Een big data-architectuur is ontworpen om de opname, verwerking en analyse van gegevens te verwerken die te groot of complex zijn voor traditionele databasesystemen. Bij welke hoeveelheid gegevens organisaties gebruik gaan maken van een big data-architectuur verschilt. Dit is afhankelijk van de mogelijkheden van de gebruikers en hun hulpprogramma's. Sommige organisaties gebruiken al voor enkele honderden gigabytes aan gegevens big data-oplossingen, terwijl andere organisaties pas overstappen bij honderden terabytes. Als hulpprogramma's voor het werken met big datasets vooruitgaan, betekent dit ook de betekenis van big data. Deze term gaat steeds meer over de waarde die via geavanceerde analyse kan worden geëxtraheerd uit gegevenssets, in plaats van alleen over de hoeveelheid gegevens, hoewel het meestal wel om zeer grote hoeveelheden gaat.
Het gegevenslandschap is de afgelopen jaren veranderd. Wat u met gegevens kunt doen, of wat er op dit gebied van u wordt verwacht, is veranderd. De kosten voor opslag zijn drastisch gedaald, terwijl er steeds meer manieren komen waarop gegevens kunnen worden verzameld. Sommige gegevens worden in een razendsnel tempo gegenereerd en moeten in een continu proces worden samengevoegd en geanalyseerd. Andere gegevens komen in een trager tempo binnen, maar in zeer grote hoeveelheden, vaak in de vorm van historische gegevens over vele tientallen jaren. U kunt te maken krijgen met geavanceerde analyseproblemen, maar ook met problemen waarvoor Machine Learning is vereist. Dit zijn uitdagingen die kunnen worden opgelost met een big data-architectuur.
Bij big data-oplossingen is meestal sprake van minstens een van de volgende typen workloads:
- Batchverwerking van ongebruikte big data-bronnen.
- Realtimeverwerking van actieve big data.
- Interactieve verkenning van big data.
- Predictive Analytics en Machine Learning.
Overweeg om een big data-architectuur te gebruiken als u het volgende wilt doen:
- Hoeveelheden gegevens opslaan en verwerken die te groot zijn voor een traditionele database.
- Ongestructureerde gegevens voorbereiden voor analyse en rapportage.
- Niet-gebonden gegevensstromen vastleggen, verwerken en analyseren, in realtime of met lage latentie.
Onderdelen van een big data-architectuur
In het volgende diagram ziet u de logische onderdelen die horen bij een big data-architectuur. Afzonderlijke oplossingen bevatten mogelijk niet alle items uit dit diagram.
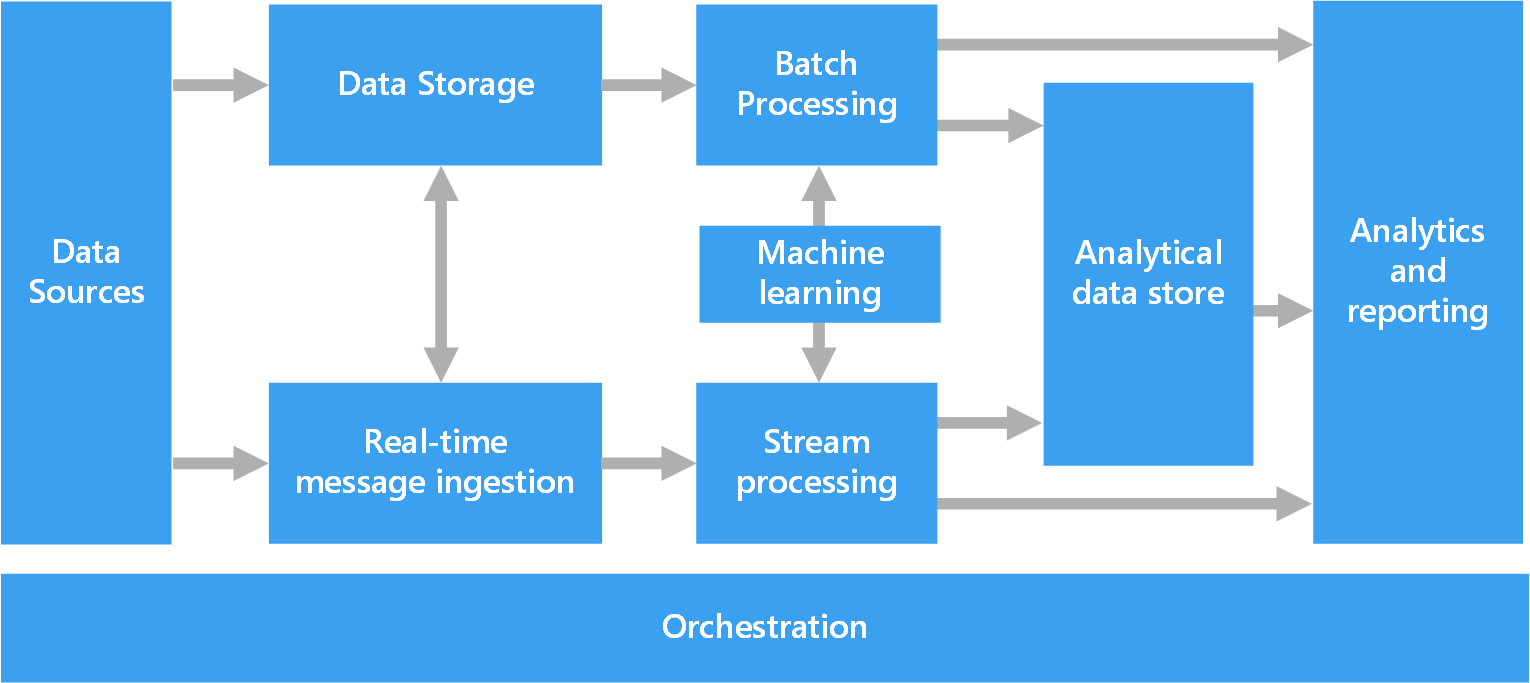
De meeste big data-architecturen bevatten een of meer van de volgende onderdelen:
Gegevensbronnen. Alle big data-oplossingen hebben een of meer gegevensbronnen als uitgangspunt. Voorbeelden zijn:
- Toepassingsgegevensopslag, zoals relationele databases.
- Statische bestanden die zijn geproduceerd met toepassingen, zoals logboekbestanden van webservers.
- Realtimegegevensbronnen, zoals IoT-apparaten.
Gegevensopslag. Gegevens voor batchverwerking worden meestal opgeslagen in een gedistribueerde bestandsopslag die hoge aantallen grote bestanden kan bevatten in verschillende indelingen. Dit soort opslag wordt ook wel een data lake genoemd. Opties voor het implementeren van deze opslag zijn Azure Data Lake Store of blobcontainers in Azure Storage.
Batchverwerking. Omdat de gegevenssets zo groot zijn, moeten met een big data-oplossing vaak gegevensbestanden worden verwerkt met behulp van langlopende batchtaken om de gegevens te filteren, samen te voegen en anderszins voor te bereiden voor analyse. Deze taken omvatten meestal het lezen van bronbestanden, het verwerken ervan, en het schrijven van de uitvoer naar nieuwe bestanden. Opties zijn onder andere het uitvoeren van U-SQL-taken in Azure Data Lake Analytics, met behulp van Hive-taken, Pig-taken of aangepaste taken voor toewijzen/verminderen in een HDInsight Hadoop-cluster, of met behulp van Java-, Scala- of Python-programma’s in een HDInsight Spark-cluster.
Berichtopname in realtime. Als de oplossing realtimebronnen omvat, moet de architectuur een methode bieden om berichten in realtime vast te leggen en op te slaan voor stroomverwerking. Dit kan een eenvoudige gegevensopslag zijn, waar binnenkomende berichten voor verwerking worden bewaard in een map. Veel oplossingen vereisen echter een berichtopnameopslag die als buffer optreedt voor berichten, en die ondersteuning biedt voor uitschalen, betrouwbare bezorging en andere zaken op het gebied van berichtwachtrijen. Dit gedeelte van een streaming-architectuur wordt vaak aangeduid als 'stroombuffering'. Opties zijn onder andere Azure Event Hubs, Azure IoT Hub en Kafka.
Stroomverwerking. Na het vastleggen van realtimeberichten moeten deze worden verwerkt door ze te filteren, samen te voegen en anderszins voor te bereiden voor analyse. De verwerkte stroom met gegevens wordt vervolgens naar een uitvoer-sink geschreven. Azure Stream Analytics biedt een beheerde service voor het verwerken van stromen, gebaseerd op de doorlopende uitvoering van SQL-query’s voor niet-gebonden stromen. U kunt ook open source Apache-streamingtechnologieën zoals Spark Streaming gebruiken in een HDInsight-cluster.
Machine learning. Het lezen van de voorbereide gegevens voor analyse (van batch- of stroomverwerking), machine learning-algoritmen kunnen worden gebruikt om modellen te bouwen die resultaten kunnen voorspellen of gegevens kunnen classificeren. Deze modellen kunnen worden getraind op grote gegevenssets en de resulterende modellen kunnen worden gebruikt om nieuwe gegevens te analyseren en voorspellingen te doen. Dit kan worden gedaan met behulp van Azure Machine Learning
Analytische gegevensarchieven. In veel big data-oplossingen worden gegevens voorbereid en worden de verwerkte gegevens vervolgens in een gestructureerde indeling aangeboden, die kan worden doorzocht met behulp van analysehulpprogramma's. De analytische gegevensopslag waarmee deze query’s worden aangeboden, kunnen relationele datawarehouses in Kimball-stijl zijn, zoals bij de meeste traditionele BI-oplossingen (Business Intelligence). De gegevens kunnen ook worden gepresenteerd met behulp van een NoSQL-technologie met lage latentie, zoals HBase, of met een interactieve Hive-database die een metagegevensabstractie biedt van gegevensbestanden in de gedistribueerde gegevensopslag. Azure Synapse Analytics biedt een beheerde service voor grootschalige datawarehousing in de cloud. HDInsight biedt ondersteuning voor Interactive Hive, HBase en Spark SQL, dat ook kan worden gebruikt om de gegevens aan te bieden voor analyse.
Analyse en rapportage. Het doel van de meeste big data-oplossingen is inzicht te bieden in gegevens via analyse en rapportage. De architectuur kan ook een gegevensmodellaag bevatten, zoals een multidimensionale OLAP-kubus of tabelvormig gegevensmodel in Azure Analysis Services, om gebruikers in staat te stellen de gegevens te analyseren. Selfservice-BI wordt mogelijk ook ondersteund, met behulp van modellerings- en visualisatietechnologieën in Microsoft Power BI of Microsoft Excel. Onder analyse en rapportage wordt ook verstaan het interactief verkennen van gegevens door wetenschappers of gegevensanalisten. Voor deze scenario's ondersteunen veel Azure-services analytische notebooks, zoals Jupyter, zodat deze gebruikers hun bestaande vaardigheden kunnen gebruiken met Python of Microsoft R. Voor grootschalige gegevensverkenning kunt u Microsoft R Server gebruiken, zelfstandig of met Spark.
Indeling. De meeste big data-oplossingen bestaan uit herhaalde gegevensverwerking, ingekapseld in werkstromen, waarmee brongegevens worden getransformeerd, gegevens worden verplaatst tussen meerdere bronnen en sinks, de verwerkte gegevens in een analytisch gegevensarchief worden geladen, of de resultaten rechtstreeks naar een rapport of een dashboard worden gepusht. U kunt een indelingstechnologie zoals Azure Data Factory of Apache Oozie en Sqoop gebruiken om deze werkstromen te automatiseren.
Lambda-architectuur
Als u werkt met zeer grote gegevenssets, kan het lang duren om het soort query's uit te voeren waaraan klanten behoefte hebben. Deze query's kunnen niet in realtime worden uitgevoerd en vereisen vaak algoritmen zoals MapReduce die parallel worden uitgevoerd in de hele gegevensset. De resultaten worden vervolgens gescheiden van de onbewerkte gegevens opgeslagen en gebruikt voor het uitvoeren van query's.
Een nadeel van deze benadering is dat het latentie introduceert. Als de verwerking enkele uren duurt, kan een query resultaten retourneren die enkele uren oud zijn. Het liefst wilt u resultaten in realtime ontvangen (wellicht met enig verlies van nauwkeurigheid) en deze resultaten combineren met de resultaten uit de batchanalyse.
In de Lambda-architectuur, geïntroduceerd door Nathan Marz, wordt dit probleem opgelost door twee paden te maken voor de gegevensstroom. Alle gegevens die het systeem binnenkomen, volgen deze twee paden:
In een batchlaag (koud pad) worden alle binnenkomende gegevens opgeslagen in onbewerkte vorm. Deze gegevens worden in batches verwerkt. Het resultaat van deze verwerking wordt opgeslagen als een batchweergave.
In een snelheidslaag (dynamisch pad) worden gegevens in realtime geanalyseerd. Deze laag is ontworpen voor een lage latentie. Dit gaat ten koste van de nauwkeurigheid.
De batchlaag wordt opgenomen in de leveringslaag waarmee de batchweergave wordt geïndexeerd voor het efficiënt uitvoeren van query's. De snelheidslaag werkt de leveringslaag bij met incrementele updates op basis van de meest recente gegevens.
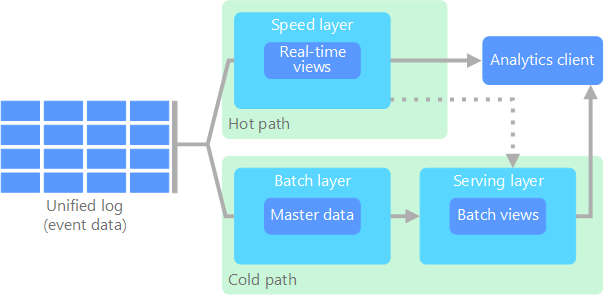
Gegevens die via het dynamische pad worden geleid, zijn onderhevig aan de latentievereisten die zijn opgelegd op basis van de snelheidslaag, zodat ze zo snel mogelijk kunnen worden verwerkt. Om de gegevens zo snel mogelijk gereed te maken, moet vaak worden ingeboet aan nauwkeurigheid. Dit gebeurt bijvoorbeeld in een IoT-scenario waarbij via een groot aantal temperatuursensoren telemetriegegevens worden verzonden. De snelheidslaag kan worden gebruikt om een verschuivend tijdvenster van de binnenkomende gegevens te verwerken.
Gegevens die binnenkomen via het koude pad, krijgen echter niet te maken met dezelfde lage latentievereisten. Dit zorgt ervoor dat grote gegevenssets heel nauwkeurig kunnen worden berekend, wat zeer tijdsintensief kan zijn.
Uiteindelijk komen het dynamische en het koude pad samen in de clienttoepassing voor analyse. Als via de client gegevens in vrijwel realtime moeten worden weergegeven (waarbij ze iets minder nauwkeurig mogen zijn), worden de resultaten van het dynamische pad gebruikt. In de overige gevallen maakt de client gebruik van de resultaten van het koude pad (die nauwkeuriger zijn, maar minder actueel). Met andere woorden: het dynamische pad bevat gegevens voor een relatief klein tijdvenster, waarna de resultaten kunnen worden bijgewerkt met nauwkeurigere gegevens uit het koude pad.
De onbewerkte gegevens in de batchlaag kunnen niet worden gewijzigd. Binnenkomende gegevens worden altijd toegevoegd aan de bestaande gegevens; de vorige gegevens worden nooit overschreven. Elke wijziging in een specifieke referentiewaarde wordt opnieuw opgeslagen als een gebeurtenisrecord met een nieuw tijdstempel. Hierdoor kan er op elk moment in de geschiedenis van de verzamelde gegevens een nieuwe berekening worden uitgevoerd. De mogelijkheid om de batchweergave opnieuw te berekenen uit de oorspronkelijke onbewerkte gegevens, is van belang omdat hierdoor weergaven kunnen worden gemaakt terwijl het systeem zich ontwikkelt.
Kappa-architectuur
Een nadeel van de Lambda-architectuur is de complexiteit. Verwerkingslogica wordt weergegeven op twee verschillende plaatsen, de koude en dynamische paden, met behulp van verschillende frameworks. Dit leidt tot dubbele berekeningslogica en tot complex beheer van de architectuur voor beide paden.
De Kappa-architectuur is geïntroduceerd door Jay Kreps als een alternatief voor de Lambda-architectuur. De basisdoelen zijn dezelfde als die van de Lambda-architectuur, maar er is één belangrijk verschil: alle gegevens worden via één enkel pad geleid met behulp van een verwerkingssysteem voor stromen.
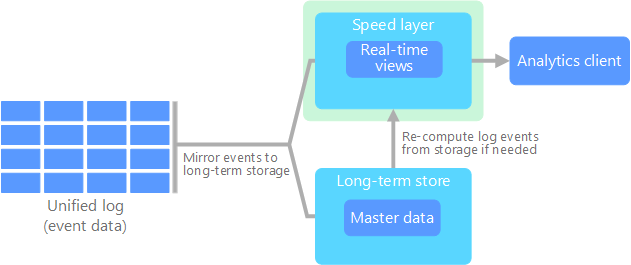
Er zijn enkele overeenkomsten met de batchlaag van de Lambda-architectuur. Zo kunnen de gebeurtenisgegevens niet worden gewijzigd en worden alle gegevens verzameld, in plaats van een subset hiervan. De gegevens worden als een gebeurtenisstroom opgenomen in een gedistribueerd en fouttolerant gecombineerd logboek. Deze gebeurtenissen worden geordend en de status van een gebeurtenis wordt alleen gewijzigd wanneer er een nieuwe gebeurtenis wordt toegevoegd. Net zoals bij de snelheidslaag van de Lambda-architectuur wordt de gebeurtenisverwerking volledig afgehandeld in de invoerstroom en is er sprake van realtimeweergave.
Als u de hele gegevensset opnieuw wilt berekenen (net zoals de batchlaag doet in de Lambda-architectuur), speelt u de stroom opnieuw af. Meestal moet u een parallelle uitvoering gebruiken om de berekening snel genoeg te voltooien.
Internet der dingen (IoT)
Uit praktisch oogpunt vertegenwoordigt IoT (Internet of Things) elk apparaat dat is verbonden met internet. Dit omvat uw pc, mobiele telefoon, smartwatch, slimme thermostaat en slimme koelkast, maar bijvoorbeeld ook met wifi uitgeruste auto's, hartmonitorimplantaten en alle overige apparaten die zijn verbonden met internet en gegevens verzenden of ontvangen. Het aantal verbonden apparaten groeit met de dag, net zoals het aantal gegevens dat via deze apparaten wordt verzameld. Het verzamelen van deze gegevens vindt vaak plaats in een zeer beperkte omgeving, soms met een hoge latentie. Soms worden er vanuit omgevingen met een lage latentie gegevens verzonden door duizenden of zelfs miljoenen apparaten tegelijk. Het is dan belangrijk dat deze gegevens snel kunnen worden opgenomen en verwerkt. Er is een goede planning vereist om op de juiste manier om te gaan met deze beperkingen en unieke vereisten.
Gebeurtenisafhankelijke architecturen zijn essentieel voor IoT-oplossingen. Het volgende diagram toont een mogelijke logische architectuur voor IoT. In het diagram ligt de nadruk op de onderdelen van de architectuur die gebeurtenisstromen verwerken.
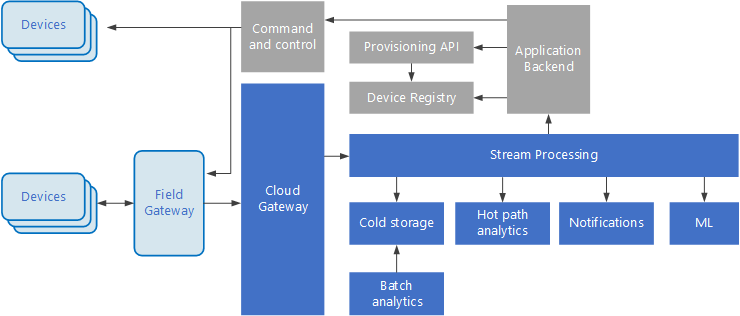
De cloudgateway neemt apparaatgebeurtenissen op bij de cloudgrens met behulp van een betrouwbaar berichtensysteem met lage latentie.
Apparaten kunnen gebeurtenissen rechtstreeks naar de cloudgateway of via een veldgateway verzenden. Een veldgateway is een gespecialiseerd apparaat of gespecialiseerde software, meestal op dezelfde locatie als de apparaten, waarmee gebeurtenissen worden ontvangen en doorgestuurd naar de cloudgateway. De veldgateway mogelijk kan ook de ongecodeerde apparaatgebeurtenissen voorverwerken, waarbij functies worden uitgevoerd als filteren, aggregeren of protocoltransformatie.
Als de gebeurtenissen zijn opgenomen, gaan ze door een of meer streamprocessors die de gegevens kunnen routeren (bijvoorbeeld naar de opslag), analyseren of op een andere manier verwerken.
Hieronder vindt u enkele algemene typen verwerking. (Deze lijst is niet volledig.)
Het schrijven van gebeurtenisgegevens naar koude opslag, voor archivering of batchanalyse.
Analyse van het langzame pad, waarbij de gebeurtenisstroom nagenoeg in realtime wordt geanalyseerd om afwijkingen te detecteren, patronen in voortschrijdende tijdvensters te herkennen of alarmen te activeren als zich een bepaalde toestand in de stream voordoet.
Verwerken van speciale typen niet-telemetrieberichten van apparaten, zoals meldingen en alarmen.
Machine learning.
De grijze vakken tonen onderdelen van een IoT-systeem die niet direct verband houden met het streamen van gebeurtenissen, maar zijn ter verduidelijking opgenomen.
Het apparaatregister is een database van de ingerichte apparaten, waaronder apparaat-id's en gewoonlijk metagegevens van apparaten, zoals de locatie.
De inrichtings-API is een normale, externe interface voor het inrichten en registreren van nieuwe apparaten.
In sommige IoT-oplossingen kunnen berichten met opdrachten en besturingsgegevens naar apparaten worden verzonden.
Volgende stappen
Bekijk de volgende relevante Azure-services: