Meer informatie over volumetalen in Azure NetApp Files
Volumetaal (vergelijkbaar met de landinstellingen van het systeem op clientbesturingssystemen) op een Azure NetApp Files-volume bepaalt de ondersteunde talen en tekensets bij het gebruik van NFS- en SMB-protocollen. Azure NetApp Files maakt gebruik van een standaardvolumetaal van C.UTF-8, die POSIX-compatibele UTF-8-codering biedt voor tekensets. De C.UTF-8-taal ondersteunt standaard tekens met een grootte van 0-3 bytes, waaronder een meerderheid van de talen van de wereld op het BMP (Basic Multilingual Plane) (inclusief Japans, Duits en het grootste deel van Hebreeuws en Cyrillisch). Zie Unicode voor meer informatie over de BMP.
Tekens buiten het BMP overschrijden soms de grootte van 3 bytes die worden ondersteund door Azure NetApp Files. Ze moeten dus surrogaatpaarlogica gebruiken, waarbij meerdere tekens bytesets worden gecombineerd om nieuwe tekens te vormen. Emojisymbolen vallen bijvoorbeeld in deze categorie en worden ondersteund in Azure NetApp Files in scenario's waarin UTF-8 niet wordt afgedwongen, zoals Windows-clients die gebruikmaken van UTF-16-codering of NFSv3 die UTF-8 niet afdwingen. NFSv4.x dwingt UTF-8 af, wat betekent dat surrogaatpaartekens niet goed worden weergegeven wanneer u NFSv4.x gebruikt.
Niet-standaardcodering, zoals Shift-JIS en minder gangbare CJK-tekens, worden ook niet goed weergegeven wanneer UTF-8 wordt afgedwongen in Azure NetApp Files.
Tip
U moet tekst verzenden en ontvangen met UTF-8 om situaties te voorkomen waarin tekens niet correct kunnen worden vertaald, wat kan leiden tot foutscenario's voor het maken/wijzigen van bestanden of het kopiëren van fouten.
De instellingen voor volumetaal kunnen momenteel niet worden gewijzigd in Azure NetApp Files. Zie Protocolgedrag met speciale tekensets voor meer informatie.
Zie best practices voor tekenset voor aanbevolen procedures.
Tekencodering in Azure NetApp Files NFS- en SMB-volumes
In een Azure NetApp Files-omgeving voor het delen van bestanden worden bestands- en mapnamen vertegenwoordigd door een reeks tekens die eindgebruikers lezen en interpreteren. De manier waarop deze tekens worden weergegeven, is afhankelijk van de manier waarop de client deze tekens verzendt en ontvangt. Als een client bijvoorbeeld verouderde American Standard Code for Information Interchange (ASCII) -codering naar het Azure NetApp Files-volume verzendt wanneer deze wordt geopend, is het beperkt tot het weergeven van alleen tekens die worden ondersteund in de ASCII-indeling.
Het Japanse teken voor gegevens is bijvoorbeeld 資. Omdat dit teken niet kan worden weergegeven in ASCII, geeft een client met ASCII-codering een '?' weer. in plaats van 資.
ASCII ondersteunt slechts 95 afdrukbare tekens, voornamelijk tekens in de Engelse taal. Elk van deze tekens maakt gebruik van 1 byte, die wordt meegefactoreerd in de totale lengte van het bestandspad op een Azure NetApp Files-volume. Dit beperkt de internationalisering van gegevenssets, omdat bestandsnamen verschillende tekens kunnen hebben die niet worden herkend door ASCII, van Japans tot Cyrillisch tot emoji. Een internationale standaard (ISO/IEC 8859) probeerde meer internationale tekens te ondersteunen, maar had ook de beperkingen. De meeste moderne clients verzenden en ontvangen tekens met behulp van een bepaalde vorm van Unicode.
Unicode
Als gevolg van de beperkingen van ASCII- en ISO/IEC 8859-coderingen is de Unicode-standaard ingesteld, zodat iedereen de taal van de thuisregio kan bekijken vanaf hun apparaten.
- Unicode ondersteunt meer dan één miljoen tekensets door het aantal toegestane bytes per teken (maximaal 4 bytes) en het totale aantal toegestane bytes in een bestandspad te verhogen in plaats van oudere coderingen, zoals ASCII.
- Unicode ondersteunt compatibiliteit met eerdere versies door de eerste 128 tekens voor ASCII te reserveren, terwijl de eerste 256 codepunten identiek zijn aan ISO/IEC 8859-standaarden.
- In de Unicode-standaard worden tekensets onderverdeeld in vliegtuigen. Een vliegtuig is een doorlopende groep van 65.536 codepunten. In totaal zijn er 17 vliegtuigen (0-16) in de Unicode-standaard. De limiet is 17 vanwege de beperkingen van UTF-16.
- Plane 0 is het BMP (Basic Multilingual Plane). Dit vlak bevat de meest gebruikte tekens in meerdere talen.
- Van de 17 vliegtuigen hebben momenteel slechts vijf tekensets toegewezen vanaf Unicode-versie 15.1.
- Vliegtuigen 1-17 staan bekend als Aanvullende meertalige vlakken (SMP) en bevatten minder gebruikte tekensets, zoals oude schrijfsystemen zoals cuneiform en hieroglyphs, evenals speciale Chinese/Japanse/Koreaanse (CJK) tekens.
- Zie Bestanden converteren naar verschillende coderingen voor methoden voor het weergeven van tekenlengten en padgrootten en voor het beheren van de codering die naar een systeem wordt verzonden.
Unicode gebruikt unicode-transformatieindeling als standaard, waarbij UTF-8 en UTF-16 de twee hoofdindelingen zijn.
Unicode-vlakken
Unicode maakt gebruik van 17 vlakken van 65.536 tekens (256 codepunten vermenigvuldigd met 256 vakken in het vlak), met Vlak 0 als het Meertalige Basisvlak (BMP). Dit vlak bevat de meest gebruikte tekens in meerdere talen. Omdat de talen en tekensets ter wereld langer zijn dan 65536 tekens, zijn er meer vlakken nodig om minder veelgebruikte tekensets te ondersteunen.
