Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Azure
U kunt een toepassing de mogelijkheid bieden tijdelijke fouten af te handelen wanneer de toepassing probeert verbinding te maken met een service of netwerkresource door een mislukte bewerking transparant opnieuw te proberen. Hiermee kunt u de stabiliteit van de toepassing verbeteren.
Context en probleem
Een toepassing die communiceert met elementen die worden uitgevoerd in de cloud, moet gevoelig zijn voor de tijdelijke fouten die in deze omgeving kunnen optreden. Fouten zijn onder meer tijdelijk verlies van de netwerkverbinding met onderdelen en services, het tijdelijk niet beschikbaar zijn van een service of time-outs die zich voordoen wanneer een service bezet is.
Doorgaans corrigeren deze fouten zichzelf en als de actie die een fout heeft geactiveerd na een geschikte vertraging wordt herhaald, zal deze waarschijnlijk lukken. Een databaseservice die een groot aantal gelijktijdige aanvragen verwerkt, kan bijvoorbeeld een beperkingsstrategie implementeren die tijdelijk verdere aanvragen weigert totdat de workload is versoepeld. Een toepassing die probeert toegang te krijgen tot de database, kan mogelijk geen verbinding maken, maar als het na een vertraging opnieuw wordt geprobeerd, kan het wel lukken.
Oplossing
In de cloud moeten tijdelijke fouten worden verwacht en moet een toepassing zijn ontworpen om ze elegant en transparant te verwerken. Dit minimaliseert de effecten die fouten kunnen hebben op de zakelijke taken die de toepassing uitvoert. Het meest voorkomende ontwerppatroon dat moet worden aangepakt, is door een mechanisme voor opnieuw proberen te introduceren.
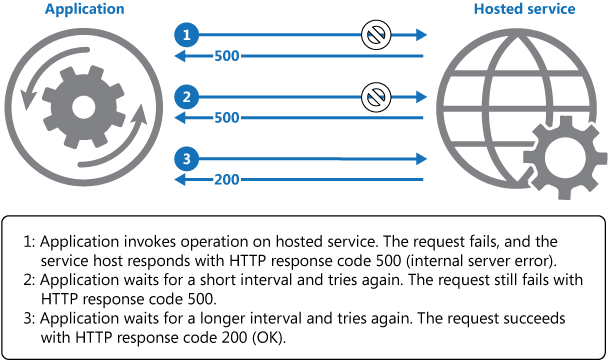
Het bovenstaande diagram illustreert het aanroepen van een bewerking in een gehoste service met behulp van een mechanisme voor opnieuw proberen. Als de aanvraag mislukt na een vooraf gedefinieerd aantal pogingen, behandelt de toepassing de fout als een uitzondering en wordt deze dienovereenkomstig verwerkt.
Notitie
Vanwege de algemene aard van tijdelijke fouten zijn ingebouwde mechanismen voor nieuwe pogingen nu beschikbaar in veel clientbibliotheken en cloudservices, met enige mate van configureerbaarheid voor het aantal maximale nieuwe pogingen, de vertraging tussen nieuwe pogingen en andere parameters. De Microsoft Entity Framework- biedt faciliteiten voor het opnieuw proberen mislukte databasebewerkingen.
Strategieën voor opnieuw proberen
Als een toepassing een fout detecteert wanneer wordt geprobeerd een aanvraag naar een externe service te verzenden, kan de fout worden afgehandeld met behulp van de volgende strategieën:
Annuleren. Als de fout aangeeft dat het probleem niet tijdelijk is of als het onwaarschijnlijk is dat de bewerking slaagt wanneer deze wordt herhaald, moet de toepassing de bewerking annuleren en een uitzondering rapporteren.
Probeer het onmiddellijk opnieuw. Als de gemelde specifieke fout ongebruikelijk of zeldzaam is, zoals een netwerkpakket dat beschadigd raakt terwijl het werd verzonden, kan het beste zijn om de aanvraag onmiddellijk opnieuw uit te voeren.
Opnieuw proberen na vertraging. Als de fout wordt veroorzaakt door een van de meest voorkomende connectiviteits- of bezetfouten, heeft het netwerk of de service mogelijk een korte periode nodig terwijl de verbindingsproblemen worden gecorrigeerd of de achterstand van het werk wordt gewist, zodat het programmatisch vertragen van de nieuwe poging een goede strategie is. In veel gevallen moet de periode tussen nieuwe pogingen worden gekozen om aanvragen van meerdere exemplaren van de toepassing zo gelijkmatig mogelijk te verspreiden om de kans te verminderen dat een drukke service overbelast blijft.
Als de aanvraag nog steeds mislukt, kan de toepassing wachten en een nieuwe poging doen. Zo nodig kan dit proces worden herhaald met toenemende vertragingen tussen nieuwe pogingen totdat een maximum aantal aanvragen is geprobeerd. De vertraging kan incrementeel of exponentieel worden vergroot, afhankelijk van het type fout en de kans dat deze in de loop der tijd wordt gecorrigeerd.
De toepassing moet alle pogingen om toegang te krijgen tot een externe service verpakken in code die een beleid voor opnieuw proberen implementeert dat overeenkomt met een van de hierboven genoemde strategieën. Voor aanvragen die naar verschillende services worden verzonden, kunnen verschillende soorten beleid gelden.
Een toepassing moet de details van fouten en mislukte bewerkingen vastleggen in een logboek. Deze informatie is nuttig voor operators. Dat gezegd hebbende, is het raadzaam om te voorkomen dat operators over overstromingen waarschuwingen krijgen over bewerkingen waarbij nieuwe pogingen zijn geslaagd, het beste om vroege fouten te registreren als informatieve vermeldingen en alleen de fout van de laatste pogingspogingen als een werkelijke fout. Hier volgt een voorbeeld van hoe dit logboekregistratiemodel eruit zou zien.
Als een service regelmatig niet beschikbaar of bezet is, komt dit vaak doordat de service geen resources meer heeft. U kunt de frequentie van deze fouten verminderen door de service uit te breiden. Als een databaseservice bijvoorbeeld voortdurend wordt overbelast, kan het nuttig zijn de database te partitioneren en de belasting over meerdere servers te verdelen.
Problemen en overwegingen
U moet de volgende punten overwegen wanneer u besluit hoe u dit patroon wilt implementeren.
Invloed op prestaties
Het beleid voor opnieuw proberen moet zijn afgestemd op de zakelijke vereisten van de toepassing en de aard van de fout. Voor sommige niet-kritieke bewerkingen is het beter om snel te mislukken in plaats van meerdere keren opnieuw te proberen en de doorvoer van de toepassing te beïnvloeden. In een interactieve webtoepassing die toegang heeft tot een externe service, is het bijvoorbeeld beter om te mislukken na een kleiner aantal nieuwe pogingen met slechts een korte vertraging tussen nieuwe pogingen en een geschikt bericht weer te geven aan de gebruiker (bijvoorbeeld 'probeer het later opnieuw'). Voor een batchtoepassing is het mogelijk beter het aantal nieuwe pogingen te verhogen met een exponentieel toenemende vertraging tussen de pogingen.
Bij een agressief beleid voor opnieuw proberen met een minimale vertraging tussen pogingen en een groot aantal nieuwe pogingen kunnen de prestaties van een bezette service die wordt uitgevoerd op (bijna) maximale capaciteit verder afnemen. Dit beleid voor opnieuw proberen kan ook van invloed zijn op de reactietijd van de toepassing als deze voortdurend probeert een mislukte bewerking uit te voeren.
Als een aanvraag na een groot aantal nieuwe pogingen nog steeds mislukt, is het beter voor de toepassing om verdere aanvragen naar dezelfde resource te voorkomen en onmiddellijk een fout te melden. Als de periode is verlopen, kan de toepassing als proef een of meer aanvragen toestaan om te kijken of ze slagen. Zie voor meer informatie over deze strategie het Circuitonderbrekerpatroon.
Idempotentie
Overweeg of de bewerking idempotent is. Als dit het geval is, is het inherent veilig om het opnieuw te proberen. Zo niet, dan kunnen nieuwe pogingen ertoe leiden dat de bewerking meer dan eenmaal wordt uitgevoerd met onbedoelde neveneffecten. Een service kan bijvoorbeeld de aanvraag ontvangen en deze met succes verwerken, waarna het verzenden van een antwoord mislukt. Op dat punt kan de logica voor opnieuw proberen de aanvraag mogelijk opnieuw verzenden, omdat ervan wordt uitgegaan dat de eerste aanvraag niet is ontvangen.
Uitzonderingstype
Een verzoek aan een dienst kan om verschillende redenen mislukken, waarbij verschillende uitzonderingen worden opgeworpen afhankelijk van de aard van de fout. Sommige uitzonderingen wijzen op een fout die snel kan worden opgelost, terwijl anderen aangeven dat de fout langduriger is. Het beleid voor opnieuw proberen kan het beste de tijd tussen pogingen aanpassen op basis van het type uitzondering.
Transactieconsistentie
Houd er rekening mee hoe het opnieuw proberen van een bewerking die deel uitmaakt van een transactie van invloed is op de algehele consistentie van de transactie. Stem het beleid voor opnieuw proberen af op transactionele bewerkingen om de kans van slagen te maximaliseren en de noodzaak om alle stappen van de transactie ongedaan te maken te verminderen.
Algemene richtlijnen
Zorg ervoor dat alle code voor opnieuw proberen volledig is getest op basis van verschillende foutvoorwaarden. Controleer of deze niet ernstig van invloed is op de prestaties of betrouwbaarheid van de toepassing, overmatige belasting van services en resources veroorzaakt of raceomstandigheden of knelpunten genereert.
Implementeer logica voor opnieuw proberen alleen als u de volledige context van een bewerking begrijpt. Als een taak die een beleid voor opnieuw proberen bevat, bijvoorbeeld een andere taak aanroept die ook een beleid voor opnieuw proberen bevat, kan deze extra laag van nieuwe pogingen lange vertragingen aan de verwerking toevoegen. Het is mogelijk beter de taak op het lagere niveau zo te configureren dat deze snel mislukt en de reden voor de fout terug te melden aan de taak die de lagere taak heeft aangeroepen. Deze taak op het hogere niveau kan vervolgens de fout afhandelen op basis van het eigen beleid.
Registreer alle verbindingsfouten die een nieuwe poging veroorzaken, zodat onderliggende problemen met de toepassing, services of resources kunnen worden geïdentificeerd.
Onderzoek de fouten waarvan de kans het grootst is dat ze optreden voor een service of resource om te achterhalen of ze waarschijnlijk langdurig of terminaal zijn. Als dat het geval, is het beter om de fout af te handelen als een uitzondering. De toepassing kan de uitzondering rapporteren of vastleggen en vervolgens proberen door te gaan door een alternatieve service aan te roepen (indien beschikbaar) of door verminderde functionaliteit te bieden. Zie Circuitonderbrekerpatroon voor meer informatie over het detecteren en afhandelen van langdurige fouten.
Wanneer dit patroon gebruiken
Gebruik dit patroon wanneer een toepassing tijdelijke fouten kan ondervinden tijdens interactie met een externe service of toegang tot een externe resource. Deze fouten zijn naar verwachting van korte duur en als een aanvraag die eerder is mislukt, wordt herhaald, kan de volgende poging mogelijk wel lukken.
Dit patroon is mogelijk niet geschikt:
- Wanneer een fout waarschijnlijk langdurig is, omdat dit de reactiesnelheid van een toepassing kan beïnvloeden. De toepassing kan tijd en resources verspillen doordat wordt geprobeerd een aanvraag te herhalen die waarschijnlijk zal mislukken.
- Voor het afhandelen van problemen die niet worden veroorzaakt door tijdelijke fouten, zoals interne uitzonderingen veroorzaakt door fouten in de bedrijfslogica van een toepassing.
- Als alternatief voor het oplossen van schaalbaarheidsproblemen in een systeem. Als een toepassing vaak fouten ondervindt omdat de service of resource bezet is, is dit vaak een teken dat de desbetreffende service of resource moet worden uitgebreid.
Workloadontwerp
Een architect moet evalueren hoe het patroon Voor opnieuw proberen kan worden gebruikt in het ontwerp van hun workload om de doelstellingen en principes te verhelpen die worden behandeld in de pijlers van het Azure Well-Architected Framework. Voorbeeld:
| Pijler | Hoe dit patroon ondersteuning biedt voor pijlerdoelen |
|---|---|
| Beslissingen over betrouwbaarheidsontwerp helpen uw workload bestand te worden tegen storingen en ervoor te zorgen dat deze herstelt naar een volledig functionerende status nadat er een fout is opgetreden. | Tijdelijke fouten in een gedistribueerd systeem beperken is een kerntechniek voor het verbeteren van de tolerantie van een workload. - RE:07 Zelfbehoud - RE:07 Tijdelijke fouten |
Net als bij elke ontwerpbeslissing moet u rekening houden met eventuele compromissen ten opzichte van de doelstellingen van de andere pijlers die met dit patroon kunnen worden geïntroduceerd.
Opmerking
Raadpleeg de handleiding Een beleid voor opnieuw proberen implementeren met .NET voor een gedetailleerd voorbeeld met behulp van de Azure SDK met ingebouwde ondersteuning voor opnieuw proberen.
Volgende stappen
Voordat u aangepaste logica voor opnieuw proberen schrijft, kunt u overwegen een algemeen framework te gebruiken, zoals Polly voor .NET of Resilience4j voor Java.
Wanneer u opdrachten verwerkt die bedrijfsgegevens wijzigen, moet u er rekening mee houden dat nieuwe pogingen ertoe kunnen leiden dat de actie tweemaal wordt uitgevoerd. Dit kan problematisch zijn als deze actie iets is als het opladen van de creditcard van een klant. Het gebruik van het Idempotentiepatroon dat in dit blogbericht wordt beschreven, kan helpen bij het omgaan met deze situaties.
Verwante resources
Betrouwbaar web-app-patroon laat zien hoe u het patroon voor opnieuw proberen kunt toepassen op webtoepassingen die in de cloud worden samengevoegd.
Voor de meeste Azure-services bevatten de client-SDK's ingebouwde logica voor opnieuw proberen.
Circuitonderbrekerpatroon. Als een fout naar verwachting langduriger is, is het mogelijk beter om een circuitonderbrekerpatroon te implementeren. Het combineren van de patronen voor opnieuw proberen en circuitonderbreker biedt een uitgebreide benadering voor het afhandelen van fouten.