Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Microsoft Fabric
Azure Data Factory
Organisaties moeten vaak gegevens uit meerdere bronnen in verschillende indelingen verzamelen en verplaatsen naar een of meer gegevensarchieven. Het doel is mogelijk niet hetzelfde type gegevensarchief als de bron en de gegevens moeten vaak worden vormgegeven, opgeschoond of getransformeerd voordat ze worden geladen.
Verschillende hulpprogramma's, services en processen helpen deze uitdagingen aan te pakken. Ongeacht de aanpak moet u het werk coördineren en gegevenstransformaties in de gegevenspijplijn toepassen. In de volgende secties worden de algemene methoden en procedures voor deze taken gemarkeerd.
ETL-proces (Extraheren, transformeren, laden)
ETL (Extract, Transform, Load) is een proces voor gegevensintegratie waarmee gegevens uit diverse bronnen worden samengevoegd tot een geïntegreerd gegevensarchief. Tijdens de transformatiefase worden gegevens gewijzigd volgens bedrijfsregels met behulp van een gespecialiseerde engine. Dit omvat vaak faseringstabellen die tijdelijk gegevens bevatten terwijl ze worden verwerkt en uiteindelijk in de bestemming worden geladen.
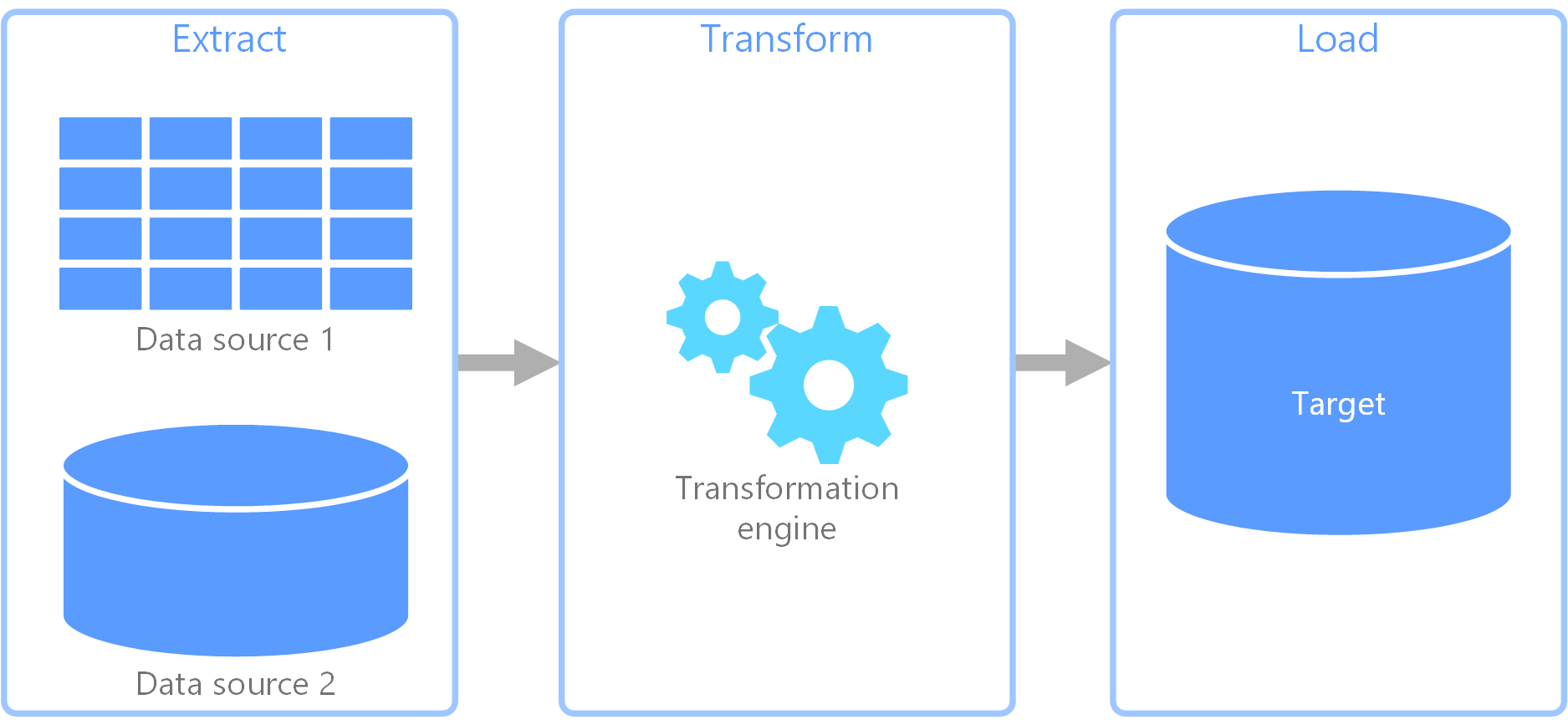
De gegevenstransformatie die plaatsvindt, omvat meestal verschillende bewerkingen, zoals filteren, sorteren, samenvoegen, gegevens samenvoegen, gegevens opschonen, ontdubbelen en valideren van gegevens.
Vaak worden de drie ETL-fasen parallel uitgevoerd om tijd te besparen. Terwijl gegevens bijvoorbeeld worden geëxtraheerd, kan een transformatieproces werken aan gegevens die al zijn ontvangen en voorbereiden voor het laden, en kan een laadproces beginnen met het werken aan de voorbereide gegevens, in plaats van te wachten tot het hele extractieproces is voltooid. Doorgaans ontwerpt u parallellisatie rond de grenzen van gegevenspartities (datum, tenant, shardsleutel) om schrijfconflicten te voorkomen en idempotente nieuwe pogingen in te schakelen.
Relevante service:
Andere hulpprogramma's:
Uitpakken, laden, transformeren (ELT)
Extraheren, laden, transformeren (ELT) verschilt alleen van ETL waar de transformatie plaatsvindt. In de ELT-pijplijn vindt de transformatie plaats in het doelgegevensarchief. In plaats van een afzonderlijke transformatie-engine te gebruiken, worden de verwerkingsmogelijkheden van het doelgegevensarchief gebruikt om gegevens te transformeren. Dit vereenvoudigt de architectuur door de transformatie-engine uit de pijplijn te verwijderen. Een ander voordeel van deze benadering is dat het schalen van het doelgegevensarchief ook de prestaties van de ELT-pijplijn schaalt. ELT werkt echter alleen goed wanneer het doelsysteem krachtig genoeg is om de gegevens efficiënt te transformeren.
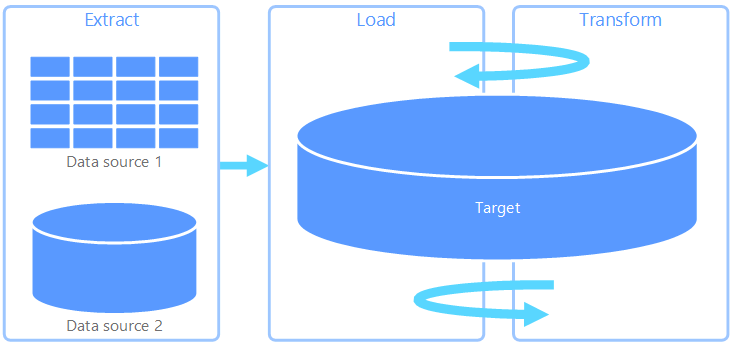
Typische gebruiksvoorbeelden voor ELT vallen binnen de big data-realm. U kunt bijvoorbeeld beginnen met het extraheren van brongegevens naar platte bestanden in schaalbare opslag, zoals een Hadoop Distributed File System (HDFS), Azure Blob Storage of Azure Data Lake Storage Gen2. Technologieën zoals Spark, Hive of PolyBase kunnen vervolgens worden gebruikt om query's uit te voeren op de brongegevens. Het belangrijkste punt met ELT is dat het gegevensarchief dat wordt gebruikt om de transformatie uit te voeren, hetzelfde gegevensarchief is als waar de gegevens uiteindelijk worden verbruikt. Dit gegevensarchief leest rechtstreeks vanuit de schaalbare opslag, in plaats van de gegevens in een eigen afzonderlijke opslag te laden. Deze methode slaat stappen voor het kopiëren van gegevens over die aanwezig zijn in ETL, wat vaak tijdrovend kan zijn voor grote gegevenssets. Sommige workloads materialiseren getransformeerde tabellen of weergaven om de prestaties van query's te verbeteren of governanceregels af te dwingen; ELT impliceert niet altijd puur gevirtualiseerde transformaties.
In de laatste fase van de ELT-pijplijn worden de brongegevens doorgaans omgezet in een indeling die efficiënter is voor de typen query's die moeten worden ondersteund. De gegevens kunnen bijvoorbeeld worden gepartitioneerd door veelgebruikte gefilterde sleutels. ELT kan ook geoptimaliseerde opslagindelingen zoals Parquet gebruiken. Dit is een kolomopslagindeling waarmee gegevens per kolom worden georganiseerd om compressie, predicaat pushdown en efficiënte analysescans mogelijk te maken.
Relevante Microsoft-service:
- Microsoft Fabric-datawarehouse
- Welkom bij Microsoft Fabric Lakehouse
- Microsoft Fabric-gegevenspijplijnen
ETL of ELT kiezen
De keuze tussen deze benaderingen is afhankelijk van uw vereisten.
Kies ETL wanneer:
- U moet zware transformaties weg van een beperkt doelsysteem offloaden
- Complexe bedrijfsregels vereisen gespecialiseerde transformatie-engines
- Wettelijke of nalevingsvereisten verplichten gecureerde faseringscontroles voordat ze worden geladen
Kies ELT wanneer:
- Uw doelsysteem is een modern datawarehouse of lakehouse met elastische rekenkrachtaanpassing
- U moet onbewerkte gegevens behouden voor verkennende analyse of toekomstige schemaontwikkeling
- Transformatielogica profiteert van de systeemeigen mogelijkheden van het doelsysteem
Gegevensstroom en controlestroom
In de context van gegevenspijplijnen zorgt de controlestroom voor de ordelijke verwerking van een set taken. Om de juiste verwerkingsvolgorde van deze taken af te dwingen, worden prioriteitsbeperkingen gebruikt. U kunt deze beperkingen beschouwen als connectors in een werkstroomdiagram, zoals wordt weergegeven in de volgende afbeelding. Elke taak heeft een resultaat, zoals geslaagd, mislukt of voltooiing. Elke volgende taak start de verwerking pas nadat de voorafgaande taak met een van deze resultaten is voltooid.
Beheerstromen voeren gegevensstromen uit als een taak. In een gegevensstroomtaak worden gegevens geëxtraheerd uit een bron, getransformeerd of geladen in een gegevensarchief. De uitvoer van een gegevensstroomtaak kan de invoer zijn voor de volgende gegevensstroomtaak en gegevensstromen kunnen parallel worden uitgevoerd. In tegenstelling tot besturingsstromen kunt u geen beperkingen toevoegen tussen taken in een gegevensstroom. U kunt echter een gegevensviewer toevoegen om de gegevens te observeren terwijl deze door elke taak worden verwerkt.
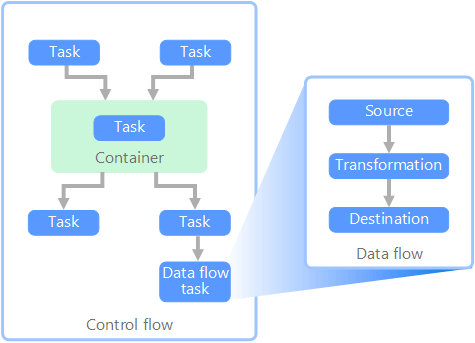
In het diagram zijn er verschillende taken binnen de controlestroom, een van deze taken is een gegevensstroomtaak. Een van de taken is genest in een container. Containers kunnen worden gebruikt om structuur aan taken te bieden, wat een werkeenheid biedt. Een voorbeeld hiervan is het herhalen van elementen in een verzameling, zoals bestanden in een map of database-instructies.
Relevante service:
Omgekeerde ETL
Reverse ETL is het proces van het verplaatsen van getransformeerde, gemodelleerde gegevens van analytische systemen naar operationele hulpprogramma's en toepassingen. In tegenstelling tot traditionele ETL, die gegevens van operationele systemen naar analyses stroomt, activeert omgekeerde ETL inzichten door gecureerde gegevens terug te pushen naar de locatie waar zakelijke gebruikers er actie op kunnen ondernemen. In een omgekeerde ETL-pijplijn stromen gegevens van datawarehouses, lakehouses of andere analytische opslag naar operationele systemen, zoals:
- CRM-platformen (Customer Relationship Management)
- Hulpprogramma's voor marketingautomatisering
- Systemen voor klantondersteuning
- Workloaddatabases
De benadering volgt nog steeds een extractie-, transformatie- en laadproces. In de transformatiestap converteert u van de specifieke indeling die wordt gebruikt door uw datawarehouse of een ander analysesysteem om deze uit te lijnen op de doelsystemen.
Zie Omgekeerd extraheren, transformeren en laden (ETL) met Azure Cosmos DB voor NoSQL voor een voorbeeld.
Architecturen voor streaminggegevens en dynamische paden
Wanneer u Lambda hot path of Kappa-architecturen nodig hebt, kunt u zich abonneren op gegevensbronnen wanneer gegevens worden gegenereerd. In tegenstelling tot ETL of ELT, die worden uitgevoerd op gegevenssets in geplande batches, verwerkt realtime streaming gegevens zodra deze binnenkomen, waardoor directe inzichten en acties mogelijk zijn.

In een streamingarchitectuur worden gegevens uit gebeurtenisbronnen opgenomen in een berichtenbroker of Event Hub (zoals Azure Event Hubs of Kafka) en vervolgens verwerkt door een streamprocessor (zoals Fabric Real-Time Intelligence, Azure Stream Analytics of Apache Flink). De processor past transformaties toe, zoals filteren, aggregeren, verrijken of samenvoegen met referentiegegevens ( allemaal in beweging) voordat resultaten worden gerouterd naar downstreamsystemen, zoals dashboards, waarschuwingen of databases.
Deze benadering is ideaal voor scenario's waarbij lage latentie en continue updates essentieel zijn, zoals:
- Productieapparatuur voor afwijkingen bewaken
- Fraude in financiële transacties detecteren
- Realtime dashboards inschakelen voor logistiek of bewerkingen
- Waarschuwingen activeren op basis van sensordrempels
Overwegingen voor betrouwbaarheid voor streaming
- Controlepunten gebruiken om ten minste één keer te verwerken en te herstellen na fouten
- Ontwerptransformaties die idempotent zijn om potentiële dubbele verwerking te verwerken
- Watermerken implementeren voor gebeurtenissen die te laat binnenkomen en verwerking buiten bestelling
- Wachtrijen met dode letters gebruiken voor berichten die niet kunnen worden verwerkt
Technologieopties
Gegevensarchieven:
- OLTP-gegevensarchieven (Online Transaction Processing)
- OLAP-gegevensarchieven (Online Analytical Processing)
- Datawarehouses
Pijplijn en indeling:
- Pijplijnindeling
- Microsoft Fabric Data Factory (moderne indeling)
- Azure Data Factory (hybride en niet-infrastructuurscenario's)
Lakehouse en moderne analyses: