Mogelijkheden voor meerdere modellen van Azure SQL Database en SQL Managed Instance
Van toepassing op:![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Met databases met meerdere modellen kunt u gegevens opslaan en ermee werken in meerdere indelingen, zoals relationele gegevens, grafieken, JSON- of XML-documenten, ruimtelijke gegevens en sleutel-waardeparen.
De Azure SQL-serie producten maakt gebruik van een relationeel model dat de beste prestaties biedt voor verschillende toepassingen voor algemeen gebruik. Azure SQL-producten zoals Azure SQL Database en SQL Managed Instance zijn echter niet beperkt tot relationele gegevens. Met deze indelingen kunt u niet-relationele indelingen gebruiken die nauw zijn geïntegreerd in het relationele model.
Overweeg het gebruik van de mogelijkheden voor meerdere modellen van Azure SQL in de volgende gevallen:
- U hebt informatie of structuren die beter geschikt zijn voor NoSQL-modellen en u geen afzonderlijke NoSQL-database wilt gebruiken.
- Een meerderheid van uw gegevens is geschikt voor een relationeel model en u moet enkele delen van uw gegevens modelleren in een NoSQL-stijl.
- U wilt de Transact-SQL-taal gebruiken om zowel relationele als NoSQL-gegevens op te vragen en te analyseren, en die gegevens vervolgens te integreren met hulpprogramma's en toepassingen die de SQL-taal kunnen gebruiken.
- U wilt databasefuncties zoals in-memory technologieën toepassen om de prestaties van uw analyses of de verwerking van uw NoSQL-gegevensstructuren te verbeteren. U kunt transactionele replicatie of leesbare replica's gebruiken om kopieën van uw gegevens te maken en enkele analyseworkloads uit de primaire database te offloaden.
In de volgende secties worden de belangrijkste mogelijkheden voor meerdere modellen van Azure SQL beschreven.
Notitie
U kunt JSONPath-expressies, XQuery-/XPath-expressies, ruimtelijke functies en grafiekquery-expressies gebruiken in dezelfde Transact-SQL-query om toegang te krijgen tot gegevens die u in de database hebt opgeslagen. Elke hulpprogramma of programmeertaal die Transact-SQL-query's kan uitvoeren, kan die queryinterface ook gebruiken voor toegang tot gegevens met meerdere modellen. Dit is het belangrijkste verschil met databases met meerdere modellen, zoals Azure Cosmos DB, die gespecialiseerde API's bieden voor gegevensmodellen.
Graph-functies
Azure SQL-producten bieden mogelijkheden voor grafiekdatabases om veel-op-veel-relaties in een database te modelleren. Een grafiek is een verzameling knooppunten (of hoekpunten) en randen (of relaties). Een knooppunt vertegenwoordigt een entiteit (bijvoorbeeld een persoon of een organisatie). Een rand vertegenwoordigt een relatie tussen de twee knooppunten die hiermee worden verbonden (bijvoorbeeld likes of vrienden).
Hier volgen enkele functies die een grafiekdatabase uniek maken:
- Randen zijn eersteklas entiteiten in een grafiekdatabase. Ze kunnen kenmerken of eigenschappen hebben die eraan zijn gekoppeld.
- Eén rand kan flexibel meerdere knooppunten in een grafiekdatabase verbinden.
- U kunt eenvoudig patroonkoppelingen en navigatiequery's met meerdere hops uitdrukken.
- U kunt transitieve sluitings- en polymorfe query's eenvoudig uitdrukken.
Grafiekrelaties en grafiekquerymogelijkheden zijn geïntegreerd in Transact-SQL en krijgen de voordelen van het gebruik van de SQL Server-database-engine als het fundamentele databasebeheersysteem. Graph-functies maken gebruik van standaard Transact-SQL-query's die zijn verbeterd met de grafiekoperator MATCH om query's uit te voeren op de grafiekgegevens.
Een relationele database kan alles bereiken wat een grafiekdatabase kan. Een grafiekdatabase kan het echter eenvoudiger maken om bepaalde query's uit te drukken. Uw beslissing om er een te kiezen, kan zijn gebaseerd op de volgende factoren:
- U moet hiërarchische gegevens modelleren waarbij één knooppunt meerdere bovenouders kan hebben, zodat u het gegevenstype hierarchyId niet kunt gebruiken.
- Uw toepassing heeft complexe veel-op-veel-relaties. Naarmate de toepassing zich ontwikkelt, worden er nieuwe relaties toegevoegd.
- U moet onderling verbonden gegevens en relaties analyseren.
- U wilt grafiekspecifieke T-SQL-zoekvoorwaarden gebruiken, zoals SHORTEST_PATH.
JSON-functies
In Azure SQL-producten kunt u gegevens parseren en opvragen die worden weergegeven in de JSON-indeling (JavaScript Object Notation) en uw relationele gegevens exporteren als JSON-tekst. JSON is een kernfunctie van de SQL Server-database-engine.
Met JSON-functies kunt u JSON-documenten in tabellen plaatsen, relationele gegevens transformeren in JSON-documenten en JSON-documenten transformeren in relationele gegevens. U kunt de standaardtaal Transact-SQL gebruiken die is uitgebreid met JSON-functies voor het parseren van documenten. U kunt ook niet-geclusterde indexen, columnstore-indexen of tabellen die zijn geoptimaliseerd voor geheugen, gebruiken om uw query's te optimaliseren.
JSON is een populaire gegevensindeling voor het uitwisselen van gegevens in moderne web- en mobiele toepassingen. JSON wordt ook gebruikt voor het opslaan van semi-gestructureerde gegevens in logboekbestanden of in NoSQL-databases. Veel REST-webservices retourneren resultaten die zijn opgemaakt als JSON-tekst of accepteren gegevens die zijn opgemaakt als JSON.
De meeste Azure-services hebben REST-eindpunten die JSON retourneren of gebruiken. Deze services omvatten Azure Cognitive Search, Azure Storage en Azure Cosmos DB.
Als u JSON-tekst hebt, kunt u gegevens extraheren uit JSON of controleren of JSON correct is opgemaakt met behulp van de ingebouwde functies JSON_VALUE, JSON_QUERY en ISJSON. De andere functies zijn:
- JSON_MODIFY: Hiermee kunt u waarden in JSON-tekst bijwerken.
- OPENJSON: Kan een matrix van JSON-objecten transformeren in een set rijen, voor geavanceerdere query's en analyses. Elke SQL-query kan worden uitgevoerd op de geretourneerde resultatenset.
- VOOR JSON: Hiermee kunt u gegevens opmaken die zijn opgeslagen in uw relationele tabellen als JSON-tekst.
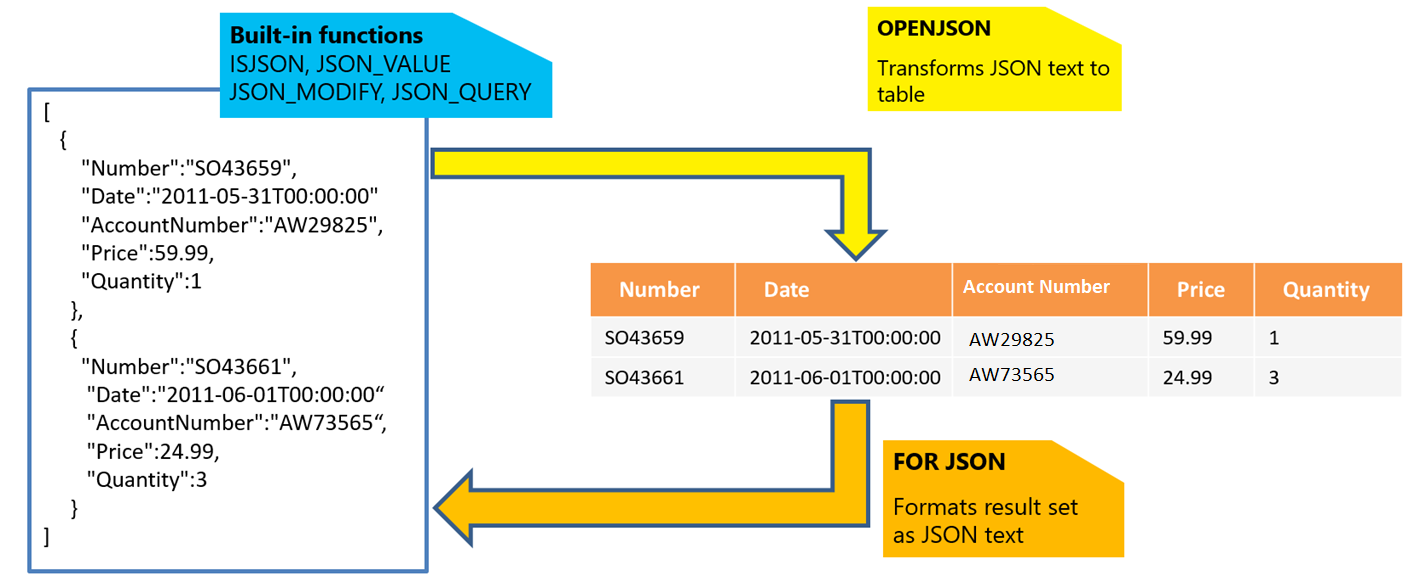
Zie Werken met JSON-gegevens voor meer informatie.
U kunt documentmodellen gebruiken in plaats van de relationele modellen in bepaalde specifieke scenario's:
- Hoge normalisatie van het schema biedt geen aanzienlijke voordelen omdat u alle velden van de objecten tegelijk opent of u geen genormaliseerde delen van de objecten bijwerkt. Het genormaliseerde model verhoogt echter de complexiteit van uw query's, omdat u een groot aantal tabellen moet samenvoegen om de gegevens op te halen.
- U werkt met toepassingen die systeemeigen JSON-documenten gebruiken voor communicatie- of gegevensmodellen en u wilt geen meer lagen introduceren waarmee relationele gegevens worden getransformeerd in JSON en omgekeerd.
- U moet uw gegevensmodel vereenvoudigen door onderliggende tabellen of entiteitsobjectwaardepatronen te denormaliseren.
- U moet gegevens laden of exporteren die zijn opgeslagen in JSON-indeling zonder een extra hulpprogramma waarmee de gegevens worden geparseerd.
XML-functies
Met XML-functies kunt u XML-gegevens opslaan en indexeren in uw database en systeemeigen XQuery-/XPath-bewerkingen gebruiken om te werken met XML-gegevens. Azure SQL-producten hebben een gespecialiseerd, ingebouwd XML-gegevenstype en queryfuncties waarmee XML-gegevens worden verwerkt.
De SQL Server-database-engine biedt een krachtig platform voor het ontwikkelen van toepassingen voor het beheren van semi-gestructureerde gegevens. Ondersteuning voor XML is geïntegreerd in alle onderdelen van de database-engine en omvat:
- De mogelijkheid om XML-waarden systeemeigen op te slaan in een xml-gegevenstypekolom die kan worden getypt op basis van een verzameling XML-schema's of niet-getypt. U kunt de XML-kolom indexeren.
- De mogelijkheid om een XQuery-query op te geven voor XML-gegevens die zijn opgeslagen in kolommen en variabelen van het XML-type. U kunt XQuery-functies gebruiken in elke Transact-SQL-query die toegang heeft tot een gegevensmodel dat u in uw database gebruikt.
- Automatische indexering van alle elementen in XML-documenten met behulp van de primaire XML-index. U kunt ook de exacte paden opgeven die moeten worden geïndexeerd met behulp van de secundaire XML-index.
OPENROWSET, waarmee xml-gegevens bulksgewijs kunnen worden geladen.- De mogelijkheid om relationele gegevens te transformeren in XML-indeling.
U kunt documentmodellen gebruiken in plaats van de relationele modellen in bepaalde specifieke scenario's:
- Hoge normalisatie van het schema biedt geen aanzienlijke voordelen omdat u alle velden van de objecten tegelijk opent of u geen genormaliseerde delen van de objecten bijwerkt. Het genormaliseerde model verhoogt echter de complexiteit van uw query's, omdat u een groot aantal tabellen moet samenvoegen om de gegevens op te halen.
- U werkt met toepassingen die systeemeigen XML-documenten gebruiken voor communicatie of gegevensmodellen en u wilt niet meer lagen introduceren waarmee relationele gegevens worden getransformeerd in JSON en omgekeerd.
- U moet uw gegevensmodel vereenvoudigen door onderliggende tabellen of entiteitsobjectwaardepatronen te denormaliseren.
- U moet gegevens laden of exporteren die zijn opgeslagen in XML-indeling zonder een extra hulpprogramma waarmee de gegevens worden geparseerd.
Ruimtelijke functies
Ruimtelijke gegevens vertegenwoordigen informatie over de fysieke locatie en vorm van objecten. Deze objecten kunnen puntlocaties of complexere objecten zijn, zoals landen/regio's, wegen of meren.
Azure SQL ondersteunt twee typen ruimtelijke gegevens:
- Het geometrietype vertegenwoordigt gegevens in een Euclidisch (plat) coördinatensysteem.
- Het geografietype vertegenwoordigt gegevens in een round-earthcoördinaatsysteem.
Met ruimtelijke functies in Azure SQL kunt u geometrische en geografische gegevens opslaan. U kunt ruimtelijke objecten in Azure SQL gebruiken om gegevens die worden weergegeven in JSON-indeling te parseren en er query's op uit te voeren en uw relationele gegevens als JSON-tekst te exporteren. Deze ruimtelijke objecten omvatten Punt, LineString en Veelhoek. Azure SQL biedt ook gespecialiseerde ruimtelijke indexen die u kunt gebruiken om de prestaties van uw ruimtelijke query's te verbeteren.
Ruimtelijke ondersteuning is een kernfunctie van de SQL Server-database-engine.
Sleutel-waardeparen
Azure SQL-producten hebben geen gespecialiseerde typen of structuren die ondersteuning bieden voor sleutel-waardeparen, omdat sleutel-waardestructuren systeemeigen kunnen worden weergegeven als standaard relationele tabellen:
CREATE TABLE Collection (
Id int identity primary key,
Data nvarchar(max)
)
U kunt deze sleutel-waardestructuur aanpassen aan uw behoeften zonder beperkingen. De waarde kan bijvoorbeeld een XML-document zijn in plaats van het nvarchar(max) type. Als de waarde een JSON-document is, kunt u een CHECK beperking gebruiken waarmee de geldigheid van JSON-inhoud wordt gecontroleerd. U kunt een willekeurig aantal waarden met betrekking tot één sleutel in de extra kolommen plaatsen. Voorbeeld:
- Voeg berekende kolommen en indexen toe om gegevenstoegang te vereenvoudigen en te optimaliseren.
- Definieer de tabel als een tabel die is geoptimaliseerd voor geheugen, alleen schema's om betere prestaties te krijgen.
Zie Hoe bwin SQL Server 2016 In-Memory OLTP gebruikt om ongekende prestaties en schaal te bereiken, voor een voorbeeld van hoe een relationeel model effectief kan worden gebruikt als een sleutel-waardepaaroplossing in de praktijk. In deze casestudy gebruikte bwin een relationeel model voor zijn ASP.NET cachingoplossing om 1,2 miljoen batches per seconde te bereiken.
Volgende stappen
Mogelijkheden voor meerdere modellen zijn kernfuncties van SQL Server-database-engine die worden gedeeld tussen Azure SQL-producten. Zie de volgende artikelen voor meer informatie over deze functies: