Toepassingen en databases afstemmen op prestaties in Azure SQL Managed Instance
Van toepassing op:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Zodra u een prestatieprobleem hebt geïdentificeerd dat u ondervindt met Azure SQL Managed Instance, is dit artikel ontworpen om u te helpen:
- Stem uw toepassing af en pas enkele aanbevolen procedures toe die de prestaties kunnen verbeteren.
- Stem de database af door indexen en query's te wijzigen om efficiënter met gegevens te werken.
In dit artikel wordt ervan uitgegaan dat u het overzicht van bewaking en afstemming en bewaking van de prestaties hebt gecontroleerd met behulp van de Query Store. Daarnaast wordt in dit artikel ervan uitgegaan dat u geen prestatieprobleem hebt met betrekking tot cpu-resourcegebruik dat kan worden opgelost door de rekenkracht of servicelaag te verhogen om meer resources te bieden aan uw met SQL beheerde exemplaar.
Notitie
Zie Toepassingen en databases afstemmen voor prestaties in Azure SQL Database voor vergelijkbare richtlijnen in Azure SQL Database.
Uw toepassing afstemmen
In traditionele on-premises SQL Server wordt het proces van de initiële capaciteitsplanning vaak gescheiden van het proces voor het uitvoeren van een toepassing in productie. Hardware- en productlicenties worden eerst aangeschaft en de prestaties worden later afgesteld. Wanneer u Azure SQL gebruikt, is het een goed idee om het proces voor het uitvoeren van een toepassing te interweaveen en deze af te stemmen. Met het model voor het betalen van capaciteit op aanvraag kunt u uw toepassing afstemmen op het gebruik van de minimale resources die nu nodig zijn, in plaats van te veel inrichten op hardware op basis van schattingen van toekomstige groeiplannen voor een toepassing, die vaak onjuist zijn.
Sommige klanten kunnen ervoor kiezen om een toepassing niet af te stemmen en in plaats daarvan hardwarebronnen te over-inrichten. Deze benadering kan een goed idee zijn als u tijdens een drukke periode geen sleuteltoepassing wilt wijzigen. Het afstemmen van een toepassing kan echter de resourcevereisten minimaliseren en de maandelijkse facturen verlagen.
Best practices en antipatronen in het toepassingsontwerp voor Azure SQL Managed Instance
Hoewel azure SQL Managed Instance-servicelagen zijn ontworpen om de stabiliteit en voorspelbaarheid van prestaties voor een toepassing te verbeteren, kunnen sommige aanbevolen procedures u helpen uw toepassing af te stemmen om beter te profiteren van de resources met een rekenkracht. Hoewel veel toepassingen aanzienlijke prestatieverbeteringen hebben door over te schakelen naar een hogere rekenkracht of servicelaag, hebben sommige toepassingen extra afstemming nodig om te profiteren van een hoger serviceniveau.
Voor betere prestaties kunt u aanvullende toepassingsafstemming overwegen voor toepassingen met deze kenmerken:
Toepassingen met trage prestaties vanwege 'chatty'-gedrag
Chatty-toepassingen maken overmatige gegevenstoegangsbewerkingen die gevoelig zijn voor netwerklatentie. Mogelijk moet u dit soort toepassingen wijzigen om het aantal bewerkingen voor gegevenstoegang tot de database te verminderen. U kunt bijvoorbeeld de prestaties van toepassingen verbeteren met behulp van technieken zoals ad-hocquery's in batches of het verplaatsen van de query's naar opgeslagen procedures. Zie Batch-query's voor meer informatie.
Databases met een intensieve workload die niet kan worden ondersteund door een hele machine
Databases die de resources van de hoogste Premium-rekenkracht overschrijden, kunnen baat hebben bij het uitschalen van de workload. Zie sharding en functionele partitionering tussen databases voor meer informatie.
Toepassingen met suboptimale query's
Toepassingen met slecht afgestemde query's profiteren mogelijk niet van een hogere rekenkracht. Dit omvat query's die geen WHERE-component hebben, ontbrekende indexen hebben of verouderde statistieken hebben. Deze toepassingen profiteren van standaardtechnieken voor het afstemmen van queryprestaties. Zie Ontbrekende indexen en queryafstemming en hinting voor meer informatie.
Toepassingen met suboptimaal ontwerp voor gegevenstoegang
Toepassingen met inherente problemen met gelijktijdigheid van gegevenstoegang, bijvoorbeeld impasses, profiteren mogelijk niet van een hogere rekenkracht. Overweeg om retouren tegen de database te verminderen door gegevens aan de clientzijde in de cache op te cachen met de Azure Caching-service of een andere cachingtechnologie. Zie cacheopslag in de toepassingslaag.
Als u impasses in Azure SQL Managed Instance wilt voorkomen, raadpleegt u De impassehulpprogramma's van de handleiding Impasses.
Uw database afstemmen
In deze sectie kijken we naar enkele technieken die u kunt gebruiken om de database af te stemmen om de beste prestaties voor uw toepassing te verkrijgen en deze uit te voeren op de laagst mogelijke rekengrootte. Sommige van deze technieken komen overeen met traditionele best practices voor het afstemmen van SQL Server, maar andere zijn specifiek voor Azure SQL Managed Instance. In sommige gevallen kunt u de verbruikte resources voor een database onderzoeken om gebieden te vinden om traditionele SQL Server-technieken verder af te stemmen en uit te breiden voor gebruik in Azure SQL Managed Instance.
Ontbrekende indexen identificeren en toevoegen
Een veelvoorkomend probleem in de prestaties van de OLTP-database heeft betrekking op het ontwerp van de fysieke database. Databaseschema's worden vaak ontworpen en verzonden zonder op schaal te testen (in belasting of in gegevensvolume). Helaas kunnen de prestaties van een queryplan op kleine schaal acceptabel zijn, maar aanzienlijk afnemen onder gegevensvolumes op productieniveau. De meest voorkomende bron van dit probleem is het ontbreken van de juiste indexen om te voldoen aan filters of andere beperkingen in een query. Vaak kunnen ontbrekende indexen manifesten als een tabelscan uitvoeren wanneer een indexzoeken volstaat.
In dit voorbeeld gebruikt het geselecteerde queryplan een scan wanneer een zoekopdracht volstaat:
DROP TABLE dbo.missingindex;
CREATE TABLE dbo.missingindex (col1 INT IDENTITY PRIMARY KEY, col2 INT);
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO dbo.missingindex(col2) VALUES (@a);
SET @a += 1;
END
COMMIT TRANSACTION;
GO
SELECT m1.col1
FROM dbo.missingindex m1 INNER JOIN dbo.missingindex m2 ON(m1.col1=m2.col1)
WHERE m1.col2 = 4;
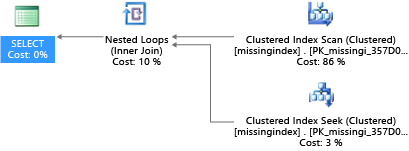
DMV's die sinds 2005 zijn ingebouwd in SQL Server, kijken naar querycompilaties waarin een index de geschatte kosten voor het uitvoeren van een query aanzienlijk zou verlagen. Tijdens het uitvoeren van query's houdt de database-engine bij hoe vaak elk queryplan wordt uitgevoerd, en wordt de geschatte kloof bijgehouden tussen het uitvoeren van het queryplan en het idee waar die index bestond. U kunt deze DMV's gebruiken om snel te raden welke wijzigingen in uw fysieke databaseontwerp de totale workloadkosten voor een database en de werkelijke workload kunnen verbeteren.
U kunt deze query gebruiken om mogelijke ontbrekende indexen te evalueren:
SELECT
CONVERT (varchar, getdate(), 126) AS runtime
, mig.index_group_handle
, mid.index_handle
, CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS improvement_measure
, 'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + '
(' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL
THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
, migs.*
, mid.database_id
, mid.[object_id]
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
In dit voorbeeld heeft de query geresulteerd in deze suggestie:
CREATE INDEX missing_index_5006_5005 ON [dbo].[missingindex] ([col2])
Nadat deze is gemaakt, kiest diezelfde SELECT-instructie een ander plan, waarbij een zoekfunctie wordt gebruikt in plaats van een scan, en vervolgens wordt het plan efficiënter uitgevoerd:
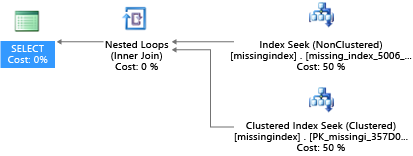
Het belangrijkste inzicht is dat de IO-capaciteit van een gedeeld basissysteem beperkter is dan die van een toegewezen servercomputer. Er is een premium voor het minimaliseren van onnodige IO om maximaal te profiteren van het systeem in de resources van elke rekenkracht van de servicelagen. De juiste opties voor het ontwerpen van fysieke databases kunnen de latentie voor afzonderlijke query's aanzienlijk verbeteren, de doorvoer verbeteren van gelijktijdige aanvragen die per schaaleenheid worden verwerkt en de kosten minimaliseren die nodig zijn om aan de query te voldoen.
Zie Niet-geclusterde indexen afstemmen met ontbrekende indexsuggesties voor meer informatie over het afstemmen van indexaanvragen.
Query's afstemmen en hinten
De queryoptimalisatie in Azure SQL Managed Instance is vergelijkbaar met de traditionele optimalisatie van SQL Server-query's. De meeste aanbevolen procedures voor het afstemmen van query's en het begrijpen van de beperkingen van het redeneringsmodel voor de queryoptimalisatie zijn ook van toepassing op Azure SQL Managed Instance. Als u query's in Azure SQL Managed Instance afstemt, profiteert u mogelijk van het verminderen van de totale resourcevereisten. Uw toepassing kan mogelijk tegen lagere kosten worden uitgevoerd dan een niet-afgestemd equivalent, omdat deze kan worden uitgevoerd met een lagere rekenkracht.
Een voorbeeld dat gebruikelijk is in SQL Server en die ook van toepassing is op Azure SQL Managed Instance, is hoe de parameters 'sniffs' van de queryoptimalisatie worden gebruikt. Tijdens de compilatie evalueert de optimalisatiefunctie voor query's de huidige waarde van een parameter om te bepalen of deze een beter queryplan kan genereren. Hoewel deze strategie vaak kan leiden tot een queryplan dat aanzienlijk sneller is dan een plan dat is gecompileerd zonder bekende parameterwaarden, werkt het momenteel onvolmaakt in Zowel Azure SQL Managed Instance. (Er is een nieuwe functie voor intelligente queryprestaties geïntroduceerd met SQL Server 2022 met de naam Met parametergevoeligheidsplanoptimalisatie wordt het scenario opgelost waarbij één plan in de cache voor een geparameteriseerde query niet optimaal is voor alle mogelijke binnenkomende parameterwaarden. Momenteel is optimalisatie van parametergevoeligheidsplan niet beschikbaar in Azure SQL Managed Instance.)
Soms wordt de parameter niet opgeslagen en soms wordt de parameter aan het snuiven, maar het gegenereerde plan is suboptimaal voor de volledige set parameterwaarden in een workload. Microsoft bevat queryhints (instructies), zodat u de intentie bewuster kunt opgeven en het standaardgedrag van parametersniffing kunt overschrijven. U kunt hints gebruiken wanneer het standaardgedrag onvolkomen is voor een specifieke klantworkload.
In het volgende voorbeeld ziet u hoe de queryprocessor een plan kan genereren dat suboptimaal is voor zowel prestaties als resourcevereisten. In dit voorbeeld ziet u ook dat als u een hint voor query's gebruikt, u de uitvoeringstijd en resourcevereisten voor uw database kunt verminderen:
DROP TABLE psptest1;
CREATE TABLE psptest1(col1 int primary key identity, col2 int, col3 binary(200));
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO psptest1(col2) values (1);
INSERT INTO psptest1(col2) values (@a);
SET @a += 1;
END
COMMIT TRANSACTION
CREATE INDEX i1 on psptest1(col2);
GO
CREATE PROCEDURE psp1 (@param1 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1
WHERE col2 = @param1
ORDER BY col2;
END
GO
CREATE PROCEDURE psp2 (@param2 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1 WHERE col2 = @param2
ORDER BY col2
OPTION (OPTIMIZE FOR (@param2 UNKNOWN))
END
GO
CREATE TABLE t1 (col1 int primary key, col2 int, col3 binary(200));
GO
Met de installatiecode wordt een tabel gemaakt met onregelmatig gedistribueerde gegevens in de t1 tabel. Het optimale queryplan verschilt op basis van welke parameter wordt geselecteerd. Helaas wordt de query niet altijd opnieuw gecompileren op basis van de meest voorkomende parameterwaarde. Het is dus mogelijk dat een suboptimaal plan in de cache wordt opgeslagen en voor veel waarden wordt gebruikt, zelfs als een ander plan gemiddeld een betere plankeuze kan zijn. Vervolgens worden in het queryplan twee opgeslagen procedures gemaakt die identiek zijn, behalve dat er een speciale queryhint is.
-- Prime Procedure Cache with scan plan
EXEC psp1 @param1=1;
TRUNCATE TABLE t1;
-- Iterate multiple times to show the performance difference
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp1 @param1=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
U wordt aangeraden ten minste tien minuten te wachten voordat u deel 2 van het voorbeeld begint, zodat de resultaten verschillen in de resulterende telemetriegegevens.
EXEC psp2 @param2=1;
TRUNCATE TABLE t1;
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp2 @param2=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
Elk deel van dit voorbeeld probeert een geparameteriseerde insert-instructie 1000 keer uit te voeren (om een voldoende belasting te genereren die moet worden gebruikt als een testgegevensset). Wanneer opgeslagen procedures worden uitgevoerd, onderzoekt de queryprocessor de parameterwaarde die tijdens de eerste compilatie aan de procedure wordt doorgegeven (parameter 'sniffing'). De processor slaat het resulterende plan in de cache op en gebruikt dit voor latere aanroepen, zelfs als de parameterwaarde anders is. Het optimale plan wordt in alle gevallen mogelijk niet gebruikt. Soms moet u de optimizer begeleiden om een plan te kiezen dat beter is voor het gemiddelde geval in plaats van het specifieke geval van toen de query voor het eerst werd gecompileerd. In dit voorbeeld genereert het eerste plan een scanplan dat alle rijen leest om elke waarde te vinden die overeenkomt met de parameter:

Omdat we de procedure hebben uitgevoerd met behulp van de waarde 1, was het resulterende plan optimaal voor de waarde 1 , maar was het suboptimaal voor alle andere waarden in de tabel. Het resultaat is waarschijnlijk niet wat u zou willen als u elk plan willekeurig zou kiezen, omdat het plan langzamer presteert en meer resources gebruikt.
Als u de test uitvoert waarop SET STATISTICS IO deze is ingesteld ON, wordt het logische scanwerk in dit voorbeeld achter de schermen uitgevoerd. U kunt zien dat er 1.148 leesbewerkingen zijn uitgevoerd door het plan (wat inefficiënt is, als het gemiddelde geval slechts één rij retourneert):

In het tweede deel van het voorbeeld wordt een queryhint gebruikt om de optimizer te vertellen een specifieke waarde te gebruiken tijdens het compilatieproces. In dit geval wordt de queryprocessor gedwongen om de waarde die als parameter wordt doorgegeven te negeren en in plaats daarvan aan te nemen UNKNOWN. Dit verwijst naar een waarde die de gemiddelde frequentie in de tabel heeft (scheeftrekken negeren). Het resulterende plan is een plan op basis van zoeken dat sneller is en gemiddeld minder resources gebruikt dan het plan in deel 1 van dit voorbeeld:
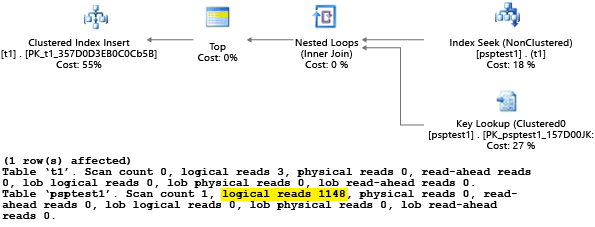
U kunt het effect zien in de sys.server_resource_stats systeemcatalogusweergave. De gegevens worden verzameld, geaggregeerd en bijgewerkt binnen intervallen van 5 tot 10 minuten. Er is één rij voor elke 15 seconden rapportage. Voorbeeld:
SELECT TOP 1000 *
FROM sys.server_resource_stats
ORDER BY start_time DESC
U kunt onderzoeken sys.server_resource_stats of de resource voor een test meer of minder resources gebruikt dan een andere test. Wanneer u gegevens vergelijkt, scheidt u de timing van tests, zodat deze zich niet in hetzelfde venster van vijf minuten in de sys.server_resource_stats weergave bevinden. Het doel van de oefening is om de totale hoeveelheid gebruikte resources te minimaliseren en niet om de piekbronnen te minimaliseren. Over het algemeen vermindert het optimaliseren van een stukje code voor latentie ook het resourceverbruik. Zorg ervoor dat de wijzigingen die u aanbrengt in een toepassing nodig zijn en dat de wijzigingen geen negatieve invloed hebben op de klantervaring voor iemand die mogelijk queryhints in de toepassing gebruikt.
Als een workload een set herhalende query's heeft, is het vaak zinvol om de optimale keuze van uw plan vast te leggen en te valideren, omdat hiermee de minimale resourcegrootte-eenheid wordt bepaald die nodig is om de database te hosten. Nadat u deze hebt gevalideerd, moet u af en toe de plannen opnieuw bekijken om ervoor te zorgen dat ze niet zijn gedegradeerd. Meer informatie over queryhints (Transact-SQL).
Best practices voor zeer grote databasearchitecturen in Azure SQL Managed Instance
In de volgende twee secties worden twee opties besproken voor het oplossen van problemen met zeer grote databases in Azure SQL Managed Instance.
Sharding tussen databases
Omdat Azure SQL Managed Instance wordt uitgevoerd op basishardware, zijn de capaciteitslimieten voor een afzonderlijke database lager dan voor een traditionele on-premises SQL Server-installatie. Sommige klanten gebruiken shardingtechnieken om databasebewerkingen over meerdere databases te verdelen wanneer de bewerkingen niet binnen de limieten van een afzonderlijke database in Azure SQL Managed Instance passen. De meeste klanten die shardingtechnieken gebruiken in Azure SQL Managed Instance splitsen hun gegevens op één dimensie in meerdere databases. Voor deze aanpak moet u begrijpen dat OLTP-toepassingen vaak transacties uitvoeren die van toepassing zijn op slechts één rij of op een kleine groep rijen in het schema.
Als een database bijvoorbeeld klantnaam, order- en ordergegevens bevat (zoals in de AdventureWorks database), kunt u deze gegevens splitsen in meerdere databases door een klant te groeperen met de gerelateerde order- en ordergegevens. U kunt garanderen dat de gegevens van de klant in een afzonderlijke database blijven. De toepassing splitst verschillende klanten over databases, zodat de belasting over meerdere databases effectief wordt verdeeld. Met sharding kunnen klanten niet alleen de maximale limiet voor de databasegrootte vermijden, maar Azure SQL Managed Instance kan ook workloads verwerken die aanzienlijk groter zijn dan de limieten van de verschillende rekengrootten, zolang elke afzonderlijke database in de servicelaaglimieten past.
Hoewel database-sharding de geaggregeerde resourcecapaciteit voor een oplossing niet vermindert, is het zeer effectief om zeer grote oplossingen te ondersteunen die zijn verspreid over meerdere databases. Elke database kan worden uitgevoerd op een andere rekenkracht om zeer grote, 'effectieve' databases met hoge resourcevereisten te ondersteunen.
Functionele partitionering
Gebruikers combineren vaak veel functies in een afzonderlijke database. Als een toepassing bijvoorbeeld logica heeft voor het beheren van inventaris voor een winkel, kan die database logica hebben die is gekoppeld aan voorraad, inkooporders bijhouden, opgeslagen procedures en geïndexeerde of gerealiseerde weergaven die rapportage aan het einde van de maand beheren. Deze techniek maakt het eenvoudiger om de database te beheren voor bewerkingen zoals back-up, maar het vereist ook dat u de hardware zo groot mogelijk maakt om de piekbelasting voor alle functies van een toepassing af te handelen.
Als u een uitschaalarchitectuur in Azure SQL Managed Instance gebruikt, is het een goed idee om verschillende functies van een toepassing op te splitsen in verschillende databases. Als u deze techniek gebruikt, wordt elke toepassing onafhankelijk geschaald. Naarmate een toepassing drukker wordt (en de belasting van de database toeneemt), kan de beheerder onafhankelijke rekengrootten kiezen voor elke functie in de toepassing. Bij de limiet kan met deze architectuur een toepassing groter zijn dan één basismachine, omdat de belasting over meerdere machines wordt verdeeld.
Batch-query's
Voor toepassingen die toegang hebben tot gegevens met behulp van grote volumes, frequente ad-hocquery's, wordt een aanzienlijke hoeveelheid reactietijd besteed aan netwerkcommunicatie tussen de toepassingslaag en de databaselaag. Zelfs wanneer zowel de toepassing als de database zich in hetzelfde datacenter bevinden, kan de netwerklatentie tussen de twee worden vergroot door een groot aantal bewerkingen voor gegevenstoegang. Als u de netwerkrondes voor de bewerkingen voor gegevenstoegang wilt verminderen, kunt u overwegen de optie te gebruiken om de ad-hocquery's te batcheren of om ze te compileren als opgeslagen procedures. Als u de ad-hocquery's batcht, kunt u meerdere query's verzenden als één grote batch in één keer naar de database. Als u ad-hocquery's compileert in een opgeslagen procedure, kunt u hetzelfde resultaat bereiken als wanneer u ze batcheert. Als u een opgeslagen procedure gebruikt, profiteert u ook van het vergroten van de kans dat de queryplannen in de database in de cache worden opgeslagen, zodat u de opgeslagen procedure opnieuw kunt gebruiken.
Sommige toepassingen zijn schrijfintensief. Soms kunt u de totale IO-belasting voor een database verminderen door na te denken over het samenvoegen van batchbewerkingen. Dit is vaak net zo eenvoudig als het gebruik van expliciete transacties in plaats van automatischcommitteren transacties in opgeslagen procedures en ad-hocbatches. Zie Batching-technieken voor databasetoepassingen in Azure voor een evaluatie van verschillende technieken die u kunt gebruiken. Experimenteer met uw eigen workload om het juiste model voor batchverwerking te vinden. Zorg ervoor dat u begrijpt dat een model mogelijk iets andere transactionele consistentiegaranties heeft. Voor het vinden van de juiste workload die het gebruik van resources minimaliseert, moet u de juiste combinatie van consistentie- en prestatieproblemen vinden.
Caching in toepassingslaag
Sommige databasetoepassingen hebben leesintensieve werkbelastingen. Cachelagen kunnen de belasting van de database verminderen en mogelijk de rekenkracht verminderen die nodig is om een database te ondersteunen met behulp van Azure SQL Managed Instance. Als u met Azure Cache voor Redis een leesintensieve werkbelasting hebt, kunt u de gegevens één keer (of misschien eenmaal per toepassingslaagcomputer, afhankelijk van de configuratie) lezen en die gegevens vervolgens buiten uw database opslaan. Dit is een manier om de databasebelasting (CPU en lees-IO) te verminderen, maar er is een effect op transactionele consistentie omdat de gegevens die uit de cache worden gelezen, mogelijk niet worden gesynchroniseerd met de gegevens in de database. Hoewel in veel toepassingen een zekere mate van inconsistentie acceptabel is, geldt dat niet voor alle workloads. U moet alle toepassingsvereisten volledig begrijpen voordat u een cachestrategie voor de toepassingslaag implementeert.
Gerelateerde inhoud
- Aankoopmodel voor vCore - Azure SQL Managed Instance
- Tempdb-instellingen configureren voor Azure SQL Managed Instance
- Prestaties van Microsoft Azure SQL Managed Instance bewaken met dynamische beheerweergaven
- Niet-geclusterde indexen afstemmen met ontbrekende indexsuggesties
- Azure SQL Managed Instance bewaken met Azure Monitor