Schaalbare cloudtoepassingen en sitebetrouwbaarheidstechniek (SRE)
Het succes van uw cloudoplossing is afhankelijk van de betrouwbaarheid. Betrouwbaarheid kan breed worden gedefinieerd als de waarschijnlijkheid dat het systeem functioneert zoals verwacht, onder de opgegeven omgevingsomstandigheden, binnen een opgegeven tijd. Site Reliability Engineering (SRE) is een set principes en procedures voor het maken van schaalbare en zeer betrouwbare softwaresystemen. SRE wordt steeds vaker gebruikt tijdens het ontwerpen van digitale services om een grotere betrouwbaarheid te garanderen.
Zie AZ-400: Een SRE-strategie (Site Reliability Engineering) ontwikkelen voor meer informatie over SRE-strategieën.
Potentiële gebruikscases
De concepten in dit artikel zijn van toepassing op:
- Op API gebaseerde cloudservices.
- Openbare webtoepassingen.
- Op IoT gebaseerde of op gebeurtenissen gebaseerde workloads.
Architectuur

Download een PowerPoint-bestand van deze architectuur.
De architectuur die hier wordt beschouwd, is dat van een schaalbaar API-platform. De oplossing bestaat uit meerdere microservices die gebruikmaken van verschillende databases en opslagservices, waaronder SaaS-oplossingen (Software as a Service), zoals Dynamics 365 en Microsoft 365.
In dit artikel wordt een oplossing behandeld die gebruikmaakt van marketplace- en e-commercegebruiksscenario's op hoog niveau om de blokken te laten zien die in het diagram worden weergegeven. De gebruiksvoorbeelden zijn:
- Product browsen.
- Registratie en aanmelding.
- Weergave van inhoud, zoals nieuwsartikelen.
- Order- en abonnementsbeheer.
Clienttoepassingen zoals web-apps, mobiele apps en zelfs servicetoepassingen gebruiken de API-platformservices via een geïntegreerd toegangspad, https://api.contoso.com.
Onderdelen
- Azure Front Door biedt een beveiligd, geïntegreerd toegangspunt voor alle aanvragen voor de oplossing. Zie overzicht van routeringsarchitectuur voor meer informatie.
- Azure API Management biedt een governancelaag boven op alle gepubliceerde API's. U kunt Azure API Management-beleid gebruiken om extra mogelijkheden toe te passen op de API-laag, zoals toegangsbeperkingen, caching en gegevenstransformatie. API Management biedt ondersteuning voor automatisch schalen in Standard- en Premium-lagen.
- Azure Kubernetes Service (AKS) is de Azure-implementatie van opensource Kubernetes-clusters. Als gehoste Kubernetes-service verwerkt Azure kritieke taken, zoals statuscontrole en onderhoud. Omdat Kubernetes-masters worden beheerd door Azure, beheert en onderhoudt u alleen de agentknooppunten. In deze architectuur worden alle microservices geïmplementeerd in AKS.
- Azure-toepassing Gateway is een toepassingsleveringscontrollerservice. Het werkt op laag 7, de toepassingslaag en heeft verschillende mogelijkheden voor taakverdeling. De Application Gateway Ingress Controller (AGIC) is een Kubernetes-toepassing waarmee AKS-klanten (Azure Kubernetes Service) de load balancer van Azure Application Gateway L7 kunnen gebruiken om cloudsoftware beschikbaar te maken op internet. Automatisch schalen en zoneredundantie worden ondersteund in de v2-SKU.
- Azure Storage, Azure Data Lake Storage, Azure Cosmos DB en Azure SQL kunnen zowel gestructureerde als niet-gestructureerde inhoud opslaan. Azure Cosmos DB-containers en -databases kunnen worden gemaakt met doorvoer voor automatische schaalaanpassing.
- Microsoft Dynamics 365 is een SaaS-aanbieding (Software as a Service) van Microsoft die verschillende zakelijke toepassingen biedt voor klantenservice, verkoop, marketing en financiën. In deze architectuur wordt Dynamics 365 voornamelijk gebruikt voor het beheren van productcatalogussen en voor klantenservicebeheer. Schaaleenheden bieden tolerantie voor Dynamics 365-toepassingen.
- Microsoft 365 (voorheen Office 365) wordt gebruikt als een bedrijfsinhoudsbeheersysteem dat is gebouwd op Microsoft 365 SharePoint in Microsoft 365. Het wordt gebruikt voor het maken, beheren en publiceren van inhoud, zoals mediaassets en documenten.
Alternatieven
Omdat deze oplossing gebruikmaakt van een zeer schaalbare architectuur op basis van microservices, moet u rekening houden met deze alternatieven voor het rekenvlak:
- Azure Functions voor serverloze API-services
- Microservices op basis van Azure Spring Apps voor Java
Juiste betrouwbaarheid
De mate van betrouwbaarheid die vereist is voor een oplossing, is afhankelijk van de bedrijfscontext. Een winkel die 14 uur open is en dat systeemgebruik binnen die periode piekt, heeft andere vereisten dan een online bedrijf dat bestellingen op alle uren accepteert. SRE-procedures kunnen worden afgestemd op het juiste niveau van betrouwbaarheid.
Betrouwbaarheid wordt gedefinieerd en gemeten met behulp van serviceniveaudoelstellingen (serviceniveaudoelstellingen (SLO's)) die het doelniveau van betrouwbaarheid voor een service definiëren. Het bereiken van het doelniveau zorgt ervoor dat consumenten tevreden zijn. De SLO-doelen kunnen zich ontwikkelen of veranderen, afhankelijk van de eisen van het bedrijf. De service-eigenaren moeten echter voortdurend de betrouwbaarheid meten tegen de SLO's om problemen te detecteren en corrigerende acties uit te voeren. SLO's worden meestal gedefinieerd als een percentageprestatie gedurende een periode.
Een andere belangrijke term die u moet noteren, is serviceniveauindicator (serviceniveauindicator (SLI)), de metrische waarde die wordt gebruikt om de SLO te berekenen. SLO's zijn gebaseerd op inzichten die zijn afgeleid van gegevens die worden vastgelegd wanneer de klant de service verbruikt. SLO's worden altijd gemeten vanuit het oogpunt van een klant.
SLO's en SLO's gaan altijd hand in hand en worden meestal op een iteratieve manier gedefinieerd. SLO's worden aangestuurd door belangrijke bedrijfsdoelstellingen, terwijl SLO's worden aangestuurd door wat er mogelijk is om te meten tijdens het implementeren van de service.
De relatie tussen de bewaakte metrische gegevens, de SLI en de SLO wordt hieronder weergegeven:
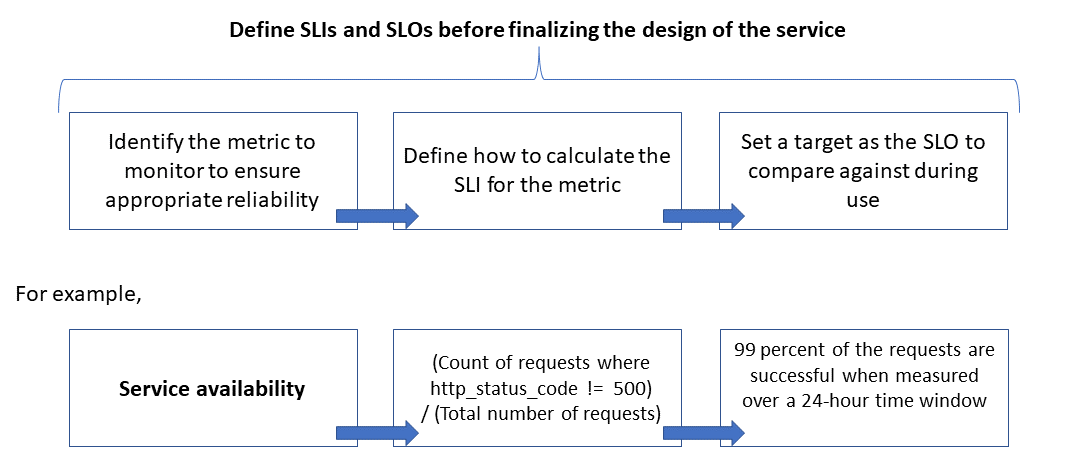
Dit wordt in meer detail uitgelegd in Metrische SLI-gegevens definiëren om SLO's te berekenen.
Modelleringsschaal- en prestatieverwachtingen
Voor een softwaresysteem verwijst de prestaties over het algemeen naar de algehele reactiesnelheid van een systeem bij het uitvoeren van een actie binnen een opgegeven tijd, terwijl schaalbaarheid de mogelijkheid van het systeem is om verhoogde gebruikersbelastingen af te handelen zonder de prestaties te kwetsen.
Een systeem wordt beschouwd als schaalbaar als de onderliggende resources dynamisch beschikbaar worden gesteld om een toename van de belasting te ondersteunen. Cloudtoepassingen moeten worden ontworpen voor schaal en het verkeersvolume is soms moeilijk te voorspellen. Seizoensgebonden pieken kunnen de schaalvereisten verhogen, met name wanneer een service aanvragen voor meerdere tenants verwerkt.
Het is een goede gewoonte om toepassingen te ontwerpen, zodat de cloudresources zo nodig automatisch omhoog en omlaag worden geschaald om te voldoen aan de belasting. In principe moet het systeem zich aanpassen aan de toename van de werkbelasting door resources op een incrementele manier in te richten of toe te wijzen om aan de vraag te voldoen. Schaalbaarheid heeft niet alleen betrekking op rekenprocessen, maar ook op andere elementen, zoals gegevensopslag en berichteninfrastructuur.
In dit artikel wordt beschreven hoe u de juiste betrouwbaarheid voor een cloudtoepassing kunt garanderen door schaal- en prestatiemodellering van de workloadscenario's uit te voeren en de resultaten te gebruiken om de monitors, de SLO's en de SLO's te definiëren.
Overwegingen
Raadpleeg de pijlers betrouwbaarheid en prestatie-efficiëntie van Azure Well Architected Framework voor hulp bij het bouwen van schaalbare en betrouwbare toepassingen.
In dit artikel wordt beschreven hoe u schaalbaarheids- en prestatiemodelleringstechnieken kunt toepassen om de oplossingsarchitectuur en het ontwerp nauwkeurig af te stemmen. Deze technieken identificeren wijzigingen in de transactiestromen voor een optimale gebruikerservaring. Baseer uw technische beslissingen over niet-functionele vereisten van de oplossing. Het proces is:
- Identificeer de schaalbaarheidsvereisten.
- Modelleer de verwachte belasting.
- Definieer de SLO's en SLO's voor de gebruikersscenario's.
Notitie
Azure-toepassing Insights, onderdeel van Azure Monitor, is een krachtig APM-hulpprogramma (Application Performance Management) dat u eenvoudig kunt integreren met uw toepassingen om telemetrie te verzenden en toepassingsspecifieke metrische gegevens te analyseren. Het biedt ook kant-en-klare dashboards en een metrische verkenner die u kunt gebruiken om de gegevens te analyseren om de bedrijfsbehoeften te verkennen.
Schaalbaarheidsvereisten vastleggen
Stel deze metrische piekbelastingsgegevens voor:
- Aantal consumenten dat het API-platform gebruikt: 1,5 miljoen
- Gebruikers per uur (30 procent van 1,5 miljoen): 450.000
- Percentage belasting voor elke activiteit:
- Product browsen: 75 procent
- Registratie inclusief het maken van profielen en aanmelden: 10 procent
- Beheer van orders en abonnementen: 10 procent
- Inhoudsweergave: 5 procent
De belasting produceert de volgende schaalvereisten, onder normale piekbelasting, voor de API's die worden gehost door het platform:
- Productmicroservice: ongeveer 500 aanvragen per seconde (RPS)
- Profielmicroservice: ongeveer 100 RPS
- Orders en betalingsmicroservice: ongeveer 100 RPS
- Inhoudsmicroservice: ongeveer 50 RPS
Deze schaalvereisten houden geen rekening met seizoensgebonden en willekeurige pieken en pieken tijdens speciale evenementen, zoals marketingpromoties. Tijdens pieken is de schaalvereiste voor sommige gebruikersactiviteiten maximaal 10 keer de normale piekbelasting. Houd rekening met deze beperkingen en verwachtingen wanneer u de ontwerpkeuzen voor de microservices maakt.
SLI-metrische gegevens definiëren om SLO's te berekenen
SLI-metrische gegevens geven de mate aan waarin een service een bevredigende ervaring biedt en kan worden uitgedrukt als de verhouding van goede gebeurtenissen tot het totale aantal gebeurtenissen.
Voor een API-service verwijzen gebeurtenissen naar de toepassingsspecifieke metrische gegevens die tijdens de uitvoering worden vastgelegd als telemetrie of verwerkte gegevens. In dit voorbeeld zijn de volgende SLI-metrische gegevens:
| Metrisch | Omschrijving |
|---|---|
| Beschikbaarheid | Of de aanvraag is verwerkt door de API |
| Latentie | Tijd voordat de API de aanvraag verwerkt en een antwoord retourneert |
| Doorvoer | Aantal aanvragen dat de API heeft verwerkt |
| Slagingspercentage | Aantal aanvragen dat de API heeft verwerkt |
| Foutpercentage | Aantal fouten voor de aanvragen die door de API zijn verwerkt |
| Nieuwheid | Aantal keren dat de gebruiker de meest recente gegevens heeft ontvangen voor leesbewerkingen op de API, ondanks dat het onderliggende gegevensarchief wordt bijgewerkt met een bepaalde schrijflatentie |
Notitie
Zorg ervoor dat u aanvullende SLA's identificeert die belangrijk zijn voor uw oplossing.
Hier volgen voorbeelden van SLO's:
- (Aantal aanvragen dat is voltooid in minder dan 1000 ms) / (aantal aanvragen)
- (Aantal zoekresultaten dat binnen drie seconden alle producten retourneert die zijn gepubliceerd in de catalogus) / (Aantal zoekopdrachten)
Nadat u de SLO's hebt gedefinieerd, bepaalt u welke gebeurtenissen of telemetriegegevens moeten worden vastgelegd om ze te meten. Als u bijvoorbeeld de beschikbaarheid wilt meten, legt u gebeurtenissen vast om aan te geven of de API-service een aanvraag heeft verwerkt. Voor HTTP-services wordt geslaagd of mislukt aangegeven met HTTP-statuscodes. Het API-ontwerp en de implementatie moeten de juiste codes opgeven. Over het algemeen zijn SLI-metrische gegevens een belangrijke invoer voor de API-implementatie.
Voor cloudsystemen kunt u enkele metrische gegevens verkrijgen met behulp van de diagnostische en bewakingsondersteuning die beschikbaar zijn voor de resources. Azure Monitor is een uitgebreide oplossing voor het verzamelen, analyseren en uitvoeren van telemetrie van uw cloudservices. Afhankelijk van uw SLI-vereisten kunnen er meer bewakingsgegevens worden vastgelegd om de metrische gegevens te berekenen.
Percentieldistributies gebruiken
Sommige SLO's worden berekend met behulp van een percentieldistributietechniek. Dit geeft betere resultaten als er uitbijters zijn die andere technieken, zoals gemiddelde of mediaandistributies, kunnen scheeftrekken.
Denk bijvoorbeeld aan de latentie van de API-aanvragen en drie seconden is de drempelwaarde voor optimale prestaties. De gesorteerde reactietijden voor een uur API-aanvragen laten zien dat slechts enkele aanvragen langer duren dan drie seconden en dat de meeste antwoorden binnen de drempelwaarde worden ontvangen. Dit is het verwachte gedrag van het systeem.
De percentielverdeling is bedoeld om uitbijters uit te sluiten die worden veroorzaakt door onregelmatige problemen. Als de juiste servicereacties zich bijvoorbeeld in het 90e of 95e percentiel bevinden, wordt de SLO als voldaan.
De juiste meetperioden kiezen
De meetperiode voor het definiëren van een SLO is erg belangrijk. Het moet activiteit vastleggen, niet-inactiviteit, zodat de resultaten zinvol zijn voor de gebruikerservaring. Dit venster kan vijf minuten tot 24 uur duren, afhankelijk van hoe u de SLI-meetwaarde wilt bewaken en berekenen.
Een prestatiebeheerproces tot stand brengen
De prestaties van een API moeten worden beheerd vanaf het begin totdat deze is afgeschaft of buiten gebruik gesteld. Er moet een robuust governanceproces worden uitgevoerd om ervoor te zorgen dat prestatieproblemen vroeg worden gedetecteerd en opgelost, voordat ze een grote storing veroorzaken die van invloed is op het bedrijf.
Dit zijn de elementen van prestatiebeheer:
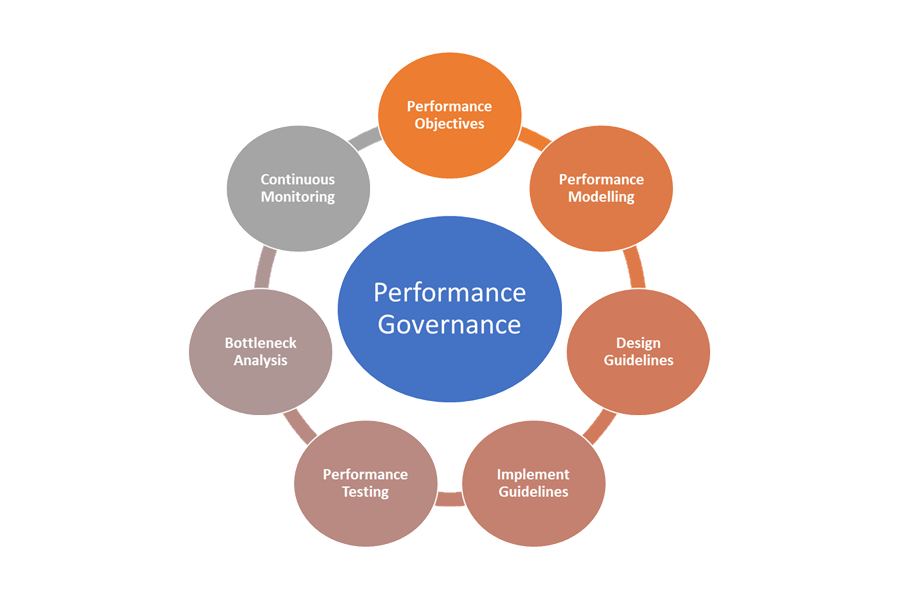
- Prestatiedoelstellingen: definieer de ambitieuze prestatie-SLO's voor de bedrijfsscenario's.
- Prestatiemodellering: identificeer bedrijfskritieke werkstromen en transacties en voer modellering uit om inzicht te krijgen in de gevolgen voor prestaties. Leg deze informatie op een gedetailleerd niveau vast voor nauwkeurigere voorspellingen.
- Ontwerprichtlijnen: ontwerprichtlijnen voor prestaties voorbereiden en passende wijzigingen in bedrijfswerkstromen aanbevelen. Zorg ervoor dat teams deze richtlijnen begrijpen.
- Richtlijnen implementeren: Richtlijnen voor het ontwerpen van prestaties implementeren voor de oplossingsonderdelen, inclusief instrumentatie voor het vastleggen van metrische gegevens. Voer prestatieontwerpbeoordelingen uit. Het is essentieel om al deze items bij te houden met behulp van backlogitems voor de architectuur voor de verschillende teams.
- Prestatietests: Voer belastings- en stresstests uit in overeenstemming met de verdeling van het belastingprofiel om de metrische gegevens vast te leggen die betrekking hebben op de platformstatus. U kunt deze tests ook uitvoeren voor een beperkte belasting om de vereisten voor de oplossingsinfrastructuur te benchmarken.
- Knelpuntanalyse: Gebruik codeinspectie en codebeoordelingen om prestatieknelpunten op verschillende onderdelen te identificeren, analyseren en verwijderen. Identificeer horizontale of verticale schaalverbeteringen die nodig zijn om de piekbelastingen te ondersteunen.
- Continue bewaking: maak een continue bewakings- en waarschuwingsinfrastructuur als onderdeel van de DevOps-processen. Zorg ervoor dat de betrokken teams op de hoogte worden gesteld wanneer de reactietijden aanzienlijk afnemen ten opzichte van benchmarks.
- Prestatiebeheer: een prestatiegovernance opzetten die bestaat uit goed gedefinieerde processen en teams om de prestatie-SLO's te ondersteunen. Houd de naleving na elke release bij om verslechtering te voorkomen vanwege build-upgrades. Voer regelmatig beoordelingen uit om te beoordelen op een verhoogde belasting om oplossingsupgrades te identificeren.
Herhaal de stappen in de loop van de ontwikkeling van uw oplossing als onderdeel van het progressieve ontwikkelingsproces.
Prestatiedoelstellingen en verwachtingen bijhouden in uw achterstand
Houd uw prestatiedoelstellingen bij om ervoor te zorgen dat ze worden bereikt. Leg gedetailleerde en gedetailleerde gebruikersverhalen vast die u wilt bijhouden. Dit helpt ervoor te zorgen dat ontwikkelteams prestatiebeheeractiviteiten een hoge prioriteit hebben.
Aspiratie-SLO's instellen voor de doeloplossing
Hier volgen voorbeelden van aspiratie-SLO's voor de API-platformoplossing die wordt overwogen:
- Reageert binnen één seconde op 95 procent van alle READ-aanvragen.
- Reageert binnen drie seconden op 95 procent van alle CREATE- en UPDATE-aanvragen.
- Reageert binnen vijf seconden op 99 procent van alle aanvragen zonder fouten.
- Reageert binnen vijf minuten op 99,9 procent van alle aanvragen.
- Minder dan één procent van de aanvragen tijdens de piekvensterfout van één uur.
De SLO's kunnen worden afgestemd op specifieke toepassingsvereisten. Het is echter essentieel om voldoende gedetailleerd te zijn om de duidelijkheid te hebben om de betrouwbaarheid te waarborgen.
Initiële SLO's meten die zijn gebaseerd op gegevens uit de logboeken
Bewakingslogboeken worden automatisch gemaakt wanneer de API-service wordt gebruikt. Stel dat een week aan gegevens het volgende weergeeft:
- Aanvragen: 123.456
- Geslaagde aanvragen: 123.204
- 90e percentiellatentie: 497 ms
- 95e percentiellatentie: 870 ms
- 99e percentiellatentie: 1024 ms
Deze gegevens produceren de volgende eerste SLA's:
- Beschikbaarheid = (123.204 / 123.456) = 99,8 procent
- Latentie = ten minste 90 procent van de aanvragen is binnen 500 ms verwerkt
- Latentie = ongeveer 98 procent van de aanvragen is binnen 1000 ms verwerkt
Stel dat tijdens de planning het SLO-doel voor aspiratielatentie 90 procent van de aanvragen binnen 500 ms wordt verwerkt met een slagingspercentage van 99 procent gedurende een periode van één week. Met de logboekgegevens kunt u eenvoudig vaststellen of aan het SLO-doel is voldaan. Als u dit type analyse enkele weken uitvoert, kunt u beginnen met het bekijken van de trends rond SLO-naleving.
Richtlijnen voor technische risicobeperking
Gebruik de volgende controlelijst met aanbevolen procedures om schaalbaarheids- en prestatierisico's te beperken:
- Ontwerp voor schaal en prestaties.
- Zorg ervoor dat u schaalvereisten vastlegt voor elk gebruikersscenario en elke workload, inclusief seizoensgebondenheid en pieken.
- Prestatiemodellering uitvoeren om systeembeperkingen en knelpunten te identificeren
- Technische schulden beheren.
- Uitgebreide tracering van metrische prestatiegegevens uitvoeren.
- U kunt scripts gebruiken om hulpprogramma's zoals K6.io, Karate en JMeter uit te voeren in uw ontwikkelfaseomgeving met een reeks gebruikersbelastingen, bijvoorbeeld 50 tot 100 RPS. Hiermee vindt u informatie in de logboeken voor het detecteren van ontwerp- en implementatieproblemen.
- Integreer de geautomatiseerde testscripts als onderdeel van uw processen voor continue implementatie (CD) om build-einden te detecteren.
- Denk aan productie.
- Pas de drempelwaarden voor automatisch schalen aan zoals aangegeven door de statusstatistieken.
- Geef de voorkeur aan horizontale schaaltechnieken boven verticaal.
- Wees proactief met schalen om seizoensgebondenheid af te handelen.
- Liever implementatie op basis van ring.
- Gebruik foutbudgetten om te experimenteren.
Prijzen
Betrouwbaarheid, prestatie-efficiëntie en kostenoptimalisatie gaan hand in hand. De Azure-services die in de architectuur worden gebruikt, helpen de kosten te verlagen, omdat ze automatisch worden geschaald om te voldoen aan veranderende gebruikersbelastingen.
Voor AKS kunt u in eerste instantie beginnen met vm's met standaardformaat voor de knooppuntgroep. U kunt vervolgens resourcevereisten bewaken tijdens het ontwikkelen of productiegebruik en dienovereenkomstig aanpassen.
Kostenoptimalisatie is een pijler van het Microsoft Azure Well-Architected Framework. Zie Overzicht van de pijler kostenoptimalisatie voor meer informatie. Gebruik de prijscalculator om de kosten van Azure-producten en -configuraties te schatten.
Medewerkers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Hoofdauteur:
- Subhajit Chatterjee | Hoofd Software Engineer
Volgende stappen
- Azure-documentatie
- Microsoft Azure Well-Architected Framework
- Architectuurstijl voor microservices
- Ontwerp om uit te schalen
- Een Azure Compute-service voor uw toepassing kiezen
- Microservicesarchitectuur in Azure Kubernetes Service
- Wat is Azure Front Door?
- Meer informatie over API Management
- Wat is de controller voor inkomend verkeer van Application Gateway?
- Azure Kubernetes Service
- Automatisch schalen en zone-redundantie in Application Gateway v2
- Een cluster automatisch schalen om te voldoen aan de toepassingsvraag op Azure Kubernetes Service (AKS)
- Azure Cosmos DB-containers en -databases maken met doorvoer automatisch schalen
- Microsoft Dynamics 365-documentatie
- Microsoft 365-documentatie
- Documentatie voor sitebetrouwbaarheidstechniek
- AZ-400: Een SRE-strategie (Site Reliability Engineering) ontwikkelen
- Basislijnwebtoepassing met zoneredundantie