Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
VAN TOEPASSING OP:
![]() MongoDB
MongoDB
Azure Cosmos DB voor MongoDB maakt gebruik van de belangrijkste mogelijkheden voor indexbeheer van Azure Cosmos DB. Dit artikel is gericht op het toevoegen van indexen met behulp van Azure Cosmos DB voor MongoDB. Indexen zijn gespecialiseerde gegevensstructuren die het uitvoeren van query's op uw gegevens ongeveer een orde van grootte sneller maken.
Indexering voor MongoDB-serverversie 3.6 en hoger
Azure Cosmos DB voor MongoDB-serverversie 3.6+ indexeert automatisch het _id veld en de shardsleutel (alleen in shardverzamelingen). De API dwingt automatisch de uniciteit van het _id-veld per shard-sleutel af.
De API voor MongoDB gedraagt zich anders dan de Azure Cosmos DB for NoSQL, waarmee standaard alle velden worden geïndexeerd.
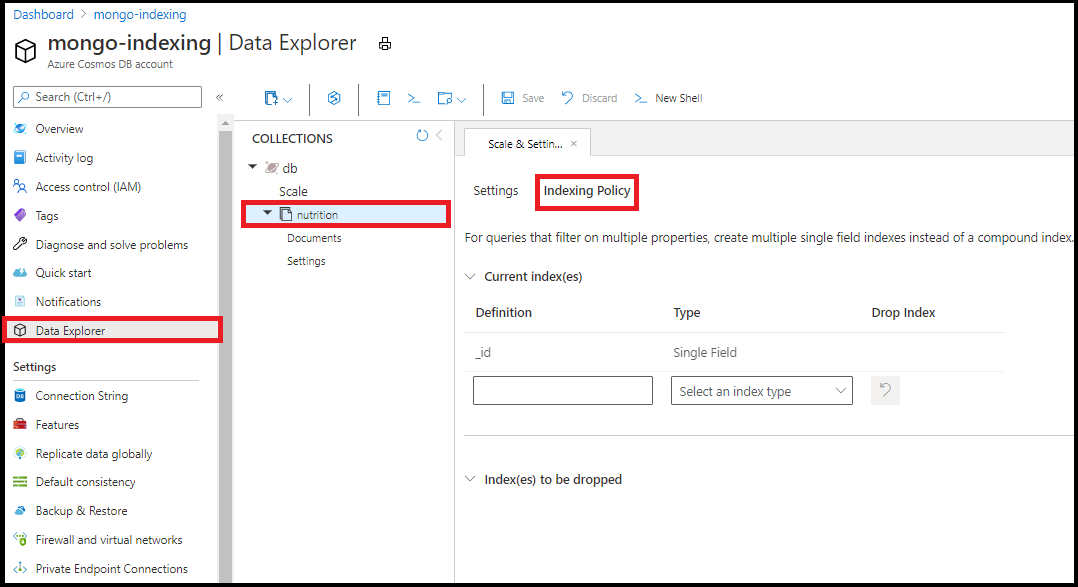
Indexeringsbeleid bewerken
U wordt aangeraden uw indexeringsbeleid te bewerken in Data Explorer in Azure Portal. U kunt enkele veld- en jokertekenindexen toevoegen vanuit de indexeringsbeleidseditor in Data Explorer:
Notitie
U kunt geen samengestelde indexen maken met behulp van de indexeringsbeleidseditor in Data Explorer.
