Overzicht van indexeren in Azure Cosmos DB
VAN TOEPASSING OP: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tafel
Tafel
Azure Cosmos DB is een schemaagnostische database waarmee u uw toepassing kunt herhalen zonder dat u te maken hebt met schema- of indexbeheer. Standaard indexeert Azure Cosmos DB automatisch elke eigenschap voor alle items in uw container zonder dat u een schema hoeft te definiëren of secundaire indexen hoeft te configureren.
Het doel van dit artikel is om uit te leggen hoe gegevens worden geïndexeerd met Azure Cosmos DB en hoe indexen worden gebruikt om de queryprestaties te verbeteren. Het is raadzaam om deze sectie te doorlopen voordat u het indexeringsbeleid aanpast.
Van items naar bomen
Telkens wanneer een item wordt opgeslagen in een container, wordt de inhoud ervan als een JSON-document geprojecteerd en vervolgens geconverteerd naar een structuurweergave. Deze conversie betekent dat elke eigenschap van dat item wordt weergegeven als een knooppunt in een boomstructuur. Er wordt een pseudohoofdknooppunt gemaakt als bovenliggend element voor alle eigenschappen op het eerste niveau van het item. De bladknooppunten bevatten de werkelijke scalaire waarden die door een item worden overgedragen.
Bekijk bijvoorbeeld dit item:
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
Deze structuur vertegenwoordigt het JSON-voorbeelditem:
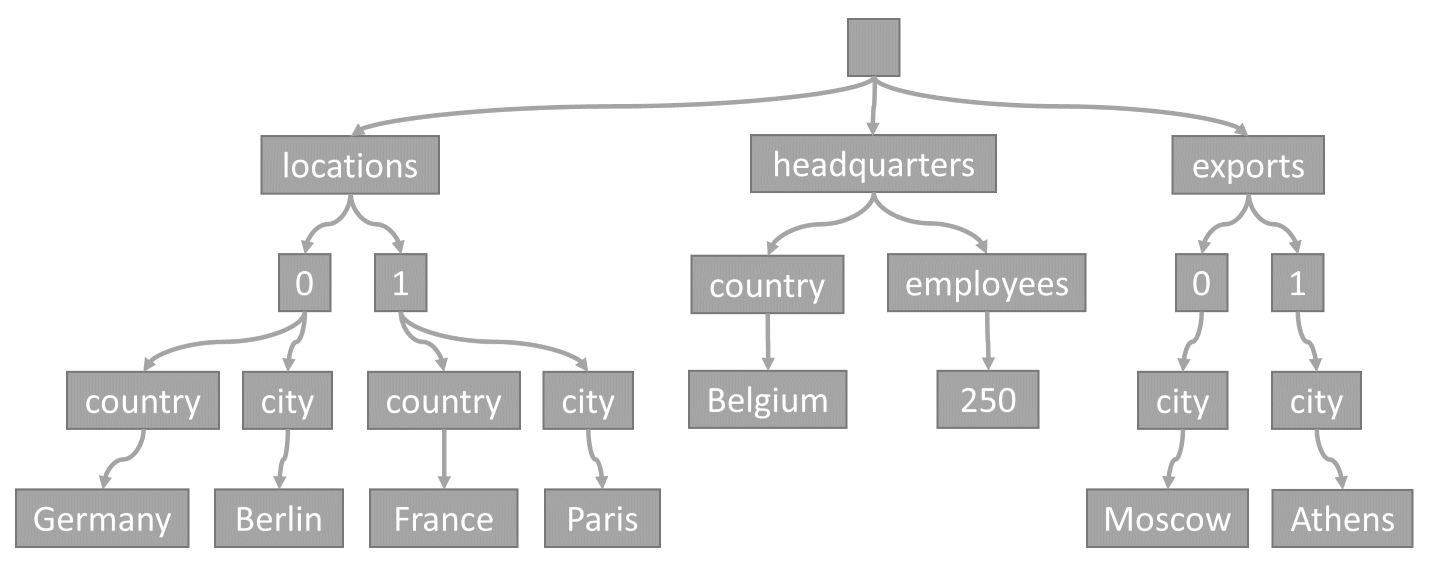
U ziet hoe matrices in de structuur worden gecodeerd: elke vermelding in een matrix krijgt een tussenliggend knooppunt met het label index van die vermelding in de matrix (0, 1 enzovoort).
Van bomen tot eigenschapspaden
De reden waarom Azure Cosmos DB items transformeert in bomen, is omdat het systeem kan verwijzen naar eigenschappen met behulp van hun paden binnen die bomen. Om het pad voor een eigenschap op te halen, kunnen we de structuur van het hoofdknooppunt naar die eigenschap doorlopen en de labels van elk doorkruist knooppunt samenvoegen.
Hier volgen de paden voor elke eigenschap uit het eerder beschreven voorbeelditem:
/locations/0/country: "Duitsland"/locations/0/city: "Berlijn"/locations/1/country: "Frankrijk"/locations/1/city: "Parijs"/headquarters/country: "België"/headquarters/employees: 250/exports/0/city: "Moskou"/exports/1/city: "Athene"
Azure Cosmos DB indexeert het pad van elke eigenschap en de bijbehorende waarde wanneer een item wordt geschreven.
Typen indexen
Azure Cosmos DB ondersteunt momenteel drie typen indexen. U kunt deze indextypen configureren bij het definiëren van het indexeringsbeleid.
Bereikindex
Bereikindexen zijn gebaseerd op een geordende structuur zoals een structuur. Het type bereikindex wordt gebruikt voor:
Gelijkheidsquery's:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")Gelijkheidsmatch op een matrixelement
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")Bereikquery's:
SELECT * FROM container c WHERE c.property > 'value'Notitie
(werkt voor
>,<,>=, ,<=)!=Controleren op de aanwezigheid van een eigenschap:
SELECT * FROM c WHERE IS_DEFINED(c.property)Systeemfuncties voor tekenreeksen:
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")ORDER BYQuery 's:SELECT * FROM container c ORDER BY c.propertyJOINQuery 's:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
Bereikindexen kunnen worden gebruikt voor scalaire waarden (tekenreeks of getal). Het standaardindexeringsbeleid voor nieuw gemaakte containers dwingt bereikindexen af voor een willekeurige tekenreeks of een willekeurig getal. Zie voorbeelden van bereikindexeringsbeleid voor meer informatie over het configureren van bereikindexen
Notitie
Een ORDER BY component die door één eigenschap wordt besteld, heeft altijd een bereikindex nodig en mislukt als het pad waarnaar wordt verwezen geen bereikindex heeft. Op dezelfde manier heeft een ORDER BY query die door meerdere eigenschappen wordt geordend, altijd een samengestelde index nodig.
Ruimtelijke index
Ruimtelijke indexen maken efficiënte query's mogelijk voor georuimtelijke objecten, zoals punten, lijnen, veelhoeken en multipolygon. Deze query's gebruiken ST_DISTANCE, ST_WITHIN ST_INTERSECTS trefwoorden. Hier volgen enkele voorbeelden die gebruikmaken van het type ruimtelijke index:
Georuimtelijke afstandsquery's:
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40Georuimtelijk binnen query's:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })Georuimtelijke intersect-query's:
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
Ruimtelijke indexen kunnen worden gebruikt voor geoJSON-objecten die correct zijn opgemaakt. Punten, LineStrings, Polygonen en MultiPolygons worden momenteel ondersteund. Zie voorbeelden van beleid voor ruimtelijke indexering voor meer informatie over het configureren van ruimtelijke indexering
Samengestelde indexen
Samengestelde indexen verhogen de efficiëntie wanneer u bewerkingen uitvoert op meerdere velden. Het samengestelde indextype wordt gebruikt voor:
ORDER BYquery's op meerdere eigenschappen:SELECT * FROM container c ORDER BY c.property1, c.property2Query's met een filter en
ORDER BY. Deze query's kunnen gebruikmaken van een samengestelde index als de filtereigenschap wordt toegevoegd aan deORDER BYcomponent.SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2Query's met een filter op twee of meer eigenschappen waarbij ten minste één eigenschap een gelijkheidsfilter is
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
Zolang één filterpredicaat een van het indextype gebruikt, evalueert de query-engine dat eerst voordat de rest wordt gescand. Als u bijvoorbeeld een SQL-query hebt, zoals SELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu")
De bovenstaande query filtert eerst op vermeldingen waarbij firstName = "Andrew" met behulp van de index. Vervolgens worden alle firstName = 'Andrew'-vermeldingen doorgegeven via een volgende pijplijn om het predicaat CONTAINS-filter te evalueren.
U kunt query's versnellen en volledige containerscans voorkomen wanneer u functies gebruikt die een volledige scan uitvoeren, zoals CONTAINS. U kunt meer filterpredicaten toevoegen die gebruikmaken van de index om deze query's sneller te maken. De volgorde van filtercomponenten is niet belangrijk. De query-engine bepaalt welke predicaten selectiever zijn en voer de query dienovereenkomstig uit.
Vectorindexen
Vectorindexen verhogen de efficiëntie bij het uitvoeren van vectorzoekopdrachten met behulp van de VectorDistance systeemfunctie. Zoekopdrachten in vectoren hebben aanzienlijk lagere latentie, hogere doorvoer en minder RU-verbruik bij het gebruik van een vectorindex.
Zie voorbeelden van vectorindexeringsbeleid voor meer informatie over het configureren van vectorindexen
ORDER BYvectorzoekquery's:SELECT c.name FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Projectie van de gelijkenisscore in vectorzoekquery's:
SELECT c.name, VectorDistance(c.vector1, c.vector2) AS SimilarityScore FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Bereikfilters voor de overeenkomstscore.
SELECT c.name FROM c WHERE VectorDistance(c.vector1, c.vector2) > 0.8 ORDER BY VectorDistance(c.vector1, c.vector2)Belangrijk
Vectorindexen moeten worden gedefinieerd op het moment van het maken van de container en kunnen niet worden gewijzigd nadat ze zijn gemaakt. In een toekomstige release kunnen vectorindexen worden gewijzigd.
Indexgebruik
Er zijn vijf manieren waarop de query-engine queryfilters kan evalueren, gesorteerd op meest efficiënt tot minst efficiënt:
- Indexzoeken
- Nauwkeurige indexscan
- Uitgevouwen indexscan
- Volledige indexscan
- Volledige scan
Wanneer u eigenschapspaden indexeren, gebruikt de query-engine automatisch de index zo efficiënt mogelijk. Afgezien van het indexeren van nieuwe eigenschapspaden hoeft u niets te configureren om te optimaliseren hoe query's de index gebruiken. De RU-kosten van een query zijn een combinatie van de RU-kosten van het indexgebruik en de RU-kosten van het laden van items.
Hier volgt een tabel met een overzicht van de verschillende manieren waarop indexen worden gebruikt in Azure Cosmos DB:
| Type indexzoekactie | Beschrijving | Algemene voorbeelden | RU-kosten van indexgebruik | RU-kosten voor het laden van items uit transactionele gegevensopslag |
|---|---|---|---|---|
| Indexzoeken | Alleen-lezen vereiste geïndexeerde waarden en alleen overeenkomende items uit het transactionele gegevensarchief laden | Gelijkheidsfilters, IN | Constante per gelijkheidsfilter | Verhogingen op basis van het aantal items in queryresultaten |
| Nauwkeurige indexscan | Binaire zoekopdracht van geïndexeerde waarden en laad alleen overeenkomende items uit het transactionele gegevensarchief | Bereikvergelijkingen (>, <= <of >=), StartsWith | Vergelijkbaar met het zoeken naar indexen, neemt enigszins toe op basis van de kardinaliteit van geïndexeerde eigenschappen | Verhogingen op basis van het aantal items in queryresultaten |
| Uitgevouwen indexscan | Geoptimaliseerde zoekopdracht (maar minder efficiënt dan een binaire zoekopdracht) van geïndexeerde waarden en laad alleen overeenkomende items uit het transactionele gegevensarchief | StartsWith (hoofdlettergevoelig), StringEquals (hoofdlettergevoelig) | Neemt enigszins toe op basis van de kardinaliteit van geïndexeerde eigenschappen | Verhogingen op basis van het aantal items in queryresultaten |
| Volledige indexscan | Afzonderlijke set geïndexeerde waarden lezen en alleen overeenkomende items uit het transactionele gegevensarchief laden | Bevat, EndsWith, RegexMatch, LIKE | Wordt lineair verhoogd op basis van de kardinaliteit van geïndexeerde eigenschappen | Verhogingen op basis van het aantal items in queryresultaten |
| Volledige scan | Alle items uit het transactionele gegevensarchief laden | Boven, onder | N.v.t. | Verhoogt op basis van het aantal items in de container |
Bij het schrijven van query's moet u filterpredicaten gebruiken die de index zo efficiënt mogelijk gebruiken. Als StartsWith u bijvoorbeeld voor uw use-case werkt, Contains moet u ervoor kiezen om StartsWith een nauwkeurige indexscan uit te voeren in plaats van een volledige indexscan.
Details van indexgebruik
In deze sectie behandelen we meer informatie over hoe query's indexen gebruiken. Dit detailniveau is niet nodig om aan de slag te gaan met Azure Cosmos DB, maar wordt gedetailleerd gedocumenteerd voor nieuwsgierige gebruikers. We verwijzen naar het voorbeelditem dat eerder in dit document is gedeeld:
Voorbeelditems:
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
Azure Cosmos DB maakt gebruik van een omgekeerde index. De index werkt door elk JSON-pad toe te kennen aan de set items die die waarde bevatten. De item-id-toewijzing wordt weergegeven op veel verschillende indexpagina's voor de container. Hier volgt een voorbeelddiagram van een omgekeerde index voor een container die de twee voorbeelditems bevat:
| Pad | Weergegeven als | Lijst met item-id's |
|---|---|---|
| /locations/0/country | Duitsland | 1 |
| /locations/0/country | Ierland | 2 |
| /locations/0/city | Berlijn | 1 |
| /locations/0/city | Dublin | 2 |
| /locations/1/country | Frankrijk | 1 |
| /locations/1/city | Parijs | 1 |
| /headquarters/country | België | 1, 2 |
| /hoofdkantoor/werknemers | 200 | 2 |
| /hoofdkantoor/werknemers | 250 | 1 |
De omgekeerde index heeft twee belangrijke kenmerken:
- Voor een bepaald pad worden waarden in oplopende volgorde gesorteerd. Daarom kan de query-engine eenvoudig worden uitgevoerd
ORDER BYvanuit de index. - Voor een bepaald pad kan de query-engine de afzonderlijke set mogelijke waarden scannen om de indexpagina's te identificeren waar de resultaten zijn.
De query-engine kan de omgekeerde index op vier verschillende manieren gebruiken:
Indexzoeken
Houd rekening met de volgende query:
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'
Het querypredicaat (filteren op items waar een locatie 'Frankrijk' heeft als land/regio) komt overeen met het pad dat in dit diagram is gemarkeerd:
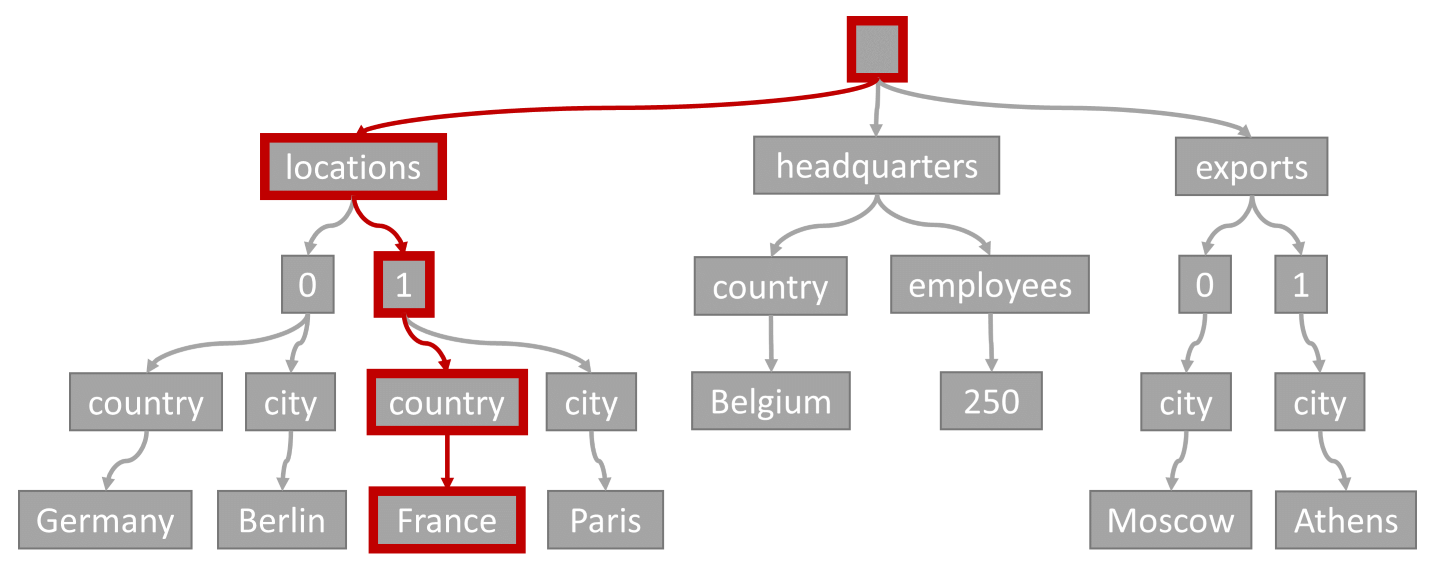
Omdat deze query een gelijkheidsfilter heeft, kunnen we na het doorlopen van deze structuur snel de indexpagina's identificeren die de queryresultaten bevatten. In dit geval zou de query-engine indexpagina's lezen die item 1 bevatten. Een indexzoeken is de meest efficiënte manier om de index te gebruiken. Met een indexzoeken lezen we alleen de benodigde indexpagina's en laden we alleen de items in de queryresultaten. Daarom zijn de opzoektijd en RU-kosten van indexzoektijd ongelooflijk laag, ongeacht het totale gegevensvolume.
Nauwkeurige indexscan
Houd rekening met de volgende query:
SELECT *
FROM company
WHERE company.headquarters.employees > 200
Het querypredicaat (filteren op items met meer dan 200 werknemers) kan worden geëvalueerd met een nauwkeurige indexscan van het headquarters/employees pad. Wanneer u een nauwkeurige indexscan uitvoert, begint de query-engine met een binaire zoekopdracht van de afzonderlijke set mogelijke waarden om de locatie van de waarde 200 voor het headquarters/employees pad te vinden. Omdat de waarden voor elk pad in oplopende volgorde worden gesorteerd, is het eenvoudig voor de query-engine om een binaire zoekopdracht uit te voeren. Nadat de query-engine de waarde 200heeft gevonden, worden alle resterende indexpagina's gelezen (in oplopende richting).
Omdat de query-engine een binaire zoekopdracht kan uitvoeren om te voorkomen dat onnodige indexpagina's worden gescand, hebben nauwkeurige indexscans meestal vergelijkbare latentie en RU-kosten voor indexzoekbewerkingen.
Uitgevouwen indexscan
Houd rekening met de volgende query:
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
Het querypredicaat (filteren op items met hoofdkantoor op een locatie die beginnen met hoofdlettergevoelig 'Verenigd') kan worden geëvalueerd met een uitgebreide indexscan van het headquarters/country pad. Bewerkingen die een uitgebreide indexscan uitvoeren, hebben optimalisaties die kunnen helpen voorkomen dat elke indexpagina moet worden gescand, maar iets duurder zijn dan de binaire zoekfunctie van een indexscan.
Als u bijvoorbeeld hoofdlettergevoelig StartsWithevalueert, controleert de query-engine de index op verschillende mogelijke combinaties van hoofdletters en kleine letters. Met deze optimalisatie kan de query-engine voorkomen dat de meeste indexpagina's worden gelezen. Verschillende systeemfuncties hebben verschillende optimalisaties die ze kunnen gebruiken om te voorkomen dat elke indexpagina wordt gelezen, zodat ze breed worden gecategoriseerd als uitgebreide indexscan.
Volledige indexscan
Houd rekening met de volgende query:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Het querypredicaat (filteren op items met hoofdkantoor op een locatie met United) kan worden geëvalueerd met een indexscan van het headquarters/country pad. In tegenstelling tot een nauwkeurige indexscan scant een volledige indexscan altijd door de afzonderlijke set mogelijke waarden om de indexpagina's te identificeren met resultaten. In dit geval Contains wordt deze uitgevoerd op de index. De indexzoektijd en RU-kosten voor indexscans nemen toe naarmate de kardinaliteit van het pad toeneemt. Met andere woorden, hoe meer mogelijke afzonderlijke waarden de query-engine moet scannen, hoe hoger de latentie en RU-kosten bij het uitvoeren van een volledige indexscan.
Denk bijvoorbeeld aan twee eigenschappen: town en country. De kardinaliteit van de stad is 5.000 en de kardinaliteit is country 200. Hier volgen twee voorbeeldquery's die elk een systeemfunctie bevatten die een volledige indexscan op de town eigenschap doet. De eerste query gebruikt meer RU's dan de tweede query omdat de kardinaliteit van de stad hoger is dan country.
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
Volledige scan
In sommige gevallen kan de query-engine mogelijk geen queryfilter evalueren met behulp van de index. In dit geval moet de query-engine alle items uit het transactionele archief laden om het queryfilter te evalueren. Volledige scans gebruiken de index niet en hebben een RU-kosten die lineair worden verhoogd met de totale gegevensgrootte. Gelukkig zijn bewerkingen die volledige scans vereisen zeldzaam.
Vectorzoekquery's zonder een gedefinieerde vectorindex
Als u geen vectorindexbeleid definieert en de VectorDistance systeemfunctie in een ORDER BY component gebruikt, resulteert dit in een volledige scan en wordt een RU-kosten hoger in rekening gebracht dan wanneer u een vectorindexbeleid hebt gedefinieerd. Vergelijkbaarheid, als u VectorDistance gebruikt met de brute force booleaanse waarde ingesteld trueop en geen index heeft flat gedefinieerd voor het vectorpad, wordt er een volledige scan uitgevoerd.
Query's met complexe filterexpressies
In de eerdere voorbeelden hebben we alleen query's overwogen die eenvoudige filterexpressies hadden (bijvoorbeeld query's met slechts één gelijkheids- of bereikfilter). In werkelijkheid hebben de meeste query's veel complexere filterexpressies.
Houd rekening met de volgende query:
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
Als u deze query wilt uitvoeren, moet de query-engine een indexzoekopdracht uitvoeren op headquarters/employees en een volledige indexscan uitvoeren op headquarters/country. De query-engine heeft interne heuristieken die worden gebruikt om de queryfilterexpressie zo efficiënt mogelijk te evalueren. In dit geval zou de query-engine voorkomen dat onnodige indexpagina's moeten worden gelezen door eerst de indexzoekfunctie uit te voeren. Als bijvoorbeeld slechts 50 items overeenkomen met het gelijkheidsfilter, hoeft de query-engine alleen te evalueren Contains op de indexpagina's die deze 50 items bevatten. Een volledige indexscan van de hele container is niet nodig.
Indexgebruik voor scalaire statistische functies
Query's met statistische functies moeten uitsluitend afhankelijk zijn van de index om deze te kunnen gebruiken.
In sommige gevallen kan de index fout-positieven retourneren. Wanneer u bijvoorbeeld evalueert Contains op de index, kan het aantal overeenkomsten in de index het aantal queryresultaten overschrijden. De query-engine laadt alle indexovereenkomsten, evalueert het filter op de geladen items en retourneert alleen de juiste resultaten.
Voor de meeste query's heeft het laden van fout-positieve indexovereenkomsten geen merkbaar effect op het indexgebruik.
Kijk bijvoorbeeld eens naar de volgende query:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
De Contains systeemfunctie kan enkele fout-positieve overeenkomsten retourneren, dus de query-engine moet controleren of elk geladen item overeenkomt met de filterexpressie. In dit voorbeeld hoeft de query-engine mogelijk slechts een paar extra items te laden, zodat het effect op het indexgebruik en de RU-kosten minimaal is.
Query's met statistische functies moeten echter uitsluitend afhankelijk zijn van de index om deze te kunnen gebruiken. Bekijk bijvoorbeeld de volgende query met een Count statistische functie:
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Net als in het eerste voorbeeld kan de Contains systeemfunctie enkele fout-positieve overeenkomsten retourneren. In tegenstelling tot de SELECT * query kan de Count query de filterexpressie op de geladen items echter niet evalueren om alle indexovereenkomsten te controleren. De Count query moet uitsluitend afhankelijk zijn van de index, dus als er een kans is dat een filterexpressie fout-positieve overeenkomsten retourneert, wordt de query-engine in een volledige scan geplaatst.
Query's met de volgende statistische functies moeten uitsluitend afhankelijk zijn van de index, dus het evalueren van sommige systeemfuncties vereist een volledige scan.
Volgende stappen
Lees meer over indexering in de volgende artikelen: