Aanbevolen waarschuwingsregels voor Kubernetes-clusters
Waarschuwingen in Azure Monitor identificeren proactief problemen met betrekking tot de status en prestaties van uw Azure-resources. In dit artikel wordt beschreven hoe u een set aanbevolen waarschuwingsregels voor metrische gegevens inschakelt en bewerkt die vooraf zijn gedefinieerd voor uw Kubernetes-clusters.
Aanbevolen waarschuwingsregels inschakelen
Gebruik een van de volgende methoden om de aanbevolen waarschuwingsregels voor uw cluster in te schakelen. U kunt zowel prometheus- als waarschuwingsregels voor metrische platformgegevens inschakelen voor hetzelfde cluster.
Notitie
ARM-sjablonen zijn de enige ondersteunde methode voor het inschakelen van aanbevolen waarschuwingen voor Kubernetes-clusters met Arc.
Met behulp van Azure Portal wordt de Prometheus-regelgroep gemaakt in dezelfde regio als het cluster.
Selecteer aanbevelingen instellen in het menu Waarschuwingen voor uw cluster.
De beschikbare Prometheus- en platformwaarschuwingsregels worden weergegeven met de Prometheus-regels georganiseerd op pod-, cluster- en knooppuntniveau. Schakel een groep Prometheus-regels in om die set regels in te schakelen. Vouw de groep uit om de afzonderlijke regels weer te geven. U kunt de standaardinstellingen behouden of afzonderlijke regels uitschakelen en hun naam en ernst bewerken.
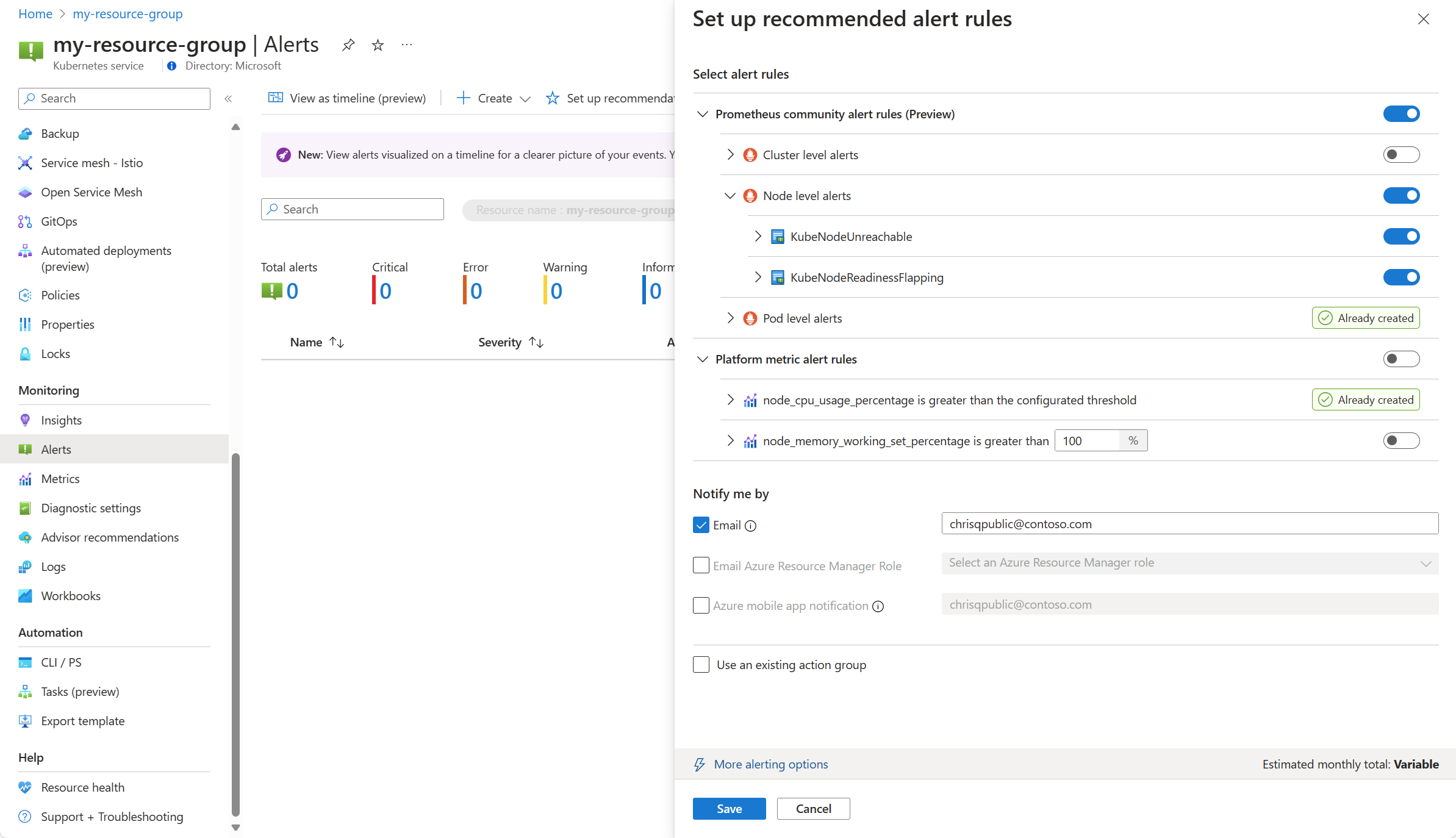
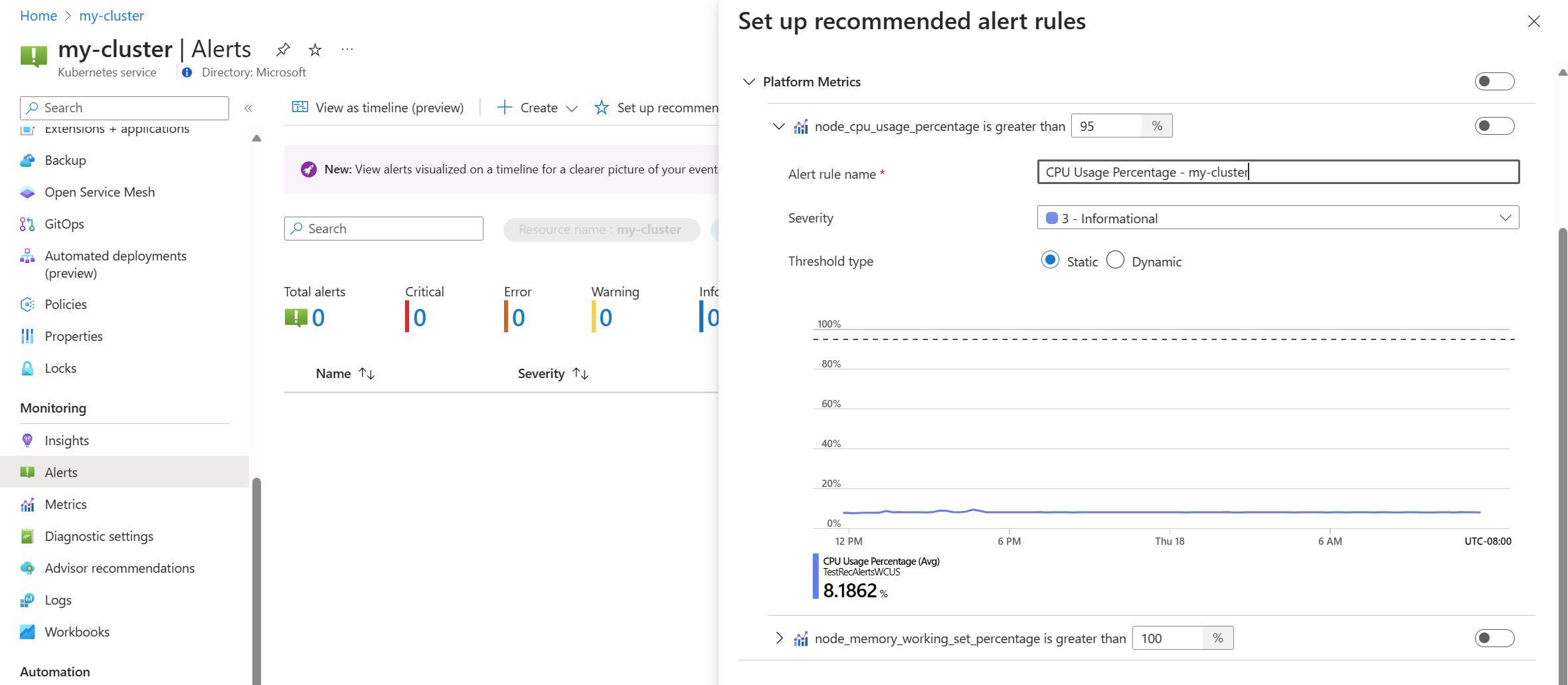
Schakel een metrische platformregel in om die regel in te schakelen. U kunt de regel uitbreiden om de details te wijzigen, zoals de naam, ernst en drempelwaarde.
Selecteer een of meer meldingsmethoden om een nieuwe actiegroep te maken of selecteer een bestaande actiegroep met de meldingsgegevens voor deze set waarschuwingsregels.
Klik op Opslaan om de regelgroep op te slaan.



Aanbevolen waarschuwingsregels bewerken
Zodra de regelgroep is gemaakt, kunt u niet dezelfde pagina in de portal gebruiken om de regels te bewerken. Voor metrische prometheus-gegevens moet u de regelgroep bewerken om eventuele regels erin te wijzigen, inclusief het inschakelen van regels die nog niet zijn ingeschakeld. Voor metrische platformgegevens kunt u elke waarschuwingsregel bewerken.
Selecteer aanbevelingen instellen in het menu Waarschuwingen voor uw cluster. Regels of regelgroepen die al zijn gemaakt, worden gelabeld als Al gemaakt.
Vouw de regel of regelgroep uit. Klik op Regelgroep weergeven voor Prometheus en Waarschuwingsregel weergeven voor metrische platformgegevens.
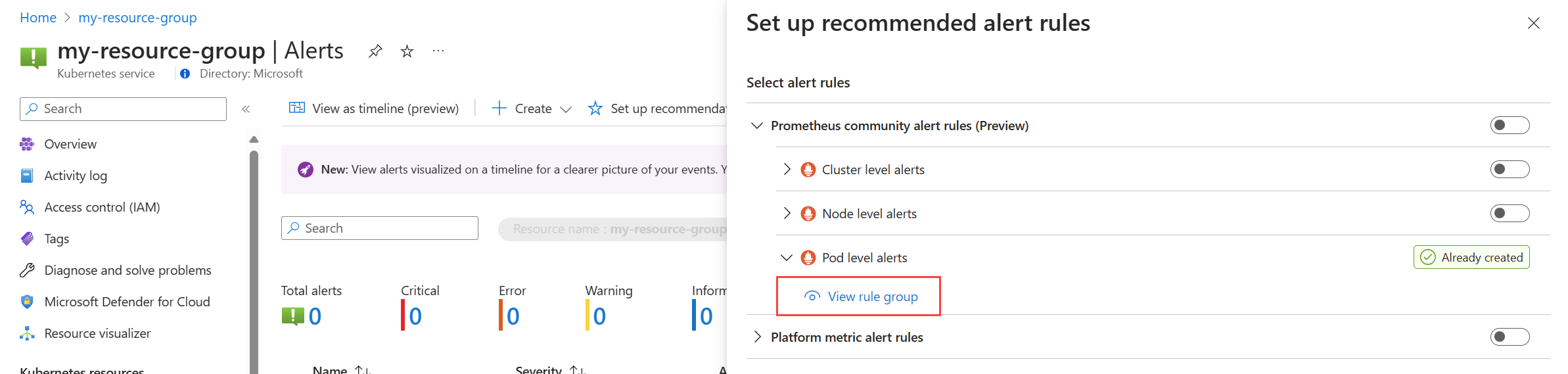
Voor Prometheus-regelgroepen:
selecteer Regels om de waarschuwingsregels in de groep weer te geven.
