In dit artikel wordt beschreven hoe een ontwikkelteam metrische gegevens heeft gebruikt om knelpunten te vinden en de prestaties van een gedistribueerd systeem te verbeteren. Het artikel is gebaseerd op werkelijke belastingstests die zijn uitgevoerd voor een voorbeeldtoepassing. De toepassing is afkomstig van de AKS-basislijn (Azure Kubernetes Service) voor microservices, samen met een Visual Studio-belastingtestproject dat wordt gebruikt om de resultaten te genereren.
Dit artikel maakt deel uit van een serie. Lees hier het eerste deel.
Scenario: meerdere back-endservices aanroepen om informatie op te halen en vervolgens de resultaten te aggregeren.
Dit scenario omvat een toepassing voor het bezorgen van drones. Clients kunnen een query uitvoeren op een REST API om hun meest recente factuurgegevens op te halen. De factuur bevat een overzicht van de leveringen, pakketten en het totale dronegebruik van de klant. Deze toepassing maakt gebruik van een microservicesarchitectuur die wordt uitgevoerd op AKS en de informatie die nodig is voor de factuur is verdeeld over verschillende microservices.
In plaats van dat de client elke service rechtstreeks aanroept, implementeert de toepassing het patroon GatewayAggregatie . Met behulp van dit patroon doet de client één aanvraag naar een gatewayservice. De gateway roept op zijn beurt de back-endservices parallel aan en voegt vervolgens de resultaten samen in één nettolading van het antwoord.
Test 1: Basislijnprestaties
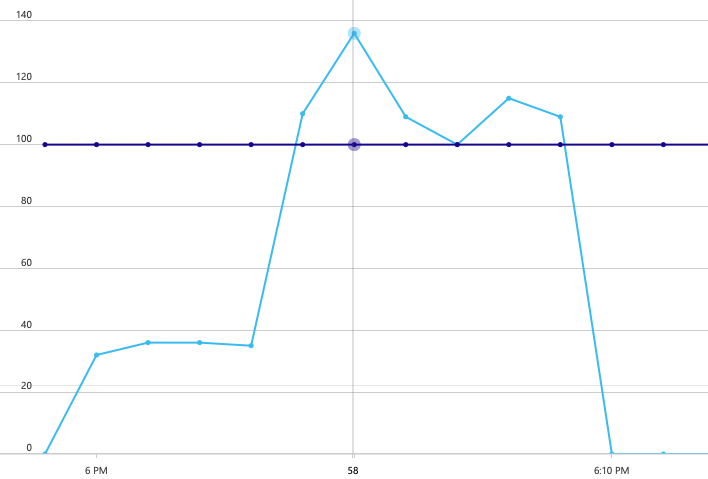
Om een basislijn vast te stellen, is het ontwikkelteam begonnen met een stapsgewijze belastingstest, waarbij de belasting van één gesimuleerde gebruiker wordt verhoogd tot maximaal 40 gebruikers, met een totale duur van 8 minuten. In de volgende grafiek, afkomstig van Visual Studio, worden de resultaten weergegeven. De paarse lijn toont de gebruikersbelasting en de oranje lijn toont de doorvoer (gemiddelde aanvragen per seconde).
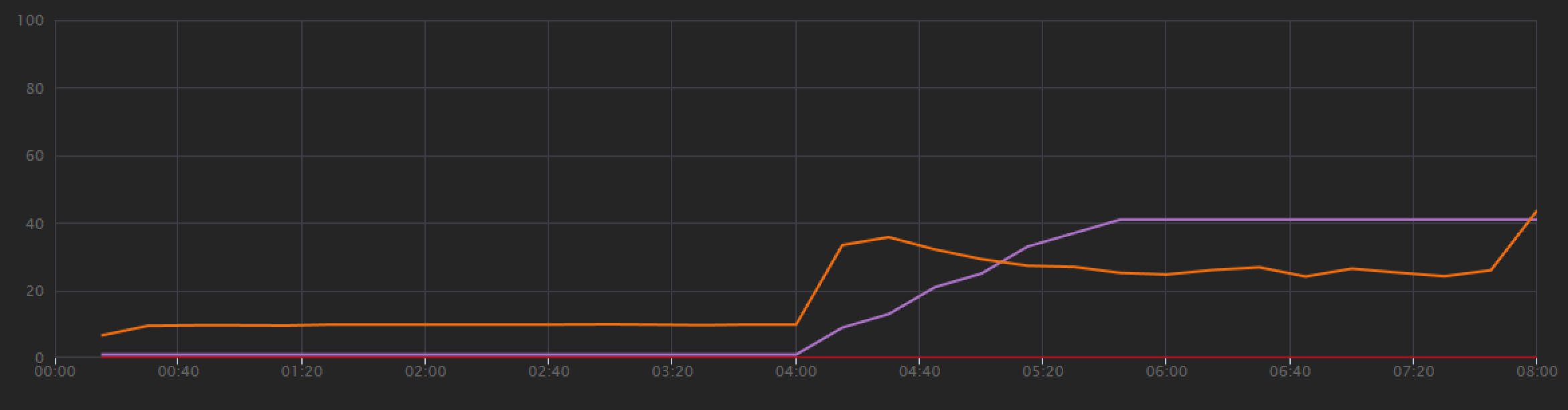
De rode lijn onder aan de grafiek geeft aan dat er geen fouten zijn geretourneerd naar de client, wat bemoedigend is. De gemiddelde doorvoer piekt echter ongeveer halverwege de test en daalt vervolgens voor de rest, zelfs terwijl de belasting blijft toenemen. Dit geeft aan dat de back-end het niet kan bijhouden. Het patroon dat hier wordt weergegeven, komt vaak voor wanneer een systeem resourcelimieten begint te bereiken: nadat een maximum is bereikt, daalt de doorvoer aanzienlijk. Resourceconflicten, tijdelijke fouten of een toename van het aantal uitzonderingen kunnen allemaal bijdragen aan dit patroon.
