In plaats van alleen de huidige status van de gegevens in een domein op te slaan, gebruikt u een archief waaraan alleen gegevens kunnen worden toegevoegd, om de volledige reeks acties te registreren die op die gegevens wordt uitgevoerd. Het archief dient als het systeem van records en kan worden gebruikt voor het realiseren van de domeinobjecten. Hiermee kunnen taken in complexe domeinen worden vereenvoudigd door het synchroniseren van het gegevensmodel en het bedrijfsdomein te omzeilen, terwijl de prestaties, de schaalbaarheid en de reactietijd worden verbeterd. Het kan ook consistentie voor transactiegegevens bieden en volledige audittrails en -geschiedenis handhaven die compenserende maatregelen mogelijk maken.
Context en probleem
De meeste toepassingen werken met gegevens en gewoonlijk wordt de huidige status van de gegevens onderhouden door deze bij te werken terwijl ermee wordt gewerkt. In het traditionele CRUD-model (create, read, update en delete) wordt een typisch gegevensproces bijvoorbeeld gebruikt om gegevens uit het archief te lezen, er enkele wijzigingen in aan te brengen en de huidige status van de gegevens bij te werken met de nieuwe waarden, vaak door transacties te gebruiken die de gegevens vergrendelen.
De benadering met CRUD kent enkele beperkingen:
CRUD-systemen voeren updatebewerkingen rechtstreeks uit op een gegevensarchief. Deze bewerkingen kunnen de prestaties en reactiesnelheid vertragen en de schaalbaarheid beperken, vanwege de verwerkingsoverhead die nodig is.
In een samenwerkingsdomein met talloze gelijktijdig werkende gebruikers, is de kans op conflicten bij het bijwerken van gegevens groter, omdat de bijwerkbewerkingen op één gegevensitem worden uitgevoerd.
Tenzij er een ander controlemechanisme is waarmee de details van elke bewerking in een afzonderlijk logboek worden vastgelegd, gaat de geschiedenis verloren.
Oplossing
Het gebeurtenisbronnenpatroon definieert een benadering voor het afhandelen van bewerkingen op gegevens die op een reeks gebeurtenissen is gebaseerd. Elke gebeurtenis wordt vastgelegd in een archief waaraan alleen gegevens kunnen worden toegevoegd. Door de toepassingscode wordt een reeks gebeurtenissen verzonden waarmee elke actie die op de gegevens in het gebeurtenisarchief is uitgevoerd (en waar ze definitief worden bewaard), dwingend worden beschreven. Elke gebeurtenis stelt een reeks gegevenswijzigingen voor (zoals AddedItemToOrder).
De gebeurtenissen worden definitief in een gebeurtenisarchief opgeslagen. Dit fungeert als het recordsysteem (de gezaghebbende gegevensbron) voor de huidige status van de gegevens. Normaal gesproken worden deze gebeurtenissen gepubliceerd, zodat gebruikers op de hoogte kunnen worden gesteld en de gebeurtenissen zo nodig kunnen verwerken. Een gebruiker kan bijvoorbeeld taken initiëren die de bewerkingen in de gebeurtenissen toepassen op andere systemen, of een andere eraan gekoppelde actie uitvoeren die is vereist om de bewerking te voltooien. De toepassingscode waarmee de gebeurtenissen worden gegenereerd, wordt losgekoppeld van de systemen die zich op de gebeurtenissen abonneren.
De door het gebeurtenisarchief gepubliceerde gebeurtenissen worden gewoonlijk gebruikt voor het onderhouden van gerealiseerde weergaven van entiteiten als ze door acties in de toepassing worden gewijzigd, en voor integratie met externe systemen. Een systeem kan bijvoorbeeld een gerealiseerde weergave van alle klantorders onderhouden, die wordt gebruikt om delen van de gebruikersinterface te vullen. De toepassing voegt nieuwe orders toe, voegt items aan de order toe of verwijdert deze en voegt verzendgegevens toe. De gebeurtenissen die deze wijzigingen beschrijven, kunnen worden verwerkt en gebruikt om de gerealiseerde weergave bij te werken.
Op elk moment is het mogelijk voor toepassingen om de geschiedenis van gebeurtenissen te lezen. U kunt deze vervolgens gebruiken om de huidige status van een entiteit te materialiseren door alle gebeurtenissen af te spelen en te gebruiken die betrekking hebben op die entiteit. Dit proces kan op aanvraag plaatsvinden om een domeinobject te materialiseren bij het verwerken van een aanvraag. Of het proces vindt plaats via een geplande taak, zodat de status van de entiteit kan worden opgeslagen als gerealiseerde weergave, ter ondersteuning van de presentatielaag.
De afbeelding toont een overzicht van het patroon, waaronder enkele opties voor het gebruik van de gebeurtenisstroom, zoals het maken van een gerealiseerde weergave, het integreren van gebeurtenissen met externe toepassingen en systemen, en het opnieuw afspelen van gebeurtenissen om projecties te maken van de huidige status van bepaalde entiteiten.
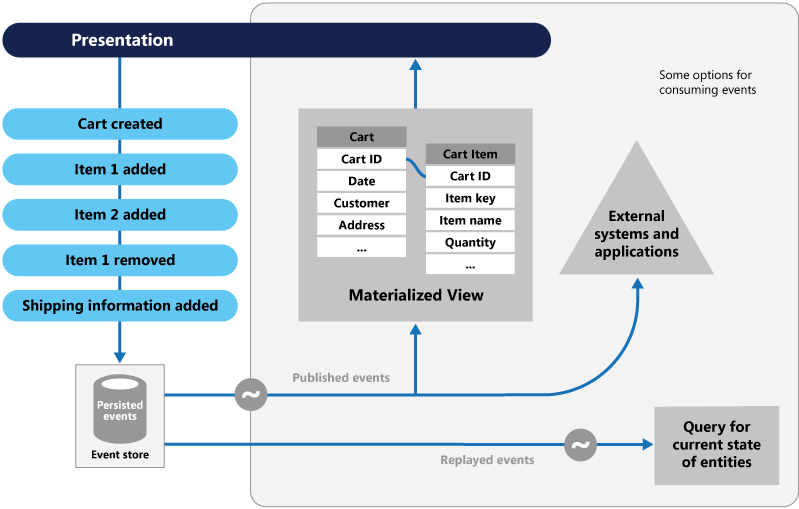
Het gebeurtenisbronnenpatroon biedt de volgende voordelen:
Gebeurtenissen zijn onveranderlijk en kunnen worden opgeslagen met een bewerking waarbij alleen gegevens kunnen worden toegevoegd. De gebruikersinterface, de werkstroom of het proces dat een gebeurtenis heeft geïnitieerd, kan door blijven gaan, en taken die de gebeurtenissen verwerken kunnen op de achtergrond worden uitgevoerd. Dit proces, gecombineerd met het feit dat er geen conflicten zijn tijdens de verwerking van transacties, kan de prestaties en schaalbaarheid voor toepassingen aanzienlijk verbeteren, met name voor het presentatieniveau of de gebruikersinterface.
Gebeurtenissen zijn eenvoudige objecten die een bepaalde actie beschrijven die is opgetreden, samen met eventuele gekoppelde gegevens die nodig zijn om de actie te beschrijven die wordt vertegenwoordigd door de gebeurtenis. Gebeurtenissen werken een gegevensarchief niet rechtstreeks bij. Ze worden op het juiste moment slechts geregistreerd voor verwerking. Het gebruik van gebeurtenissen kan de implementatie en het beheer vereenvoudigen.
Gebeurtenissen hebben doorgaan betekenis voor een domeinexpert, terwijl vanwege objectrelationele onverenigbaarheid complexe databasetabellen soms lastig te begrijpen zijn. Tabellen zijn kunstmatige constructies die de huidige status van het systeem vertegenwoordigen, niet de gebeurtenissen die hebben plaatsgevonden.
Met gebeurtenisbronnen kan worden voorkomen dat gelijktijdige updates conflicten veroorzaken, omdat de vereiste voor het rechtstreeks bijwerken van objecten in het gegevensarchief wordt vermeden. Het domeinmodel moet echter nog steeds zodanig worden ontworpen dat aanvragen die tot een inconsistente status kunnen leiden, worden voorkomen.
De opslag van alleen toevoeggebeurtenissen biedt een audittrail die kan worden gebruikt om acties te bewaken die zijn uitgevoerd op een gegevensarchief. De huidige status kan opnieuw worden gegenereerd als gerealiseerde weergaven of projecties door de gebeurtenissen op elk gewenst moment opnieuw af te spelen en kan helpen bij het testen en opsporen van fouten in het systeem. Bovendien kan de vereiste om compenserende gebeurtenissen te gebruiken om wijzigingen te annuleren een geschiedenis bieden van wijzigingen die zijn omgekeerd. Deze mogelijkheid zou niet het geval zijn als het model de huidige status heeft opgeslagen. De lijst met gebeurtenissen kan ook worden gebruikt om de prestaties van toepassingen te analyseren en trends in gebruikersgedrag te detecteren. Of kan worden gebruikt om andere nuttige bedrijfsgegevens te verkrijgen.
Het gebeurtenissenarchief activeert gebeurtenissen en taken voeren bewerkingen uit als reactie op die gebeurtenissen. Deze ontkoppeling van de taken van de gebeurtenissen biedt flexibiliteit en uitbreidbaarheid. De taken kennen het type en de datum van de gebeurtenis, maar niet de bewerking die de gebeurtenis heeft geactiveerd. Bovendien kan elke gebeurtenis door meerdere taken worden verwerkt. Hierdoor is eenvoudige integratie mogelijk met andere services en systemen die alleen letten op nieuwe gebeurtenissen die door het gebeurtenissenarchief worden geactiveerd. De gebeurtenissen met betrekking tot gebeurtenisbronnen zijn meestal van een erg laag niveau. Het kan daarom noodzakelijk zijn in plaats daarvan specifieke integratiegebeurtenissen te genereren.
Gebeurtenisbronnen worden gewoonlijk gecombineerd met het CQRS-patroon door gegevensbeheertaken uit te voeren als reactie op de gebeurtenissen, en door weergaven vanuit de opgeslagen gebeurtenissen te realiseren.
Problemen en overwegingen
Beschouw de volgende punten als u besluit hoe u dit patroon wilt implementeren:
Het systeem is uiteindelijk pas consistent als er gerealiseerde weergaven worden gemaakt of projecties van gegevens gegenereerd door gebeurtenissen opnieuw af te spelen. Er is enige vertraging tussen een toepassing die gebeurtenissen toevoegt aan het gebeurtenisarchief als gevolg van het verwerken van een aanvraag, de gepubliceerde gebeurtenissen en de consumenten van de gebeurtenissen die deze verwerken. Tijdens deze periode kunnen gebeurtenissen waarin verdere wijzigingen aan entiteiten worden beschreven, in het gebeurtenissenarchief zijn binnengekomen. Het systeem moet worden ontworpen om rekening te houden met uiteindelijke consistentie in deze scenario's.
Notitie
Zie Data Consistency Primer (Inleiding tot gegevensconsistentie) voor informatie over uiteindelijke consistentie.
Het gebeurtenissenarchief is de permanente informatiebron. De gebeurtenisgegevens mogen dan ook nooit worden bijgewerkt. De enige manier om een entiteit bij te werken om een wijziging ongedaan te maken, is door een compenserende gebeurtenis aan het gebeurtenissenarchief toe te voegen. Als de indeling (niet de gegevens) van de persistente gebeurtenissen moeten worden gewijzigd (bijvoorbeeld tijdens een migratie), kan het lastig zijn bestaande gebeurtenissen in het archief te combineren met de nieuwe versie. Mogelijk dienen alle gebeurtenissen die wijzigingen aanbrengen, doorlopen te worden, zodat ze aan de nieuwe indeling voldoen. Of er dienen nieuwe gebeurtenissen te worden toegevoegd die de nieuwe indeling gebruiken. U kunt bijvoorbeeld een versiestempel gebruiken op elke versie van het gebeurtenissenschema, zodat zowel de oude als de nieuwe indeling behouden blijft.
Mogelijk kunnen zowel toepassingen met meerdere threads als meerdere exemplaren van toepassingen gebeurtenissen in het gebeurtenissenarchief opslaan. De consistentie van gebeurtenissen in het gebeurtenissenarchief is van vitaal belang, evenals de volgorde van gebeurtenissen die van invloed is op een bepaalde entiteit (de volgorde waarin wijzigingen aan een entiteit optreden, beïnvloedt de huidige status ervan). Door een tijdstempel aan elke gebeurtenis toe te voegen kunnen problemen worden voorkomen. Een andere veelgebruikte methode bestaat uit het toevoegen van aantekeningen aan elke gebeurtenis die het gevolg zijn van een aanvraag met een incrementele id. Als twee acties tegelijkertijd gebeurtenissen voor dezelfde entiteit willen toevoegen, kan het gebeurtenissenarchief een gebeurtenis weigeren die overeenkomt met een bestaande entiteit-id en gebeurtenis-id.
Er bestaan geen standaardmethoden of al aanwezige mechanismen (zoals SQL-query's) om gebeurtenissen te lezen om informatie te verkrijgen. De enige gegevens die kunnen worden geëxtraheerd zijn een stroom gebeurtenissen die een gebeurtenis-id als criteria gebruiken. De gebeurtenis-id is doorgaans toegewezen aan afzonderlijke entiteiten. De huidige status van een entiteit kan alleen worden bepaald door alle gebeurtenissen die er betrekking op hebben, opnieuw af te spelen tegen de oorspronkelijke status van die entiteit.
De lengte van elke gebeurtenisstroom is van invloed op het beheren en bijwerken van het systeem. Als de stromen groot zijn, kunt u op bepaalde tijdstippen momentopnamen maken, bijvoorbeeld van een bepaald aantal gebeurtenissen. De huidige status van de entiteit kan uit de momentopname worden verkregen en door alle gebeurtenissen die na dat tijdstip zijn opgetreden, opnieuw af te spelen. Zie De replicatie van primaire onderliggende momentopnamen voor meer informatie over het maken van momentopnamen van gegevens.
Hoewel met gebeurtenisbronnen de kans op conflicterende updates van gegevens wordt geminimaliseerd, moet de toepassing nog steeds in staat zijn inconsistenties af te kunnen handelen die het gevolg zijn van uiteindelijke inconsistentie en het gebrek aan transacties. Een gebeurtenis die aangeeft dat een voorraadvermindering in de voorraad kan binnenkomen in het gegevensarchief terwijl een bestelling voor dat item wordt geplaatst. Deze situatie resulteert in een vereiste om de twee bewerkingen af te stemmen, hetzij door de klant te adviseren of door een terugbestelling te maken.
De publicatie van gebeurtenissen kan ten minste één keer zijn en dus moeten gebruikers van de gebeurtenissen idempotent zijn. Zij moeten de update die in een gebeurtenis staat beschreven, niet opnieuw toepassen als de gebeurtenis vaker wordt verwerkt. Meerdere exemplaren van een consument kunnen de eigenschap van een entiteit onderhouden en aggregeren, zoals het totale aantal geplaatste orders. Er moet slechts één slagen in het verhogen van de aggregaties, wanneer er een order geplaatste gebeurtenis plaatsvindt. Hoewel dit resultaat geen belangrijk kenmerk is van gebeurtenisbronnen, is dit de gebruikelijke implementatiebeslissing.
De geselecteerde gebeurtenisopslag moet ondersteuning bieden voor de gebeurtenisbelasting die door uw toepassing is gegenereerd.
Houd rekening met scenario's waarbij de verwerking van één gebeurtenis betrekking heeft op het maken van een of meer nieuwe gebeurtenissen, omdat dit een oneindige lus kan veroorzaken.
Wanneer dit patroon gebruiken
Gebruik dit patroon in de volgende scenario's:
Als u de bedoeling, het doel of de reden in de gegevens wilt vastleggen. Wijzigingen in een klantentiteit kunnen bijvoorbeeld worden vastgelegd als een reeks specifieke gebeurtenistypen, zoals Verplaatst huis, Gesloten account of Overleden.
Als het cruciaal is het optreden van conflicterende updates aan gegevens te minimaliseren of volledige te voorkomen.
Wanneer u gebeurtenissen wilt vastleggen die zich voordoen, om ze opnieuw af te spelen om de status van een systeem te herstellen, wijzigingen terug te draaien of om een geschiedenis en auditlogboek te behouden. Wanneer een taak bijvoorbeeld meerdere stappen omvat, moet u mogelijk acties uitvoeren om updates terug te zetten en vervolgens enkele stappen opnieuw afspelen om de gegevens weer in een consistente status te brengen.
Wanneer u gebeurtenissen gebruikt. Het is een natuurlijk kenmerk van de werking van de toepassing en vereist weinig extra ontwikkel- of implementatie-inspanning.
Wanneer u het invoerproces wilt loskoppelen of gegevens wilt bijwerken van de taken die nodig zijn om deze acties toe te passen. Deze wijziging kan zijn om de prestaties van de gebruikersinterface te verbeteren of om gebeurtenissen te distribueren naar andere listeners die actie ondernemen wanneer de gebeurtenissen plaatsvinden. U kunt bijvoorbeeld een salarissysteem integreren met een website voor het indienen van onkosten. De gebeurtenissen die door het gebeurtenisarchief worden gegenereerd als reactie op gegevensupdates die op de website zijn aangebracht, worden gebruikt door zowel de website als het salarissysteem.
Als u flexibiliteit wilt om de indeling van gerealiseerde modellen en entiteitsgegevens te wijzigen als de vereisten veranderen, of, wanneer deze worden gebruikt met CQRS, moet u een leesmodel of de weergaven aanpassen die de gegevens beschikbaar maken.
Wanneer het wordt gebruikt met CQRS en uiteindelijke consistentie acceptabel is terwijl een leesmodel wordt bijgewerkt, of de invloed van de prestaties van het reactiveren van entiteiten en gegevens uit een gebeurtenisstroom acceptabel is.
Dit patroon is wellicht niet geschikt in de volgende situaties:
Kleine of eenvoudige domeinen, systemen met weinig of geen bedrijfslogica of niet-domeinsystemen die in het algemeen goed werken met traditionele CRUD-gegevensbeheermechanismen.
Systemen waarbij consistentie en updates aan de weergaven van de gegevens in realtime zijn vereist.
Systemen waarbij audittrails, geschiedenis en mogelijkheden voor het terugdraaien en opnieuw afspelen van acties niet vereist zijn.
Systemen waarbij er slechts weinig conflicterende updates zijn voor de onderliggende gegevens. Bijvoorbeeld systemen die hoofdzakelijk gegevens toevoegen in plaats van ze bij te werken.
Workloadontwerp
Een architect moet evalueren hoe het patroon Gebeurtenisbronnen kan worden gebruikt in het ontwerp van hun workload om de doelstellingen en principes te verhelpen die worden behandeld in de pijlers van het Azure Well-Architected Framework. Voorbeeld:
| Pijler | Hoe dit patroon ondersteuning biedt voor pijlerdoelen |
|---|---|
| Beslissingen over betrouwbaarheidsontwerp helpen uw workload bestand te worden tegen storingen en ervoor te zorgen dat deze herstelt naar een volledig functionerende status nadat er een fout is opgetreden. | Als gevolg van het vastleggen van een geschiedenis van wijzigingen in een complex bedrijfsproces, kan het herstel van statussen mogelijk maken als u statusarchieven moet herstellen. - RE:06 Gegevenspartitionering - RE:09 Herstel na noodgevallen |
| Prestatie-efficiëntie helpt uw workload efficiënt te voldoen aan de vereisten door optimalisaties in schalen, gegevens, code. | Dit patroon, meestal gecombineerd met CQRS, een geschikt domeinontwerp en strategische momentopnamen, kan de prestaties van werkbelastingen verbeteren vanwege de atomische bewerkingen die alleen worden toegevoegd en het vermijden van databasevergrendeling voor schrijf- en leesbewerkingen. - PE:08 Gegevensprestaties |
Net als bij elke ontwerpbeslissing moet u rekening houden met eventuele compromissen ten opzichte van de doelstellingen van de andere pijlers die met dit patroon kunnen worden geïntroduceerd.
Opmerking
Een conferentiebeheersysteem moet het aantal voltooide reserveringen voor een conferentie bijhouden. Op deze manier kan worden gecontroleerd of er nog seats beschikbaar zijn wanneer een potentiële deelnemer probeert een reservering te maken. Het systeem kan het totale aantal reserveringen voor een conferentie op ten minste twee manieren opslaan:
Het systeem kan informatie over het totale aantal reserveringen opslaan als een aparte entiteit in een database waarin de reserveringsgegevens worden bewaard. Als er reserveringen worden gedaan of geannuleerd, kan dit aantal worden verhoogd respectievelijk verlaagd. Deze benadering is in theorie eenvoudig, maar kan aanleiding geven tot schaalbaarheidsproblemen als een groot aantal deelnemers in korte tijd plaatsen wil reserveren. Bijvoorbeeld op de laatste dag voordat de reserveringsperiode afloopt.
Het systeem kan informatie over reserveringen en annuleringen opslaan als gebeurtenissen die in een gebeurtenissenarchief worden bewaard. Vervolgens kan het aantal beschikbare plaatsen worden berekend door de gebeurtenissen opnieuw af te spelen. Deze benadering kan meer schaalbaar zijn vanwege de onveranderlijkheid van de gebeurtenissen. Het systeem hoeft alleen maar gegevens te lezen in het gebeurtenissenarchief of gegevens toe te voegen aan het gebeurtenissenarchief. Gebeurtenisinformatie over reserveringen en annuleringen wordt nooit gewijzigd.
In het volgende diagram wordt getoond hoe het subsysteem voor het reserveren van plaatsen van het conferentiebeheersysteem kan worden geïmplementeerd door middel van gebeurtenisbronnen.
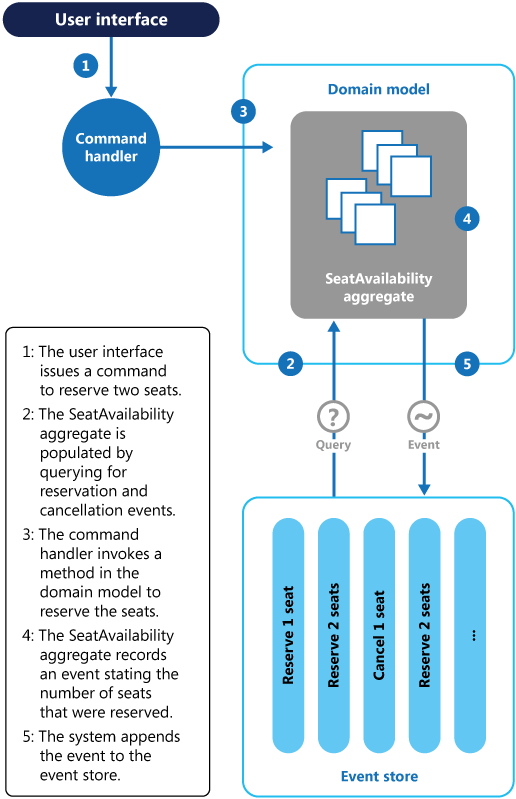
De volgorde van de acties voor het reserveren van twee plaatsen is als volgt:
De gebruikersinterface geeft de opdracht plaatsen te reserveren voor twee deelnemers. De opdracht wordt afgehandeld door een aparte opdrachthandler. Dit is een stukje logica dat wordt ontkoppeld van de gebruikersinterface en verantwoordelijk is voor het afhandelen van aanvragen die als opdrachten zijn gepost.
Er wordt een aggregatie met informatie over alle reserveringen voor de conferentie gebouwd door query's uit te voeren in de gebeurtenissen waarin de reserveringen en annuleringen staan beschreven. Dit aggregaat wordt
SeatAvailabilitygenoemd en bevindt zich in een domeinmodel dat methoden beschikbaar maakt voor het uitvoeren van query's in gegevens en het wijzigen van gegevens in het aggregaat.Sommige optimalisaties waarmee u rekening moet houden, zijn het gebruik van momentopnamen (zodat u geen query's hoeft uit te voeren op de volledige lijst met gebeurtenissen om de huidige status van de aggregatie te verkrijgen) en een kopie in de cache van de aggregatie in het geheugen hoeft te onderhouden.
De opdrachthandler roept een methode aan die door het domeinmodel beschikbaar wordt gemaakt om reserveringen te maken.
Het
SeatAvailability-aggregaat registreert een gebeurtenis met het aantal gereserveerde plaatsen. De volgende keer dat het aggregaat gebeurtenissen toepast, worden alle reserveringen gebruikt om te berekenen hoeveel plaatsen er nog resteren.Het systeem voegt de nieuwe gebeurtenis toe aan de lijst met gebeurtenissen in het gebeurtenissenarchief.
Als een gebruiker een plaats annuleert, volgt het systeem een soortgelijk proces. Hierbij wordt een opdracht gegeven waarmee een annuleringsgebeurtenis wordt gegenereerd die aan het gebeurtenissenarchief wordt toegevoegd.
Naast het bieden van meer schaalbaarheidsbereik, biedt het gebruik van een gebeurtenisarchief ook een volledige geschiedenis of audittrail van de reserveringen en annuleringen voor een conferentie. De gebeurtenissen in het gebeurtenissenarchief zijn vormen de juiste record. Het is niet nodig om aggregaties op een andere manier te behouden, omdat het systeem de gebeurtenissen eenvoudig opnieuw kan afspelen en de status op elk gewenst moment kan herstellen.
In Introducing Event Sourcing (Inleiding tot gebeurtenisbronnen) vindt u meer informatie over dit voorbeeld.
Volgende stappen
Inleiding over gegevensconsistentie. Wanneer u gebeurtenisbronnen gebruikt met een afzonderlijk leesarchief of gerealiseerde weergaven, zijn de leesgegevens niet onmiddellijk consistent. In plaats daarvan zijn de gegevens alleen uiteindelijk consistent. In dit artikel vindt u een overzicht van de problemen met betrekking tot het onderhouden van consistentie over gedistribueerde gegevens.
Richtlijnen voor gegevenspartitionering. Gegevens worden vaak gepartitioneerd wanneer u gebeurtenisbronnen gebruikt om de schaalbaarheid te verbeteren, conflicten te verminderen en de prestaties te optimaliseren. In dit artikel wordt beschreven hoe u gegevens opsplitst in afzonderlijke partities en welke problemen zich kunnen voordoen.
Blog van Martin Fowler:
Verwante resources
De volgende patronen en richtlijnen zijn mogelijk ook relevant bij de implementatie van dit patroon:
CQRS-patroon (Command and Query Responsibility Segregation). Het leesarchief (de permanente bron van informatie voor een CQRS-implementatie) wordt vaak gebaseerd op een implementatie van het gebeurtenisbronnenpatroon. Het beschrijft hoe de bewerkingen die gegevens in een toepassing lezen, door middel van afzonderlijke interfaces moeten worden gescheiden van de bewerkingen die gegevens bijwerken.
Gerealiseerde weergave-patroon. Het gegevensarchief dat wordt gebruikt in een systeem dat is gebaseerd op gebeurtenisbronnen, is doorgaans niet geschikt voor efficiënte query's. Daarom worden vaak weergaven van de gegevens gegenereerd die vooraf zijn ingevuld. Dit kan op regelmatige basis zijn of als de gegevens worden gewijzigd.
Patroon Compenserende transactie. De bestaande gegevens in een gebeurtenisbronnenarchief worden niet bijgewerkt. In plaats daarvan worden nieuwe vermeldingen toegevoegd die de status van entiteiten overschakelen naar de nieuwe waarden. Als u een wijziging wilt omkeren, worden compenserende vermeldingen gebruikt omdat het niet mogelijk is om de vorige wijziging om te keren. Beschrijft hoe het werk dat door een eerdere bewerking is uitgevoerd, ongedaan kan worden gemaakt.