Ontwerpoverwegingen voor zelfbedieningsgegevensplatformen
Data mesh is een interessante nieuwe benadering van het ontwerpen en ontwikkelen van gegevensarchitectuur. In tegenstelling tot traditionele gegevensarchitectuur scheidt data mesh de verantwoordelijkheid tussen functionele gegevensdomeinen die zich richten op het maken van gegevensproducten en een platformteam dat zich richt op technische mogelijkheden. Deze scheiding van verantwoordelijkheden moet worden weerspiegeld in uw platform. U moet een evenwicht vinden tussen het bieden van domeinagnostische mogelijkheden en het inschakelen van uw domeinteams om hun gegevens in uw organisatie te modelleren, te verwerken en te distribueren.
Het kiezen van het juiste niveau van domeingranulariteit en regels voor het loskoppelen van platforms is niet eenvoudig. Dit artikel bevat verschillende scenario's die u gedetailleerde richtlijnen bieden.
Analyses op cloudschaal
Als u een data mesh wilt bouwen met Azure, raden we u aan om analyses op cloudschaal te gebruiken. Dit framework is een implementeerbare referentiearchitectuur en wordt geleverd met opensource-sjablonen en aanbevolen procedures. De analysearchitectuur op cloudschaal heeft twee belangrijke bouwstenen die fundamenteel zijn voor alle implementatieopties:
- Landingszone voor gegevensbeheer: de basis van uw gegevensarchitectuur. Het bevat alle kritieke mogelijkheden voor gegevensbeheer, zoals gegevenscatalogus, gegevensherkomst, API-catalogus, hoofdgegevensbeheer, enzovoort.
- Zones voor gegevenslanding: abonnementen die uw analyse- en AI-oplossingen hosten. Ze bevatten belangrijke mogelijkheden voor het hosten van een analyseplatform.
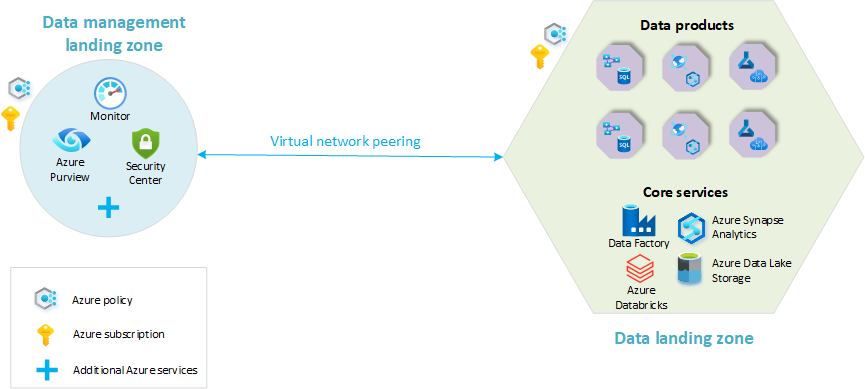
Het volgende diagram biedt een overzicht van een analyseplatform op cloudschaal met een landingszone voor gegevensbeheer en één gegevenslandingszone. Niet alle Azure-services worden weergegeven in het diagram. Het is vereenvoudigd om de belangrijkste resourceorganisatieconcepten in deze architectuur te markeren.
Het cloudgebaseerde analyseframework is niet expliciet voor welk type gegevensarchitectuur u moet inrichten. U kunt deze gebruiken voor veel algemene analyseoplossingen op cloudschaal, waaronder (enterprise) datawarehouses, data lakes, data lake houses en data meshes. Alle voorbeeldoplossingen in dit artikel maken gebruik van data mesh-architectuur.
Begrijp dat alle architecturen voldoen aan de principes van data mesh: domeineigendom, gegevens als product, zelfbedieningsgegevensplatform en federatieve rekenkundige governance. Verschillende paden kunnen allemaal leiden tot een data mesh. Er is geen enkel goed of verkeerd antwoord. U moet de juiste afwegingen maken voor de behoeften van uw organisatie.
Enkele gegevenslandingszone
Het eenvoudigste implementatiepatroon voor het bouwen van een data mesh-architectuur omvat één landingszone voor gegevensbeheer en één gegevenslandingszone. De gegevensarchitectuur in een dergelijk scenario ziet er als volgt uit:

In dit model bevinden al uw functionele gegevensdomeinen zich in dezelfde gegevenslandingszone. Eén abonnement bevat een standaardset services. Resourcegroepen scheiden verschillende gegevensdomeinen en gegevensproducten. Standaardgegevensservices, zoals Azure Data Lake Store, Azure Logic Apps en Azure Synapse Analytics, zijn van toepassing op alle domeinen.
Alle gegevensdomeinen volgen data mesh-principes: gegevens volgen het eigendom van het domein en gegevens worden behandeld als producten. Het platform is volledig selfservice, hoewel er beperkte variaties van services zijn. Alle domeinen moeten sterk voldoen aan dezelfde principes voor gegevensbeheer.
Deze implementatieoptie kan nuttig zijn voor kleinere bedrijven of greenfield-projecten die data mesh willen omarmen, maar niet te gecompliceerde dingen. Deze implementatie kan ook een startpunt zijn voor een organisatie die van plan is iets complexer te maken. In dit geval wilt u op een later tijdstip uitbreiden naar meerdere landingszones.
Uitgelijnde bronsysteem en op de consument afgestemde landingszones
In het vorige model hebben we geen rekening gehouden met andere abonnementen of on-premises toepassingen. U kunt het vorige model enigszins wijzigen door een door het bronsysteem uitgelijnde landingszone toe te voegen om alle binnenkomende gegevens te beheren. Onboarding van gegevens is een moeilijk proces, dus het gebruik van twee datalandingszones is handig. Onboarding blijft een van de meest uitdagende onderdelen van het gebruik van gegevens in grote mate. Onboarding vereist ook vaak extra hulpprogramma's om integratie aan te pakken, omdat de uitdagingen verschillen van die van integratie. Het helpt om onderscheid te maken tussen het leveren van gegevens en het verbruiken van gegevens.

In de architectuur aan de linkerkant van dit diagram faciliteren services alle onboarding van gegevens, zoals CDC, services voor het ophalen van API's of data lake-services voor het dynamisch bouwen van gegevenssets. Services in dit platform kunnen gegevens ophalen uit on-premises, cloudomgevingen of SaaS-leveranciers. Dit type platform heeft doorgaans ook meer overhead, omdat er meer koppeling is met onderliggende operationele toepassingen. Mogelijk wilt u dit anders behandelen dan elk gegevensgebruik.
In de architectuur aan de rechterkant van het diagram optimaliseert de organisatie voor verbruik en heeft de organisatie services die zijn gericht op het omzetten van gegevens in waarde. Deze services kunnen machine learning, rapportage, enzovoort omvatten.
Deze architectuurdomeinen volgen alle principes van data mesh. Domeinen zijn eigenaar van gegevens en mogen gegevens rechtstreeks naar andere domeinen distribueren.
Hub-, algemene en speciale datalandingszones
De volgende implementatieoptie is een andere iteratie van het vorige ontwerp. Deze implementatie volgt een beheerde mesh-topologie: gegevens worden gedistribueerd via een centrale hub, waarin gegevens per domein worden gepartitioneerd, logisch geïsoleerd en niet geïntegreerd. De hub van dit model maakt gebruik van een eigen (domeinagnostische) gegevenslandingszone en kan eigendom zijn van een centraal gegevensbeheerteam dat toezicht houdt op welke gegevens worden gedistribueerd naar welke andere domeinen. De hub biedt ook services die het onboarden van gegevens mogelijk maken.

Gebruik algemene gegevenslandingszone voor domeinen waarvoor standaardservices nodig zijn voor het gebruik, het gebruik, het analyseren en maken van nieuwe gegevens. Dit ene abonnement bevat een standaardset services. Pas ook gegevensvirtualisatie toe, omdat de meeste gegevensproducten al in de hub worden bewaard en u geen extra gegevensduplicatie nodig hebt.
Met deze implementatie kunnen 'specials' worden gebruikt: extra landingszones die u kunt inrichten wanneer het niet mogelijk is om domeinen logisch te groeperen. Ze kunnen nodig zijn wanneer regionale of juridische grenzen van toepassing zijn, of wanneer uw domeinen unieke en contrasterende vereisten hebben. Mogelijk hebt u ze ook nodig in situaties waarin een sterk globaal dochterondernemingbeheer wordt toegepast met uitzonderingen voor overzeese activiteiten.
Als uw organisatie moet bepalen welke gegevens worden gedistribueerd en gebruikt door welke domeinen, is hubimplementatie een goede optie. Het is ook een optie als u zich bezighoudt met tijdvariant en niet-vluchtige problemen voor grote gegevensgebruikers. U kunt het ontwerp van gegevensproduct sterk standaardiseren, zodat uw domeinen tijdreizen kunnen uitvoeren en nieuwe ervaringen kunnen uitvoeren. Dit model is vooral gebruikelijk in de financiële sector.
Functionele en regionaal uitgelijnde datalandingszones
Door meerdere landingszones voor gegevens in te richten, kunt u functionele domeinen groeperen op basis van cohesie en efficiëntie voor het werken en delen van gegevens. Al uw gegevenslandingszones voldoen aan dezelfde controle en besturingselementen, maar u kunt nog steeds flexibiliteit en ontwerpwijzigingen tussen verschillende datalandingszones hebben.

Bepaal de functionele gegevensdomeinen die u logisch wilt groeperen voor een gedeelde gegevenslandingszone. U kunt bijvoorbeeld dezelfde sjablonen implementeren als u regionale grenzen hebt. Eigendom, beveiliging of juridische grenzen kunnen u dwingen om domeinen te scheiden. Flexibiliteit, het tempo van verandering en scheiding of verkoop van uw mogelijkheden zijn ook belangrijke factoren om rekening mee te houden.
Meer richtlijnen en aanbevolen procedures vindt u in gegevensdomeinen.
Verschillende landingszones staan niet op zichzelf. Ze kunnen verbinding maken met data lakes die worden gehost in andere zones. Hiermee kunnen domeinen samenwerken binnen uw onderneming. U kunt ook polyglotpersistentie toepassen om verschillende technologieën voor gegevensopslag te combineren. Met Polyglot-persistentie kunnen uw domeinen rechtstreeks gegevens uit andere domeinen lezen zonder gegevens te dupliceren.
Wanneer u meerdere landingszones voor gegevens implementeert, weet u dat er beheeroverhead is gekoppeld aan elke gegevenslandingszone. U moet VNet-peering toepassen tussen alle landingszones voor gegevens, u moet extra privé-eindpunten beheren, enzovoort.
Het implementeren van meerdere landingszones voor gegevens is een goede optie als uw gegevensarchitectuur groot is. U kunt meer landingszones toevoegen aan uw architectuur om te voldoen aan algemene behoeften van verschillende domeinen. Deze extra landingszones maken gebruik van peering van virtuele netwerken om verbinding te maken met zowel de landingszone voor gegevensbeheer als alle andere landingszones. Met peering kunt u gegevenssets en resources delen in uw landingszones. Door gegevens over afzonderlijke zones te splitsen, kunt u workloads verdelen over uw Azure-abonnementen en -resources. Deze aanpak helpt bij het organisch implementeren van de data mesh.
Grote ondernemingen die verschillende gegevensbeheerzones vereisen
Grote ondernemingen die op wereldwijde schaal opereren, kunnen contrasterende vereisten voor gegevensbeheer hebben tussen verschillende onderdelen van hun organisatie. U kunt meerdere gegevensbeheer- en gegevenslandingszones samen implementeren om dit probleem op te lossen. In het volgende diagram ziet u een voorbeeld van dit type architectuur:

Meerdere landingszones voor gegevensbeheer moeten uw overhead en integratiecomplexiteit rechtvaardigen. Een andere landingszone voor gegevensbeheer kan bijvoorbeeld zinvol zijn voor situaties waarin de (meta)gegevens van uw organisatie niet mogen worden gezien door iemand buiten uw organisatie.
Conclusie
De overgang naar data mesh is een culturele verschuiving met nuances, afwegingen en overwegingen. U kunt analyses op cloudschaal gebruiken om best practices en uitvoerbare resources te verkrijgen. De referentiearchitecturen van dit artikel bieden uitgangspunten voor het starten van uw implementatie.