Realtime big data-analyses versnellen met behulp van de Spark-connector
Van toepassing op:![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Notitie
Vanaf september 2020 wordt deze connector niet actief onderhouden. Apache Spark Verbinding maken or voor SQL Server en Azure SQL is nu echter beschikbaar, met ondersteuning voor Python- en R-bindingen, een eenvoudiger te gebruiken interface voor het bulksgewijs invoegen van gegevens en vele andere verbeteringen. We raden u ten zeerste aan om de nieuwe connector te evalueren en te gebruiken in plaats van deze. De informatie over de oude connector (deze pagina) wordt alleen bewaard voor archiveringsdoeleinden.
Met de Spark-connector kunnen databases in Azure SQL Database, Azure SQL Managed Instance en SQL Server fungeren als de invoergegevensbron of uitvoergegevenssink voor Spark-taken. Hiermee kunt u realtime transactionele gegevens gebruiken in big data-analyses en resultaten behouden voor ad-hocquery's of rapportages. Vergeleken met de ingebouwde JDBC-connector biedt deze connector de mogelijkheid om gegevens bulksgewijs in uw database in te voegen. Het kan beter presteren dan rij-op-rij-invoeging met 10x tot 20x snellere prestaties. De Spark-connector ondersteunt verificatie met Microsoft Entra ID (voorheen Azure Active Directory) om verbinding te maken met Azure SQL Database en Azure SQL Managed Instance, zodat u verbinding kunt maken met uw database vanuit Azure Databricks met behulp van uw Microsoft Entra-account. Het biedt vergelijkbare interfaces met de ingebouwde JDBC-connector. Het is eenvoudig om uw bestaande Spark-taken te migreren om deze nieuwe connector te gebruiken.
Notitie
Microsoft Entra-id is de nieuwe naam voor Azure Active Directory (Azure AD). Op dit moment wordt de documentatie bijgewerkt.
Een Spark-connector downloaden en bouwen
De GitHub-opslagplaats voor de oude connector waarnaar eerder vanaf deze pagina is gekoppeld, wordt niet actief onderhouden. In plaats daarvan raden we u sterk aan om de nieuwe connector te evalueren en te gebruiken.
Officiële ondersteunde versies
| Onderdeel | Versie |
|---|---|
| Apache Spark | 2.0.2 of hoger |
| Scala | 2.10 of hoger |
| Microsoft JDBC-stuurprogramma voor SQL Server | 6.2 of hoger |
| Microsoft SQL Server | SQL Server 2008 of hoger |
| Azure SQL-database | Ondersteund |
| Azure SQL Managed Instance | Ondersteund |
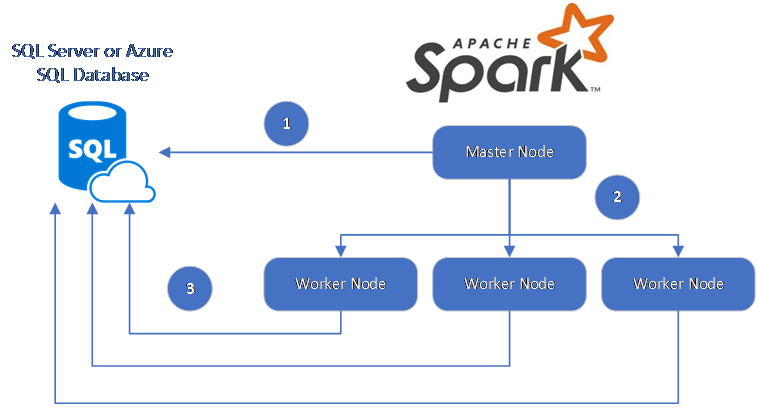
De Spark-connector maakt gebruik van het Microsoft JDBC-stuurprogramma voor SQL Server om gegevens te verplaatsen tussen Spark-werkknooppunten en -databases:
De gegevensstroom is als volgt:
- Het Spark-hoofdknooppunt maakt verbinding met databases in SQL Database of SQL Server en laadt gegevens uit een specifieke tabel of met behulp van een specifieke SQL-query.
- Het Spark-hoofdknooppunt distribueert gegevens naar werkknooppunten voor transformatie.
- Het werkknooppunt maakt verbinding met databases die verbinding maken met SQL Database en SQL Server en schrijft gegevens naar de database. De gebruiker kan ervoor kiezen om rij-op-rij in te voegen of bulksgewijs in te voegen.
In het volgende diagram ziet u de gegevensstroom.
De Spark-connector bouwen
Op dit moment maakt het connectorproject gebruik van Maven. Als u de connector wilt bouwen zonder afhankelijkheden, kunt u het volgende uitvoeren:
- mvn clean package
- De nieuwste versies van het JAR downloaden uit de releasemap
- De SQL Database Spark JAR opnemen
gegevens Verbinding maken en lezen met behulp van de Spark-connector
U kunt vanuit een Spark-taak verbinding maken met databases in SQL Database en SQL Server om gegevens te lezen of te schrijven. U kunt ook een DML- of DDL-query uitvoeren in databases in SQL Database en SQL Server.
Gegevens lezen uit Azure SQL en SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Gegevens lezen uit Azure SQL en SQL Server met een opgegeven SQL-query
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
Gegevens schrijven naar Azure SQL en SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Aquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
DML- of DDL-query uitvoeren in Azure SQL en SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
Verbinding maken van Spark met behulp van Microsoft Entra-verificatie
U kunt verbinding maken met SQL Database en SQL Managed Instance met behulp van Microsoft Entra-verificatie. Gebruik Microsoft Entra-verificatie om identiteiten van databasegebruikers centraal te beheren en als alternatief voor SQL-verificatie.
Verbinding maken met de verificatiemodus ActiveDirectoryPassword
Installatievereiste
Als u de ActiveDirectoryPassword-verificatiemodus gebruikt, moet u microsoft-authentication-library-for-java en de bijbehorende afhankelijkheden downloaden en opnemen in het Java-buildpad.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Verbinding maken met behulp van een toegangstoken
Installatievereiste
Als u de verificatiemodus op basis van een toegangstoken gebruikt, moet u microsoft-authentication-library-for-java en de bijbehorende afhankelijkheden downloaden en opnemen in het Java-buildpad.
Zie Microsoft Entra-verificatie gebruiken voor meer informatie over het ophalen van een toegangstoken voor uw database in Azure SQL Database of Azure SQL Managed Instance.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.windows.net",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Gegevens schrijven met behulp van bulksgewijs invoegen
De traditionele jdbc-connector schrijft gegevens naar uw database met behulp van rij-per-rij-invoeging. U kunt de Spark-connector gebruiken om gegevens naar Azure SQL en SQL Server te schrijven met behulp van bulksgewijs invoegen. Dit verbetert de schrijfprestaties aanzienlijk bij het laden van grote gegevenssets of het laden van gegevens in tabellen waarin een kolomarchiefindex wordt gebruikt.
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
Volgende stappen
Als u dat nog niet hebt gedaan, downloadt u de Spark-connector vanuit de GitHub-opslagplaats azure-sqldb-spark en verkent u de aanvullende resources in de opslagplaats:
U kunt ook de Handleiding voor Apache Spark SQL, DataFrames en Gegevenssets en de Documentatie voor Azure Databricks bekijken.