Vlak 1 (de Aanvullende Meertalige Vliegtuigen (SMP)) bevat bijvoorbeeld historische scripts zoals cuneiform en Egyptische hieroglyfen, evenals enkele Osage, Warang Citi, Adlam, Wancho en Toto. Vlak 1 bevat ook enkele symbolen en emoticontekens .
Vliegtuig 2 – het Aanvullende Ideographic Plane (SIP) – bevat Chinese/Japanse/Koreaanse (CJK) Unified Ideographs. Tekens in vlak 1 en 2 zijn over het algemeen 4 bytes groot.
Voorbeeld:
- Het "grijnsgezicht met grote ogen" emoticon "😃" in vliegtuig 1 is 4 bytes groot.
- Het Egyptische hieroglyph "𓀀" in vliegtuig 1 is 4 bytes groot.
- Het Osage-teken '𐒸' in vlak 1 is 4 bytes groot.
- Het CJK-teken "𫝁" in vlak 2 is 4 bytes groot.
Omdat deze tekens allemaal >3 bytes groot zijn, moeten surrogaatparen goed werken. Azure NetApp Files biedt systeemeigen ondersteuning voor surrogaatparen, maar de weergave van de tekens varieert afhankelijk van het protocol dat wordt gebruikt, de landinstellingen van de client en de instellingen van de externe clienttoegangstoepassing.
UTF-8
UTF-8 maakt gebruik van 8-bits codering en kan maximaal 1.112.064 codepunten (of tekens) bevatten. UTF-8 is de standaardcodering voor alle talen in linux-besturingssystemen. Omdat UTF-8 gebruikmaakt van 8-bits codering, is het maximaal niet-ondertekende gehele getal mogelijk 255 (2^8 – 1), wat ook de maximale bestandsnaamlengte voor die codering is. UTF-8 wordt gebruikt op meer dan 98% van de pagina's op internet, waardoor het verreweg de meest gebruikte coderingsstandaard is. De Web Hypertext Application Technology Working Group (WHATWG) beschouwt UTF-8 "de verplichte codering voor alle [tekst]" en dat browsertoepassingen om veiligheidsredenen UTF-16 niet mogen gebruiken.
Tekens in UTF-8-indeling gebruiken elk 1 tot 4 bytes, maar bijna alle tekens in alle talen gebruiken tussen 1 en 3 bytes. Bijvoorbeeld:
- De Latijnse letter "A" gebruikt 1 byte. (Een van de 128 gereserveerde ASCII-tekens)
- Een copyrightsymbool '©' maakt gebruik van 2 bytes.
- Het teken 'ä' gebruikt 2 bytes. (1 byte voor "a" + 1 byte voor de umlaut)
- Het Japanse Kanji-symbool voor gegevens (資) gebruikt 3 bytes.
- Een grinning face emoji (😃) gebruikt 4 bytes.
Taallandinstellingen kunnen gebruikmaken van computerstandaard UTF-8 (C.UTF-8) of een meer regiospecifieke indeling, zoals en_US. UTF-8, ja. UTF-8, enzovoort. UTF-8-codering moet worden gebruikt voor Linux-clients wanneer u waar mogelijk toegang krijgt tot Azure NetApp Files. Vanaf OS X gebruiken macOS-clients ook UTF-8 voor de standaardcodering en moeten ze niet worden aangepast.
Windows-clients gebruiken UTF-16. In de meeste gevallen moet deze instelling blijven staan als de standaardinstelling voor de landinstelling van het besturingssysteem, maar nieuwere clients bieden bèta-ondersteuning voor UTF-8 tekens via een selectievakje. Terminalclients in Windows kunnen ook zo nodig worden aangepast voor het gebruik van UTF-8 in PowerShell of CMD. Zie Dual-protocolgedrag met speciale tekensets voor meer informatie.
UTF-16
UTF-16 maakt gebruik van 16-bits codering en kan alle 1.112.064 codepunten van Unicode coderen. De codering voor UTF-16 kan één of twee 16-bits code-eenheden gebruiken, elke 2 bytes in grootte. Alle tekens in UTF-16 gebruiken 2- of 4-bytegrootten. Tekens in UTF-16 die 4 bytes gebruiken, maken gebruik van surrogaatparen, waarbij twee afzonderlijke twee bytetekens worden gecombineerd om een nieuw teken te maken. Deze aanvullende tekens vallen buiten het standaard BMP-vlak en in een van de andere meertalige vlakken.
UTF-16 wordt gebruikt in Windows-besturingssystemen en API's, Java en JavaScript. Omdat het geen ondersteuning biedt voor achterwaartse compatibiliteit met ASCII-indelingen, is het nooit populair geworden op het web. UTF-16 is slechts ongeveer 0,002% van alle pagina's op internet. De Web Hypertext Application Technology Working Group (WHATWG) beschouwt UTF-8 "de verplichte codering voor alle tekst" en raadt toepassingen aan om UTF-16 niet te gebruiken voor browserbeveiliging.
Azure NetApp Files ondersteunt de meeste UTF-16 tekens, waaronder surrogaatparen. In gevallen waarin het teken niet wordt ondersteund, melden Windows-clients een fout van 'bestandsnaam die u hebt opgegeven, is niet geldig of te lang'.
Verwerking van tekenset via externe clients
Externe verbindingen met clients die Azure NetApp Files-volumes koppelen (zoals SSH-verbindingen met Linux-clients voor toegang tot NFS-koppelingen) kunnen worden geconfigureerd voor het verzenden en ontvangen van specifieke volumetaalcoderingen. De taalcodering die via het hulpprogramma voor externe verbindingen naar de client wordt verzonden, bepaalt hoe tekensets worden gemaakt en bekeken. Als gevolg hiervan kan een externe verbinding die gebruikmaakt van een andere taalcodering dan een andere externe verbinding (zoals twee verschillende PuTTY-vensters) verschillende resultaten weergeven voor tekens bij het weergeven van bestands- en mapnamen in het Azure NetApp Files-volume. In de meeste gevallen ontstaan er geen verschillen (zoals voor Latijnse/Engelse tekens), maar in het geval van speciale tekens, zoals emoji's, kunnen de resultaten variëren.
Als u bijvoorbeeld een codering van UTF-8 gebruikt voor de externe verbinding, worden voorspelbare resultaten weergegeven voor tekens in Azure NetApp Files-volumes, omdat C.UTF-8 de volumetaal is. Het Japanse teken voor 'data' (資) wordt anders weergegeven, afhankelijk van de codering die door de terminal wordt verzonden.
Tekencodering in PuTTY
Wanneer een PuTTY-venster gebruikmaakt van UTF-8 (gevonden in de vertaalinstellingen van Windows), wordt het teken correct weergegeven voor een gekoppeld NFSv3-volume in Azure NetApp Files:

Als in het PuTTY-venster een andere codering wordt gebruikt, zoals ISO-8859-1:1998 (Latijns-1, Europa - west), wordt hetzelfde teken anders weergegeven, ook al is de bestandsnaam hetzelfde.

PuTTY bevat standaard geen CJK-coderingen. Er zijn patches beschikbaar om deze taalsets toe te voegen aan PuTTY.
Tekencoderingen in Bastion
Microsoft Azure raadt aan Bastion te gebruiken voor externe connectiviteit met virtuele machines (VM's) in Azure. Wanneer u Bastion gebruikt, wordt de taalcodering die wordt verzonden en ontvangen niet weergegeven in de configuratie, maar maakt gebruik van standaard UTF-8-codering. Als gevolg hiervan moeten de meeste tekensets in PuTTY met UTF-8 ook zichtbaar zijn in Bastion, mits de tekensets worden ondersteund in het protocol dat wordt gebruikt.

Tip
Andere SSH-terminals kunnen worden gebruikt, zoals TeraTerm. TeraTerm biedt standaard een breder scala aan ondersteunde tekensets, waaronder CJK-coderingen en niet-standaardcoderingen zoals Shift-JIS.
Protocolgedrag met speciale tekensets
Azure NetApp Files-volumes maken gebruik van UTF-8-codering en bieden systeemeigen ondersteuning voor tekens die niet groter zijn dan 3 bytes. Alle tekens in de ASCII- en UTF-8-set worden correct weergegeven omdat ze in het bereik van 1 tot 3 bytes vallen. Voorbeeld:
- Het Latijnse alfabetteken A gebruikt 1 byte (een van de 128 gereserveerde ASCII-tekens).
- Een copyrightsymbool © maakt gebruik van 2 bytes.
- Het teken 'ä' gebruikt 2 bytes (1 byte voor 'a' en 1 byte voor de umlaut).
- Het Japanse Kanji-symbool voor gegevens (資) gebruikt 3 bytes.
Azure NetApp Files ondersteunt ook bepaalde tekens die groter zijn dan 3 bytes via surrogaatpaarlogica (zoals emoji), mits de clientcodering en protocolversie deze ondersteunt. Zie voor meer informatie over protocolgedrag:
SMB-gedrag
In SMB-volumes maakt en onderhoudt Azure NetApp Files twee namen voor bestanden of mappen in elke map die toegang heeft vanaf een SMB-client: de oorspronkelijke lange naam en een naam in 8.3-indeling.
Bestandsnamen in SMB met Azure NetApp Files
Wanneer bestands- of mapnamen de toegestane tekenbytes overschrijden of niet-ondersteunde tekens gebruiken, genereert Azure NetApp Files als volgt een 8.3-indelingsnaam:
- Hiermee wordt de oorspronkelijke naam van het bestand of de oorspronkelijke map afgekapt.
- Er wordt een tilde (~) en een numerieke waarde (1-5) toegevoegd aan bestands- of mapnamen die niet meer uniek zijn nadat ze zijn afgekapt. Als er meer dan vijf bestanden met niet-naam zijn, maakt Azure NetApp Files een unieke naam zonder relatie tot de oorspronkelijke naam. Voor bestanden kapt Azure NetApp Files de bestandsnaamextensie af tot drie tekens.
Als een NFS-client bijvoorbeeld een bestand met de naam specifications.htmlmaakt, maakt Azure NetApp Files de bestandsnaam specif~1.htm volgens de 8.3-indeling. Als deze naam al bestaat, gebruikt Azure NetApp Files een ander nummer aan het einde van de bestandsnaam. Als een NFS-client bijvoorbeeld een ander bestand met de naam specifications\_new.htmlmaakt, is de 8.3-indeling.specifications\_new.html specif~2.htm
Speciaal teken in SMB met Azure NetApp Files
Wanneer u SMB gebruikt met Azure NetApp Files-volumes, zijn tekens die groter zijn dan 3 bytes die worden gebruikt in bestands- en mapnamen (inclusief emoticons) toegestaan vanwege ondersteuning voor surrogaatpaar. Hieronder ziet u wat Windows Verkenner ziet voor tekens buiten het BMP op een map die is gemaakt op basis van een Windows-client wanneer u Engels gebruikt met de standaard-UTF-16-codering.
Notitie
Het standaardlettertype in Windows Verkenner is Segoe UI. Lettertypewijzigingen kunnen van invloed zijn op de weergave van bepaalde tekens op clients.

Hoe de tekens op de client worden weergegeven, is afhankelijk van het systeemlettertype en de taal- en landinstellingen. Over het algemeen worden tekens die in het BMP vallen ondersteund in alle protocollen, ongeacht of de codering UTF-8 of UTF-16 is.
Wanneer u CMD of PowerShell gebruikt, is de tekensetweergave afhankelijk van de lettertype-instellingen. Deze hulpprogramma's hebben standaard beperkte lettertypeopties. CMD gebruikt Consolas als het standaardlettertype.
Bestandsnamen worden mogelijk niet zoals verwacht weergegeven, afhankelijk van het lettertype dat wordt gebruikt omdat sommige consoles geen systeemeigen ondersteuning bieden voor de Segoe-gebruikersinterface of andere lettertypen die speciale tekens correct weergeven.
Dit probleem kan worden opgelost op Windows-clients met behulp van PowerShell ISE, dat krachtigere lettertypeondersteuning biedt. Als u bijvoorbeeld powerShell ISE instelt op Segoe UI, worden de bestandsnamen met ondersteunde tekens correct weergegeven.

PowerShell ISE is echter ontworpen voor het uitvoeren van scripts in plaats van voor het beheren van shares. Nieuwere Windows-versies bieden Windows Terminal, waarmee u de lettertypen en coderingswaarden kunt beheren.
Notitie
Gebruik de chcp opdracht om de codering voor de terminal weer te geven. Zie Codepagina-id's voor een volledige lijst met codepagina's.

Als het volume is ingeschakeld voor dual-protocol (zowel NFS als SMB), kunt u verschillende gedragingen observeren. Zie dual-protocolgedrag met speciale tekensets voor meer informatie.
NFS-gedrag
Hoe NFS speciale tekens weergeeft, is afhankelijk van de versie van NFS die wordt gebruikt, de landinstellingen van de client, geïnstalleerde lettertypen en de instellingen van de client voor externe verbindingen die worden gebruikt. Als u bijvoorbeeld Bastion gebruikt om toegang te krijgen tot een Ubuntu-client, wordt het teken anders weergegeven dan een PuTTY-client die is ingesteld op een andere landinstelling op dezelfde VM. De volgende NFS-voorbeelden zijn afhankelijk van deze landinstellingen voor de Ubuntu-VM:
~$ locale
LANG=C.UTF-8
LANGUAGE=
LC\_CTYPE="C.UTF-8"
LC\_NUMERIC="C.UTF-8"
LC\_TIME="C.UTF-8"
LC\_COLLATE="C.UTF-8"
LC\_MONETARY="C.UTF-8"
LC\_MESSAGES="C.UTF-8"
LC\_PAPER="C.UTF-8"
LC\_NAME="C.UTF-8"
LC\_ADDRESS="C.UTF-8"
LC\_TELEPHONE="C.UTF-8"
LC\_MEASUREMENT="C.UTF-8"
LC\_IDENTIFICATION="C.UTF-8"
LC\_ALL=
NFSv3-gedrag
NFSv3 dwingt UTF-codering niet af voor bestanden en mappen. In de meeste gevallen mogen speciale tekensets geen problemen hebben. De gebruikte verbindingsclient kan echter van invloed zijn op de wijze waarop tekens worden verzonden en ontvangen. Als u bijvoorbeeld Unicode-tekens buiten het BMP gebruikt voor een mapnaam in de Azure-verbindingsclient Bastion, kan dit leiden tot onverwacht gedrag vanwege de werking van de clientcodering.
In de volgende schermopname kan Bastion de waarden niet kopiëren en plakken naar de CLI-prompt van buiten de browser bij het benoemen van een map via NFSv3. Wanneer u de waarde probeert NFSv3Bastion𓀀𫝁😃𐒸te kopiëren en plakken, worden de speciale tekens weergegeven als aanhalingstekens in de invoer.

De opdracht kopiëren en plakken is toegestaan via NFSv3, maar de tekens worden gemaakt als hun numerieke waarden, wat van invloed is op de weergave:
NFSv3Bastion'$'\262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355
Deze weergave wordt veroorzaakt door de codering die door Bastion wordt gebruikt voor het verzenden van tekstwaarden bij het kopiëren en plakken.
Wanneer u PuTTY gebruikt om een map te maken met dezelfde tekens ten opzichte van NFSv3, wordt de mapnaam anders dan in Bastion gebruikt toen Bastion werd gebruikt om deze te maken. De emoticon wordt weergegeven zoals verwacht (vanwege de geïnstalleerde lettertypen en landinstellingen), maar de andere tekens (zoals osage '𐒸') niet.

In een PuTTY-venster worden de tekens correct weergegeven:

NFSv4.x-gedrag
NFSv4.x dwingt UTF-8-codering af in bestands- en mapnamen volgens de RFC-8881 internationalisatiespecificaties.
Als er een speciaal teken wordt verzonden met niet-UTF-8-codering, is het mogelijk dat NFSv4.x de waarde niet toestaat.
In sommige gevallen kan een opdracht worden toegestaan met behulp van een teken buiten het BMP (Basic Multilingual Plane), maar wordt de waarde mogelijk niet weergegeven nadat deze is gemaakt.
Het uitgeven mkdir met een mapnaam, inclusief de tekens '𓀀𫝁😃𐒸' (tekens in de aanvullende meertalige vlakken (SMP) en het aanvullende Ideographic Plane (SIP)) lijkt te slagen in NFSv4.x. De map is niet zichtbaar bij het uitvoeren van de ls opdracht.
root@ubuntu:/NFSv4/NFS$ mkdir "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS$ ls -la
total 8
drwxrwxr-x 3 nobody 4294967294 4096 Jan 10 17:15 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
root@ubuntu:/NFSv4/NFS$
De map bestaat in het volume. Als u de naam van de verborgen map wijzigt, werkt dit vanuit de PuTTY-client en kan een bestand in die map worden gemaakt.
