Fase voor het verkrijgen en begrijpen van gegevens van de levenscyclus van het team Datawetenschap proces
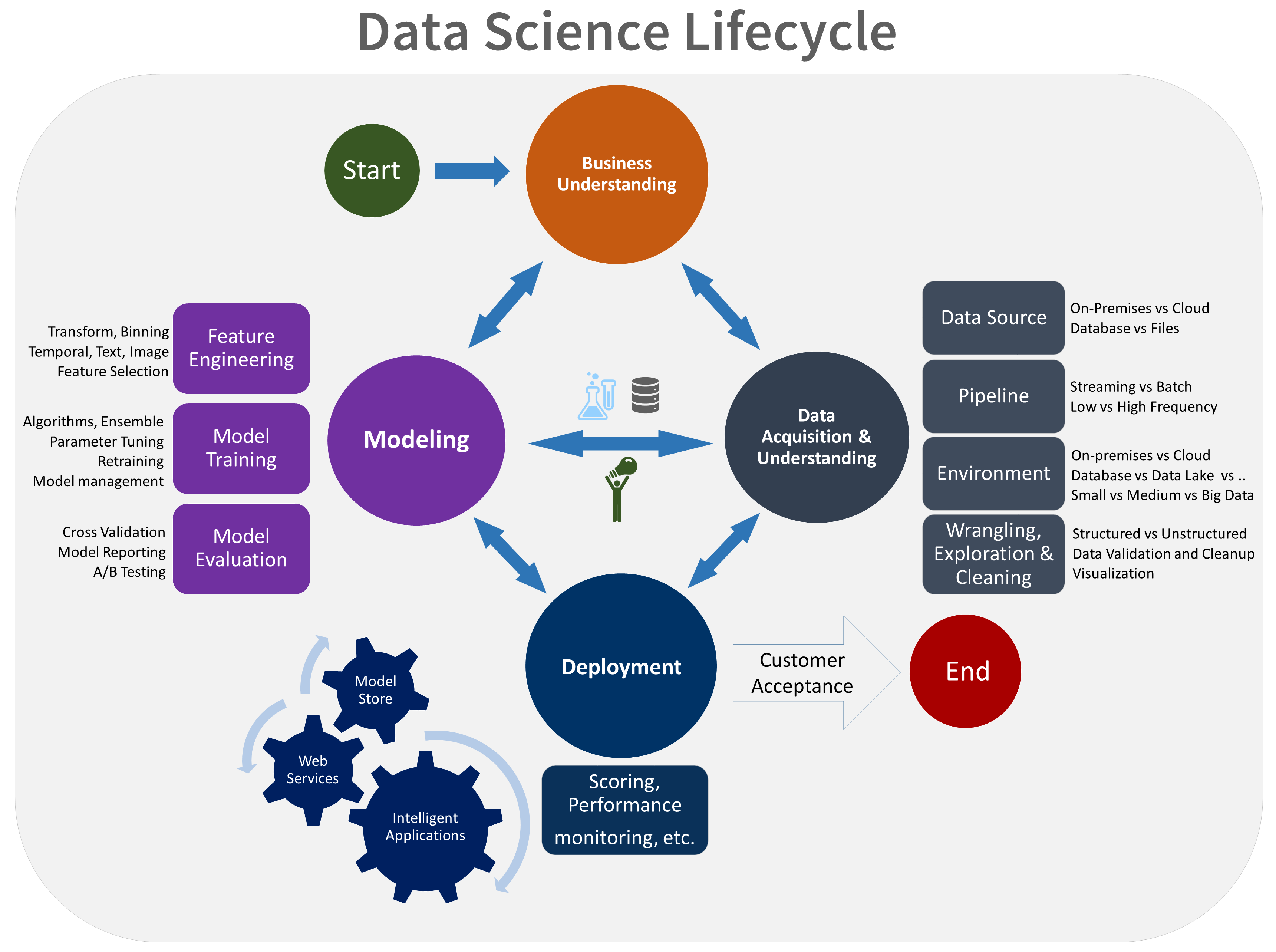
In dit artikel worden de doelen, taken en producten beschreven die zijn gekoppeld aan de fase voor het verkrijgen en begrijpen van gegevens van het TDSP (Team Datawetenschap Process). Dit proces biedt een aanbevolen levenscyclus die uw team kan gebruiken om uw data science-projecten te structuren. De levenscyclus bevat een overzicht van de belangrijkste fasen die uw team uitvoert, vaak iteratief:
- Bedrijfskennis
- Gegevens ophalen en begrijpen
- Modelleren
- Implementatie
- Klantacceptatie
Hier volgt een visuele weergave van de TDSP-levenscyclus:
Doelstellingen
De doelstellingen van de fase voor het verkrijgen en begrijpen van gegevens zijn:
Maak een schone, hoogwaardige gegevensset die duidelijk is gerelateerd aan de doelvariabelen. Zoek de gegevensset in de juiste analyseomgeving, zodat uw team klaar is voor de modelleringsfase.
Ontwikkel een oplossingsarchitectuur van de gegevenspijplijn die de gegevens regelmatig vernieuwt en beoordeelt.
De taken voltooien
De fase voor het verkrijgen en begrijpen van gegevens heeft drie hoofdtaken:
Gegevens opnemen in de doelanalytische omgeving.
Verken gegevens om te bepalen of de gegevens de vraag kunnen beantwoorden.
Stel een gegevenspijplijn in om nieuwe of regelmatig vernieuwde gegevens te scoren.
Gegevens opnemen
Stel een proces in voor het verplaatsen van gegevens van de bronlocaties naar de doellocaties waar u analysebewerkingen uitvoert, zoals training en voorspellingen.
Gegevens verkennen
Voordat u uw modellen traint, moet u een goed begrip van de gegevens ontwikkelen. Echte gegevenssets zijn vaak luidruchtig, ontbreken waarden of hebben een groot aantal andere discrepanties. U kunt gegevenssamenvatting en visualisatie gebruiken om de kwaliteit van uw gegevens te controleren en informatie te verzamelen voor het verwerken van de gegevens voordat deze gereed is voor modellering. Dit proces is vaak iteratief.
Nadat u tevreden bent over de kwaliteit van de opgeschoonde gegevens, is de volgende stap het beter begrijpen van de patronen in de gegevens. Deze gegevensanalyse helpt u bij het kiezen en ontwikkelen van een geschikt voorspellend model voor uw doel. Bepaal hoeveel de gegevens overeenkomen met het doel. Bepaal vervolgens of uw team voldoende gegevens heeft om verder te gaan met de volgende modelleringsstappen. Dit proces is vaak iteratief. Mogelijk moet u nieuwe gegevensbronnen zoeken met nauwkeurigere of relevantere gegevens om de gegevensset die in eerste instantie in de vorige fase is geïdentificeerd, aan te passen.
Een gegevenspijplijn instellen
Naast het opnemen en opschonen van gegevens, moet u doorgaans een proces instellen om nieuwe gegevens te beoordelen of de gegevens regelmatig te vernieuwen als onderdeel van een doorlopend leerproces. U kunt een gegevenspijplijn of werkstroom gebruiken om gegevens te scoren. We raden een pijplijn aan die gebruikmaakt van Azure Data Factory.
In deze fase ontwikkelt u een oplossingsarchitectuur van de gegevenspijplijn. U maakt de pijplijn parallel met de volgende fase van het data science-project. Afhankelijk van uw bedrijfsbehoeften en de beperkingen van uw bestaande systemen waarin deze oplossing wordt geïntegreerd, kan de pijplijn het volgende zijn:
- Op batch gebaseerde
- Streamen of realtime
- Hybride
Integreren met MLflow
Tijdens de fase van gegevensbegrip kunt u het bijhouden van experimenten van MLflow gebruiken om verschillende strategieën voor het verwerken van gegevens en experimentele gegevensanalyse bij te houden en te documenteren.
Artifacts
In deze fase levert uw team het volgende:
Een rapport over gegevenskwaliteit met gegevenssamenvattingen, de relaties tussen elk kenmerk en doel, de classificatie van variabelen en meer.
Een oplossingsarchitectuur, zoals een diagram of beschrijving van uw gegevenspijplijn die uw team gebruikt om voorspellingen uit te voeren op nieuwe gegevens. Dit diagram bevat ook de pijplijn om uw model opnieuw te trainen op basis van nieuwe gegevens. Wanneer u de TDSP-mapstructuursjabloon gebruikt, slaat u het document op in de projectmap.
Een controlepuntbeslissing. Voordat u begint met het bouwen van volledige functies en modellen, kunt u het project opnieuw evalueren om te bepalen of de verwachte waarde voldoende is om door te gaan met het uitvoeren ervan. U kunt bijvoorbeeld klaar zijn om door te gaan, meer gegevens moeten verzamelen of het project verlaten als u geen gegevens kunt vinden die de vragen beantwoorden.
Literatuur die door peers is beoordeeld
Onderzoekers publiceren studies over de TDSP in peer-review literatuur. De bronvermeldingen bieden een mogelijkheid om andere toepassingen of vergelijkbare ideeën te onderzoeken met de TDSP, waaronder de fase voor het verkrijgen en begrijpen van de levenscyclus van gegevens.
Medewerkers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Hoofdauteur:
- Mark Tabladillo | Senior Cloud Solution Architect
Als u niet-openbare LinkedIn-profielen wilt zien, meldt u zich aan bij LinkedIn.
Verwante resources
In deze artikelen worden de andere fasen van de TDSP-levenscyclus beschreven: