Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In deze zelfstudie leert u hoe u een Azure Data Factory-pijplijn maakt en uitvoert waarmee een Azure Batch-workload wordt uitgevoerd. Een Python-script wordt uitgevoerd op de Batch-knooppunten om csv-invoer (door komma's gescheiden waarden) op te halen uit een Azure Blob Storage-container, de gegevens te bewerken en de uitvoer naar een andere opslagcontainer te schrijven. Je gebruikt Batch Explorer om een Batch pool en nodes te maken, en Azure Storage Explorer om te werken met opslagcontainers en bestanden.
In deze tutorial leer je hoe je:
- Gebruik Batch Explorer om een Batch-pool en knooppunten te maken.
- Gebruik Storage Explorer om opslagcontainers te maken en invoerbestanden te uploaden.
- Ontwikkel een Python-script om invoergegevens te manipuleren en output te produceren.
- Maak een Data Factory-pijplijn waarmee de Batch-workload wordt uitgevoerd.
- Gebruik Batch Explorer om de output logbestanden te bekijken.
Prerequisites
- Een Azure-account met een actieve abonnement. Als je er geen hebt, maak een gratis account aan.
- Een Batch-account met een gekoppeld Azure Storage-account. U kunt de accounts aanmaken met een van de volgende methoden: Azure portal | Azure CLI | Bicep | ARM template | Terraform.
- Een Data Factory-instantie. Om de datafabriek aan te maken, volgt u de instructies in Een datafabriek maken.
- Batch Explorer is gedownload en geïnstalleerd.
- Storage Explorer gedownload en geïnstalleerd.
-
Python 3.8 of hoger, waarbij het azure-storage-blob-pakket is geïnstalleerd met behulp van
pip. - De iris.csv invoergegevensset die is gedownload van GitHub.
Gebruik Batch Explorer om een Batch-pool en knooppunten te maken
Gebruik Batch Explorer om een pool van rekendiensten te maken om uw werklast uit te voeren.
Meld u aan bij Batch Explorer met uw Azure-referenties.
Selecteer uw Batch-account.
Selecteer Pools in de linkerzijbalk en selecteer vervolgens het +-pictogram om een pool toe te voegen.
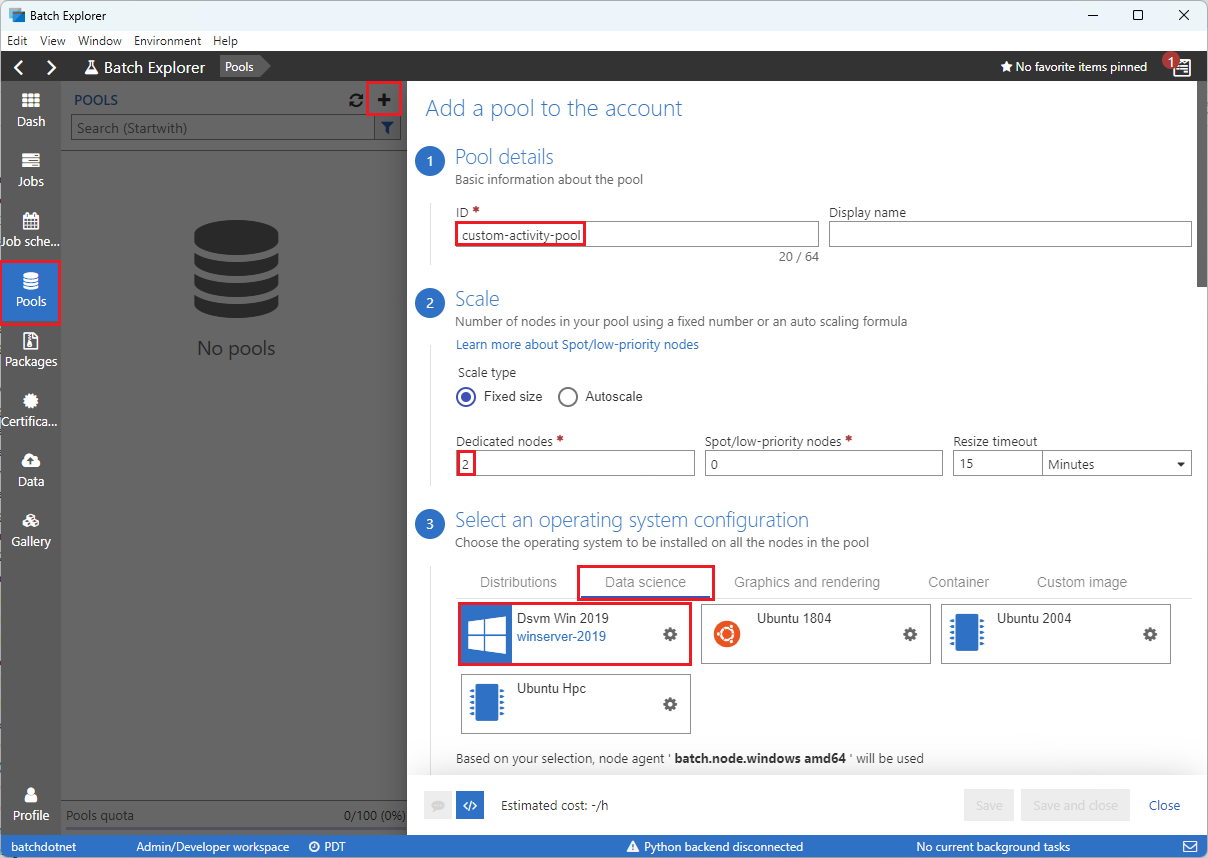
Vul het formulier Een pool toevoegen aan de account in als volgt:
- Voer onder IDeen aangepaste activiteitspool in.
- Voer onder Toegewezen knooppunten2 in.
- Als u een configuratie van een besturingssysteem selecteert, selecteert u het tabblad Data science en selecteert u vervolgens Dsvm Win 2019.
- Voor Kies een formaat voor de virtuele machine, selecteer Standard_F2s_v2.
- Selecteer voor Starten van de taakEen begintaak toevoegen.
Voer op het startscherm onder Commandoregel
cmd /c "pip install azure-storage-blob pandas"in en kies vervolgens Selecteren. Deze opdracht installeert hetazure-storage-blobpakket op elke node zodra het wordt gestart.
Selecteer Opslaan en sluiten.

Gebruik Storage Explorer om blobcontainers te maken
Gebruik Storage Explorer om blob containers te maken om invoer- en uitvoerbestanden op te slaan, en upload vervolgens uw invoerbestanden.
- Meld u aan bij Storage Explorer met uw Azure-referenties.
- Zoek en vouw in de linkerzijbalk het opslagaccount uit dat is gekoppeld aan uw Batch-account.
- Klik met de rechtermuisknop op Blob Containers, en selecteer Create Blob Container, of selecteer Create Blob Container via Actions onderaan de zijbalk.
- Voer input in het invoerveld in.
- Maak nog een blobcontainer aan met de naam output.
- Selecteer de input container en selecteer vervolgens Upload>Bestanden uploaden in het rechterpaneel.
- Op het scherm Bestanden uploaden onder Geselecteerde bestanden, selecteer de drie puntjes ... naast het invoerveld.
- Navigeer naar de locatie van uw gedownloade iris.csv-bestand, selecteer Openen en selecteer vervolgens Uploaden.

Ontwikkel een Python-script
Het volgende Python-script laadt het iris.csv-datasetbestand van je Storage Explorer input-container, manipuleert de gegevens en slaat de resultaten op in de output-container.
Het script dient de verbindingsreeks te gebruiken voor het Azure Storage-account dat is gekoppeld aan uw Batch-account. Om de verbindingsreeks te verkrijgen:
- In de Azure-portal zoek en selecteer de naam van de opslagaccount die aan je Batch-account is gekoppeld.
- Op de pagina voor het opslagaccount selecteert u Toegangssleutels in de linker navigatie onder Beveiliging + netwerken.
- Selecteer Onder key1 de optie Weergeven naast verbindingsreeks en selecteer vervolgens het pictogram Kopiëren om de verbindingsreeks te kopiëren.
Plak de verbindingstekst in het volgende script en vervang de <storage-account-connection-string> placeholder. Sla het script op als een bestand met de naam main.py.
Belangrijk
Het beschikbaar maken van accountsleutels in de app-bron wordt niet aanbevolen voor productiegebruik. Je moet de toegang tot inloggegevens beperken en er in je code naar verwijzen door gebruik te maken van variabelen of een configuratiebestand. Het is het beste om Batch- en opslagaccountsleutels in Azure Key Vault op te slaan.
