Patroon leiderkiezing
Coördineer de acties die worden uitgevoerd door een verzameling samenwerkende instanties in een gedistribueerde toepassing door één exemplaar te kiezen als de leider die verantwoordelijk is voor het beheren van de andere exemplaren. Dit kan helpen ervoor te zorgen dat exemplaren niet met elkaar conflicteren, conflicten veroorzaken voor gedeelde resources of per ongeluk interfereren met het werk dat andere exemplaren uitvoeren.
Context en probleem
Een typische cloudtoepassing heeft veel taken die op een gecoördineerde manier fungeren. Deze taken kunnen allemaal exemplaren zijn die dezelfde code uitvoeren en toegang tot dezelfde resources vereisen, of ze werken mogelijk parallel samen om de afzonderlijke onderdelen van een complexe berekening uit te voeren.
De taakexemplaren kunnen gedurende een groot deel van de tijd afzonderlijk worden uitgevoerd, maar het kan ook nodig zijn om de acties van elk exemplaar te coördineren om ervoor te zorgen dat ze geen conflict veroorzaken, conflicten veroorzaken voor gedeelde resources of per ongeluk interfereren met het werk dat andere taakexemplaren uitvoeren.
Voorbeeld:
- In een cloudsysteem dat horizontaal schalen implementeert, kunnen meerdere exemplaren van dezelfde taak tegelijkertijd worden uitgevoerd met elk exemplaar dat een andere gebruiker bedient. Als deze exemplaren naar een gedeelde resource schrijven, is het nodig om hun acties te coördineren om te voorkomen dat elk exemplaar de wijzigingen van de andere exemplaren overschrijft.
- Als de taken afzonderlijke elementen van een complexe berekening parallel uitvoeren, moeten de resultaten worden samengevoegd wanneer ze allemaal zijn voltooid.
De taakexemplaren zijn allemaal peers, dus er is geen natuurlijke leider die als coördinator of aggregator kan fungeren.
Oplossing
Er moet één taakexemplaren worden gekozen om te fungeren als leider en dit exemplaar moet de acties van de andere onderliggende taakinstanties coördineren. Als alle taakexemplaren dezelfde code uitvoeren, kunnen ze elk fungeren als de leider. Daarom moet het verkiezingsproces zorgvuldig worden beheerd om te voorkomen dat twee of meer instanties tegelijkertijd de leiderpositie overnemen.
Het systeem moet een robuust mechanisme bieden voor het selecteren van de leider. Deze methode moet omgaan met gebeurtenissen zoals netwerkstoringen of procesfouten. In veel oplossingen bewaken de onderliggende taakexemplaren de leider via een bepaald type heartbeatmethode of door polling. Als de aangewezen leider onverwacht wordt beëindigd of als een netwerkfout de leider niet beschikbaar maakt voor de onderliggende taakexemplaren, is het nodig om een nieuwe leider te kiezen.
Er zijn meerdere strategieën voor het kiezen van een leider in een set taken in een gedistribueerde omgeving, waaronder:
- Racen om een gedeelde, gedistribueerde mutex te verkrijgen. Het eerste taakexemplaren dat de mutex verkrijgt, is de leider. Het systeem moet er echter voor zorgen dat, als de leider wordt beëindigd of wordt losgekoppeld van de rest van het systeem, de mutex wordt vrijgegeven zodat een ander taakex-exemplaar de leider kan worden. Deze strategie wordt gedemonstreerd in het onderstaande voorbeeld.
- Het implementeren van een van de algemene algoritmen voor leiderkiezers, zoals het Bully-algoritme, het Raft Consensus-algoritme of het Ring-algoritme. Bij deze algoritmen wordt ervan uitgegaan dat elke kandidaat in de verkiezing een unieke id heeft en dat deze op betrouwbare wijze kan communiceren met de andere kandidaten.
Problemen en overwegingen
Houd rekening met de volgende punten bij het bepalen hoe u dit patroon implementeert:
- Het proces van het kiezen van een leider moet bestand zijn tegen tijdelijke en permanente fouten.
- Het moet mogelijk zijn om te detecteren wanneer de leider is mislukt of anders niet beschikbaar is geworden (bijvoorbeeld vanwege een communicatiefout). Hoe snel detectie nodig is, is afhankelijk van het systeem. Sommige systemen kunnen gedurende korte tijd functioneren zonder een leider, waarbij een tijdelijke fout kan worden opgelost. In andere gevallen kan het nodig zijn om fouten van leiders onmiddellijk te detecteren en een nieuwe verkiezing te activeren.
- In een systeem dat horizontale automatische schaalaanpassing implementeert, kan de leider worden beëindigd als het systeem wordt teruggeschaald en een deel van de rekenresources afsluit.
- Met behulp van een gedeelde, gedistribueerde mutex wordt een afhankelijkheid van de externe service geïntroduceerd die de mutex biedt. De service vormt een single point of failure. Als het om welke reden dan ook niet meer beschikbaar is, kan het systeem geen leider kiezen.
- Het gebruik van één speciaal proces omdat de leider een eenvoudige benadering is. Als het proces echter mislukt, kan er een aanzienlijke vertraging optreden tijdens het opnieuw opstarten. De resulterende latentie kan van invloed zijn op de prestaties en reactietijden van andere processen als ze wachten totdat de leider een bewerking coördineert.
- Het handmatig implementeren van een van de leiderkiesalgoritmen biedt de grootste flexibiliteit voor het afstemmen en optimaliseren van de code.
- Vermijd dat de leider een knelpunt in het systeem wordt. Het doel van de leider is het coördineren van het werk van de onderliggende taken en het hoeft niet noodzakelijkerwijs deel te nemen aan dit werk zelf, hoewel dit wel moet kunnen als de taak niet als leider wordt gekozen.
Wanneer gebruikt u dit patroon?
Gebruik dit patroon wanneer de taken in een gedistribueerde toepassing, zoals een in de cloud gehoste oplossing, zorgvuldige coördinatie nodig hebben en er geen natuurlijke leider is.
Dit patroon is mogelijk niet nuttig als:
- Er is een natuurlijk leider of speciaal proces dat altijd als leider kan fungeren. Het kan bijvoorbeeld mogelijk zijn om een singleton-proces te implementeren dat de taakexemplaren coördineert. Als dit proces mislukt of beschadigd raakt, kan het systeem het afsluiten en opnieuw opstarten.
- De coördinatie tussen taken kan worden bereikt met behulp van een lichtgewicht methode. Als bijvoorbeeld meerdere taakexemplaren alleen gecoördineerde toegang tot een gedeelde resource nodig hebben, is een betere oplossing om optimistische of pessimistische vergrendeling te gebruiken om de toegang te beheren.
- Een oplossing van derden, zoals Apache Zookeeper , is mogelijk een efficiëntere oplossing.
Workloadontwerp
Een architect moet evalueren hoe het Leader Election-patroon kan worden gebruikt in het ontwerp van hun workload om de doelstellingen en principes te verhelpen die worden behandeld in de pijlers van het Azure Well-Architected Framework. Voorbeeld:
| Pilaar | Hoe dit patroon ondersteuning biedt voor pijlerdoelen |
|---|---|
| Beslissingen over betrouwbaarheidsontwerp helpen uw workload bestand te worden tegen storingen en ervoor te zorgen dat deze herstelt naar een volledig functionerende status nadat er een fout is opgetreden. | Dit patroon vermindert het effect van storingen in knooppunten door werk betrouwbaar om te leiden. Het implementeert ook failover via consensusalgoritmen wanneer een leider defect is. - RE:05 Redundantie - RE:07 Zelfherstel |
Net als bij elke ontwerpbeslissing moet u rekening houden met eventuele compromissen ten opzichte van de doelstellingen van de andere pijlers die met dit patroon kunnen worden geïntroduceerd.
Voorbeeld
Het leader election-voorbeeld op GitHub laat zien hoe u een lease op een Azure Storage-blob gebruikt om een mechanisme te bieden voor het implementeren van een gedeelde, gedistribueerde mutex. Deze mutex kan worden gebruikt om een leider te kiezen tussen een groep beschikbare werkrolexemplaren. De eerste instantie voor het verkrijgen van de lease wordt gekozen als leider en blijft de leider totdat de lease wordt vrijgegeven of de lease niet kan worden verlengd. Andere werkrolexemplaren kunnen de blob-lease blijven bewaken als de leider niet meer beschikbaar is.
Een blob-lease is een exclusieve schrijfvergrendeling voor een blob. Eén blob kan op elk moment slechts één lease bevatten. Een werkrolexemplaren kunnen een lease aanvragen via een opgegeven blob en de lease wordt verleend als er geen ander werkrolexemplaren een lease over dezelfde blob bevatten. Anders genereert de aanvraag een uitzondering.
Als u wilt voorkomen dat een instantie van een leider de lease voor onbepaalde tijd behoudt, geeft u een levensduur voor de lease op. Wanneer dit verloopt, wordt de lease beschikbaar. Hoewel een instantie de lease behoudt, kan deze echter aanvragen dat de lease wordt verlengd en wordt de lease gedurende een langere periode verleend. Het exemplaar van de leider kan dit proces voortdurend herhalen als deze de lease wil behouden. Zie Lease Blob (REST API) voor meer informatie over het leasen van een blob.
De BlobDistributedMutex klasse in het onderstaande C#-voorbeeld bevat de RunTaskWhenMutexAcquired methode waarmee een werkrolexemplaren een lease kunnen verkrijgen via een opgegeven blob. De details van de blob (de naam, container en opslagaccount) worden doorgegeven aan de constructor in een BlobSettings object wanneer het BlobDistributedMutex object wordt gemaakt (dit object is een eenvoudige struct die is opgenomen in de voorbeeldcode). De constructor accepteert ook een Task code die verwijst naar de code die het werkrolexemplaren moeten uitvoeren als deze de lease over de blob heeft verkregen en de leider wordt gekozen. Houd er rekening mee dat de code waarmee de details op laag niveau van het verkrijgen van de lease worden verwerkt, wordt geïmplementeerd in een afzonderlijke helperklasse met de naam BlobLeaseManager.
public class BlobDistributedMutex
{
...
private readonly BlobSettings blobSettings;
private readonly Func<CancellationToken, Task> taskToRunWhenLeaseAcquired;
...
public BlobDistributedMutex(BlobSettings blobSettings,
Func<CancellationToken, Task> taskToRunWhenLeaseAcquired, ... )
{
this.blobSettings = blobSettings;
this.taskToRunWhenLeaseAcquired = taskToRunWhenLeaseAcquired;
...
}
public async Task RunTaskWhenMutexAcquired(CancellationToken token)
{
var leaseManager = new BlobLeaseManager(blobSettings);
await this.RunTaskWhenBlobLeaseAcquired(leaseManager, token);
}
...
De RunTaskWhenMutexAcquired methode in het bovenstaande codevoorbeeld roept de RunTaskWhenBlobLeaseAcquired methode aan die wordt weergegeven in het volgende codevoorbeeld om de lease daadwerkelijk te verkrijgen. De RunTaskWhenBlobLeaseAcquired methode wordt asynchroon uitgevoerd. Als de lease is verkregen, is het werkrolexemplaren geselecteerd als leider. Het doel van de taskToRunWhenLeaseAcquired gemachtigde is het uitvoeren van het werk dat de andere werkrolexemplaren coördineert. Als de lease niet wordt verkregen, is een ander werkrolexemplaren geselecteerd als de leider en blijft het huidige werkrolexemplaren een ondergeschikte. Houd er rekening mee dat de TryAcquireLeaseOrWait methode een helpermethode is die gebruikmaakt van het BlobLeaseManager object om de lease te verkrijgen.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (!token.IsCancellationRequested)
{
// Try to acquire the blob lease.
// Otherwise wait for a short time before trying again.
string? leaseId = await this.TryAcquireLeaseOrWait(leaseManager, token);
if (!string.IsNullOrEmpty(leaseId))
{
// Create a new linked cancellation token source so that if either the
// original token is canceled or the lease can't be renewed, the
// leader task can be canceled.
using (var leaseCts =
CancellationTokenSource.CreateLinkedTokenSource(new[] { token }))
{
// Run the leader task.
var leaderTask = this.taskToRunWhenLeaseAcquired.Invoke(leaseCts.Token);
...
}
}
}
...
}
De taak die door de leider is gestart, wordt ook asynchroon uitgevoerd. Terwijl deze taak wordt uitgevoerd, probeert de RunTaskWhenBlobLeaseAcquired methode die wordt weergegeven in het volgende codevoorbeeld periodiek de lease te vernieuwen. Dit helpt ervoor te zorgen dat het werkrolexemplaren de leider blijven. In de voorbeeldoplossing is de vertraging tussen verlengingsaanvragen minder dan de tijd die is opgegeven voor de duur van de lease om te voorkomen dat een ander werkrolexemplaren worden gekozen als leider. Als de verlenging om welke reden dan ook mislukt, wordt de opvultaak geannuleerd.
Als de lease niet kan worden vernieuwd of de taak wordt geannuleerd (mogelijk als gevolg van het afsluiten van het werkrolexemplaren), wordt de lease vrijgegeven. Op dit moment kan dit of een ander werkrolexemplaren worden gekozen als de leider. In het onderstaande code-extract ziet u dit deel van het proces.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (...)
{
...
if (...)
{
...
using (var leaseCts = ...)
{
...
// Keep renewing the lease in regular intervals.
// If the lease can't be renewed, then the task completes.
var renewLeaseTask =
this.KeepRenewingLease(leaseManager, leaseId, leaseCts.Token);
// When any task completes (either the leader task itself or when it
// couldn't renew the lease) then cancel the other task.
await CancelAllWhenAnyCompletes(leaderTask, renewLeaseTask, leaseCts);
}
}
}
}
...
}
De KeepRenewingLease methode is een andere helpermethode die gebruikmaakt van het BlobLeaseManager object om de lease te vernieuwen. De CancelAllWhenAnyCompletes methode annuleert de taken die zijn opgegeven als de eerste twee parameters. Het volgende diagram illustreert het gebruik van de BlobDistributedMutex klasse om een leider te kiezen en een taak uit te voeren die bewerkingen coördineert.
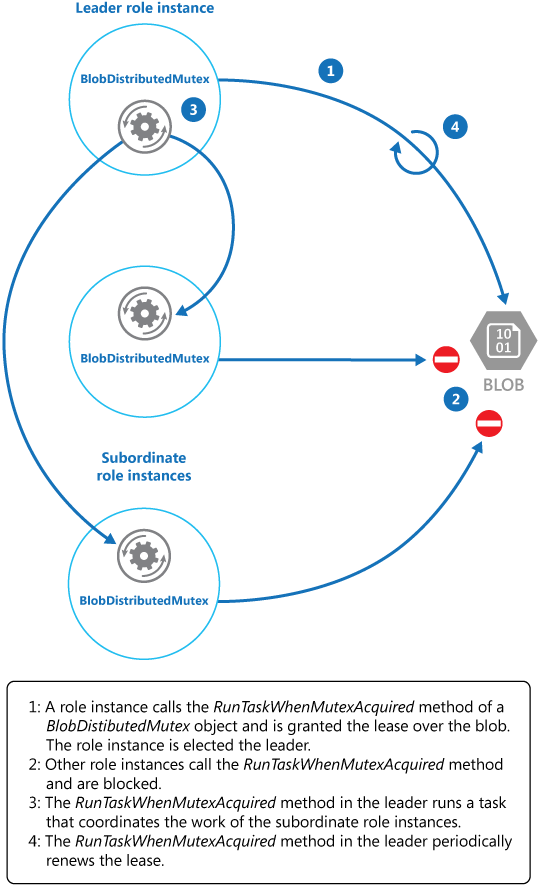
In het volgende codevoorbeeld ziet u hoe u de BlobDistributedMutex klasse binnen een werkrolexemplaren gebruikt. Deze code verkrijgt een lease via een blob met de naam MyLeaderCoordinatorTask in de container Azure Blob Storage van de lease en geeft aan dat de code die in de MyLeaderCoordinatorTask methode is gedefinieerd, moet worden uitgevoerd als het werkrolexemplaren de leider wordt gekozen.
// Create a BlobSettings object with the connection string or managed identity and the name of the blob to use for the lease
BlobSettings blobSettings = new BlobSettings(storageConnStr, "leases", "MyLeaderCoordinatorTask");
// Create a new BlobDistributedMutex object with the BlobSettings object and a task to run when the lease is acquired
var distributedMutex = new BlobDistributedMutex(
blobSettings, MyLeaderCoordinatorTask);
// Wait for completion of the DistributedMutex and the UI task before exiting
await distributedMutex.RunTaskWhenMutexAcquired(cancellationToken);
...
// Method that runs if the worker instance is elected the leader
private static async Task MyLeaderCoordinatorTask(CancellationToken token)
{
...
}
Let op de volgende punten over de voorbeeldoplossing:
- De blob is een potentieel single point of failure. Als de blobservice niet meer beschikbaar is of niet toegankelijk is, kan de leider de lease niet verlengen en kan geen ander werkrolexemplaren de lease verkrijgen. In dit geval kan geen werkrolinstantie fungeren als de leider. De blob-service is echter ontworpen om tolerant te zijn, dus een volledige fout van de blobservice wordt als zeer onwaarschijnlijk beschouwd.
- Als de taak die door de leider wordt uitgevoerd, blijft de leider de lease verlengen, waardoor andere werkrolinstanties de lease niet kunnen verkrijgen en de positie van de leider overnemen om taken te coördineren. In de praktijk moet de gezondheid van de leider regelmatig worden gecontroleerd.
- Het verkiezingsproces is niet-deterministisch. U kunt geen veronderstellingen maken over welk werkrolexemplaren de blob-lease verkrijgen en de leider worden.
- De blob die als doel van de blob-lease wordt gebruikt, mag niet worden gebruikt voor een ander doel. Als een werkrolinstantie probeert gegevens op te slaan in deze blob, zijn deze gegevens niet toegankelijk, tenzij het werkrolexemplaren de leider is en de blob-lease bevat.
Volgende stappen
De volgende richtlijnen zijn mogelijk ook relevant bij het implementeren van dit patroon:
- Dit patroon heeft een downloadbare voorbeeldtoepassing.
- Richtlijnen voor automatisch schalen. Het is mogelijk om exemplaren van de taakhosts te starten en te stoppen wanneer de belasting van de toepassing varieert. Automatisch schalen kan helpen bij het onderhouden van doorvoer en prestaties tijdens piekverwerkingstijden.
- Het asynchrone patroon op basis van een taak.
- Een voorbeeld van het bully-algoritme.
- Een voorbeeld van het ringalgoritmen.
- Apache Curator een clientbibliotheek voor Apache ZooKeeper.
- Het artikel Lease Blob (REST API) op MSDN.