Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
De Azure SQL-trigger maakt gebruik van sql-functionaliteit voor het bijhouden van wijzigingen om een SQL-tabel te controleren op wijzigingen en een functie te activeren wanneer een rij wordt gemaakt, bijgewerkt of verwijderd. Zie Wijzigingen bijhouden instellen voor configuratiedetails voor gebruik met de Azure SQL-trigger. Zie het overzicht van de SQL-binding voor informatie over het instellen van de Azure SQL-extensie voor Azure Functions.
De beslissingen voor het schalen van Azure SQL-triggers voor de abonnementen Verbruik en Premium worden uitgevoerd via schaalaanpassing op basis van doel. Zie Doelgebaseerde schaalaanpassing en bekijk de azure Functions-hostingopties voor meer informatie.
Notitie
Ondersteuning voor verbruiksabonnementen vereist release v3.1.284 of hoger van de Azure SQL-bindingen voor Azure Functions.
Overzicht van functionaliteit
De Azure SQL-triggerbinding maakt gebruik van een polling-lus om te controleren op wijzigingen, waardoor de gebruikersfunctie wordt geactiveerd wanneer er wijzigingen worden gedetecteerd. Op hoog niveau ziet de lus er als volgt uit:
while (true) {
1. Get list of changes on table - up to a maximum number controlled by the Sql_Trigger_MaxBatchSize setting
2. Trigger function with list of changes
3. Wait for delay controlled by Sql_Trigger_PollingIntervalMs setting
}
Wijzigingen worden verwerkt in de volgorde waarin de wijzigingen zijn aangebracht, waarbij de oudste wijzigingen eerst worden verwerkt. Enkele opmerkingen over de verwerking van wijzigingen:
- Als wijzigingen in meerdere rijen tegelijk worden aangebracht in de exacte volgorde die naar de functie wordt verzonden, is gebaseerd op de volgorde die wordt geretourneerd door de functie CHANGETABLE
- Wijzigingen worden 'batched' samen voor een rij. Als er meerdere wijzigingen worden aangebracht in een rij tussen elke iteratie van de lus, bestaat er slechts één wijzigingsvermelding voor die rij die het verschil tussen de laatst verwerkte status en de huidige status weergeeft
- Als er wijzigingen worden aangebracht in een set rijen en vervolgens een andere set wijzigingen worden aangebracht in de helft van dezelfde rijen, worden de helft van de rijen die niet een tweede keer zijn gewijzigd eerst verwerkt. Deze verwerkingslogica wordt veroorzaakt door de bovenstaande opmerking met de wijzigingen die in batch worden verwerkt. De trigger ziet alleen de 'laatste' wijziging die is aangebracht en gebruikt voor de volgorde waarin deze worden verwerkt
Notitie
Azure SQL-wijzigingstracking kan rijniveauwijzigingen detecteren in tabellen die gebruikmaken van encryptietechnologieën zoals Always Encrypted of Transparent Data Encryption (TDE). De Azure SQL-trigger ontsleutelt of stelt echter geen versleutelde kolomwaarden bloot in de wijzigingspayload. De trigger kan detecteren dat er een wijziging is geweest, maar kan geen toegang krijgen tot de ontsleutelde data voor die kolommen.
Zie voor meer informatie over het bijhouden van wijzigingen en hoe het wordt gebruikt door toepassingen zoals Azure SQL-triggers, het werken met het bijhouden van wijzigingen.
Belangrijk
Voor optimale beveiliging moet u Microsoft Entra ID met beheerde identiteiten gebruiken voor verbindingen tussen Functions en Azure SQL Database. Beheerde identiteiten maken uw app veiliger door geheimen uit uw toepassingsimplementaties te elimineren, zoals referenties in de verbindingsreeks s, servernamen en poorten die worden gebruikt. In deze zelfstudie leert u hoe u beheerde identiteiten gebruikt, een functie-app verbinden met Azure SQL met beheerde identiteiten en SQL-bindingen.
Voorbeeld van gebruik
Meer voorbeelden voor de Azure SQL-trigger zijn beschikbaar in de GitHub-opslagplaats.
