Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Microsoft streeft ernaar om ervoor te zorgen dat Azure-services altijd beschikbaar zijn. Er kunnen echter niet-geplande servicestoringen optreden. Als uw toepassing tolerantie vereist, raadt Microsoft u aan uw app te configureren voor geo-redundantie. Daarnaast moeten klanten een noodherstelplan hebben voor het afhandelen van een regionale servicestoring. Een belangrijk onderdeel van een noodherstelplan is het voorbereiden van een failover naar de secundaire replica van uw app en opslag in het geval dat de primaire replica niet meer beschikbaar is.
In Durable Functions wordt alle status standaard opgeslagen in Azure Storage. Een taakhub is een logische container voor Azure Storage-resources die worden gebruikt voor indelingen en entiteiten. Orchestrator-, activiteits- en entiteitsfuncties kunnen alleen met elkaar communiceren wanneer ze deel uitmaken van dezelfde taakhub. Dit document verwijst naar taakhubs bij het beschrijven van scenario's om deze Azure Storage-resources maximaal beschikbaar te houden.
Notitie
In de richtlijnen in dit artikel wordt ervan uitgegaan dat u de standaard Azure Storage-provider gebruikt voor het opslaan van Durable Functions runtimestatus. Het is echter mogelijk om alternatieve opslagproviders te configureren die de status ergens anders opslaan, zoals een SQL Server-database. Verschillende strategieën voor herstel na noodgevallen en geo-distributie kunnen vereist zijn voor de alternatieve opslagproviders. Zie de documentatie over Durable Functions opslagproviders voor meer informatie over de alternatieve opslagproviders.
Indelingen en entiteiten kunnen worden geactiveerd met behulp van clientfuncties die zelf worden geactiveerd via HTTP of een van de andere ondersteunde Azure Functions triggertypen. Ze kunnen ook worden geactiveerd met behulp van ingebouwde HTTP-API's. Ter vereenvoudiging wordt in dit artikel aandacht besteed aan scenario's met betrekking tot Azure Storage en OP HTTP gebaseerde functietriggers, en opties om de beschikbaarheid te verhogen en downtime tijdens noodherstelactiviteiten te minimaliseren. Andere triggertypen, zoals Service Bus- of Azure Cosmos DB-triggers, worden niet expliciet behandeld.
De volgende scenario's zijn gebaseerd op Active-Passive configuraties, omdat ze worden geleid door het gebruik van Azure Storage. Dit patroon bestaat uit het implementeren van een back-upfunctie-app (passieve) in een andere regio. Traffic Manager controleert de primaire (actieve) functie-app op HTTP-beschikbaarheid. Er wordt een failover uitgevoerd naar de back-upfunctie-app als de primaire functie mislukt. Zie De Methode prioriteit Traffic-Routing van Azure Traffic Manager voor meer informatie.
Notitie
- De voorgestelde Active-Passive-configuratie zorgt ervoor dat een client altijd nieuwe indelingen via HTTP kan activeren. Als gevolg van twee functie-apps die dezelfde taakhub in de opslag delen, worden sommige opslagtransacties op de achtergrond tussen beide echter gedistribueerd. Voor deze configuratie worden dus extra kosten voor uitgaand verkeer in rekening gebracht voor de secundaire functie-app.
- Het onderliggende opslagaccount en de taakhub worden gemaakt in de primaire regio en worden gedeeld door beide functie-apps.
- Alle functie-apps die redundant zijn geïmplementeerd, moeten dezelfde functietoegangssleutels delen in het geval dat ze via HTTP worden geactiveerd. De Functions Runtime maakt een beheer-API beschikbaar waarmee gebruikers via programmacode functiesleutels kunnen toevoegen, verwijderen en bijwerken. Sleutelbeheer is ook mogelijk met behulp van Azure Resource Manager-API's.
Scenario 1: berekening met gelijke taakverdeling met gedeelde opslag
Als de rekeninfrastructuur in Azure uitvalt, is de functie-app mogelijk niet meer beschikbaar. Om de kans op dergelijke downtime te minimaliseren, worden in dit scenario twee functie-apps gebruikt die zijn geïmplementeerd in verschillende regio's. Traffic Manager is geconfigureerd om problemen in de primaire functie-app te detecteren en verkeer automatisch om te leiden naar de functie-app in de secundaire regio. Deze functie-app deelt hetzelfde Azure Storage-account en dezelfde taakhub. Daarom gaat de status van de functie-apps niet verloren en kan het werk normaal worden hervat. Zodra de status is hersteld in de primaire regio, start Azure Traffic Manager automatisch met het routeren van aanvragen naar die functie-app.
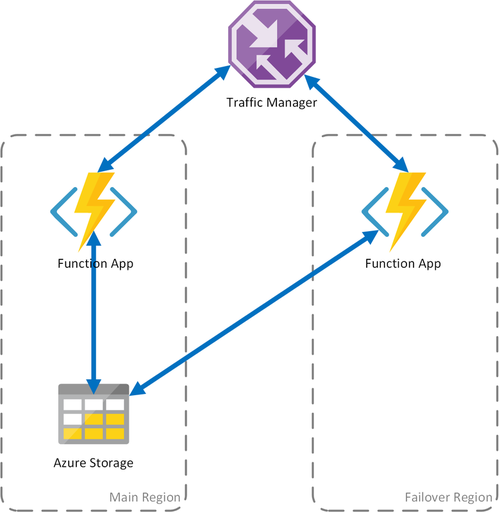
Er zijn verschillende voordelen bij het gebruik van dit implementatiescenario:
- Als de rekeninfrastructuur uitvalt, kan het werk in de failoverregio worden hervat zonder gegevensverlies.
- Traffic Manager zorgt automatisch voor de automatische failover naar de functie-app met een goede status.
- Traffic Manager brengt automatisch verkeer naar de primaire functie-app tot stand nadat de storing is gecorrigeerd.
Met behulp van dit scenario kunt u echter het volgende overwegen:
- Als de functie-app wordt geïmplementeerd met behulp van een toegewezen App Service-plan, verhoogt het repliceren van de rekeninfrastructuur in het failover-datacenter de kosten.
- Dit scenario heeft betrekking op storingen in de rekeninfrastructuur, maar het opslagaccount blijft het single point of failure voor de functie-app. Als er een opslagstoring optreedt, ondervindt de toepassing downtime.
- Als er een failover voor de functie-app wordt uitgevoerd, treedt de latentie op omdat deze toegang krijgt tot het opslagaccount in verschillende regio's.
- Toegang tot de opslagservice vanuit een andere regio waar deze zich bevindt, leidt tot hogere kosten vanwege uitgaand netwerkverkeer.
- Dit scenario is afhankelijk van Traffic Manager. Gezien de werking van Traffic Manager, kan het enige tijd duren voordat een clienttoepassing die een Durable Function gebruikt, opnieuw een query moet uitvoeren op het adres van de functie-app vanuit Traffic Manager.
Notitie
Vanaf v2.3.0 van de Durable Functions-extensie kunnen twee functie-apps veilig tegelijkertijd worden uitgevoerd met hetzelfde opslagaccount en dezelfde configuratie van de taakhub. De eerste app die wordt gestart, krijgt een blob-lease op toepassingsniveau die voorkomt dat andere apps berichten stelen uit de wachtrijen van de taakhub. Als deze eerste app niet meer wordt uitgevoerd, verloopt de lease ervan en kan deze worden verkregen door een tweede app, die vervolgens doorgaat met het verwerken van taakhubberichten.
Vóór v2.3.0 verwerken functie-apps die zijn geconfigureerd voor het gebruik van hetzelfde opslagaccount berichten en worden opslagartefacten gelijktijdig bijgewerkt, wat resulteert in veel hogere algemene latenties en uitgaande kosten. Als voor de primaire apps en replica-apps ooit verschillende code is geïmplementeerd, zelfs tijdelijk, kunnen indelingen ook niet correct worden uitgevoerd vanwege inconsistenties in de orchestratorfunctie in de twee apps. Het wordt daarom aanbevolen dat alle apps waarvoor geo-distributie is vereist voor herstel na noodgevallen, v2.3.0 of hoger van de Durable-extensie gebruiken.
Scenario 2: rekenproces met gelijke taakverdeling met regionale opslag
Het voorgaande scenario heeft alleen betrekking op fouten in de rekeninfrastructuur. Als de opslagservice uitvalt, resulteert dit in een storing van de functie-app. Voor een continue werking van de durable functions wordt in dit scenario een lokaal opslagaccount gebruikt in elke regio waarin de functie-apps worden geïmplementeerd.
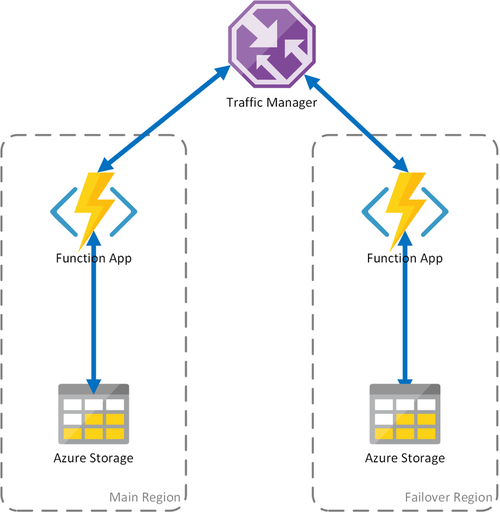
Met deze benadering worden verbeteringen toegevoegd ten tijde van het vorige scenario:
- Als de functie-app uitvalt, zorgt Traffic Manager voor failover-overschakeling naar de secundaire regio. Omdat de functie-app echter afhankelijk is van een eigen opslagaccount, blijven de duurzame functies werken.
- Tijdens een failover is er geen extra latentie in de failoverregio, omdat de functie-app en het opslagaccount een colocatie hebben.
- Fouten in de opslaglaag veroorzaken fouten in de duurzame functies, die op hun beurt een omleiding naar de failoverregio activeren. Aangezien de functie-app en opslag per regio worden geïsoleerd, blijven de duurzame functies werken.
Belangrijke overwegingen voor dit scenario:
- Als de functie-app wordt geïmplementeerd met behulp van een toegewezen App Service-plan, verhoogt het repliceren van de rekeninfrastructuur in het failover-datacenter de kosten.
- De huidige status is geen failover, wat betekent dat bestaande indelingen en entiteiten effectief worden onderbroken en niet beschikbaar zijn totdat de primaire regio is hersteld.
Samenvattend is de afweging tussen het eerste en tweede scenario dat latentie behouden blijft en de kosten voor uitgaand verkeer worden geminimaliseerd, maar dat bestaande indelingen en entiteiten niet beschikbaar zijn tijdens de downtime. Of deze compromissen acceptabel zijn, is afhankelijk van de vereisten van de toepassing.
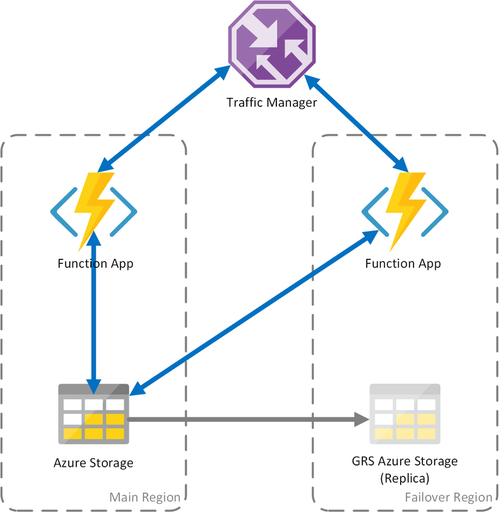
Scenario 3: berekening met gelijke taakverdeling met gedeelde GRS-opslag
Dit scenario is een wijziging ten opzichte van het eerste scenario, het implementeren van een gedeeld opslagaccount. Het belangrijkste verschil is dat het opslagaccount wordt gemaakt met geo-replicatie ingeschakeld. Functioneel gezien biedt dit scenario dezelfde voordelen als scenario 1, maar biedt het extra voordelen voor gegevensherstel:
- Geografisch redundante opslag (GRS) en GRS met leestoegang (RA-GRS) maximaliseren de beschikbaarheid voor uw opslagaccount.
- Als er een regionale storing is in de Opslagservice, kunt u handmatig een failover naar de secundaire replica initiëren. In extreme omstandigheden waarin een regio verloren gaat als gevolg van een groot noodgeval, kan Microsoft een regionale failover initiëren. In dit geval is er geen actie van uw kant vereist.
- Wanneer een failover plaatsvindt, blijft de status van de duurzame functies behouden tot de laatste replicatie van het opslagaccount, die doorgaans om de paar minuten plaatsvindt.
Net als bij de andere scenario's zijn er belangrijke overwegingen:
- Een failover naar de replica kan enige tijd duren. Totdat de failover is voltooid en de DNS-records van Azure Storage zijn bijgewerkt, ondervindt de functie-app een storing.
- Er zijn hogere kosten voor het gebruik van geografisch gerepliceerde opslagaccounts.
- GRS-replicatie kopieert uw gegevens asynchroon. Sommige van de meest recente transacties kunnen verloren gaan vanwege de latentie van het replicatieproces.
Notitie
Zoals beschreven in Scenario 1, wordt het sterk aanbevolen dat functie-apps die met deze strategie worden geïmplementeerd, v2.3.0 of hoger van de Durable Functions-extensie gebruiken.
Zie de documentatie voor herstel na noodgeval en failover van opslagaccounts voor meer informatie.