De betrouwbaarheidsscore van een antwoord
Wanneer een gebruikersquery wordt vergeleken met een knowledge base, retourneert QnA Maker relevante antwoorden, samen met een betrouwbaarheidsscore. Deze score geeft het vertrouwen aan dat het antwoord de juiste overeenkomst is voor de opgegeven gebruikersquery.
De betrouwbaarheidsscore is een getal tussen 0 en 100. Een score van 100 is waarschijnlijk een exacte overeenkomst, terwijl een score van 0 betekent dat er geen overeenkomend antwoord is gevonden. Hoe hoger de score- hoe groter het vertrouwen in het antwoord. Voor een bepaalde query kunnen er meerdere antwoorden worden geretourneerd. In dat geval worden de antwoorden geretourneerd in volgorde van afnemende betrouwbaarheidsscore.
In het onderstaande voorbeeld ziet u één QnA-entiteit, met 2 vragen.

Voor het bovenstaande voorbeeld kunt u scores zoals het onderstaande voorbeeldscorebereik verwachten voor verschillende typen gebruikersquery's:
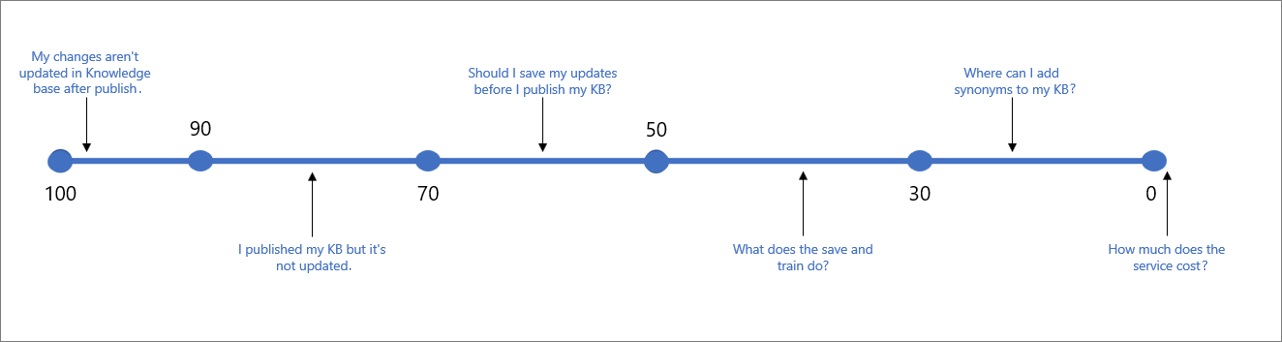
De volgende tabel geeft een typische betrouwbaarheid aan die is gekoppeld aan een bepaalde score.
| Scorewaarde | Betekenis van score | Voorbeeldquery |
|---|---|---|
| 90 - 100 | Een bijna exacte overeenkomst van de gebruikersquery en een KB-vraag | "Mijn wijzigingen worden na publicatie niet bijgewerkt in KB" |
| > 70 | Hoge betrouwbaarheid: meestal een goed antwoord dat de query van de gebruiker volledig beantwoordt | "Ik heb mijn KB gepubliceerd, maar deze is niet bijgewerkt" |
| 50 - 70 | Gemiddelde betrouwbaarheid: meestal een redelijk goed antwoord dat de hoofdintentie van de gebruikersquery moet beantwoorden | "Moet ik mijn updates opslaan voordat ik mijn KB publiceer?" |
| 30 - 50 | Lage betrouwbaarheid: meestal een gerelateerd antwoord, dat gedeeltelijk de intentie van de gebruiker beantwoordt | "Wat doet het opslaan en trainen?" |
| < 30 | Zeer lage betrouwbaarheid: beantwoordt doorgaans niet de query van de gebruiker, maar bevat enkele overeenkomende woorden of woordgroepen | " Waar kan ik synoniemen toevoegen aan mijn KB" |
| 0 | Geen overeenkomst, dus het antwoord wordt niet geretourneerd. | "Hoeveel kost de service" |
Een scoredrempel kiezen
In de bovenstaande tabel ziet u de scores die voor de meeste KB's worden verwacht. Omdat elke KB echter verschillend is en verschillende typen woorden, intenties en doelen heeft, raden we u aan de drempelwaarde te testen en te kiezen die het beste bij u past. De drempelwaarde is standaard ingesteld op 0, zodat alle mogelijke antwoorden worden geretourneerd. De aanbevolen drempelwaarde die voor de meeste KB's moet werken, is 50.
Houd bij het kiezen van uw drempelwaarde rekening met het evenwicht tussen nauwkeurigheid en dekking en pas uw drempelwaarde aan op basis van uw vereisten.
Als nauwkeurigheid (of precisie) belangrijker is voor uw scenario, verhoogt u de drempelwaarde. Op deze manier is het elke keer dat u een antwoord retourneert een veel betrouwbaarder geval en veel waarschijnlijker het antwoord dat gebruikers zoeken. In dit geval kunt u meer vragen onbeantwoord laten. Als u bijvoorbeeld de drempelwaarde 70 maakt, mist u mogelijk enkele dubbelzinnige voorbeelden, zoals 'Wat is opslaan en trainen?'.
Als dekking (of relevante overeenkomsten) belangrijker is en u zoveel mogelijk vragen wilt beantwoorden, zelfs als er slechts een gedeeltelijke relatie is met de vraag van de gebruiker, verlaagt u de drempelwaarde. Dit betekent dat er meer gevallen kunnen zijn waarbij het antwoord niet de werkelijke query van de gebruiker beantwoordt, maar een ander enigszins gerelateerd antwoord geeft. Als u bijvoorbeeld de drempelwaarde 30 maakt, kunt u antwoorden geven op query's zoals 'Waar kan ik mijn KB bewerken?'
Notitie
Nieuwere versies van QnA Maker bevatten verbeteringen in scorelogica en kunnen van invloed zijn op uw drempelwaarde. Wanneer u de service bijwerkt, moet u de drempelwaarde indien nodig testen en aanpassen. U kunt hier uw QnA-serviceversie controleren en zien hoe u de nieuwste updates hier kunt downloaden.
Drempel instellen
Stel de drempelwaardescore in als een eigenschap van de JSON-hoofdtekst van de GenerateAnswer-API. Dit betekent dat u deze instelt voor elke aanroep naar GenerateAnswer.
Stel vanuit het botframework de score in als onderdeel van het optiesobject met C# of Node.js.
Betrouwbaarheidsscores verbeteren
Als u de betrouwbaarheidsscore van een bepaald antwoord op een gebruikersquery wilt verbeteren, kunt u de gebruikersquery toevoegen aan de Knowledge Base als een alternatieve vraag voor dat antwoord. U kunt ook hoofdlettergevoelige woordwijzigingen gebruiken om synoniemen toe te voegen aan trefwoorden in uw KB.
Vergelijkbare betrouwbaarheidsscores
Wanneer meerdere antwoorden een vergelijkbare betrouwbaarheidsscore hebben, is de kans groot dat de query te algemeen was en daarom overeenkomt met gelijke waarschijnlijkheid met meerdere antwoorden. Probeer uw QnA's beter te structuren, zodat elke QnA-entiteit een afzonderlijke intentie heeft.
Betrouwbaarheidsscoreverschillen tussen test en productie
De betrouwbaarheidsscore van een antwoord kan verwaarloosbaar veranderen tussen de test- en de gepubliceerde versie van de Knowledge Base, zelfs als de inhoud hetzelfde is. Dit komt doordat de inhoud van de test en de gepubliceerde Knowledge Base zich in verschillende Azure AI Search-indexen bevinden.
De testindex bevat alle QnA-paren van uw Knowledge Bases. Bij het uitvoeren van query's op de testindex is de query van toepassing op de hele index en worden de resultaten beperkt tot de partitie voor die specifieke Knowledge Base. Als de resultaten van de testquery negatief van invloed zijn op uw mogelijkheid om de Knowledge Base te valideren, kunt u het volgende doen:
- organiseer uw Knowledge Base met behulp van een van de volgende:
- 1 resource beperkt tot 1 kB: beperk uw enkele QnA-resource (en de resulterende Azure AI Search-testindex) tot één Knowledge Base.
- 2 resources - 1 voor test, 1 voor productie: twee QnA Maker-resources hebben, één voor testen (met eigen test- en productieindexen) en één voor product (ook met eigen test- en productieindexen)
- en gebruik altijd dezelfde parameters, zoals top bij het uitvoeren van query's op zowel uw test- als productiekennisdatabase
Wanneer u een knowledge base publiceert, wordt de inhoud van uw knowledge base verplaatst van de testindex naar een productieindex in Azure Search. Bekijk hoe de publicatiebewerking werkt.
Als u een knowledge base in verschillende regio's hebt, gebruikt elke regio een eigen Azure AI Search-index. Omdat er verschillende indexen worden gebruikt, zijn de scores niet precies hetzelfde.
Geen overeenkomst gevonden
Wanneer er geen goede overeenkomst wordt gevonden door de classificatie, wordt de betrouwbaarheidsscore van 0,0 of 'Geen' geretourneerd en is het standaardantwoord 'Geen goede overeenkomst gevonden in de KB'. U kunt dit standaardantwoord in de bot of toepassingscode overschrijven die het eindpunt aanroept. U kunt ook het onderdrukkingsantwoord instellen in Azure en dit wijzigt de standaardwaarde voor alle knowledge bases die zijn geïmplementeerd in een bepaalde QnA Maker-service.