Laten we de bewakingsgegevens bekijken om te leren wat er in het systeem gebeurt. De volgende grafiek is afkomstig uit Application Insights. Het toont de gemiddelde duur van de HTTP-aanroepen van de gateway naar de back-endservices.
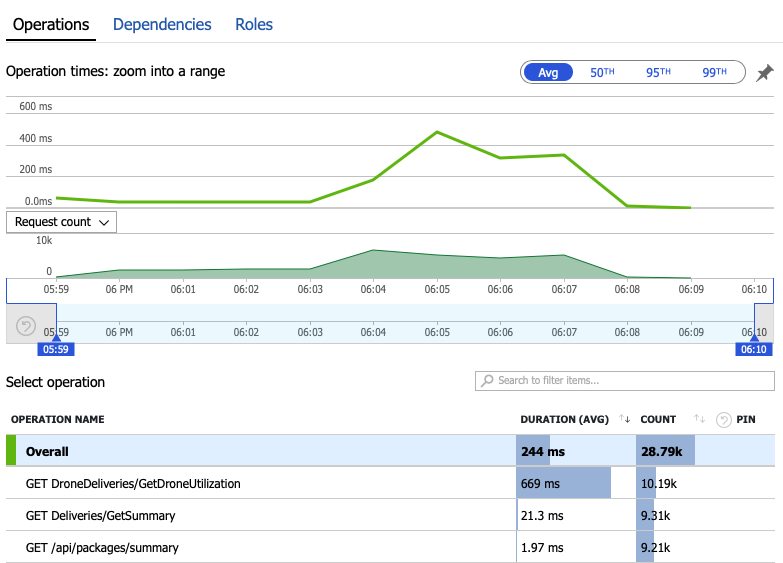
In deze grafiek ziet u dat één bewerking in het bijzonder, GetDroneUtilization, gemiddeld veel langer duurt, in een volgorde van grootte. De gateway voert deze aanroepen parallel uit, dus de langzaamste bewerking bepaalt hoe lang het duurt voordat de hele aanvraag is voltooid.
Het is duidelijk dat de volgende stap is om de GetDroneUtilization bewerking te onderzoeken en te zoeken naar eventuele knelpunten. Een mogelijkheid is uitputting van resources. Misschien heeft deze specifieke back-endservice onvoldoende CPU of geheugen. Voor een AKS-cluster is deze informatie beschikbaar in de Azure Portal via de functie Azure Monitor container insights. In de volgende grafieken ziet u het resourcegebruik op clusterniveau:
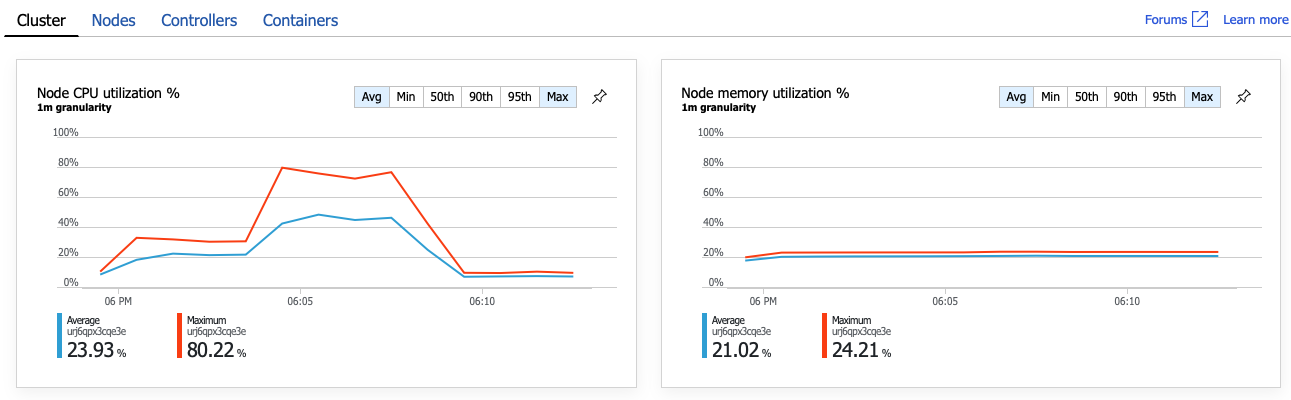
In deze schermopname worden zowel de gemiddelde als de maximumwaarde weergegeven. Het is belangrijk om te kijken naar meer dan alleen het gemiddelde, omdat het gemiddelde pieken in de gegevens kan verbergen. Hier blijft het gemiddelde CPU-gebruik onder de 50%, maar er zijn een paar pieken tot 80%. Dat is dicht bij de capaciteit, maar nog steeds binnen de toleranties. Iets anders veroorzaakt het knelpunt.
