Gezichtspositie met viseme krijgen
Notitie
Als u de landinstellingen wilt verkennen die worden ondersteund voor viseme-id's en vormen wilt combineren, raadpleegt u de lijst met alle ondersteunde landinstellingen. Scalable Vector Graphics (SVG) wordt alleen ondersteund voor de en-US landinstelling.
Een viseme is de visuele beschrijving van een phoneme in gesproken taal. Het definieert de positie van het gezicht en de mond terwijl een persoon spreekt. Elk viseme toont de belangrijkste gezichtshoudingen voor een specifieke set telefoontjes.
U kunt visemes gebruiken om de beweging van 2D- en 3D avatarmodellen te beheren, zodat de gezichtsposities het best zijn afgestemd op synthetische spraak. U kunt bijvoorbeeld:
- Maak een virtuele spraakassistent met animatie voor intelligente kiosken en bouw geïntegreerde services voor uw klanten met meerdere modussen.
- Bouw meeslepende nieuwsuitzendingen en verbeter de ervaringen van het publiek met natuurlijke gezichts- en mondbewegingen.
- Genereer interactieve gaming avatars en cartoon personages die kunnen spreken met dynamische inhoud.
- Maak effectievere video's voor taalonderwijs die taalleerders helpen het mondgedrag van elk woord en telefoonme te begrijpen.
- Mensen met gehoorproblemen kan ook visueel geluid en spraakinhoud met 'lip-read' ophalen die visemes op een geanimeerd gezicht laat zien.
Bekijk deze inleidende video voor meer informatie over visemes.
Algemene werkstroom voor het produceren van viseme met spraak
Neurale tekst naar spraak (NeuralE TTS) verandert invoertekst of SSML (Speech Synthesis Markup Language) in levensechte gesynthetiseerde spraak. Spraakaudio-uitvoer kan worden vergezeld door viseme-id, Scalable Vector Graphics (SVG) of vormen met elkaar combineren. Met behulp van een 2D- of 3D-renderingengine kunt u deze viseme-gebeurtenissen gebruiken om uw avatar te animeren.
De algemene werkstroom van viseme wordt weergegeven in het volgende stroomdiagram:
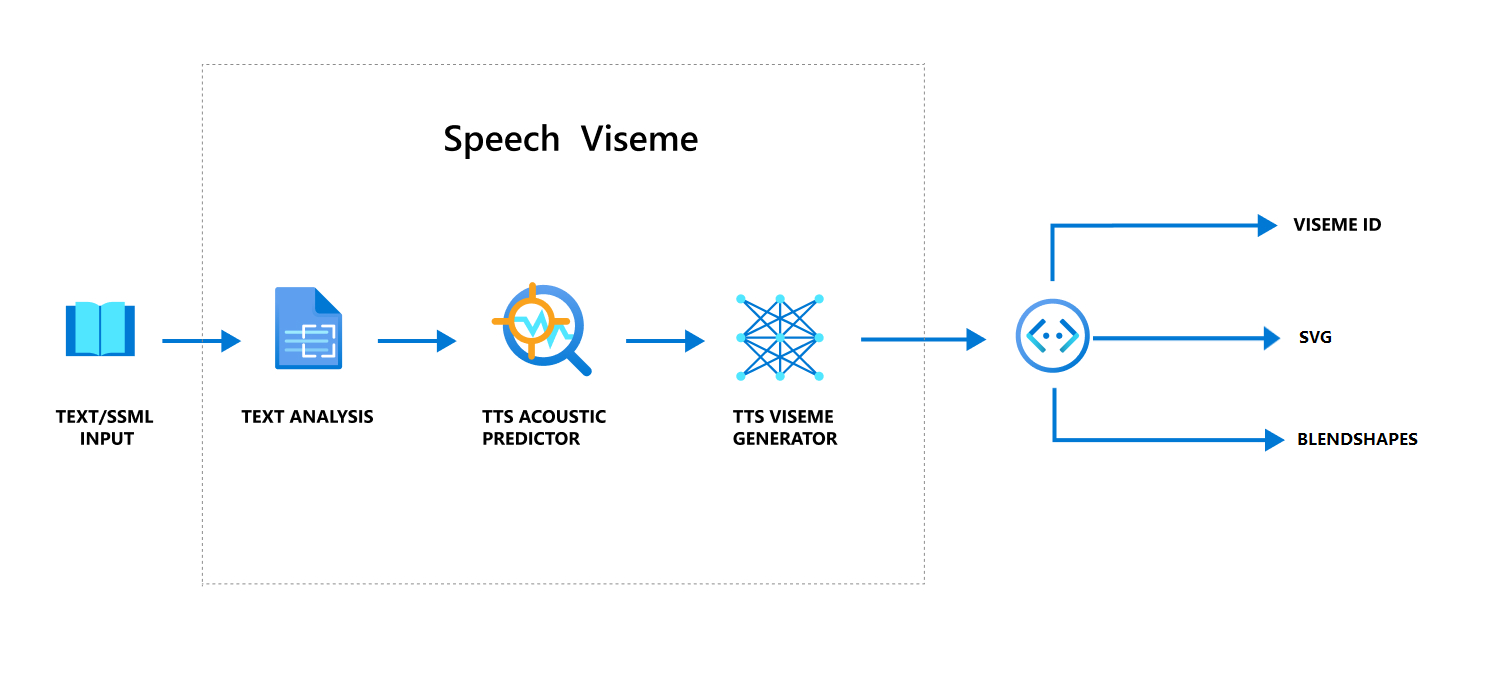
Viseme-id
Viseme-id verwijst naar een geheel getal dat een viseme aangeeft. Wij bieden 22 verschillende visemen, elk met de mondpositie voor een specifieke set telefoontjes. Er is geen een-op-een-correspondentie tussen visemes en telefoontjes. Vaak komen meerdere telefoontjes overeen met één viseme, omdat ze er hetzelfde uitzagen op het gezicht van de luidspreker wanneer ze worden geproduceerd, zoals s en z. Zie de tabel voor het toewijzen van fonetische id's aan specifiekere informatie.
Spraakaudio-uitvoer kan worden vergezeld door viseme-id's en Audio offset. De Audio offset geeft de offsettijdstempel aan die de begintijd van elk viseme vertegenwoordigt, in tikken (100 nanoseconden).
Telefoontjes toewijzen aan visemen
Visemes verschilt per taal en landinstelling. Elke landinstelling heeft een set visemen die correspondeert met de specifieke fonemes. De documentatie over SSML-fonetische alfabetten wijst viseme-id's toe aan de bijbehorende IPA-telefoon (International Telefoon tic Alphabet). In de tabel in deze sectie ziet u een toewijzingsrelatie tussen viseme-id's en mondposities, met typische IPA-phonemes voor elke viseme-id.
| Viseme-id | IPA | Mondpositie |
|---|---|---|
| 0 | Geluid dempen |  |
| 1 | æ, , əʌ |
 |
| 2 | ɑ |
 |
| 3 | ɔ |
 |
| 4 | ɛ, ʊ |
 |
| 5 | ɝ |
 |
| 6 | j, , iɪ |
 |
| 7 | w, u |
 |
| 8 | o |
 |
| 9 | aʊ |
 |
| 10 | ɔɪ |
 |
| 11 | aɪ |
 |
| 12 | h |
 |
| 13 | ɹ |
 |
| 14 | l |
 |
| 15 | s, z |
 |
| 16 | ʃ, , , tʃdʒʒ |
 |
| 17 | ð |
 |
| 18 | f, v |
 |
| 19 | d, , , tnθ |
 |
| 20 | k, , gŋ |
 |
| 21 | p, , bm |
 |
2D SVG-animatie
Voor 2D-tekens kunt u een teken ontwerpen dat bij uw scenario past en SVG (Scalable Vector Graphics) gebruiken voor elke viseme-id om een op tijd gebaseerde gezichtspositie te krijgen.
Met tijdelijke tags die worden geleverd in een viseme-gebeurtenis, worden deze goed ontworpen SVG's verwerkt met vloeiende wijzigingen en bieden ze een robuuste animatie aan de gebruikers. In de volgende afbeelding ziet u bijvoorbeeld een rood-spraakgevoelig teken dat is ontworpen voor taalonderwijs.

Animatie van 3D-vormen combineren
U kunt blendshapes gebruiken om de gezichtsbewegingen van een 3D-teken te besturen dat u hebt ontworpen.
De JSON-tekenreeks voor mixshapes wordt weergegeven als een tweedimensionale matrix. Elke rij vertegenwoordigt een frame. Elk frame (in 60 FPS) bevat een matrix van 55 gezichtsposities.
Viseme-gebeurtenissen ophalen met de Speech SDK
Als u zicht wilt krijgen op uw gesynthetiseerde spraak, abonneert u zich op de gebeurtenis in de VisemeReceived Speech SDK.
Notitie
Als u uitvoer van SVG- of blendshapes wilt aanvragen, moet u het mstts:viseme element in SSML gebruiken. Zie voor meer informatie het viseme-element in SSML gebruiken.
In het volgende codefragment ziet u hoe u zich kunt abonneren op de viseme-gebeurtenis:
using (var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig))
{
// Subscribes to viseme received event
synthesizer.VisemeReceived += (s, e) =>
{
Console.WriteLine($"Viseme event received. Audio offset: " +
$"{e.AudioOffset / 10000}ms, viseme id: {e.VisemeId}.");
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
var result = await synthesizer.SpeakSsmlAsync(ssml);
}
auto synthesizer = SpeechSynthesizer::FromConfig(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer->VisemeReceived += [](const SpeechSynthesisVisemeEventArgs& e)
{
cout << "viseme event received. "
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
<< "Audio offset: " << e.AudioOffset / 10000 << "ms, "
<< "viseme id: " << e.VisemeId << "." << endl;
// `Animation` is an xml string for SVG or a json string for blend shapes
auto animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
auto result = synthesizer->SpeakSsmlAsync(ssml).get();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.VisemeReceived.addEventListener((o, e) -> {
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
System.out.print("Viseme event received. Audio offset: " + e.getAudioOffset() / 10000 + "ms, ");
System.out.println("viseme id: " + e.getVisemeId() + ".");
// `Animation` is an xml string for SVG or a json string for blend shapes
String animation = e.getAnimation();
});
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
SpeechSynthesisResult result = synthesizer.SpeakSsmlAsync(ssml).get();
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def viseme_cb(evt):
print("Viseme event received: audio offset: {}ms, viseme id: {}.".format(
evt.audio_offset / 10000, evt.viseme_id))
# `Animation` is an xml string for SVG or a json string for blend shapes
animation = evt.animation
# Subscribes to viseme received event
speech_synthesizer.viseme_received.connect(viseme_cb)
# If VisemeID is the only thing you want, you can also use `speak_text_async()`
result = speech_synthesizer.speak_ssml_async(ssml).get()
var synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.visemeReceived = function (s, e) {
window.console.log("(Viseme), Audio offset: " + e.audioOffset / 10000 + "ms. Viseme ID: " + e.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.animation;
}
// If VisemeID is the only thing you want, you can also use `speakTextAsync()`
synthesizer.speakSsmlAsync(ssml);
SPXSpeechSynthesizer *synthesizer =
[[SPXSpeechSynthesizer alloc] initWithSpeechConfiguration:speechConfig
audioConfiguration:audioConfig];
// Subscribes to viseme received event
[synthesizer addVisemeReceivedEventHandler: ^ (SPXSpeechSynthesizer *synthesizer, SPXSpeechSynthesisVisemeEventArgs *eventArgs) {
NSLog(@"Viseme event received. Audio offset: %fms, viseme id: %lu.", eventArgs.audioOffset/10000., eventArgs.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
NSString *animation = eventArgs.Animation;
}];
// If VisemeID is the only thing you want, you can also use `SpeakText`
[synthesizer speakSsml:ssml];
Hier volgt een voorbeeld van de viseme-uitvoer.
(Viseme), Viseme ID: 1, Audio offset: 200ms.
(Viseme), Viseme ID: 5, Audio offset: 850ms.
……
(Viseme), Viseme ID: 13, Audio offset: 2350ms.
Nadat u de viseme-uitvoer hebt verkregen, kunt u deze gebeurtenissen gebruiken om tekenanimatie aan te sturen. U kunt uw eigen tekens bouwen en deze automatisch animeren.