Gegevens verplaatsen tussen uitgeschaalde clouddatabases
Van toepassing op:![]() Azure SQL Database
Azure SQL Database
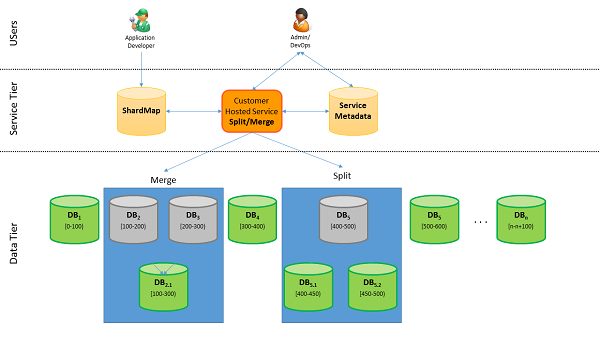
Als u een Software as a Service-ontwikkelaar bent en plotseling uw app enorme vraag ondergaat, moet u rekening houden met de groei. U voegt dus meer databases (shards) toe. Hoe kunt u de gegevens opnieuw distribueren naar de nieuwe databases zonder de gegevensintegriteit te verstoren? Gebruik het hulpprogramma splitsen en samenvoegen om gegevens van beperkte databases naar de nieuwe databases te verplaatsen.
Het hulpprogramma voor splitsen samenvoegen wordt uitgevoerd als een Azure-webservice. Een beheerder of ontwikkelaar gebruikt het hulpprogramma om shardlets (gegevens uit een shard) tussen verschillende databases (shards) te verplaatsen. Het hulpprogramma maakt gebruik van shard-toewijzingsbeheer om de database met metagegevens van de service te onderhouden en consistente toewijzingen te garanderen.
Downloaden
Microsoft.Azure.SqlDatabase.ElasticScale.Service.SplitMerge
Documentatie
- Zelfstudie voor het splitsen en samenvoegen van elastische databases
- Beveiligingsconfiguratie splitsen en samenvoegen
- Beveiligingsoverwegingen voor splitsen en samenvoegen
- Shard-toewijzingsbeheer
- Bestaande databases migreren voor uitschaling
- Hulpprogramma's voor elastische databases
- Woordenlijst voor hulpprogramma's voor Elastic Database
Waarom het hulpprogramma voor splitsen samenvoegen gebruiken
Flexibiliteit
Toepassingen moeten flexibel worden uitgebreid buiten de grenzen van één database in Azure SQL Database. Gebruik het hulpprogramma om gegevens naar behoefte naar nieuwe databases te verplaatsen terwijl de integriteit behouden blijft.
Splitsen om te groeien
Als u de totale capaciteit voor het afhandelen van explosieve groei wilt vergroten, maakt u extra capaciteit door de gegevens te sharden en door deze over incrementeel meer databases te distribueren totdat aan de capaciteitsbehoeften is voldaan. Dit is een uitstekend voorbeeld van de gesplitste functie.
Samenvoegen om te verkleinen
Capaciteit moet worden verkleind vanwege de seizoensgebonden aard van een bedrijf. Met het hulpprogramma kunt u omlaag schalen naar minder schaaleenheden wanneer het bedrijf traag is. De samenvoegfunctie in de splitssamenvoegservice voor elastisch schalen heeft betrekking op deze vereiste.
Hotspots beheren door shardlets te verplaatsen
Met meerdere tenants per database kan de toewijzing van shardlets aan shards leiden tot capaciteitsknelpunten op sommige shards. Hiervoor moet u shardlets opnieuw toewijzen of bezige shardlets verplaatsen naar nieuwe of minder gebruikte shards.
Concepten en belangrijke functies
Door de klant gehoste services
De splitssamenvoeging wordt geleverd als een door de klant gehoste service. U moet de service implementeren en hosten in uw Microsoft Azure-abonnement. Het pakket dat u downloadt van NuGet bevat een configuratiesjabloon die u kunt voltooien met de informatie voor uw specifieke implementatie. Zie de zelfstudie voor splitsen en samenvoegen voor meer informatie. Omdat de service wordt uitgevoerd in uw Azure-abonnement, kunt u de meeste beveiligingsaspecten van de service beheren en configureren. De standaardsjabloon bevat de opties voor het configureren van TLS, clientverificatie op basis van certificaten, versleuteling voor opgeslagen referenties, DoS-beveiliging en IP-beperkingen. Meer informatie over de beveiligingsaspecten vindt u in het volgende document over de beveiligingsconfiguratie voor splitsen en samenvoegen.
De standaard geïmplementeerde service wordt uitgevoerd met één werkrol en één webrol. Elke toepassing maakt gebruik van de grootte van de A1-VM in Azure Cloud Services. Hoewel u deze instellingen niet kunt wijzigen bij het implementeren van het pakket, kunt u deze wijzigen na een geslaagde implementatie in de actieve cloudservice (via Azure Portal). Houd er rekening mee dat de werkrol niet mag worden geconfigureerd voor meer dan één exemplaar om technische redenen.
Shard-kaartintegratie
De split-merge-service communiceert met de shard-toewijzing van de toepassing. Wanneer u de split-merge-service gebruikt om bereiken te splitsen of samen te voegen of shardlets tussen shards te verplaatsen, houdt de service de shard-toewijzing automatisch up-to-date. Hiervoor maakt de service verbinding met de shard-toewijzingsbeheerdatabase van de toepassing en onderhoudt de bereiken en toewijzingen als voortgang van splits-/samenvoeg-/verplaatsingsaanvragen. Dit zorgt ervoor dat de shard-kaart altijd een actuele weergave weergeeft wanneer bewerkingen voor splitsen en samenvoegen worden uitgevoerd. Splits-, samenvoeg- en shardlet-verplaatsingsbewerkingen worden geïmplementeerd door een batch shardlets van de bronshard naar de doelshard te verplaatsen. Tijdens de verplaatsingsbewerking voor shardleten worden de shardlets die aan de huidige batch zijn onderworpen, gemarkeerd als offline in de shard-toewijzing en zijn ze niet beschikbaar voor gegevensafhankelijke routeringsverbindingen met behulp van de Open Verbinding maken ionForKey-API.
Consistente shardlet-verbindingen
Wanneer de gegevensverplaatsing voor een nieuwe batch shardlets begint, worden alle shard-toewijzingsverbindingen die gegevensafhankelijke routeringsverbindingen met de shard-opslag van de shardlet bevatten, gedood en worden volgende verbindingen van de shard-toewijzings-API's naar de shardlets geblokkeerd terwijl de gegevensverplaatsing wordt uitgevoerd om inconsistenties te voorkomen. Verbinding maken ions naar andere shardlets op dezelfde shard worden ook gedood, maar slaagt onmiddellijk opnieuw bij opnieuw proberen. Zodra de batch is verplaatst, worden de shardlets opnieuw online gemarkeerd voor de doelshard en worden de brongegevens uit de bronshard verwijderd. De service doorloopt deze stappen voor elke batch totdat alle shardlets zijn verplaatst. Dit leidt tot verschillende kill-bewerkingen voor verbindingen tijdens de volledige splits-/samenvoeg-/verplaatsingsbewerking.
Beschikbaarheid van shardlet beheren
Als u de verbinding beperkt tot de huidige batch met shardlets, zoals hierboven is besproken, beperkt u het bereik van niet-beschikbaarheid tot één batch shardlets tegelijk. Dit heeft de voorkeur boven een benadering waarbij de volledige shard offline blijft voor alle shardlets tijdens een splits- of samenvoegbewerking. De grootte van een batch, gedefinieerd als het aantal afzonderlijke shardlets dat tegelijk moet worden verplaatst, is een configuratieparameter. Deze kan worden gedefinieerd voor elke splits- en samenvoegbewerking, afhankelijk van de beschikbaarheid en prestatiebehoeften van de toepassing. Houd er rekening mee dat het bereik dat is vergrendeld in de shard-toewijzing mogelijk groter is dan de opgegeven batchgrootte. Dit komt doordat de service de bereikgrootte kiest, zodat het werkelijke aantal sharding-sleutelwaarden in de gegevens ongeveer overeenkomt met de batchgrootte. Dit is belangrijk om te onthouden met name voor sparse gevulde shardingsleutels.
