Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
SQL Managed Instance ingeschakeld door Azure Arc wordt geïmplementeerd in Kubernetes als een containertoepassing. Er wordt gebruikgemaakt van Kubernetes-constructies, zoals stateful sets en permanente opslag, om ingebouwde mogelijkheden te bieden:
- Gezondheidsmonitoring
- Foutdetectie
- Automatische failover om de servicestatus te behouden.
Voor een grotere betrouwbaarheid kunt u ook SQL Managed Instance configureren die door Azure Arc is ingeschakeld voor implementatie met extra replica's in een configuratie met hoge beschikbaarheid. De gegevenscontroller voor Arc-gegevensservices beheert:
- Controleren
- Foutdetectie
- Automatische failover
Gegevensservice met Arc biedt deze service zonder tussenkomst van de gebruiker. De dienst:
- De beschikbaarheidsgroep instellen
- Hiermee configureert u eindpunten voor databasespiegeling
- Databases toevoegen aan de beschikbaarheidsgroep
- Coördineert failover en upgrade.
In dit document worden beide typen hoge beschikbaarheid verkend.
SQL Managed Instance ingeschakeld door Azure Arc biedt verschillende niveaus van hoge beschikbaarheid, afhankelijk van of het beheerde SQL-exemplaar is geïmplementeerd als een servicelaag voor algemeen gebruik of Bedrijfskritiek servicelaag.
Hoge beschikbaarheid in de servicelaag Algemeen gebruik
In de servicelaag Algemeen gebruik is er slechts één replica beschikbaar en wordt de hoge beschikbaarheid bereikt via Kubernetes-indeling. Als bijvoorbeeld een pod of knooppunt met de containerimage van het beheerde exemplaar crasht, probeert Kubernetes een andere pod of knooppunt op te zetten en te koppelen aan dezelfde permanente opslag. Gedurende deze tijd is het beheerde SQL-exemplaar niet beschikbaar voor de toepassingen. Toepassingen moeten opnieuw verbinding maken en de transactie opnieuw proberen wanneer de nieuwe pod actief is. Als load balancer het servicetype wordt gebruikt, kunnen toepassingen opnieuw verbinding maken met hetzelfde primaire eindpunt en wordt de verbinding door Kubernetes omgeleid naar de nieuwe primaire. Als het servicetype is nodeport , moeten de toepassingen opnieuw verbinding maken met het nieuwe IP-adres.
Ingebouwde hoge beschikbaarheid controleren
Als u de ingebouwde hoge beschikbaarheid van Kubernetes wilt controleren, kunt u het volgende doen:
- Verwijder de pod van een bestaand beheerd exemplaar
- Controleren of Kubernetes herstelt na deze actie
Tijdens het herstellen bootstrapt Kubernetes een andere pod en koppelt de permanente opslag.
Vereisten
- Voor een Kubernetes-cluster is gedeelde, externe opslag vereist
- Een met SQL beheerd exemplaar dat door Azure Arc is geïmplementeerd met één replica (standaard)
Bekijk de pods.
kubectl get pods -n <namespace of data controller>Verwijder de pod van de beheerde instantie.
kubectl delete pod <name of managed instance>-0 -n <namespace of data controller>Bijvoorbeeld
user@pc:/# kubectl delete pod sql1-0 -n arc pod "sql1-0" deletedBekijk de pods om te controleren of het beheerde exemplaar wordt hersteld.
kubectl get pods -n <namespace of data controller>Voorbeeld:
user@pc:/# kubectl get pods -n arc NAME READY STATUS RESTARTS AGE sql1-0 2/3 Running 0 22s
Nadat alle containers in de pod zijn hersteld, kunt u verbinding maken met het beheerde exemplaar.
Hoge beschikbaarheid in Bedrijfskritiek servicelaag
Binnen de Bedrijfskritische servicelaag biedt SQL Managed Instance voor Azure Arc, naast wat systeemeigen wordt geleverd door Kubernetes-orkestratie, een geïntegreerde beschikbaarheidsgroep. De ingesloten beschikbaarheidsgroep is gebouwd op SQL Server AlwaysOn-technologie. Het biedt hogere beschikbaarheidsniveaus. SQL Managed Instance die door Azure Arc is ingeschakeld en met de servicelaag Bedrijfskritisch is geïmplementeerd, kan worden ingezet met 2 of 3 replica's. Deze replica's worden altijd gesynchroniseerd met elkaar.
Met ingesloten beschikbaarheidsgroepen zijn eventuele crashes van pods of fouten van knooppunten transparant voor de applicatie. De ingesloten beschikbaarheidsgroep biedt ten minste één andere pod die alle gegevens van de primaire pod bevat en gereed is om verbindingen op te nemen.
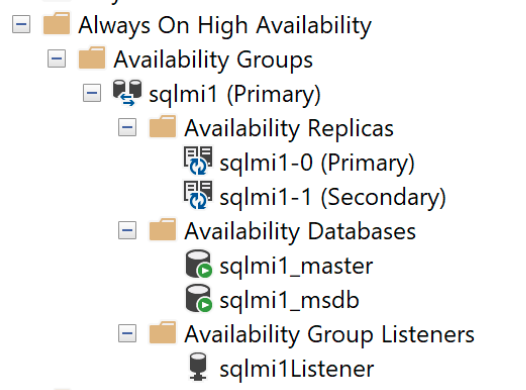
Ingesloten beschikbaarheidsgroepen
Een beschikbaarheidsgroep verbindt een of meer gebruikersdatabases in een logische groep, zodat wanneer er een failover plaatsvindt, de hele groep databases een failover naar de secundaire replica uitvoert als één eenheid. Een beschikbaarheidsgroep repliceert alleen gegevens in de gebruikersdatabases, maar niet de gegevens in systeemdatabases, zoals aanmeldingen, machtigingen of agenttaken. Een ingesloten beschikbaarheidsgroep bevat metagegevens van systeemdatabases zoals msdb en master databases. Wanneer aanmeldingen worden gemaakt of gewijzigd in de primaire replica, worden ze automatisch ook gemaakt in de secundaire replica's. Wanneer een agenttaak wordt gemaakt of gewijzigd in de primaire replica, ontvangen de secundaire replica's deze wijzigingen ook.
Sql Managed Instance ingeschakeld door Azure Arc maakt gebruik van dit concept van een ingesloten beschikbaarheidsgroep en voegt kubernetes-operator toe, zodat deze op schaal kunnen worden geïmplementeerd en beheerd.
Mogelijkheden die beschikbaarheidsgroepen bevatten, maken het volgende mogelijk:
Wanneer deze wordt geïmplementeerd met meerdere replica's, wordt één beschikbaarheidsgroep met dezelfde naam gemaakt als het met Arc ingeschakelde SQL beheerde exemplaar. Standaard heeft een ingesloten beschikbaarheidsgroep drie replica's, waaronder een primaire. Alle CRUD-bewerkingen voor de beschikbaarheidsgroep worden intern beheerd, inclusief het maken van de beschikbaarheidsgroep of het toevoegen van replica's aan de gemaakte beschikbaarheidsgroep. U kunt geen extra beschikbaarheidsgroepen maken in een instantie.
Alle databases worden automatisch toegevoegd aan de beschikbaarheidsgroep, inclusief alle gebruikers- en systeemdatabases, zoals
masterenmsdb. Deze functie biedt een weergave van een enkel systeem voor de replica's van de beschikbaarheidsgroep. Let op zowelcontainedag_masteralscontainedag_msdbdatabases als u rechtstreeks verbinding maakt met de instantie. Decontainedag_*databases vertegenwoordigen demasterenmsdbbinnen de beschikbaarheidsgroep.Een extern eindpunt wordt automatisch ingericht voor het maken van verbinding met databases binnen de beschikbaarheidsgroep. Dit eindpunt
<managed_instance_name>-external-svcspeelt de rol van de listener van de beschikbaarheidsgroep.
SQL Managed Instance implementeren die is ingeschakeld door Azure Arc met meerdere replica's met behulp van Azure Portal
Ga vanuit Azure Portal naar de pagina SQL Managed Instance maken waarvoor Azure Arc is ingeschakeld:
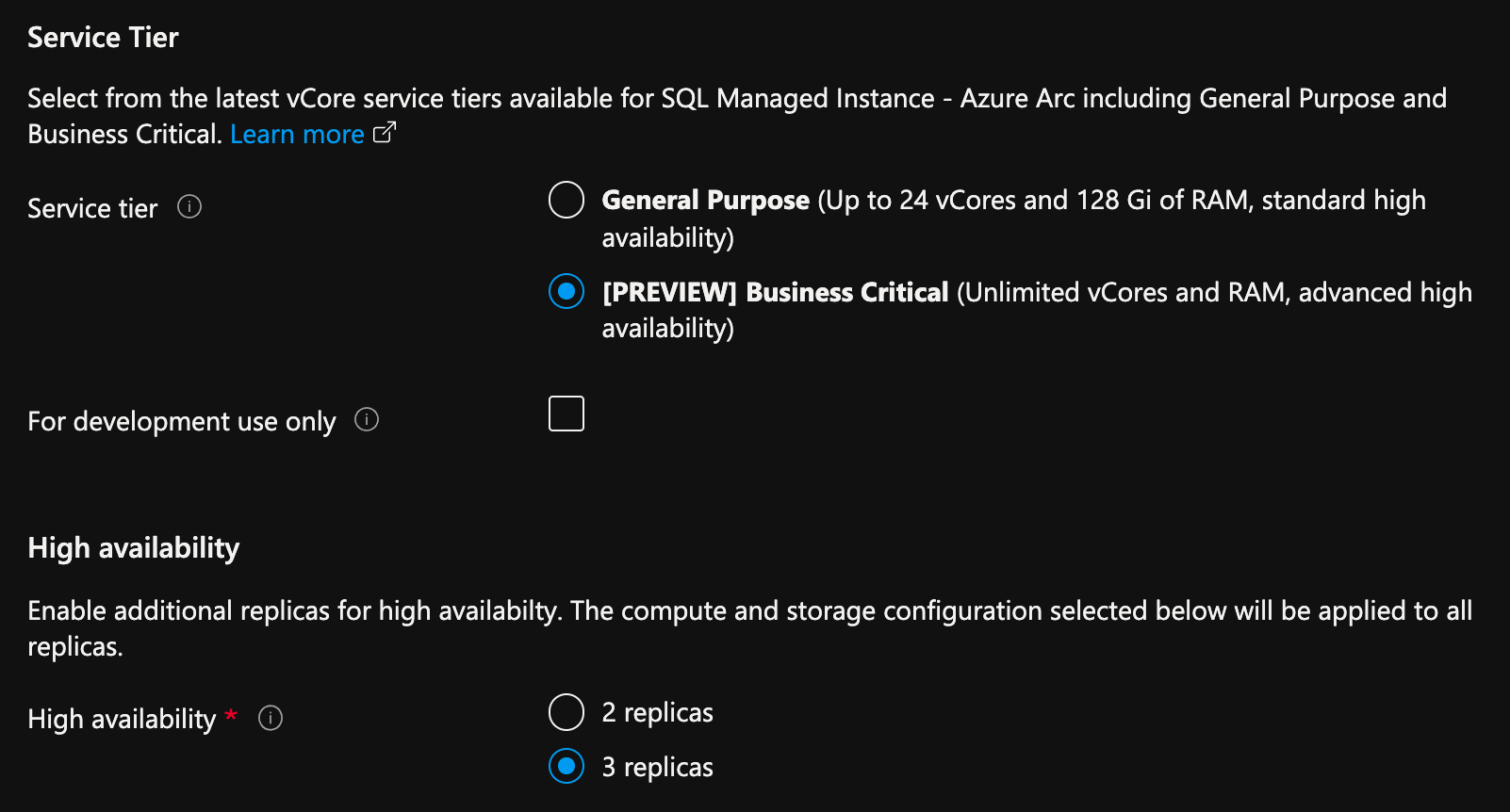
- Selecteer Compute + Storage configureren onder Compute + Storage. In de portal worden geavanceerde instellingen weergegeven.
- Selecteer onder Servicelaag Bedrijfskritiek.
- Controleer 'Alleen voor ontwikkelingsgebruik' als u deze gebruikt voor ontwikkelingsdoeleinden.
- Onder Hoge beschikbaarheid selecteert u 2 replica's of 3 replica's.
Implementeren met meerdere replica's met behulp van Azure CLI
Wanneer een met SQL beheerd exemplaar dat door Azure Arc is ingeschakeld, wordt geïmplementeerd in Bedrijfskritiek servicelaag, maakt de implementatie meerdere replica's. De installatie en configuratie van beperkte beschikbaarheidsgroepen tussen deze instanties worden automatisch uitgevoerd tijdens de provisioning.
Met de volgende opdracht maakt u bijvoorbeeld een beheerd exemplaar met 3 replica's.
Indirect verbonden modus:
az sql mi-arc create -n <instanceName> --k8s-namespace <namespace> --use-k8s --tier <tier> --replicas <number of replicas>
Voorbeeld:
az sql mi-arc create -n sqldemo --k8s-namespace my-namespace --use-k8s --tier BusinessCritical --replicas 3
Rechtstreeks verbonden modus:
az sql mi-arc create --name <name> --resource-group <group> --location <Azure location> –subscription <subscription> --custom-location <custom-location> --tier <tier> --replicas <number of replicas>
Voorbeeld:
az sql mi-arc create --name sqldemo --resource-group rg --location uswest2 –subscription xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --custom-location private-location --tier BusinessCritical --replcias 3
Standaard worden alle replica's geconfigureerd in de synchrone modus. Dit betekent dat updates op het primaire exemplaar synchroon worden gerepliceerd naar elk van de secundaire exemplaren.
Hoge beschikbaarheidsstatus weergeven en bewaken
Zodra de implementatie is voltooid, maakt u vanuit SQL Server Management Studio verbinding met het primaire eindpunt.
Controleer en haal het eindpunt van de primaire replica op en maak er verbinding mee vanuit SQL Server Management Studio.
Als het SQL-exemplaar bijvoorbeeld is geïmplementeerd met behulp van service-type=loadbalancer, voert u de onderstaande opdracht uit om het eindpunt op te halen waarmee verbinding moet worden gemaakt:
az sql mi-arc list --k8s-namespace my-namespace --use-k8s
of
kubectl get sqlmi -A
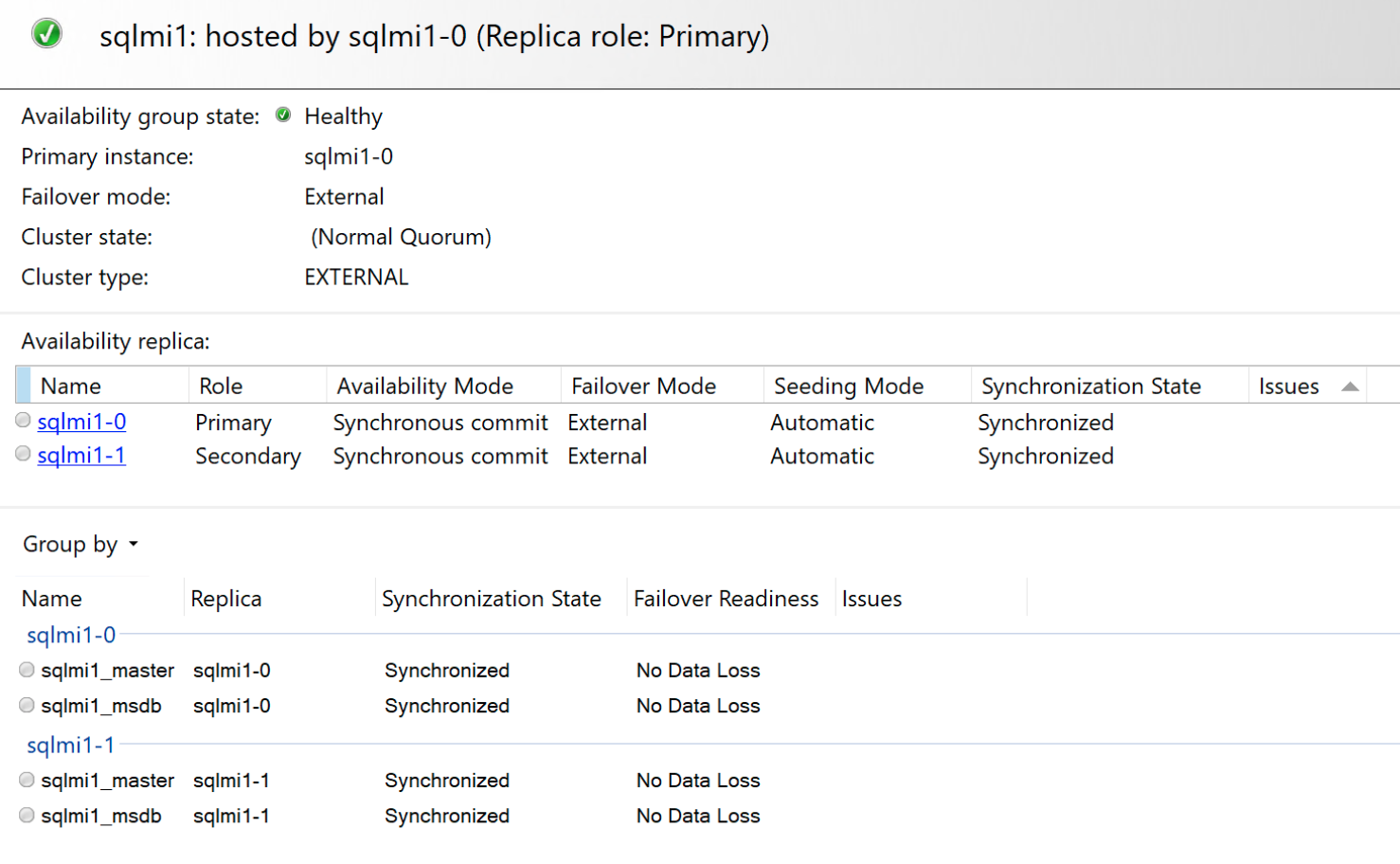
Verkrijg de primaire en secundaire eindpunten en de AG-status.
Gebruik de kubectl describe sqlmi of az sql mi-arc show opdrachten om de primaire en secundaire eindpunten en de status van hoge beschikbaarheid weer te geven.
Voorbeeld:
kubectl describe sqlmi sqldemo -n my-namespace
of
az sql mi-arc show --name sqldemo --k8s-namespace my-namespace --use-k8s
Voorbeelduitvoer; uw uitvoer zal anders zijn:
"status": {
"endpoints": {...
"mirroring": "10.15.100.150:5022",
"primary": "10.15.100.150,1433",
"secondary": "10.15.100.156,1433"
},
"highAvailability": {
"healthState": "OK",
"mirroringCertificate": "-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----"
},
"observedGeneration": 1,
"readyReplicas": "2/2",
"state": "Ready"
}
U kunt verbinding maken met het primaire eindpunt met SQL Server Management Studio en DMV's controleren als:
SELECT * FROM sys.dm_hadr_availability_replica_states
En het dashboard voor beperkte beschikbaarheid:
Failoverscenario's
In tegenstelling tot SQL Server AlwaysOn-beschikbaarheidsgroepen is de ingesloten beschikbaarheidsgroep een beheerde oplossing voor hoge beschikbaarheid. Daarom zijn de failovermodi beperkt in vergelijking met de typische modi die beschikbaar zijn in SQL Server AlwaysOn-beschikbaarheidsgroepen.
Implementeer de dienst Business Critical voor beheerde SQL-exemplaren in een configuratie met twee replica's of een configuratie met drie replica's. De gevolgen van fouten en de daaropvolgende herstelbaarheid verschillen bij elke configuratie. Een exemplaar van drie replica's biedt een hoger beschikbaarheids- en herstelniveau dan een exemplaar van twee replica's.
In een configuratie van twee replica's wordt de secundaire replica automatisch gepromoveerd naar de primaire replica als beide statussen SYNCHRONIZEDvan het knooppunt niet meer beschikbaar zijn. Wanneer de mislukte replica beschikbaar wordt, wordt deze bijgewerkt met alle wijzigingen die in behandeling zijn. Als er verbindingsproblemen zijn tussen de replica's, kan de primaire replica geen transacties doorvoeren omdat elke transactie moet worden doorgevoerd op beide replica's voordat een succes wordt geretourneerd op de primaire replica.
In een configuratie met drie replica's moet een transactie ten minste 2 van de drie replica's doorvoeren voordat een geslaagd bericht naar de toepassing wordt geretourneerd. In het geval van een fout wordt een van de secundaire bestanden automatisch gepromoveerd naar primair, terwijl Kubernetes probeert de mislukte replica te herstellen. Wanneer de replica beschikbaar wordt, wordt deze automatisch gekoppeld aan de opgenomen beschikbaarheidsgroep en worden achterstallige wijzigingen gesynchroniseerd. Als er verbindingsproblemen zijn tussen de replica's en meer dan 2 replica's niet synchroon zijn, worden er geen transacties doorgevoerd in de primaire replica.
Notitie
Het wordt aanbevolen om een Bedrijfskritiek SQL Managed Instance te implementeren in een configuratie met drie replica's dan een twee replicaconfiguratie om bijna nul gegevensverlies te bereiken.
Voer voor een geplande gebeurtenis de volgende opdracht uit om een failover van de primaire replica naar een van de secundaire replica's uit te voeren:
Als u verbinding maakt met de primaire server, kunt u de volgende T-SQL gebruiken om een failover van het SQL-exemplaar uit te voeren naar een van de secundaire databases:
ALTER AVAILABILITY GROUP current SET (ROLE = SECONDARY);
Als u verbinding maakt met de secundaire, kunt u de volgende T-SQL gebruiken om de gewenste secundaire naar primaire replica te promoveren.
ALTER AVAILABILITY GROUP current SET (ROLE = PRIMARY);
Primaire voorkeurs replica
U kunt ook als volgt een specifieke replica instellen als de primaire replica met behulp van AZ CLI:
az sql mi-arc update --name <sqlinstance name> --k8s-namespace <namespace> --use-k8s --preferred-primary-replica <replica>
Voorbeeld:
az sql mi-arc update --name sqldemo --k8s-namespace my-namespace --use-k8s --preferred-primary-replica sqldemo-3
Notitie
Kubernetes probeert de voorkeursreplica in te stellen, maar dit is niet gegarandeerd.
Een database herstellen naar een exemplaar met meerdere replica's
Aanvullende stappen zijn vereist voor het herstellen van een database in een beschikbaarheidsgroep. In de volgende stappen ziet u hoe u een database herstelt in een beheerd exemplaar en deze toevoegt aan een beschikbaarheidsgroep.
Stel het externe eindpunt van het primair exemplaar bloot door een nieuwe Kubernetes-service te maken.
Bepaal de pod die als host fungeert voor de primaire replica. Maak verbinding met het beheerde exemplaar en voer het volgende uit:
SELECT @@SERVERNAMEDe query retourneert de pod die als host fungeert voor de primaire replica.
Maak de Kubernetes-service voor de primaire instantie door de volgende opdracht uit te voeren als uw Kubernetes-cluster gebruik maakt van
NodePort-diensten. Vervang<podName>door de naam van de server die in de vorige stap is geretourneerd,<serviceName>door de voorkeursnaam voor de Kubernetes-service die is gemaakt.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortVoer voor een LoadBalancer-service dezelfde opdracht uit, behalve dat het type service dat is gemaakt, is
LoadBalancer. Voorbeeld:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerHier volgt een voorbeeld van deze opdracht die wordt uitgevoerd op Azure Kubernetes Service, waarbij de pod die als host fungeert voor de primaire is
sql2-0:kubectl -n arc-cluster expose pod sql2-0 --port=1533 --name=sql2-0-p --type=LoadBalancerHaal het IP-adres op van de Kubernetes-service die is gemaakt:
kubectl get services -n <namespaceName>Herstel de database naar het eindpunt van de primaire instantie.
Voeg het back-upbestand van de database toe aan de primaire exemplaarcontainer.
kubectl cp <source file location> <pod name>:var/opt/mssql/data/<file name> -c <serviceName> -n <namespaceName>Voorbeeld
kubectl cp /home/WideWorldImporters-Full.bak sql2-1:var/opt/mssql/data/WideWorldImporters-Full.bak -c arc-sqlmi -n arcHerstel het back-upbestand van de database door de onderstaande opdracht uit te voeren.
RESTORE DATABASE test FROM DISK = '/var/opt/mssql/data/<file name>.bak' WITH MOVE '<database name>' to '/var/opt/mssql/data/<file name>.mdf' ,MOVE '<database name>' to '/var/opt/mssql/data/<file name>_log.ldf' ,RECOVERY, REPLACE, STATS = 5; GOVoorbeeld
RESTORE Database WideWorldImporters FROM DISK = '/var/opt/mssql/data/WideWorldImporters-Full.BAK' WITH MOVE 'WWI_Primary' TO '/var/opt/mssql/data/WideWorldImporters.mdf', MOVE 'WWI_UserData' TO '/var/opt/mssql/data/WideWorldImporters_UserData.ndf', MOVE 'WWI_Log' TO '/var/opt/mssql/data/WideWorldImporters.ldf', MOVE 'WWI_InMemory_Data_1' TO '/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1', RECOVERY, REPLACE, STATS = 5; GOVoeg de database toe aan de beschikbaarheidsgroep.
Om de database toe te voegen aan de beschikbaarheidsgroep, moet deze worden uitgevoerd in de modus volledig herstel en moet er een logboekback-up worden gemaakt. Voer de onderstaande TSQL-instructies uit om de herstelde database toe te voegen aan de beschikbaarheidsgroep.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>In het volgende voorbeeld wordt een database met de naam
WideWorldImporterstoegevoegd die is hersteld op het exemplaar:ALTER DATABASE WideWorldImporters SET RECOVERY FULL; BACKUP DATABASE WideWorldImporters TO DISK='/var/opt/mssql/data/WideWorldImporters.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE WideWorldImporters
Belangrijk
Als best practice moet u de Hierboven gemaakte Kubernetes-service verwijderen door deze opdracht uit te voeren:
kubectl delete svc sql2-0-p -n arc
Beperkingen
SQL Managed Instance ingeschakeld door Azure Arc-beschikbaarheidsgroepen heeft dezelfde beperkingen als beschikbaarheidsgroepen voor big dataclusters. Zie Sql Server Big Data Cluster implementeren met hoge beschikbaarheid voor meer informatie.
Gerelateerde inhoud
Meer informatie over functies en mogelijkheden van SQL Managed Instance ingeschakeld door Azure Arc