Indextypen
Eén veld
U kunt indexen maken voor elk veld. De sorteervolgorde van de index voor één veld maakt niet uit. Met de volgende opdracht maakt u een index voor het veld name:
db.coll.createIndex({name:1})
U kunt dezelfde index name voor één veld maken in Azure Portal:
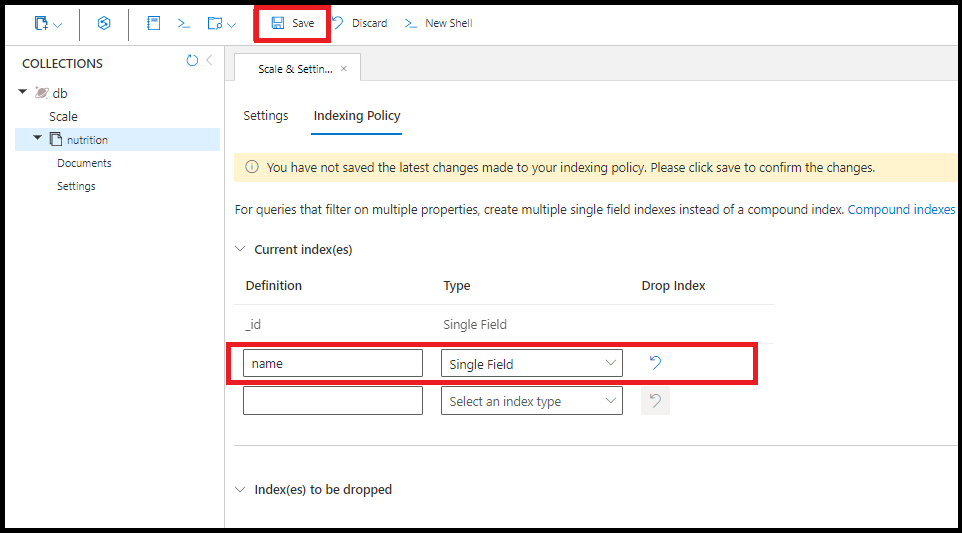
Eén query maakt gebruik van meerdere indexen voor één veld, indien beschikbaar. U kunt maximaal 500 indexen voor één veld per verzameling maken.
Samengestelde indexen (MongoDB-server versie 3.6+)
In de API voor MongoDB zijn samengestelde indexen vereist als uw query meerdere velden tegelijk kan sorteren. Voor query's met meerdere filters die niet hoeven te worden gesorteerd, maakt u meerdere indexen voor één veld in plaats van een samengestelde index om te besparen op indexeringskosten.
Een samengestelde index of indexen van één veld voor elk veld in de samengestelde index resulteert in dezelfde prestaties voor het filteren in query's.
Samengestelde indexen op geneste velden worden niet standaard ondersteund vanwege beperkingen met matrices. Als uw geneste veld geen array bevat, werkt de index zoals bedoeld. Als uw geneste veld ergens op het pad een array bevat, wordt die waarde genegeerd in de index.
Een samengestelde index met people.dylan.age werkt in dit geval omdat er geen matrix op het pad staat:
{
"people": {
"dylan": {
"name": "Dylan",
"age": "25"
},
"reed": {
"name": "Reed",
"age": "30"
}
}
}
Deze samengestelde index werkt in dit geval niet omdat er een matrix in het pad staat:
{
"people": [
{
"name": "Dylan",
"age": "25"
},
{
"name": "Reed",
"age": "30"
}
]
}
Deze functie kan worden ingeschakeld voor uw databaseaccount door de functie 'EnableUniqueCompoundNestedDocs' in te schakelen.
Notitie
U kunt geen samengestelde indexen maken voor matrices.
Met de volgende opdracht maakt u een samengestelde index voor de velden name en age:
db.coll.createIndex({name:1,age:1})
U kunt samengestelde indexen gebruiken om efficiënt te sorteren op meerdere velden tegelijk, zoals wordt weergegeven in het volgende voorbeeld:
db.coll.find().sort({name:1,age:1})
U kunt de voorgaande samengestelde index ook gebruiken om efficiënt te sorteren op een query met de tegenovergestelde sorteervolgorde voor alle velden. Hier volgt een voorbeeld:
db.coll.find().sort({name:-1,age:-1})
De volgorde van de paden in de samengestelde index moet echter exact overeenkomen met de query. Hier volgt een voorbeeld van een query waarvoor een extra samengestelde index is vereist:
db.coll.find().sort({age:1,name:1})
Indexen met meerdere sleutels
Azure Cosmos DB maakt indexen met meerdere sleutels om inhoud te indexeren die is opgeslagen in matrices. Als u een veld indexeert met een matrixwaarde, indexeert Azure Cosmos DB automatisch elk element in de matrix.
Georuimtelijke indexen
Veel georuimtelijke operators profiteren van georuimtelijke indexen. Momenteel ondersteunt Azure Cosmos DB voor MongoDB 2dsphere indexen. De API biedt nog geen ondersteuning voor 2d indexen.
Hier volgt een voorbeeld van het maken van een georuimtelijke index in het location veld:
db.coll.createIndex({ location : "2dsphere" })
Tekstindexen
Azure Cosmos DB voor MongoDB biedt momenteel geen ondersteuning voor tekstindexen. Voor zoekquery's voor tekst in tekenreeksen moet u Azure AI Search-integratie gebruiken met Azure Cosmos DB.
Wildcard-indexen
U kunt jokertekenindexen gebruiken om query's op onbekende velden te ondersteunen. Stel dat u een verzameling hebt die gegevens over gezinnen bevat.
Dit is een onderdeel van een voorbeelddocument in die verzameling:
"children": [
{
"firstName": "Henriette Thaulow",
"grade": "5"
}
]
Hier volgt nog een voorbeeld, deze keer met een iets andere set eigenschappen in children:
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"pets": [
{ "givenName": "Goofy" },
{ "givenName": "Shadow" }
]
},
{
"familyName": "Merriam",
"givenName": "John",
}
]
In deze verzameling kunnen documenten veel verschillende eigenschappen hebben. Als u alle gegevens in de children matrix wilt indexeren, hebt u twee opties: afzonderlijke indexen maken voor elke afzonderlijke eigenschap of één jokertekenindex maken voor de hele children matrix.
Een jokertekenindex maken
Met de volgende opdracht maakt u een jokertekenindex voor alle eigenschappen binnen children:
db.coll.createIndex({"children.$**" : 1})
In tegenstelling tot in MongoDB kunnen jokertekenindexen meerdere velden in querypredicaten ondersteunen. Er is geen verschil in queryprestaties als u één jokertekenindex gebruikt in plaats van een afzonderlijke index te maken voor elke eigenschap.
U kunt de volgende indextypen maken met behulp van jokertekensyntaxis:
- Eén veld
- Ruimtelijke gegevens
Alle eigenschappen indexeren
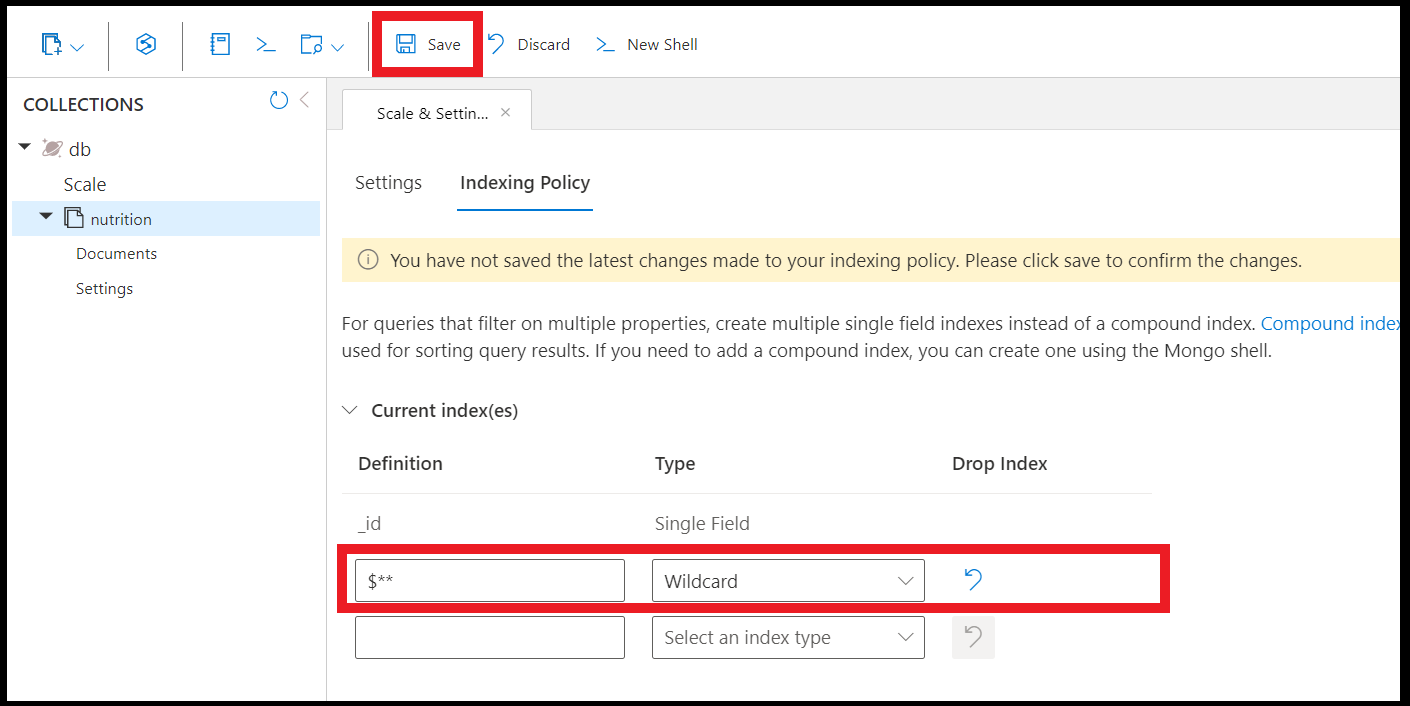
U kunt als volgt een jokertekenindex maken voor alle velden:
db.coll.createIndex( { "$**" : 1 } )
U kunt ook jokertekenindexen maken met behulp van Data Explorer in Azure Portal:
Notitie
Als u net begint met ontwikkelen, raden we u ten zeerste aan om te beginnen met een wildcard index voor alle velden. Dit vereenvoudigt de ontwikkeling en maakt het eenvoudiger om query's te optimaliseren.
Documenten met veel velden hebben mogelijk een hoge ru-kosten (Request Unit) voor schrijfbewerkingen en updates. Als u een workload met veel schrijfbewerkingen hebt, moet u ervoor kiezen om afzonderlijke paden te indexeren in plaats van wildcard-indexen te gebruiken.
Beperkingen
Jokertekenindexen bieden geen ondersteuning voor een van de volgende indextypen of eigenschappen:
- Combinatie
- TTL
- Uniek
In tegenstelling tot in MongoDB kunt u in Azure Cosmos DB voor MongoDB geen jokertekenindexen gebruiken voor:
Een wildcard-index maken inclusief meerdere specifieke velden
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection " : { "children.givenName" : 1, "children.grade" : 1 } } )Een wildcard-index maken die meerdere specifieke velden uitsluit
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection" : { "children.givenName" : 0, "children.grade" : 0 } } )
Als alternatief kunt u meerdere jokertekenindexen maken.
Indexeigenschappen
De volgende bewerkingen zijn gebruikelijk voor accounts die wire protocol versie 4.0 en accounts leveren die eerdere versies leveren. Meer informatie over ondersteunde indexen en geïndexeerde eigenschappen.
Unieke indexen
Unieke indexen zijn handig om af te dwingen dat twee of meer documenten niet dezelfde waarde bevatten voor geïndexeerde velden.
Met de volgende opdracht maakt u een unieke index voor het veld student_id:
globaldb:PRIMARY> db.coll.createIndex( { "student_id" : 1 }, {unique:true} )
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 4
}
Voor shard-verzamelingen moet u de shardsleutel (partitiesleutel) opgeven om een unieke index te maken. Met andere woorden, alle unieke indexen op een shardverzameling zijn samengestelde indexen waarbij een van de velden de shardsleutel is. Het eerste veld in de volgorde moet de shardsleutel zijn.
