Consolideer meerdere taken of bewerkingen in een enkele rekenkundige eenheid. Dit kan het gebruik van berekenbronnen verhogen en de kosten en beheeroverhead verminderen die zijn gekoppeld aan het uitvoeren van berekenverwerkingen in cloudtoepassingen.
Context en probleem
Een cloudtoepassing implementeert vaak tal van bewerkingen. In sommige oplossingen is het zinvol om het ontwerpprincipe van de scheiding van problemen in eerste instantie te volgen en deze bewerkingen te verdelen in afzonderlijke rekeneenheden die afzonderlijk worden gehost en geïmplementeerd (bijvoorbeeld als afzonderlijke App Service-web-apps of afzonderlijke virtuele machines). Hoewel deze strategie het logische ontwerp van de oplossing vereenvoudigt, kan de implementatie van een groot aantal rekenkundige eenheden als onderdeel van dezelfde toepassing echter runtime-hostingkosten verhogen en het beheer van het systeem complexer maken.
De afbeelding toont een voorbeeld van een vereenvoudigde structuur van een cloudoplossing die wordt geïmplementeerd met meer dan één rekenkundige eenheid. Elke rekenkundige eenheid wordt uitgevoerd in een eigen virtuele omgeving. Elke functie is als een afzonderlijke taak geïmplementeerd (met de naam Taak A tot en met Taak E) die wordt uitgevoerd in een eigen rekenkundige eenheid.
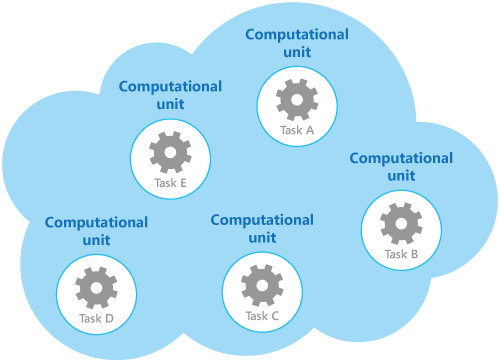
Elke rekenkundige eenheid verbruikt toerekenbare resources, zelfs wanneer deze niet-actief is of weinig wordt gebruikt. Daarom is dit niet altijd de meest rendabele oplossing.
In Azure is dit probleem van toepassing op App Services, Container Apps en Virtuele machines. Deze items worden uitgevoerd in hun eigen omgeving. Het uitvoeren van een verzameling afzonderlijke websites, microservices of virtuele machines die zijn ontworpen om een set goed gedefinieerde bewerkingen uit te voeren, maar die moeten communiceren en samenwerken als onderdeel van één oplossing, kan een inefficiënt gebruik van resources zijn.
Oplossing
Het is mogelijk om meerdere taken of bewerkingen in een enkele rekenkundige eenheid te consolideren om de kosten te verlagen, gebruik te vergroten, communicatiesnelheid te verbeteren en beheer te beperken.
Taken kunnen worden gegroepeerd volgens de criteria op basis van de functies die door de omgeving zijn opgegeven en de kosten die zijn gekoppeld aan deze functies. Een veelgebruikte aanpak is om te zoeken naar taken die een vergelijkbaar profiel hebben met betrekking tot hun schaalbaarheid, levensduur en verwerkingsvereisten. Als u deze groepeert, kunnen ze als een eenheid worden geschaald. Door de flexibiliteit van veel cloudomgevingen kunnen extra exemplaren van een rekenkundige eenheid worden gestart en gestopt volgens de werkbelasting. Azure biedt bijvoorbeeld automatische schaalaanpassing die u kunt toepassen op App Services en Virtuele-machineschaalsets. Zie voor meer informatie Richtlijnen voor automatisch schalen.
Schaalbaarheid kan echter ook worden gebruikt om te bepalen welke bewerkingen niet moeten worden gegroepeerd. Neem bijvoorbeeld de volgende twee taken:
- Taak 1 peilt incidentele, tijdongevoelige berichten die naar een wachtrij worden verzonden.
- Taak 2 verwerkt hoge pieken in netwerkverkeer.
De tweede taak vereist flexibiliteit waarbij gebruik kan worden gemaakt van het starten en stoppen van een groot aantal exemplaren van de rekenkundige eenheid. Het toepassen van dezelfde schaal op de eerste taak zal simpelweg resulteren in meer taken die luisteren naar incidentele berichten in dezelfde wachtrij. Dit is een verspilling van resources.
In veel cloudomgevingen is het mogelijk om de resources op te geven die voor een rekenkundige eenheid beschikbaar zijn met betrekking tot het aantal CPU-kernen, het geheugen, de schijfruimte enzovoort. In het algemeen geldt hoe meer resources er zijn opgegeven, hoe hoger de kosten zijn. Als u geld wilt besparen, is het belangrijk om het werk dat een dure rekenkundige eenheid uitvoert te maximaliseren en deze niet voor een langere periode inactief te laten zijn.
Als er taken zijn die veel CPU-energie in korte pieken nodig hebben, overweeg deze dan in één rekenkundige eenheid te consolideren die de benodigde energie levert. Het is echter belangrijk dat u deze behoefte om dure resources bezig te houden en conflicten die kunnen optreden als deze overbelast raken in evenwicht houdt. Langlopende, rekenintensieve taken mogen bijvoorbeeld niet dezelfde rekenkundige eenheid delen.
Problemen en overwegingen
Houd rekening met de volgende punten bij het implementeren van dit patroon:
Schaalbaarheid en flexibiliteit. Veel cloudoplossingen implementeren schaalbaarheid en flexibiliteit op het niveau van de rekenkundige eenheid door exemplaren van eenheden te starten en te stoppen. Voorkom dat u taken die conflicterende schaalbaarheidsvereisten hebben in dezelfde rekenkundige eenheid groepeert.
Levensduur. De cloudinfrastructuur recyclet periodiek de virtuele omgeving die als host fungeert voor een rekenkundige eenheid. Wanneer er veel langlopende taken binnen een rekenkundige eenheid worden uitgevoerd, kan het noodzakelijk zijn om de eenheid te configureren om te voorkomen dat deze wordt gerecycled totdat deze taken zijn voltooid. U kunt de taken ook ontwerpen met behulp van een benadering waarbij op punten wordt gecontroleerd, waardoor ze foutloos stoppen en verdergaan vanaf het punt waarop ze zijn onderbroken wanneer de rekenkundige eenheid opnieuw wordt gestart.
Vrijgeeffrequentie. Als de implementatie of configuratie van een taak regelmatig wijzigt, kan het nodig zijn om de rekenkundige eenheid die als host fungeert voor de bijgewerkte code te stoppen, opnieuw te configureren en de eenheid opnieuw te implementeren en vervolgens opnieuw te starten. Dit proces vereist ook dat alle andere taken binnen dezelfde rekenkundige eenheid worden gestopt, opnieuw worden geïmplementeerd en opnieuw worden gestart.
Beveiliging. Taken in dezelfde rekenkundige eenheid delen mogelijk dezelfde beveiligingscontext en hebben toegang tot dezelfde resources. Er moet een hoge mate van vertrouwen zijn tussen de taken en vertrouwen dat één taak niet wordt beschadigd of een negatieve invloed op een andere taak heeft. Daarnaast vergroot een toename van het aantal taken die in een rekenkundige eenheid worden uitgevoerd de kwetsbaarheid voor aanvallen van de eenheid. Elke taak is net zo veilig als de taak met de meeste beveiligingsproblemen.
Fouttolerantie. Als één taak in een rekenkundige eenheid mislukt of zich abnormaal gedraagt, kan deze invloed hebben op de andere taken die binnen dezelfde eenheid worden uitgevoerd. Als één taak bijvoorbeeld niet correct wordt gestart, kan dit ertoe leiden dat de hele opstartlogica voor de rekenkundige eenheid mislukt en voorkomt dat andere taken in dezelfde eenheid worden uitgevoerd.
Conflicten. Vermijd conflicten tussen taken die concurreren voor resources in dezelfde rekenkundige eenheid. Taken die dezelfde rekenkundige eenheid delen, moeten in het ideale geval andere kenmerken van resourcegebruik vertonen. Twee rekenintensieve taken moeten zich bijvoorbeeld niet in dezelfde rekenkundige eenheid bevinden. Hetzelfde geldt voor twee taken die grote hoeveelheden geheugen gebruiken. Het combineren van een rekenintensieve taak met een taak waarvoor een grote hoeveelheid geheugen is vereist, is echter een werkbare combinatie.
Notitie
Overweeg alleen rekenresources te consolideren voor een systeem dat gedurende een bepaalde periode in productie is, zodat operators en ontwikkelaars het systeem kunnen bewaken en een heatmap kunnen maken die aangeeft hoe elke taak verschillende resources gebruikt. Deze heatmap kan worden gebruikt om te bepalen welke taken goede kandidaten zijn voor het delen van rekenresources.
Complexiteit. De combinatie van meerdere taken in één rekenkundige eenheid voegt complexiteit toe aan de code in de eenheid. Hierdoor wordt het mogelijk moeilijker om te testen, fouten op te sporen en te onderhouden.
Stabiele logische architectuur. Ontwerp en implementeer de code in elke taak, zodat deze niet hoeft te wijzigen, zelfs wanneer de fysieke omgeving waarin de taak wordt uitgevoerd, wijzigt.
Andere strategieën. Het consolideren van rekenresources is slechts één manier om de kosten met betrekking tot meerdere taken die gelijktijdig worden uitgevoerd te verlagen. Dit vereist een zorgvuldige planning en bewaking om ervoor te zorgen dat dit een effectieve aanpak blijft. Andere strategieën zijn mogelijk meer geschikt. Dit is afhankelijk van de aard van het werk en waar de gebruikers die deze taken uitvoeren zich bevinden. De functionele ontleding van de werkbelasting (zoals is beschreven in de Compute Partitioning Guidance (Richtlijnen voor berekenpartitionering)) bijvoorbeeld is misschien een betere optie.
