
U maakt een ITransaction object met behulp van de IDatabase.CreateTransaction methode. U roept opdrachten aan bij de transactie met behulp van de methoden van het ITransaction object.
De ITransaction interface biedt toegang tot een set methoden die vergelijkbaar zijn met methoden die toegankelijk zijn voor de IDatabase interface, behalve dat alle methoden asynchroon zijn. Dit betekent dat ze alleen worden uitgevoerd wanneer de ITransaction.Execute methode wordt aangeroepen. De waarde die door de ITransaction.Execute methode wordt geretourneerd, geeft aan of de transactie is gemaakt (waar) of als deze is mislukt (onwaar).
In het volgende codefragment ziet u een voorbeeld waarin twee tellers worden verhoogd en afgekoppeld als onderdeel van dezelfde transactie:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = transaction.Execute();
Console.WriteLine("Transaction {0}", result ? "succeeded" : "failed");
Console.WriteLine("Result of increment: {0}", tx1.Result);
Console.WriteLine("Result of decrement: {0}", tx2.Result);
Redis-transacties zijn in tegenstelling tot transacties in relationele databases. Met Execute de methode worden alle opdrachten die deel uitmaken van de transactie die moeten worden uitgevoerd in de wachtrij geplaatst. Als een van deze opdrachten onjuist is, wordt de transactie gestopt. Als alle opdrachten in de wachtrij zijn geplaatst, wordt elke opdracht asynchroon uitgevoerd.
Als een opdracht mislukt, worden de andere nog steeds verwerkt. Als u wilt controleren of een opdracht is voltooid, moet u de resultaten van de opdracht ophalen met behulp van de eigenschap Resultaat van de bijbehorende taak, zoals wordt weergegeven in het bovenstaande voorbeeld. Als u de eigenschap Resultaat leest, wordt de aanroepende thread geblokkeerd totdat de taak is voltooid.
Zie Transacties in Redis voor meer informatie.
Wanneer u batchbewerkingen uitvoert, kunt u de IBatch interface van de StackExchange-bibliotheek gebruiken. Deze interface biedt toegang tot een set methoden die vergelijkbaar zijn met methoden die vergelijkbaar zijn met methoden die toegankelijk zijn voor de IDatabase interface, behalve dat alle methoden asynchroon zijn.
U maakt een IBatch object met behulp van de IDatabase.CreateBatch methode en voert vervolgens de batch uit met behulp van de IBatch.Execute methode, zoals wordt weergegeven in het volgende voorbeeld. Met deze code wordt eenvoudig een tekenreekswaarde ingesteld, worden dezelfde tellers verhoogd en afgemaakt die in het vorige voorbeeld worden gebruikt en worden de resultaten weergegeven:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
IBatch batch = cache.CreateBatch();
batch.StringSetAsync("data:key1", 11);
var t1 = batch.StringIncrementAsync("data:counter1");
var t2 = batch.StringDecrementAsync("data:counter2");
batch.Execute();
Console.WriteLine("{0}", t1.Result);
Console.WriteLine("{0}", t2.Result);
Het is belangrijk om te begrijpen dat, in tegenstelling tot een transactie, als een opdracht in een batch mislukt omdat deze onjuist is, de andere opdrachten mogelijk nog steeds worden uitgevoerd. De IBatch.Execute methode retourneert geen indicatie van slagen of mislukken.
Open- en vergeet-cachebewerkingen uitvoeren
Redis ondersteunt brand- en vergeetbewerkingen met behulp van opdrachtvlagmen. In deze situatie start de client gewoon een bewerking, maar heeft geen interesse in het resultaat en wacht niet totdat de opdracht is voltooid. In het onderstaande voorbeeld ziet u hoe u de INCR-opdracht uitvoert als een fire and forget-bewerking:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
Automatisch verlopende sleutels opgeven
Wanneer u een item opslaat in een Redis-cache, kunt u een time-out opgeven waarna het item automatisch uit de cache wordt verwijderd. U kunt ook een query uitvoeren op de hoeveelheid tijd die een sleutel heeft voordat deze verloopt met behulp van de TTL opdracht. Deze opdracht is beschikbaar voor StackExchange-toepassingen met behulp van de IDatabase.KeyTimeToLive methode.
