Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Dit artikel bouwt voort op verschillende Concepten van Azure Cosmos DB, zoals gegevensmodellering, partitionering en ingerichte doorvoer om te laten zien hoe u een praktijkoefening voor gegevensontwerp kunt aanpakken.
Als u meestal met relationele databases werkt, hebt u waarschijnlijk gewoonten ontwikkeld voor het ontwerpen van gegevensmodellen. Vanwege de specifieke beperkingen, maar ook de unieke sterke punten van Azure Cosmos DB, worden de meeste van deze aanbevolen procedures niet goed vertaald en kunt u naar suboptimale oplossingen slepen. Het doel van dit artikel is om u te begeleiden bij het volledige proces van het modelleren van een praktijkgebruiksscenario in Azure Cosmos DB, van itemmodellering tot colocatie van entiteiten en containerpartitionering.
Voor een voorbeeld waarin de concepten in dit artikel worden geïllustreerd, downloadt of bekijkt u deze door de community gegenereerde broncode.
Belangrijk
Een bijdrager aan de community heeft dit codevoorbeeld bijgedragen. Het Azure Cosmos DB-team biedt geen ondersteuning voor het onderhoud.
Het scenario
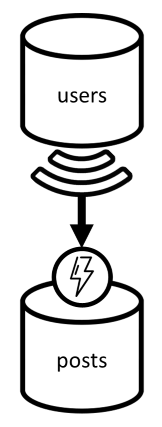
Voor deze oefening gaan we rekening houden met het domein van een blogplatform waar gebruikersberichten kunnen maken. Gebruikers kunnen ook leuk vinden en opmerkingen toevoegen aan deze berichten.
Aanbeveling
Sommige woorden worden cursief gemarkeerd om het soort 'dingen' te identificeren dat door ons model wordt bewerkt.
Meer vereisten toevoegen aan onze specificatie:
- Op een voorpagina wordt een feed met onlangs gemaakte berichten weergegeven.
- We kunnen alle posts van een gebruiker ophalen, alle opmerkingen bij een post en alle vind-ik-leuks bij een post.
- Berichten worden geretourneerd met de gebruikersnaam van hun auteurs en een aantal reacties en likes dat ze hebben.
- Opmerkingen en vind-ik-leuks worden ook geretourneerd met de gebruikersnamen van degenen die ze hebben gemaakt.
- Wanneer berichten worden weergegeven als lijsten, hoeven berichten alleen een afgekapte samenvatting van hun inhoud weer te geven.
De belangrijkste toegangspatronen identificeren
Om te beginnen geven we een structuur aan onze eerste specificatie door de toegangspatronen van onze oplossing te identificeren. Bij het ontwerpen van een gegevensmodel voor Azure Cosmos DB is het belangrijk om te begrijpen welke aanvragen het model moet dienen om ervoor te zorgen dat het model deze aanvragen efficiënt verwerkt.
Om het algehele proces gemakkelijker te volgen, categoriseren we deze verschillende aanvragen als opdrachten of query's, waardoor een deel van de woordenschat wordt geleend uit de scheiding van CQRS (Command Query Responsibility Segregation). In CQRS zijn opdrachten schrijfverzoeken (dat wil zeggen, intenties om het systeem bij te werken) en query's zijn alleen-lezen verzoeken.
Hier volgt de lijst met aanvragen die door ons platform worden weergegeven:
- [C1] Een gebruiker maken of bewerken
- [Q1] Een gebruiker ophalen
- [C2] Een bericht maken of bewerken
- [Q2] Een bericht ophalen
- [Q3] Berichten van een gebruiker in korte vorm weergeven
- [C3] Een opmerking maken
- [Q4] Opmerkingen van een bericht weergeven
- [C4] Een bericht leuk vinden
- [Q5] Likes van een bericht lijst tonen
- [Q6] Bekijk de x meest recente berichten in korte vorm (feed)
In deze fase hebben we niet nagedacht over de details van wat elke entiteit (gebruiker, post, enzovoort) bevat. Deze stap is meestal een van de eerste die moeten worden aangepakt bij het ontwerpen voor een relationele database. We beginnen met deze stap eerst omdat we moeten achterhalen hoe deze entiteiten zich vertalen in termen van tabellen, kolommen, refererende sleutels, enzovoort. Het is veel minder een probleem met een documentdatabase die geen schema bij schrijven afdwingt.
Het is belangrijk om onze toegangspatronen vanaf het begin te identificeren, omdat deze lijst met aanvragen onze testsuite wordt. Telkens wanneer we het gegevensmodel herhalen, doorlopen we elk van de aanvragen en controleren we de prestaties en schaalbaarheid. We berekenen de aanvraageenheden (RU) die in elk model worden gebruikt en optimaliseren ze. Al deze modellen gebruiken het standaardindexeringsbeleid en u kunt dit overschrijven door specifieke eigenschappen te indexeren, waardoor het RU-verbruik en de latentie verder kunnen worden verbeterd.
V1: Een eerste versie
We beginnen met twee containers: users en posts.
Gebruikerscontainer
In deze container worden alleen gebruikersitems opgeslagen:
{
"id": "<user-id>",
"username": "<username>"
}
We partitioneren deze container op id, wat betekent dat elke logische partitie binnen die container slechts één item bevat.
Berichtencontainer
Deze container host entiteiten zoals berichten, opmerkingen en vind-ik-leuks:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"title": "<post-title>",
"content": "<post-content>",
"creationDate": "<post-creation-date>"
}
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"creationDate": "<like-creation-date>"
}
We partitioneren deze container op postId, wat betekent dat elke logische partitie in die container één post bevat, alle opmerkingen voor dat bericht en alle vind-ik-leuks voor dat bericht.
We hebben een type eigenschap geïntroduceerd in de items die zijn opgeslagen in deze container om onderscheid te maken tussen de drie typen entiteiten die door deze container worden gehost.
We hebben er ook voor gekozen om te verwijzen naar gerelateerde gegevens in plaats van deze in te sluiten, omdat:
- Er is geen bovengrens voor het aantal berichten dat een gebruiker kan maken.
- Berichten kunnen willekeurig lang zijn.
- Er is geen bovengrens aan het aantal opmerkingen en vind-ik-leuks dat een bericht kan hebben.
- We willen een opmerking of een like aan een bericht kunnen toevoegen zonder het bericht zelf bij te werken.
Zie Gegevensmodellering in Azure Cosmos DB voor meer informatie over deze concepten.
Hoe goed presteert ons model?
Het is nu tijd om de prestaties en schaalbaarheid van onze eerste versie te beoordelen. Voor elk van de eerder geïdentificeerde aanvragen meten we de latentie en het aantal aanvraageenheden dat wordt verbruikt. Deze meting wordt uitgevoerd tegen een dummy-dataset met 100.000 gebruikers met 5 tot 50 berichten per gebruiker, tot 25 reacties en 100 vind-ik-leuks per bericht.
[C1] Een gebruiker maken of bewerken
Deze aanvraag is eenvoudig te implementeren omdat we alleen een item in de users container maken of bijwerken. De aanvragen worden mooi verdeeld over alle partities dankzij de id partitiesleutel.
| Latency | Aanvraageenheden | prestatie |
|---|---|---|
7 ms |
5.71 RU |
✅ |
[Q1] Een gebruiker ophalen
Het ophalen van een gebruiker wordt uitgevoerd door het bijbehorende item uit de users container te lezen.
| Latency | Aanvraageenheden | prestatie |
|---|---|---|
2 ms |
1 RU |
✅ |
[C2] Een bericht maken of bewerken
Net als bij [C1] moeten we alleen naar de posts container schrijven.
| Latency | Aanvraageenheden | prestatie |
|---|---|---|
9 ms |
8.76 RU |
✅ |
[Q2] Een bericht ophalen
We beginnen met het ophalen van het bijbehorende document uit de posts container. Maar dat is niet voldoende, volgens onze specificatie, moeten we ook de gebruikersnaam van de auteur van het bericht verzamelen, evenals het aantal opmerkingen en het aantal vind-ik-leuks voor het bericht. Voor de vermelde aggregaties moeten nog drie SQL-query's worden uitgegeven.
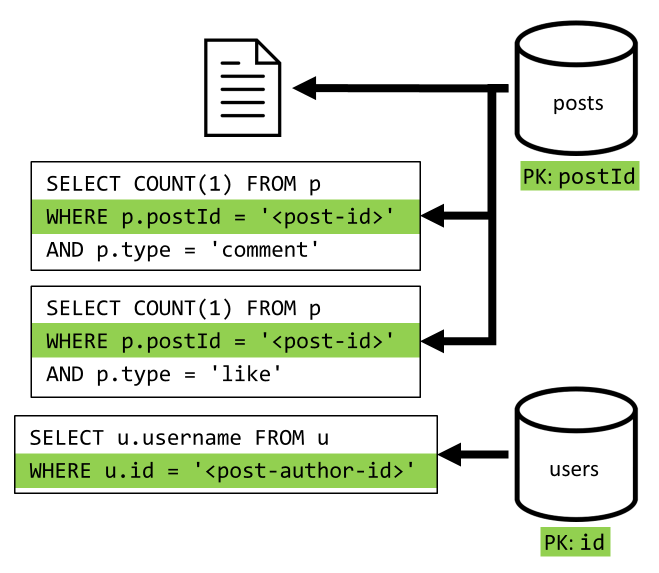
Elk van de query's filtert op de partitiesleutel van de respectieve container. Dit is precies wat we willen om de prestaties en schaalbaarheid te maximaliseren. Maar uiteindelijk moeten we vier bewerkingen uitvoeren om één post te retourneren, dus we verbeteren dat in een volgende iteratie.
| Latency | Aanvraageenheden | prestatie |
|---|---|---|
9 ms |
19.54 RU |
⚠ |
[Q3] Berichten van een gebruiker in korte vorm weergeven
Eerst moeten we de gewenste berichten ophalen met een SQL-query waarmee de berichten worden opgehaald die overeenkomen met die specifieke gebruiker. Maar we moeten ook meer query's uitvoeren om de gebruikersnaam van de auteur en het aantal opmerkingen en vind-ik-leuks te verzamelen.
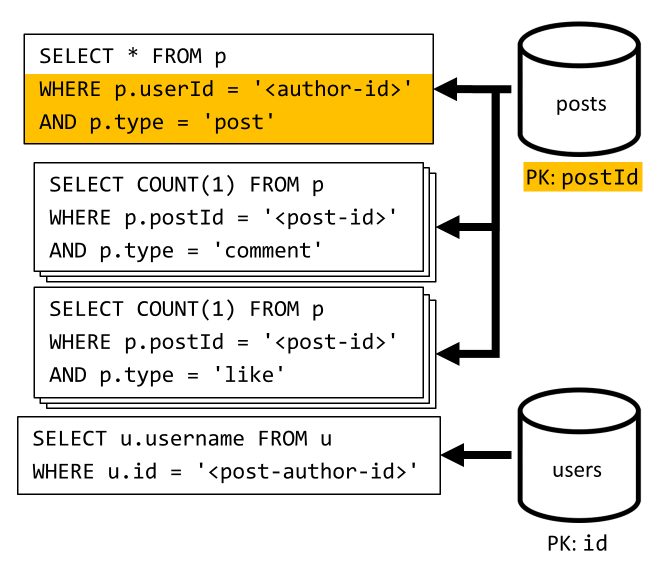
Deze implementatie biedt veel nadelen:
- De queries die het aantal opmerkingen en likes aggregeren, moeten worden uitgegeven voor elk bericht dat door de eerste query wordt geretourneerd.
- De hoofdquery filtert niet op de partitiesleutel van de
postscontainer, wat leidt tot een fan-out en een partitiescan over de container.
| Latency | Aanvraageenheden | prestatie |
|---|---|---|
130 ms |
619.41 RU |
⚠ |
[C3] Een opmerking maken
Er wordt een opmerking gemaakt door het bijbehorende item in de posts container te schrijven.
| Latency | Aanvraageenheden | prestatie |
|---|---|---|
7 ms |
8.57 RU |
✅ |
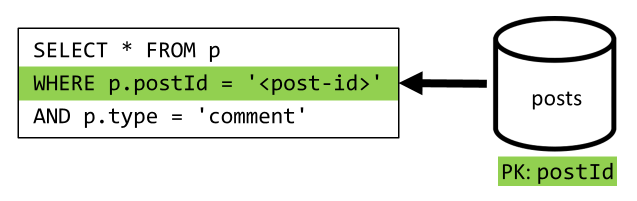
[Q4] Opmerkingen van een bericht weergeven
We beginnen met een query waarmee alle opmerkingen voor dat bericht worden opgehaald en opnieuw moeten we ook gebruikersnamen afzonderlijk aggregeren voor elke opmerking.
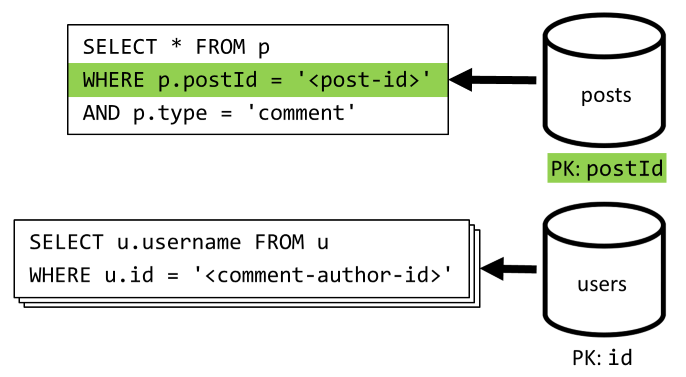
Hoewel de hoofdquery wel filtert op de partitiesleutel van de container, heeft de aparte aggregatie van gebruikersnamen een negatieve invloed op de algehele prestaties. Dat verbeteren we later.
| Latency | Aanvraageenheden | prestatie |
|---|---|---|
23 ms |
27.72 RU |
⚠ |
[C4] Een bericht leuk vinden
Net als [C3] maken we het bijbehorende item in de posts container.
| Latency | Aanvraageenheden | prestatie |
|---|---|---|
6 ms |
7.05 RU |
✅ |
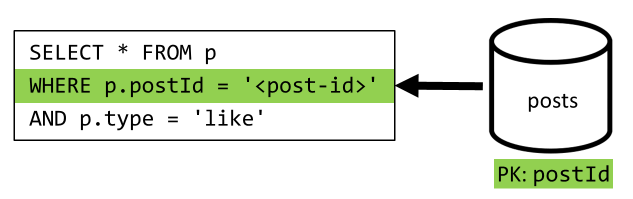
Toon likes van een bericht
Zoals bij [Q4] voeren we een query uit op de vind-ik-leuks voor dat bericht om vervolgens hun gebruikersnamen te verzamelen.
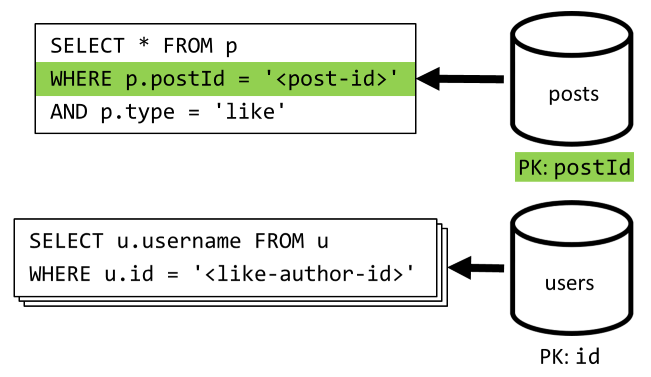
| Latency | Aanvraageenheden | prestatie |
|---|---|---|
59 ms |
58.92 RU |
⚠ |
[Q6] De x meest recente berichten weergeven die zijn gemaakt in korte vorm (feed)
We halen de meest recente berichten op door een query uit te voeren op de posts container, gesorteerd op aflopende creatiedatum. Vervolgens aggregeren we de gebruikersnamen en het aantal opmerkingen en vind-ik-leuks voor elk van de berichten.
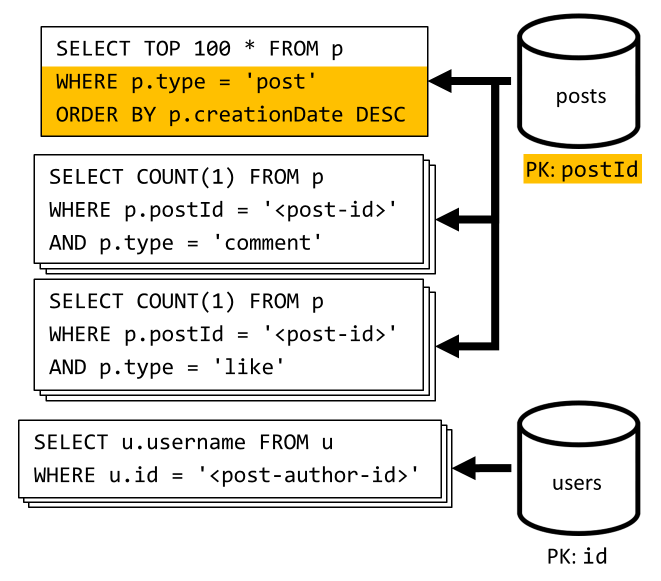
Nogmaals, onze eerste query filtert niet op de partitiesleutel van de posts container, waardoor een kostbare fan-out wordt geactiveerd. Deze is nog erger omdat we met een grotere set resultaten werken en de resultaten sorteren met een ORDER BY clausule, wat het duurder maakt in termen van aanvraageenheden.
| Latency | Aanvraageenheden | prestatie |
|---|---|---|
306 ms |
2063.54 RU |
⚠ |
Nadenken over de prestaties van V1
Als we kijken naar de prestatieproblemen die we in de vorige sectie hebben ondervonden, kunnen we twee hoofdklassen van problemen identificeren:
- Voor sommige aanvragen moeten meerdere query's worden uitgegeven om alle gegevens te verzamelen die we moeten retourneren.
- Sommige query's filteren niet op de partitiesleutel van de containers waarop ze gericht zijn, wat leidt tot een brede verspreiding die onze schaalbaarheid belemmert.
Laten we elk van deze problemen oplossen, beginnend met de eerste.
V2: Introduceer denormalisatie om de leesopdrachten te optimaliseren
De reden waarom we in sommige gevallen meer aanvragen moeten uitgeven, is omdat de resultaten van de eerste aanvraag niet alle gegevens bevatten die we moeten retourneren. Het denormaliseren van gegevens lost dit soort problemen op in onze gegevensset wanneer u werkt met een niet-relationeel gegevensarchief zoals Azure Cosmos DB.
In ons voorbeeld wijzigen we postitems om de gebruikersnaam van de auteur van het bericht toe te voegen, het aantal opmerkingen en het aantal vind-ik-leuks:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
We wijzigen ook opmerkingen en like-items om de gebruikersnaam toe te voegen van de gebruiker die ze heeft gemaakt:
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"userUsername": "<comment-author-username>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"userUsername": "<liker-username>",
"creationDate": "<like-creation-date>"
}
Denormaliseer commentaar- en like-tellingen
Wat we willen bereiken, is dat telkens wanneer we een opmerking of een dergelijke toevoegen, we ook de commentCount of de likeCount in het bijbehorende bericht verhogen. Wanneer postId de container gepartitioneerd is op posts, bevinden het nieuwe item (opmerking of "vind ik leuk") en het bijbehorende bericht zich in dezelfde logische partitie. Als gevolg hiervan kunnen we een opgeslagen procedure gebruiken om die bewerking uit te voeren.
Wanneer u een opmerking maakt ([C3]), wordt de volgende opgeslagen procedure voor die container aangeroepen in plaats van alleen een nieuw item toe te voegen in de posts container:
function createComment(postId, comment) {
var collection = getContext().getCollection();
collection.readDocument(
`${collection.getAltLink()}/docs/${postId}`,
function (err, post) {
if (err) throw err;
post.commentCount++;
collection.replaceDocument(
post._self,
post,
function (err) {
if (err) throw err;
comment.postId = postId;
collection.createDocument(
collection.getSelfLink(),
comment
);
}
);
})
}
Deze opgeslagen procedure neemt de id van het bericht en de hoofdtekst van de nieuwe opmerking als parameters, en vervolgens:
- haalt het bericht op.
- verhoogt de
commentCount. - vervangt het bericht.
- voegt de nieuwe opmerking toe.
Aangezien opgeslagen procedures worden uitgevoerd als atomische transacties, blijft de waarde van commentCount en het werkelijke aantal opmerkingen altijd gesynchroniseerd.
We roepen uiteraard een vergelijkbare opgeslagen procedure aan bij het toevoegen van nieuwe likes om het likeCount te verhogen.
Gebruikersnamen denormaliseren
Gebruikersnamen vereisen een andere benadering omdat gebruikers niet alleen in verschillende partities, maar in een andere container zitten. Wanneer we gegevens moeten denormaliseren tussen partities en containers, kunnen we de wijzigingenfeed van de broncontainer gebruiken.
In ons voorbeeld gebruiken we de wijzigingenfeed van de users container om te reageren wanneer gebruikers hun gebruikersnamen bijwerken. Als dat gebeurt, wordt de wijziging doorgegeven door een andere opgeslagen procedure op de posts container aan te roepen:
function updateUsernames(userId, username) {
var collection = getContext().getCollection();
collection.queryDocuments(
collection.getSelfLink(),
`SELECT * FROM p WHERE p.userId = '${userId}'`,
function (err, results) {
if (err) throw err;
for (var i in results) {
var doc = results[i];
doc.userUsername = username;
collection.upsertDocument(
collection.getSelfLink(),
doc);
}
});
}
Deze opgeslagen procedure gebruikt de id van de gebruiker en de nieuwe gebruikersnaam van de gebruiker als parameters. Vervolgens:
- hiermee worden alle items opgehaald die overeenkomen met de
userIditems (die berichten, opmerkingen of vind-ik-leuks kunnen zijn). - voor elk van deze items:
- vervangt de
userUsername. - vervangt het item.
- vervangt de
Belangrijk
Deze bewerking is kostbaar omdat deze opgeslagen procedure moet worden uitgevoerd op elke partitie van de posts container. We gaan ervan uit dat de meeste gebruikers tijdens de registratie een geschikte gebruikersnaam kiezen en deze nooit wijzigen, dus deze update wordt zelden uitgevoerd.
Wat zijn de prestatieverbeteringen van V2?
Laten we het hebben over enkele prestatieverbeteringen van V2.
[Q2] Een bericht ophalen
Nu onze denormalisatie is ingesteld, hoeven we slechts één item op te halen om die aanvraag af te handelen.
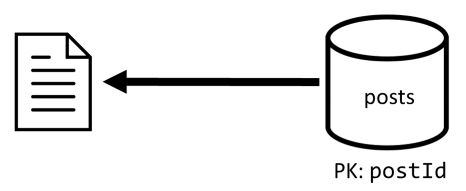
| Latency | Aanvraageenheden | prestatie |
|---|---|---|
2 ms |
1 RU |
✅ |
[Q4] Opmerkingen van een bericht weergeven
Ook hier kunnen we de extra aanvragen die de gebruikersnamen ophalen uitsparen en in plaats daarvan één enkele query gebruiken die filtert op de partitiesleutel.
| Latency | Aanvraageenheden | prestatie |
|---|---|---|
4 ms |
7.72 RU |
✅ |
Toon likes van een bericht
Exact dezelfde situatie bij het weergeven van vind-ik-leuks.
| Latency | Aanvraageenheden | prestatie |
|---|---|---|
4 ms |
8.92 RU |
✅ |
V3: Zorg ervoor dat alle aanvragen schaalbaar zijn
Er zijn nog steeds twee aanvragen die we niet volledig hebben geoptimaliseerd bij het bekijken van onze algehele prestatieverbeteringen. Deze aanvragen zijn [Q3] en [Q6]. Dit zijn de aanvragen die betrekking hebben op query's die niet filteren op de partitiesleutel van de containers waarop ze zijn gericht.
[Q3] Berichten van een gebruiker in korte vorm weergeven
Deze aanvraag profiteert al van de verbeteringen die zijn geïntroduceerd in V2, waardoor meer query's worden bespaard.

De overgebleven query wordt echter nog steeds niet gefilterd op de partitiesleutel van de posts-container.
De manier om na te denken over deze situatie is eenvoudig:
- Deze aanvraag moet worden gefilterd op de
userIdpagina omdat we alle berichten voor een bepaalde gebruiker willen ophalen. - Het werkt niet goed omdat het wordt uitgevoerd op de
postscontainer, dieuserIdpartitionering niet heeft. - Wat duidelijk is, zouden we ons prestatieprobleem oplossen door deze aanvraag uit te voeren op een container die is gepartitioneerd met
userId. - Het blijkt dat we al een dergelijke container hebben: de
userscontainer!
We introduceren dus een tweede niveau van denormalisatie door hele berichten te dupliceren naar de users container. Door dat te doen, verkrijgen we effectief een kopie van onze berichten, gepartitioneerd langs een andere dimensie, waardoor ze veel efficiënter kunnen worden opgehaald met hun userId.
De users container bevat nu twee soorten items:
{
"id": "<user-id>",
"type": "user",
"userId": "<user-id>",
"username": "<username>"
}
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
In dit voorbeeld:
- We hebben een
typeveld in het gebruikersitem geïntroduceerd om gebruikers te onderscheiden van berichten. - We hebben ook een
userIdveld toegevoegd in het gebruikersitem, dat overbodig is met hetidveld, maar is vereist omdat deuserscontainer nu is gepartitioneerd metuserId(en nietidzoals eerder).
Om die denormalisatie te bereiken, gebruiken we opnieuw de wijzigingenfeed. Deze keer reageren we op de wijzigingenfeed van de posts container om nieuwe of bijgewerkte post naar de users container te verzenden. En omdat het opsommen van berichten niet vereist hun volledige inhoud terug te geven, kunnen we ze in het proces afkorten.
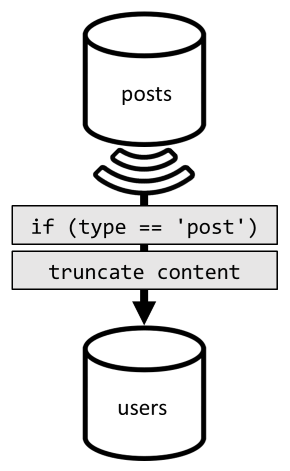
We kunnen onze query nu routeren naar de users container en filteren op de partitiesleutel van de container.

| Latency | Aanvraageenheden | prestatie |
|---|---|---|
4 milliseconden |
6.46 RU |
✅ |
[Q6] De x meest recente berichten weergeven die zijn gemaakt in korte vorm (feed)
We moeten hier met een vergelijkbare situatie omgaan: zelfs nadat er meerdere onnodige query's zijn overgebleven als gevolg van denormalisatie geïntroduceerd in V2, filtert de resterende query niet met de partitiesleutel van de container.
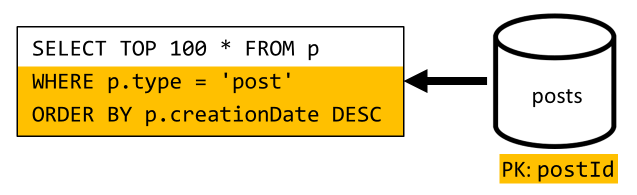
Door dezelfde benadering te volgen, vereist het maximaliseren van de prestaties en schaalbaarheid van dit verzoek dat het slechts één partitie raakt. Het is mogelijk om maar één partitie te benaderen, omdat we slechts een beperkt aantal items hoeven te retourneren. Om de startpagina van ons blogplatform te kunnen vullen, moeten we alleen de 100 meest recente berichten ophalen, zonder dat u de hele gegevensset hoeft te pagineren.
Om deze laatste aanvraag te optimaliseren, introduceren we een derde container in ons ontwerp, volledig gewijd aan het leveren van deze aanvraag. We denormaliseren onze berichten naar die nieuwe feed container:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Het type veld partitioneert deze container, die zich altijd post in onze items bevindt. Dit zorgt ervoor dat alle items in deze container zich in dezelfde partitie bevinden.
Om de denormalisatie te bereiken, moeten we alleen de pijplijn van de wijzigingenfeed koppelen die we eerder hebben geïntroduceerd om de berichten naar die nieuwe container te verzenden. Belangrijk om rekening mee te houden is dat we ervoor moeten zorgen dat we alleen de 100 meest recente berichten opslaan; anders kan de inhoud van de container groter worden dan de maximale grootte van een partitie. Deze beperking kan worden geïmplementeerd door een post-trigger aan te roepen telkens wanneer een document wordt toegevoegd in de container:
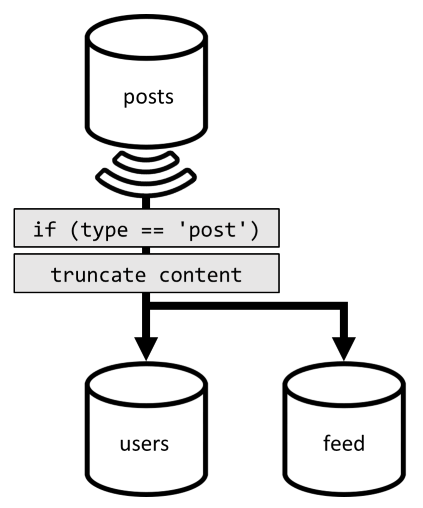
Hier volgt de hoofdtekst van de 'post-trigger' waarmee de verzameling wordt verkort:
function truncateFeed() {
const maxDocs = 100;
var context = getContext();
var collection = context.getCollection();
collection.queryDocuments(
collection.getSelfLink(),
"SELECT VALUE COUNT(1) FROM f",
function (err, results) {
if (err) throw err;
processCountResults(results);
});
function processCountResults(results) {
// + 1 because the query didn't count the newly inserted doc
if ((results[0] + 1) > maxDocs) {
var docsToRemove = results[0] + 1 - maxDocs;
collection.queryDocuments(
collection.getSelfLink(),
`SELECT TOP ${docsToRemove} * FROM f ORDER BY f.creationDate`,
function (err, results) {
if (err) throw err;
processDocsToRemove(results, 0);
});
}
}
function processDocsToRemove(results, index) {
var doc = results[index];
if (doc) {
collection.deleteDocument(
doc._self,
function (err) {
if (err) throw err;
processDocsToRemove(results, index + 1);
});
}
}
}
De laatste stap is het omleiden van onze query naar onze nieuwe feed container:
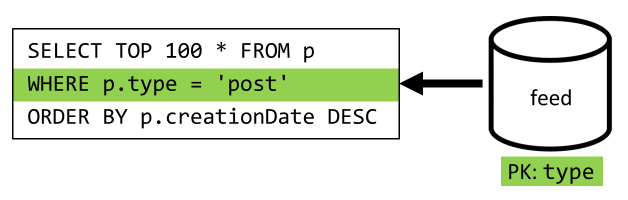
| Latency | Aanvraageenheden | prestatie |
|---|---|---|
9 ms |
16.97 RU |
✅ |
Conclusion
Laten we eens kijken naar de algemene prestatie- en schaalbaarheidsverbeteringen die we hebben geïntroduceerd in de verschillende versies van ons ontwerp.
| V1 | V2 | V3 | |
|---|---|---|---|
| [C1] |
7 ms / 5.71 RU |
7 ms / 5.71 RU |
7 ms / 5.71 RU |
| [Q1] |
2 ms / 1 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [C2] |
9 ms / 8.76 RU |
9 ms / 8.76 RU |
9 ms / 8.76 RU |
| [Q2] |
9 ms / 19.54 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [Q3] |
130 ms / 619.41 RU |
28 ms / 201.54 RU |
4 ms / 6.46 RU |
| [C3] |
7 ms / 8.57 RU |
7 ms / 15.27 RU |
7 ms / 15.27 RU |
| [Q4] |
23 ms / 27.72 RU |
4 ms / 7.72 RU |
4 ms / 7.72 RU |
| [C4] |
6 ms / 7.05 RU |
7 ms / 14.67 RU |
7 ms / 14.67 RU |
| [Q5] |
59 ms / 58.92 RU |
4 ms / 8.92 RU |
4 ms / 8.92 RU |
| [Q6] |
306 ms / 2063.54 RU |
83 ms / 532.33 RU |
9 ms / 16.97 RU |
We hebben een scenario met veel leesbewerkingen geoptimaliseerd
Mogelijk merkt u dat we ons hebben geconcentreerd op het verbeteren van de prestaties van leesaanvragen (query's) ten koste van schrijfaanvragen (opdrachten). In veel gevallen activeren schrijfbewerkingen nu volgende denormalisatie via wijzigingenfeeds, waardoor ze rekenkundig duurder en langer zijn om te worden gerealiseerd.
We rechtvaardigen deze focus op leesprestaties door het feit dat een blogplatform, zoals de meeste sociale apps, leesintensief is. Een werkbelasting met veel leesbewerkingen geeft aan dat de hoeveelheid leesaanvragen die het moet verwerken, meestal een hogere orde heeft dan het aantal schrijfaanvragen. Het is dus logisch om schrijfaanvragen duurder te maken om leesaanvragen goedkoper en beter te laten presteren.
Als we kijken naar de meest extreme optimalisatie die we hebben gedaan, ging [Q6] van 2000+ RU's naar slechts 17 RU's; We hebben dat bereikt door berichten te denormaliseren tegen ongeveer 10 RU's per item. Omdat we veel meer feedaanvragen zouden leveren dan het maken of bijwerken van berichten, is de kosten van deze denormalisatie te verwaarlozen gezien de totale besparingen.
Denormalisatie kan incrementeel worden toegepast
De schaalbaarheidsverbeteringen die we in dit artikel hebben verkend, omvatten denormalisatie en duplicatie van gegevens in de gegevensset. Er moet worden opgemerkt dat deze optimalisaties niet op dag één hoeven te worden ingesteld. Query's die filteren op partitiesleutels, presteren beter op schaal, maar query's tussen partities kunnen acceptabel zijn als ze zelden of tegen een beperkte gegevensset worden aangeroepen. Als u alleen een prototype bouwt of een product start met een klein en gecontroleerd gebruikersbestand, kunt u deze verbeteringen waarschijnlijk later besparen. Wat belangrijk is, is om de prestaties van uw model te bewaken , zodat u kunt bepalen of en wanneer het tijd is om ze binnen te halen.
De wijzigingenfeed die we gebruiken om updates naar andere containers te distribueren, slaan al deze updates permanent op. Deze persistentie maakt het mogelijk om alle updates aan te vragen sinds het maken van de container en om gedesnormaliseerde weergaven op te starten als een eenmalige inhaalactie, zelfs als uw systeem al veel gegevens bevat.
Volgende stappen
Na deze inleiding tot praktische gegevensmodellering en partitionering, kunt u de volgende artikelen controleren om de concepten te bekijken: