Gedistribueerde toepassingen en services die worden uitgevoerd in de cloud zijn van nature complexe stukjes software die veel bewegende onderdelen bevatten. In een productieomgeving is het belangrijk dat u de manier kunt bijhouden waarop gebruikers uw systeem gebruiken, het resourcegebruik traceren en over het algemeen de status en prestaties van uw systeem bewaken. U kunt deze informatie gebruiken als een diagnostisch hulpmiddel om problemen op te sporen en op te lossen, en ook om te helpen potentiële problemen op te sporen en te voorkomen dat deze zich voordoen.
Scenario's voor bewaking en diagnose
U kunt bewaking gebruiken om een beter inzicht te krijgen in hoe goed een systeem werkt. Bewaking is een essentieel onderdeel van het onderhoud van de doelen voor servicekwaliteit. Algemene scenario's voor het verzamelen van bewakingsgegevens zijn onder andere:
- Ervoor zorgen dat het systeem in orde blijft.
- Het bijhouden van de beschikbaarheid van het systeem en de bijbehorende onderdelen.
- Goede prestaties bijhouden om ervoor te zorgen dat de doorvoer van het systeem niet onverwacht degradeert als het werkvolume toeneemt.
- Garanderen dat het systeem voldoet aan service level agreements (SLA's) met klanten.
- De privacy en beveiliging van het systeem, de gebruikers en hun gegevens beschermen.
- Het bijhouden van de bewerkingen die worden uitgevoerd voor controle of regelgeving.
- Het bewaken van het dagelijkse gebruik van het systeem en het ontdekken van trends die tot problemen kunnen leiden, als ze niet worden opgelost.
- Het bijhouden van problemen die optreden vanaf de eerste rapportage tot de analyse van mogelijke oorzaken, rectificatie, daaropvolgende software-updates en implementatie.
- Bewerkingen traceren en foutopsporing van softwareversies.
Notitie
Deze lijst is niet bedoeld om veelomvattend te zijn. Dit document is gericht op deze scenario's als de meest voorkomende situaties voor het uitvoeren van bewaking. Mogelijk zijn er andere die minder gangbaar zijn, of specifiek voor uw omgeving.
De volgende secties beschrijven deze scenario's in meer detail. De informatie voor elk scenario wordt beschreven in de volgende indeling:
- Een kort overzicht van het scenario.
- De typische vereisten van dit scenario.
- De onbewerkte instrumentatiegegevens die nodig zijn voor de ondersteuning van het scenario en mogelijke bronnen van deze informatie.
- Hoe deze onbewerkte gegevens kunnen worden geanalyseerd en gecombineerd om zinvolle diagnostische informatie te genereren.
Statuscontrole
Een systeem is in orde als het wordt uitgevoerd en aanvragen kan verwerken. Het doel van de statuscontrole is het genereren van een momentopname van de huidige status van het systeem, zodat u kunt controleren of alle onderdelen van het systeem werken zoals verwacht.
Vereisten voor statuscontrole
Een operator moet snel (binnen een paar seconden) worden gewaarschuwd als een deel van het systeem als niet in orde wordt beschouwd. De operator moet in staat zijn om na te gaan welke onderdelen van het systeem normaal functioneren en bij welke onderdelen zich problemen voordoen. De systeemstatus kan worden gemarkeerd via een verkeerslichtsysteem:
- Rood voor niet in orde (het systeem is gestopt)
- Geel voor gedeeltelijk in orde (het systeem wordt uitgevoerd met verminderde functionaliteit)
- Groen voor volledig in orde
Een uitgebreid systeem voor statuscontrole stelt een operator in staat om in te zoomen via het systeem om de status van de subsystemen en onderdelen weer te geven. Als het algehele systeem bijvoorbeeld wordt weergegeven als gedeeltelijk in orde, moet de operator kunnen inzoomen en bepalen welke functionaliteit momenteel niet beschikbaar is.
Vereisten voor gegevensbronnen, instrumentatie en gegevensverzameling
De onbewerkte gegevens die vereist zijn ter ondersteuning van statuscontrole kunnen worden gegenereerd als gevolg van:
- Het traceren van de uitvoering van gebruikersaanvragen. Deze informatie kan worden gebruikt om te bepalen welke aanvragen zijn geslaagd, welke zijn mislukt en hoelang elke aanvraag duurt.
- Synthetische gebruikersbewaking. Dit proces simuleert de stappen die worden uitgevoerd door een gebruiker en volgt een vooraf gedefinieerde reeks stappen. De resultaten van elke stap moeten worden vastgelegd.
- Logboekregistratie van uitzonderingen, fouten en waarschuwingen. Deze informatie kan worden vastgelegd als gevolg van de traceringsinstructies die in de toepassingscode zijn ingesloten, evenals het ophalen van gegevens uit de gebeurtenislogboeken van de services waarnaar het systeem verwijst.
- De status bewaken van de services van derden die het systeem gebruikt. Deze bewaking moet mogelijk statusgegevens ophalen en parseren die door deze services worden geleverd. Deze informatie heeft mogelijk een aantal verschillende indelingen nodig.
- Eindpuntbewaking. Dit mechanisme wordt uitgebreid beschreven in de sectie 'Beschikbaarheid bewaken'.
- Verzamelen van informatie over omgevingsprestaties, zoals CPU-gebruik of I/O-activiteit op de achtergrond (inclusief netwerk).
Statusgegevens analyseren
De primaire focus van de statuscontrole is snel aangeven of het systeem wordt uitgevoerd. Hot-analyse van de directe gegevens kan een waarschuwing activeren als een essentieel onderdeel wordt gedetecteerd als niet in orde. (Het reageert bijvoorbeeld niet op een opeenvolgende reeks pings.) De operator kan vervolgens de juiste corrigerende actie ondernemen.
Een geavanceerder systeem kan een voorspellend element bevatten waarmee een cold-analyse wordt uitgevoerd via recente en huidige werkbelastingen. Een cold-analyse kan actuele trends ontdekken en bepalen of het systeem waarschijnlijk in orde blijft of toch aanvullende resources nodig heeft. Dit voorspellende element moet worden gebaseerd op kritieke prestatiegegevens, zoals:
- De snelheid van aanvragen die gericht zijn op elke service of elk subsysteem.
- De reactietijden van deze aanvragen.
- De hoeveelheid gegevens die binnenkomt naar en van elke service.
Als de waarde van een willekeurige statistiek een opgegeven drempelwaarde overschrijdt, kan het systeem een waarschuwing geven om een operator of automatisch schalen (indien beschikbaar) in te schakelen, om de preventieve acties uit te voeren die nodig zijn voor het onderhouden van de systeemstatus. Deze acties kunnen bestaan uit het toevoegen van resources, het opnieuw starten van een of meer services die zijn mislukt of het beperken van de bandbreedte van aanvragen met lagere prioriteit.
Bewaking op beschikbaarheid
Een systeem dat echt in orde is, vereist dat de onderdelen en subsystemen waaruit het systeem bestaat, beschikbaar zijn. Bewaking op beschikbaarheid is nauw verwant aan de statuscontrole. Maar waar statuscontrole onmiddellijk een overzicht van de huidige status van het systeem biedt, is bewaking op beschikbaarheid betrokken bij het bijhouden van de beschikbaarheid van het systeem en de bijbehorende onderdelen voor het genereren van statistieken over de uptime van het systeem.
In veel systemen wordt een aantal onderdelen (zoals een database) geconfigureerd met ingebouwde redundantie om snelle failover toe te staan in geval van een ernstige fout of verlies van verbinding. In het ideale geval mogen gebruikers niet merken dat deze fout is opgetreden. Maar vanuit het perspectief van beschikbaarheidsbewaking is het nodig zoveel mogelijk informatie te verzamelen over deze fouten om de oorzaak te bepalen en corrigerende maatregelen te nemen om te voorkomen dat ze in de toekomst weer voorkomen.
De gegevens die nodig zijn om de beschikbaarheid te bewaken, kan afhankelijk zijn van een aantal factoren van lager niveau. Veel van deze factoren zijn mogelijk specifiek voor de toepassing, het systeem en de omgeving. Een effectief bewakingssysteem legt de beschikbaarheidsgegevens vast die overeenkomen met deze factoren op laag niveau en verzamelt deze vervolgens om een overzicht van het systeem te geven. De zakelijke functionaliteit in een e-commerce-systeem dat het klanten mogelijk maakt om opdrachten te plaatsen, is bijvoorbeeld afhankelijk van de opslagplaats waar ordergegevens worden opgeslagen en het betalingssysteem dat verantwoordelijk is voor de financiële transacties voor het betalen voor deze orders. De beschikbaarheid van het onderdeel voor orderplaatsing van het systeem is daarom een functie van de beschikbaarheid van de opslagplaats en het subsysteem voor betalingen.
Vereisten voor de bewaking op beschikbaarheid
Een operator moet ook de historische beschikbaarheid van elk systeem en subsysteem kunnen zien en deze informatie kunnen gebruiken om trends te herkennen die kunnen leiden tot periodiek mislukken van een of meer subsystemen. (Beginnen services te mislukken op een bepaald tijdstip van de dag, dat overeenkomt met piekuren in het proces?)
bewakingsoplossing moet een onmiddellijke en historische weergave bieden van de beschikbaarheid of onbeschikbaarheid van elk subsysteem. Ook moet het snel een operator kunnen waarschuwen wanneer een of meer services mislukken of wanneer gebruikers geen verbinding met de services kunnen maken. Hierbij moet niet alleen elke service worden bewaakt, maar er moet ook worden gekeken naar de acties die door elke gebruiker worden uitgevoerd, als deze acties mislukken bij pogingen om te communiceren met een service. Tot op zekere hoogte is het normaal dat er verbindingsfouten voorkomen. Deze worden mogelijk veroorzaakt door tijdelijke fouten. Maar het is mogelijk handig om het systeem toe te staan een waarschuwing te activeren voor het aantal verbindingsfouten in een specifieke periode van een opgegeven subsysteem.
Vereisten voor gegevensbronnen, instrumentatie en gegevensverzameling
Net als bij statuscontrole kunnen de onbewerkte gegevens die vereist zijn ter ondersteuning van de bewaking op beschikbaarheid worden gegenereerd als gevolg van synthetische gebruikersbewaking en het registreren van eventuele uitzonderingen, fouten en waarschuwingen die kunnen optreden. Gegevens over de beschikbaarheid kunnen bovendien worden verkregen door het uitvoeren van eindpuntbewaking. De toepassing kan een of meer statuseindpunten blootstellen, die elk de toegang tot een functioneel gebied in het systeem testen. Het bewakingssysteem kan elk eindpunt pingen volgens een gedefinieerde planning en de resultaten (slagen of mislukken) verzamelen.
Alle time-outs, netwerkverbindingsfouten en nieuwe verbindingspogingen moeten worden geregistreerd. Alle gegevens moeten tijdstempel hebben.
Gegevens over de beschikbaarheid analyseren
De instrumentatiegegevens moeten worden samengevoegd en gecorreleerd ter ondersteuning van de volgende soorten analyse:
- De onmiddellijke beschikbaarheid van het systeem en de subsystemen.
- Het uitvalpercentage van de beschikbaarheid van het systeem en de subsystemen. In het ideale geval moet een operator fouten kunnen correleren met specifieke activiteiten: wat gebeurde er toen er een fout in het systeem optrad?
- Een historisch overzicht van de foutfrequenties van het systeem of de subsystemen over een opgegeven periode en de belasting op het systeem (aantal aanvragen van gebruikers, bijvoorbeeld) toen er een fout optrad.
- De redenen voor de onbeschikbaarheid van het systeem of een subsysteem. De redenen kunnen zijn: service niet actief, connectiviteit verloren, verbonden maar er treedt een time-out op, verbonden maar retourneert fouten.
U kunt het beschikbaarheidspercentage van een service gedurende een periode berekenen met behulp van de volgende formule:
%Availability = ((Total Time – Total Downtime) / Total Time ) * 100
Dit is handig voor de SLA. (SLA-bewaking wordt verderop in deze richtlijnen uitgebreider beschreven.) De definitie van downtime is afhankelijk van de service. Visual Studio Team Services Build Service definieert downtime bijvoorbeeld als de periode (totaal aantal samengevoegde minuten) waarbinnen Build Service niet beschikbaar is. Een minuut wordt beschouwd als niet-beschikbaar als alle achtereenvolgende HTTP-verzoeken aan Build Service voor de uitvoering van bewerkingen, gestart door de klant, gedurende die minuut resulteren in een foutcode, of geen reactie retourneren.
Prestatiebewaking
Als het systeem onder steeds zwaardere belasting wordt geplaatst (door het verhogen van het aantal gebruikers), neemt de grootte van de gegevenssets waartoe deze gebruikers toegang hebben toe en wordt de kans op uitval van een of meer onderdelen groter. Onderdeelfouten worden vaak voorafgegaan door een afname in de prestaties. Als u een dergelijke afname detecteert, kunt u proactieve stappen nemen om de situatie op te lossen.
De systeemprestaties zijn afhankelijk van een aantal factoren. Elke factor wordt gewoonlijk gemeten via Key Performance Indicators (KPI's), zoals het aantal databasetransacties per seconde of het aantal netwerkaanvragen dat met succes wordt onderhouden in een opgegeven periode. Sommige van deze KPI's zijn mogelijk beschikbaar als specifieke prestatiemeters, terwijl andere kunnen worden afgeleid uit een combinatie van metrische gegevens.
Notitie
Het bepalen van slechte of goede prestaties vereist dat u weet op welk prestatieniveau het systeem moet kunnen lopen. Dit vereist observatie van het systeem terwijl het bij een normale belasting werkt en het vastleggen van gegevens voor elke KPI gedurende een bepaalde periode. Dit kan betekenen dat u het systeem bij een gesimuleerde belasting in een testomgeving moet uitvoeren en de juiste gegevens moet verzamelen, voordat u het systeem in een productieomgeving implementeert.
U moet er ook voor zorgen dat bewaking voor prestatiedoeleinden geen belasting voor het systeem wordt. U kunt mogelijk het detailniveau voor de gegevens die door de prestatiecontrole worden verzameld dynamisch aanpassen.
Vereisten voor de bewaking van prestaties
Als u systeemprestaties wilt onderzoeken, moet de informatie die een operator ziet doorgaans het volgende bevatten:
- De frequenties van reacties op aanvragen van gebruikers.
- Het aantal gelijktijdige aanvragen van gebruikers.
- Het volume van het netwerkverkeer.
- De frequenties volgens welke zakelijke transacties worden uitgevoerd.
- De gemiddelde verwerkingstijd voor aanvragen.
Het kan ook handig zijn om hulpmiddelen te bieden waarmee een operator ter plaatse correlaties kan ontdekken, zoals:
- Het aantal gelijktijdige gebruikers ten opzichte van de latentietijden (hoelang het duurt om een aanvraag te verwerken nadat de gebruiker deze heeft verzonden).
- Het aantal gelijktijdige gebruikers ten opzichte van de gemiddelde reactietijd (hoelang het duurt om een aanvraag te voltooien nadat is gestart met het verwerken).
- Het volume van aanvragen ten opzichte van het aantal verwerkingsfouten.
Samen met deze functionele informatie op hoog niveau moet een operator een gedetailleerde weergave kunnen verkrijgen van de prestaties voor elk onderdeel in het systeem. Deze gegevens worden meestal verzorgd door middel van prestatiemeteritems van laag niveau, waarmee gegevens worden bijgehouden zoals:
- Geheugengebruik.
- Het aantal threads.
- CPU-verwerkingstijd.
- Lengte van de wachtrij voor aanvragen.
- I/O-frequenties en fouten van schijf of netwerk.
- Het aantal geschreven of gelezen bytes.
- Middleware indicatoren, zoals wachtrijlengte.
Alle visualisaties moeten een operator toestaan een bepaalde tijdsperiode op te geven. De weergegeven gegevens kunnen een momentopname zijn van de huidige situatie of een historisch overzicht van de prestaties.
Een operator moet de mogelijkheid hebben om een waarschuwing te geven op basis van elke prestatiemeting voor elke opgegeven waarde tijdens een opgegeven tijdsinterval.
Vereisten voor gegevensbronnen, instrumentatie en gegevensverzameling
U kunt op hoog niveau prestatiegegevens (doorvoer, het aantal gelijktijdige gebruikers, aantal zakelijke transacties, foutfrequenties, enzovoort) verzamelen met de bewaking van de voortgang van gebruikersaanvragen wanneer deze het systeem binnenkomen en worden verwerkt. Hierbij moet u instructies voor het traceren van de belangrijkste punten in de toepassingscode gebruiken, in combinatie met klokinformatie. Alle fouten, uitzonderingen en waarschuwingen moeten worden vastgelegd met voldoende gegevens om ze te correleren met de aanvragen waardoor ze zijn veroorzaakt. Het logboek van Internet Information Services (IIS) is een andere nuttige bron.
Indien mogelijk moet u ook prestatiegegevens vastleggen voor externe systemen die de toepassing gebruikt. Deze externe systemen kunnen hun eigen prestatiemeteritems leveren, of andere functies voor het aanvragen van prestatiegegevens. Als dit niet mogelijk is, registreer dan informatie zoals de begintijd en eindtijd van elke aanvraag aan een extern systeem, samen met de status van de bewerking (geslaagd, mislukt of waarschuwing). U kunt bijvoorbeeld een stopwatch-benadering gebruiken om de tijd van aanvragen vast te leggen: start een timer wanneer de aanvraag wordt gestart en stop de timer als de aanvraag is voltooid.
Prestatiegegevens van laag niveau voor afzonderlijke onderdelen in een systeem zijn mogelijk beschikbaar via functies en services, zoals Windows-prestatiemeteritems en Azure Diagnostics.
Prestatiegegevens analyseren
Veel van de analysewerkzaamheden bestaan uit het aggregeren van prestatiegegevens op gebruikersaanvraagtype of het subsysteem of de service waarnaar elke aanvraag wordt verzonden. Een voorbeeld van een gebruikersaanvraag is het toevoegen van een item aan een winkelwagen of het afrekenen in een e-commerce-systeem.
Een andere algemene vereiste is het samenvatten van prestatiegegevens in geselecteerde percentielen. Een operator kan bijvoorbeeld de reactietijden voor 99 procent van de aanvragen, 95 procent van de aanvragen en 70 procent van de aanvragen bepalen. Er zijn mogelijk SLA-doelen of andere doelstellingen voor elke percentiel ingesteld. De lopende resultaten moeten worden gerapporteerd in bijna realtime om te helpen met het detecteren van onmiddellijke problemen. De resultaten moeten ook over langere tijd worden verzameld voor statistische doeleinden.
In het geval van latentieproblemen met prestaties moet een operator snel de oorzaak van het knelpunt kunnen identificeren door de latentie van elke stap die elke aanvraag uitvoert te controleren. De prestatiegegevens moeten daarom een methode opgeven voor het correleren van de prestatiemeters voor elke stap, om ze te koppelen aan een specifieke aanvraag.
Afhankelijk van de vereisten voor visualisatie kan het nuttig zijn een gegevenskubus die weergaven van de onbewerkte gegevens bevat te genereren en op te slaan. Deze gegevenskubus kan het uitvoeren van complexe ad-hoc query's en analyse van de informatie over de prestaties mogelijk maken.
Controleren van beveiliging
Alle commerciële systemen die gevoelige gegevens bevatten, moeten een beveiligingsstructuur implementeren. De complexiteit van het beveiligingsmechanisme is meestal een functie van de vertrouwelijkheid van de gegevens. In een systeem waarin gebruikers moeten worden geverifieerd, moet u het volgende opnemen:
- Alle aanmeldpogingen, of ze nu mislukken of slagen.
- Alle bewerkingen die worden uitgevoerd door ( en de details van alle resources die worden geopend door) een geverifieerde gebruiker.
- Wanneer een gebruiker een sessie beëindigt en zich afmeldt.
Bewaking helpt mogelijk met het detecteren van aanvallen op het systeem. Een groot aantal mislukte aanmeldingspogingen kan bijvoorbeeld duiden op een brute-force-aanval. Een onverwachte piek in aanvragen is mogelijk het resultaat van een DDoS-aanval (gedistribueerde denial-of-service). U moet voorbereid zijn op het bewaken van alle aanvragen voor alle resources, ongeacht de bron van deze aanvragen. Een systeem dat een beveiligingsprobleem bij het aanmelden heeft, kan mogelijk per ongeluk resources naar de buitenwereld zichtbaar maken, zonder dat een gebruiker zich daadwerkelijk moet aanmelden.
Vereisten voor de beveiligingsbewaking
De belangrijkste aspecten van beveiligingsbewaking moeten een operator in staat stellen het volgende te doen:
- Pogingen tot binnendringen door een niet-geverifieerde entiteit detecteren.
- Pogingen door entiteiten identificeren om bewerkingen uit te voeren op gegevens waarvoor ze geen toegang hebben gekregen.
- Bepalen of het systeem, of een deel van het systeem, van buiten of binnen wordt aangevallen. (Bijvoorbeeld een kwaadwillende geverifieerde gebruiker die het systeem probeert te saboteren.)
Ter ondersteuning van deze vereisten moet een operator op de hoogte worden gesteld als:
- Eén account maakt herhaalde mislukte aanmeldingspogingen binnen een opgegeven periode.
- Eén geverifieerd account probeert herhaaldelijk toegang te krijgen tot een verboden resource gedurende een opgegeven periode.
- Een groot aantal niet-geverifieerde of niet-geautoriseerde aanvragen vindt plaats tijdens een opgegeven periode.
De informatie die wordt gegeven aan een operator moet het hostadres van de bron van elke aanvraag bevatten. Als er regelmatig schendingen van de beveiliging uit een bepaald bereik van adressen optreden, worden deze hosts mogelijk geblokkeerd.
Een belangrijk onderdeel in het onderhouden van de beveiliging van een systeem is het snel in staat zijn om acties te detecteren die van het gebruikelijke patroon afwijken. Informatie zoals het aantal mislukte of geslaagde aanmeldingsaanvragen kan visueel worden weergegeven om te detecteren of er een piek in de activiteit op een ongebruikelijk tijdstip is. (Een voorbeeld van deze activiteit is dat gebruikers zich om 03:00 uur 's nachts aanmelden en een groot aantal bewerkingen uitvoeren, terwijl hun werkdag om 09:00 uur start). Deze informatie kan ook worden gebruikt voor het configureren van automatisch schalen op basis van tijd. Als een operator bijvoorbeeld ziet dat een groot aantal gebruikers zich regelmatig op een bepaald tijdstip van de dag aanmeldt, kan de operator aanvullende verificatieservices starten voor het verwerken van de hoeveelheid werk en vervolgens deze extra services afsluiten wanneer de piek voorbij is.
Vereisten voor gegevensbronnen, instrumentatie en gegevensverzameling
Beveiliging is een alomvattend aspect van de meeste gedistribueerde systemen. De relevante gegevens worden waarschijnlijk op meerdere punten in een systeem gegenereerd. Overweeg gebruik te maken van een SIEM-benadering (Security Information and Event Management) voor het verzamelen van de beveiligingsinformatie, die het resultaat is van gebeurtenissen die tot stand komen door de toepassing, netwerkapparatuur, servers, firewalls, antivirussoftware en andere elementen ter preventie van onrechtmatige toegang.
Beveiligingsbewaking kan gebruikmaken van gegevens van hulpprogramma's die geen deel uitmaken van uw toepassing. Deze hulpprogramma's kunnen werktuigen zijn die activiteiten identificeren, zoals het scannen van poorten door externe organisaties, of netwerkfilters die pogingen van niet-geverifieerde toegang tot uw toepassing en gegevens detecteren.
In alle gevallen moeten de verzamelde gegevens een beheerder in staat stellen om de aard van een aanval te bepalen en de juiste tegenmaatregelen te nemen.
Beveiligingsgegevens analyseren
Een kenmerk van beveiligingsbewaking is de verscheidenheid aan bronnen waaruit de gegevens voortkomen. De verschillende indelingen en de mate van detail vereisen vaak een complexe analyse van de vastgelegde gegevens om ze in een samenhangende thread van informatie met elkaar te kunnen verbinden. Behalve de eenvoudigste gevallen (zoals het detecteren van een groot aantal mislukte aanmeldingen of herhaalde pogingen voor onbevoegde toegang tot kritieke bronnen), kan het onmogelijk zijn om complexe geautomatiseerde verwerking van de beveiligingsgegevens uit te voeren. In plaats daarvan is het misschien beter om deze gegevens, tijdstempel, maar anders in de oorspronkelijke vorm, te schrijven naar een beveiligde opslagplaats om een deskundige handmatige analyse mogelijk te maken.
SLA-bewaking
Veel commerciële systemen die ondersteuning bieden aan betalende klanten, geven garanties over de prestaties van het systeem in de vorm van SLA's. In wezen staat in SLA's dat een bepaald werkvolume, binnen een overeengekomen tijdsbestek en zonder verlies van kritieke gegevens, kan worden verwerkt door het systeem. SLA-bewaking heeft betrekking op het zorgen dat het systeem kan voldoen aan meetbare SLA's.
Notitie
SLA-bewaking is nauw verwant aan prestatiebewaking. Maar waar prestatiebewaking zich bezighoudt met ervoor zorgen dat het systeem optimaal functioneert, wordt SLA-bewaking bepaald door een contractuele verplichting die definieert wat optimaal daadwerkelijk betekent.
SLA's zijn vaak gedefinieerd in termen van:
- Algemene beschikbaarheid van het systeem. Een organisatie kan bijvoorbeeld garanderen dat het systeem 99,9 procent van de tijd beschikbaar is. Dit is gelijk aan maximaal 9 uur downtime per jaar, of ongeveer 10 minuten per week.
- Operationele doorvoer. Dit aspect wordt vaak uitgedrukt als een of meer bovengrenzen, zoals een garantie dat het systeem maximaal 100.000 gelijktijdige gebruikersaanvragen kan ondersteunen, of 10.000 gelijktijdige zakelijke transacties kan verwerken.
- Operationele reactietijd. Het systeem kan ook garanties geven met betrekking tot de snelheid waarmee aanvragen worden verwerkt. Een voorbeeld is dat 99 procent van alle zakelijke transacties binnen 2 seconden wordt voltooid en geen enkele transactie langer dan 10 seconden duurt.
Notitie
Sommige contracten voor commerciële systemen kunnen ook SLA's bevatten voor klantondersteuning. Een voorbeeld hiervan is dat alle helpdeskaanvragen binnen vijf minuten een reactie veroorzaken en dat 99 procent van alle problemen binnen 1 werkdag volledig wordt aangepakt. Effectief problemen bijhouden (verderop in dit gedeelte) is essentieel om aan SLA's zoals deze te voldoen.
Vereisten voor SLA-bewaking
Op het hoogste niveau moet een operator in een oogopslag kunnen vaststellen of het systeem al dan niet voldoet aan de overeengekomen SLA's. En als dat niet zo is, moet de operator naar beneden kunnen inzoomen en de onderliggende factoren kunnen onderzoeken om de redenen voor inferieure prestaties te bepalen.
Typische indicatoren op hoog niveau die visueel kunnen worden weergegeven, zijn onder andere:
- Het percentage van uptime van de service.
- De doorvoer van de toepassing (gemeten in termen van geslaagde transacties of bewerkingen per seconde).
- Het aantal geslaagde/mislukte toepassingsaanvragen.
- Het aantal toepassings- en systeemfouten, -uitzonderingen en -waarschuwingen.
Al deze indicatoren moeten kunnen worden gefilterd voor een opgegeven periode.
Een cloudtoepassing zal waarschijnlijk bestaan uit een aantal subsystemen en onderdelen. Een operator moet een belangrijke indicator kunnen selecteren en zien hoe de status van de onderliggende elementen deze indicator bepaalt. Als de uptime van het algehele systeem bijvoorbeeld minder is dan een acceptabele waarde, moet een operator kunnen inzoomen en bepalen welke elementen bijdragen aan deze fout.
Notitie
Uptime van het systeem moet zorgvuldig worden gedefinieerd. In een systeem dat gebruikmaakt van redundantie om maximale beschikbaarheid te garanderen, kunnen afzonderlijke instanties van elementen mislukken, terwijl het systeem functioneel kan blijven. Uptime van het systeem zoals weergegeven door statuscontrole zou de cumulatieve uptime van elk element moeten aangeven en niet noodzakelijkerwijs of het systeem daadwerkelijk is gestopt. Bovendien kunnen fouten mogelijk worden geïsoleerd. Dus zelfs als een specifiek systeem niet beschikbaar is, kan de rest van het systeem beschikbaar blijven, zij het met verminderde functionaliteit. (Een fout in een e-commerce-systeem kan ervoor zorgen dat een klant geen orders kan plaatsen, maar de klant kan mogelijk nog steeds door de productcatalogus bladeren.)
Met het oog op waarschuwingen moet het systeem een gebeurtenis kunnen genereren als een van de indicatoren op hoog niveau een opgegeven drempelwaarde overschrijdt. De details op lager niveau van de diverse factoren waaruit de indicator op hoog niveau bestaat, moeten beschikbaar zijn als contextuele gegevens voor het waarschuwende systeem.
Vereisten voor gegevensbronnen, instrumentatie en gegevensverzameling
De onbewerkte gegevens die vereist zijn ter ondersteuning van SLA-bewaking zijn vergelijkbaar met de onbewerkte gegevens die vereist zijn voor de prestatiebewaking, samen met enkele aspecten van de status- en beschikbaarheidsbewaking. (Zie deze secties voor meer informatie.) U kunt deze gegevens vastleggen door:
- Eindpuntbewaking uit te voeren.