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ sudo touch Unicode.txt
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ ls -la
-rw-r--r-- 1 root root 0 Jan 10 17:31 Unicode.txt
Een stat-opdracht van PuTTY bevestigt ook dat de map bestaat:
root@ubuntu:/NFSv4/NFS$ stat "NFSv4 Putty 𓀀𫝁😃𐒸"
**File: NFSv4 Putty** **𓀀**** 𫝁 ****😃**** 𐒸**
Size: 4096 Blocks: 8 IO Block: 262144 **directory**
Device: 3ch/60d Inode: 101 Links: 2
Access: (0775/drwxrwxr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-01-10 17:15:44.860775000 +0000
Modify: 2024-01-10 17:31:35.049770000 +0000
Change: 2024-01-10 17:31:35.049770000 +0000
Birth: -
Hoewel de map is bevestigd dat deze bestaat, werken opdrachten met jokertekens niet, omdat de client de map in de weergave niet officieel kan zien.
root@ubuntu:/NFSv4/NFS$ cp \* /NFSv3/
cp: can't stat '\*': No such file or directory
NFSv4.1 verzendt een fout naar de client wanneer er een teken optreedt dat niet afhankelijk is van UTF-8-codering.
Wanneer u bijvoorbeeld Bastion gebruikt om toegang te krijgen tot dezelfde map die we hebben gemaakt met PuTTY via NFSv4.1, is dit het resultaat:
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃�"
-bash: cd: $'NFSv4 Putty \262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355': Invalid argument
The "invalid argument" error message doesn't help diagnose the root cause, but a packet capture shines a light on the problem:
78 1.704856 y.y.y.y x.x.x.x NFS 346 V4 Call (Reply In 79) LOOKUP DH: 0x44caa451/NFSv4 Putty ��������
79 1.705058 x.x.x.x y.y.y.y NFS 166 V4 Reply (Call In 25) OPEN Status: NFS4ERR\_INVAL
NFS4ERR_INVAL wordt behandeld in RFC-8881.
Omdat de map toegankelijk is vanuit PuTTY (omdat de codering wordt verzonden en ontvangen), kan deze worden gekopieerd als de naam is opgegeven. Na het kopiëren van die map van het Azure NetApp Files-volume NFSv4.1 naar het NFSv3 Azure NetApp Files-volume, wordt de mapnaam weergegeven:
root@ubuntu:/NFSv4/NFS$ cp -r /NFSv4/NFS/"NFSv4 Putty 𓀀𫝁😃𐒸" /NFSv3/NFSv3/
root@ubuntu:/NFSv4/NFS$ ls -la /NFSv3/NFSv3 | grep v4
drwxrwxr-x 2 root root 4096 Jan 10 17:49 NFSv4 Putty 𓀀𫝁😃𐒸
NFS4ERR\_INVAL Dezelfde fout kan worden weergegeven als een bestandsconversie (met behulp van 'iconv') naar een niet-UTF-8-indeling wordt geprobeerd, zoals Shift-JIS.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Zie Bestanden converteren naar verschillende coderingen voor meer informatie.
Gedrag van twee protocollen
Met Azure NetApp Files kunnen volumes worden geopend door zowel NFS als SMB via toegang met twee protocollen. Vanwege de grote verschillen in de taalcodering die wordt gebruikt door NFS (UTF-8) en SMB (UTF-16), kunnen tekensets, bestands- en mapnamen en padlengten zeer verschillend gedrag hebben in verschillende protocollen.
Door NFS gemaakte bestanden en mappen van SMB weergeven
Wanneer Azure NetApp Files wordt gebruikt voor toegang met twee protocollen (SMB en NFS), kan een tekenset die niet wordt ondersteund door UTF-16, worden gebruikt in een bestandsnaam die is gemaakt met UTF-8 via NFS. In deze scenario's wordt, wanneer SMB een bestand met niet-ondersteunde tekens opent, de naam afgekapt in SMB met behulp van de korte bestandsnaamconventie 8.3.
Door NFSv3 gemaakte bestanden en SMB-gedrag met tekensets
NFSv3 dwingt UTF-8-codering niet af. Tekens die gebruikmaken van niet-standaardtaalcoderingen (zoals Shift-JIS) werken met Azure NetApp Files wanneer u NFSv3 gebruikt.
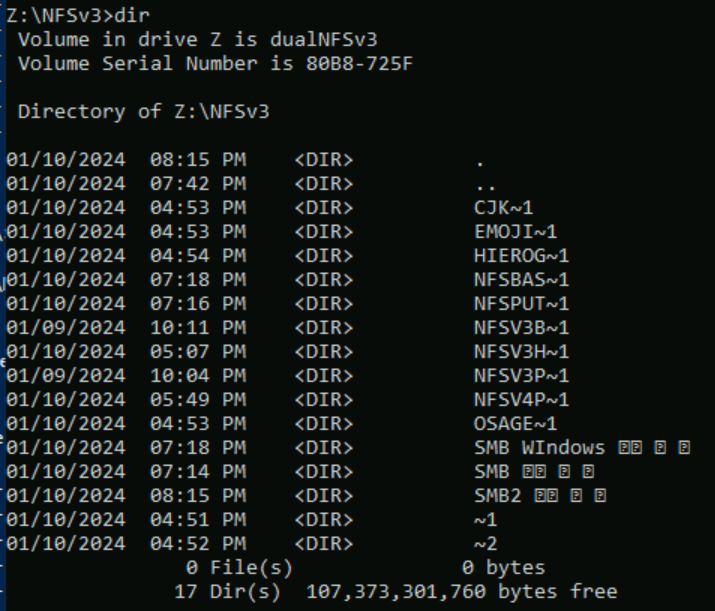
In het volgende voorbeeld zijn een reeks mapnamen met verschillende tekensets van verschillende vlakken in Unicode gemaakt in een Azure NetApp Files-volume met behulp van NFSv3. Wanneer deze worden weergegeven vanuit NFSv3, worden deze correct weergegeven.
root@ubuntu:/NFSv3/dual$ ls -la
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-English
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-Japanese-German-資ä
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-copyright-©
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-CJK-plane2-𫝁
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-emoji-plane1-😃
Vanuit Windows SMB worden de mappen met tekens in de BMP-weergave correct weergegeven, maar tekens buiten dat vlak worden weergegeven met de 8.3-naamnotatie omdat de UTF-8/UTF-16-conversie niet compatibel is voor deze tekens.
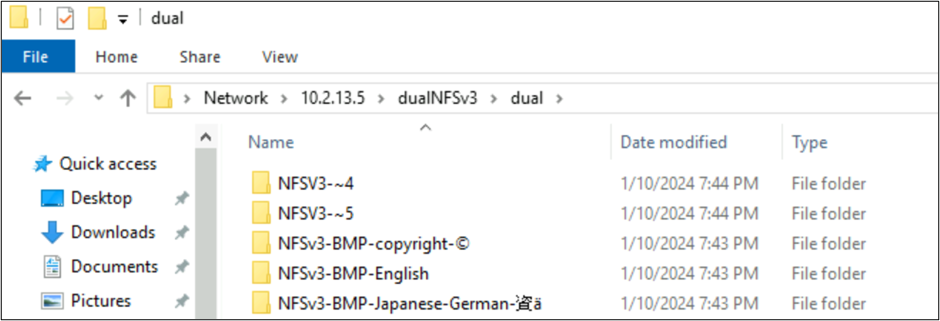
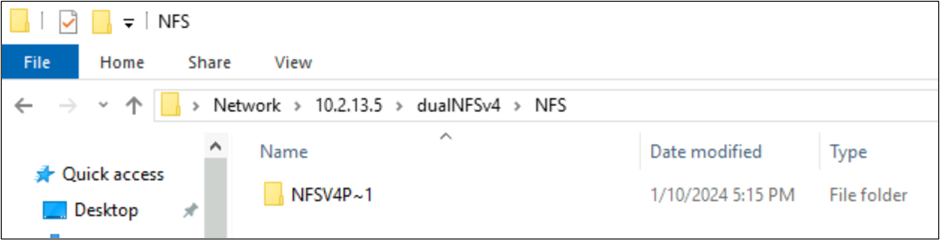
Door NFSv4.1 gemaakte bestanden en SMB-gedrag met tekensets
In de vorige voorbeelden is een map met de naam NFSv4 Putty 𓀀𫝁😃𐒸 gemaakt op een Azure NetApp Files-volume via NFSv4.1, maar kan deze niet worden weergegeven met NFSv4.1. Het kan echter worden gezien met behulp van SMB. De naam wordt afgekapt in SMB naar een ondersteunde 8.3-indeling vanwege de niet-ondersteunde tekensets die zijn gemaakt op basis van de NFS-client en de incompatibele UTF-8/UTF-16-conversie voor tekens in verschillende Unicode-vlakken.
Wanneer een mapnaam standaard UTF-8 tekens gebruikt die in het BMP (Engels of anderszins) zijn gevonden, worden de namen door SMB correct vertaald.
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-English
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-資ä
root@ubuntu:/NFSv4/NFS$ ls -la
total 16
drwxrwxr-x 5 nobody 4294967294 4096 Jan 10 18:26 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
**drwxrwxr-x 2 root root 4096 Jan 10 18:21 NFS-created-English**
**drwxrwxr-x 2 root root 4096 Jan 10 18:26 NFS-created-**** 資 ****ä**
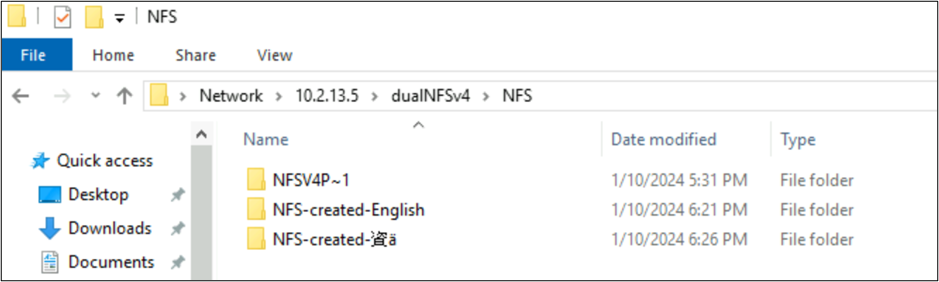
Door SMB gemaakte bestanden en mappen via NFS
Windows-clients zijn het primaire type clients dat wordt gebruikt voor toegang tot SMB-shares. Deze clients zijn standaard ingesteld op UTF-16-codering. Het is mogelijk om bepaalde met UTF-8 gecodeerde tekens in Windows te ondersteunen door deze in te schakelen in regio-instellingen:
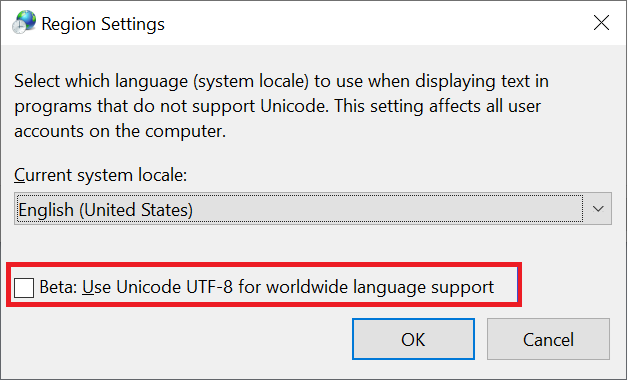
Wanneer een bestand of map wordt gemaakt via een SMB-share in Azure NetApp Files, wordt de tekenset gecodeerd als UTF-16. Als gevolg hiervan kunnen clients die UTF-8-codering gebruiken (zoals op Linux gebaseerde NFS-clients) sommige tekensets mogelijk niet correct vertalen, met name tekens die buiten het BMP (Basic Multilingual Plane) vallen.
Niet-ondersteund tekengedrag
Wanneer in deze scenario's een NFS-client een bestand opent dat is gemaakt met SMB met niet-ondersteunde tekens, wordt de naam weergegeven als een reeks numerieke waarden die de Unicode-waarden voor het teken vertegenwoordigen.
Deze map is bijvoorbeeld gemaakt in Windows Verkenner met tekens buiten het BMP.
PS Z:\SMB\> dir
Directory: Z:\SMB
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/9/2024 9:53 PM SMB𓀀𫝁😃𐒸
In plaats van NFSv3 wordt de door SMB gemaakte map weergegeven:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 9 21:53 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Via NFSv4.1 wordt de door SMB gemaakte map als volgt weergegeven:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 4 17:09 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Ondersteund tekengedrag
Wanneer de tekens zich in de BMP bevinden, zijn er geen problemen tussen de SMB- en NFS-protocollen en de bijbehorende versies.
Een mapnaam die is gemaakt met behulp van SMB op een Azure NetApp Files-volume met tekens in de BMP in meerdere talen (Engels, Duits, Cyrillisch, Runic) wordt bijvoorbeeld prima weergegeven in alle protocollen en versies.
- Basic Latin "SMB"
- Grieks "ͶΘΩ"
- Cyrillisch "ЄЊ"
- Runic "ᚠᚱᛯ"
- CJK-compatibiliteits-Ideographs "豈滑虜"
Dit is hoe de naam wordt weergegeven in SMB:
PS Z:\SMB\> mkdir SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/11/2024 8:00 PM SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Dit is hoe de naam wordt weergegeven in NFSv3:
$ ls | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Zo wordt de naam van NFSv4.1 weergegeven:
$ ls /NFSv4/SMB | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Bestanden converteren naar verschillende coderingen
Bestands- en mapnamen zijn niet de enige gedeelten van bestandssysteemobjecten die gebruikmaken van taalcoderingen. Bestandsinhoud (zoals speciale tekens in een tekstbestand) kan ook een rol spelen. Als een bestand bijvoorbeeld wordt opgeslagen met speciale tekens in een niet-compatibele indeling, kan er een foutbericht worden weergegeven. In dit geval kan een bestand met Katagana-tekens niet worden opgeslagen in ANSI, omdat deze tekens niet bestaan in die codering.
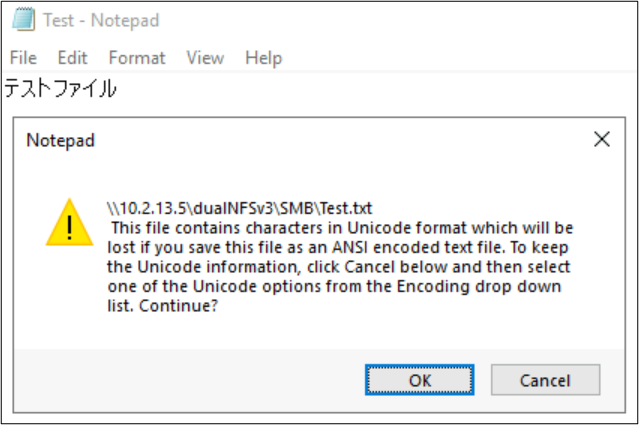
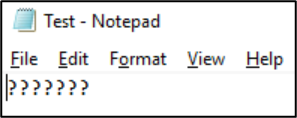
Zodra dat bestand in die indeling is opgeslagen, worden de tekens geconverteerd naar vraagtekens:
Bestandscoderingen kunnen worden bekeken vanaf NAS-clients. Op Windows-clients kunt u een toepassing zoals Kladblok of Kladblok++ gebruiken om een codering van een bestand weer te geven. Als Windows-subsysteem voor Linux (WSL) of Git op de client zijn geïnstalleerd, kan de file opdracht worden gebruikt.
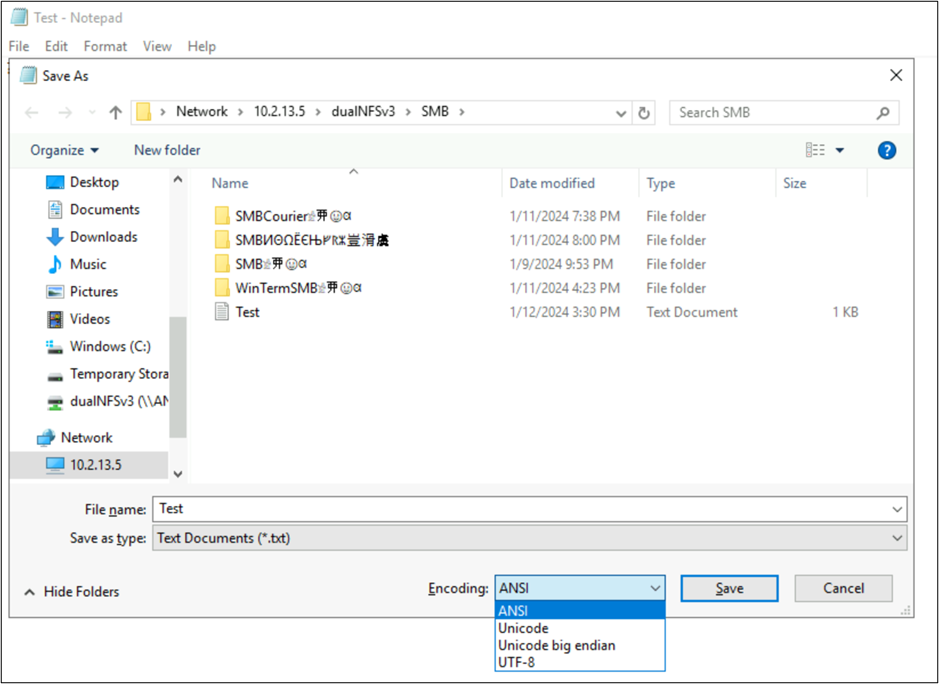
Met deze toepassingen kunt u ook de codering van het bestand wijzigen door op te slaan als verschillende coderingstypen. Daarnaast kan PowerShell worden gebruikt om codering te converteren naar bestanden met de Get-Content en Set-Content cmdlets.
Het bestand utf8-text.txt wordt bijvoorbeeld gecodeerd als UTF-8 en bevat tekens buiten het BMP. Omdat UTF-8 wordt gebruikt, worden de tekens correct weergegeven.
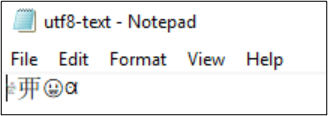
Als de codering wordt geconverteerd naar UTF-32, worden de tekens niet correct weergegeven.
PS Z:\SMB\> Get-Content .\utf8-text.txt |Set-Content -Encoding UTF32 -Path utf32-text.txt
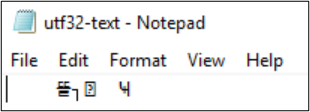
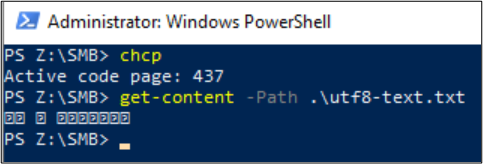
Get-Content kan ook worden gebruikt om de bestandsinhoud weer te geven. PowerShell maakt standaard gebruik van UTF-16-codering (codepagina 437) en de lettertypeselecties voor de console zijn beperkt, zodat het bestand met de UTF-8-indeling met speciale tekens niet correct kan worden weergegeven:
Linux-clients kunnen de file opdracht gebruiken om de codering van het bestand weer te geven. Als er in omgevingen met twee protocollen een bestand wordt gemaakt met behulp van SMB, kan de Linux-client met behulp van NFS de bestandscodering controleren.
$ file -i utf8-text.txt
utf8-text.txt: text/plain; charset=utf-8
$ file -i utf32-text.txt
utf32-text.txt: text/plain; charset=utf-32le
Conversie van bestandscodering kan worden uitgevoerd op Linux-clients met behulp van de iconv opdracht. Als u de lijst met ondersteunde coderingsindelingen wilt bekijken, gebruikt u iconv -l.
Het met UTF-8 gecodeerde bestand kan bijvoorbeeld worden geconverteerd naar UTF-16.
$ iconv -t UTF16 utf8-text.txt \> utf16-text.txt
$ file -i utf8-text.txt
utf8-text.txt: text/plain; **charset=utf-8**
$ file -i utf16-text.txt
utf16-text.txt: text/plain; **charset=utf-16le**
Als de tekenset op de naam van het bestand of in de inhoud van het bestand niet wordt ondersteund door de doelcodering, is conversie niet toegestaan. Shift-JIS biedt bijvoorbeeld geen ondersteuning voor de tekens in de inhoud van het bestand.
$ iconv -t SJIS utf8-text.txt SJIS-text.txt
iconv: illegal input sequence at position 0
Als een bestand tekens bevat die worden ondersteund door de codering, slaagt de conversie. Als het bestand bijvoorbeeld de Katagana-tekens bevat テストファイル, slaagt shift-JIS-conversie via NFS. Omdat de NFS-client die hier wordt gebruikt, shift-JIS niet begrijpt vanwege landinstellingen, toont de codering 'unknown-8bit'.
$ cat SJIS.txt
テストファイル
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
$ iconv -t SJIS SJIS.txt \> SJIS2.txt
$ file -i SJIS.txt
SJIS.txt: text/plain; **charset=utf-8**
$ file -i SJIS2.txt
SJIS2.txt: text/plain; **charset=unknown-8bit**
Omdat Azure NetApp Files-volumes alleen ondersteuning bieden voor UTF-8-compatibele opmaak, worden de Katagana-tekens geconverteerd naar een onleesbare indeling.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Bij gebruik van NFSv4.x is conversie toegestaan wanneer niet-compatibele tekens aanwezig zijn in de inhoud van het bestand, ook al dwingt NFSv4.x UTF-8-codering af. In dit voorbeeld toont een UTF-8 gecodeerd bestand met Katagana-tekens op een Azure NetApp Files-volume de inhoud van een bestand correct.
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
S$ cat SJIS.txt
テストファイル
Maar als het eenmaal is geconverteerd, worden de tekens in het bestand onjuist weergegeven vanwege de incompatibele codering.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Als de naam van het bestand niet-ondersteunde tekens voor UTF-8 bevat, slaagt de conversie via NFSv3, maar voert een failover uit van NFSv4.x vanwege de UTF-8-afdwinging van de protocolversie.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Aanbevolen procedures voor tekenset
Wanneer u speciale tekens of tekens buiten de standaard BMP (Basic Multilingual Plane) op Azure NetApp Files-volumes gebruikt, moeten enkele aanbevolen procedures in overweging worden genomen.
- Omdat Azure NetApp Files-volumes gebruikmaken van UTF-8-volumetaal, moet de bestandscodering voor NFS-clients ook UTF-8-codering gebruiken voor consistente resultaten.
- Tekensets in bestandsnamen of in de bestandsinhoud moeten UTF-8 compatibel zijn voor de juiste weergave en functionaliteit.
- Omdat SMB gebruikmaakt van UTF-16-tekencodering, worden tekens buiten het BMP mogelijk niet goed weergegeven via NFS in volumes met twee protocollen. Minimaliseer zo mogelijk het gebruik van speciale tekens in bestandsinhoud.
- Vermijd het gebruik van speciale tekens buiten de BMP in bestandsnamen, met name wanneer u NFSv4.1- of dual-protocolvolumes gebruikt.
- Voor tekensets die niet in de BMP staan, moet UTF-8-codering het weergeven van de tekens in Azure NetApp Files toestaan bij gebruik van één bestandsprotocol (alleen SMB of alleen NFS). Volumes met twee protocollen kunnen echter in de meeste gevallen niet worden gebruikt voor deze tekensets.
- Niet-standaardcodering (zoals Shift-JIS) wordt niet ondersteund op Azure NetApp Files-volumes.
- Surrogaatpaartekens (zoals emoji) worden ondersteund op Azure NetApp Files-volumes.