# Load libraries
# from azure.storage.blob import BlobClient
from azure.storage.blob import BlobServiceClient
import pandas as pd
import io
# Define parameters
connectionString = "<storage-account-connection-string>"
containerName = "output"
outputBlobName = "iris_setosa.csv"
# Establish connection with the blob storage account
blob = BlobClient.from_connection_string(conn_str=connectionString, container_name=containerName, blob_name=outputBlobName)
# Initialize the BlobServiceClient (This initializes a connection to the Azure Blob Storage, downloads the content of the 'iris.csv' file, and then loads it into a Pandas DataFrame for further processing.)
blob_service_client = BlobServiceClient.from_connection_string(conn_str=connectionString)
blob_client = blob_service_client.get_blob_client(container_name=containerName, blob_name=outputBlobName)
# Download the blob content
blob_data = blob_client.download_blob().readall()
# Load iris dataset from the task node
# df = pd.read_csv("iris.csv")
df = pd.read_csv(io.BytesIO(blob_data))
# Take a subset of the records
df = df[df['Species'] == "setosa"]
# Save the subset of the iris dataframe locally in the task node
df.to_csv(outputBlobName, index = False)
with open(outputBlobName, "rb") as data:
blob.upload_blob(data, overwrite=True)
Raadpleeg de documentatie van Azure Blob Storage voor meer informatie over het werken met Azure Blob Storage.
Voer het script lokaal uit om de functionaliteit te testen en valideren.
python main.py
Het script moet een uitvoerbestand met de naam iris_setosa.csv produceren dat alleen de gegevensrecords bevat met Species = setosa. Nadat u hebt gecontroleerd of het correct werkt, uploadt u het main.py scriptbestand naar de invoercontainer van Storage Explorer.
Stel een Data Factory-pijplijn in
Maak en valideer een Data Factory-pijplijn die gebruikmaakt van uw Python-script.
Verkrijg accountinformatie
De Data Factory-pijplijn maakt gebruik van uw Batch- en Storage-accountnamen, accountcodes en Batch-accountendpoint. Verkrijg deze informatie van de Azure portal:
Zoek in de Azure-zoekbalk naar uw Batch-accountnaam en selecteer deze.
Selecteer sleutels in de linkernavigatiebalk op de pagina van uw Batch-account.
Op de Sleutels pagina, kopieer de volgende waarden:
- Batchaccount
- Account-eindpunt
- Primaire toegangssleutel
- Naam van opslagaccount
- Key1
De pijplijn maken en uitvoeren
Als Azure Data Factory Studio nog niet wordt uitgevoerd, selecteert u Start studio op uw Data Factory-pagina in Azure Portal.
In Data Factory Studio, selecteer het Author-potloodpictogram in de linker navigatiebalk.
Onder Factory Resources, selecteer het +-icoon en selecteer vervolgens Pipeline.
In het Eigenschappen-venster aan de rechterkant, verander de naam van de pijplijn naar Run Python.
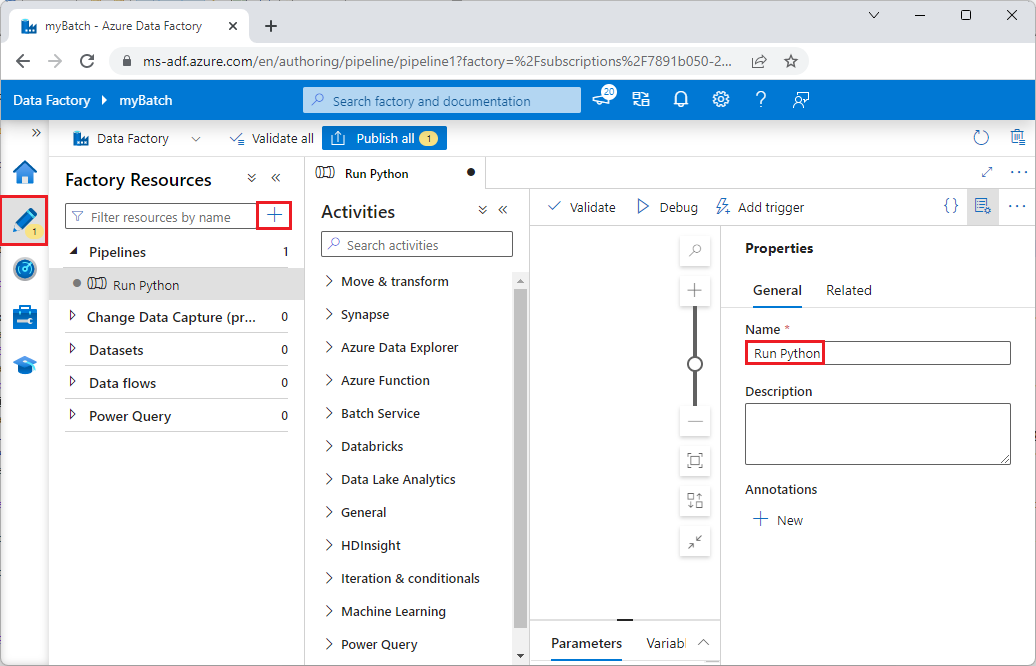
In het deelvenster Activiteiten, vouw Batch Service uit en sleep de Aangepaste activiteit naar het ontwerpoppervlak voor de pijplijn.
Voer onder het ontwerpcanvas op het tabblad AlgemeentestPipeline onder Naam in.
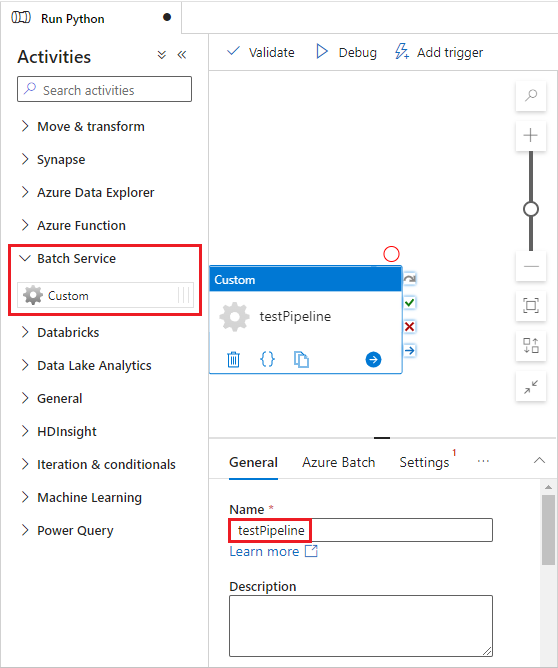
Selecteer het tabblad Azure Batch en selecteer vervolgens Nieuw.
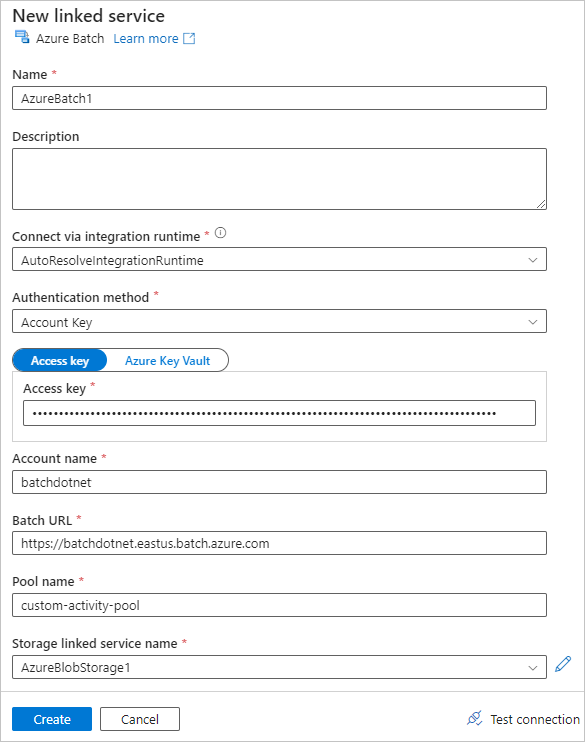
Vul het formulier Nieuwe gekoppelde service als volgt in:
- Naam: Voer een naam in voor de gekoppelde service, zoals AzureBatch1.
- Toegangssleutel: Voer de primaire toegangssleutel in die je hebt gekopieerd van je Batch-account.
- Account name: Voer uw Batch-accountnaam in.
-
Batch URL: Voer het account-eindpunt in dat je hebt gekopieerd van je Batch-account, zoals
https://batchdotnet.eastus.batch.azure.com. - Poolnaam: Voer custom-activity-pool in, de pool die je in Batch Explorer hebt gemaakt.
- Storage account linked service name: Selecteer Nieuw. Op het volgende scherm, voer een Naam in voor de gekoppelde opslagservice, zoals AzureBlobStorage1, selecteer je Azure-abonnement en gekoppelde opslagaccount, en selecteer vervolgens Maken.
Onderaan het Batch Nieuwe gekoppelde service scherm, selecteer Verbinding testen. Wanneer de verbinding succesvol is, selecteer Create.
Selecteer het Instellingen tabblad, en voer de volgende instellingen in of selecteer ze.
-
Opdracht: Druk op
cmd /C python main.py. - Koppelingsservice resource: Selecteer de gekoppelde opslagservice die je hebt gemaakt, zoals AzureBlobStorage1, en test de verbinding om ervoor te zorgen dat deze succesvol is.
- Map pad: Selecteer het mapicoon en selecteer vervolgens de invoer container en klik op OK. De bestanden uit deze map worden van de container naar de poolnodes gedownload voordat het Python-script wordt uitgevoerd.
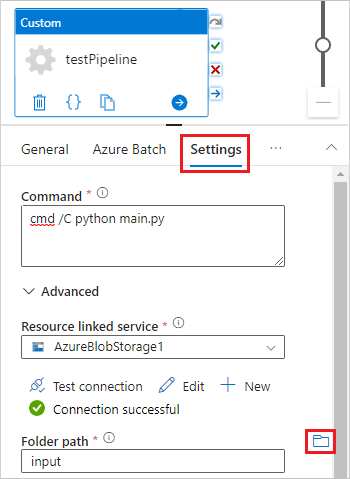
-
Opdracht: Druk op
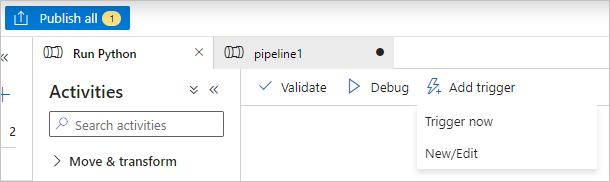
Selecteer Valideren op de pijplijnwerkbalk om de pijplijn te valideren.
Selecteer Debug om de pijplijn te testen en ervoor te zorgen dat deze correct werkt.
Selecteer Publish all om de pijplijn te publiceren.
Selecteer Trigger toevoegen en selecteer vervolgens Nu activeren om de pijplijn uit te voeren, of Nieuw/Bewerken om deze in te plannen.

Gebruik Batch Explorer om logbestanden te bekijken
Als het uitvoeren van je pipeline waarschuwingen of fouten oplevert, kun je Batch Explorer gebruiken om de stdout.txt en stderr.txt uitvoerbestanden te bekijken voor meer informatie.
- Kies in Batch Explorer Jobs in de linkerzijbalk.
- Selecteer de adfv2-custom-activity-pool-taak.
- Selecteer een taak die een mislukte uitgangscode had.
- Bekijk de bestanden stdout.txt en stderr.txt om uw probleem te onderzoeken en te diagnosticeren.
Opruimen van middelen
Batch-accounts, opdrachten en taken zijn gratis, maar rekenknooppunten kosten zelfs wanneer ze geen taken uitvoeren. U kunt het beste alleen knooppuntgroepen toewijzen als dat nodig is en de pools verwijderen wanneer u klaar bent. Als u pools verwijdert, worden alle taakuitvoer op de knooppunten en de knooppunten zelf verwijderd.
Invoer- en uitvoerbestanden blijven in het opslagaccount en kunnen kosten in rekening brengen. Wanneer u de bestanden niet meer nodig hebt, kunt u de bestanden of containers verwijderen. Wanneer je je Batch-account of gekoppelde opslagaccount niet langer nodig hebt, kun je ze verwijderen.
Volgende stappen
In deze zelfstudie hebt u geleerd hoe u een Python-script gebruikt met Batch Explorer, Storage Explorer en Data Factory om een Batch-workload uit te voeren. Voor meer informatie over Data Factory, zie Wat is Azure Data Factory?