- Logboekregistratie van uitzonderingen, fouten en waarschuwingen.
- Het uitvoeren van gebruikersaanvragen te traceren.
- De beschikbaarheid te bewaken van de services van derden die het systeem gebruikt.
- Tellers en metrische prestatiegegevens te gebruiken.
Alle gegevens moeten zijn getimed en tijdstempel.
SLA-gegevens analyseren
De instrumentatiegegevens moeten worden samengevoegd om een beeld van de algehele prestaties van het systeem te genereren. Cumulatieve gegevens moeten ook inzoomen ondersteunen, om het onderzoek van de prestaties van de onderliggende subsystemen mogelijk te maken. Wat u bijvoorbeeld moet kunnen:
- Het totale aantal aanvragen van gebruikers gedurende een bepaalde periode berekenen en de frequentie van slagen en mislukken van deze aanvragen bepalen.
- De reactietijden van gebruikersaanvragen combineren om een algemeen overzicht van systeemreactietijden te genereren.
- De voortgang van aanvragen van gebruikers analyseren om de totale reactietijd van een aanvraag op te splitsen in de reactietijden van de afzonderlijke werkitems in die aanvraag.
- De algemene beschikbaarheid van het systeem als een percentage van uptime voor een bepaalde periode bepalen.
- Het percentage tijdsbeschikbaarheid van de afzonderlijke onderdelen en services in een systeem analyseren. Hierbij moeten mogelijk de logboeken die door services van derden zijn gegenereerd worden geparseerd.
Veel commerciële systemen zijn verplicht echte prestatiecijfers te rapporteren in verhouding tot overeengekomen SLA's voor een opgegeven periode, meestal een maand. Deze informatie kan worden gebruikt voor het berekenen van tegoed of andere vormen van terugbetalingen voor klanten als in die periode niet aan de SLA's is voldaan. U kunt de beschikbaarheid van een service berekenen met behulp van de techniek die beschreven is in de sectie Gegevens over de beschikbaarheid analyseren.
Een organisatie kan voor interne doeleinden ook het aantal en de aard van incidenten waardoor services mislukken bijhouden. Leren hoe u deze problemen snel kunt oplossen, of deze volledig kunt voorkomen, helpt met het beperken van de downtime en voldoen aan de SLA's.
Controle
Afhankelijk van de aard van de toepassing zijn er mogelijk statutaire of andere wettelijke voorschriften die vereisten opgeven voor de controle op bewerkingen van gebruikers en het vastleggen van alle datatoegang. Controle kan bewijzen leveren die klanten koppelen aan specifieke aanvragen. Nonrepudiation is een belangrijke factor in veel e-business systemen om vertrouwen te behouden tussen een klant en de organisatie die verantwoordelijk is voor de toepassing of service.
Vereisten voor controle
Een analist moet de volgorde van de zakelijke activiteiten kunnen traceren die gebruikers uitvoeren, zodat u de acties van gebruikers kunt reconstrueren. Dit kan nodig zijn voor registratie, of als onderdeel van een forensisch onderzoek.
Controlegegevens zijn uiterst gevoelig. Deze bevatten waarschijnlijk gegevens waarmee de gebruikers van het systeem en de taken die ze uitvoeren, kunnen worden geïdentificeerd. Om deze reden hebben controlegegevens waarschijnlijk eerder de vorm van rapporten die alleen beschikbaar zijn voor vertrouwde analisten, dan van een interactief systeem dat het inzoomen op grafische bewerkingen ondersteunt. Een analist moet in staat zijn om een bereik van rapporten te genereren. Rapporten kunnen bijvoorbeeld een lijst bevatten met alle gebruikersactiviteiten gedurende een opgegeven periode, details van een tijdlijn van de activiteit voor één gebruiker of een lijst met de volgorde van bewerkingen die worden uitgevoerd op een of meer resources.
Vereisten voor gegevensbronnen, instrumentatie en gegevensverzameling
De primaire bronnen met informatie voor controle kunnen het volgende bevatten:
- Het beveiligingssysteem waarmee de verificatie van gebruikers wordt beheerd.
- Logboeken met traceringen die gebruikersactiviteit vastleggen.
- Beveiligingslogboeken die alle identificeerbare en niet-identificeerbare netwerkaanvragen bijhouden.
De indeling van de audit-gegevens en de manier waarop deze zijn opgeslagen, kan worden aangestuurd door juridische vereisten. Het kan bijvoorbeeld onmogelijk zijn de gegevens op wat voor manier dan ook op te schonen. (Deze moet worden opgenomen in de oorspronkelijke indeling.) Toegang tot de opslagplaats waar deze wordt bewaard, moet worden beveiligd om manipulatie te voorkomen.
Analyseren van controlegegevens
Een analist moet toegang kunnen krijgen tot het geheel van de onbewerkte gegevens, in de oorspronkelijke vorm. De hulpprogramma's voor het analyseren van deze gegevens moeten niet alleen algemene controlerapporten genereren, maar zijn waarschijnlijk ook gespecialiseerd en worden afzonderlijk gehouden van het systeem.
Gebruiksbewaking
Gebruiksbewaking houdt bij hoe de functies en onderdelen van een toepassing worden gebruikt. Een operator kan de verzamelde gegevens gebruiken om:
Te bepalen welke functies intensief worden gebruikt en eventuele mogelijke hotspots in het systeem te bepalen. Elementen met intensief verkeer hebben mogelijk baat bij functionele partitionering of zelfs replicatie om de belasting meer evenredig te verdelen. Een operator kan deze informatie ook gebruiken om na te gaan welke functies zelden worden gebruikt en dus buiten gebruik kunnen worden gesteld of kunnen worden vervangen in een toekomstige versie van het systeem.
Verzamel informatie over de operationele gebeurtenissen van het systeem bij normaal gebruik. U kunt bijvoorbeeld in een e-commerce-site de statistische informatie over het aantal transacties en het volume van klanten die hiervoor verantwoordelijk zijn vastleggen. Deze informatie kan worden gebruikt voor het plannen van capaciteit wanneer het aantal klanten groeit.
Detecteer (mogelijk indirect) de tevredenheid van de gebruikers met de prestaties of de functionaliteit van het systeem. Als bijvoorbeeld een groot aantal klanten in een e-commerce-systeem regelmatig hun winkelwagen afbreken, is dit mogelijk vanwege een probleem met de afhandelingsfunctionaliteit.
Factureringsgegevens genereren. Een commerciële toepassing of service met meerdere tenants brengt mogelijk kosten in rekening aan klanten voor de resources die ze gebruiken.
Quota afdwingen. Als een gebruiker in een systeem met meerdere tenants zijn betaalde quotum voor de verwerkingstijd of het resourcegebruik gedurende een bepaalde periode overschrijdt, kan zijn toegang worden beperkt of de verwerking worden beperkt.
Vereisten voor gebruiksbewaking
Als u systeemprestaties wilt onderzoeken, moet de informatie die een operator kan zien doorgaans het volgende bevatten:
- Het aantal aanvragen dat wordt verwerkt door elk subsysteem en omgeleid naar elke resource.
- Het werk dat elke gebruiker uitvoert.
- Het volume van de gegevensopslag dat elke gebruiker in beslag neemt.
- De bronnen waartoe elke gebruiker toegang heeft.
Ook moet een operator grafieken kunnen genereren. Een grafiek kan bijvoorbeeld de gebruikers weergeven die de meeste resources opeisen, of de meest aangesproken resources of systeemfuncties.
Vereisten voor gegevensbronnen, instrumentatie en gegevensverzameling
Gebruik bijhouden kan worden uitgevoerd op een relatief hoog niveau. Het kan de begin- en eindtijden van iedere aanvraag en de aard van de aanvraag (lezen, schrijven, enzovoort, afhankelijk van de betreffende resource) noteren. U vindt deze informatie door:
- Gebruikersactiviteit te traceren.
- Prestatiemeteritems vast te leggen die het gebruik meten voor elke resource.
- Het resourcegebruik door elke gebruiker te bewaken.
Voor metingdoeleinden moet u ook kunnen bepalen welke gebruikers verantwoordelijk zijn voor het uitvoeren van welke bewerkingen en welke resources deze bewerkingen gebruiken. De verzamelde gegevens moeten gedetailleerd genoeg zijn voor het inschakelen van nauwkeurige facturering.
Bijhouden van problemen
Klanten en andere gebruikers rapporteren mogelijk problemen als onverwachte gebeurtenissen of gedrag in het systeem optreden. Bijhouden van problemen heeft betrekking op het beheer van deze problemen, het koppelen ervan met inspanningen voor het oplossen van eventuele onderliggende problemen in het systeem en het informeren van de klanten over mogelijke oplossingen.
Vereisten voor bijhouden van problemen
Operators voeren het bijhouden van problemen vaak uit met behulp van een afzonderlijk systeem waarmee ze de details van problemen die gebruikers rapporteren vastleggen en rapporteren. Deze gegevens kunnen de taken omvatten die de gebruiker probeerde uit te voeren, symptomen van het probleem, de volgorde van gebeurtenissen en de fout- of waarschuwingsberichten die zijn afgegeven.
Vereisten voor gegevensbronnen, instrumentatie en gegevensverzameling
De eerste gegevensbron voor gegevens over het bijhouden van problemen, is de gebruiker die het probleem oorspronkelijk heeft gerapporteerd. Het is mogelijk dat de gebruiker aanvullende gegevens kan bieden, zoals:
- Een crashdump (als de toepassing een onderdeel bevat dat wordt uitgevoerd op het bureaublad van de gebruiker).
- Een momentopname van het scherm.
- De datum en tijd waarop de fout is opgetreden, samen met eventuele andere omgevingsinformatie zoals de locatie van de gebruiker.
Deze informatie kan worden gebruikt om te helpen met de foutopsporing en een achterstand samen te stellen voor toekomstige versies van de software.
Analyseren van gegevens van het bijhouden van problemen
Andere gebruikers kunnen hetzelfde probleem melden. Het systeem om problemen bij te houden moet algemene rapporten koppelen.
De voortgang van de foutopsporing moet worden geregistreerd op basis van elk probleemrapport. Als het probleem is opgelost, kan de klant worden geïnformeerd over de oplossing.
Als een gebruiker een probleem met een bekende oplossing rapporteert in het systeem om problemen bij te houden, moet de operator de gebruiker onmiddellijk kunnen informeren over de oplossing.
Bewerkingen traceren en foutopsporing van softwareversies
Wanneer een gebruiker een probleem meldt, is de gebruiker vaak alleen op de hoogte van het onmiddellijke effect dat deze heeft op zijn of haar activiteiten. De gebruiker kan de resultaten van zijn eigen ervaring alleen rapporteren aan een operator die verantwoordelijk is voor het beheren van het systeem. Deze ervaringen zijn meestal slechts een zichtbaar symptoom van een of meer fundamentele problemen. In veel gevallen moet een analist door de volgorde van de onderliggende bewerkingen graven om de hoofdoorzaak van het probleem vast te stellen. Dit proces wordt analyse van hoofdoorzaken genoemd.
Notitie
Analyse van hoofdoorzaken onthult mogelijk een inefficiëntie in het ontwerp van een toepassing. In deze gevallen is het mogelijk om de betrokken elementen bij te werken en te implementeren als onderdeel van een latere release. Dit proces vereist zorgvuldig beheer en de bijgewerkte componenten moeten nauw worden bewaakt.
Vereisten voor de tracering en foutopsporing
Voor het traceren van onverwachte gebeurtenissen en andere problemen is het essentieel dat de bewakingsgegevens genoeg informatie bieden, zodat een analist terug kan traceren naar de oorsprong van deze problemen en de volgorde van de gebeurtenissen die hebben plaatsgevonden kan reconstrueren. Deze informatie moet voldoende zijn voor een analist om de hoofdoorzaak van problemen vast te stellen. Een ontwikkelaar kan vervolgens de noodzakelijke wijzigingen aanbrengen om te voorkomen dat ze in de toekomst weer gebeuren.
Vereisten voor gegevensbronnen, instrumentatie en gegevensverzameling
Het oplossen van problemen kan betrekking hebben op alle methoden (en de bijbehorende parameters) die worden aangeroepen als onderdeel van een bewerking, om een structuur te bouwen die de logische stroom door het systeem weergeeft wanneer een klant een specifieke aanvraag indient. Uitzonderingen en waarschuwingen die het systeem genereert als gevolg van deze stroom, moeten worden vastgelegd en gelogd.
Ter ondersteuning van foutopsporing krijgt het systeem hooks waarmee een operator informatie over de status op belangrijke punten in het systeem kan vastleggen. Of het systeem biedt gedetailleerde stapsgewijze informatie als de geselecteerde bewerkingen worden uitgevoerd. Vastleggen van gegevens op dit niveau kan een extra belasting op het systeem betekenen en moet een tijdelijk proces zijn. Een operator maakt voornamelijk gebruik van dit proces als een zeer ongebruikelijke reeks gebeurtenissen optreedt en deze moeilijk te repliceren is, of wanneer een nieuwe versie van een of meer elementen in een systeem zorgvuldige controle vereist om ervoor te zorgen dat de elementen werken zoals verwacht.
De pijplijn voor bewaking en diagnose
Het bewaken van een grootschalig gedistribueerd systeem vormt een aanzienlijke uitdaging. Elk van de scenario's beschreven in de vorige sectie moet niet per se als op zichzelf staand worden beschouwd. Er is waarschijnlijk een aanzienlijke overlap in de bewakingsgegevens en diagnostische gegevens die voor elke situatie zijn vereist, hoewel deze gegevens mogelijk op verschillende manieren moeten worden verwerkt en gepresenteerd. Daarom moet u rekening houden met een holistische interpretatie van bewaking en diagnostiek.
U kunt het volledige proces rondom bewaking en diagnostische gegevens zien als een pijplijn die bestaat uit de fasen die zijn weergegeven in Afbeelding 1.