Het voorbeeld verwijst naar een ToDoItem klasse en een bijbehorende databasetabel:
namespace AzureSQL.ToDo
{
public class ToDoItem
{
public Guid Id { get; set; }
public int? order { get; set; }
public string title { get; set; }
public string url { get; set; }
public bool? completed { get; set; }
}
}
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Wijzigingen bijhouden is ingeschakeld voor de database en in de tabel:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
De SQL-trigger bindt aan een IReadOnlyList<SqlChange<T>>, een lijst SqlChange met objecten die elk twee eigenschappen hebben:
-
Item: het item dat is gewijzigd. Het type item moet het tabelschema volgen zoals in de
ToDoItemklasse wordt weergegeven. -
Bewerking: een waarde uit
SqlChangeOperationopsomming. De mogelijke waarden zijnInsert,UpdateenDelete.
In het volgende voorbeeld ziet u een C#-functie die wordt aangeroepen wanneer er wijzigingen in de ToDo tabel zijn:
using System;
using System.Collections.Generic;
using Microsoft.Azure.Functions.Worker;
using Microsoft.Azure.Functions.Worker.Extensions.Sql;
using Microsoft.Extensions.Logging;
using Newtonsoft.Json;
namespace AzureSQL.ToDo
{
public static class ToDoTrigger
{
[Function("ToDoTrigger")]
public static void Run(
[SqlTrigger("[dbo].[ToDo]", "SqlConnectionString")]
IReadOnlyList<SqlChange<ToDoItem>> changes,
FunctionContext context)
{
var logger = context.GetLogger("ToDoTrigger");
foreach (SqlChange<ToDoItem> change in changes)
{
ToDoItem toDoItem = change.Item;
logger.LogInformation($"Change operation: {change.Operation}");
logger.LogInformation($"Id: {toDoItem.Id}, Title: {toDoItem.title}, Url: {toDoItem.url}, Completed: {toDoItem.completed}");
}
}
}
}
Voorbeeld van gebruik
Meer voorbeelden voor de Azure SQL-trigger zijn beschikbaar in de GitHub-opslagplaats.
Het voorbeeld verwijst naar een ToDoItem klasse, een SqlChangeToDoItem klasse, een SqlChangeOperation enum en een bijbehorende databasetabel:
In een afzonderlijk bestand ToDoItem.java:
package com.function;
import java.util.UUID;
public class ToDoItem {
public UUID Id;
public int order;
public String title;
public String url;
public boolean completed;
public ToDoItem() {
}
public ToDoItem(UUID Id, int order, String title, String url, boolean completed) {
this.Id = Id;
this.order = order;
this.title = title;
this.url = url;
this.completed = completed;
}
}
In een afzonderlijk bestand SqlChangeToDoItem.java:
package com.function;
public class SqlChangeToDoItem {
public ToDoItem item;
public SqlChangeOperation operation;
public SqlChangeToDoItem() {
}
public SqlChangeToDoItem(ToDoItem Item, SqlChangeOperation Operation) {
this.Item = Item;
this.Operation = Operation;
}
}
In een afzonderlijk bestand SqlChangeOperation.java:
package com.function;
import com.google.gson.annotations.SerializedName;
public enum SqlChangeOperation {
@SerializedName("0")
Insert,
@SerializedName("1")
Update,
@SerializedName("2")
Delete;
}
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Wijzigingen bijhouden is ingeschakeld voor de database en in de tabel:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
De SQL-trigger bindt aan een SqlChangeToDoItem[], een matrix met SqlChangeToDoItem objecten die elk twee eigenschappen bevatten:
-
item: het item dat is gewijzigd. Het type item moet het tabelschema volgen zoals in de
ToDoItemklasse wordt weergegeven. -
bewerking: een waarde uit
SqlChangeOperationenum. De mogelijke waarden zijnInsert,UpdateenDelete.
In het volgende voorbeeld ziet u een Java-functie die wordt aangeroepen wanneer er wijzigingen in de ToDo tabel zijn:
package com.function;
import com.microsoft.azure.functions.ExecutionContext;
import com.microsoft.azure.functions.annotation.FunctionName;
import com.microsoft.azure.functions.sql.annotation.SQLTrigger;
import com.function.Common.SqlChangeToDoItem;
import com.google.gson.Gson;
import java.util.logging.Level;
public class ProductsTrigger {
@FunctionName("ToDoTrigger")
public void run(
@SQLTrigger(
name = "todoItems",
tableName = "[dbo].[ToDo]",
connectionStringSetting = "SqlConnectionString")
SqlChangeToDoItem[] todoItems,
ExecutionContext context) {
context.getLogger().log(Level.INFO, "SQL Changes: " + new Gson().toJson(changes));
}
}
Voorbeeld van gebruik
Meer voorbeelden voor de Azure SQL-trigger zijn beschikbaar in de GitHub-opslagplaats.
Het voorbeeld verwijst naar een ToDoItem databasetabel:
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Wijzigingen bijhouden is ingeschakeld voor de database en in de tabel:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
De SQL-trigger bindt aan todoChanges, een lijst met objecten die elk twee eigenschappen bevatten:
- item: het item dat is gewijzigd. De structuur van het item volgt het tabelschema.
-
bewerking: de mogelijke waarden zijn
Insert,UpdateenDelete.
In het volgende voorbeeld ziet u een PowerShell-functie die wordt aangeroepen wanneer er wijzigingen in de ToDo tabel zijn.
Hier volgen bindingsgegevens in het function.json-bestand:
{
"name": "todoChanges",
"type": "sqlTrigger",
"direction": "in",
"tableName": "dbo.ToDo",
"connectionStringSetting": "SqlConnectionString"
}
In de configuratiesectie worden deze eigenschappen uitgelegd.
Hier volgt een PowerShell-voorbeeldcode voor de functie in het run.ps1 bestand:
using namespace System.Net
param($todoChanges)
# The output is used to inspect the trigger binding parameter in test methods.
# Use -Compress to remove new lines and spaces for testing purposes.
$changesJson = $todoChanges | ConvertTo-Json -Compress
Write-Host "SQL Changes: $changesJson"
Voorbeeld van gebruik
Meer voorbeelden voor de Azure SQL-trigger zijn beschikbaar in de GitHub-opslagplaats.
Het voorbeeld verwijst naar een ToDoItem databasetabel:
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Wijzigingen bijhouden is ingeschakeld voor de database en in de tabel:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
De SQL-trigger bindt todoChanges, een matrix met objecten die elk twee eigenschappen hebben:
- item: het item dat is gewijzigd. De structuur van het item volgt het tabelschema.
-
bewerking: de mogelijke waarden zijn
Insert,UpdateenDelete.
In het volgende voorbeeld ziet u een JavaScript-functie die wordt aangeroepen wanneer er wijzigingen in de ToDo tabel zijn.
Hier volgen bindingsgegevens in het function.json-bestand:
{
"name": "todoChanges",
"type": "sqlTrigger",
"direction": "in",
"tableName": "dbo.ToDo",
"connectionStringSetting": "SqlConnectionString"
}
In de configuratiesectie worden deze eigenschappen uitgelegd.
Hier volgt een voorbeeld van JavaScript-code voor de functie in het index.js bestand:
module.exports = async function (context, todoChanges) {
context.log(`SQL Changes: ${JSON.stringify(todoChanges)}`)
}
Voorbeeld van gebruik
Meer voorbeelden voor de Azure SQL-trigger zijn beschikbaar in de GitHub-opslagplaats.
Het voorbeeld verwijst naar een ToDoItem databasetabel:
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Wijzigingen bijhouden is ingeschakeld voor de database en in de tabel:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
De SQL-trigger verbindt met een variabele todoChanges, een lijst met objecten die elk twee eigenschappen hebben:
- item: het item dat is gewijzigd. De structuur van het item volgt het tabelschema.
-
bewerking: de mogelijke waarden zijn
Insert,UpdateenDelete.
In het volgende voorbeeld ziet u een Python-functie die wordt aangeroepen wanneer er wijzigingen in de ToDo tabel zijn.
Hier volgt een python-voorbeeldcode voor het function_app.py-bestand:
import json
import logging
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="ToDoTrigger")
@app.sql_trigger(arg_name="todo",
table_name="ToDo",
connection_string_setting="SqlConnectionString")
def todo_trigger(todo: str) -> None:
logging.info("SQL Changes: %s", json.loads(todo))
Kenmerken
De C#-bibliotheek maakt gebruik van het kenmerk SqlTrigger om de SQL-trigger voor de functie te declareren, die de volgende eigenschappen heeft:
| Kenmerkeigenschap | Beschrijving |
|---|---|
| TableName- | Vereist. De naam van de tabel die wordt bewaakt door de trigger. |
| ConnectionStringSetting | Vereist. De naam van een app-instelling die de verbindingsreeks bevat voor de database die de tabel bevat die wordt gecontroleerd op wijzigingen. De naam van de verbindingsreeks-instelling komt overeen met de toepassingsinstelling (voor local.settings.json lokale ontwikkeling) die de verbindingsreeks bevat naar het Azure SQL- of SQL Server-exemplaar. |
| LeasesTableName | Optioneel. Naam van de tabel die wordt gebruikt voor het opslaan van leases. Als dit niet is opgegeven, wordt de naam van de leasetabel Leases_{FunctionId}_{TableId}. Meer informatie over hoe dit wordt gegenereerd, vindt u hier. |
Aantekeningen
Gebruik in de Java Functions Runtime-bibliotheek de @SQLTrigger aantekening (com.microsoft.azure.functions.sql.annotation.SQLTrigger) voor parameters waarvan de waarde afkomstig is van Azure SQL. Deze aantekening ondersteunt de volgende elementen:
| Onderdeel | Beschrijving |
|---|---|
| naam | Vereist. De naam van de parameter waaraan de trigger is gekoppeld. |
| tableName | Vereist. De naam van de tabel die wordt bewaakt door de trigger. |
| connectionStringSetting | Vereist. De naam van een app-instelling die de verbindingsreeks bevat voor de database die de tabel bevat die wordt gecontroleerd op wijzigingen. De naam van de verbindingsreeks-instelling komt overeen met de toepassingsinstelling (voor local.settings.json lokale ontwikkeling) die de verbindingsreeks bevat naar het Azure SQL- of SQL Server-exemplaar. |
| LeasesTableName | Optioneel. Naam van de tabel die wordt gebruikt voor het opslaan van leases. Als dit niet is opgegeven, wordt de naam van de leasetabel Leases_{FunctionId}_{TableId}. Meer informatie over hoe dit wordt gegenereerd, vindt u hier. |
Configuratie
In de volgende tabel worden de bindingsconfiguratie-eigenschappen uitgelegd die u in het function.json-bestand hebt ingesteld.
| function.json-eigenschap | Beschrijving |
|---|---|
| naam | Vereist. De naam van de parameter waaraan de trigger is gekoppeld. |
| soort | Vereist. Moet worden ingesteld op sqlTrigger. |
| richting | Vereist. Moet worden ingesteld op in. |
| tableName | Vereist. De naam van de tabel die wordt bewaakt door de trigger. |
| connectionStringSetting | Vereist. De naam van een app-instelling die de verbindingsreeks bevat voor de database die de tabel bevat die wordt gecontroleerd op wijzigingen. De naam van de verbindingsreeks-instelling komt overeen met de toepassingsinstelling (voor local.settings.json lokale ontwikkeling) die de verbindingsreeks bevat naar het Azure SQL- of SQL Server-exemplaar. |
| LeasesTableName | Optioneel. Naam van de tabel die wordt gebruikt voor het opslaan van leases. Als dit niet is opgegeven, wordt de naam van de leasetabel Leases_{FunctionId}_{TableId}. Meer informatie over hoe dit wordt gegenereerd, vindt u hier. |
Optionele configuratie
De volgende optionele instellingen kunnen worden geconfigureerd voor de SQL-trigger voor lokale ontwikkeling of voor cloudimplementaties.
host.json
In deze sectie worden de configuratie-instellingen beschreven die beschikbaar zijn voor deze binding in versie 2.x en hoger. Instellingen in het bestand host.json zijn van toepassing op alle functies in een exemplaar van een functie-app. Zie host.json naslaginformatie voor Azure Functions voor meer informatie over configuratie-instellingen voor functie-apps.
| Instelling | Verstek | Beschrijving |
|---|---|---|
| MaxBatchSize | 100 | Het maximum aantal wijzigingen dat wordt verwerkt met elke iteratie van de triggerlus voordat deze naar de geactiveerde functie wordt verzonden. |
| PollingIntervalMs | 1000 | De vertraging in milliseconden tussen het verwerken van elke batch wijzigingen. (1000 ms is 1 seconde) |
| MaxChangesPerWorker | 1000 | De bovengrens voor het aantal wijzigingen in behandeling in de gebruikerstabel die per toepassingsmedewerker zijn toegestaan. Als het aantal wijzigingen deze limiet overschrijdt, kan dit leiden tot uitschalen. De instelling geldt alleen voor Azure Function-apps waarvoor runtimegestuurd schalen is ingeschakeld. |
Voorbeeld van host.json bestand
Hier volgt een voorbeeld van host.json bestand met de optionele instellingen:
{
"version": "2.0",
"extensions": {
"Sql": {
"MaxBatchSize": 300,
"PollingIntervalMs": 1000,
"MaxChangesPerWorker": 100
}
},
"logging": {
"applicationInsights": {
"samplingSettings": {
"isEnabled": true,
"excludedTypes": "Request"
}
},
"logLevel": {
"default": "Trace"
}
}
}
local.setting.json
In het local.settings.json-bestand worden app-instellingen en -instellingen opgeslagen die worden gebruikt door lokale ontwikkelhulpprogramma's. Instellingen in het local.settings.json-bestand worden alleen gebruikt wanneer u uw project lokaal uitvoert. Wanneer u uw project publiceert naar Azure, moet u ook alle vereiste instellingen toevoegen aan de app-instellingen voor de functie-app.
Belangrijk
Omdat de local.settings.json geheimen kan bevatten, zoals verbindingsreeks s, moet u deze nooit opslaan in een externe opslagplaats. Hulpprogramma's die Functies ondersteunen, bieden manieren om instellingen in het local.settings.json-bestand te synchroniseren met de app-instellingen in de functie-app waarmee uw project wordt geïmplementeerd.
| Instelling | Verstek | Beschrijving |
|---|---|---|
| Sql_Trigger_BatchSize | 100 | Het maximum aantal wijzigingen dat wordt verwerkt met elke iteratie van de triggerlus voordat deze naar de geactiveerde functie wordt verzonden. |
| Sql_Trigger_PollingIntervalMs | 1000 | De vertraging in milliseconden tussen het verwerken van elke batch wijzigingen. (1000 ms is 1 seconde) |
| Sql_Trigger_MaxChangesPerWorker | 1000 | De bovengrens voor het aantal wijzigingen in behandeling in de gebruikerstabel die per toepassingsmedewerker zijn toegestaan. Als het aantal wijzigingen deze limiet overschrijdt, kan dit leiden tot uitschalen. De instelling geldt alleen voor Azure Function-apps waarvoor runtimegestuurd schalen is ingeschakeld. |
Voorbeeld van local.settings.json bestand
Hier volgt een voorbeeld van local.settings.json bestand met de optionele instellingen:
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "dotnet",
"SqlConnectionString": "",
"Sql_Trigger_MaxBatchSize": 300,
"Sql_Trigger_PollingIntervalMs": 1000,
"Sql_Trigger_MaxChangesPerWorker": 100
}
}
Wijzigingen bijhouden instellen (vereist)
Voor het instellen van wijzigingen bijhouden voor gebruik met de Azure SQL-trigger zijn twee stappen vereist. Deze stappen kunnen worden uitgevoerd vanuit elk SQL-hulpprogramma dat ondersteuning biedt voor het uitvoeren van query's, waaronder Visual Studio Code, Azure Data Studio of SQL Server Management Studio.
Schakel wijzigingen bijhouden in de SQL-database in, waarbij u vervangt
your database namedoor de naam van de database waarin de tabel moet worden bewaakt:ALTER DATABASE [your database name] SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);Met de
CHANGE_RETENTIONoptie geeft u de periode op waarvoor informatie over het bijhouden van wijzigingen (wijzigingsgeschiedenis) wordt bewaard. De retentie van de wijzigingsgeschiedenis door de SQL-database kan van invloed zijn op de triggerfunctionaliteit. Als de Azure-functie bijvoorbeeld enkele dagen is uitgeschakeld en vervolgens wordt hervat, bevat de database de wijzigingen die in de afgelopen twee dagen in het bovenstaande installatievoorbeeld zijn opgetreden.De
AUTO_CLEANUPoptie wordt gebruikt om de opschoontaak in of uit te schakelen waarmee oude gegevens over wijzigingen bijhouden worden verwijderd. Als een tijdelijk probleem waardoor de trigger niet kan worden uitgevoerd, kan het uitschakelen van automatisch opschonen handig zijn om het verwijderen van gegevens ouder dan de bewaarperiode te onderbreken totdat het probleem is opgelost.Meer informatie over opties voor het bijhouden van wijzigingen is beschikbaar in de SQL-documentatie.
Schakel wijzigingen bijhouden in de tabel in, waarbij u de
your table namenaam van de tabel vervangt door de naam van de tabel (indien nodig het schema wijzigen):ALTER TABLE [dbo].[your table name] ENABLE CHANGE_TRACKING;De trigger moet leestoegang hebben voor de tabel die wordt bewaakt op wijzigingen en in de systeemtabellen voor wijzigingen bijhouden. Elke functietrigger heeft een gekoppelde tabel voor het bijhouden van wijzigingen en leases in een schema
az_func. Deze tabellen worden gemaakt door de trigger als ze nog niet bestaan. Meer informatie over deze gegevensstructuren vindt u in de documentatie van de Azure SQL-bindingsbibliotheek.
Runtimegestuurd schalen inschakelen
Desgewenst kunnen uw functies automatisch worden geschaald op basis van het aantal wijzigingen dat in behandeling is voor verwerking in de gebruikerstabel. Als u wilt dat uw functies correct kunnen worden geschaald in het Premium-abonnement bij het gebruik van SQL-triggers, moet u bewaking van runtimeschaal inschakelen.
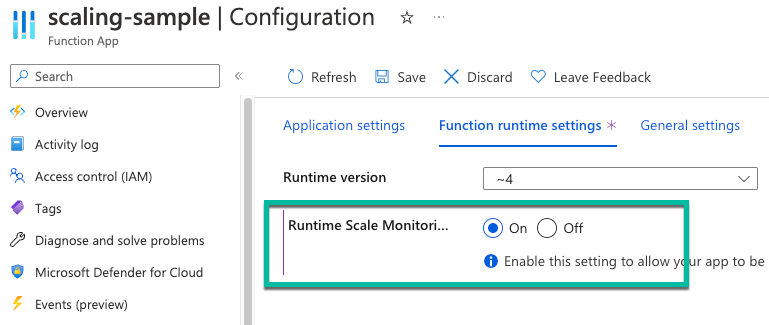
Selecteer Configuratie in de Azure-portal in uw functie-app.
Selecteer op het tabblad Runtime-instellingen voor Runtime-schaalbewaking de optie Aan.
Ondersteuning voor opnieuw proberen
Meer informatie over de ondersteunings- en leasetabellen voor SQL-triggers is beschikbaar in de GitHub-opslagplaats.
Nieuwe pogingen voor opstarten
Als er een uitzondering optreedt tijdens het opstarten, probeert de hostruntime de triggerlistener automatisch opnieuw op te starten met een strategie voor exponentieel uitstel. Deze nieuwe pogingen worden voortgezet totdat de listener is gestart of het opstarten wordt geannuleerd.
Nieuwe pogingen voor verbroken verbindingen
Als de functie is gestart, maar een fout veroorzaakt dat de verbinding wordt verbroken (zoals de server die offline gaat), blijft de functie proberen de verbinding opnieuw te openen totdat de functie is gestopt of de verbinding slaagt. Als de verbinding opnieuw tot stand is gebracht, worden de verwerkingswijzigingen opgehaald waar deze was gebleven.
Houd er rekening mee dat deze nieuwe pogingen buiten de ingebouwde logica voor niet-actieve verbindingen vallen die sqlClient heeft die kan worden geconfigureerd met de ConnectRetryCount en ConnectRetryIntervalverbindingsreeks opties. De ingebouwde inactieve verbindingspogingen worden eerst geprobeerd en als deze niet opnieuw verbinding maken, probeert de triggerbinding de verbinding zelf opnieuw tot stand te brengen.
Nieuwe pogingen voor functie-uitzonderingen
Als er een uitzondering optreedt in de gebruikersfunctie bij het verwerken van wijzigingen, wordt de batch met rijen die momenteel worden verwerkt, binnen 60 seconden opnieuw geprobeerd. Andere wijzigingen worden gedurende deze periode als normaal verwerkt, maar de rijen in de batch die de uitzondering hebben veroorzaakt, worden genegeerd totdat de time-outperiode is verstreken.
Als de uitvoering van de functie vijf keer in een rij mislukt voor een bepaalde rij, wordt die rij volledig genegeerd voor alle toekomstige wijzigingen. Omdat de rijen in een batch niet deterministisch zijn, kunnen rijen in een mislukte batch in verschillende batches terechtkomen in volgende aanroepen. Dit betekent dat niet alle rijen in de mislukte batch noodzakelijkerwijs worden genegeerd. Als andere rijen in de batch de uitzondering veroorzaakten, kunnen de 'goede' rijen in een andere batch terechtkomen die in toekomstige aanroepen niet mislukken.