Verantwoordelijke en vertrouwde AI
Microsoft beschrijft zes belangrijke principes voor verantwoordelijke AI: verantwoordelijkheid, inclusiviteit, betrouwbaarheid en veiligheid, eerlijkheid, transparantie en privacy en beveiliging. Deze principes zijn essentieel voor het creëren van verantwoorde en betrouwbare AI wanneer deze overstapt naar basisproducten en -services. Ze worden geleid door twee perspectieven: ethisch en verklaarbaar.
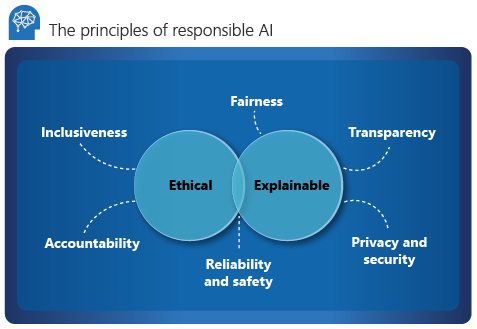
Ethische
Vanuit een ethisch perspectief moet AI het volgende doen:
- Wees eerlijk en inclusief in zijn beweringen.
- Verantwoordelijk zijn voor zijn beslissingen.
- Verschillende rassen, handicaps of achtergronden niet discrimineren of belemmeren.
In 2017 heeft Microsoft een adviescommissie opgericht voor AI, ethiek en effecten in engineering en onderzoek (Aether). De belangrijkste verantwoordelijkheid van de commissie is het adviseren over problemen, technologieën, processen en best practices voor verantwoorde AI. Zie Understanding the Microsoft governance model - Aether + Office of Responsible AI (Inzicht in het Microsoft-governancemodel - Aether + Office of Responsible AI) voor meer informatie.
Verantwoordelijkheid
Verantwoordelijkheid is een essentiële pijler van verantwoorde AI. De mensen die een AI-systeem ontwerpen en implementeren, moeten verantwoordelijk zijn voor de acties en beslissingen, vooral naarmate we meer autonome systemen ontwikkelen.
Organisaties moeten overwegen om een interne controle-instantie op te richten die toezicht, inzichten en richtlijnen biedt over het ontwikkelen en implementeren van AI-systemen. Deze richtlijnen kunnen variëren, afhankelijk van het bedrijf en de regio, en moeten het AI-traject van een organisatie weerspiegelen.
Inclusiviteit
Inclusiviteit vereist dat AI rekening moet houden met alle menselijke rassen en ervaringen. Inclusieve ontwerpprocedures kunnen ontwikkelaars helpen bij het begrijpen en aanpakken van potentiële barrières die onbedoeld mensen kunnen uitsluiten. Waar mogelijk moeten organisaties spraak-naar-tekst-, tekst-naar-spraak- en visuele herkenningstechnologie gebruiken om mensen met gehoor-, visuele en andere beperkingen te ondersteunen.
Betrouwbaarheid en veiligheid
AI-systemen kunnen alleen worden vertrouwd als ze betrouwbaar en veilig zijn. Het is belangrijk dat een systeem werkt zoals het oorspronkelijk is ontworpen en veilig reageert op nieuwe situaties. De inherente tolerantie moet zich verzetten tegen beoogde of onbedoelde manipulatie.
Een organisatie moet strenge tests en validaties uitvoeren voor bedrijfsomstandigheden om ervoor te zorgen dat het systeem veilig reageert op edge-gevallen. Het moet A/B-tests en methoden voor kampioen/uitdager integreren in het evaluatieproces.
De prestaties van een AI-systeem kunnen na verloop van tijd afnemen. Een organisatie moet een robuust bewakings- en modeltraceringsproces opzetten om reactief en proactief de prestaties van het model te meten (en het zo nodig opnieuw te trainen voor modernisering).
Verklaarbaar
Uitlegbaarheid helpt gegevenswetenschappers, auditors en zakelijke besluitvormers ervoor te zorgen dat AI-systemen hun beslissingen kunnen rechtvaardigen en hoe ze tot hun conclusies komen. Uitlegbaarheid zorgt er ook voor dat het bedrijfsbeleid, industrienormen en overheidsvoorschriften worden nageleefd.
Een data scientist moet aan een belanghebbende kunnen uitleggen hoe deze bepaalde niveaus van nauwkeurigheid heeft bereikt en wat van invloed is op het resultaat. Om te voldoen aan het beleid van het bedrijf, heeft een auditor een hulpprogramma nodig dat het model valideert. Een zakelijke beslisser moet vertrouwen krijgen door een transparant model te bieden.
Hulpmiddelen voor uitleg
Microsoft heeft InterpretML ontwikkeld, een opensource-toolkit waarmee organisaties modelverklaarbaarheid kunnen bereiken. Het ondersteunt glass-box- en black-box-modellen:
Glazen doosmodellen zijn te interpreteren vanwege hun structuur. Voor deze modellen biedt Explainable Boosting Machine (EBM) de status van het algoritme op basis van een beslissingsstructuur of lineaire modellen. EBM biedt verklaringen zonder verlies en kan worden bewerkt door domeinexperts.
Black-box-modellen zijn moeilijker te interpreteren vanwege een complexe interne structuur, het neurale netwerk. Uitlegprogramma's zoals lokale interpreteerbare model-agnostische uitleg (LIME) of SHapley Additive exPlanations (SHAP) interpreteren deze modellen door de relatie tussen de invoer en uitvoer te analyseren.
Fairlearn is een Azure Machine Learning-integratie en een opensource-toolkit voor de SDK en de grafische gebruikersinterface van AutoML. Het maakt gebruik van uitlegfuncties om te begrijpen wat voornamelijk van invloed is op het model en maakt gebruik van domeinexperts om deze invloeden te valideren.
Bekijk de interpreteerbaarheid van modellen in Azure Machine Learning voor meer informatie over uitlegbaarheid.
Verdeling
Eerlijkheid is een kern ethisch principe dat alle mensen willen begrijpen en toepassen. Dit principe is nog belangrijker wanneer AI-systemen worden ontwikkeld. Belangrijke controles en evenwichten moeten ervoor zorgen dat de beslissingen van het systeem geen onderscheid maken tussen een groep of individu op basis van geslacht, ras, seksuele geaardheid of religie.
Microsoft biedt een controlelijst voor AI-eerlijkheid die richtlijnen en oplossingen biedt voor AI-systemen. Deze oplossingen zijn losjes onderverdeeld in vijf fasen: envision, prototype, build, launch en evolve. Elke fase bevat aanbevolen due diligence-activiteiten die helpen de impact van oneerlijkheid in het systeem te minimaliseren.
Fairlearn integreert met Azure Machine Learning en ondersteunt gegevenswetenschappers en ontwikkelaars bij het beoordelen en verbeteren van de eerlijkheid van hun AI-systemen. Het biedt algoritmen voor het beperken van oneerlijke behandeling en een interactief dashboard waarmee de eerlijkheid van het model wordt gevisualiseerd. Een organisatie moet de toolkit gebruiken en de eerlijkheid van het model nauwkeurig beoordelen terwijl het wordt gebouwd. Deze activiteit moet een integraal onderdeel zijn van het data science-proces.
Meer informatie over het beperken van oneerlijkheid in machine learning-modellen.
Transparantie
Door transparantie te bereiken, krijgt het team inzicht in het volgende:
- De gegevens en algoritmen die zijn gebruikt om het model te trainen.
- De transformatielogica die is toegepast op de gegevens.
- Het uiteindelijke model dat is gegenereerd.
- De gekoppelde assets van het model.
Deze informatie biedt inzicht in hoe het model is gemaakt, zodat het team het op een transparante manier kan reproduceren. Momentopnamen in Azure Machine Learning-werkruimten ondersteunen transparantie door alle trainingsgerelateerde assets en metrische gegevens die bij het experiment betrokken zijn, vast te leggen of opnieuw te trainen.
Privacy en beveiliging
Een gegevenshouder is verplicht om de gegevens in een AI-systeem te beschermen. Privacy en beveiliging zijn een integraal onderdeel van dit systeem.
Persoonlijke gegevens moeten worden beveiligd en de toegang tot deze gegevens mag geen inbreuk maken op de privacy van een persoon. Differentiële privacy van Azure helpt bij het beschermen en behouden van privacy door gegevens willekeurig te maken en ruis toe te voegen om persoonlijke gegevens voor gegevenswetenschappers te verbergen.
Richtlijnen voor menselijke AI
Richtlijnen voor menselijk AI-ontwerp bestaan uit 18 principes die gedurende vier perioden plaatsvinden: in eerste instantie, tijdens interactie, wanneer het verkeerd is en in de loop van de tijd. Deze principes helpen een organisatie een meer inclusief en mensgericht AI-systeem te produceren.
Aanvankelijk
Verduidelijken wat het systeem kan doen. Als het AI-systeem metrische gegevens gebruikt of genereert, is het belangrijk om ze allemaal te laten zien en hoe ze worden bijgehouden.
Verduidelijken hoe goed het systeem kan doen wat het doet. Help gebruikers te begrijpen dat AI niet volledig nauwkeurig is. Stel verwachtingen in voor wanneer het AI-systeem fouten kan maken.
Tijdens interactie
Contextafhankelijk relevante informatie weergeven. Geef visuele informatie op met betrekking tot de huidige context en omgeving van de gebruiker, zoals hotels in de buurt. Retourneer details dicht bij de doelbestemming en -datum.
Verminder sociale vooroordelen. Zorg ervoor dat de taal en het gedrag geen onbedoelde stereotypen of vooroordelen veroorzaken. Een functie voor automatisch aanvullen moet bijvoorbeeld inclusief genderidentiteit zijn.
Als het verkeerd is
- Efficiënt ontslag ondersteunen. Een eenvoudig mechanisme bieden om ongewenste functies of services te negeren of te verwijderen.
- Ondersteuning voor efficiënte correctie. Biedt een intuïtieve manier om het bewerken, verfijnen of herstellen te vereenvoudigen.
- Maak duidelijk waarom het systeem deed wat het deed. Optimaliseer uitlegbare AI om inzichten te bieden over de beweringen van het AI-systeem.
Binnen een bepaalde periode
- Onthoud recente interacties. Bewaar een geschiedenis van interacties voor toekomstig gebruik.
- Leer van gebruikersgedrag. Pas de interactie aan uw persoonlijke voorkeur aan op basis van het gedrag van de gebruiker.
- Werk bij en pas deze voorzichtig aan. Beperk verstorende wijzigingen en werk deze bij op basis van het profiel van de gebruiker.
- Moedig gedetailleerde feedback aan. Verzamel feedback van gebruikers over hun interacties met het AI-systeem.
Vertrouwd AI-framework

AI-ontwerper
De AI-ontwerper bouwt het model en is verantwoordelijk voor:
Gegevensdrift en kwaliteitscontroles. De ontwerper detecteert uitbijters en voert gegevenskwaliteitscontroles uit om ontbrekende waarden te identificeren. De ontwerper standaardiseert ook distributie, onderzoekt gegevens en produceert use-case- en projectrapporten.
Het beoordelen van gegevens in de bron van het systeem om mogelijke vooroordelen te identificeren.
AI-algoritmen ontwerpen om gegevensvooroordelen te minimaliseren. Deze inspanningen omvatten het ontdekken van hoe binning, groepering en normalisatie (met name in traditionele machine learning-modellen zoals boomstructuurmodellen) minderheidsgroepen uit gegevens kunnen elimineren. Categorisch AI-ontwerp herhaalt gegevensvooroordelen door sociale, raciale en geslachtsklassen te groeperen in brancheverticalen die afhankelijk zijn van beschermde gezondheidsinformatie (PHI) en persoonlijke gegevens.
Optimaliseren van bewaking en waarschuwingen om doellekken te identificeren en de ontwikkeling van het model te versterken.
Het instellen van best practices voor rapportage en inzichten die een gedetailleerd inzicht in het model bieden. De ontwerpfunctie vermijdt black-box-benaderingen die gebruikmaken van functie- of vectorbelang, UMAP-clustering (Uniform Manifold Approximation and Projection), Friedman's H-statistiek, functie-effecten en gerelateerde technieken. Metrische identificatiegegevens helpen bij het definiëren van voorspellende invloed, relaties en afhankelijkheden tussen correlaties in complexe en moderne gegevenssets.
AI-beheerder en -functionarissen
De AI-beheerder en -functionarissen houden toezicht op AI, governance en frameworkbewerkingen en metrische prestatiegegevens. Ze houden ook toezicht op de implementatie van AI-beveiliging en het rendement van de investering van het bedrijf. Hun taken omvatten:
Een traceringsdashboard bewaken dat modelbewaking ondersteunt en metrische modelgegevens voor productiemodellen combineert. Het dashboard is gericht op nauwkeurigheid, modeldegradatie, gegevensdrift, afwijking en wijzigingen in de snelheid/fout van deductie.
Flexibele implementatie en herimplementatie implementeren (bij voorkeur via een REST API) waarmee modellen kunnen worden geïmplementeerd in een open, agnostische architectuur. De architectuur integreert het model met bedrijfsprocessen en genereert waarde voor feedbacklussen.
Werken aan het bouwen van modelgovernance en -toegang om grenzen te stellen en negatieve bedrijfs- en operationele gevolgen te beperken. RBAC-standaarden (op rollen gebaseerd toegangsbeheer) bepalen beveiligingscontroles, waardoor beperkte productieomgevingen en het IP-adres behouden blijven.
Ai-audit- en nalevingsframeworks gebruiken om bij te houden hoe modellen zich ontwikkelen en veranderen om branchespecifieke standaarden te handhaven. Interpreteerbare en verantwoordelijke AI is gebaseerd op uitlegbaarheidsmetingen, beknopte functies, modelvisualisaties en branche-verticale taal.
ZAKELIJKE AI-consumenten
Zakelijke AI-consumenten (bedrijfsexperts) sluiten de feedbacklus en leveren input voor de AI-ontwerper. Voorspellende besluitvorming en mogelijke gevolgen voor vooroordelen, zoals eerlijkheid en ethische maatregelen, privacy en naleving en bedrijfsefficiëntie, helpen bij het evalueren van AI-systemen. Hier volgen enkele overwegingen voor zakelijke consumenten:
Feedbacklussen behoren tot het ecosysteem van een bedrijf. Gegevens die de vooroordelen, fouten, voorspellingssnelheid en eerlijkheid van een model laten zien, zorgen voor vertrouwen en evenwicht tussen de AI-ontwerper, beheerder en officieren. Mensgerichte evaluatie zou AI geleidelijk moeten verbeteren na verloop van tijd.
Het minimaliseren van AI-leren van multidimensionale, complexe gegevens kan helpen om bevooroordeeld leren te voorkomen. Deze techniek wordt less-than-one-shot (LO-shot) leren genoemd.
Het gebruik van ontwerp en hulpprogramma's voor interpreteerbaarheid houdt AI-systemen verantwoordelijk voor mogelijke vooroordelen. Problemen met modelvooroordelen en eerlijkheid moeten worden gemarkeerd en ingevoerd in een waarschuwings- en anomaliedetectiesysteem dat van dit gedrag leert en automatisch vooroordelen verhelpt.
Elke voorspellende waarde moet worden onderverdeeld in afzonderlijke kenmerken of vectoren op basis van urgentie of impact. Het moet uitgebreide voorspellingsverklaringen bieden die kunnen worden geëxporteerd naar een bedrijfsrapport voor controle- en nalevingsbeoordelingen, transparantie van klanten en bedrijfsgereedheid.
Vanwege toenemende wereldwijde beveiligings- en privacyrisico's moeten best practices voor het oplossen van gegevensschendingen tijdens deductie voldoen aan de regelgeving in afzonderlijke brancheverticalen. Voorbeelden hiervan zijn waarschuwingen over niet-naleving van PHI en persoonsgegevens of waarschuwingen over schending van nationale/regionale beveiligingswetten.
Volgende stappen
Verken menselijke AI-richtlijnen voor meer informatie over verantwoorde AI.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor