In dit artikel wordt beschreven hoe een ontwikkelteam metrische gegevens heeft gebruikt om knelpunten te vinden en de prestaties van een gedistribueerd systeem te verbeteren. Het artikel is gebaseerd op het testen van de werkelijke belasting die we hebben uitgevoerd voor een voorbeeldtoepassing.
Dit artikel maakt deel uit van een serie. Lees hier het eerste deel.
Scenario: een stroom gebeurtenissen verwerken met behulp van Azure Functions.

In dit scenario verzendt een vloot van drones in realtime positiegegevens naar Azure IoT Hub. Een Functions-app ontvangt de gebeurtenissen, transformeert de gegevens in GeoJSON-indeling en schrijft de getransformeerde gegevens naar Azure Cosmos DB. Azure Cosmos DB biedt systeemeigen ondersteuning voor georuimtelijke gegevens en Azure Cosmos DB-verzamelingen kunnen worden geïndexeerd voor efficiënte ruimtelijke query's. Een clienttoepassing kan bijvoorbeeld alle drones binnen 1 km van een bepaalde locatie opvragen of alle drones binnen een bepaald gebied vinden.
Deze verwerkingsvereisten zijn eenvoudig genoeg om geen volwaardige stroomverwerkingsengine te vereisen. Bij de verwerking worden met name geen stromen samengevoegd, geen gegevens samengevoegd of verwerkt in tijdvensters. Op basis van deze vereisten is Azure Functions geschikt voor het verwerken van de berichten. Azure Cosmos DB kan ook worden geschaald om een zeer hoge schrijfdoorvoer te ondersteunen.
Doorvoer bewaken
Dit scenario vormt een interessante prestatie-uitdaging. De gegevenssnelheid per apparaat is bekend, maar het aantal apparaten kan fluctueren. Voor dit bedrijfsscenario zijn de latentievereisten niet bijzonder streng. De gerapporteerde positie van een drone hoeft slechts binnen een minuut nauwkeurig te zijn. Dat gezegd hebbende, moet de functie-app de gemiddelde opnamesnelheid in de loop van de tijd bijhouden.
IoT Hub slaat berichten op in een logboekstroom. Binnenkomende berichten worden toegevoegd aan de staart van de stroom. Een lezer van de stream, in dit geval de functie-app, bepaalt de eigen snelheid waarmee de stream wordt doorkruist. Deze ontkoppeling van de lees- en schrijfpaden maakt IoT Hub zeer efficiënt, maar betekent ook dat een trage lezer achter kan blijven. Om deze voorwaarde te detecteren, heeft het ontwikkelteam een aangepaste metrische waarde toegevoegd om de late status van berichten te meten. Met deze metrische waarde wordt het verschil vastgelegd tussen wanneer een bericht op IoT Hub aankomt en wanneer de functie het bericht voor verwerking ontvangt.
var ticksUTCNow = DateTimeOffset.UtcNow;
// Track whether messages are arriving at the function late.
DateTime? firstMsgEnqueuedTicksUtc = messages[0]?.EnqueuedTimeUtc;
if (firstMsgEnqueuedTicksUtc.HasValue)
{
CustomTelemetry.TrackMetric(
context,
"IoTHubMessagesReceivedFreshnessMsec",
(ticksUTCNow - firstMsgEnqueuedTicksUtc.Value).TotalMilliseconds);
}
De TrackMetric methode schrijft een aangepaste metrische waarde naar Application Insights. Zie Aangepaste telemetrie in C#-functie voor meer informatie over het gebruik TrackMetric in een Azure-functie.
Als de functie het aantal berichten bijhoudt, moet deze metrische waarde een lage stabiele status hebben. Enige latentie is onvermijdelijk, dus de waarde zal nooit nul zijn. Maar als de functie achterloopt, zal de delta tussen de ge enqueueerde tijd en de verwerkingstijd beginnen op te gaan.
Test 1: Basislijn
De eerste belastingstest toonde een onmiddellijk probleem aan: de functie-app heeft consistent HTTP 429-fouten ontvangen van Azure Cosmos DB, wat aangeeft dat Azure Cosmos DB de schrijfaanvragen heeft beperkt.
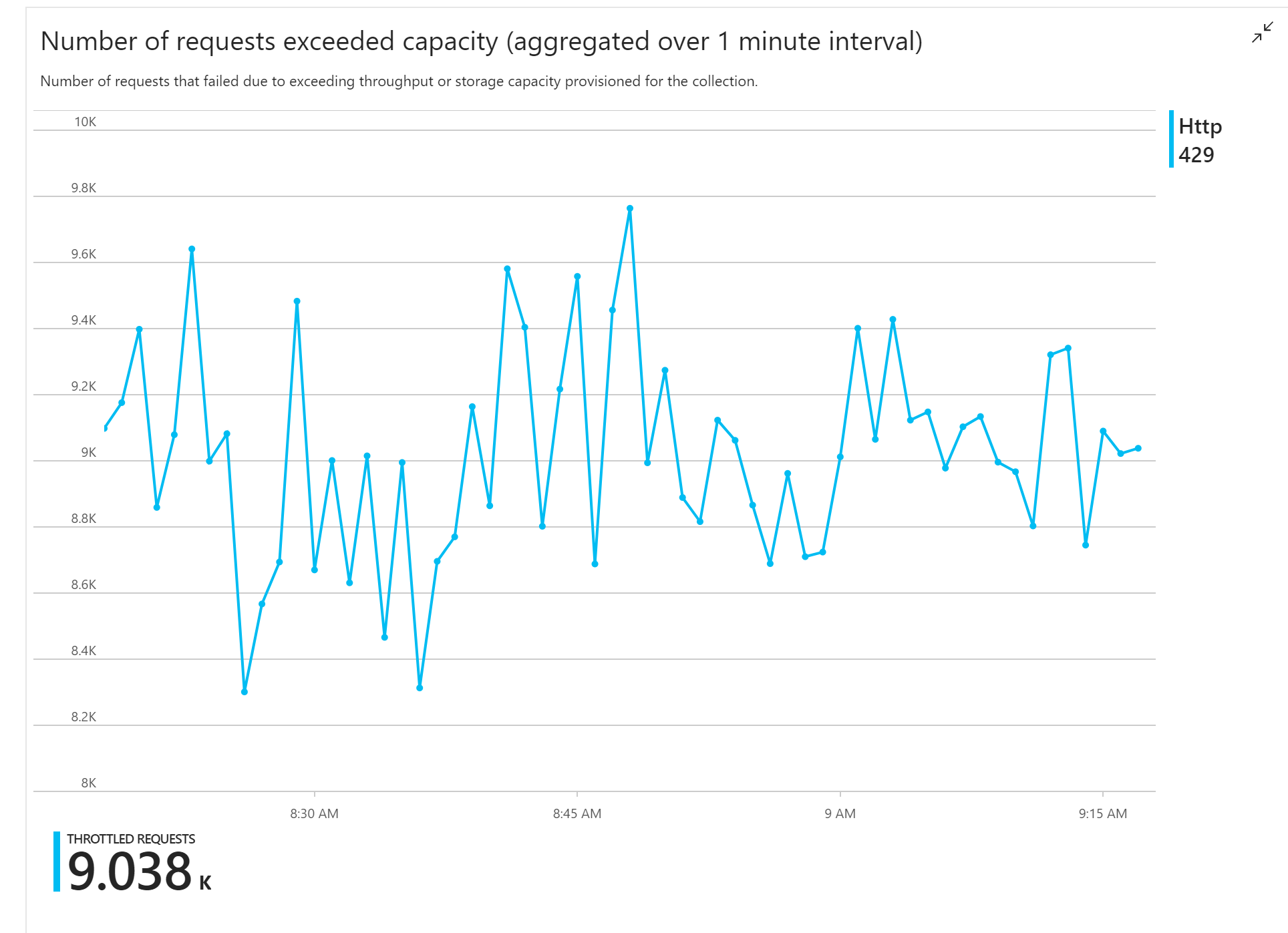
Als reactie heeft het team Azure Cosmos DB geschaald door het aantal RU's te verhogen dat voor de verzameling is toegewezen, maar de fouten bleven zich voordoen. Dit leek vreemd, omdat de berekening van de back-of-envelope aantoonde dat Azure Cosmos DB geen probleem zou moeten hebben met het bijhouden van het volume van schrijfaanvragen.
Later die dag heeft een van de ontwikkelaars het volgende e-mailbericht naar het team verzonden:
Ik heb naar Azure Cosmos DB gekeken voor het warme pad. Er is één ding dat ik niet begrijp. De partitiesleutel is deliveryId, maar deliveryId wordt niet verzonden naar Azure Cosmos DB. Mis ik iets?
Dat was de aanwijzing. Als u de heatmap van de partitie bekijkt, bleek dat alle documenten op dezelfde partitie terechtkwamen.
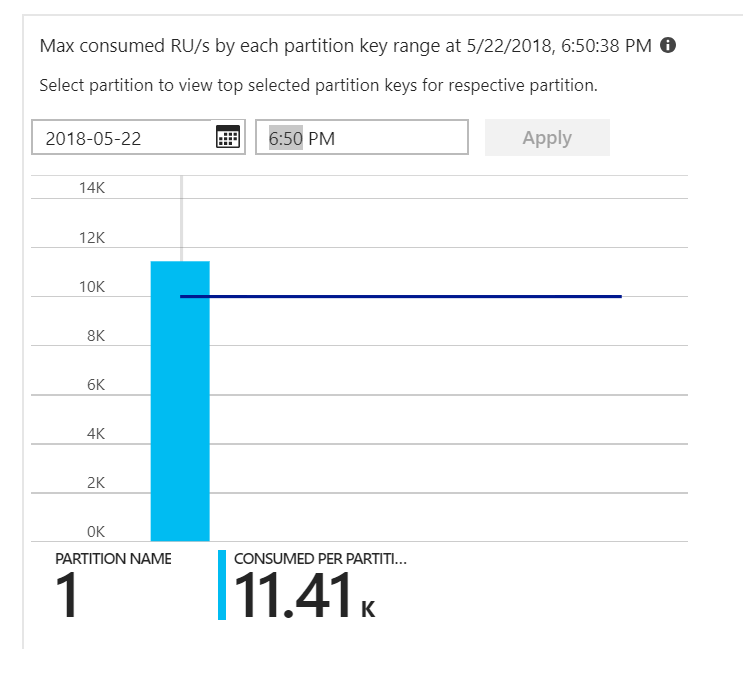
Wat u in de heatmap wilt zien, is een gelijkmatige verdeling over alle partities. In dit geval, omdat elk document naar dezelfde partitie werd geschreven, hielp het toevoegen van RU's niet. Het probleem bleek een fout in de code te zijn. Hoewel de Azure Cosmos DB-verzameling een partitiesleutel had, heeft de Azure-functie de partitiesleutel niet daadwerkelijk in het document opgenomen. Zie De doorvoerdistributie over partities bepalen voor meer informatie over de partitie-heatmap.
Test 2: Partitioneringsprobleem oplossen
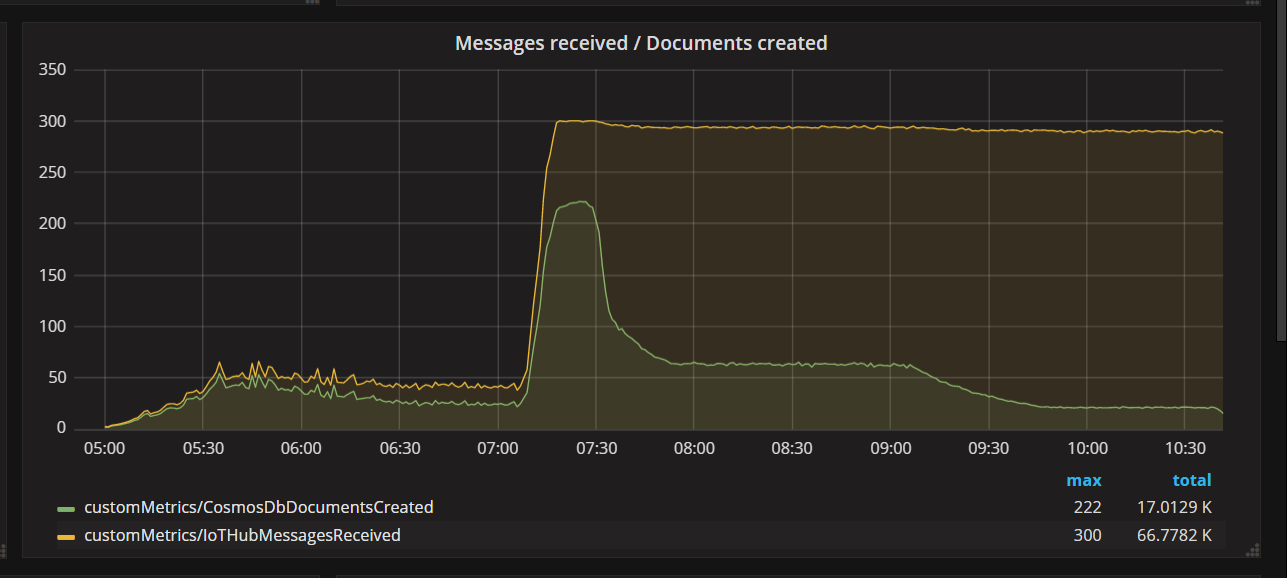
Toen het team een codeoplossing heeft geïmplementeerd en de test opnieuw heeft uitgevoerd, is de beperking van Azure Cosmos DB gestopt. Een tijdje zag alles er goed uit. Maar bij een bepaalde belasting liet telemetrie zien dat de functie minder documenten schreef dan nodig was. In de volgende grafiek ziet u berichten die worden ontvangen van IoT Hub versus documenten die naar Azure Cosmos DB zijn geschreven. De gele lijn is het aantal ontvangen berichten per batch en de groene lijn is het aantal documenten dat per batch is geschreven. Deze moeten proportioneel zijn. In plaats daarvan neemt het aantal databaseschrijfbewerkingen per batch aanzienlijk af rond ongeveer 07:30.
In de volgende grafiek ziet u de latentie tussen wanneer een bericht op IoT Hub van een apparaat binnenkomt en wanneer de functie-app dat bericht verwerkt. U kunt zien dat op hetzelfde moment de late tijd aanzienlijk piekt, afneemt en de dalingen afneemt.
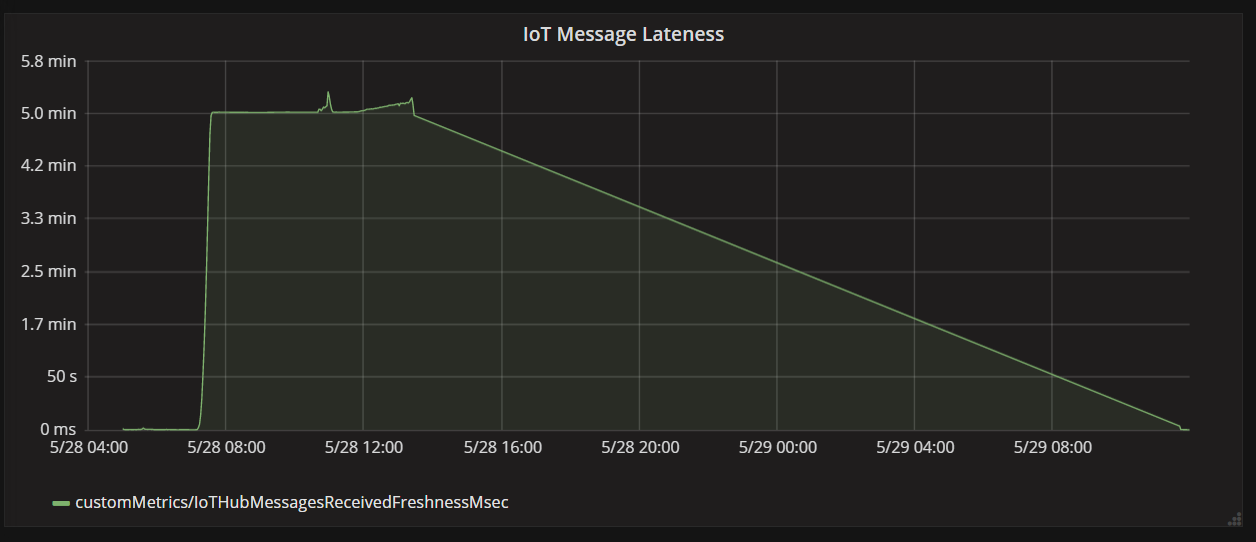
De reden waarom de waarde piekt na 5 minuten en vervolgens daalt naar nul, is omdat de functie-app berichten verwijdert die meer dan 5 minuten te laat zijn:
foreach (var message in messages)
{
// Drop stale messages,
if (message.EnqueuedTimeUtc < cutoffTime)
{
log.Info($"Dropping late message batch. Enqueued time = {message.EnqueuedTimeUtc}, Cutoff = {cutoffTime}");
droppedMessages++;
continue;
}
}
U kunt dit zien in de grafiek wanneer de metrische waarde voor te laatheid weer terugvalt naar nul. In de tussentijd zijn er gegevens verloren gegaan, omdat de functie berichten weggooit.
Wat was er aan de hand? Voor deze specifieke belastingtest had de Azure Cosmos DB-verzameling RU's om over te blijven, dus het knelpunt lag niet bij de database. Het probleem lag in plaats daarvan in de lus voor berichtverwerking. Eenvoudig gezegd, de functie schreef documenten niet snel genoeg om het binnenkomende aantal berichten bij te houden. Na verloop van tijd liep het steeds verder achter.
Test 3: Parallelle schrijfbewerkingen
Als de tijd voor het verwerken van een bericht het knelpunt is, is een oplossing om meer berichten parallel te verwerken. In dit scenario geldt het volgende:
- Verhoog het aantal IoT Hub partities. Elke IoT Hub partitie krijgt één functie-exemplaar tegelijk toegewezen, dus we verwachten dat de doorvoer lineair wordt geschaald met het aantal partities.
- Parallelliseer de documentschrijfbewerkingen binnen de functie.
Om de tweede optie te verkennen, heeft het team de functie aangepast om parallelle schrijfbewerkingen te ondersteunen. De oorspronkelijke versie van de functie heeft de Azure Cosmos DB-uitvoerbinding gebruikt. De geoptimaliseerde versie roept de Azure Cosmos DB-client rechtstreeks aan en voert de schrijfbewerkingen parallel uit met Behulp van Task.WhenAll:
private async Task<(long documentsUpserted,
long droppedMessages,
long cosmosDbTotalMilliseconds)>
ProcessMessagesFromEventHub(
int taskCount,
int numberOfDocumentsToUpsertPerTask,
EventData[] messages,
TraceWriter log)
{
DateTimeOffset cutoffTime = DateTimeOffset.UtcNow.AddMinutes(-5);
var tasks = new List<Task>();
for (var i = 0; i < taskCount; i++)
{
var docsToUpsert = messages
.Skip(i * numberOfDocumentsToUpsertPerTask)
.Take(numberOfDocumentsToUpsertPerTask);
// client will attempt to create connections to the data
// nodes on Azure Cosmos DB clusters on a range of port numbers
tasks.Add(UpsertDocuments(i, docsToUpsert, cutoffTime, log));
}
await Task.WhenAll(tasks);
return (this.UpsertedDocuments,
this.DroppedMessages,
this.CosmosDbTotalMilliseconds);
}
Houd er rekening mee dat racevoorwaarden mogelijk zijn met benadering. Stel dat twee berichten van dezelfde drone toevallig in dezelfde batch berichten binnenkomen. Door ze parallel te schrijven, kan het latere bericht worden overschreven door het eerdere bericht. Voor dit specifieke scenario kan de toepassing tolereren dat er af en toe een bericht verloren gaat. Drones verzenden elke vijf seconden nieuwe positiegegevens, zodat de gegevens in Azure Cosmos DB voortdurend worden bijgewerkt. In andere scenario's kan het echter belangrijk zijn om berichten strikt op volgorde te verwerken.
Na het implementeren van deze codewijziging kon de toepassing meer dan 2500 aanvragen per seconde opnemen met behulp van een IoT Hub met 32 partities.
Overwegingen aan de clientzijde
De algehele clientervaring kan worden verminderd door agressieve parallelle uitvoering aan de serverzijde. Overweeg het gebruik van azure Cosmos DB bulkexecutorbibliotheek (niet weergegeven in deze implementatie), waardoor de rekenresources aan de clientzijde aanzienlijk worden verminderd die nodig zijn om de doorvoer te verzadigen die aan een Azure Cosmos DB-container is toegewezen. Een toepassing met één thread die gegevens schrijft met behulp van de API voor bulkimport, bereikt bijna tien keer meer schrijfdoorvoer in vergelijking met een toepassing met meerdere threads die gegevens parallel schrijft terwijl de CPU van de clientcomputer wordt verzadigd.
Samenvatting
Voor dit scenario zijn de volgende knelpunten geïdentificeerd:
- Dynamische schrijfpartitie, vanwege een ontbrekende partitiesleutelwaarde in de documenten die worden geschreven.
- Het schrijven van documenten in serieel per IoT Hub partitie.
Om deze problemen vast te stellen, is het ontwikkelteam gebaseerd op de volgende metrische gegevens:
- Beperkte aanvragen in Azure Cosmos DB.
- Partitie-heatmap: maximaal verbruikte RU's per partitie.
- Ontvangen berichten versus gemaakte documenten.
- Te laat bericht.