Zelfstudie: Gegevens synchroniseren van SQL Edge naar Azure Blob Storage met behulp van Azure Data Factory
Belangrijk
Azure SQL Edge biedt geen ondersteuning meer voor het ARM64-platform.
In deze zelfstudie leert u hoe u Azure Data Factory gebruikt om gegevens incrementeel te synchroniseren met Azure Blob Storage vanuit een tabel in een exemplaar van Azure SQL Edge.
Voordat u begint
Als u nog geen database of tabel hebt gemaakt in uw implementatie van Azure SQL Edge, gebruikt u een van de volgende methoden om er een te maken:
Gebruik SQL Server Management Studio of Azure Data Studio om verbinding te maken met SQL Edge. Voer een SQL-script uit om de database en tabel te maken.
Maak een database en tabel met behulp van sqlcmd door rechtstreeks verbinding te maken met de SQL Edge-module. Zie sqlcmd - Connect to the Database Engine (sqlcmd: verbinding maken met de database-engine) voor meer informatie.
Gebruik SQLPackage.exe om een DAC-pakketbestand te implementeren in de SQL Edge-container. U kunt dit proces automatiseren door de URI van het SqlPackage-bestand op te geven als onderdeel van de configuratie met de gewenste eigenschappen van de module. U kunt ook rechtstreeks het clienthulpprogramma SqlPackage.exe gebruiken om een DAC-pakket te implementeren in SQL Edge.
Zie Download and install sqlpackage (SqlPackage downloaden en installeren) voor meer informatie over het downloaden van SqlPackage.exe. Hier volgen enkele voorbeelden van opdrachten voor SqlPackage.exe. Raadpleeg de documentatie van SqlPackage.exe voor meer informatie.
Een DAC-pakket maken
sqlpackage /Action:Extract /SourceConnectionString:"Data Source=<Server_Name>,<port>;Initial Catalog=<DB_name>;User ID=<user>;Password=<password>" /TargetFile:<dacpac_file_name>Een DAC-pakket toepassen
sqlpackage /Action:Publish /Sourcefile:<dacpac_file_name> /TargetServerName:<Server_Name>,<port> /TargetDatabaseName:<DB_Name> /TargetUser:<user> /TargetPassword:<password>
Een SQL-tabel en -procedure maken om de watermerkniveaus op te slaan en bij te werken
Een watermerktabel wordt gebruikt om een stempel op te slaan met de tijd waarop gegevens voor het laatst zijn gesynchroniseerd met Azure Storage. De watermerktabel wordt na elke synchronisatie bijgewerkt via een opgeslagen Transact-SQL-procedure (T-SQL).
Voer deze opdrachten uit in de instantie van SQL Edge:
CREATE TABLE [dbo].[watermarktable] (
TableName VARCHAR(255),
WatermarkValue DATETIME,
);
GO
CREATE PROCEDURE usp_write_watermark @timestamp DATETIME,
@TableName VARCHAR(50)
AS
BEGIN
UPDATE [dbo].[watermarktable]
SET [WatermarkValue] = @timestamp
WHERE [TableName] = @TableName;
END
GO
Een Data Factory-pijplijn maken
In deze sectie maakt u een Azure Data Factory-pijplijn om gegevens vanuit een tabel in Azure SQL Edge te synchroniseren met Azure Blob-opslag.
Een data factory maken via de gebruikersinterface van Data Factory
Maak een data factory door de instructies in deze zelfstudie te volgen.
Een Data Factory-pijplijn maken
Selecteer Pijplijn maken op de pagina Aan de slag in de gebruikersinterface van Data Factory.

Voer op de pagina Algemeen van het venster Eigenschappen voor de pijplijn de naam PeriodicSync in.
Voeg een opzoekactiviteit toe om de oude watermerkwaarde op te halen. Vouw in het deelvenster Activiteiten de optie Algemeen uit en sleep de activiteit Opzoeken naar het gebied voor het ontwerpen van pijplijnen. Wijzig de naam van de activiteit in OldWatermark.
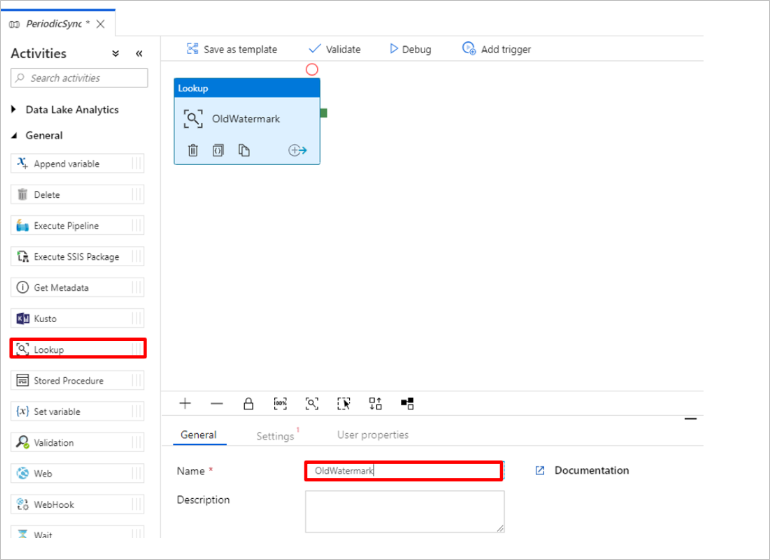
Ga naar het tabblad Instellingen en selecteer Nieuw voor Brongegevensset. U gaat nu een gegevensset maken die de gegevens in de watermerktabel vertegenwoordigt. Deze tabel bevat de oude grenswaarde die is gebruikt in de vorige kopieerbewerking.
Selecteer in het venster Nieuwe gegevensset de optie Azure SQL Server en selecteer vervolgens Doorgaan.
Ga in het venster Eigenschappen instellen voor de gegevensset naar Naam en voer WatermarkDataset in.
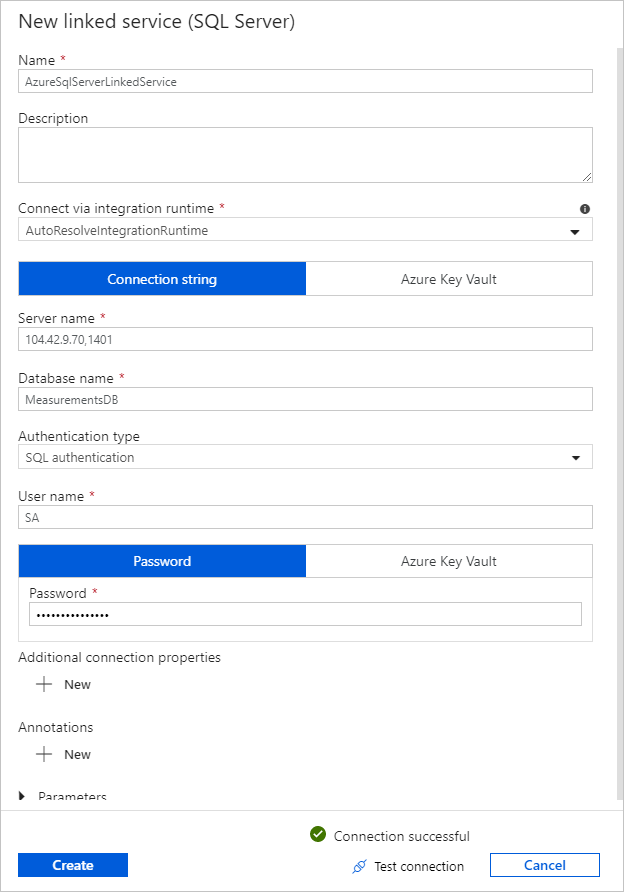
Selecteer Nieuw voor Gekoppelde serviceen voer deze stappen uit:
Voer SQLDBEdgeLinkedService in bij Naam.
Voer bij Servernaam de gegevens van de SQL Edge-server in.
Selecteer de naam van uw database in de lijst bij Databasenaam.
Geef waarden op voor Gebruikersnaam en Wachtwoord.
Als u de verbinding met de instantie van SQL Edge wilt testen, selecteert u Verbinding testen.
Selecteer Maken.
Selecteer OK.
Selecteer Bewerkenop het tabblad Instellingen.
Selecteer op het tabblad Verbinding maken ion de optie
[dbo].[watermarktable]Tabel. Als u eerst een voorbeeld van de gegevens in de tabel wilt bekijken, klikt u op Gegevens vooraf bekijken.Ga naar de pijplijneditor door bovenaan op het tabblad Pijplijn te klikken of door de naam van de pijplijn te selecteren in de structuurweergave aan de linkerkant. Controleer of in het eigenschappenvenster voor de opzoekactiviteit WatermarkDataset is geselecteerd in de lijst Brongegevensset.
Vouw in het deelvenster Activiteiten de optie Algemeen uit en sleep een andere activiteit Opzoeken naar het gebied voor het ontwerpen van pijplijnen. Geef de activiteit de naam NewWatermark op het tabblad Algemeen van het eigenschappenvenster. Met deze opzoekactiviteit wordt de nieuwe watermerkwaarde opgehaald uit de tabel met de brongegevens, zodat deze kan worden gekopieerd naar de bestemming.
Ga in het eigenschappenvenster voor de tweede opzoekactiviteit naar het tabblad Instellingen en selecteer Nieuw om een gegevensset te maken die verwijst naar de brontabel die de nieuwe watermerkwaarde bevat.
Selecteer in het venster Nieuwe gegevensset de optie SQL Edge-instantie en selecteer vervolgens Doorgaan.
Voer in het venster Eigenschappen instellen onder NaamSourceDataset in. Selecteer SQLDBEdgeLinkedService bij Gekoppelde service.
Selecteer bij Tabelde tabel die u wilt synchroniseren. U kunt ook een query opgeven voor deze gegevensset, zoals verderop in deze zelfstudie wordt beschreven. De query heeft voorrang op de tabel die u in deze stap opgeeft.
Selecteer OK.
Ga naar de pijplijneditor door bovenaan op het tabblad Pijplijn te klikken of door de naam van de pijplijn te selecteren in de structuurweergave aan de linkerkant. Controleer of in het eigenschappenvenster voor de opzoekactiviteit SourceDataset is geselecteerd in de lijst Brongegevensset.
Selecteer Query bij Query gebruiken. Werk de tabelnaam in de volgende query bij en voer vervolgens de query uit. U selecteert alleen de maximumwaarde van
timestampin de tabel. Zorg ervoor dat u Alleen eerste rij selecteert.SELECT MAX(timestamp) AS NewWatermarkValue FROM [TableName];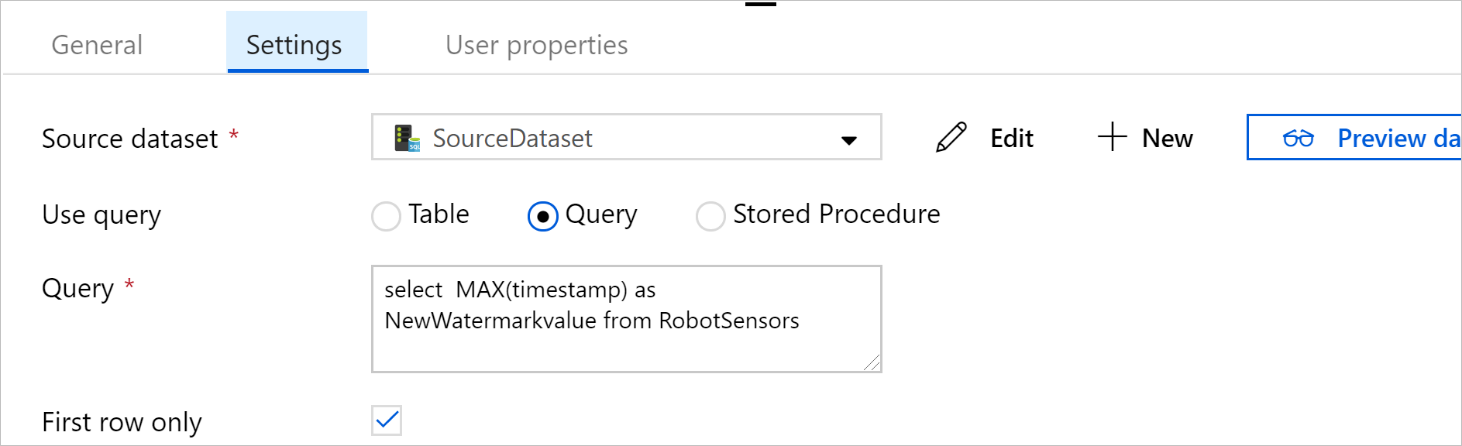
Vouw in het deelvenster Activiteiten de optie Verplaatsen en transformeren uit en sleep de activiteit Kopiëren van het deelvenster Activiteiten naar het ontwerpgebied. Stel de naam van de activiteit in op IncrementalCopy.
Verbind beide opzoekactiviteiten met de activiteit Kopiëren door de groene knop die is vastgemaakt aan de opzoekactiviteiten naar de activiteit Kopiëren te slepen. Laat de muisknop los als de rand van de activiteit Kopiëren blauw wordt.
Selecteer de activiteit Kopiëren en controleer of de eigenschappen voor de activiteit worden weergegeven in het venster Eigenschappen.
Ga naar het tabblad Bron in het venster Eigenschappen en voer deze stappen uit:
Selecteer SourceDataset in het vak Brongegevensset.
Selecteer Query bij Query gebruiken.
Typ de SQL-query in het vak Query. Hier ziet u een voorbeeld:
SELECT * FROM TemperatureSensor WHERE timestamp > '@{activity(' OldWaterMark ').output.firstRow.WatermarkValue}' AND timestamp <= '@{activity(' NewWaterMark ').output.firstRow.NewWatermarkvalue}';Selecteer op het tabblad Sink de optie Nieuw onder Sink-gegevensset.
In deze zelfstudie is het sink-gegevensarchief een gegevensarchief van Azure Blob Storage. Selecteer Azure Blob-opslag en selecteer vervolgens Doorgaan in het venster Nieuwe gegevensset.
Selecteer in het venster Indeling selecteren de indeling van uw gegevens en selecteer vervolgens Doorgaan.
Geef in het venster Eigenschappen instellen bij Naam de naam SinkDataset op. Selecteer Nieuw bij Gekoppelde service. U gaat nu een verbinding (gekoppelde service) maken met de Azure Blob-opslag.
Voer deze stappen uit in het venster Nieuwe gekoppelde service (Azure Blob-opslag):
Geef in het vak Naam de naam AzureStorageLinkedService op.
Selecteer bij Naam van opslagaccount het Azure-opslagaccount voor uw Azure-abonnement.
Test de verbinding en selecteer vervolgens Voltooien.
Controleer of in het venster Eigenschappen instellenAzureStorageLinkedService is geselecteerd bij Gekoppelde service. Selecteer Maken en OK.
Selecteer Bewerken op het tabblad Sink.
Ga naar het tabblad Verbinding van SinkDataset en voer deze stappen uit:
Voer onder Bestandspad de
asdedatasyncnaam van de blobcontainer in enincrementalcopyis de mapnaamasdedatasync/incrementalcopy. Maak de container als deze niet bestaat of gebruik de naam van een bestaande container. Azure Data Factory maakt automatisch de uitvoermapincrementalcopyals deze niet bestaat. U kunt ook de knop Bladeren voor het bestandspad gebruiken om naar een map in een blob-container te navigeren.Voor het bestandsgedeelte van het bestandspad selecteert u Dynamische inhoud toevoegen [Alt+P] en voert u
@CONCAT('Incremental-', pipeline().RunId, '.txt')het venster in dat wordt geopend. Selecteer Voltooien. De bestandsnaam wordt dynamisch gegenereerd met behulp van de expressie. Elke pijplijnuitvoering heeft een unieke id. De kopieeractiviteit gebruikt de run-id om de bestandsnaam te genereren.
Ga naar de pijplijneditor door bovenaan op het tabblad Pijplijn te klikken of door de naam van de pijplijn te selecteren in de structuurweergave aan de linkerkant.
Vouw in het deelvenster Activiteiten de optie Algemeen uit en sleep de activiteit Opgeslagen procedure van het deelvenster Activiteiten naar het ontwerpgebied voor pijplijnen. Verbind de groene uitvoer (geslaagd) van de activiteit Kopiëren met de activiteit Opgeslagen procedure.
Selecteer Opgeslagen procedureactiviteit in de ontwerpfunctie voor pijplijnen en wijzig de naam ervan in
SPtoUpdateWatermarkActivity.Ga naar het tabblad SQL-account en selecteer *QLDBEdgeLinkedService bij Gekoppelde service.
Ga naar het tabblad Opgeslagen procedure en voer deze stappen uit:
Selecteer onder De naam van de opgeslagen procedure de optie
[dbo].[usp_write_watermark].Als u waarden wilt opgeven voor de parameters van de opgeslagen procedure, selecteert u Importparameter en voert u deze waarden in voor de parameters:
Name Type Weergegeven als LastModifiedTime Datum en tijd @{activity('NewWaterMark').output.firstRow.NewWatermarkvalue}TableName String @{activity('OldWaterMark').output.firstRow.TableName}Klik in de werkbalk op Valideren om de instellingen voor de pijplijn te valideren. Controleer of er geen validatiefouten zijn. Selecteer >> om het venster Pijplijnvalidatierapport te sluiten.
Publiceer de entiteiten (gekoppelde services, gegevenssets en pijplijnen) naar de Azure Data Factory-service door de knop Alles publiceren te selecteren. Wacht totdat er een bericht verschijnt dat de publicatie is voltooid.
Een pijplijn activeren op basis van een planning
Selecteer op de werkbalk van de pijplijn Trigger toevoegen, selecteer Nieuw/bewerken en selecteer ten slotte Nieuw.
Geef de trigger de naam HourlySync. Selecteer onder Type de optie Planning. Stel de optie Herhaling in op 1 uur.
Selecteer OK.
Selecteer Alles publiceren.
Selecteer Nu activeren.
Ga naar het tabblad Controleren aan de linkerkant. U kunt de status van de pijplijnuitvoering zien die is geactiveerd met de handmatige trigger. Selecteer Vernieuwen om de lijst te vernieuwen.
Volgende stappen
- Met de Azure Data Factory-pijplijn uit deze zelfstudie worden gegevens in een tabel in een SQL Edge-instantie ieder uur gekopieerd naar een locatie in Azure Blob-opslag. Doorloop deze zelfstudies voor meer informatie over het gebruiken van Data Factory in andere scenario's.