Klik op het pictogram Bewerken naast een regel die u wilt wijzigen. Gebruik de richtlijnen in Een waarschuwingsregel maken om de regel te wijzigen.
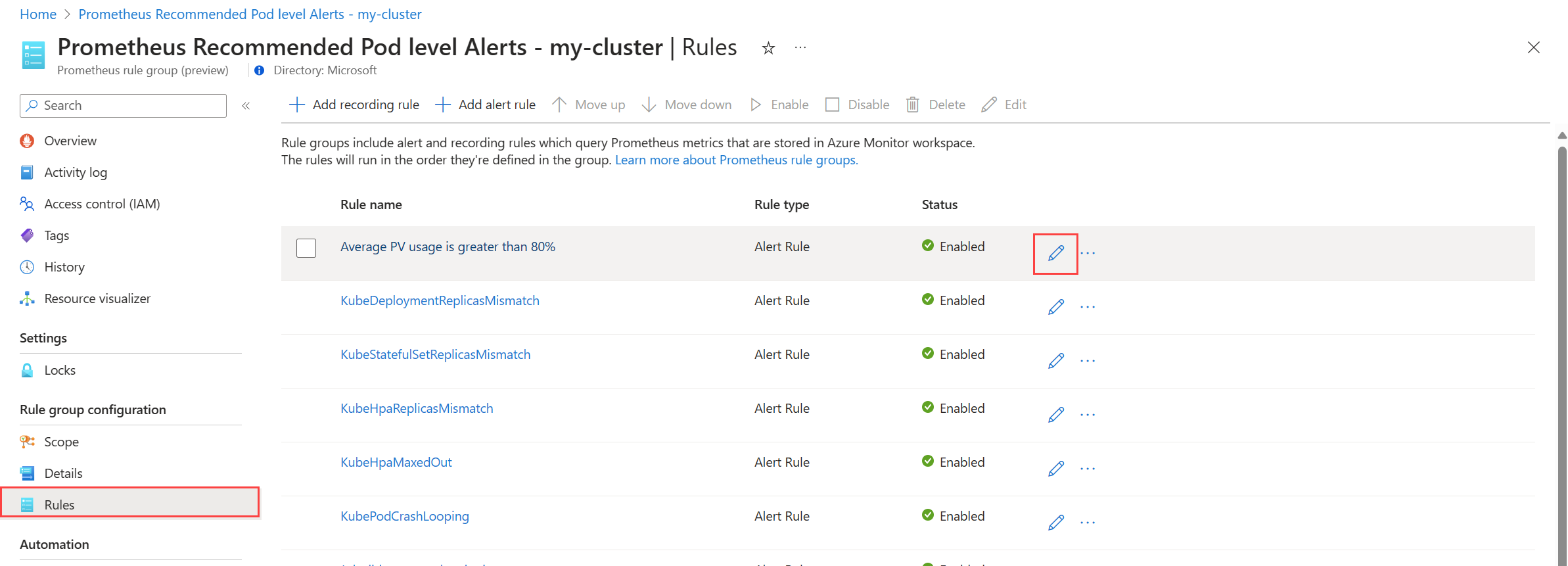
Wanneer u klaar bent met het bewerken van regels in de groep, klikt u op Opslaan om de regelgroep op te slaan.
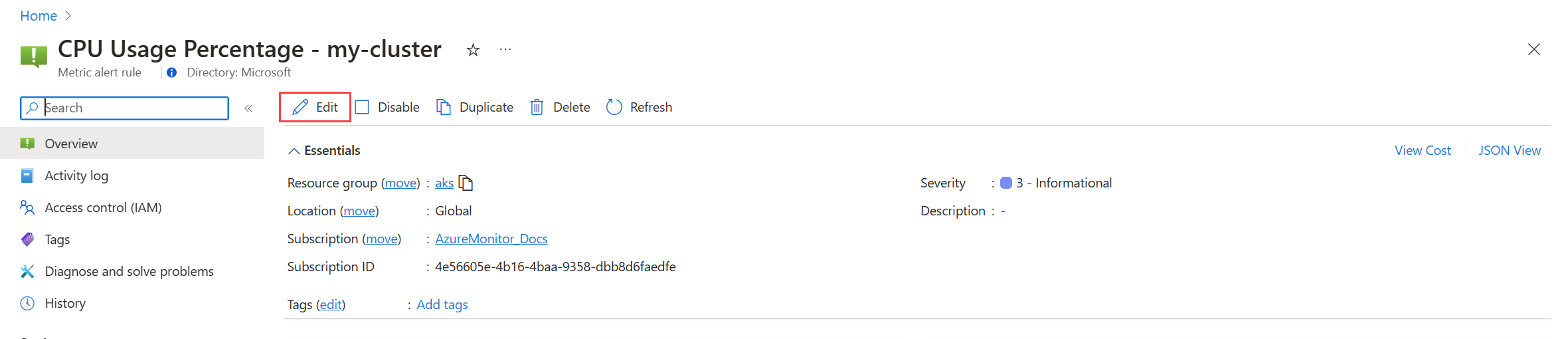
Voor metrische platformgegevens:
klik op Bewerken om de details voor de waarschuwingsregel te openen. Gebruik de richtlijnen in Een waarschuwingsregel maken om de regel te wijzigen.



Waarschuwingsregelgroep uitschakelen
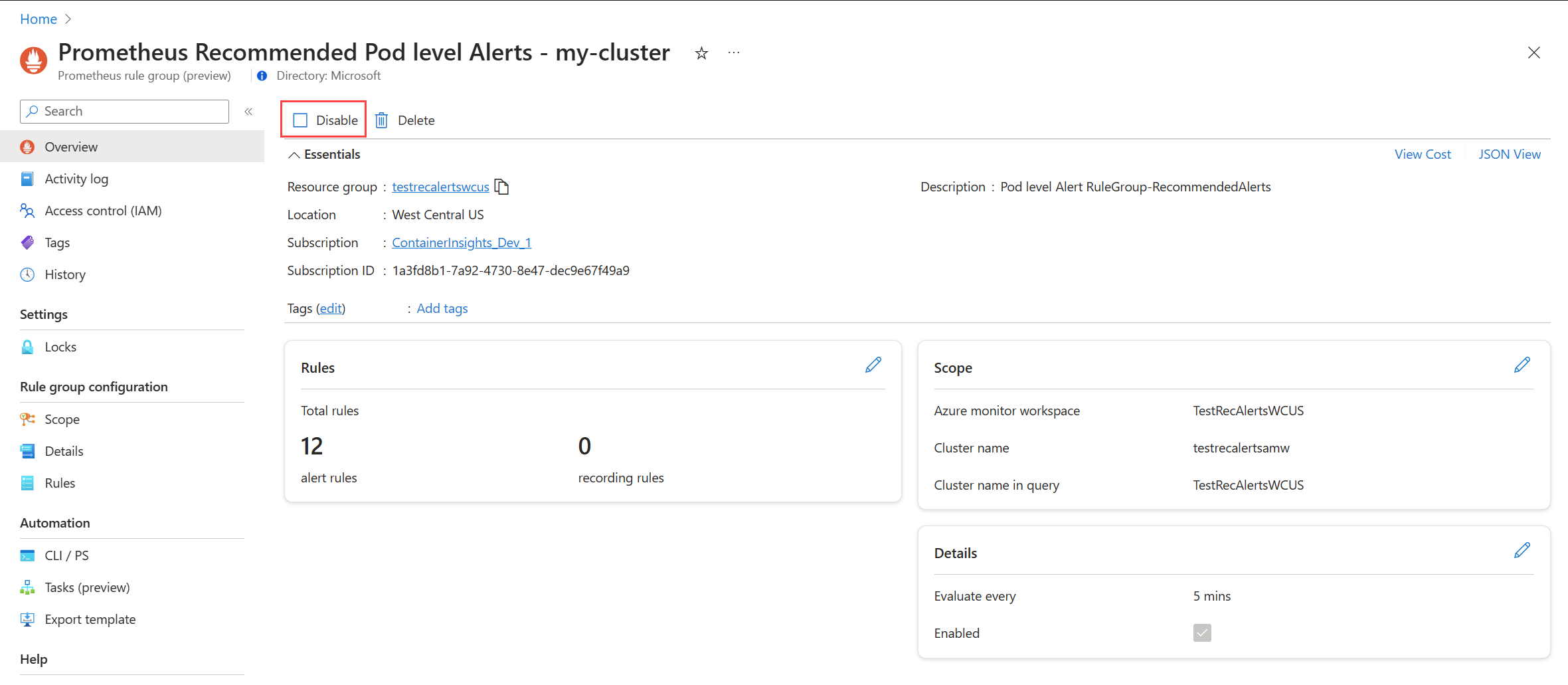
Schakel de regelgroep uit om te stoppen met het ontvangen van waarschuwingen van de regels erin.
Bekijk de regelregel voor de Prometheus-waarschuwingsgroep of de waarschuwingsregel voor metrische platformgegevens, zoals beschreven in Aanbevolen waarschuwingsregels bewerken.
Selecteer In het menu Overzicht de optie Uitschakelen.

Details van aanbevolen waarschuwingsregel
De volgende tabellen bevatten de details van elke aanbevolen waarschuwingsregel. Broncode voor elke code is beschikbaar in GitHub , samen met handleidingen voor probleemoplossing van de Prometheus-community.
Waarschuwingsregels voor Prometheus-community
Waarschuwingen op clusterniveau
| Naam van waarschuwing | Beschrijving | Standaarddrempelwaarde | Tijdsbestek (minuten) |
|---|---|---|---|
| KubeCPUQuotaOvercommit | Het quotum voor CPU-resources dat is toegewezen aan naamruimten overschrijdt de beschikbare CPU-resources op de knooppunten van het cluster met meer dan 50% voor de afgelopen 5 minuten. | >1.5 | 5 |
| KubeMemoryQuotaOvercommit | Het quotum voor geheugenresources dat is toegewezen aan naamruimten overschrijdt de beschikbare geheugenresources op de knooppunten van het cluster met meer dan 50% voor de afgelopen 5 minuten. | >1.5 | 5 |
| KubeContainerOOMKilledCount | Een of meer containers binnen pods zijn de afgelopen 5 minuten gedood vanwege OOM-gebeurtenissen (out-of-memory). | >0 | 5 |
| KubeClientErrors | Het aantal clientfouten (HTTP-statuscodes vanaf 5xx) in Kubernetes API-aanvragen overschrijdt 1% van de totale API-aanvraagsnelheid voor de afgelopen 15 minuten. | >0.01 | 15 |
| KubePersistentVolumeFillingUp | Het permanente volume wordt gevuld en verwacht dat er gedurende de afgelopen 6 uur onvoldoende ruimte beschikbaar is die wordt geëvalueerd op de beschikbare ruimteverhouding, gebruikte ruimte en voorspelde lineaire trend van beschikbare ruimte. Deze voorwaarden worden in de afgelopen 60 minuten geëvalueerd. | N.v.t. | 60 |
| KubePersistentVolumeInodesFillingUp | In de afgelopen 15 minuten is minder dan 3% van de inodes binnen een permanent volume beschikbaar. | <0.03 | 15 |
| KubePersistentVolumeErrors | Een of meer permanente volumes bevinden zich in een mislukte of in behandeling zijnde fase voor de afgelopen 5 minuten. | >0 | 5 |
| KubeContainerWaiting | Een of meer containers binnen Kubernetes-pods hebben een wachtstatus voor de afgelopen 60 minuten. | >0 | 60 |
| KubeDaemonSetNotScheduled | Een of meer pods worden gedurende de afgelopen 15 minuten niet gepland op een knooppunt. | >0 | 15 |
| KubeDaemonSetMisScheduled | Een of meer pods worden de afgelopen 15 minuten verkeerd gepland binnen het cluster. | >0 | 15 |
| KubeQuotaAlmostFull | Het gebruik van Kubernetes-resourcequota ligt tussen de 90% en 100% van de vaste limieten voor de afgelopen 15 minuten. | >0,9 <1 | 15 |
Waarschuwingen op knooppuntniveau
| Naam van waarschuwing | Beschrijving | Standaarddrempelwaarde | Tijdsbestek (minuten) |
|---|---|---|---|
| KubeNodeUnreachable | Een knooppunt is de afgelopen 15 minuten niet bereikbaar. | 1 | 15 |
| KubeNodeReadinessFlapping | De gereedheidsstatus van een knooppunt is gedurende de afgelopen 15 minuten meer dan 2 keer gewijzigd. | 2 | 15 |
Waarschuwingen op podniveau
| Naam van waarschuwing | Beschrijving | Standaarddrempelwaarde | Tijdsbestek (minuten) |
|---|---|---|---|
| KubePVUsageHigh | Het gemiddelde gebruik van permanente volumes (CV's) op pods overschrijdt 80% voor de afgelopen 15 minuten. | >0.8 | 15 |
| KubeDeploymentReplicasMismatch | Het gewenste aantal replica's en het aantal beschikbare replica's voor de afgelopen tien minuten komt niet overeen. | N.v.t. | 10 |
| KubeStatefulSetReplicasMismatch | Het aantal kant-en-klare replica's in de StatefulSet komt niet overeen met het totale aantal replica's in de StatefulSet voor de afgelopen 15 minuten. | N.v.t. | 15 |
| KubeHpaReplicasMismatch | De horizontale automatische schaalaanpassing van pods in het cluster komt niet overeen met het gewenste aantal replica's voor de afgelopen 15 minuten. | N.v.t. | 15 |
| KubeHpaMaxedOut | De horizontale automatische schaalaanpassing van pods (HPA) in het cluster wordt gedurende de afgelopen 15 minuten uitgevoerd op de maximumreplica's. | N.v.t. | 15 |
| KubePodCrashLooping | Een of meer pods bevinden zich in een CrashLoopBackOff-voorwaarde, waarbij de pod continu vastloopt na het opstarten en de laatste 15 minuten niet kan worden hersteld. | >=1 | 15 |
| KubeJobStale | Ten minste één taakexemplaren zijn de afgelopen 6 uur niet voltooid. | >0 | 360 |
| KubePodContainerRestart | Een of meer containers binnen pods in het Kubernetes-cluster zijn in het afgelopen uur minstens één keer opnieuw opgestart. | >0 | 15 |
| KubePodReadyStateLow | Het percentage pods in een gereede status valt onder de 80% voor elke implementatie of daemonset in het Kubernetes-cluster voor de afgelopen 5 minuten. | <0.8 | 5 |
| KubePodFailedState | Een of meer pods hebben een mislukte status voor de afgelopen 5 minuten. | >0 | 5 |
| KubePodNotReadyByController | Een of meer pods hebben niet de status Gereed (bijvoorbeeld in de fase In behandeling of Onbekend) voor de afgelopen 15 minuten. | >0 | 15 |
| KubeStatefulSetGenerationMismatch | De waargenomen generatie van een Kubernetes StatefulSet komt niet overeen met de metagegevensgeneratie voor de afgelopen 15 minuten. | N.v.t. | 15 |
| KubeJobFailed | Een of meer Kubernetes-taken zijn in de afgelopen 15 minuten mislukt. | >0 | 15 |
| KubeContainerAverageCPUHigh | Het gemiddelde CPU-gebruik per container overschrijdt 95% voor de afgelopen 5 minuten. | >0.95 | 5 |
| KubeContainerAverageMemoryHigh | Het gemiddelde geheugengebruik per container overschrijdt 95% voor de afgelopen 5 minuten. | >0.95 | 10 |
| KubeletPodStartUpLatencyHigh | Het 99e percentiel van de opstartlatentie van de pod overschrijdt 60 seconden voor de afgelopen 10 minuten. | >60 | 10 |
Waarschuwingsregels voor metrische platformgegevens
| Naam van waarschuwing | Beschrijving | Standaarddrempelwaarde | Tijdsbestek (minuten) |
|---|---|---|---|
| Cpu-percentage knooppunt is groter dan 95% | Het CPU-percentage van het knooppunt is de afgelopen 5 minuten groter dan 95%. | 95 | 5 |
| Percentage werkset voor knooppuntgeheugen is groter dan 100% | Het percentage werksets voor het knooppuntgeheugen is de afgelopen 5 minuten groter dan 100%. | 100 | 5 |
Waarschuwingen voor metrische gegevens over verouderde containerinzichten (preview)
Metrische regels in Container Insights zijn buiten gebruik gesteld op 31 mei 2024. Deze regels waren in openbare preview, maar zijn buiten gebruik gesteld zonder algemene beschikbaarheid te bereiken, omdat de nieuwe aanbevolen metrische waarschuwingen die in dit artikel worden beschreven, nu beschikbaar zijn.
Als u deze verouderde waarschuwingsregels al hebt ingeschakeld, moet u deze uitschakelen en de nieuwe ervaring inschakelen.
Waarschuwingsregels voor metrische gegevens uitschakelen
- Selecteer aanbevolen waarschuwingen (preview) in het menu Inzichten voor uw cluster.
- Wijzig de status voor elke waarschuwingsregel in Uitgeschakeld.
Verouderde waarschuwingstoewijzing
De volgende tabel wijst elk van de verouderde metrische waarschuwingen voor Container Insights toe aan de equivalente aanbevolen metrische waarschuwingen van Prometheus.
| Aanbevolen waarschuwing voor aangepaste metrische gegevens | Equivalente aanbevolen waarschuwing voor Prometheus/Platform-metrische gegevens | Conditie |
|---|---|---|
| Aantal voltooide taken | KubeJobStale (waarschuwingen op podniveau) | Ten minste één taakexemplaren zijn de afgelopen 6 uur niet voltooid. |
| CPU-percentage container | KubeContainerAverageCPUHigh (waarschuwingen op podniveau) | Het gemiddelde CPU-gebruik per container overschrijdt 95% voor de afgelopen 5 minuten. |
| Geheugenpercentage containerwerkset | KubeContainerAverageMemoryHigh (waarschuwingen op podniveau) | Het gemiddelde geheugengebruik per container overschrijdt 95% voor de afgelopen 5 minuten. |
| Aantal mislukte pods | KubePodFailedState (waarschuwingen op podniveau) | Een of meer pods hebben een mislukte status voor de afgelopen 5 minuten. |
| CPU-percentage knooppunt | Cpu-percentage van knooppunten is groter dan 95% (metrische platformgegevens) | Het CPU-percentage van het knooppunt is de afgelopen 5 minuten groter dan 95%. |
| Percentage schijfgebruik van knooppunten | N.v.t. | Gemiddeld schijfgebruik voor een knooppunt is groter dan 80%. |
| NotReady-status van knooppunt | KubeNodeUnreachable (waarschuwingen op knooppuntniveau) | Een knooppunt is de afgelopen 15 minuten niet bereikbaar. |
| Geheugenpercentage van werkset van knooppunt | Percentage werkset voor knooppuntgeheugen is groter dan 100% | Het percentage werksets voor het knooppuntgeheugen is de afgelopen 5 minuten groter dan 100%. |
| Door OOM vermoorde containers | KubeContainerOOMKilledCount (waarschuwingen op clusterniveau) | Een of meer containers binnen pods zijn de afgelopen 5 minuten gedood vanwege OOM-gebeurtenissen (out-of-memory). |
| Percentage permanent volumegebruik | KubePVUsageHigh (waarschuwingen op podniveau) | Het gemiddelde gebruik van permanente volumes (CV's) op pods overschrijdt 80% voor de afgelopen 15 minuten. |
| Pods gereed % | KubePodReadyStateLow (waarschuwingen op podniveau) | Het percentage pods in een gereede status valt onder de 80% voor elke implementatie of daemonset in het Kubernetes-cluster voor de afgelopen 5 minuten. |
| Aantal containers opnieuw starten | KubePodContainerRestart (waarschuwingen op podniveau) | Een of meer containers binnen pods in het Kubernetes-cluster zijn in het afgelopen uur minstens één keer opnieuw opgestart. |
Volgende stappen
- Lees meer over de verschillende typen waarschuwingsregels in Azure Monitor.
- Lees meer over waarschuwingsregelgroepen in de beheerde Azure Monitor-service voor Prometheus.