In het volgende codefragment ziet u hoe u een verlooptijd van 20 seconden instelt op een sleutel en hoe u de resterende levensduur van de sleutel opvraagt:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns a null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
U kunt de verlooptijd ook instellen op een specifieke datum en tijd met behulp van de opdracht EXPIRE, die beschikbaar is in de StackExchange-bibliotheek als methode KeyExpireAsync :
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration date of midnight on 1st January 2015
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2015, 1, 1, 0, 0, 0, DateTimeKind.Utc));
...
Hint
U kunt handmatig een item uit de cache verwijderen met behulp van de DEL-opdracht, die beschikbaar is via de StackExchange-bibliotheek als methode IDatabase.KeyDeleteAsync .
Tags gebruiken om items in de cache kruislings te correleren
Een Redis-set is een verzameling van meerdere items die één sleutel delen. U kunt een set maken met behulp van de SADD-opdracht. U kunt de items in een set ophalen met behulp van de opdracht SMEMBERS. De StackExchange-bibliotheek implementeert de SADD-opdracht met de IDatabase.SetAddAsync methode en de opdracht SMEMBERS met de IDatabase.SetMembersAsync methode.
U kunt bestaande sets ook combineren om nieuwe sets te maken met behulp van de SDIFF-opdrachten (setverschil), SINTER (snijpunt instellen) en SUNION-opdrachten (samenvoeging instellen). Met de StackExchange-bibliotheek worden deze bewerkingen in de IDatabase.SetCombineAsync methode gecombineerd. De eerste parameter voor deze methode geeft de setbewerking op die moet worden uitgevoerd.
De volgende codefragmenten laten zien hoe sets nuttig kunnen zijn voor het snel opslaan en ophalen van verzamelingen gerelateerde items. Deze code maakt gebruik van het BlogPost type dat eerder in dit artikel is beschreven in de sectie Redis Cache-clienttoepassingen implementeren.
Een BlogPost object bevat vier velden: een id, een titel, een classificatiescore en een verzameling tags. In het eerste codefragment hieronder ziet u de voorbeeldgegevens die worden gebruikt voor het vullen van BlogPost een C#-lijst met objecten:
List<string[]> tags = new List<string[]>
{
new[] { "iot","csharp" },
new[] { "iot","azure","csharp" },
new[] { "csharp","git","big data" },
new[] { "iot","git","database" },
new[] { "database","git" },
new[] { "csharp","database" },
new[] { "iot" },
new[] { "iot","database","git" },
new[] { "azure","database","big data","git","csharp" },
new[] { "azure" }
};
List<BlogPost> posts = new List<BlogPost>();
int blogKey = 0;
int numberOfPosts = 20;
Random random = new Random();
for (int i = 0; i < numberOfPosts; i++)
{
blogKey++;
posts.Add(new BlogPost(
blogKey, // Blog post ID
string.Format(CultureInfo.InvariantCulture, "Blog Post #{0}",
blogKey), // Blog post title
random.Next(100, 10000), // Ranking score
tags[i % tags.Count])); // Tags--assigned from a collection
// in the tags list
}
U kunt de tags voor elk BlogPost object opslaan als een set in een Redis-cache en elke set koppelen aan de id van de BlogPost. Hierdoor kan een toepassing snel alle tags vinden die deel uitmaken van een specifiek blogbericht. Als u zoeken in de tegenovergestelde richting wilt inschakelen en alle blogberichten wilt zoeken die een specifieke tag delen, kunt u een andere set maken waarin de blogberichten naar de tag-id in de sleutel verwijzen:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Tags are easily represented as Redis Sets
foreach (BlogPost post in posts)
{
string redisKey = string.Format(CultureInfo.InvariantCulture,
"blog:posts:{0}:tags", post.Id);
// Add tags to the blog post in Redis
await cache.SetAddAsync(
redisKey, post.Tags.Select(s => (RedisValue)s).ToArray());
// Now do the inverse so we can figure out which blog posts have a given tag
foreach (var tag in post.Tags)
{
await cache.SetAddAsync(string.Format(CultureInfo.InvariantCulture,
"tag:{0}:blog:posts", tag), post.Id);
}
}
Met deze structuren kunt u veel algemene query's zeer efficiënt uitvoeren. U kunt bijvoorbeeld alle tags voor blogpost 1 als volgt vinden en weergeven:
// Show the tags for blog post #1
foreach (var value in await cache.SetMembersAsync("blog:posts:1:tags"))
{
Console.WriteLine(value);
}
U vindt alle tags die gebruikelijk zijn voor blogpost 1 en blogpost 2 door als volgt een set snijpuntbewerking uit te voeren:
// Show the tags in common for blog posts #1 and #2
foreach (var value in await cache.SetCombineAsync(SetOperation.Intersect, new RedisKey[]
{ "blog:posts:1:tags", "blog:posts:2:tags" }))
{
Console.WriteLine(value);
}
En u vindt alle blogberichten die een specifieke tag bevatten:
// Show the ids of the blog posts that have the tag "iot".
foreach (var value in await cache.SetMembersAsync("tag:iot:blog:posts"))
{
Console.WriteLine(value);
}
Onlangs geopende items zoeken
Een veelvoorkomende taak die vereist is voor veel toepassingen is het vinden van de meest recent geopende items. Een blogsite kan bijvoorbeeld informatie over de laatst gelezen blogberichten weergeven.
U kunt deze functionaliteit implementeren met behulp van een Redis-lijst. Een Redis-lijst bevat meerdere items die dezelfde sleutel delen. De lijst fungeert als een wachtrij met dubbele einden. U kunt items naar beide uiteinden van de lijst pushen met behulp van de LPUSH-opdrachten (left push) en RPUSH (right push). U kunt items ophalen uit beide uiteinden van de lijst met behulp van de LPOP- en RPOP-opdrachten. U kunt ook een set elementen retourneren met behulp van de opdrachten LRANGE en RRANGE.
De onderstaande codefragmenten laten zien hoe u deze bewerkingen kunt uitvoeren met behulp van de StackExchange-bibliotheek. Deze code maakt gebruik van het BlogPost type uit de vorige voorbeelden. Als een blogbericht wordt gelezen door een gebruiker, pusht de IDatabase.ListLeftPushAsync methode de titel van het blogbericht naar een lijst die is gekoppeld aan de sleutel 'blog:recent_posts' in de Redis-cache.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:recent_posts";
BlogPost blogPost = ...; // Reference to the blog post that has just been read
await cache.ListLeftPushAsync(
redisKey, blogPost.Title); // Push the blog post onto the list
Naarmate er meer blogberichten worden gelezen, worden hun titels naar dezelfde lijst gepusht. De lijst wordt gerangschikt op basis van de volgorde waarin de titels zijn toegevoegd. De meest recent gelezen blogberichten bevinden zich aan de linkerkant van de lijst. (Als hetzelfde blogbericht meerdere keren wordt gelezen, bevat het meerdere vermeldingen in de lijst.)
U kunt de titels van de laatst gelezen berichten weergeven met behulp van de IDatabase.ListRange methode. Deze methode gebruikt de sleutel die de lijst, een beginpunt en een eindpunt bevat. Met de volgende code worden de titels van de tien blogberichten (items van 0 tot en met 9) aan het meest linkse einde van de lijst opgehaald:
// Show latest ten posts
foreach (string postTitle in await cache.ListRangeAsync(redisKey, 0, 9))
{
Console.WriteLine(postTitle);
}
Houd er rekening mee dat met de ListRangeAsync methode geen items uit de lijst worden verwijderd. Hiervoor kunt u de IDatabase.ListLeftPopAsync en IDatabase.ListRightPopAsync methoden gebruiken.
Als u wilt voorkomen dat de lijst voor onbepaalde tijd groeit, kunt u items periodiek verwijderen door de lijst te knippen. In het onderstaande codefragment ziet u hoe u alle behalve de vijf meest linkse items uit de lijst verwijdert:
await cache.ListTrimAsync(redisKey, 0, 5);
Een leader board implementeren
Standaard worden de items in een set niet in een specifieke volgorde bewaard. U kunt een geordende set maken met behulp van de ZADD-opdracht (de IDatabase.SortedSetAdd methode in de StackExchange-bibliotheek). De items worden geordend met behulp van een numerieke waarde die een score wordt genoemd, die als parameter voor de opdracht wordt opgegeven.
Met het volgende codefragment wordt de titel van een blogbericht toegevoegd aan een geordende lijst. In dit voorbeeld heeft elk blogbericht ook een scoreveld dat de rangschikking van het blogbericht bevat.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // Reference to a blog post that has just been rated
await cache.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
U kunt de titels en scores van blogposts in oplopende scorevolgorde ophalen met behulp van de IDatabase.SortedSetRangeByRankWithScores methode:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(redisKey))
{
Console.WriteLine(post);
}
Opmerking
De StackExchange-bibliotheek biedt ook de IDatabase.SortedSetRangeByRankAsync methode die de gegevens in scorevolgorde retourneert, maar de scores worden niet geretourneerd.
U kunt ook items ophalen in aflopende volgorde van scores en het aantal geretourneerde items beperken door aanvullende parameters aan de IDatabase.SortedSetRangeByRankWithScoresAsync methode op te geven. In het volgende voorbeeld worden de titels en scores van de top 10 gerangschikte blogberichten weergegeven:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
In het volgende voorbeeld wordt de IDatabase.SortedSetRangeByScoreWithScoresAsync methode gebruikt, die u kunt gebruiken om de items te beperken die worden geretourneerd naar items die binnen een bepaald scorebereik vallen:
// Blog posts with scores between 5000 and 100000
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
Bericht met behulp van kanalen
Afgezien van het fungeren als een gegevenscache, biedt een Redis-server berichten via een mechanisme voor uitgevers/abonnees met hoge prestaties. Clienttoepassingen kunnen zich abonneren op een kanaal en andere toepassingen of services kunnen berichten naar het kanaal publiceren. Abonnerende toepassingen ontvangen deze berichten en kunnen ze verwerken.
Redis biedt de opdracht SUBSCRIBE voor clienttoepassingen die kunnen worden gebruikt om zich te abonneren op kanalen. Met deze opdracht wordt de naam verwacht van een of meer kanalen waarop de toepassing berichten accepteert. De StackExchange-bibliotheek bevat de ISubscription interface, waarmee een .NET Framework-toepassing zich kan abonneren en publiceren op kanalen.
U maakt een ISubscription object met behulp van de GetSubscriber methode van de verbinding met de Redis-server. Vervolgens luistert u naar berichten op een kanaal met behulp van de SubscribeAsync methode van dit object. In het volgende codevoorbeeld ziet u hoe u zich abonneert op een kanaal met de naam 'messages:blogPosts':
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
await subscriber.SubscribeAsync("messages:blogPosts", (channel, message) => Console.WriteLine("Title is: {0}", message));
De eerste parameter voor de Subscribe methode is de naam van het kanaal. Deze naam volgt dezelfde conventies die worden gebruikt door sleutels in de cache. De naam kan binaire gegevens bevatten, maar we raden u aan relatief korte, zinvolle tekenreeksen te gebruiken om goede prestaties en onderhoudbaarheid te garanderen.
Houd er ook rekening mee dat de naamruimte die door kanalen wordt gebruikt, gescheiden is van de naamruimte die wordt gebruikt door sleutels. Dit betekent dat u kanalen en sleutels met dezelfde naam kunt hebben, hoewel uw toepassingscode hierdoor moeilijker te onderhouden is.
De tweede parameter is een gedelegeerde actie. Deze gemachtigde wordt asynchroon uitgevoerd wanneer er een nieuw bericht op het kanaal wordt weergegeven. In dit voorbeeld wordt gewoon het bericht op de console weergegeven (het bericht bevat de titel van een blogbericht).
Als u naar een kanaal wilt publiceren, kan een toepassing de opdracht Redis PUBLISH gebruiken. De StackExchange-bibliotheek biedt de IServer.PublishAsync methode om deze bewerking uit te voeren. In het volgende codefragment ziet u hoe u een bericht publiceert naar het kanaal 'messages:blogPosts':
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
BlogPost blogPost = ...;
subscriber.PublishAsync("messages:blogPosts", blogPost.Title);
Er zijn verschillende punten die u moet begrijpen over het mechanisme voor publiceren/abonneren:
- Meerdere abonnees kunnen zich abonneren op hetzelfde kanaal en ze ontvangen allemaal de berichten die naar dat kanaal zijn gepubliceerd.
- Abonnees ontvangen alleen berichten die zijn gepubliceerd nadat ze zich hebben geabonneerd. Kanalen worden niet gebufferd en zodra een bericht is gepubliceerd, wordt het bericht door de Redis-infrastructuur naar elke abonnee gepusht en vervolgens verwijderd.
- Berichten worden standaard ontvangen door abonnees in de volgorde waarin ze worden verzonden. In een zeer actief systeem met een groot aantal berichten en veel abonnees en uitgevers kan een gegarandeerde sequentiële bezorging van berichten de prestaties van het systeem vertragen. Als elk bericht onafhankelijk is en de volgorde niet belangrijk is, kunt u gelijktijdige verwerking door het Redis-systeem inschakelen, wat kan helpen de reactiesnelheid te verbeteren. U kunt dit in een StackExchange-client bereiken door de PreserveAsyncOrder in te stellen van de verbinding die door de abonnee wordt gebruikt op false:
ConnectionMultiplexer redisHostConnection = ...;
redisHostConnection.PreserveAsyncOrder = false;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
Serialisatieoverwegingen
Wanneer u een serialisatie-indeling kiest, kunt u rekening houden met de prestaties, interoperabiliteit, versiebeheer, compatibiliteit met bestaande systemen, gegevenscompressie en geheugenoverhead. Wanneer u de prestaties evalueert, moet u er rekening mee houden dat benchmarks zeer afhankelijk zijn van context. Ze weerspiegelen mogelijk niet uw werkelijke workload en overwegen mogelijk geen nieuwere bibliotheken of versies. Er is geen 'snelste' serializer voor alle scenario's.
Enkele opties om te overwegen zijn onder meer:
Protocolbuffers (ook wel protobuf genoemd) is een serialisatie-indeling die door Google is ontwikkeld voor het efficiënt serialiseren van gestructureerde gegevens. Er worden sterk getypte definitiebestanden gebruikt om berichtstructuren te definiëren. Deze definitiebestanden worden vervolgens gecompileerd naar taalspecifieke code voor het serialiseren en deserialiseren van berichten. Protobuf kan worden gebruikt via bestaande RPC-mechanismen of kan een RPC-service genereren.
Apache Thrift maakt gebruik van een vergelijkbare benadering, met sterk getypte definitiebestanden en een compilatiestap voor het genereren van de serialisatiecode en RPC-services.
Apache Avro biedt vergelijkbare functionaliteit als ProtocolBuffers en Thrift, maar er is geen compilatiestap. In plaats daarvan bevatten geserialiseerde gegevens altijd een schema waarin de structuur wordt beschreven.
JSON is een open standaard die gebruikmaakt van door mensen leesbare tekstvelden. Het biedt brede platformoverschrijdende ondersteuning. JSON maakt geen gebruik van berichtschema's. Als tekstopmaak is het niet erg efficiënt via de kabel. In sommige gevallen retourneert u echter mogelijk items in de cache rechtstreeks naar een client via HTTP. In dat geval kan het opslaan van JSON de kosten voor het deseriialiseren van een andere indeling besparen en vervolgens serialiseren naar JSON.
binary JSON (BSON) is een binaire serialisatie-indeling die gebruikmaakt van een structuur die vergelijkbaar is met JSON. BSON is ontworpen om lichtgewicht, gemakkelijk te scannen en snel te serialiseren en deserialiseren ten opzichte van JSON. Nettoladingen zijn vergelijkbaar met JSON. Afhankelijk van de gegevens kan een BSON-nettolading kleiner of groter zijn dan een JSON-nettolading. BSON heeft een aantal extra gegevenstypen die niet beschikbaar zijn in JSON, met name BinData (voor bytematrices) en Date.
MessagePack is een binaire serialisatie-indeling die is ontworpen om compact te zijn voor verzending via de kabel. Er zijn geen berichtschema's of controle van berichttypen.
Bond is een platformoverschrijdend framework voor het werken met geschematiseerde gegevens. Het ondersteunt serialisatie en deserialisatie in meerdere talen. Belangrijke verschillen van andere systemen die hier worden vermeld, zijn ondersteuning voor overname, typealiassen en generics.
gRPC is een opensource RPC-systeem dat is ontwikkeld door Google. Standaard wordt protocolbuffers gebruikt als definitietaal en onderliggende indeling voor berichtuitwisseling.
Volgende stappen
- Azure Cache voor Redis-documentatie
- Veelgestelde vragen over Azure Cache voor Redis
- Asynchroon patroon op basis van taken
- Documentatie voor Redis
- StackExchange.Redis
- Handleiding voor gegevenspartitionering
Verwante middelen
De volgende patronen zijn mogelijk ook relevant voor uw scenario wanneer u caching in uw toepassingen implementeert:
Cache-aside-patroon: In dit patroon wordt beschreven hoe u gegevens op aanvraag in een cache laadt vanuit een gegevensarchief. Dit patroon helpt ook om consistentie te behouden tussen gegevens die zijn opgeslagen in de cache en de gegevens in het oorspronkelijke gegevensarchief.
Het Sharding-patroon biedt informatie over het implementeren van horizontale partitionering om de schaalbaarheid te verbeteren bij het opslaan en openen van grote hoeveelheden gegevens.