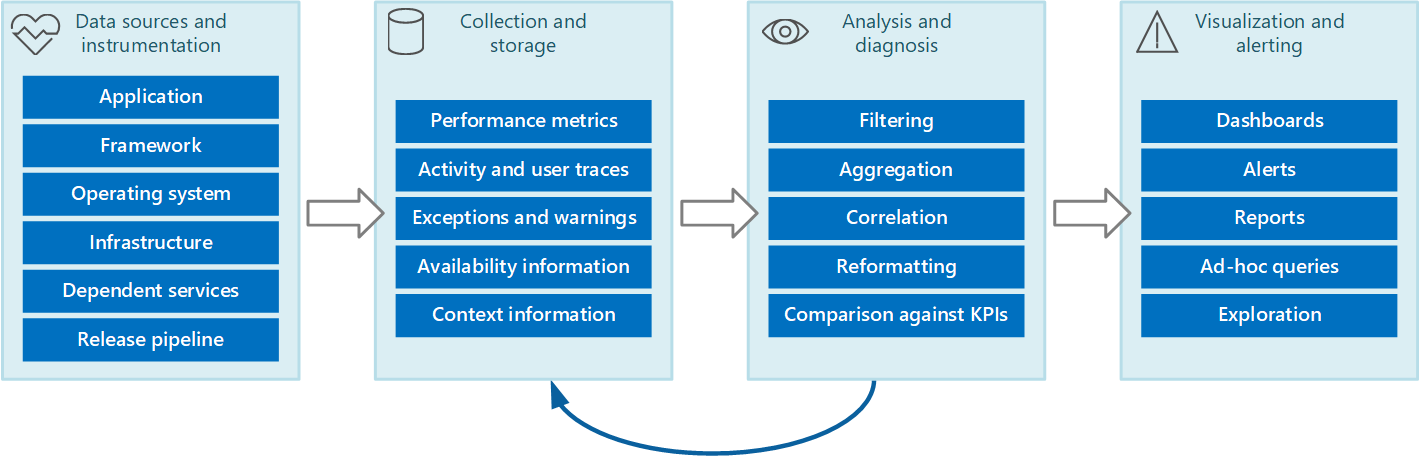
Afbeelding 1: de fasen in de bewakings- en diagnosepijplijn.
Afbeelding 1 toont u hoe de gegevens voor controle en diagnostiek afkomstig kunnen zijn uit een groot aantal verschillende gegevensbronnen. De fasen instrumentatie en verzameling zijn betrokken bij het identificeren van de bronnen van waaruit de gegevens moeten worden vastgelegd, te bepalen welke gegevens vast te leggen, hoe deze vast moeten worden gelegd en hoe deze gegevens zodanig moeten worden opgemaakt dat ze gemakkelijk kunnen worden onderzocht. De analyse-/diagnosefase neemt de onbewerkte gegevens en gebruikt deze voor het genereren van betekenisvolle informatie die een operator kan gebruiken om te bepalen wat de status van het systeem is. De operator kan deze informatie gebruiken om beslissingen te nemen over acties die mogelijk kunnen worden ondernomen en vervolgens de resultaten weer in de fasen instrumentatie en verzameling terug te voeren. De fase visualisatie/waarschuwingen geeft een verbruikbare weergave van de systeemstatus. Deze kan gegevens bijna in realtime weergeven met behulp van een reeks dashboards. Bovendien kunnen er rapporten, grafieken en diagrammen worden gegenereerd om een historisch overzicht te geven van de gegevens waarmee lange-termijntrends kunnen worden achterhaald. Als informatie aangeeft aan dat een KPI waarschijnlijk acceptabele grenzen zal overschrijden, kan deze fase ook een waarschuwing aan een operator activeren. In sommige gevallen kan een waarschuwing ook worden gebruikt voor het activeren van een geautomatiseerd proces dat corrigerende maatregelen probeert te nemen, zoals automatisch schalen.
Houd er rekening mee dat deze stappen een continu stroomproces vormen waarbij de fasen parallel plaatsvinden. In het ideale geval moeten alle fasen dynamisch kunnen worden geconfigureerd. Op bepaalde tijdstippen, met name wanneer een systeem pas is geïmplementeerd of er problemen zijn, kan het nodig zijn om op meer frequente basis uitgebreide gegevens te verzamelen. Op andere tijden moet het mogelijk zijn om terug te keren naar een basisniveau van essentiële informatie, om te controleren of het systeem correct functioneert.
Daarnaast moet het volledige bewakingsproces worden gezien als een live, continue oplossing die onderhevig is aan aanpassingen en verbeteringen als gevolg van feedback. U kunt bijvoorbeeld beginnen met het meten van veel factoren om de systeemstatus te bepalen. Analyse kan na verloop van tijd leiden tot een verfijning wanneer u metingen negeert die niet relevant zijn, zodat u zich preciezer kunt concentreren op de gegevens die u nodig hebt, terwijl achtergrondruis wordt geminimaliseerd.
Bronnen van bewakingsgegevens en diagnostische gegevens
De informatie die gebruikmaakt van het bewakingsproces kan afkomstig zijn uit verschillende bronnen, zoals geïllustreerd in Afbeelding 1. Op toepassingsniveau wordt informatie opgehaald uit de logboeken met traceringen die zijn opgenomen in de code van het systeem. Ontwikkelaars moeten een standaardbenadering volgen voor het bijhouden van de beheersstroom via hun code. Een vermelding voor een methode kan bijvoorbeeld een traceringsbericht verzenden met de naam van de methode, de huidige tijd, de waarde van elke parameter en eventuele andere relevante informatie. Het vastleggen van de toegangs- en uitgangstijden kan ook nuttig zijn.
U moet alle uitzonderingen en waarschuwingen vastleggen en ervoor zorgen dat u een volledige tracering behoudt van eventuele geneste uitzonderingen en waarschuwingen. In het ideale geval legt u ook informatie vast over de gebruiker die de code gebruikt, samen met informatie over correlatie (om aanvragen te volgen als ze het systeem passeren). En u moet pogingen vastleggen om toegang te krijgen tot alle resources zoals berichtenwachtrijen, databases, bestanden en andere afhankelijke services. Deze informatie kan worden gebruikt voor meet- en controledoeleinden.
Veel toepassingen gebruiken bibliotheken en frameworks om algemene taken uit te voeren, zoals toegang tot een gegevensarchief of communicatie via een netwerk. Deze frameworks worden mogelijk geconfigureerd om hun eigen traceringsberichten en onbewerkte diagnostische informatie te geven, zoals transactietarieven en geslaagde en mislukte gegevenstransmissies.
Notitie
Veel moderne frameworks publiceren automatisch gebeurtenissen voor prestaties en tracering. Het vastleggen van deze informatie is gewoon een kwestie van de mogelijkheid leveren om deze op te halen en te bewaren op een plek waar ze kan worden verwerkt en geanalyseerd.
Het besturingssysteem waarop de toepassing wordt uitgevoerd, kan een informatiebron op laag niveau door het hele systeem zijn, zoals prestatiemeteritems die aangeven wat de I/O-frequenties, het geheugengebruik en het CPU-gebruik zijn. Fouten in het besturingssysteem (zoals het niet correct kunnen openen van een bestand) kunnen ook worden gerapporteerd.
U moet ook rekening houden met de onderliggende infrastructuur en onderdelen waarop uw systeem wordt uitgevoerd. Virtuele machines, virtuele netwerken en opslagservices kunnen allemaal bronnen zijn van belangrijke prestatiemeteritems op het niveau van de infrastructuur en andere diagnostische gegevens.
Als uw toepassing gebruikmaakt van andere externe services, zoals een webserver of databasebeheersysteem, kunnen deze services hun eigen traceringsinformatie, logboeken en prestatiemeteritems publiceren. Voorbeelden zijn onder meer dynamische beheerweergaven van SQL Server voor het bijhouden van bewerkingen die worden uitgevoerd op een SQL Server-database en IIS-traceerlogboeken voor de registratie van aanvragen bij een webserver.
Wanneer de onderdelen van een systeem worden gewijzigd en nieuwe versies worden geïmplementeerd, is het belangrijk in staat te zijn om kenmerkproblemen, gebeurtenissen en metrische gegevens voor elke versie toe te kennen. Deze informatie moet worden teruggekoppeld naar de release-pijplijn zodat problemen met een specifieke versie van een onderdeel snel kunnen worden opgespoord en verholpen.
Beveiligingsproblemen kunnen op elk willekeurig moment in het systeem optreden. Een gebruiker kan bijvoorbeeld proberen zich aan te melden met een ongeldige gebruikersnaam of wachtwoord. Een geverifieerde gebruiker probeert wellicht onbevoegd toegang te verkrijgen tot een resource. Of een gebruiker kan een ongeldige of verouderde sleutel voor toegang tot gecodeerde gegevens opgeven. Beveiligingsinformatie voor geslaagde en mislukte aanvragen moet altijd worden vastgelegd.
De sectie Een toepassing instrumenteren bevat meer instructies voor de informatie die u moet vastleggen. Maar u kunt een aantal strategieën gebruiken om deze informatie te verzamelen:
Toepassing/systeemcontrole. Deze strategie maakt gebruik van interne bronnen binnen de toepassing, toepassingsframeworks, het besturingssysteem en de infrastructuur. De toepassingscode kan eigen bewakingsgegevens genereren op belangrijke punten tijdens de levenscyclus van een clientaanvraag. De toepassing kan traceringsinstructies opnemen die selectief kunnen worden ingeschakeld of uitgeschakeld, naar gelang de omstandigheden. Het is eventueel ook mogelijk om diagnostische gegevens dynamisch te injecteren met behulp van een diagnostisch framework. Deze frameworks bieden meestal invoegtoepassingen die kunnen worden gekoppeld aan verschillende instrumentatiepunten in uw code en traceringsgegevens op deze punten kunnen vastleggen.
Daarnaast kan uw code of de onderliggende infrastructuur gebeurtenissen op kritieke punten genereren. Bewakingsagents die zijn geconfigureerd om te luisteren naar deze gebeurtenissen kunnen informatie van de gebeurtenis vastleggen.
Echte gebruikersbewaking. Deze benadering registreert de interactie tussen een gebruiker en de toepassing en observeert de stroom van elke aanvraag en reactie. Deze informatie kan een tweeledig doel hebben: ze kan worden gebruikt voor het meten van gebruik door elke gebruiker en ze kan worden gebruikt om te bepalen of gebruikers adequate servicekwaliteit (bijvoorbeeld snelle responstijden, lage latentie en minimale fouten) ontvangen. De vastgelegde gegevens kunt u gebruiken om problematische gebieden te identificeren waar de meeste storingen optreden. U kunt de gegevens ook gebruiken om elementen te identificeren waarbij het systeem vertraagt, mogelijk vanwege hotspots in de toepassing of een andere vorm van knelpunten. Als u deze benadering zorgvuldig implementeert, is het mogelijk de gebruikersstromen via de toepassing voor foutopsporing en testdoeleinden te reconstrueren.
Belangrijk
U moet er rekening mee houden dat de gegevens van de bewaking van echte gebruikers uiterst gevoelig zijn, omdat deze mogelijk vertrouwelijke informatie bevatten. Als u de vastgelegde gegevens opslaat, moet u ze veilig opslaan. Als u de gegevens wilt gebruiken voor prestatiebewaking of foutopsporing, moet u eerst alle persoonlijke gegevens verwijderen.
Synthetische gebruikersbewaking. In deze benadering schrijft u uw eigen testclient die een gebruiker simuleert en een configureerbare maar typische reeks bewerkingen uitvoert. U kunt de prestaties van de testclient bijhouden om te helpen met het bepalen van de status van het systeem. U kunt ook meerdere exemplaren van de testclient gebruiken als onderdeel van een bewerking om de belasting te testen, om vast te stellen hoe het systeem reageert onder zware belasting en wat voor bewakingsuitvoer wordt gegenereerd in deze omstandigheden.
Notitie
U kunt echte en synthetische gebruikersbewaking implementeren door code in te sluiten die de uitvoering van methodeaanroepen en andere belangrijke onderdelen van een toepassing bijhoudt en klokt.
Profileren. Deze benadering is voornamelijk gericht op het controleren en verbeteren van de prestaties van toepassingen. In plaats van op het functionele niveau van de reële en synthetische gebruikersbewaking te werken, wordt informatie op lager niveau vastgelegd terwijl de toepassing wordt uitgevoerd. U kunt het profileren implementeren met behulp van periodieke steekproeven van de uitvoeringsstatus van een toepassing (bepalen welk stuk code door de toepassing wordt uitgevoerd op een bepaald moment). U kunt ook instrumentatie gebruiken die sondes op belangrijke verbindingspunten in de code invoegt (zoals het begin en einde van een methodeaanroep) en registreert welke methoden zijn aangeroepen, op welk tijdstip en hoelang elke aanroep duurde. Vervolgens kunt u deze gegevens analyseren om te bepalen welke onderdelen van de toepassing leiden tot prestatieproblemen.
Eindpuntbewaking. Deze methode maakt gebruik van een of meer diagnostische eindpunten die de toepassing specifiek voor bewaking blootlegt. Een eindpunt verschaft toegang tot de toepassingscode en kan informatie over de status van het systeem retourneren. Verschillende eindpunten kunnen zich concentreren op verschillende aspecten van de functionaliteit. U kunt uw eigen diagnostische client schrijven om periodieke aanvragen naar deze eindpunten te verzenden en de antwoorden te assimileren. Zie het patroon Statuseindpuntbewaking voor meer informatie.
U moet een combinatie van de volgende manieren gebruiken voor maximale dekking.
Een toepassing instrumenteren
Instrumentatie is een belangrijk onderdeel van het bewakingsproces. Alleen als u eerst de gegevens vastlegt waarmee u deze beslissingen kunt maken, kunt u zinvolle beslissingen nemen over de prestaties en de status van een systeem. De informatie die u verzamelt via instrumentatie moet voldoende zijn om prestaties te beoordelen, problemen te onderzoeken en beslissingen te nemen zonder dat u zich moet aanmelden bij een externe productieserver om tracering (en foutopsporing) handmatig uit te voeren. Instrumentatiegegevens omvatten doorgaans metrische gegevens en informatie die naar traceerlogboeken worden geschreven.
De inhoud van een traceringslogboek kan het resultaat zijn van tekstgegevens die zijn geschreven door de toepassing of binaire gegevens die zijn gemaakt als gevolg van een traceringsbeurt, als de toepassing gebruikmaakt van Event Tracing voor Windows (ETW). De inhoud kan ook worden gegenereerd uit systeemlogboeken die gebeurtenissen vastleggen die voortvloeien uit delen van de infrastructuur, zoals een webserver. Tekstuele logboekberichten zijn vaak bedoeld om voor mensen leesbaar te zijn, maar ze moeten ook in een indeling worden geschreven die een geautomatiseerd systeem eenvoudig kan parseren.
Ook moet u de logboeken categoriseren. Probeer niet om alle traceergegevens naar een enkel logboek te schrijven, maar gebruik afzonderlijke logboeken om de uitvoer vast te leggen van verschillende operationele aspecten van het systeem. Vervolgens kunt u snel berichten in het logboek filteren door het juiste logboek te lezen, in plaats van een enkel lang bestand te moeten verwerken. Schrijf nooit informatie die andere beveiligingsvereisten heeft (zoals controle-informatie en gegevens voor foutopsporing) in hetzelfde logboek.
Notitie
Een logboek kan worden geïmplementeerd als een bestand op het bestandssysteem of het kan worden ondergebracht in een andere indeling, zoals een blob in blobopslag. Logboekgegevens kunnen ook worden ondergebracht in meer gestructureerde opslag, zoals rijen in een tabel.
Metrische gegevens zijn over het algemeen een meting van het aantal van sommige aspecten of resources in het systeem op een bepaald tijdstip, met een of meer gekoppelde tags of dimensies (soms een sample genoemd). Slechts één exemplaar van metrische gegevens is doorgaans niet handig op zichzelf. In plaats daarvan moeten metrische gegevens gedurende een periode worden vastgelegd. Het belangrijkste probleem dat u in overweging moet nemen, is welke metrische gegevens moeten worden vastgelegd en hoe vaak. Het te vaak genereren van metrische gegevens kan een aanzienlijke extra belasting op het systeem betekenen, terwijl het niet vaak genoeg vastleggen van metrische gegevens ertoe kan leiden dat u de omstandigheden mist die leiden tot een belangrijke gebeurtenis. De overwegingen variëren per type metrische gegevens. CPU-gebruik op een server kan bijvoorbeeld van seconde tot seconde aanzienlijk verschillen, maar hoog gebruik wordt alleen een probleem als het meerdere minuten aanhoudt.
Informatie voor het correleren van gegevens
U kunt eenvoudig afzonderlijke prestatiemeteritems op systeemniveau bewaken, metrische gegevens voor resources vastleggen en traceringsinformatie voor toepassingen ophalen uit verschillende logboekbestanden. Maar bepaalde vormen van bewaking hebben de analyse- en diagnostische gegevensfase in de bewakingspijplijn nodig, die de gegevens correleert die zijn opgehaald uit diverse bronnen. Deze gegevens nemen mogelijk verschillende vormen aan in de onbewerkte gegevens en het analyseproces moet van voldoende instrumentatiegegevens worden voorzien om deze verschillende vormen toe te kunnen wijzen. Op het niveau van het toepassingsframework kan een taak bijvoorbeeld worden geïdentificeerd door een thread-id. Binnen een toepassing is hetzelfde werk mogelijk gekoppeld aan de gebruikers-id voor de gebruiker die deze taak uitvoert.
Er is ook waarschijnlijk geen 1:1-toewijzing tussen threads en gebruikersaanvragen, omdat asynchrone bewerkingen mogelijk dezelfde threads opnieuw gebruiken om bewerkingen namens meer dan één gebruiker uit te voeren. Om zaken nog verder te bemoeilijken, kan een enkele aanvraag door meer dan één thread worden uitgevoerd als de uitvoerbewerking door het systeem stroomt. Koppel indien mogelijk elke aanvraag aan een unieke activiteits-id die wordt doorgegeven via het systeem als onderdeel van de context van de aanvraag. (De techniek voor het genereren en opnemen van activiteits-id's in de traceringsinformatie hangt af van de technologie die wordt gebruikt om de traceringsgegevens vast te leggen.)
Alle bewakingsgegevens moeten op dezelfde manier worden getypt. Noteer alle datums en tijden met behulp van Coordinated Universal Time voor consistentie. Hierdoor kunt u gemakkelijker reeksen gebeurtenissen traceren.
Notitie
Computers in de verschillende tijdzones en netwerken kunnen mogelijk niet worden gesynchroniseerd. U hoeft niet alleen tijdstempels te gebruiken voor het correleren van instrumentatiegegevens die meerdere computers omvatten.
Informatie die in de instrumentatiegegevens moet worden opgenomen
Houd rekening met de volgende punten bij het bepalen van welke instrumentatiegegevens u moet verzamelen:
Zorg ervoor dat informatie wordt vastgelegd door traceringsgebeurtenissen en voor machine en mensen leesbaar is. Neem goed gedefinieerde schema's aan voor deze informatie, ter bevordering van de automatische verwerking van logboekgegevens over systemen en voor het bieden van consistentie in bewerkingen en het lezen van de logboeken door technisch personeel. Neem omgevingsinformatie op, zoals de implementatieomgeving, de computer waarop het proces wordt uitgevoerd, de details van het proces en de aanroepstack.
Schakel profilering alleen in indien nodig, omdat het een aanzienlijke overhead op het systeem kan opleggen. Profileren via instrumentatie registreert een gebeurtenis (zoals een methodeaanroep) telkens wanneer die zich voordoet, terwijl steekproeven alleen geselecteerde gebeurtenissen registreren. De selectie kan op tijd zijn gebaseerd (eenmaal per n seconden) of op basis van frequentie (eenmaal per n aanvragen). Als gebeurtenissen heel vaak voorkomen, kan profilering door instrumentatie ertoe leiden dat het teveel een last wordt en zelf de algehele prestaties beïnvloedt. In dit geval kan de aanpak van steekproeven beter zijn. Als de frequentie van gebeurtenissen echter laag is, worden ze door steekproeven mogelijk gemist. In dit geval is instrumentatie mogelijk een betere benadering.
Geef voldoende context zodat een ontwikkelaar of beheerder de bron van elke aanvraag bepalen kan. Dit kan een vorm van activiteits-id zijn, die een specifiek exemplaar van een aanvraag identificeert. Deze kan mogelijk ook gegevens bevatten die kunnen worden gebruikt om deze activiteit te correleren met het rekenwerk dat wordt uitgevoerd en de resources die worden gebruikt. Houd er rekening mee dat dit werk mogelijk over proces- en machinegrenzen heengaat. Voor het meten moet de context ook een verwijzing opnemen (direct of indirect via andere gecorreleerde informatie) naar de klant die de aanvraag heeft veroorzaakt. Deze context biedt waardevolle informatie over de status van de toepassing op het moment dat de bewakingsgegevens zijn vastgelegd.
Registreer alle aanvragen en de locaties of regio's waaruit deze aanvragen worden gedaan. Deze informatie kan helpen bij het bepalen of er locatiespecifieke hotspots zijn. Deze informatie kan ook zijn nuttig bij het bepalen of u een toepassing of de gegevens die worden gebruikt opnieuw wilt indelen.
Leg de details van uitzonderingen zorgvuldig vast. Kritieke foutopsporingsinformatie gaat vaak verloren gaan als gevolg van slechte uitzonderingsverwerking. Leg de volledige details vast over uitzonderingen die de toepassing genereert, zoals interne uitzonderingen en andere contextinformatie. Voeg indien mogelijk de aanroepstack toe.
Wees consequent met de gegevens die door de verschillende elementen van uw toepassing worden vastgelegd, omdat dit kan helpen bij het analyseren van gebeurtenissen en het correleren ervan met aanvragen van gebruikers. Denk na over het gebruik van een uitgebreid en configureerbaar pakket voor logboekregistratie om gegevens te verzamelen, in plaats van ervan afhankelijk te zijn dat ontwikkelaars dezelfde werkwijze aannemen als ze verschillende onderdelen van het systeem implementeren. Verzamel gegevens van de belangrijkste prestatiemeteritems, zoals het volume van de uitgevoerde I/O, het netwerkgebruik, het aantal aanvragen, het geheugengebruik en CPU-gebruik. Sommige infrastructuurservices bieden wellicht hun eigen specifieke prestatiemeteritems, zoals het aantal verbindingen met een database, de frequentie waarmee transacties worden uitgevoerd en het aantal transacties dat slaagt of mislukt. Toepassingen kunnen ook hun eigen specifieke prestatiemeteritems definiëren.
Registreer alle aanroepen naar externe services, zoals databases, webservices of andere services op systeemniveau die deel uitmaken van de infrastructuur. Registreer gegevens over de tijd die nodig is om elke aanroep uit te voeren, en het slagen of het mislukken van de aanroep. Leg indien mogelijk informatie vast over alle nieuwe pogingen en mislukkingen voor tijdelijke fouten die optreden.
Compatibiliteit met telemetrie-systemen bieden
In veel gevallen is de informatie die de instrumentatie produceert gegenereerd als een reeks gebeurtenissen en doorgegeven aan een afzonderlijk telemetriesysteem voor verwerking en analyse. Een telemetriesysteem is meestal onafhankelijk van bepaalde toepassingen of technologieën, maar het verwacht van informatie dat deze een specifieke indeling volgt, die gewoonlijk wordt gedefinieerd door een schema. Het schema geeft in feite een contract aan, waarin de gegevensvelden en -typen staan die het telemetriesysteem kan opnemen. Het schema moet worden gegeneraliseerd om toe te staan dat gegevens binnenkomen vanaf verschillende platforms en apparaten.
Een algemeen schema moet velden bevatten die gemeenschappelijk zijn voor alle instrumentatiegebeurtenissen, zoals de naam van de gebeurtenis, de tijd van de gebeurtenis, het IP-adres van de afzender en de details die vereist zijn voor het correleren met andere gebeurtenissen (zoals een gebruikers-id, een apparaat-id en een toepassings-id). Houd er rekening mee dat er een aantal apparaten kunnen zijn die gebeurtenissen oproepen, dus mag het schema niet afhankelijk zijn van het type apparaat. Bovendien roepen verschillende apparaten mogelijk gebeurtenissen op voor dezelfde toepassing. De toepassing ondersteunt misschien roaming of een andere vorm van distributie over meerdere apparaten.
Het schema kan ook domeinvelden bevatten die relevant zijn voor een bepaald scenario dat gebruikelijk is over verschillende toepassingen. Dit kan informatie zijn over uitzonderingen, het begin- en eindevenement van de toepassing en het slagen of mislukken van API-aanroepen van webservices. Alle toepassingen die gebruikmaken van dezelfde reeks domeinvelden moeten dezelfde set van gebeurtenissen verzenden, die het bouwen van een set algemene rapporten en analyses mogelijk maakt.
Een schema kan ten slotte aangepaste velden bevatten voor het vastleggen van de details van toepassingsspecifieke gebeurtenissen.
Best practices voor het instrumenteren van toepassingen
De volgende lijst bevat een overzicht van best practices voor het instrumenteren van een gedistribueerde toepassing die wordt uitgevoerd in de cloud.
Maak het gemakkelijk logboeken te lezen en te parseren. Gebruik waar mogelijk gestructureerde logboekregistratie. Wees beknopt en beschrijvend in berichten in het logboek.
Identificeer in alle logboeken de bron en geef de context- en timinginformatie terwijl elk logboekregistratie wordt geschreven.
Gebruik dezelfde tijdzone en notatie voor alle tijdstempels. Dit helpt gebeurtenissen te correleren voor bewerkingen die gelden voor hardware en services die worden uitgevoerd in verschillende geografische regio's.
Categoriseer logboeken en schrijf berichten naar het juiste logbestand.
Maak geen gevoelige informatie bekend over het systeem, of persoonlijke gegevens over gebruikers. Schoon deze informatie op voordat ze wordt vastgelegd, maar zorg ervoor dat de relevante gegevens blijven behouden. Verwijder bijvoorbeeld de id en het wachtwoord uit alle tekenreeksen voor databaseverbindingen, maar schrijf de resterende gegevens naar het logboek, zodat een analist kan bepalen of het systeem toegang heeft tot de juiste database. Registreer alle kritieke uitzonderingen, maar maak het voor de beheerder mogelijk om logboekregistratie in of uit te schakelen voor lagere niveaus van uitzonderingen en waarschuwingen. Leg bovendien alle gegevens vast voor de logica voor opnieuw proberen. Deze gegevens kunnen nuttig zijn om de tijdelijke status van het systeem te bewaken.
Traceer aanroepen buiten het proces, zoals aanvragen naar externe webservices of databases.
Combineer geen berichten in het logboek met andere beveiligingsvereisten in hetzelfde logboekbestand. Schrijf bijvoorbeeld geen foutopsporing en controle-informatie naar hetzelfde logboek.
Zorg ervoor dat alle aanroepen voor logboekregistraties fire-and-forget-bewerkingen zijn die de voortgang van zakelijke activiteiten niet blokkeren, met uitzondering van controlegebeurtenissen. Controlegebeurtenissen zijn uitzonderlijk omdat ze essentieel zijn voor het bedrijf en kunnen worden geclassificeerd als een fundamenteel onderdeel van zakelijke activiteiten.
Zorg ervoor dat de logboekregistratie uitgebreid kan worden en geen directe afhankelijkheden van een concreet doel heeft. In plaats van gegevens te schrijven met behulp van System.Diagnostics.Trace, kunt u bijvoorbeeld een abstracte interface (zoals ILogger) definiëren, die logboekregistratiemethoden beschrijft en die kan worden geïmplementeerd via alle geschikte middelen.
Zorg ervoor dat alle registratie failsafe is en nooit opeenvolgende fouten activeert. Logboekregistratie moet geen uitzonderingen genereren.
Behandel instrumentatie als een continu iteratief proces en controleer de logboeken regelmatig, niet alleen als er een probleem is.
Gegevens verzamelen en opslaan
De verzamelfase van het bewakingsproces is betrokken bij het ophalen van de informatie die door instrumentatie wordt gegenereerd en formatteert deze gegevens om het voor de analyse-/diagnosefase gemakkelijker te maken om de getransformeerde gegevens in de betrouwbare opslag te verbruiken en op te slaan. De instrumentatiegegevens die afkomstig zijn uit verschillende onderdelen van een gedistribueerd systeem kunnen worden ondergebracht in verschillende locaties en met verschillende bestandsindelingen. Uw toepassingscode kan bijvoorbeeld logboekbestanden genereren voor tracering en toepassingsgegevens van het gebeurtenislogboek, terwijl de prestatiemeteritems die belangrijke aspecten bewaken van de infrastructuur die uw toepassing gebruikt, kunnen worden vastgelegd via andere technologieën. Alle onderdelen van derden en services die uw toepassing gebruikt, kan informatie over de instrumentatie verschaffen in verschillende indelingen met behulp van afzonderlijke traceringsbestanden, blobopslag of zelfs een aangepast gegevensarchief.
Verzamelen van gegevens wordt vaak uitgevoerd via een verzameling die autonoom kan worden uitgevoerd vanuit de toepassing die de instrumentatiegegevens genereert. Afbeelding 2 toont een voorbeeld van deze architectuur en markeert het subsysteem voor het verzamelen van instrumentatiegegevens.
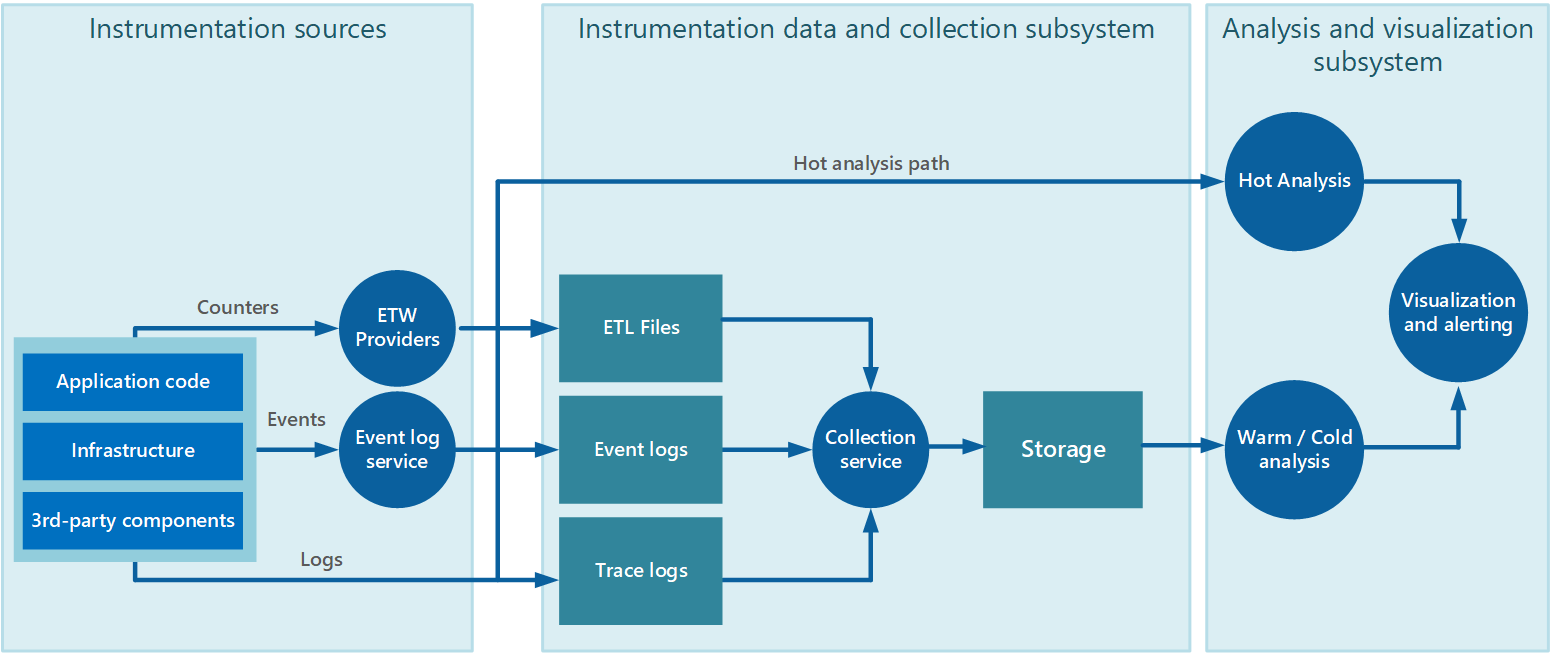
Afbeelding 2: instrumentatiegegevens verzamelen.
Houd er rekening mee dat dit een vereenvoudigde weergave is. De verzamelservice is niet noodzakelijkerwijs een enkel proces en is mogelijk uit veel delen samengesteld die worden uitgevoerd op verschillende computers, zoals beschreven in de volgende secties. Bovendien, als de analyse van sommige telemetrische gegevens snel moet worden uitgevoerd (hot-analyse, zoals beschreven in de sectie Ondersteunen van hot-, warm- en cold-analyse verderop in dit document), kunnen lokale onderdelen die buiten verzamelservice werken onmiddellijk de analysetaken uitvoeren. Afbeelding 2 toont deze situatie voor de geselecteerde gebeurtenissen. Na de analytische verwerking kunnen de resultaten rechtstreeks naar het subsysteem voor visualisatie en waarschuwingen worden verzonden. Gegevens die worden onderworpen aan hot- of cold-analyse worden bewaard in de opslag terwijl ze op verwerking wachten.
Voor Azure-toepassingen en services biedt Azure Diagnostics een mogelijke oplossing voor het vastleggen van gegevens. Azure Diagnostics verzamelt gegevens uit de volgende bronnen voor elk rekenknooppunt, aggregeert deze en uploadt ze vervolgens naar Azure Storage:
- IIS-logboeken
- Logboeken van mislukte IIS-aanvragen
- Windows-gebeurtenislogboeken
- Prestatiemeteritems
- Crashdumps
- Logboeken van Azure Diagnostics-infrastructuur
- Aangepaste foutenlogboeken
- .NET EventSource
- Op manifest gebaseerde ETW
Zie voor meer informatie het artikel Azure: Telemetry Basics and Troubleshooting (Azure: basisbeginselen en probleemoplossing voor telemetrie).
Strategieën voor het verzamelen van instrumentatiegegevens
Gezien de elastische aard van de cloud en om de noodzaak te voorkomen dat telemetriegegevens handmatig van elk knooppunt in het systeem moeten worden opgehaald, dient u te zorgen dat de gegevens worden overgedragen naar een centrale locatie en daar worden geconsolideerd. In een systeem dat meerdere datacenters omvat, kan het nuttig zijn de gegevens eerst te verzamelen, consolideren en op te slaan op basis van regio, en vervolgens de regionale gegevens samen te voegen in één centraal systeem.
Om het gebruik van de bandbreedte te optimaliseren, kunt u ervoor kiezen minder urgente gegevens in reeksen zoals batches over te dragen. De gegevens moeten echter niet voor onbepaalde tijd worden uitgesteld, vooral als deze tijdgebonden informatie bevatten.
Instrumentatiegegevens pullen en pushen
Het subsysteem voor het verzamelen van instrumentatiegegevens kan actief instrumentatiegegevens ophalen uit de verschillende logboeken en andere bronnen voor elk exemplaar van de toepassing (het pull-model). Of het kan fungeren als een passieve ontvanger die wacht tot de gegevens worden verzonden vanuit de onderdelen die deel uitmaken van elk exemplaar van de toepassing (het push-model).
Een benadering voor de implementatie van het pull-model is het gebruik van de bewakingsagents die met elke instantie van de toepassing lokaal worden uitgevoerd. Een bewakingsagent is een afzonderlijk proces dat periodiek telemetrische gegevens ophaalt (pullt) die bij het lokale knooppunt zijn verzameld en deze informatie rechtstreeks naar centrale opslag schrijft die door alle exemplaren van de toepassing wordt gedeeld. Dit is het mechanisme dat door Azure Diagnostics wordt geïmplementeerd. Elk exemplaar van een Azure-web- of werkrol kan worden geconfigureerd voor het vastleggen van diagnostische gegevens en andere traceringsinformatie die lokaal wordt opgeslagen. De bewakingsagent die naast elk exemplaar wordt uitgevoerd, kopieert de opgegeven gegevens naar Azure Storage. Het artikel Enabling Diagnostics in Azure Cloud Services and Virtual Machines (Diagnostische gegevens inschakelen in Azure Cloud Services en virtuele machines) biedt meer details over dit proces. Sommige elementen, zoals IIS-logboeken, crashdumps en aangepaste fout-logboeken worden naar de blobopslag geschreven. Gegevens uit het Windows-gebeurtenislogboek, ETW-gebeurtenissen en prestatiemeteritems worden geregistreerd in de tabelopslag. Afbeelding 3 laat dit mechanisme zien.
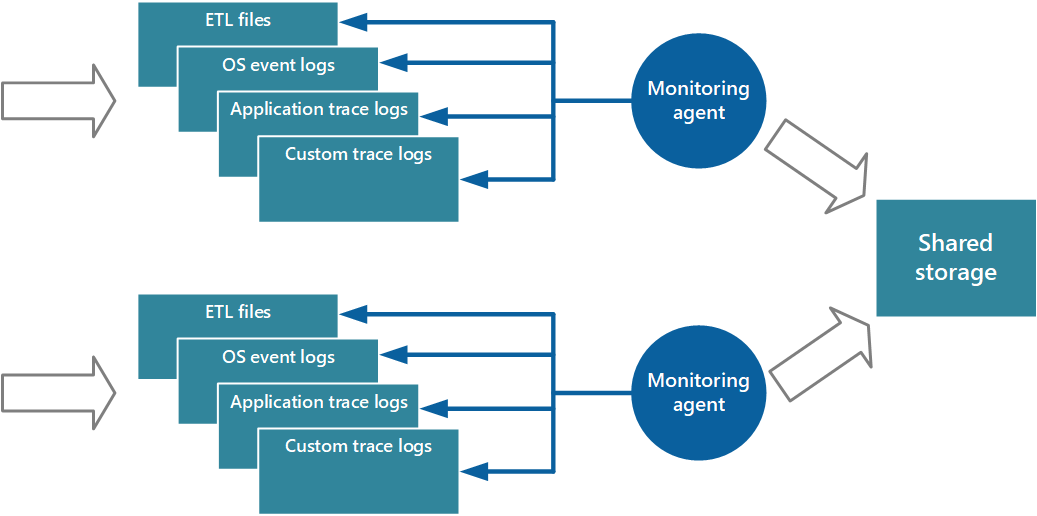
Afbeelding 3: een bewakingsagent gebruiken om informatie op te halen en naar gedeelde opslag te schrijven.
Notitie
Het gebruik van een bewakingsagent is ideaal voor het vastleggen van gegevens die natuurlijk worden opgehaald uit een gegevensbron. Een voorbeeld is de informatie van dynamische beheerweergaven van SQL Server of de lengte van een Azure Service Bus-wachtrij.
Het is mogelijk om de hierboven beschreven aanpak te gebruiken voor het opslaan van telemetriegegevens voor een kleinschalige toepassing, die wordt uitgevoerd op een beperkt aantal knooppunten op één locatie. Een complexe, zeer schaalbare, algemene cloudtoepassing kan echter zeer grote hoeveelheden gegevens genereren uit honderden web- en werkrollen, database shards en andere services. Deze stroom van gegevens kan eenvoudig de I/O-bandbreedte overbelasten die beschikbaar is bij een enkele, centrale locatie. Uw telemetrie-oplossing moet daarom schaalbaar zijn om te voorkomen dat deze fungeert als een knelpunt wanneer het systeem wordt uitgebreid. Uw oplossing moet in het ideale geval gebruikmaken van een zekere mate van redundantie om de risico's te verminderen van het verlies van belangrijke informatie voor prestatiebewaking (zoals controle- of factureringsgegevens) als een onderdeel van het systeem mislukt.
Om deze problemen op te lossen, kunt u wachtrijen implementeren, zoals wordt weergegeven in afbeelding 4. In deze architectuur plaatst de lokale bewakingsagent (indien deze op de juiste wijze kan worden geconfigureerd) of aangepaste service voor gegevensverzameling (indien niet) gegevens in een wachtrij. Een afzonderlijk proces dat asynchroon wordt uitgevoerd (de service opslag-schrijven in afbeelding 4) haalt de gegevens uit deze wachtrij en schrijft deze naar de gedeelde opslag. Een berichtenwachtrij is geschikt voor dit scenario omdat deze 'ten minste eenmaal'-semantiek biedt, die helpt ervoor te zorgen dat gegevens in de wachtrij niet verloren raken nadat deze gepost zijn. U kunt de service opslag-schrijven implementeren met behulp van een afzonderlijke werkrol.
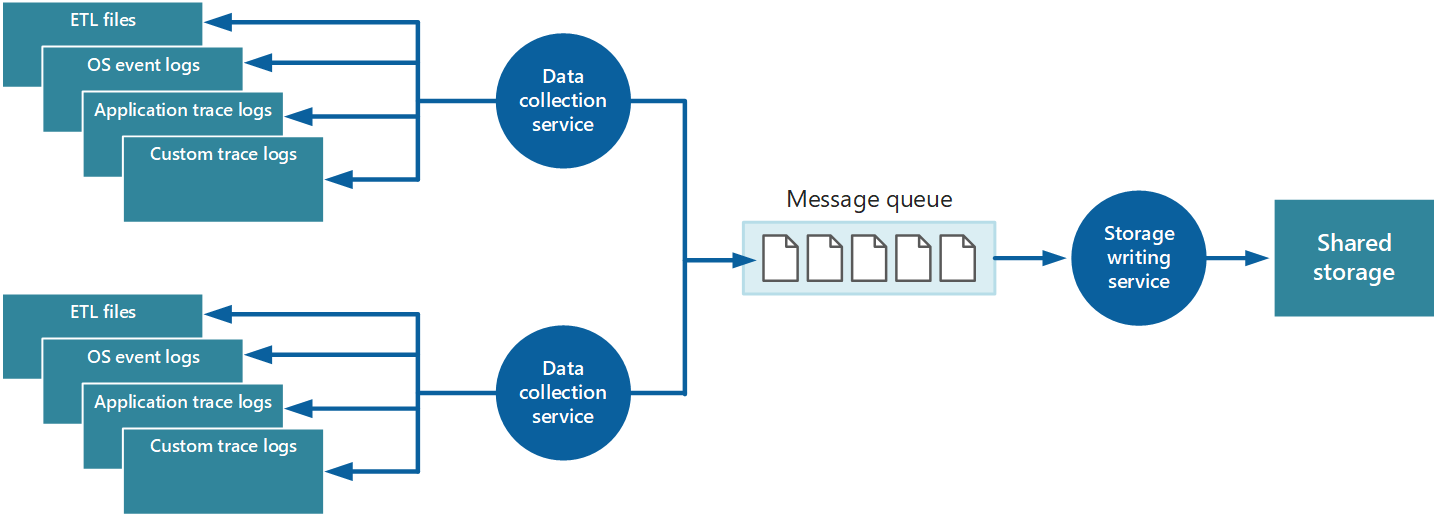
Afbeelding 4: Een wachtrij gebruiken om instrumentatiegegevens te bufferen.
De lokale service om gegevens te verzamelen kan gegevens toevoegen aan een wachtrij, onmiddellijk nadat deze zijn ontvangen. De wachtrij fungeert als een buffer en de service opslag-schrijven kan de gegevens ophalen en in zijn eigen tempo schrijven. Standaard werkt een wachtrij op basis van first-in, first-out. Maar u kunt prioriteiten aanbrengen om berichten te versnellen door de wachtrij, als ze gegevens bevatten die sneller moeten worden verwerkt. Zie Priority Queue pattern (Patroon Prioriteit van wachtrij) voor meer informatie. U kunt ook verschillende kanalen (zoals Service Bus-onderwerpen) gebruiken om gegevens naar andere bestemmingen te sturen, afhankelijk van de vorm van analytische verwerking die vereist is.
Voor schaalbaarheid kunt u meerdere exemplaren van de service opslag-schrijven uitvoeren. Als er een groot aantal gebeurtenissen is, kunt u een gebeurtenishub gebruiken om de gegevens naar andere rekenresources te verzenden voor verwerking en opslag.
Instrumentatiegegevens consolideren
De instrumentatiegegevens die de service voor gegevensverzameling ophaalt uit een enkele instantie van een toepassing, bieden een gelokaliseerde weergave van de status en prestaties van deze instantie. Voor het evalueren van de algemene status van het systeem is het nodig om sommige aspecten van de gegevens in de lokale weergaven te consolideren. U kunt dit uitvoeren nadat de gegevens zijn opgeslagen, maar in sommige gevallen kunt u dit ook bereiken als de gegevens worden verzameld. In plaats van dat ze rechtstreeks naar de gedeelde opslag worden geschreven, kunnen de gegevens worden doorgegeven via een afzonderlijke service voor gegevensconsolidatie die gegevens combineert en fungeert als een filter en schoonmaakproces. Instrumentatiegegevens met dezelfde correlatie-informatie, zoals een activiteits-id, kunnen bijvoorbeeld worden verenigd. (Het is mogelijk dat een gebruiker begint met het uitvoeren van een bedrijfsbewerking op het ene knooppunt en vervolgens wordt overgedragen naar een ander knooppunt in het geval van een storing in het knooppunt, of afhankelijk van hoe taakverdeling is geconfigureerd.) Dit proces kan ook dubbele gegevens detecteren en verwijderen (altijd een mogelijkheid als de telemetrieservice berichtenwachtrijen gebruikt om instrumentatiegegevens naar de opslag te pushen). Afbeelding 5 toont een voorbeeld van deze structuur.
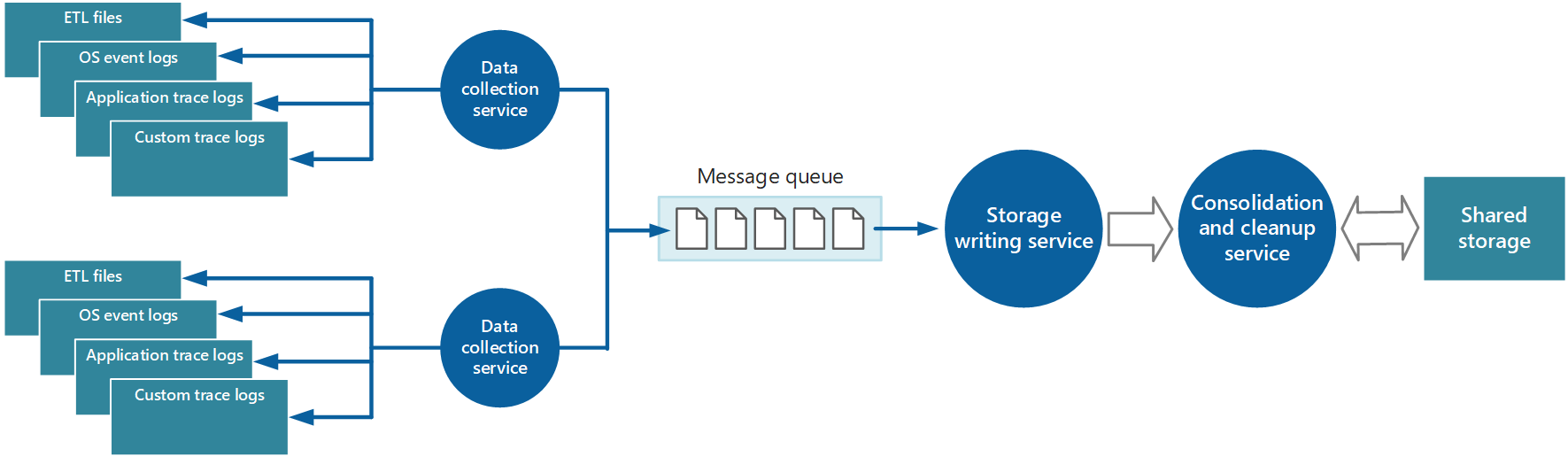
Afbeelding 5: Een afzonderlijke service gebruiken om instrumentatiegegevens samen te voegen en op te schonen.
Instrumentatiegegevens opslaan
De vorige discussies hebben een vrij eenvoudig beeld laten zien van de manier waarop instrumentatiegegevens zijn opgeslagen. In werkelijkheid kan het zinvol zijn de verschillende soorten gegevens op te slaan met behulp van de technologieën die het meest geschikt zijn voor de manier waarop elk type waarschijnlijk wordt gebruikt.
Azure blob- en tabelopslag hebben bijvoorbeeld een aantal overeenkomsten in de manier waarop ze toegankelijk zijn. Maar ze hebben beperkingen in de bewerkingen die u ermee kunt uitvoeren, en de granulariteit van de gegevens die ze hebben is heel anders. Als u meer analytische bewerkingen wilt uitvoeren of functies voor zoeken in volledige tekst van de gegevens nodig hebt, is het mogelijk beter om gegevensopslag te gebruiken met mogelijkheden die zijn geoptimaliseerd voor bepaalde typen query's en gegevenstoegang. Voorbeeld:
- Prestatiemeteritem-gegevens kunnen worden opgeslagen in een SQL database zodat ad hoc-analyse mogelijk is.
- Logboeken met traceringen kunnen mogelijk beter worden opgeslagen in Azure Cosmos DB.
- Beveiligingsgegevens kunnen naar Hadoop Distributed File System worden geschreven.
- Gegevens waarvoor zoeken in volledige tekst nodig is, kunnen worden opgeslagen via Elasticsearch (die ook zoekopdrachten versnelt met behulp van uitgebreid indexeren).
U kunt een extra service implementeren, die periodiek de gegevens ophaalt uit de gedeelde opslag en de gegevens partitioneert en filtert aan de hand van het doel en deze vervolgens naar een geschikte set gegevensarchieven schrijft, zoals weergegeven in afbeelding 6. Een alternatieve methode is het opnemen van deze functionaliteit in het proces voor consolidatie en opschonen en de gegevens rechtstreeks naar deze archieven te schrijven wanneer ze worden opgehaald, in plaats van ze op te slaan in een tussenliggende gedeelde opslagruimte. Elke methode heeft zijn voordelen en nadelen. Implementatie van een afzonderlijke partitioneringsservice vermindert de belasting van de service voor consolidatie en opschoning en zorgt ervoor dat ten minste een deel van de gepartitioneerde gegevens wordt gegenereerd wanneer dat nodig is (afhankelijk van hoeveel gegevens worden bewaard in de gedeelde opslag). Dit verbruikt echter aanvullende resources. Bovendien kan er een vertraging optreden tussen de ontvangst van gegevens van elke toepassingsinstantie en de conversie van deze gegevens in toepasbare informatie.
Afbeelding 6: Gegevens partitioneren op basis van analytische en opslagvereisten.
Dezelfde instrumentatiegegevens zijn mogelijk vereist voor meer dan één doel. Prestatiemeteritems kunnen bijvoorbeeld worden gebruikt om een historisch overzicht te geven van de systeemprestaties gedurende een bepaalde periode. Deze informatie kan worden gecombineerd met andere gebruiksgegevens voor het genereren van de factureringsgegevens voor de klant. In deze situaties worden dezelfde gegevens mogelijk verzonden naar meer dan één bestemming, zoals een documentdatabase die als een lange-termijnarchief kan optreden om informatie over facturering op te slaan, en een multidimensionale opslag voor het verwerken van complexe prestatieanalyses.
U moet ook overwegen hoe dringend de gegevens nodig zijn. Gegevens die informatie over waarschuwingen bieden, moeten snel kunnen worden geopend. Daarom moeten ze worden ondergebracht in snelle gegevensopslag en worden geïndexeerd of gestructureerd voor het optimaliseren van de query's die het waarschuwende systeem uitvoert. In sommige gevallen kan het voor de telemetrieservice die de gegevens op elk knooppunt verzamelt nodig zijn om gegevens lokaal te formatteren en op te slaan, zodat een lokale instantie van het waarschuwende systeem snel melding kan maken van problemen. Dezelfde gegevens kunnen worden verzonden naar de opslagschrijfservice die wordt weergegeven in de vorige diagrammen en centraal worden opgeslagen als dit ook voor andere doeleinden vereist is.
Informatie die wordt gebruikt voor meer uitgebreide analyse, voor rapportage en het herkennen van historische trends is minder urgent en kan worden opgeslagen op een manier die ondersteuning biedt voor gegevensanalyse en ad-hoc-query's. Zie voor meer informatie de sectie Hot-, warm- en cold-analyse ondersteunen verderop in dit document.
Logboekrotatie en gegevensretentie
Instrumentatie kan grote hoeveelheden gegevens genereren. Deze gegevens kunnen op verschillende plaatsen worden ondergebracht, te beginnen met de onbewerkte logboekbestanden, logboekbestanden voor tracering en andere gegevens die op elk knooppunt zijn vastgelegd voor de geconsolideerde, opgeschoonde en gepartitioneerde weergave van deze gegevens in gedeelde opslag. In sommige gevallen worden de oorspronkelijke onbewerkte brongegevens verwijderd van elk knooppunt nadat de gegevens zijn verwerkt en overgebracht. In andere gevallen is het mogelijk noodzakelijk of nuttig om de onbewerkte gegevens op te slaan. Gegevens die worden gegenereerd voor foutopsporing kunnen bijvoorbeeld mogelijk het best in onbewerkte vorm beschikbaar blijven, maar kunnen snel worden verwijderd nadat de fouten zijn verholpen.
Prestatiegegevens hebben vaak een langere levensduur, zodat ze kunnen worden gebruikt voor het ontdekken van prestatietrends en voor het plannen van capaciteit. De geconsolideerde weergave van deze gegevens wordt meestal voor een beperkte periode online opgeslagen voor snelle toegang. Daarna kunnen deze worden gearchiveerd of verwijderd. Gegevens verzameld voor het meten en facturering van klanten moeten mogelijk voor onbepaalde tijd worden opgeslagen. Bovendien zijn er mogelijk voorschriften die bepalen dat bepaalde gegevens, die worden verzameld voor controle- en beveiligingsdoeleinden, ook moeten worden gearchiveerd en opgeslagen. Deze gegevens zijn ook gevoelig en moeten mogelijk worden versleuteld of anders beveiligd om manipulatie te voorkomen. U moet nooit wachtwoorden van gebruikers of andere informatie die kan worden gebruikt voor identiteitsfraude vastleggen. Zulke gegevens moeten uit deze informatie worden verwijderd voordat deze wordt opgeslagen.
Down-sampling
Het is handig om historische gegevens op te slaan, zodat u ook op lange termijn trends kunt herkennen. In plaats van de oude gegevens in zijn geheel op te slaan, is down-sampling van de gegevens mogelijk, zodat de resolutie en kosten voor opslag worden verlaagd. Als voorbeeld: u kunt gegevens consolideren die meer dan een maand oud zijn om een beeld per uur te vormen, in plaats van prestatieindicatoren per minuut op te slaan.
Best practices voor het verzamelen en opslaan van informatie voor logboekregistratie
De volgende lijst bevat een overzicht van best practices voor het vastleggen en opslaan van informatie van logboekregistratie:
De bewakingsagent of de gegevensverzamelingsservice moet worden uitgevoerd als een out-of-process-service en moet eenvoudig te implementeren zijn.
Alle uitvoer van de bewakingsagent of service voor gegevensverzameling moet een agnostische indeling hebben die onafhankelijk is van computer, besturingssysteem of netwerkprotocol. Verzend bijvoorbeeld informatie in een zelfbeschrijvende indeling zoals JSON, MessagePack of Protobuf, in plaats van ETL/ETW. Het gebruik van een standaardindeling zorgt ervoor dat het systeem verwerkingspijplijnen kan bouwen. Onderdelen die gegevens in de overeengekomen indeling lezen, transformeren en verzenden, kunnen eenvoudig worden geïntegreerd.
Het proces voor het bewaken en verzamelen van gegevens moet failsafe zijn en moet geen cascade-foutcondities activeren.
In het geval van een tijdelijke fout bij het verzenden van gegevens naar een gegevens-sink, moet de bewakingsagent of service voor gegevensverzameling worden voorbereid om opnieuw telemetriegegevens te rangschikken, zodat de meest recente gegevens eerst worden verzonden. (De bewakingsagent/service voor gegevensverzameling kan ervoor kiezen om de oudere gegevens te verwijderen of deze lokaal op te slaan en later naar eigen goeddunken te verzenden.)
Gegevens analyseren en problemen diagnosticeren
Een belangrijk onderdeel van het proces voor bewaking en diagnostiek, is het analyseren van de verzamelde gegevens om een goed beeld te krijgen van het algehele welzijn van het systeem. U moet uw eigen KPI's en metrische prestatiegegevens gedefinieerd hebben en het is belangrijk te begrijpen hoe u de gegevens kunt structureren die zijn verzameld om te voldoen aan de vereisten van uw analyse. Het is ook belangrijk om te begrijpen hoe de gegevens die zijn opgenomen in de verschillende metrische gegevens en logboekbestanden worden gecorreleerd, omdat deze informatie de sleutel kan zijn tot het bijhouden van een reeks gebeurtenissen en kan helpen bij het analyseren van problemen die zich voordoen.
Zoals beschreven in de sectie Instrumentatiegegevens consolideren, worden de gegevens voor elk onderdeel van het systeem meestal lokaal opgenomen, maar moeten ze over het algemeen worden gecombineerd met gegevens die zijn gegenereerd op andere sites die deel uitmaken van het systeem. Deze informatie vereist zorgvuldige correlatie om ervoor te zorgen dat de gegevens nauwkeurig worden gecombineerd. De gebruiksgegevens voor een bewerking kunnen bijvoorbeeld een knooppunt omvatten dat als host fungeert voor een website waarmee een gebruiker verbinding maakt, een knooppunt waarop een afzonderlijke service wordt uitgevoerd die toegankelijk is als onderdeel van deze bewerking, en gegevensopslag op een ander knooppunt. Deze informatie moet worden gekoppeld om een algemeen overzicht te bieden van het gebruik van de resources en verwerking voor de bewerking. Sommige voorverwerking en filteren van gegevens kunnen zich voordoen op het knooppunt waarop de gegevens worden vastgelegd, terwijl aggregatie en opmaak waarschijnlijker op een centraal knooppunt plaatsvinden.
Ondersteunen van hot-, warm- en cold-analyse
Het analyseren en formatteren van de gegevens voor visualisatie-, rapportage- en waarschuwingsdoeleinden kan een complex proces zijn dat een eigen set resources verbruikt. Sommige formulieren van de bewaking zijn tijdkritiek en vereisen directe analyse van gegevens om effectief te zijn. Dit staat bekend als hot-analyse. Voorbeelden hiervan zijn de analyses die vereist zijn voor waarschuwingen en sommige aspecten van beveiligingsbewaking (zoals een aanval op het systeem detecteren). Gegevens die voor deze doeleinden zijn vereist, moeten snel beschikbaar en gestructureerd zijn voor efficiënte verwerking. In sommige gevallen kan het nodig zijn om de analyseverwerking te verplaatsen naar de afzonderlijke knooppunten waar de gegevens worden bewaard.
Andere vormen van analyse zijn minder urgent en vereisen mogelijk enige berekening en aggregatie nadat de onbewerkte gegevens zijn ontvangen. Dit heet warm-analyse. Analyse van prestaties worden vaak in deze categorie ingedeeld. In dit geval is een geïsoleerde, enkele prestatiegebeurtenis waarschijnlijk niet statistisch relevant. (Dit kan worden veroorzaakt door een plotselinge piek of glitch.) De gegevens uit een reeks gebeurtenissen moeten een betrouwbaarder beeld bieden van systeemprestaties.
Warm-analyse kan ook worden gebruikt om te helpen bij het analyseren van statusproblemen. Een statusgebeurtenis wordt gewoonlijk verwerkt met hot-analyse en kan onmiddellijk een melding genereren. Een operator moet in staat zijn op de redenen voor de statusgebeurtenis in te zoomen door de gegevens van het warm-pad te onderzoeken. Deze gegevens moet informatie bevatten over de gebeurtenissen die tot het probleem leiden dat de statusgebeurtenis heeft veroorzaakt.
Bepaalde typen bewaking genereren meer lange-termijngegevens. Deze analyse kan worden uitgevoerd op een later tijdstip, mogelijk volgens een vooraf gedefinieerd schema. In sommige gevallen moet de analyse mogelijk complex filteren van grote hoeveelheden gegevens uitvoeren, vastgelegd over een bepaalde periode. Dit heet cold-analyse. De belangrijkste vereiste is dat de gegevens veilig worden opgeslagen nadat deze zijn opgenomen. Bewaking en controle van het gebruik vereisen bijvoorbeeld een duidelijk beeld van de status van het systeem op regelmatige tijdsintervallen, maar deze informatie over de status hoeft niet onmiddellijk nadat deze is verzameld beschikbaar te zijn voor het verwerken.
Een operator kan cold-analyse ook gebruiken om de gegevens van voorspellende statusanalyse te leveren. De operator kan gedurende een bepaalde periode historische gegevens verzamelen en ze gebruiken in combinatie met de huidige statusgegevens (opgehaald uit het hot-pad) om trends te analyseren die binnenkort statusproblemen kunnen veroorzaken. In dergelijke gevallen kan het nodig zijn om een waarschuwing te activeren, zodat de herstelbewerking kan worden uitgevoerd.
Correleren van gegevens
De gegevens die door instrumentatie worden opgevangen, kunnen een momentopname van de systeemstatus geven, maar het doel van de analyse is dat met deze gegevens actie wordt ondernomen. Voorbeeld:
- Wat is de oorzaak van intensief I/O-laden op systeemniveau op een bepaald tijdstip?
- Is dit het resultaat van een groot aantal databasebewerkingen?
- Is dit weerspiegeld in de reactietijden van de database, het aantal transacties per seconde en de reactietijden van de toepassing op hetzelfde punt?
Zo ja, dan kan het sharden van gegevens over meerdere servers mogelijk de belasting verminderen. Bovendien kunnen uitzonderingen optreden als gevolg van een storing op elk niveau van het systeem. Een uitzondering in één niveau activeert vaak nog een fout in het bovenstaande niveau.
Daarom moet u de verschillende soorten bewakingsgegevens op elk niveau kunnen correleren om een algemeen overzicht te produceren van de status van het systeem en de toepassingen die erop worden uitgevoerd. U kunt deze informatie daarna gebruiken om te bepalen of het systeem acceptabel werkt of niet en om te bepalen wat kan worden gedaan om de kwaliteit van het systeem te verbeteren.
Zoals beschreven in de sectie Informatie voor het correleren van gegevens, moet u ervoor zorgen dat de onbewerkte gegevens voldoende informatie over context en activiteis-id bevatten om de vereiste aggregaties voor het correleren van gebeurtenissen te ondersteunen. Bovendien kunnen deze gegevens worden ondergebracht in verschillende indelingen en kan het nodig zijn om deze informatie te parseren, om deze te converteren naar een gestandaardiseerde indeling voor analyse.
Het oplossen en diagnosticeren van problemen
Diagnose vereist de mogelijkheid om de oorzaak van fouten of onverwacht gedrag te bepalen, met inbegrip van het uitvoeren van oorzaakanalyse van de hoofdmap. De informatie die is vereist omvat doorgaans:
- Gedetailleerde gegevens uit de gebeurtenislogboeken en traceringen, ofwel voor het hele systeem, ofwel voor een opgegeven subsysteem tijdens een opgegeven periode.
- Volledige stack-traces ten gevolge van uitzonderingen en fouten van een opgegeven niveau, die zich binnen het systeem of een opgegeven subsysteem gedurende een bepaalde periode voordoen.
- Crashdumps voor alle mislukte processen, ofwel op een willekeurige plaats in het systeem, ofwel voor een opgegeven subsysteem tijdens een opgegeven periode.
- Activiteitenlogboeken die de bewerkingen registreren, die worden uitgevoerd door alle gebruikers of voor geselecteerde gebruikers gedurende een bepaalde periode.
Gegevens analyseren voor het oplossen van problemen vereist vaak een uitgebreide technische kennis van de systeemarchitectuur en de verschillende onderdelen die samen de oplossing vormen. Als gevolg hiervan is vaak een grote mate van handmatige interventie nodig om de gegevens te interpreteren, de oorzaak van problemen vast te stellen en een geschikte strategie aan te bevelen om ze te corrigeren. Het kan zinvol zijn om een kopie van deze informatie op te slaan in de oorspronkelijke indeling en ze voor cold-analyse door een deskundige beschikbaar te stellen.
Gegevens visualiseren en waarschuwingen geven
Een belangrijk aspect van elk systeem van toezicht is de mogelijkheid om de gegevens zo te presenteren dat een operator snel eventuele trends of problemen vinden kan. Ook is het belangrijk om snel een operator te kunnen informeren als er een significante gebeurtenis is opgetreden die mogelijk aandacht vereist.
Gegevenspresentatie kan verschillende vormen aannemen, waaronder visualisatie met behulp van dashboards, waarschuwingen en rapportages.
Visualisatie met behulp van dashboards
De meest voorkomende manier om gegevens te visualiseren is het gebruik van dashboards die informatie kunnen weergeven als een reeks diagrammen, grafieken of een andere afbeelding. Deze items kunnen als parameters worden gebruikt en een analist moet de belangrijke parameters (zoals de periode) voor een specifieke situatie kunnen selecteren.
Dashboards kunnen hiërarchisch worden georganiseerd. Op het hoogste niveau kunnen dashboards een algemeen overzicht van elk aspect van het systeem geven, maar stellen ze een operator ook in staat om op details in te zoomen. Een dashboard dat bijvoorbeeld de algehele schijf-I/O's voor het systeem weergeeft, moet de analist toestaan om de I/O-frequenties voor elke afzonderlijke schijf te bekijken om na te gaan of een of meer specifieke apparaten verantwoordelijk zijn voor een onevenredige hoeveelheid verkeer. In het ideale geval moet het dashboard ook verwante informatie tonen, zoals de bron van elke aanvraag (de gebruiker of activiteit) die deze I/O genereert. Deze informatie kan vervolgens worden gebruikt om te bepalen of (en hoe) de belasting meer gelijkmatig over apparaten te verdelen en of het systeem beter zou presteren als meer apparaten zijn toegevoegd.
Een dashboard maakt mogelijk ook gebruik van kleurcodering of enige andere visuele aanwijzingen om waarden aan te geven die afwijkend lijken, of die zich buiten een verwacht bereik bevinden. Met behulp van het vorige voorbeeld:
- Een schijf met een I/O-snelheid die gedurende een langere periode bijna de maximale capaciteit bereikt (hot-schijf) kan rood gemarkeerd worden.
- Een schijf met een I/O-snelheid die periodiek op de maximumlimiet wordt uitgevoerd gedurende korte periodes (warm-schijf) kan geel worden gemarkeerd.
- Een schijf die normaal gebruik vertoont kan in groen worden weergegeven.
Houd er rekening mee dat een dashboardsysteem de onbewerkte gegevens moet hebben om efficiënt te kunnen werken. Als u uw eigen dashboardsysteem wilt maken, of een dashboard gebruikt dat is ontwikkeld door een andere organisatie, moet u begrijpen welke gegevens u moet verzamelen, met welke mate van granulatie en hoe deze moeten worden geformatteerd zodat het dashboard ze kan gebruiken.
Een goed dashboard geeft niet alleen informatie weer, maar maakt het ook voor een analist mogelijk ad-hoc vragen te stellen over die informatie. Sommige systemen bieden beheerhulpprogramma's die een operator kan gebruiken om deze taken uit te voeren en de onderliggende gegevens te verkennen. Daarnaast, afhankelijk van de opslagplaats die wordt gebruikt voor deze gegevens, is het misschien mogelijk rechtstreeks een query op deze gegevens uit te voeren, of ze te importeren in hulpprogramma's voor verdere analyse en rapportage, zoals Microsoft Excel.
Notitie
Omdat deze informatie mogelijk commercieel gevoelig is, moet u de toegang tot dashboards beperken tot bevoegd personeel. U moet ook de onderliggende gegevens voor dashboards beschermen om te voorkomen dat gebruikers deze wijzigen.
Waarschuwingen geven
Waarschuwen is het proces van het analyseren van de bewakings- en instrumentatiegegevens en het genereren van een melding als er een significante gebeurtenis wordt gedetecteerd.
Waarschuwen zorgt ervoor dat het systeem in orde, responsief en beveiligd blijft. Het is een belangrijk onderdeel van een systeem dat garanties over prestaties, beschikbaarheid en privacy geeft aan de gebruikers, waar wellicht onmiddellijk actie op de gegevens moet worden ondernemen. Een operator moet mogelijk een melding krijgen van de gebeurtenis die de waarschuwing heeft geactiveerd. Waarschuwen kan ook worden gebruikt om systeemfuncties zoals automatisch schalen aan te roepen.
Waarschuwen is meestal afhankelijk van de volgende instrumentatiegegevens:
- Beveiligingsevenementen. Als in de gebeurtenislogboeken wordt aangegeven dat herhaalde verificatie- of autorisatiefouten optreden, kan het systeem worden aangevallen en moet een operator worden geïnformeerd.
- Metrische gegevens over prestaties. Het systeem moet snel reageren als bepaalde metrische gegevens voor prestaties een opgegeven drempelwaarde overschrijden.
- Beschikbaarheidsgegevens. Als er een storing wordt gedetecteerd, is het mogelijk nodig om snel een of meer subsystemen op te starten of failover-overschakeling naar een back-up-resource uit te voeren. Herhaalde fouten in een subsysteem kunnen een indicatie zijn van ernstigere problemen.
Operators ontvangen mogelijk informatie over waarschuwingen over veel bezorgingskanalen zoals e-mail, een semafoon of een sms-bericht. Een waarschuwing kan ook een indicatie omvatten over hoe essentieel een situatie is. Veel waarschuwingssystemen ondersteunen abonneegroepen en alle operators die lid zijn van dezelfde groep, kunnen dezelfde set waarschuwingen ontvangen.
Een waarschuwingssysteem moet kunnen worden aangepast en de juiste waarden uit de onderliggende instrumentatiegegevens kunnen worden opgegeven als parameters. Deze aanpak maakt het een operator mogelijk om gegevens te filteren en zich te richten op deze drempels of combinaties van waarden die van belang zijn. Houd er rekening mee dat in sommige gevallen de onbewerkte gegevens kunnen worden opgegeven aan het waarschuwingssysteem. In andere gevallen is het mogelijk meer toepasselijk om cumulatieve gegevens op te geven. (Een waarschuwing kan bijvoorbeeld worden geactiveerd als het CPU-gebruik voor een knooppunt met 90 procent is overschreden in de afgelopen 10 minuten). De details die zijn opgegeven voor het waarschuwingssysteem moeten ook eventuele relevante samenvattingen en contextgegevens bevatten. Deze gegevens kunnen helpen het risico te verkleinen dat fout-positieve gebeurtenissen een waarschuwing veroorzaken.
Rapportage
Rapportage wordt gebruikt voor het genereren van een algemeen overzicht van het systeem. Dit maakt mogelijk gebruik van historische gegevens naast actuele informatie. Rapportagevereisten zelf kunnen worden onderverdeeld in twee hoofdcategorieën: operationele rapportage en rapportage van beveiliging.
Operationele rapportage bevat doorgaans de volgende aspecten:
- Statistische gegevens die u kunt gebruiken om inzicht te verkrijgen in het resourcegebruik van het algehele systeem of de opgegeven subsystemen tijdens een opgegeven tijdvenster.
- Trends in resourcegebruik identificeren voor het algehele systeem of opgegeven subsystemen tijdens een opgegeven periode.
- Bewaking van de uitzonderingen die zijn opgetreden in het hele systeem of in opgegeven subsystemen gedurende een opgegeven periode.
- Het bepalen van de efficiëntie van de toepassing in termen van de geïmplementeerde resources en het begrijpen of het volume van resources (en de bijbehorende kosten) kan worden verminderd zonder dat dit onnodig van invloed is op de prestaties.
Beveiligingsrapportage heeft betrekking op het bijhouden van het gebruik van het systeem door klanten. Dit is onder andere:
- Gebruikersbewerkingen controleren. Hiervoor moeten de afzonderlijke aanvragen worden vastgelegd die door elke gebruiker worden uitgevoerd, samen met datums en tijden. De gegevens moeten worden gestructureerd zodat een beheerder snel de volgorde van de bewerkingen kan reconstrueren, die een gebruiker gedurende een bepaalde periode uitvoert.
- Resourcegebruik bijhouden door gebruiker. U moet hiervoor vastleggen hoe elke aanvraag voor een gebruiker toegang krijgt tot de diverse bronnen waaruit het systeem bestaat en hoelang. Een beheerder moet deze gegevens kunnen gebruiken voor het genereren van een utilisatierapport voor gebruikers gedurende een bepaalde periode, mogelijk voor facturatie.
In veel gevallen kunnen batchprocessen rapporten genereren volgens een ingesteld schema. (Latentie is normaal gesproken geen probleem.) Maar indien nodig moeten ze ook beschikbaar zijn voor generatie. Een voorbeeld: als u gegevens opslaat in een relationele database zoals Azure SQL Database, kunt u een hulpprogramma zoals SQL Server Reporting Services gebruiken voor het uitpakken en opmaken van gegevens en deze als een set met rapporten presenteren.
Volgende stappen
- Overzicht van Azure Monitor
- Monitor, diagnose, and troubleshoot Microsoft Azure Storage (Bewaken, diagnosticeren en problemen oplossen in Microsoft Azure Storage)
- Overzicht van waarschuwingen in Microsoft Azure
- Servicestatusmeldingen bekijken met Azure Portal
- Wat is Application Insights?
- Diagnostische gegevens over prestaties voor virtuele Azure-machines
- SQL Server Data Tools (SSDT) voor Visual Studio downloaden en installeren
Verwante resources
- Richtlijnen voor automatisch schalen beschrijft hoe u de management overhead kunt verkleinen door de noodzaak voor een operator te verminderen om voortdurend de prestaties van een systeem te controleren en beslissingen over het toevoegen of verwijderen van resources te maken.
- Het patroon Statuseindpuntbewaking beschrijft hoe u functionele controles implementeert in een toepassing waartoe externe hulpprogramma's met regelmatige tussenpozen toegang hebben via weergegeven eindpunten.
- Het patroon Prioriteitswachtrij laat zien hoe u prioriteit kunt geven aan berichten in de wachtrij, zodat urgente aanvragen worden ontvangen en kunnen worden verwerkt voordat u minder urgente berichten ontvangt.