In de volgende grafiek wordt de ware dader weergegeven. In deze grafiek ziet u HTTP-antwoordcodes uit de back-enddatabase van de Delivery-service, in dit geval Azure Cosmos DB. De blauwe lijn vertegenwoordigt succescodes (HTTP 2xx), terwijl de groene lijn HTTP 429-fouten vertegenwoordigt. Een HTTP 429-retourcode betekent dat Azure Cosmos DB aanvragen tijdelijk beperkt, omdat de aanroeper meer resource-eenheden (RU) verbruikt dan is ingericht.
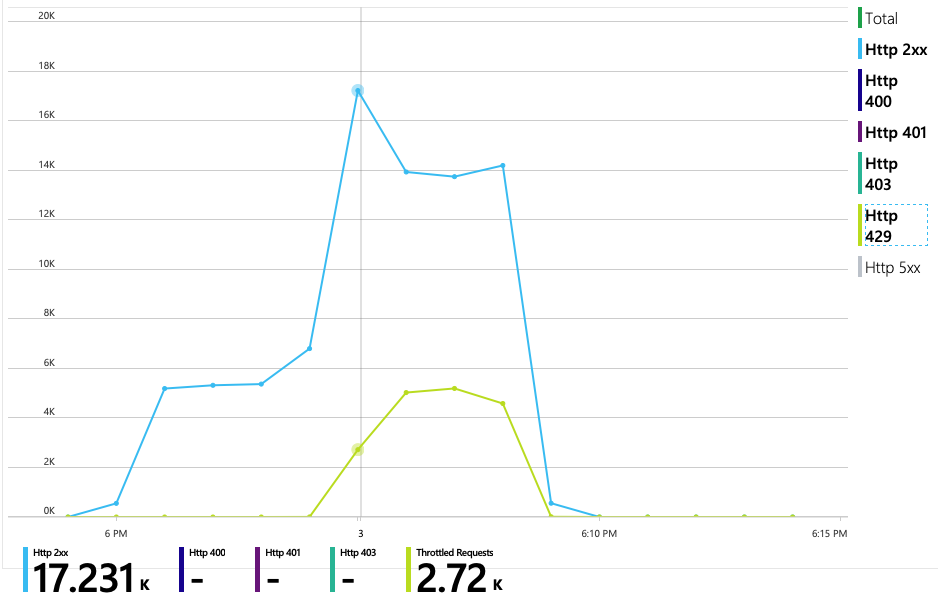
Om meer inzicht te krijgen, heeft het ontwikkelteam Application Insights gebruikt om de end-to-end-telemetrie weer te geven voor een representatieve steekproef van aanvragen. Hier volgt één exemplaar:
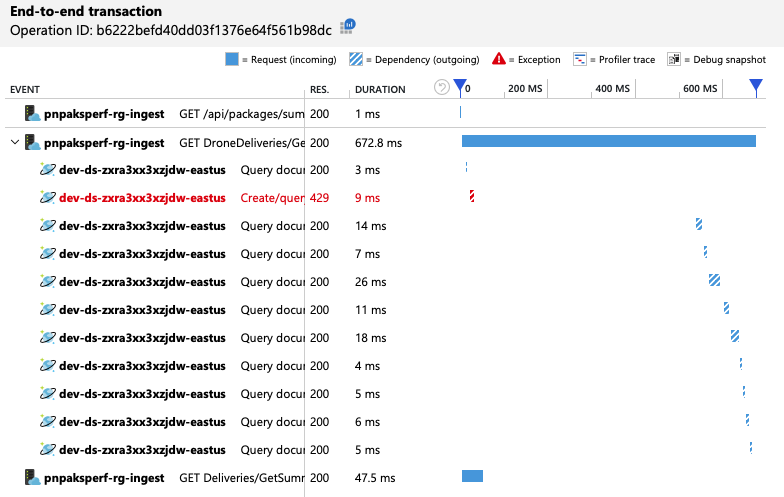
In deze weergave worden de aanroepen weergegeven die betrekking hebben op één clientaanvraag, samen met tijdsinformatie en antwoordcodes. De aanroepen op het hoogste niveau zijn van de gateway naar de back-endservices. De aanroep naar GetDroneUtilization wordt uitgebreid om aanroepen naar externe afhankelijkheden weer te geven, in dit geval naar Azure Cosmos DB. De aanroep in het rood heeft een HTTP 429-fout geretourneerd.
Let op de grote kloof tussen de HTTP 429-fout en de volgende aanroep. Wanneer de Azure Cosmos DB-clientbibliotheek een HTTP 429-fout ontvangt, wordt automatisch een back-up uitgevoerd en wordt gewacht om de bewerking opnieuw uit te voeren. Wat deze weergave laat zien, is dat tijdens de 672 ms die deze bewerking duurde, het grootste deel van die tijd werd besteed aan het wachten op het opnieuw proberen van Azure Cosmos DB.
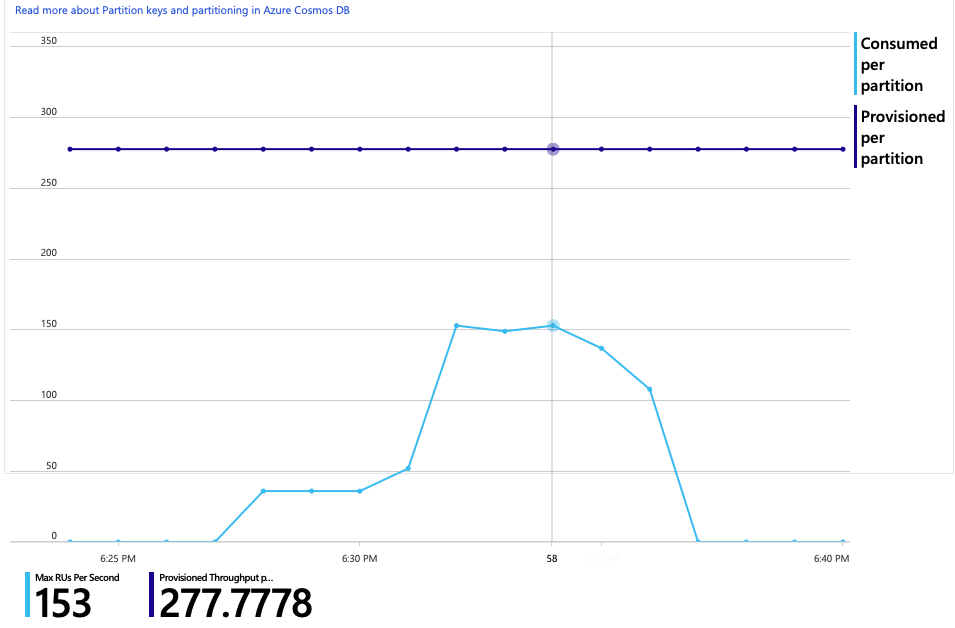
Hier volgt nog een interessante grafiek voor deze analyse. Het RU-verbruik per fysieke partitie versus ingerichte RU's per fysieke partitie wordt weergegeven:
Om deze grafiek te begrijpen, moet u begrijpen hoe Azure Cosmos DB partities beheert. Verzamelingen in Azure Cosmos DB kunnen een partitiesleutel hebben. Elke mogelijke sleutelwaarde definieert een logische partitie van de gegevens in de verzameling. Azure Cosmos DB distribueert deze logische partities over een of meer fysieke partities. Het beheer van fysieke partities wordt automatisch verwerkt door Azure Cosmos DB. Naarmate u meer gegevens opslaat, kan Azure Cosmos DB logische partities verplaatsen naar nieuwe fysieke partities om de belasting over de fysieke partities te verdelen.
Voor deze belastingstest is de Azure Cosmos DB-verzameling ingericht met 900 RU's. De grafiek toont 100 RU per fysieke partitie, wat een totaal van negen fysieke partities impliceert. Hoewel Azure Cosmos DB automatisch de sharding van fysieke partities afhandelt, kan het kennen van het aantal partities inzicht geven in de prestaties. Het ontwikkelteam gebruikt deze informatie later, terwijl ze doorgaan met optimaliseren. Waar de blauwe lijn de paarse horizontale lijn overschrijdt, heeft het RU-verbruik de ingerichte RU's overschreden. Dat is het punt waarop Azure Cosmos DB aanroepen gaat beperken.
Test 2: Resource-eenheden verhogen
Voor de tweede belastingstest heeft het team de Azure Cosmos DB-verzameling uitgeschaald van 900 RU naar 2500 RU. De doorvoer steeg van 19 aanvragen per seconde naar 23 aanvragen per seconde en de gemiddelde latentie daalde van 669 ms naar 569 ms.
| Metrisch | Test 1 | Test 2 |
|---|---|---|
| Doorvoer (req/sec) | 19 | 23 |
| Gemiddelde latentie (ms) | 669 | 569 |
| Geslaagde aanvragen | 9,8 K | 11 K |
Dit zijn geen enorme voordelen, maar als u de grafiek in de loop van de tijd bekijkt, ziet u een completer beeld:
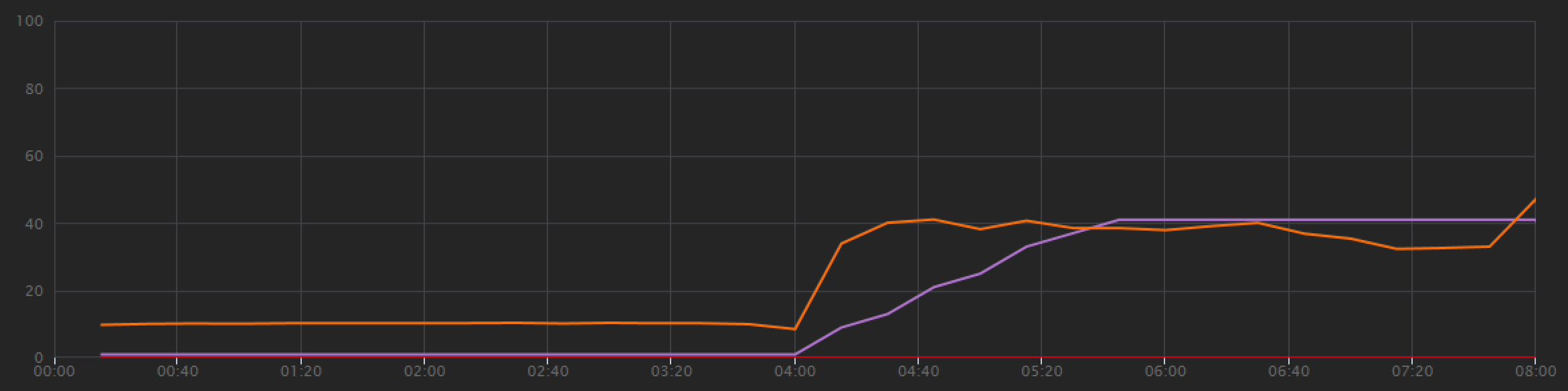
Terwijl de vorige test een eerste piek liet zien, gevolgd door een scherpe daling, toont deze test een consistentere doorvoer. De maximale doorvoer is echter niet aanzienlijk hoger.
Alle aanvragen naar Azure Cosmos DB hebben een 2xx-status geretourneerd en de HTTP 429-fouten zijn verdwenen:
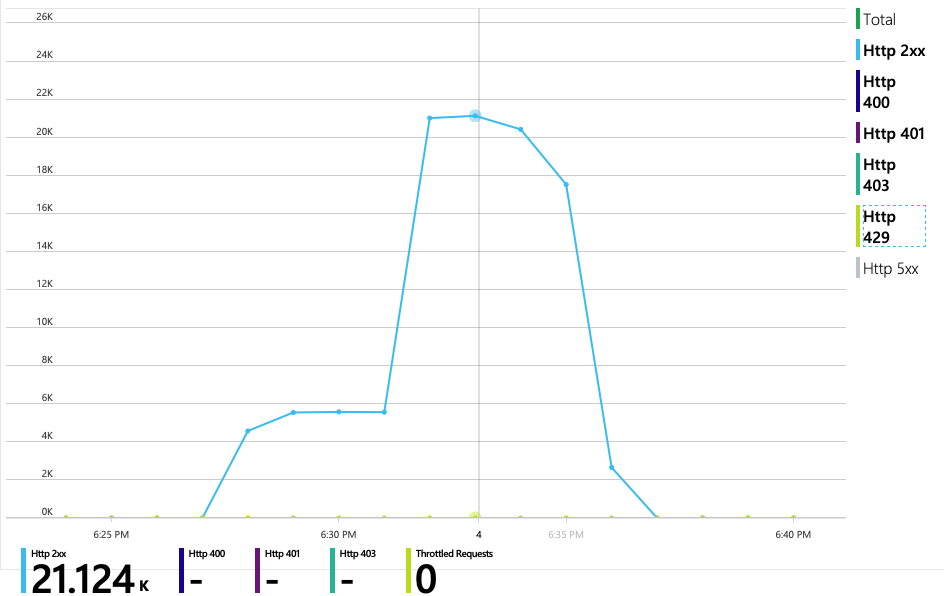
De grafiek van RU-verbruik versus ingerichte RU's laat zien dat er voldoende ruimte is. Er zijn ongeveer 275 RU's per fysieke partitie en de belastingtest piekte met ongeveer 100 RU's die per seconde zijn verbruikt.
Een andere interessante metrische waarde is het aantal aanroepen naar Azure Cosmos DB per geslaagde bewerking:
| Metrisch | Test 1 | Test 2 |
|---|---|---|
| Aanroepen per bewerking | 11 | 9 |
Ervan uitgaande dat er geen fouten zijn, moet het aantal aanroepen overeenkomen met het werkelijke queryplan. In dit geval omvat de bewerking een partitieoverschrijdende query die alle negen fysieke partities raakt. De hogere waarde in de eerste belastingstest weerspiegelt het aantal aanroepen dat een 429-fout heeft geretourneerd.
Dit metrische gegeven is berekend door een aangepaste Log Analytics-query uit te voeren:
let start=datetime("2020-06-18T20:59:00.000Z");
let end=datetime("2020-07-24T21:10:00.000Z");
let operationNameToEval="GET DroneDeliveries/GetDroneUtilization";
let dependencyType="Azure DocumentDB";
let dataset=requests
| where timestamp > start and timestamp < end
| where success == true
| where name == operationNameToEval;
dataset
| project reqOk=itemCount
| summarize
SuccessRequests=sum(reqOk),
TotalNumberOfDepCalls=(toscalar(dependencies
| where timestamp > start and timestamp < end
| where type == dependencyType
| summarize sum(itemCount)))
| project
OperationName=operationNameToEval,
DependencyName=dependencyType,
SuccessRequests,
AverageNumberOfDepCallsPerOperation=(TotalNumberOfDepCalls/SuccessRequests)
Samenvattend toont de tweede belastingstest verbetering. De bewerking duurt echter GetDroneUtilization nog steeds ongeveer een orde van grootte langer dan de volgende langzaamste bewerking. Als u de end-to-end-transacties bekijkt, kunt u uitleggen waarom:
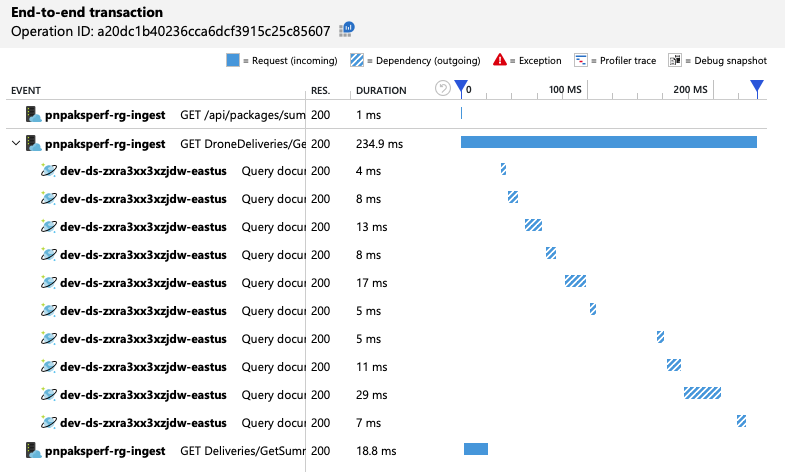
Zoals eerder vermeld, omvat de GetDroneUtilization bewerking een partitieoverschrijdende query naar Azure Cosmos DB. Dit betekent dat de Azure Cosmos DB-client de query naar elke fysieke partitie moet uitwaaieren en de resultaten moet verzamelen. Zoals in de end-to-end-transactieweergave wordt weergegeven, worden deze query's serieel uitgevoerd. De bewerking duurt zo lang als de som van alle query's. Dit probleem wordt alleen maar erger naarmate de grootte van de gegevens toeneemt en er meer fysieke partities worden toegevoegd.
Test 3: Parallelle query's
Op basis van de vorige resultaten is een voor de hand liggende manier om de latentie te verminderen door de query's parallel uit te voeren. De Azure Cosmos DB-client-SDK heeft een instelling waarmee de maximale mate van parallelle uitvoering wordt bepaald.
| Waarde | Beschrijving |
|---|---|
| 0 | Geen parallelle uitvoering (standaard) |
| > 0 | Maximum aantal parallelle aanroepen |
| -1 | De client-SDK selecteert een optimale mate van parallelle uitvoering |
Voor de derde belastingstest is deze instelling gewijzigd van 0 in -1. De volgende tabel bevat een overzicht van de resultaten:
| Metrisch | Test 1 | Test 2 | Test 3 |
|---|---|---|---|
| Doorvoer (req/sec) | 19 | 23 | 42 |
| Gemiddelde latentie (ms) | 669 | 569 | 215 |
| Geslaagde aanvragen | 9,8 K | 11 K | 20 K |
| Vertraagde aanvragen | 2,72 K | 0 | 0 |
In de belastingtestgrafiek is niet alleen de totale doorvoer veel hoger (de oranje lijn), maar de doorvoer houdt ook gelijke tred met de belasting (de paarse lijn).
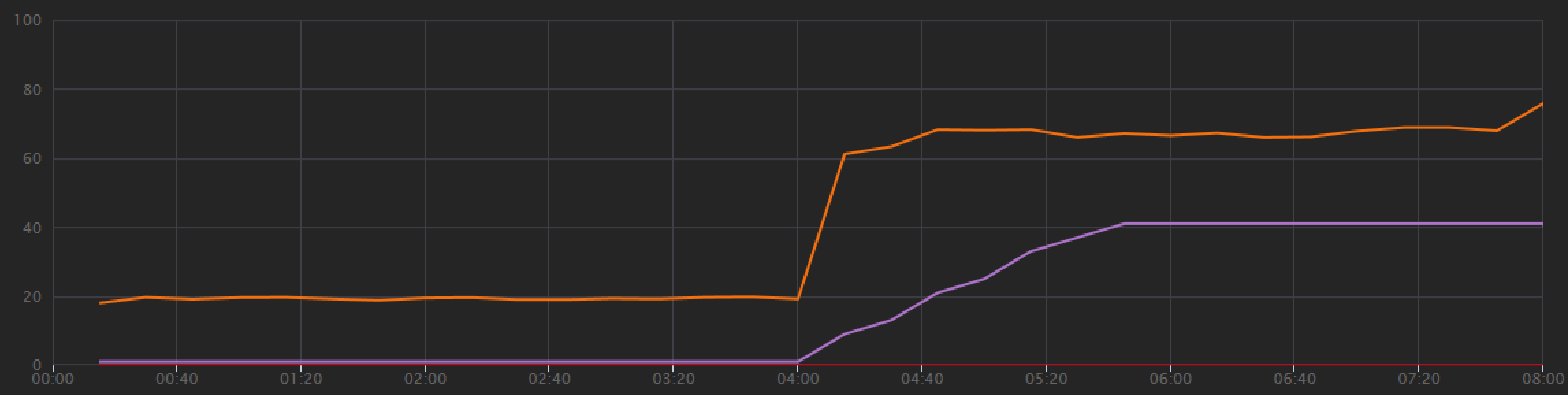
We kunnen controleren of de Azure Cosmos DB-client query's parallel maakt door te kijken naar de end-to-end transactieweergave:
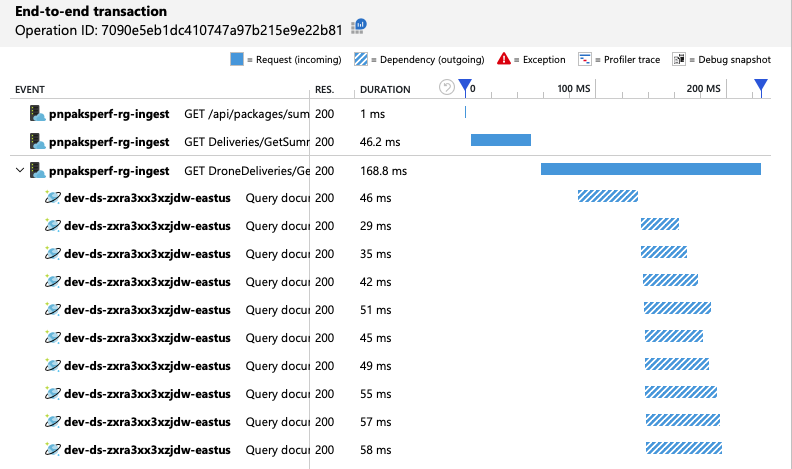
Een neveneffect van het verhogen van de doorvoer is dat het aantal verbruikte RU's per seconde ook toeneemt. Hoewel Azure Cosmos DB geen aanvragen heeft beperkt tijdens deze test, lag het verbruik dicht bij de ingerichte RU-limiet:
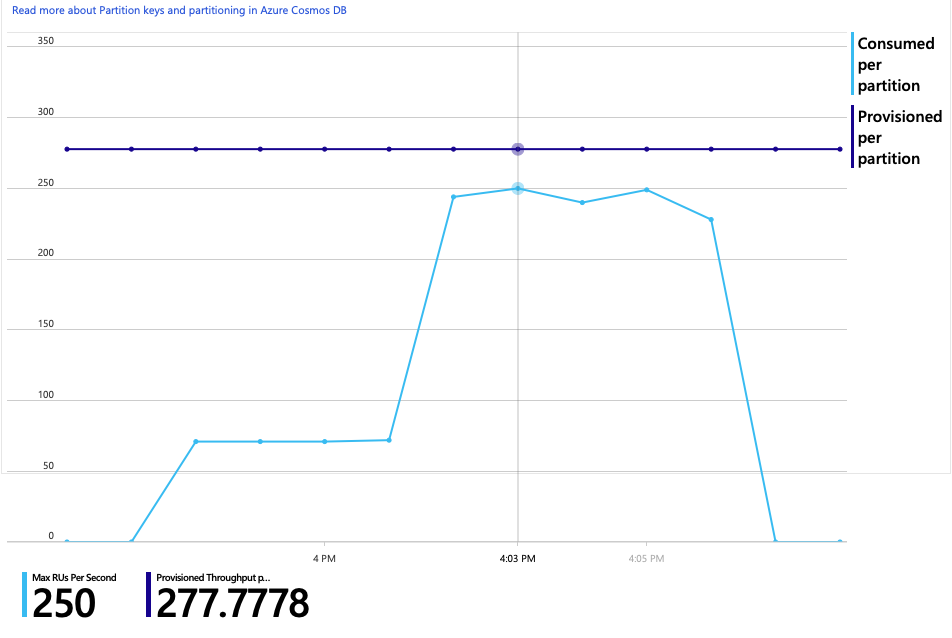
Deze grafiek kan een signaal zijn om de database verder uit te schalen. Het blijkt echter dat we in plaats daarvan de query kunnen optimaliseren.
Stap 4: De query optimaliseren
Bij de vorige belastingstest zijn betere prestaties op het gebied van latentie en doorvoer aan het licht gekomen. De gemiddelde latentie van aanvragen is verminderd met 68% en de doorvoer is met 220% toegenomen. De query voor meerdere partities is echter een probleem.
Het probleem met query's voor meerdere partities is dat u voor RU betaalt voor elke partitie. Als de query slechts af en toe wordt uitgevoerd, bijvoorbeeld één keer per uur, maakt het mogelijk niet uit. Maar wanneer u een leesintensieve workload ziet waarbij een partitieoverschrijdende query is betrokken, moet u zien of de query kan worden geoptimaliseerd door een partitiesleutel op te geven. (Mogelijk moet u de verzameling opnieuw ontwerpen om een andere partitiesleutel te gebruiken.)
Dit is de query voor dit specifieke scenario:
SELECT * FROM c
WHERE c.ownerId = <ownerIdValue> and
c.year = <yearValue> and
c.month = <monthValue>
Met deze query worden records geselecteerd die overeenkomen met een bepaalde eigenaar-id en maand/jaar. In het oorspronkelijke ontwerp is geen van deze eigenschappen de partitiesleutel. Hiervoor moet de client de query naar elke fysieke partitie uitwaaieren en de resultaten verzamelen. Om de queryprestaties te verbeteren, heeft het ontwikkelteam het ontwerp gewijzigd, zodat de eigenaar-id de partitiesleutel voor de verzameling is. Op die manier kan de query zich richten op een specifieke fysieke partitie. (Azure Cosmos DB verwerkt dit automatisch. U hoeft de toewijzing tussen partitiesleutelwaarden en fysieke partities niet te beheren.)
Na het overschakelen van de verzameling naar de nieuwe partitiesleutel is er een aanzienlijke verbetering in ru-verbruik, wat zich direct vertaalt in lagere kosten.
| Metrisch | Test 1 | Test 2 | Test 3 | Test 4 |
|---|---|---|---|---|
| RU's per bewerking | 29 | 29 | 29 | 3.4 |
| Aanroepen per bewerking | 11 | 9 | 10 | 1 |
In de end-to-end-transactieweergave ziet u dat, zoals voorspeld, de query slechts één fysieke partitie leest:
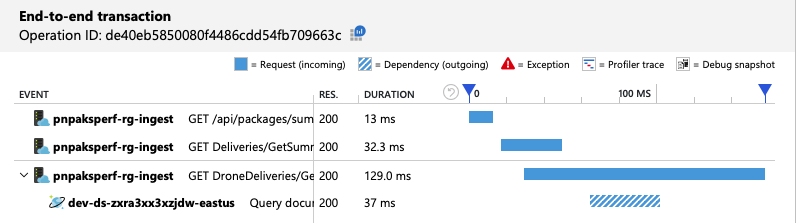
De belastingtest toont verbeterde doorvoer en latentie:
| Metrisch | Test 1 | Test 2 | Test 3 | Test 4 |
|---|---|---|---|---|
| Doorvoer (req/sec) | 19 | 23 | 42 | 59 |
| Gemiddelde latentie (ms) | 669 | 569 | 215 | 176 |
| Geslaagde aanvragen | 9,8 K | 11 K | 20 K | 29 K |
| Beperkte aanvragen | 2,72 K | 0 | 0 | 0 |
Een gevolg van de verbeterde prestaties is dat het CPU-gebruik van knooppunten zeer hoog wordt:
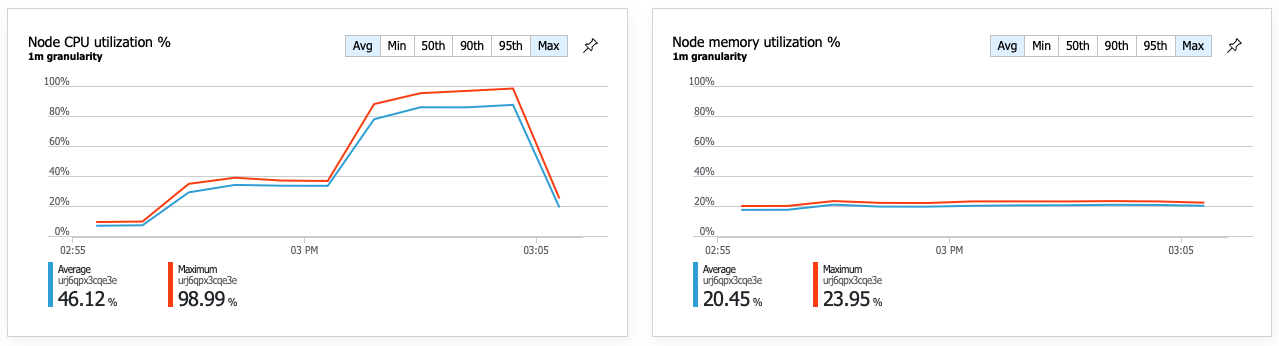
Aan het einde van de belastingstest bereikte de gemiddelde CPU ongeveer 90% en de maximale CPU 100%. Deze metrische waarde geeft aan dat CPU het volgende knelpunt in het systeem is. Als er een hogere doorvoer nodig is, is de volgende stap mogelijk het uitschalen van de Delivery-service naar meer exemplaren.
Samenvatting
Voor dit scenario zijn de volgende knelpunten geïdentificeerd:
- Azure Cosmos DB-beperkingsaanvragen vanwege onvoldoende ingerichte RU's.
- Hoge latentie veroorzaakt door het uitvoeren van query's op meerdere databasepartities in serieel.
- Inefficiënte query voor meerdere partities, omdat de query de partitiesleutel niet bevat.
Daarnaast is het CPU-gebruik geïdentificeerd als een potentieel knelpunt op hogere schaal. Om deze problemen vast te stellen, heeft het ontwikkelteam gekeken naar:
- Latentie en doorvoer van de belastingstest.
- Azure Cosmos DB-fouten en RU-verbruik.
- De end-to-end transactieweergave in Application Insight.
- CPU- en geheugengebruik in Azure Monitor-container insights.