Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
van toepassing op:![]() Azure SQL Database-
Azure SQL Database-
Belangrijk
SQL Data Sync wordt op 30 september 2027 buiten gebruik gesteld. Overweeg om te migreren naar alternatieve oplossingen voor gegevensreplicatie/synchronisatie.
SQL Data Sync is een service die is gebouwd op Azure SQL Database waarmee u de gegevens die u selecteert bidirectioneel kunt synchroniseren tussen meerdere databases, zowel on-premises als in de cloud.
Azure SQL Data Sync biedt geen ondersteuning voor Azure SQL Managed Instance of Azure Synapse Analytics.
Overzicht
Data Sync is gebaseerd op het concept van een synchronisatiegroep. Een synchronisatiegroep is een groep databases die u wilt synchroniseren.
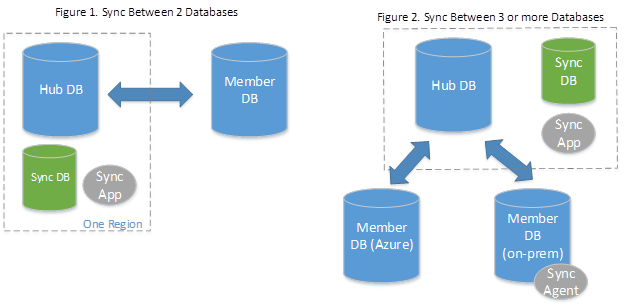
Data Sync maakt gebruik van een hub- en spoke-topologie om gegevens te synchroniseren. U definieert een van de databases in de synchronisatiegroep als de hubdatabase. De rest van de databases zijn liddatabases. Synchronisatie vindt alleen plaats tussen de hub en afzonderlijke leden.
- De Hub Database- moet een Azure SQL Database zijn.
- De liddatabases kunnen databases zijn in Azure SQL Database of in exemplaren van SQL Server.
- De Sync Metagegevensdatabase bevat de metadata en het logboek voor Data Sync. De Sync Metagegevensdatabase moet een Azure SQL Database zijn die zich in dezelfde regio bevindt als de Hub Database. De database voor synchronisatiemetagegevens is door de klant gemaakt en eigendom van de klant. U kunt slechts één synchronisatiemetagegevensdatabase per regio en abonnement hebben. Synchronisatiemetagegevensdatabase kan niet worden verwijderd of hernoemd terwijl er synchronisatiegroepen of synchronisatieagents bestaan. Microsoft raadt aan een nieuwe, lege database te maken voor gebruik als de database met synchronisatiemetagegevens. Data Sync maakt tabellen in deze database en voert een frequente workload uit.
Notitie
Als u een on-premises database als liddatabase gebruikt, moet u een lokale synchronisatieagent installeren en configureren.
Een synchronisatiegroep heeft de volgende eigenschappen:
- In het Synchronisatieschema wordt beschreven welke gegevens worden gesynchroniseerd.
- De Synchronisatierichting kan bidirectioneel zijn of in slechts één richting stromen. Dat wil zeggen: de synchronisatierichting kan Hub naar Lidzijn, of Lid naar Hub, of beide.
- Het synchronisatie-interval beschrijft hoe vaak synchronisatie plaatsvindt.
- Het beleid voor conflictoplossing is een groepsbeleid dat kan worden Hub wint of lid wint.
Wanneer gebruikt u
Data Sync is handig in gevallen waarin gegevens moeten worden bijgewerkt in verschillende databases in Azure SQL Database of SQL Server. Dit zijn de belangrijkste use cases voor Data Sync:
- hybride gegevenssynchronisatie: met Data Sync kunt u gegevens gesynchroniseerd houden tussen uw databases in SQL Server en Azure SQL Database om hybride toepassingen in te schakelen. Deze mogelijkheid kan een beroep doen op klanten die overwegen om over te stappen naar de cloud en een deel van hun toepassing in Azure willen plaatsen.
- gedistribueerde toepassingen: In veel gevallen is het handig om verschillende werkbelastingen over verschillende databases te scheiden. Als u bijvoorbeeld een grote productiedatabase hebt, maar u ook een rapportage- of analyseworkload op deze gegevens moet uitvoeren, is het handig om een tweede database te hebben voor deze extra workload. Deze benadering minimaliseert de invloed van de prestaties op uw productieworkload. U kunt Data Sync gebruiken om deze twee databases gesynchroniseerd te houden.
- Wereldwijd gedistribueerde toepassingen: Veel bedrijven omvatten verschillende regio's en zelfs verschillende landen/regio's. Als u de netwerklatentie wilt minimaliseren, kunt u uw gegevens het beste in een regio bij u in de buurt hebben. Met Data Sync kunt u eenvoudig databases in regio's over de hele wereld gesynchroniseerd houden.
Data Sync is niet de voorkeursoplossing voor de volgende scenario's:
| Scenario | Enkele aanbevolen oplossingen |
|---|---|
| Noodherstel | Automatische back-ups in Azure SQL Database |
| Leesschaal | Gebruik alleen-lezen replica's om alleen-lezen query-workloads te verlichten |
| ETL (OLTP naar OLAP) | Azure Data Factory of SQL Server Integration Services |
| Migratie van SQL Server naar Azure SQL Database. SQL Data Sync kan echter worden gebruikt nadat de migratie is voltooid, om ervoor te zorgen dat de bron en het doel gesynchroniseerd blijven. | Azure Database Migration Service |
Hoe het werkt
- Wijzigingen in gegevens bijhouden: Data Sync houdt wijzigingen bij met behulp van triggers voor invoegen, bijwerken en verwijderen. De wijzigingen worden vastgelegd in een zijtabel in de gebruikersdatabase. BULK INSERT activeert standaard geen triggers. Als FIRE_TRIGGERS niet is opgegeven, worden er geen invoegtriggers uitgevoerd. Voeg de optie FIRE_TRIGGERS toe zodat Data Sync deze invoegingen kan bijhouden.
- Gegevens synchroniseren: Data Sync is ontworpen in een hub- en spoke-model. De hub wordt afzonderlijk gesynchroniseerd met elk lid. Wijzigingen van de hub worden naar het lid gedownload en vervolgens worden wijzigingen van het lid geüpload naar de hub.
-
Conflicten oplossen: Data Sync biedt twee opties voor conflictoplossing, Hub wint of lid wint.
- Als u Hub selecteert, overschrijven de wijzigingen in de hub altijd de wijzigingen in het lid.
- Als u Lid wintselecteert, overschrijven de wijzigingen in het lid de wijzigingen in de hub. Als er meer dan één lid is, is de uiteindelijke waarde afhankelijk van het lid dat als eerste wordt gesynchroniseerd.
Vergelijken met transactionele replicatie
| Gegevenssynchronisatie | Transactionele replicatie | |
|---|---|---|
| voordelen | - Actief-actief ondersteuning - Bidirectioneel tussen on-premises en Azure SQL Database |
- Lagere latentie - Transactionele consistentie - Bestaande topologie na migratie opnieuw gebruiken -Ondersteuning voor Azure SQL Managed Instance |
| nadelen | - Geen transactionele consistentie - Hogere impact op prestaties |
- Kan niet publiceren vanuit Azure SQL Database - Hoge onderhoudskosten |
Waarschuwing
SQL Data Sync vereist SQL-verificatie voor verbindingen met de hub- en liddatabases. Verificatie van Microsoft Entra (Azure AD) wordt niet ondersteund door SQL Data Sync. Omdat SQL-verificatie afhankelijk is van statische wachtwoorden, profiteert deze niet van moderne beveiligingen, zoals meervoudige verificatie (MFA), voorwaardelijke toegang of beheerde identiteiten. Dit kan de blootstelling voor het hele SQL-exemplaar verhogen tot diefstal van inloggegevens, brute-force aanvallen en operationele overhead voor wachtwoordrotatie en beleidsimplementatie. Geef waar mogelijk de voorkeur aan oplossingen die ondersteuning bieden voor Microsoft Entra-verificatie of beheerde identiteiten. Omdat SQL Data Sync is gepland voor buitengebruikstelling, migreert u naar een alternatief dat overeenkomt met de beveiligingsstandaarden van uw organisatie.
Privékoppeling voor Data Sync
Notitie
De privékoppeling van SQL Data Sync verschilt van de Azure Private Link-.
Met de nieuwe private link-functie kunt u een door een service beheerd privé-eindpunt kiezen om een beveiligde verbinding tot stand te brengen tussen de synchronisatieservice en uw lid-/hubdatabases tijdens het gegevenssynchronisatieproces. Een door een service beheerd privé-eindpunt is een privé-IP-adres binnen een specifiek virtueel netwerk en subnet. Binnen Data Sync wordt het beheerde privé-eindpunt van de service gemaakt door Microsoft en wordt deze uitsluitend gebruikt door de Data Sync-service voor een bepaalde synchronisatiebewerking.
Lees voordat u de privékoppeling instelt de algemene vereisten voor de functie.

Notitie
U moet het door de service beheerde privé-eindpunt handmatig goedkeuren op de privé-eindpuntverbindingen pagina van Azure Portal tijdens de implementatie van de synchronisatiegroep of met behulp van PowerShell.
Aan de slag
Data Sync instellen in Azure Portal
- Zelfstudie: SQL Data Sync instellen tussen databases in Azure SQL Database en SQL Server
- De Data Sync Agent - De Data Sync Agent voor SQL Data Sync
Data Sync instellen met PowerShell
- PowerShell gebruiken om gegevens te synchroniseren tussen meerdere databases in Azure SQL Database
- PowerShell gebruiken om gegevens te synchroniseren tussen SQL Database en SQL Server
Data Sync instellen met REST API
Bekijk de aanbevolen procedures voor Data Sync
Er is iets misgegaan
- Problemen met SQL Data Sync- oplossen
Consistentie en prestaties
Uiteindelijke consistentie
Omdat Data Sync is gebaseerd op triggers, wordt transactionele consistentie niet gegarandeerd. Microsoft garandeert dat alle wijzigingen uiteindelijk worden aangebracht en dat Data Sync geen gegevensverlies veroorzaakt.
Invloed op de prestaties
Data Sync maakt gebruik van triggers voor invoegen, bijwerken en verwijderen om wijzigingen bij te houden. Er worden zijtabellen gemaakt in de gebruikersdatabase voor het bijhouden van wijzigingen. Deze activiteiten voor het bijhouden van wijzigingen hebben invloed op uw databaseworkload. Evalueer uw servicelaag en voer indien nodig een upgrade uit.
Het inrichten en ongedaan maken van de inrichting tijdens het maken, bijwerken en verwijderen van synchronisatiegroepen kan ook van invloed zijn op de prestaties van de database.
Vereisten en beperkingen
Algemene vereisten
- Elke tabel moet een primaire sleutel hebben. Wijzig de waarde van de primaire sleutel in een willekeurige rij niet. Als u een primaire-sleutelwaarde moet wijzigen, verwijdert u de rij en maakt u deze opnieuw met de nieuwe primaire-sleutelwaarde.
Belangrijk
Als u de waarde van een bestaande primaire sleutel wijzigt, resulteert dit in het volgende foutieve gedrag:
- Gegevens tussen hub en lid kunnen verloren gaan, ook al meldt synchronisatie geen probleem.
- Synchronisatie kan falen omdat de traceringstabel een rij bevat die niet meer bestaat in de bron, als gevolg van een wijziging in de primaire sleutel.
Isolatie van momentopnamen moet zijn ingeschakeld voor synchronisatieleden en hubs. Zie Isolatie van momentopnamen in SQL Servervoor meer informatie.
Als u een privékoppeling voor Data Sync wilt gebruiken, moeten zowel de lid- als hubdatabases worden gehost in Azure (dezelfde of verschillende regio's), in hetzelfde cloudtype (bijvoorbeeld zowel in de openbare cloud als in beide in de overheidscloud). Daarnaast moeten resourceproviders
Microsoft.Networkgeregistreerd zijn voor de abonnementen die de hub- en lidservers hosten om gebruik te kunnen maken van de private link. Ten slotte moet u de privékoppeling voor Data Sync handmatig goedkeuren tijdens de synchronisatieconfiguratie, in de sectie Privé-eindpuntverbindingen in Azure Portal of via PowerShell. Zie zelfstudie: SQL Data Sync instellen tussen databases in Azure SQL Database en SQL Servervoor meer informatie over het goedkeuren van de privékoppeling. Zodra u het beheerde privé-eindpunt van de service goedkeurt, vindt alle communicatie tussen de synchronisatieservice en de lid-/hubdatabases plaats via de privékoppeling. Bestaande synchronisatiegroepen kunnen worden bijgewerkt om deze functie in te schakelen.
Algemene beperkingen
- Een tabel kan geen identiteitskolom hebben die niet de primaire sleutel is.
- Een primaire sleutel kan niet de volgende gegevenstypen hebben: sql_variant, binaire, varbinary, afbeelding, xml-.
- Wees voorzichtig wanneer u de volgende gegevenstypen als primaire sleutel gebruikt, omdat de ondersteunde precisie slechts tot de tweede is: tijd, datum/tijd, datetime2, datetimeoffset.
- De namen van objecten (databases, tabellen en kolommen) mogen de afdrukbare tekens punt (
.), linkervierkante haak ([) of rechtervierkante haak (]) niet bevatten. - Een tabelnaam mag geen afdrukbare tekens bevatten:
! " # $ % ' ( ) * + -of spatie. - Verificatie van Microsoft Entra (voorheen Azure Active Directory) wordt niet ondersteund.
- Als er tabellen met dezelfde naam maar een ander schema zijn (bijvoorbeeld
dbo.customersensales.customers), kan slechts één van de tabellen worden gesynchroniseerd. - Kolommen met door de gebruiker gedefinieerde gegevenstypen worden niet ondersteund.
- Het verplaatsen van servers tussen verschillende abonnementen wordt niet ondersteund.
- Als twee primaire sleutels alleen verschillen in het geval (bijvoorbeeld
Fooenfoo), biedt Data Sync geen ondersteuning voor dit scenario. - Het afkappen van tabellen is geen bewerking die wordt ondersteund door Data Sync (wijzigingen worden niet bijgehouden).
- Het gebruik van een Azure SQL Hyperscale-database als hub- of synchronisatiemetagegevensdatabase wordt niet ondersteund. Een Hyperscale-database kan echter een liddatabase zijn in een Data Sync-topologie.
- Tabellen die zijn geoptimaliseerd voor geheugen worden niet ondersteund.
- Schemawijzigingen worden niet automatisch gerepliceerd.
- Data Sync ondersteunt alleen de volgende twee indexeigenschappen: uniek, gegroepeerd/niet-geclusterd. Andere eigenschappen van een index, zoals
IGNORE_DUP_KEYof het filterpredicaatWHERE, worden niet ondersteund en de doelindex wordt ingericht zonder deze eigenschappen, zelfs als de bronindex deze eigenschappen heeft ingesteld. - Een Elastische Azure-taakdatabase kan niet worden gebruikt als de SQL Data Sync Metadata-database en omgekeerd.
- SQL Data Sync wordt niet ondersteund voor grootboekdatabases.
- Data Sync is geen hulpprogramma voor herstel na noodgevallen of een hulpprogramma voor hoge beschikbaarheid en synchroniseert geen eigen synchronisatiegroepinformatie. Er is geen automatisch herstel na noodgevallen voor Data Sync.
- Data Sync biedt geen ondersteuning voor netwerkbeveiligingsperimeter (NSP).
Niet-ondersteunde gegevenstypen
- FileStream
- SQL/CLR UDT
- XMLSchemaCollection (ondersteund door XML)
- Cursor, RowVersion, Timestamp, Hierarchyid
Niet-ondersteunde kolomtypen
Data Sync kan geen alleen-lezen-kolommen of systeemgegenereerde kolommen synchroniseren. Bijvoorbeeld:
- Berekende kolommen
- Door het systeem gegenereerde kolommen voor tijdelijke tabellen
Beperkingen voor service- en databasedimensies
| dimensies | beperken | tijdelijke oplossing |
|---|---|---|
| Het maximum aantal synchronisatiegroepen waartoe elke database kan behoren. | 5 | |
| Maximum aantal eindpunten in één synchronisatiegroep | 30 | |
| Maximum aantal on-premises eindpunten in één synchronisatiegroep. | 5 | Meerdere synchronisatiegroepen maken |
| Database, tabel-, schema- en kolomnamen | 50 tekens per naam | |
| Tabellen in een synchronisatiegroep | 500 | Meerdere synchronisatiegroepen maken |
| Kolommen in een tabel in een synchronisatiegroep | 1000 | |
| Gegevensrijgrootte in een tabel | 24 Mb |
Notitie
Er kunnen maximaal 30 eindpunten in één synchronisatiegroep aanwezig zijn als er slechts één synchronisatiegroep is. Als er meer dan één synchronisatiegroep is, mag het totale aantal eindpunten voor alle synchronisatiegroepen niet groter zijn dan 30. Als een database deel uitmaakt van meerdere synchronisatiegroepen, wordt deze geteld als meerdere eindpunten, niet als één.
Netwerkvereisten
Notitie
Als u Private Link synchroniseren gebruikt, zijn deze netwerkvereisten niet van toepassing.
Wanneer de synchronisatiegroep tot stand is gebracht, moet de Data Sync-service verbinding maken met de hubdatabase. Bij het tot stand brengen van de synchronisatiegroep moet de Azure SQL-server de volgende configuratie hebben in de Firewalls and virtual networks-instellingen:
- Openbare netwerktoegang weigeren moet zijn ingesteld op Uit.
- Azure-services en -resources toegang geven tot deze server moet zijn ingesteld op Ja, of u moet IP-regels maken voor de IP-adressen die worden gebruikt door de Data Sync-service.
Zodra de synchronisatiegroep is gemaakt en ingericht, kunt u deze instellingen uitschakelen. De synchronisatieagent maakt rechtstreeks verbinding met de hubdatabase en u kunt de IP-regels van de server firewall gebruiken of privé-eindpunten om de agent toegang te geven tot de hubserver.
Notitie
Als u de schema-instellingen van de synchronisatiegroep wijzigt, moet u de Data Sync-service opnieuw toegang geven tot de server, zodat de hubdatabase opnieuw kan worden ingericht.
Gegevensresidentie in de regio
Als u gegevens in dezelfde regio synchroniseert, worden in SQL Data Sync geen klantgegevens opgeslagen/verwerkt buiten die regio waarin het service-exemplaar wordt geïmplementeerd. Als u gegevens in verschillende regio's synchroniseert, repliceert SQL Data Sync klantgegevens naar de gekoppelde regio's.
Veelgestelde vragen over SQL Data Sync
Hoeveel kost de SQL Data Sync-service?
Er worden geen kosten in rekening gebracht voor de SQL Data Sync-service zelf. U verzamelt echter nog steeds kosten voor gegevensoverdracht voor gegevensverplaatsing in en uit uw SQL Database-exemplaar. Zie kosten voor gegevensoverdrachtvoor meer informatie.
Welke regio's ondersteunen Data Sync?
SQL Data Sync is beschikbaar in alle regio's.
Is een Azure SQL Database-account vereist?
Ja. U moet een Azure SQL Database-account hebben om de hubdatabase te hosten.
Kan ik Data Sync alleen gebruiken om te synchroniseren tussen SQL Server-databases?
Niet rechtstreeks. U kunt echter indirect synchroniseren tussen SQL Server-databases door een Hub-database in Azure te maken en vervolgens de on-premises databases toe te voegen aan de synchronisatiegroep.
Kan ik Data Sync configureren voor synchronisatie tussen databases in Azure SQL Database die deel uitmaken van verschillende abonnementen?
Ja. U kunt synchronisatie configureren tussen databases die tot resourcegroepen behoren van verschillende abonnementen, zelfs als de abonnementen tot verschillende tenants behoren.
- Als de abonnementen deel uitmaken van dezelfde tenant en u gemachtigd bent voor alle abonnementen, kunt u de synchronisatiegroep configureren in Azure Portal.
- Anders moet u PowerShell gebruiken om de synchronisatieleden toe te voegen.
- Private Link wordt niet ondersteund in scenario's tussen tenants.
Kan ik Data Sync instellen voor synchronisatie tussen databases in SQL Database die deel uitmaken van verschillende clouds (zoals openbare Azure-cloud en Azure beheerd door 21Vianet)?
Data Sync biedt geen ondersteuning voor synchronisatie tussen clouds.
Kan ik Data Sync gebruiken om gegevens uit mijn productiedatabase te seeden naar een lege database en deze vervolgens te synchroniseren?
Ja. Maak het schema handmatig in de nieuwe database door het script uit het origineel te schrijven. Nadat u het schema hebt gemaakt, voegt u de tabellen toe aan een synchronisatiegroep om de gegevens te kopiëren en gesynchroniseerd te houden.
Moet ik SQL Data Sync gebruiken om een back-up te maken van mijn databases en deze te herstellen?
Het is niet raadzaam om SQL Data Sync te gebruiken om een back-up van uw gegevens te maken. U kunt geen back-ups maken en herstellen naar een bepaald tijdstip omdat SQL Data Sync-synchronisaties niet zijn geversied. Bovendien maakt SQL Data Sync geen back-up van andere SQL-objecten, zoals opgeslagen procedures, en doet het equivalent van een herstelbewerking niet snel.
Zie Een transactioneel consistente kopie van een database in Azure SQL Database kopiërenvoor een aanbevolen back-uptechniek.
Kunnen versleutelde tabellen en kolommen door Data Sync worden gesynchroniseerd?
- Als een database Always Encrypted gebruikt, kunt u alleen de tabellen en kolommen synchroniseren die niet versleuteld. U kunt de versleutelde kolommen niet synchroniseren, omdat Data Sync de gegevens niet kan ontsleutelen.
- Als een kolom gebruikmaakt van Column-Level Encryption (CLE), kunt u de kolom synchroniseren, zolang de rijgrootte kleiner is dan de maximale grootte van 24 Mb. Data Sync behandelt de kolom die is versleuteld met sleutel (CLE) als normale binaire gegevens. Als u de gegevens voor andere synchronisatieleden wilt ontsleutelen, moet u hetzelfde certificaat hebben.
Wordt sortering ondersteund in SQL Data Sync?
Ja. SQL Data Sync biedt ondersteuning voor het configureren van sorteringsinstellingen in de volgende scenario's:
- Als de geselecteerde synchronisatieschematabellen zich nog niet in uw hub- of liddatabases bevinden, maakt de service bij het implementeren van de synchronisatiegroep automatisch de bijbehorende tabellen en kolommen met de sorteringsinstellingen die zijn geselecteerd in de lege doeldatabases.
- Als de tabellen die moeten worden gesynchroniseerd, al bestaan in zowel uw hub- als liddatabases, vereist SQL Data Sync dat de primaire-sleutelkolommen dezelfde sortering hebben tussen hub- en liddatabases om de synchronisatiegroep te kunnen implementeren. Er zijn geen sorteringsbeperkingen voor andere kolommen dan de primaire-sleutelkolommen.
Wordt federatie ondersteund in SQL Data Sync?
Federatieve basisdatabase kan zonder enige beperking worden gebruikt in de SQL Data Sync-service. U kunt het federatieve database-eindpunt niet toevoegen aan de huidige versie van SQL Data Sync.
Kan ik Data Sync gebruiken om gegevens te synchroniseren die zijn geëxporteerd uit Dynamics 365 met behulp van de BYOD-functie (Bring Your Own Database) ?
Met de Dynamics 365 Bring Your Own Database-functie kunnen beheerders gegevensentiteiten uit de toepassing exporteren naar hun eigen Microsoft Azure SQL-database. Data Sync kan worden gebruikt om deze gegevens te synchroniseren met andere databases als gegevens worden geëxporteerd met behulp van incrementele push- (volledige push wordt niet ondersteund) en triggers inschakelen in de doeldatabase is ingesteld op ja.
Hoe maak ik Data Sync in de failovergroep ter ondersteuning van herstel na noodgevallen?
SQL Data Sync biedt geen mogelijkheden voor automatische failover of herstel na noodgevallen. Als er een databasefailover naar een andere regio wordt uitgevoerd, werkt de synchronisatiegroep niet meer. Maak de synchronisatiegroep handmatig opnieuw in de failoverregio met dezelfde instellingen als de primaire regio.
Verwante inhoud
Bewaken en problemen oplossen
Wordt SQL Data Sync uitgevoerd zoals verwacht? Raadpleeg de volgende artikelen om activiteiten te bewaken en problemen op te lossen:
Meer informatie over Azure SQL Database
Zie de volgende artikelen voor meer informatie over Azure SQL Database:
- Overzicht van SQL Database
- databaselevenscyclusbeheer