Activiteitstests configureren
In containers geplaatste toepassingen kunnen langere tijd worden uitgevoerd, wat resulteert in beschadigde statussen die mogelijk moeten worden hersteld door de container opnieuw te starten. Azure Container Instances biedt ondersteuning voor liveness-tests, zodat u uw containers in uw containergroep kunt configureren om opnieuw te starten als kritieke functionaliteit niet werkt. De livenesstest gedraagt zich als een Kubernetes-livenesstest.
In dit artikel wordt uitgelegd hoe u een containergroep implementeert die een livenesstest bevat, waarmee het automatisch opnieuw opstarten van een gesimuleerde beschadigde container wordt gedemonstreerd.
Azure Container Instances ondersteunt ook gereedheidstests, die u kunt configureren om ervoor te zorgen dat verkeer alleen een container bereikt wanneer deze gereed is.
YAML-implementatie
Maak een liveness-probe.yaml bestand met het volgende fragment. Dit bestand definieert een containergroep die bestaat uit een NGINX-container die uiteindelijk beschadigd raakt.
apiVersion: 2019-12-01
location: eastus
name: livenesstest
properties:
containers:
- name: mycontainer
properties:
image: mcr.microsoft.com/oss/nginx/nginx:1.15.5-alpine
command:
- "/bin/sh"
- "-c"
- "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
ports: []
resources:
requests:
cpu: 1.0
memoryInGB: 1.5
livenessProbe:
exec:
command:
- "cat"
- "/tmp/healthy"
periodSeconds: 5
osType: Linux
restartPolicy: Always
tags: null
type: Microsoft.ContainerInstance/containerGroups
Voer de volgende opdracht uit om deze containergroep te implementeren met de voorgaande YAML-configuratie:
az container create --resource-group myResourceGroup --name livenesstest -f liveness-probe.yaml
Startopdracht
De implementatie bevat een command eigenschap die een startopdracht definieert die wordt uitgevoerd wanneer de container voor het eerst wordt uitgevoerd. Deze eigenschap accepteert een matrix met tekenreeksen. Met deze opdracht wordt de container gesimuleerd die een beschadigde status invoert.
Eerst wordt er een bash-sessie gestart en wordt er een bestand gemaakt dat in de /tmp map wordt aangeroepenhealthy. Het slaapt vervolgens 30 seconden voordat het bestand wordt verwijderd en voert vervolgens een slaapstand van 10 minuten in:
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
Liveness-opdracht
Deze implementatie definieert een livenessProbe die ondersteuning biedt voor een exec liveness-opdracht die fungeert als de livenesscontrole. Als deze opdracht wordt afgesloten met een andere waarde dan nul, wordt de container gedood en opnieuw gestart, waardoor het healthy bestand niet kan worden gevonden. Als deze opdracht wordt afgesloten met afsluitcode 0, wordt er geen actie ondernomen.
De periodSeconds eigenschap wijst de liveness-opdracht aan die elke 5 seconden moet worden uitgevoerd.
Liveness-uitvoer controleren
Binnen de eerste 30 seconden bestaat het healthy bestand dat door de startopdracht is gemaakt. Wanneer de liveness-opdracht controleert op het bestaan van het healthy bestand, retourneert de statuscode 0, signalering geslaagd, zodat er geen herstart plaatsvindt.
Na 30 seconden begint de cat /tmp/healthy opdracht te mislukken, waardoor er beschadigde gebeurtenissen ontstaan en gebeurtenissen worden gedood.
Deze gebeurtenissen kunnen worden weergegeven vanuit Azure Portal of Azure CLI.
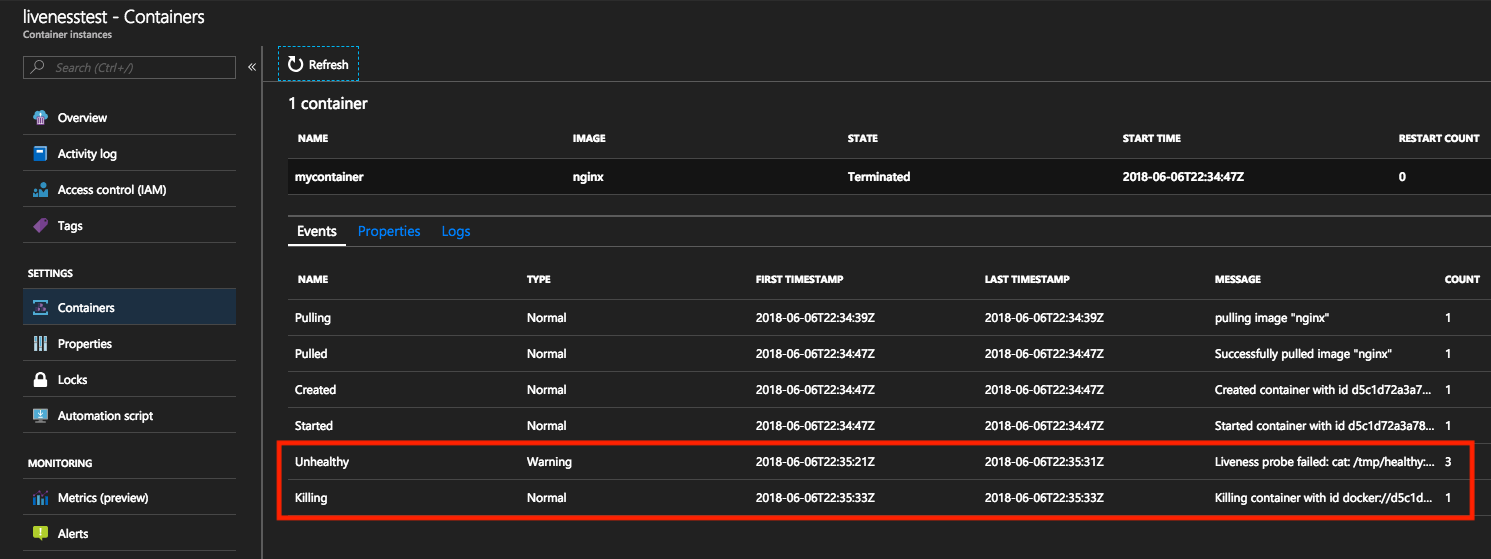
Door de gebeurtenissen in Azure Portal weer te geven, worden gebeurtenissen van het type Unhealthy geactiveerd wanneer de liveness-opdracht mislukt. De volgende gebeurtenis is van het type Killing, die een containerverwijdering aantekent, zodat opnieuw opstarten kan worden gestart. Het aantal keer dat de container opnieuw wordt opgestart, wordt steeds verhoogd wanneer deze gebeurtenis plaatsvindt.
Opnieuw opstarten wordt ter plaatse voltooid, zodat resources zoals openbare IP-adressen en knooppuntspecifieke inhoud behouden blijven.

Als de livenesstest continu mislukt en te veel herstarts activeert, voert uw container een vertraging voor exponentieel uitstel in.
Liveness-tests en beleid voor opnieuw opstarten
Beleid voor opnieuw opstarten vervangt het gedrag van opnieuw opstarten dat wordt geactiveerd door liveness-tests. Als u bijvoorbeeld een restartPolicy = Never en een livenesstest instelt, wordt de containergroep niet opnieuw opgestart vanwege een mislukte livenesscontrole. De containergroep voldoet in plaats daarvan aan het beleid voor opnieuw opstarten van de containergroep.Never
Volgende stappen
Scenario's op basis van taken vereisen mogelijk een livenesstest om automatische herstarts in te schakelen als een vereiste functie niet goed werkt. Zie Taken in containers uitvoeren in Azure Container Instances voor meer informatie over het uitvoeren van op taken gebaseerde containers.