Metagegevensopslag
De service voor splitsen samenvoegen maakt gebruik van een database om de status te behouden en logboeken te bewaren tijdens het verwerken van aanvragen. De gebruiker maakt deze database in zijn of haar abonnement en levert de verbindingsreeks voor deze database in het configuratiebestand voor de service-implementatie. Beheer istrators van de organisatie van de gebruiker kunnen ook verbinding maken met deze database om de voortgang van de aanvraag te controleren en gedetailleerde informatie over mogelijke fouten te onderzoeken.
Sharding-awareness
De split-merge-service maakt onderscheid tussen (1) shardtabellen, (2) referentietabellen en (3) normale tabellen. De semantiek van een bewerking splitsen/samenvoegen/verplaatsen is afhankelijk van het type tabel dat wordt gebruikt en wordt als volgt gedefinieerd:
Shard-tabellen
Splits-, samenvoeg- en verplaatsingsbewerkingen verplaatsen shardlets van de bron naar de doelshard. Nadat de algehele aanvraag is voltooid, zijn deze shardlets niet meer aanwezig op de bron. Houd er rekening mee dat de doeltabellen moeten bestaan op de doelhard en geen gegevens mogen bevatten in het doelbereik voordat de bewerking wordt verwerkt.
Referentietabellen
Voor referentietabellen kopieert de splits-, samenvoeg- en verplaatsingsbewerkingen de gegevens van de bron naar de doelshard. Houd er echter rekening mee dat er geen wijzigingen optreden in de doelshard voor een bepaalde tabel als er al een rij aanwezig is in deze tabel op het doel. De tabel moet leeg zijn voor elke kopieerbewerking van een verwijzingstabel om te worden verwerkt.
Andere tabellen
Andere tabellen kunnen aanwezig zijn op de bron of het doel van een splits- en samenvoegbewerking. De split-merge-service negeert deze tabellen voor gegevensverplaatsing of kopieerbewerkingen. Houd er echter rekening mee dat ze deze bewerkingen kunnen verstoren in geval van beperkingen.
De informatie over naslagtabellen versus shardtabellen wordt verstrekt door de
SchemaInfoAPI's op de shard-kaart. In het volgende voorbeeld ziet u het gebruik van deze API's voor een bepaald shard-toewijzingsbeheerobject:// Create the schema annotations SchemaInfo schemaInfo = new SchemaInfo(); // reference tables schemaInfo.Add(new ReferenceTableInfo("dbo", "region")); schemaInfo.Add(new ReferenceTableInfo("dbo", "nation")); // sharded tables schemaInfo.Add(new ShardedTableInfo("dbo", "customer", "C_CUSTKEY")); schemaInfo.Add(new ShardedTableInfo("dbo", "orders", "O_CUSTKEY")); // publish smm.GetSchemaInfoCollection().Add(Configuration.ShardMapName, schemaInfo);De tabellen
regionennationzijn gedefinieerd als referentietabellen en worden gekopieerd met splits-/samenvoeg-/verplaatsingsbewerkingen.customerenordersop zijn beurt worden gedefinieerd als shardtabellen.C_CUSTKEYenO_CUSTKEYfungeren als de shardingsleutel.
Referentiële integriteit
De split-merge-service analyseert afhankelijkheden tussen tabellen en maakt gebruik van relaties tussen refererende sleutels en primaire sleutelrelaties om de bewerkingen voor het verplaatsen van referentietabellen en shardlets te faseren. In het algemeen worden referentietabellen eerst gekopieerd in de afhankelijkheidsvolgorde en worden shardlets gekopieerd in volgorde van hun afhankelijkheden binnen elke batch. Dit is nodig zodat FK-PK-beperkingen voor de doelshard worden gehonoreerd wanneer de nieuwe gegevens binnenkomen.
Consistentie van Shard-kaart en uiteindelijke voltooiing
In aanwezigheid van fouten hervat de service voor splitsen en samenvoegen bewerkingen na eventuele storingen en is bedoeld om eventuele lopende aanvragen te voltooien. Er kunnen echter onherstelbare situaties zijn, bijvoorbeeld wanneer de doelshard verloren gaat of is gecompromitteerd buiten reparatie. Onder deze omstandigheden kunnen sommige shardlets die moeten worden verplaatst, zich blijven bevinden op de bronshard. De service zorgt ervoor dat shardlet-toewijzingen alleen worden bijgewerkt nadat de benodigde gegevens naar het doel zijn gekopieerd. Shardlets worden alleen verwijderd op de bron zodra alle gegevens naar het doel zijn gekopieerd en de bijbehorende toewijzingen zijn bijgewerkt. De verwijderingsbewerking vindt plaats op de achtergrond terwijl het bereik al online is op de doelshard. De split-merge-service zorgt altijd voor de juistheid van de toewijzingen die zijn opgeslagen in de shard-toewijzing.
De gebruikersinterface voor splitsen en samenvoegen
Het servicepakket voor splitsen en samenvoegen omvat een werkrol en een webrol. De webrol wordt gebruikt om aanvragen voor splitssamenvoeging op een interactieve manier in te dienen. De belangrijkste onderdelen van de gebruikersinterface zijn als volgt:
Bewerkingstype
Het bewerkingstype is een keuzerondje waarmee het type bewerking wordt bepaald dat door de service voor deze aanvraag wordt uitgevoerd. U kunt kiezen tussen de scenario's voor splitsen, samenvoegen en verplaatsen. U kunt ook een eerder ingediende bewerking annuleren. U kunt splits-, samenvoeg- en verplaatsingsaanvragen gebruiken voor bereik-shard-toewijzingen. Lijst met shard-kaarten biedt alleen ondersteuning voor verplaatsingsbewerkingen.
Shard-toewijzing
De volgende sectie met aanvraagparameters bevat informatie over de shard-toewijzing en de database die als host fungeert voor uw shard-toewijzing. U moet met name de naam opgeven van de server en database die als host fungeert voor de shardmap, referenties om verbinding te maken met de shard-toewijzingsdatabase en ten slotte de naam van de shard-toewijzing. Momenteel accepteert de bewerking slechts één set referenties. Deze referenties moeten over voldoende machtigingen beschikken om wijzigingen in de shard-toewijzing en de gebruikersgegevens op de shards uit te voeren.
Bronbereik (splitsen en samenvoegen)
Een splits- en samenvoegbewerking verwerkt een bereik met behulp van de lage en hoge sleutel. Als u een bewerking met een niet-gebonden hoge-sleutelwaarde wilt opgeven, schakelt u het selectievakje 'Hoge sleutel is max' in en laat u het veld met hoge sleutel leeg. De bereiksleutelwaarden die u opgeeft, hoeven niet exact overeen te komen met een toewijzing en de bijbehorende grenzen in uw shard-kaart. Als u geen bereikgrenzen opgeeft, leidt de service automatisch het dichtstbijzijnde bereik af. U kunt het PowerShell-script GetMappings.ps1 gebruiken om de huidige toewijzingen op te halen in een bepaalde shard-toewijzing.
Gedrag van gesplitste bron (gesplitst)
Definieer voor splitsbewerkingen het punt om het bronbereik te splitsen. U doet dit door de shardingsleutel op te geven waar u de splitsing wilt uitvoeren. Gebruik het keuzerondje om aan te geven of u het onderste deel van het bereik wilt verplaatsen (met uitzondering van de splitssleutel) of dat u het bovenste deel wilt verplaatsen (inclusief de splitssleutel).
Bronshardlet (verplaatsen)
Verplaatsingsbewerkingen verschillen van splits- of samenvoegbewerkingen omdat ze geen bereik nodig hebben om de bron te beschrijven. Een bron voor verplaatsen wordt eenvoudig geïdentificeerd door de sharding-sleutelwaarde die u wilt verplaatsen.
Doel-shard (gesplitst)
Zodra u de informatie hebt opgegeven over de bron van de splitsbewerking, moet u definiëren waar u de gegevens naartoe wilt kopiëren door de server- en databasenaam voor het doel op te geven.
Doelbereik (samenvoegen)
Samenvoegbewerkingen verplaatsen shardlets naar een bestaande shard. U identificeert de bestaande shard door de bereikgrenzen op te geven van het bestaande bereik waarmee u wilt samenvoegen.
Batchgrootte
De batchgrootte bepaalt het aantal shardlets dat offline gaat tijdens de gegevensverplaatsing. Dit is een geheel getal, waarbij u kleinere waarden kunt gebruiken wanneer u gevoelig bent voor lange perioden van downtime voor shardlets. Grotere waarden verhogen de tijd dat een bepaalde shardlet offline is, maar kunnen de prestaties verbeteren.
Bewerkings-id (annuleren)
Als u een actieve bewerking hebt die niet meer nodig is, kunt u de bewerking annuleren door de bewerkings-id op te geven in dit veld. U kunt de bewerkings-id ophalen uit de aanvraagstatustabel (zie sectie 8.1) of uit de uitvoer in de webbrowser waar u de aanvraag hebt ingediend.
Vereisten en beperkingen
De huidige implementatie van de split-merge-service is onderhevig aan de volgende vereisten en beperkingen:
- De shards moeten bestaan en moeten worden geregistreerd in de shard-toewijzing voordat een bewerking voor splitsen samenvoegen op deze shards kan worden uitgevoerd.
- De service maakt geen tabellen of andere databaseobjecten automatisch als onderdeel van de bewerkingen. Dit betekent dat het schema voor alle shard-tabellen en verwijzingstabellen moet bestaan op de doelshard vóór een splits-/samenvoeg-/verplaatsingsbewerking. Met name Shard-tabellen moeten leeg zijn in het bereik waar nieuwe shardlets moeten worden toegevoegd door een splits-/samenvoeg-/verplaatsingsbewerking. Anders mislukt de bewerking de eerste consistentiecontrole op de doelshard. Houd er ook rekening mee dat verwijzingsgegevens alleen worden gekopieerd als de verwijzingstabel leeg is en dat er geen consistentiegaranties zijn met betrekking tot andere gelijktijdige schrijfbewerkingen in de referentietabellen. We raden dit aan: bij het uitvoeren van splits-/samenvoegbewerkingen worden er geen andere schrijfbewerkingen aangebracht in de referentietabellen.
- De service is afhankelijk van de rijidentiteit die is ingesteld door een unieke index of sleutel die de shardingsleutel bevat om de prestaties en betrouwbaarheid voor grote shardlets te verbeteren. Hierdoor kan de service gegevens op een nog nauwkeurigere granulariteit verplaatsen dan alleen de sharding-sleutelwaarde. Dit helpt bij het verminderen van de maximale hoeveelheid logboekruimte en vergrendelingen die nodig zijn tijdens de bewerking. Overweeg om een unieke index of een primaire sleutel te maken, inclusief de sharding-sleutel in een bepaalde tabel als u die tabel wilt gebruiken met aanvragen voor splitsen/samenvoegen/verplaatsen. Om prestatieredenen moet de sharding-sleutel de voorloopkolom in de sleutel of de index zijn.
- Tijdens de verwerking van aanvragen kunnen sommige shardletgegevens zowel op de bron- als de doelshard aanwezig zijn. Dit is nodig om te beschermen tegen storingen tijdens de shardlet-verplaatsing. De integratie van split-merge met de shard-toewijzing zorgt ervoor dat verbindingen via de gegevensafhankelijke routerings-API's met behulp van de methode Open Verbinding maken ionForKey op de shard-kaart geen inconsistente tussenliggende statussen zien. Wanneer u echter verbinding maakt met de bron- of doelshards zonder de methode Open Verbinding maken ionForKey te gebruiken, zijn inconsistente tussenliggende statussen mogelijk zichtbaar wanneer aanvragen voor splitsen/samenvoegen/verplaatsen worden uitgevoerd. Deze verbindingen kunnen gedeeltelijke of dubbele resultaten weergeven, afhankelijk van de timing of de shard die de verbinding onderliggend is. Deze beperking omvat momenteel de verbindingen die zijn gemaakt door Multi-Shard-query's op elastische schaal.
- De metagegevensdatabase voor de service voor splitsen en samenvoegen mag niet worden gedeeld tussen verschillende rollen. Een rol van de split-merge-service die in fasering wordt uitgevoerd, moet bijvoorbeeld verwijzen naar een andere metagegevensdatabase dan de productierol.
Billing
De split-merge-service wordt uitgevoerd als een cloudservice in uw Microsoft Azure-abonnement. Daarom zijn kosten voor cloudservices van toepassing op uw exemplaar van de service. Tenzij u regelmatig splits-/samenvoeg-/verplaatsingsbewerkingen uitvoert, wordt u aangeraden de cloudservice voor splitsen en samenvoegen te verwijderen. Dit bespaart kosten voor het uitvoeren of implementeren van cloudservice-exemplaren. U kunt uw direct uitvoerbare configuratie opnieuw implementeren en starten wanneer u splits- of samenvoegbewerkingen moet uitvoeren.
Controleren
Statustabellen
De service voor splitsen en samenvoegen biedt de tabel RequestStatus in de database voor het metagegevensarchief voor het bewaken van voltooide en lopende aanvragen. De tabel bevat een rij voor elke aanvraag voor splitsen en samenvoegen die is verzonden naar dit exemplaar van de service voor splitsen en samenvoegen. Het geeft de volgende informatie voor elke aanvraag:
Tijdstempel
De tijd en datum waarop de aanvraag is gestart.
OperationId
Een GUID die de aanvraag uniek identificeert. Deze aanvraag kan ook worden gebruikt om de bewerking te annuleren terwijl deze nog steeds actief is.
-Status
De huidige status van de aanvraag. Voor lopende aanvragen wordt ook de huidige fase weergegeven waarin de aanvraag zich bevindt.
CancelRequest
Een vlag die aangeeft of de aanvraag is geannuleerd.
Vooruitgang
Een percentageschatting van voltooiing voor de bewerking. Een waarde van 50 geeft aan dat de bewerking ongeveer 50% voltooid is.
DETAILS
Een XML-waarde die een gedetailleerder voortgangsrapport biedt. Het voortgangsrapport wordt periodiek bijgewerkt omdat sets rijen van bron naar doel worden gekopieerd. In het geval van fouten of uitzonderingen bevat deze kolom ook meer gedetailleerde informatie over de fout.
Azure Diagnostics
De split-merge-service maakt gebruik van Azure Diagnostics op basis van Azure SDK 2.5 voor bewaking en diagnose. U bepaalt de configuratie van diagnostische gegevens, zoals hier wordt uitgelegd: Diagnostische gegevens inschakelen in Azure Cloud Services en Virtuele machines. Het downloadpakket bevat twee diagnostische configuraties: één voor de webrol en één voor de werkrol. Het bevat de definities voor het vastleggen van prestatiemeteritems, IIS-logboeken, Windows-gebeurtenislogboeken en gebeurtenislogboeken voor toepassingsgebeurtenissen splitsen.
Diagnostische gegevens implementeren
Notitie
In dit artikel wordt gebruikgemaakt van de Azure Az PowerShell-module. Dit is de aanbevolen PowerShell-module voor interactie met Azure. Raadpleeg Azure PowerShell installeren om aan de slag te gaan met de Az PowerShell-module. Raadpleeg Azure PowerShell migreren van AzureRM naar Az om te leren hoe u naar de Azure PowerShell-module migreert.
Belangrijk
De PowerShell Azure Resource Manager-module wordt nog steeds ondersteund, maar alle toekomstige ontwikkeling is voor de Az.Sql-module. Zie AzureRM.Sql voor deze cmdlets. De argumenten voor de opdrachten in de Az-module en in de AzureRm-modules zijn vrijwel identiek.
Als u bewaking en diagnostische gegevens wilt inschakelen met behulp van de diagnostische configuratie voor de web- en werkrollen die worden geleverd door het NuGet-pakket, voert u de volgende opdrachten uit met behulp van Azure PowerShell:
$storageName = "<azureStorageAccount>"
$key = "<azureStorageAccountKey"
$storageContext = New-AzStorageContext -StorageAccountName $storageName -StorageAccountKey $key
$configPath = "<filePath>\SplitMergeWebContent.diagnostics.xml"
$serviceName = "<cloudServiceName>"
Set-AzureServiceDiagnosticsExtension -StorageContext $storageContext `
-DiagnosticsConfigurationPath $configPath -ServiceName $serviceName `
-Slot Production -Role "SplitMergeWeb"
Set-AzureServiceDiagnosticsExtension -StorageContext $storageContext `
-DiagnosticsConfigurationPath $configPath -ServiceName $serviceName `
-Slot Production -Role "SplitMergeWorker"
Meer informatie over het configureren en implementeren van diagnostische instellingen vindt u hier: Diagnostische gegevens inschakelen in Azure Cloud Services en Virtuele machines.
Diagnostische gegevens ophalen
U kunt eenvoudig toegang krijgen tot uw diagnostische gegevens vanuit Visual Studio Server Explorer in het Azure-deel van de Server Explorer-structuur. Open een Visual Studio-exemplaar en klik in de menubalk op Weergeven en Server Explorer. Klik op het Azure-pictogram om verbinding te maken met uw Azure-abonnement. Navigeer vervolgens naar Azure -> Storage -><your storage account> Tables ->> WADLogsTable. Zie Server Explorer voor meer informatie.
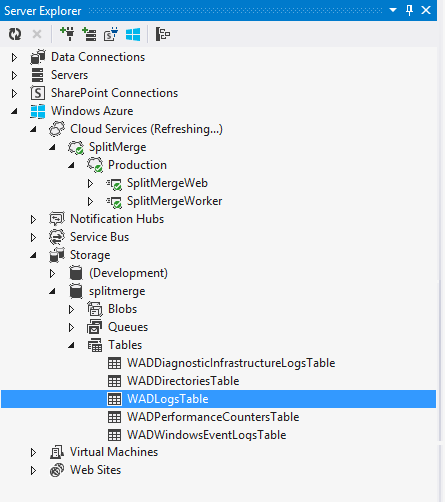
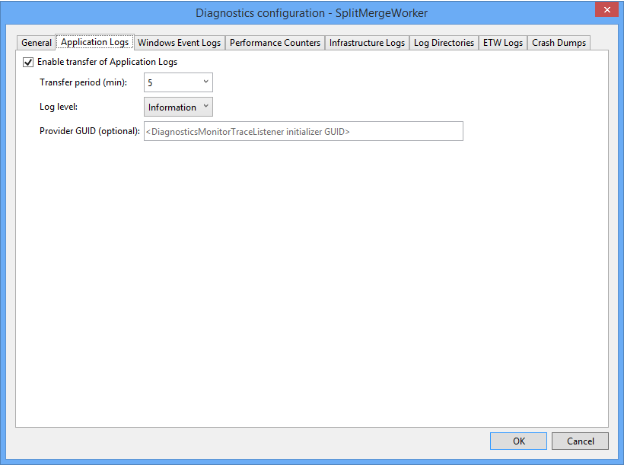
De WADLogsTable gemarkeerd in de bovenstaande afbeelding bevat de gedetailleerde gebeurtenissen uit het toepassingslogboek van de split-merge-service. Houd er rekening mee dat de standaardconfiguratie van het gedownloade pakket is afgestemd op een productie-implementatie. Daarom is het interval waarmee logboeken en tellers worden opgehaald uit de service-exemplaren groot (5 minuten). Voor test en ontwikkeling verlaagt u het interval door de diagnostische instellingen van het web of de werkrol aan te passen aan uw behoeften. Klik met de rechtermuisknop op de rol in Visual Studio Server Explorer (zie hierboven) en pas vervolgens de overdrachtsperiode aan in het dialoogvenster voor de configuratie-instellingen voor diagnostische gegevens:
Prestaties
Over het algemeen worden betere prestaties verwacht van hogere, beter presterende servicelagen. Hogere I/O-, CPU- en geheugentoewijzingen voor de hogere servicelagen profiteren van de bulkbewerkingen voor kopiëren en verwijderen die door de split-merge-service worden gebruikt. Verhoog daarom alleen de servicelaag voor die databases voor een gedefinieerde, beperkte periode.
De service voert ook validatiequery's uit als onderdeel van de normale bewerkingen. Deze validatiequery's controleren op onverwachte aanwezigheid van gegevens in het doelbereik en zorgen ervoor dat een splits-/samenvoeg-/verplaatsingsbewerking begint met een consistente status. Deze query's werken allemaal over sharding-sleutelbereiken die zijn gedefinieerd door het bereik van de bewerking en de batchgrootte die is opgegeven als onderdeel van de aanvraagdefinitie. Deze query's presteren het beste wanneer een index aanwezig is met de shardingsleutel als de voorloopkolom.
Bovendien kan de service met een eigenschap uniekheid met de shardingsleutel een geoptimaliseerde benadering gebruiken die het resourceverbruik beperkt in termen van logboekruimte en geheugen. Deze eigenschap uniekheid is vereist voor het verplaatsen van grote gegevensgrootten (meestal boven 1 GB).
Upgrade uitvoeren
- Volg de stappen in Een service voor splitsen samenvoegen implementeren.
- Wijzig het configuratiebestand van de cloudservice voor de implementatie voor splitsen en samenvoegen om de nieuwe configuratieparameters weer te geven. Een nieuwe vereiste parameter is de informatie over het certificaat dat wordt gebruikt voor versleuteling. Een eenvoudige manier om dit te doen, is door het nieuwe configuratiesjabloonbestand van de download te vergelijken met uw bestaande configuratie. Zorg ervoor dat u de instellingen voor
DataEncryptionPrimaryCertificateThumbprintenDataEncryptionPrimaryvoor zowel het web als de werkrol toevoegt. - Voordat u de update implementeert in Azure, moet u ervoor zorgen dat alle momenteel uitgevoerde bewerkingen voor splitsen en samenvoegen zijn voltooid. U kunt dit eenvoudig doen door query's uit te voeren op de tabellen RequestStatus en PendingWorkflows in de metagegevensdatabase voor samenvoeging voor lopende aanvragen.
- Werk uw bestaande cloudservice-implementatie bij voor split-merge in uw Azure-abonnement met het nieuwe pakket en het bijgewerkte serviceconfiguratiebestand.
U hoeft geen nieuwe metagegevensdatabase in te richten om een upgrade uit te voeren voor splitsen en samenvoegen. Met de nieuwe versie wordt uw bestaande metagegevensdatabase automatisch bijgewerkt naar de nieuwe versie.
Aanbevolen procedures en probleemoplossing
- Definieer een testtenant en oefen uw belangrijkste splits-/samenvoeg-/verplaatsingsbewerkingen uit met de testtenant over verschillende shards. Zorg ervoor dat alle metagegevens correct zijn gedefinieerd in uw shard-toewijzing en dat de bewerkingen geen beperkingen of refererende sleutels schenden.
- Behoud de grootte van de testtenantgegevens boven de maximale gegevensgrootte van uw grootste tenant om ervoor te zorgen dat u geen problemen ondervindt met betrekking tot de gegevensgrootte. Hiermee kunt u een bovengrens beoordelen op de tijd die nodig is om één tenant te verplaatsen.
- Zorg ervoor dat uw schema verwijderingen toestaat. Voor de split-merge-service is de mogelijkheid nodig om gegevens uit de bronshard te verwijderen zodra de gegevens naar het doel zijn gekopieerd. Met verwijderingstriggers kan bijvoorbeeld worden voorkomen dat de service de gegevens op de bron verwijdert en kan dit ertoe leiden dat bewerkingen mislukken.
- De sharding-sleutel moet de voorloopkolom in uw primaire sleutel of unieke indexdefinitie zijn. Dit zorgt voor de beste prestaties voor de validatiequery's voor splitsen of samenvoegen, en voor de werkelijke bewerkingen voor gegevensverplaatsing en verwijdering die altijd werken op shardingsleutelbereiken.
- Plaats uw service voor splitsen en samenvoegen in de regio en het datacenter waar uw databases zich bevinden.
Aanvullende bronnen
Gebruikt u nog geen hulpprogramma's voor elastische databases? Bekijk de handleiding Aan de slag. Neem voor vragen contact met ons op op de microsoft Q&A-vragenpagina voor SQL Database en voor functieaanvragen, voeg nieuwe ideeën toe of stem op bestaande ideeën in het feedbackforum van SQL Database.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor