Gegevenstoepassingen (uitgelijnde bron)
Als u ervoor hebt gekozen om geen gegevensagnostische engine te implementeren voor het eenmaal opnemen van gegevens uit operationele bronnen, of als complexe verbindingen niet worden gefaciliteerd in uw gegevensagnostische engine, moet u een gegevenstoepassing maken die is afgestemd op de bron. Het moet dezelfde stroom volgen als een gegevensagnostische engine zou doen bij het opnemen van gegevens uit externe gegevensbronnen.
Overzicht
Uw toepassingsresourcegroep is alleen verantwoordelijk voor gegevensopname en -verrijking van externe bronnen, zoals telemetrie, financiën of CRM. Deze laag kan in realtime, batch- en microbatch worden uitgevoerd.
In deze sectie wordt de infrastructuur uitgelegd die is geïmplementeerd voor elke gegevenstoepassing (bron uitgelijnde) resourcegroep binnen uw gegevenslandingszone.
Tip
Voor data mesh kunt u ervoor kiezen om een van deze per bron of één per domein te implementeren. De principes van gegevensstandaardisatie, gegevenskwaliteit en gegevensherkomst moeten nog steeds worden gevolgd. Ops-teams voor gegevensplatforms kunnen codefragmenten ontwikkelen en een beroep op hen doen om dit te bereiken.
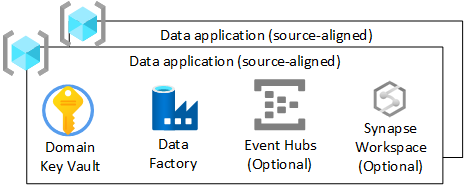
Voor elke gegevenstoepassing (bron uitgelijnd) resourcegroep in uw gegevenslandingszone moet u het volgende maken:
- Een Azure-Key Vault
- Een Azure Data Factory, om ontwikkelde technische pijplijnen uit te voeren die gegevens transformeren van onbewerkt naar verrijkt
- Een service-principal die door de gegevenstoepassing (bron uitgelijnd) wordt gebruikt voor het implementeren van opnametaken in Azure Databricks (alleen als u Azure Databricks gebruikt)
U kunt ook exemplaren van andere services maken, zoals Azure Event Hubs, Azure IoT Hub, Azure Stream Analytics en Azure Machine Learning.
Notitie
U moet een Spark-engine zoals Azure Synapse Spark of Azure Databricks gebruiken om de Delta Lake-standaard af te dwingen.
Als u Besluit om Azure Databricks te gebruiken, raden we u aan Azure Data Factory te implementeren in plaats van Azure Synapse Analytics-werkruimte om de oppervlakte te beperken tot alleen vereiste functies.
Als u echter een allesomvattend ontwikkelgebied met pijplijnen en Spark nodig hebt, gebruikt u Azure Synapse Analytics. Pas een beleid toe om alleen het gebruik van Spark en pijplijnen toe te staan, zodat u geen silo's in een Azure Synapse SQL-pool maakt.
Azure Key Vault
Gebruik de functionaliteit van Azure Key Vault om waar mogelijk geheimen in Azure op te slaan.
Elke gegevenstoepassing (bron uitgelijnd) resourcegroep of gegevensdomein (indien mesh) heeft een Azure-Key Vault. Dit zorgt ervoor dat de versleutelingssleutel, het geheim en de certificaatversleuteling voldoen aan de vereisten van uw omgeving. Dit zorgt voor een betere scheiding van administratieve taken en vermindert ook het risico van het combineren van sleutels, integraties en geheimen van verschillende classificaties.
Alle sleutels met betrekking tot uw gegevenstoepassing (bron uitgelijnd) moeten zijn opgenomen in uw Azure Key Vault.
Belangrijk
Sleutelkluizen voor gegevenstoepassingen (uitgelijnd op de bron) moeten het model met de minste bevoegdheden volgen en moeten zowel limieten voor transactieschaal als het delen van geheimen tussen omgevingen vermijden.
Azure Data Factory
Implementeer een Azure Data Factory om pijplijnen die door uw gegevenstoepassingsteam zijn geschreven, toe te staan gegevens van onbewerkt naar verrijkt te nemen met behulp van ontwikkelde pijplijnen. Gebruik toewijzingsgegevensstromen voor transformaties en maak gebruik van de Azure Databricks-werkruimte (opnemen) of Azure Synapse Spark voor complexe transformaties.
U moet Azure Data Factory verbinden met het DevOps-exemplaar van de opslagplaats van uw gegevenstoepassing (uitgelijnde bron). Met deze verbinding kunnen CI/CD-implementaties worden geïmplementeerd.
Event Hubs
Als uw gegevenstoepassing (op bron is afgestemd) een vereiste heeft om gegevens in te streamen, kunt u downstream Event Hubs implementeren in de resourcegroep van uw gegevenstoepassing (uitgelijnd aan de bron).