Partitioneren in Azure Cosmos DB voor Apache Cassandra
VAN TOEPASSING OP: ![]() Cassandra
Cassandra
In dit artikel wordt beschreven hoe partitionering werkt in Azure Cosmos DB voor Apache Cassandra.
API voor Cassandra maakt gebruik van partitionering om de afzonderlijke tabellen in een keyspace te schalen om te voldoen aan de prestatiebehoeften van uw toepassing. Partities worden gevormd op basis van de waarde van een partitiesleutel die is gekoppeld aan elke record in een tabel. Alle records in een partitie hebben dezelfde partitiesleutelwaarde. Azure Cosmos DB beheert transparant en automatisch de plaatsing van partities in de fysieke resources om efficiënt te voldoen aan de schaalbaarheids- en prestatiebehoeften van de tabel. Naarmate de doorvoer- en opslagvereisten van een toepassing toenemen, worden de gegevens in Azure Cosmos DB verplaatst en verdeeld over een groter aantal fysieke machines.
Partitionering gedraagt zich vanuit het oogpunt van ontwikkelaars op dezelfde manier voor Azure Cosmos DB voor Apache Cassandra als in systeemeigen Apache Cassandra. Er zijn echter enkele verschillen achter de schermen.
Verschillen tussen Apache Cassandra en Azure Cosmos DB
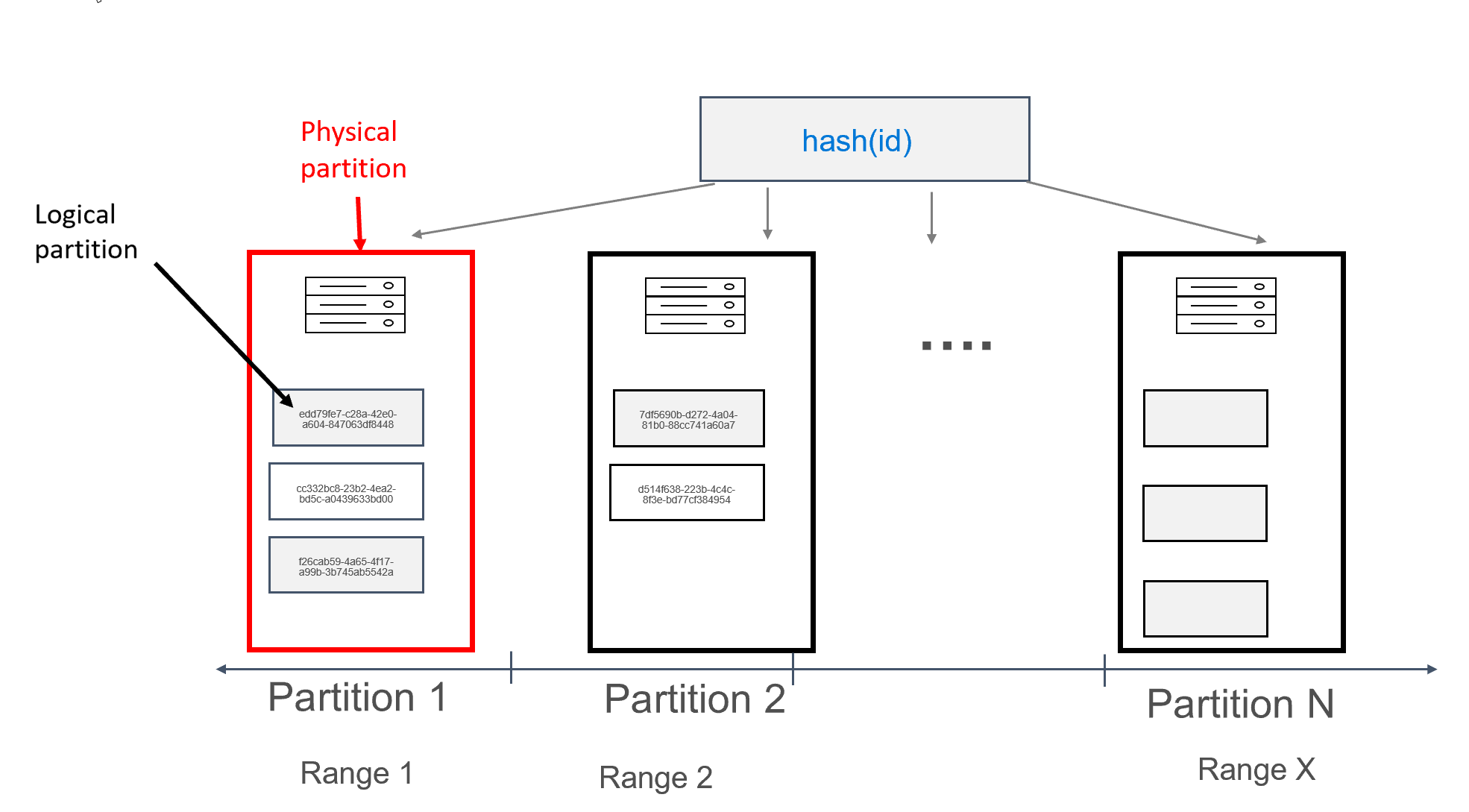
In Azure Cosmos DB wordt elke computer waarop partities worden opgeslagen, zelf een fysieke partitie genoemd. De fysieke partitie is vergelijkbaar met een virtuele machine; een toegewezen rekeneenheid of een set fysieke resources. Elke partitie die op deze rekeneenheid is opgeslagen, wordt een logische partitie genoemd in Azure Cosmos DB. Als u al bekend bent met Apache Cassandra, kunt u logische partities op dezelfde manier beschouwen als gewone partities in Cassandra.
Apache Cassandra raadt een limiet van 100 MB aan voor de grootte van een gegevens die in een partitie kunnen worden opgeslagen. De API voor Cassandra voor Azure Cosmos DB maakt maximaal 20 GB per logische partitie en maximaal 30 GB aan gegevens per fysieke partitie mogelijk. In Azure Cosmos DB wordt, in tegenstelling tot Apache Cassandra, rekencapaciteit die beschikbaar is in de fysieke partitie uitgedrukt met behulp van één metrische waarde, aanvraageenheden, waarmee u uw workload kunt zien in termen van aanvragen (lees- of schrijfbewerkingen) per seconde, in plaats van kernen, geheugen of IOPS. Dit kan de capaciteitsplanning duidelijker maken, zodra u de kosten van elke aanvraag begrijpt. Elke fysieke partitie kan maximaal 10000 RU's aan rekenkracht bevatten. Meer informatie over schaalbaarheidsopties vindt u in ons artikel over elastisch schalen in API voor Cassandra.
In Azure Cosmos DB bestaat elke fysieke partitie uit een set replica's, ook wel replicasets genoemd, met ten minste 4 replica's per partitie. Dit is in tegenstelling tot Apache Cassandra, waarbij het instellen van een replicatiefactor van 1 mogelijk is. Dit leidt echter tot lage beschikbaarheid als het enige knooppunt met de gegevens uitvalt. In API voor Cassandra is er altijd een replicatiefactor van 4 (quorum van 3). Azure Cosmos DB beheert automatisch replicasets, terwijl deze moeten worden onderhouden met behulp van verschillende hulpprogramma's in Apache Cassandra.
Apache Cassandra heeft een concept van tokens, wat hashes van partitiesleutels zijn. De tokens zijn gebaseerd op een murmur3 64 byte-hash, met waarden variërend van -2^63 tot -2^63 - 1. Dit bereik wordt meestal de tokenring genoemd in Apache Cassandra. De tokenring wordt gedistribueerd in tokenbereiken en deze bereiken zijn verdeeld over de knooppunten die aanwezig zijn in een systeemeigen Apache Cassandra-cluster. Partitionering voor Azure Cosmos DB wordt op een vergelijkbare manier geïmplementeerd, met uitzondering van een ander hash-algoritme en een grotere interne tokenring. Extern maken we echter hetzelfde tokenbereik beschikbaar als Apache Cassandra, d.w., -2^63 tot -2^63 - 1.
Primaire sleutel
Alle tabellen in API voor Cassandra moeten een primary key gedefinieerde tabel hebben. De syntaxis voor een primaire sleutel wordt hieronder weergegeven:
column_name cql_type_definition PRIMARY KEY
Stel dat we een gebruikerstabel willen maken, waarin berichten voor verschillende gebruikers worden opgeslagen:
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
In dit ontwerp hebben we het id veld gedefinieerd als de primaire sleutel. De primaire sleutel fungeert als de id voor de record in de tabel en wordt ook gebruikt als de partitiesleutel in Azure Cosmos DB. Als de primaire sleutel op de eerder beschreven manier is gedefinieerd, is er slechts één record in elke partitie. Dit resulteert in een perfect horizontale en schaalbare distributie bij het schrijven van gegevens naar de database en is ideaal voor gebruiksscenario's voor sleutelwaardezoekacties. De toepassing moet de primaire sleutel opgeven wanneer gegevens uit de tabel worden gelezen om de leesprestaties te maximaliseren.
Samengestelde primaire sleutel
Apache Cassandra heeft ook een concept van compound keys. Een samengestelde primary key bestaat uit meer dan één kolom; de eerste kolom is de partition key, en eventuele extra kolommen zijn de clustering keys. De syntaxis voor een compound primary key wordt hieronder weergegeven:
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
Stel dat we het bovenstaande ontwerp willen wijzigen en het mogelijk maken om berichten voor een bepaalde gebruiker efficiënt op te halen:
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
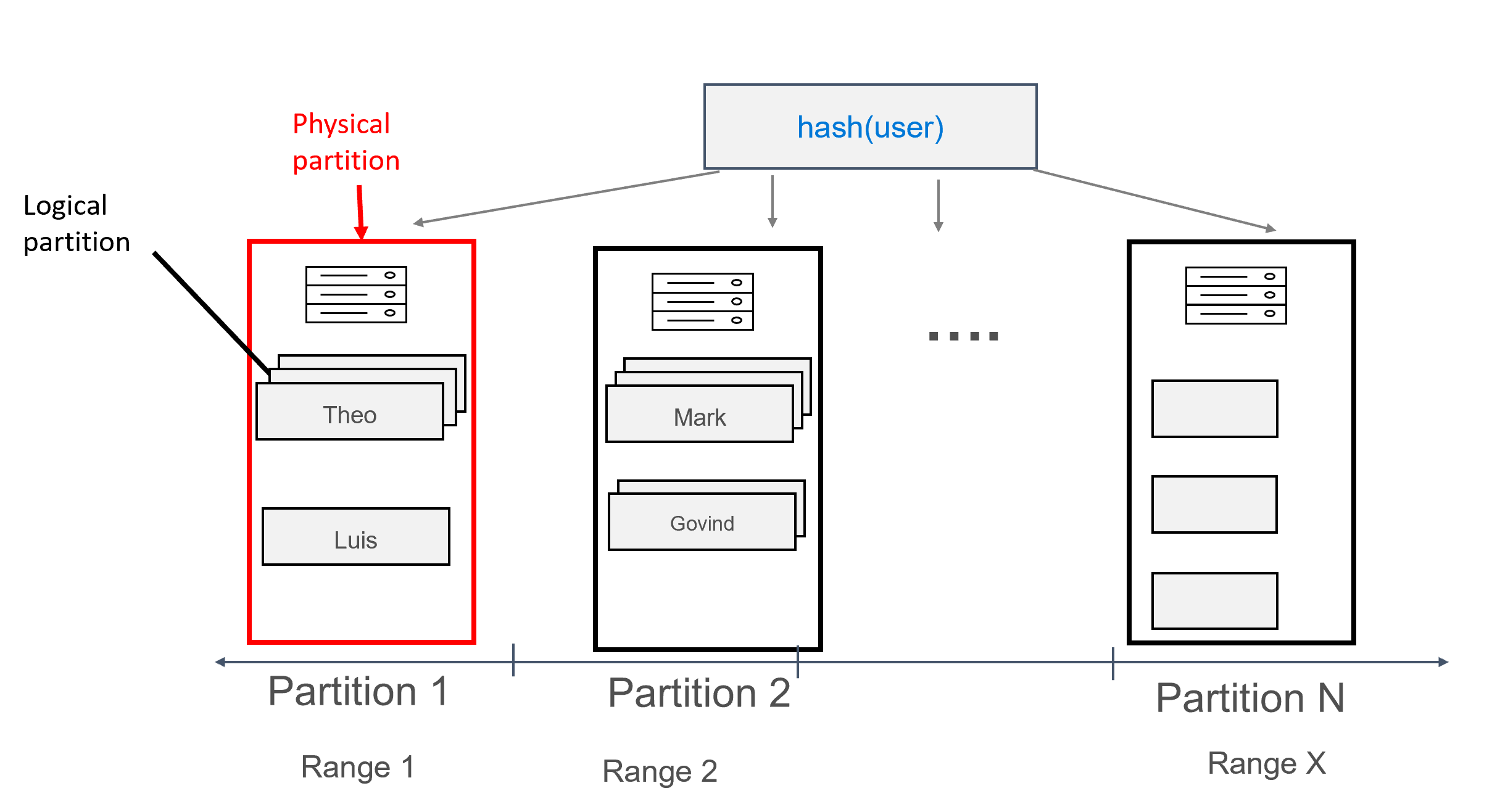
In dit ontwerp definiëren user we nu als de partitiesleutel en id als de clustersleutel. U kunt zoveel clustersleutels definiëren als u wilt, maar elke waarde (of een combinatie van waarden) voor de clusteringsleutel moet uniek zijn om ervoor te zorgen dat meerdere records aan dezelfde partitie worden toegevoegd, bijvoorbeeld:
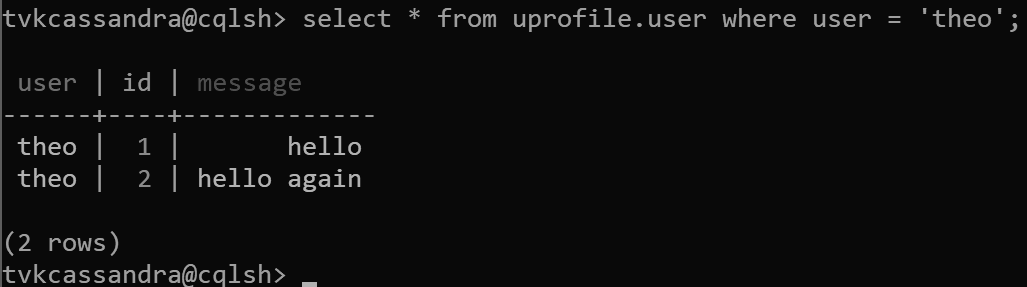
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
Wanneer gegevens worden geretourneerd, worden deze gesorteerd op de clusteringsleutel, zoals verwacht in Apache Cassandra:
Waarschuwing
Wanneer u query's uitvoert op gegevens in een tabel met een samengestelde primaire sleutel, moet u, als u wilt filteren op de partitiesleutel en andere niet-geïndexeerde velden naast de clusteringsleutel, ervoor zorgen dat u expliciet een secundaire index toevoegt aan de partitiesleutel:
CREATE INDEX ON uprofile.user (user);
Azure Cosmos DB voor Apache Cassandra past standaard geen indexen toe op partitiesleutels en de index in dit scenario kan de queryprestaties aanzienlijk verbeteren. Lees ons artikel over secundaire indexering voor meer informatie.
Met gegevens die op deze manier zijn gemodelleerd, kunnen meerdere records worden toegewezen aan elke partitie, gegroepeerd op gebruiker. We kunnen dus een query uitgeven die efficiënt wordt gerouteerd door de partition key (in dit geval user) om alle berichten voor een bepaalde gebruiker op te halen.
Samengestelde partitiesleutel
Samengestelde partitiesleutels werken in feite op dezelfde manier als samengestelde sleutels, behalve dat u meerdere kolommen kunt opgeven als een samengestelde partitiesleutel. De syntaxis van samengestelde partitiesleutels wordt hieronder weergegeven:
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
U kunt bijvoorbeeld het volgende hebben, waarbij de unieke combinatie van firstname de partitiesleutel id en lastname de clusteringsleutel is:
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );
Volgende stappen
- Meer informatie over partitioneren en horizontaal schalen in Azure Cosmos DB.
- Meer informatie over ingerichte doorvoer in Azure Cosmos DB.
- Meer informatie over wereldwijde distributie in Azure Cosmos DB.