Wanneer dit patroon gebruiken
Gebruik dit patroon voor taken die niet rendabel zijn als ze worden uitgevoerd in hun eigen rekenkundige eenheden. Als een taak vaak niet-actief is, kan het uitvoeren van deze taak in een toegewezen eenheid kostbaar zijn.
Dit patroon is mogelijk niet geschikt voor taken die kritieke fouttolerante bewerkingen uitvoeren of taken die uiterst gevoelige of persoonlijke gegevens verwerken en hun eigen beveiligingscontext vereisen. Deze taken moeten in hun eigen geïsoleerde omgeving worden uitgevoerd in een afzonderlijke rekenkundige eenheid.
Workloadontwerp
Een architect moet evalueren hoe het patroon Consolidatie van rekenresources kan worden gebruikt in het ontwerp van hun workload om de doelstellingen en principes te verhelpen die worden behandeld in de pijlers van het Azure Well-Architected Framework. Voorbeeld:
| Pijler | Hoe dit patroon ondersteuning biedt voor pijlerdoelen |
|---|---|
| Kostenoptimalisatie is gericht op het ondersteunen en verbeteren van het rendement van uw workload op investering. | Dit patroon maximaliseert het gebruik van computerresources door ongebruikte ingerichte capaciteit te voorkomen via aggregatie van onderdelen of zelfs hele workloads in een poolinfrastructuur. - CO:14 Samenvoeging |
| Operational Excellence helpt bij het leveren van workloadkwaliteit via gestandaardiseerde processen en teamcohesie. | Consolidatie kan leiden tot een meer homogeen rekenplatform, dat het beheer en de waarneembaarheid kan vereenvoudigen, verschillende benaderingen voor operationele taken kan verminderen en de benodigde hoeveelheid hulpprogramma's kan verminderen. - OE:07 Bewakingssysteem - OE:10 Automation-ontwerp |
| Prestatie-efficiëntie helpt uw workload efficiënt te voldoen aan de vereisten door optimalisaties in schalen, gegevens, code. | Consolidatie maximaliseert het gebruik van rekenresources met behulp van reserveknooppuntcapaciteit en vermindert de behoefte aan overprovisioning. Grote (verticaal geschaalde) rekeninstanties worden vaak gebruikt in de resourcegroep voor deze infrastructuren. - PE:02 Capaciteitsplanning - PE:03 Services selecteren |
Net als bij elke ontwerpbeslissing moet u rekening houden met eventuele compromissen ten opzichte van de doelstellingen van de andere pijlers die met dit patroon kunnen worden geïntroduceerd.
Keuzen voor toepassingsplatform
Dit patroon kan op verschillende manieren worden bereikt, afhankelijk van de rekenservice die u gebruikt. Zie de volgende voorbeeldservices:
- Azure-app Service en Azure Functions: Implementeer gedeelde App Service-plannen, die de hostingserverinfrastructuur vertegenwoordigen. Een of meer apps kunnen worden geconfigureerd om te worden uitgevoerd op dezelfde rekenresources (of in hetzelfde App Service-plan).
- Azure Container Apps: Container-apps implementeren in dezelfde gedeelde omgevingen, met name in situaties waarin u gerelateerde services moet beheren of als u verschillende toepassingen in hetzelfde virtuele netwerk moet implementeren.
- Azure Kubernetes Service (AKS):AKS is een hostinfrastructuur op basis van containers waarin meerdere toepassingen of toepassingsonderdelen kunnen worden geconfigureerd voor co-uitvoering op dezelfde rekenresources (knooppunten), gegroepeerd op rekenvereisten zoals CPU- of geheugenbehoeften (knooppuntgroepen).
- Virtuele machines: Implementeer één set virtuele machines voor alle tenants die moeten worden gebruikt, op die manier worden de beheerkosten gedeeld tussen de tenants. Virtuele-machineschaalsets is een functie die ondersteuning biedt voor gedeeld resourcebeheer, taakverdeling en horizontaal schalen van virtuele machines.
Verwante resources
De volgende patronen en richtlijnen zijn mogelijk ook relevant bij de implementatie van dit patroon:
Richtlijnen voor automatisch schalen. Automatisch schalen kan worden gebruikt om exemplaren van service gehoste rekenkundige resources te starten en stoppen, afhankelijk van de verwachte vraag voor verwerking.
Compute Partitioning Guidance (Richtlijnen voor berekenpartitionering). Hierin wordt beschreven hoe u de services en onderdelen in een cloudservice kunt toewijzen op een manier die doorlopende kosten minimaliseert en tegelijkertijd de schaalbaarheid, prestaties, beschikbaarheid en beveiliging van de service behoudt.
Architectuurbenaderingen voor compute in multitenant-oplossingen. Biedt richtlijnen over de overwegingen en vereisten die essentieel zijn voor oplossingsarchitecten wanneer ze de rekenservices van een multitenant-oplossing plannen.