Met de volgende opdrachten maakt u een shard-verzameling coll (de shardsleutel is university) met een unieke index op de velden student_id en university:
globaldb:PRIMARY> db.runCommand({shardCollection: db.coll._fullName, key: { university: "hashed"}});
{
"_t" : "ShardCollectionResponse",
"ok" : 1,
"collectionsharded" : "test.coll"
}
globaldb:PRIMARY> db.coll.createIndex( { "university" : 1, "student_id" : 1 }, {unique:true});
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 3,
"numIndexesAfter" : 4
}
In het voorgaande voorbeeld retourneert het weglaten van de "university":1 component een fout met het volgende bericht:
cannot create unique index over {student_id : 1.0} with shard key pattern { university : 1.0 }
Beperkingen
Er moeten unieke indexen worden gemaakt terwijl de verzameling leeg is.
Unieke indexen voor geneste velden worden niet standaard ondersteund vanwege beperkingen met matrices. Als uw geneste veld geen matrix bevat, werkt de index zoals bedoeld. Als uw geneste veld een matrix bevat (ergens in het pad), wordt die waarde genegeerd in de unieke index en blijft de uniekheid voor die waarde niet behouden.
Een unieke index voor people.tom.age werkt in dit geval omdat er geen matrix op het pad staat:
{ "people": { "tom": { "age": "25" }, "mark": { "age": "30" } } }
maar werkt niet in dit geval omdat er een matrix in het pad staat:
{ "people": { "tom": [ { "age": "25" } ], "mark": [ { "age": "30" } ] } }
Deze functie kan worden ingeschakeld voor uw databaseaccount door de functie 'EnableUniqueCompoundNestedDocs' in te schakelen.
TTL indexen
Als u het verlopen van documenten in een bepaalde verzameling wilt inschakelen, moet u een TTL-index (Time-to-Live) maken. Een TTL-index is een index in het _ts veld met een expireAfterSeconds waarde.
Voorbeeld:
globaldb:PRIMARY> db.coll.createIndex({"_ts":1}, {expireAfterSeconds: 10})
Met de voorgaande opdracht worden alle documenten in de db.coll verzameling verwijderd die de afgelopen tien seconden niet zijn gewijzigd.
Notitie
Het veld _ts is specifiek voor Azure Cosmos DB en is niet toegankelijk vanaf MongoDB-clients. Het is een gereserveerde eigenschap (systeem) die het tijdstempel van de laatste wijziging van het document bevat.
Voortgang van index bijhouden
Versie 3.6+ van Azure Cosmos DB voor MongoDB ondersteunt de currentOp() opdracht om de voortgang van de index op een database-exemplaar bij te houden. Met deze opdracht wordt een document geretourneerd dat informatie bevat over actieve bewerkingen op een database-exemplaar. U gebruikt de currentOp opdracht om alle actieve bewerkingen in systeemeigen MongoDB bij te houden. In Azure Cosmos DB voor MongoDB ondersteunt deze opdracht alleen het bijhouden van de indexbewerking.
Hier volgen enkele voorbeelden die laten zien hoe u de opdracht gebruikt om de voortgang van de currentOp index bij te houden:
De voortgang van de index voor een verzameling ophalen:
db.currentOp({"command.createIndexes": <collectionName>, "command.$db": <databaseName>})De voortgang van de index voor alle verzamelingen in een database ophalen:
db.currentOp({"command.$db": <databaseName>})De voortgang van de index ophalen voor alle databases en verzamelingen in een Azure Cosmos DB-account:
db.currentOp({"command.createIndexes": { $exists : true } })
Voorbeelden van uitvoer van indexvoortgang
De voortgangsdetails van de index geven het voortgangspercentage voor de huidige indexbewerking weer. Hier volgt een voorbeeld van de indeling van het uitvoerdocument voor verschillende fasen van de indexvoortgang:
Een indexbewerking voor een 'foo'-verzameling en 'staafdatabase' die 60 procent voltooid is, heeft het volgende uitvoerdocument. In
Inprog[0].progress.totalhet veld wordt 100 weergegeven als het voltooiingspercentage van het doel.{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 60 %", "progress" : { "done" : 60, "total" : 100 }, …………..….. } ], "ok" : 1 }Als een indexbewerking zojuist is gestart op een 'foo'-verzameling en 'staaf'-database, kan het uitvoerdocument 0 procent voortgang weergeven totdat het een meetbaar niveau bereikt.
{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 0 %", "progress" : { "done" : 0, "total" : 100 }, …………..….. } ], "ok" : 1 }Wanneer de indexbewerking wordt voltooid, worden in het uitvoerdocument lege
inprogbewerkingen weergegeven.{ "inprog" : [], "ok" : 1 }
Updates van achtergrondindex
Ongeacht de waarde die is opgegeven voor de eigenschap Achtergrondindex , worden indexupdates altijd op de achtergrond uitgevoerd. Omdat indexupdates aanvraageenheden (RU's) verbruiken met een lagere prioriteit dan andere databasebewerkingen, leiden indexwijzigingen niet tot downtime voor schrijfbewerkingen, updates of verwijderingen.
Er is geen invloed op de leesbeschikbaarheid wanneer een nieuwe index wordt toegevoegd. Query's maken alleen gebruik van nieuwe indexen zodra de indextransformatie is voltooid. Tijdens de indextransformatie blijft de query-engine bestaande indexen gebruiken, zodat u vergelijkbare leesprestaties ziet tijdens de indexeringstransformatie naar wat u hebt waargenomen voordat u de indexeringswijziging initieert. Bij het toevoegen van nieuwe indexen is er ook geen risico op onvolledige of inconsistente queryresultaten.
Wanneer u indexen verwijdert en direct query's uitvoert met filters voor de verwijderde indexen, kunnen de resultaten inconsistent en onvolledig zijn totdat de indextransformatie is voltooid. Als u indexen verwijdert, biedt de query-engine geen consistente of volledige resultaten wanneer query's filteren op deze zojuist verwijderde indexen. De meeste ontwikkelaars verwijderen geen indexen en proberen ze vervolgens onmiddellijk op te vragen, dus in de praktijk is dit onwaarschijnlijk.
Notitie
U kunt de voortgang van de index bijhouden.
Opdracht ReIndex
Met de reIndex opdracht worden alle indexen voor een verzameling opnieuw gemaakt. In sommige zeldzame gevallen kunnen queryprestaties of andere indexproblemen in uw verzameling worden opgelost door de opdracht uit te reIndex voeren. Als u problemen ondervindt met indexeren, is het opnieuw maken van de indexen met de reIndex opdracht een aanbevolen benadering.
U kunt de reIndex opdracht uitvoeren met behulp van de volgende syntaxis:
db.runCommand({ reIndex: <collection> })
U kunt de onderstaande syntaxis gebruiken om te controleren of het uitvoeren van de opdracht de reIndex queryprestaties in uw verzameling verbetert:
db.runCommand({"customAction":"GetCollection",collection:<collection>, showIndexes:true})
Voorbeelduitvoer:
{
"database" : "myDB",
"collection" : "myCollection",
"provisionedThroughput" : 400,
"indexes" : [
{
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
},
{
"v" : 1,
"key" : {
"b.$**" : 1
},
"name" : "b.$**_1",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
}
],
"ok" : 1
}
reIndex zal de queryprestaties verbeteren als requiresReIndex waar is. Als reIndex de queryprestaties niet worden verbeterd, wordt deze eigenschap weggelaten.
Verzamelingen migreren met indexen
Op dit moment kunt u alleen unieke indexen maken wanneer de verzameling geen documenten bevat. Populaire MongoDB-migratiehulpprogramma's proberen de unieke indexen te maken na het importeren van de gegevens. Om dit probleem te omzeilen, kunt u handmatig de bijbehorende collecties en unieke indexen maken in plaats van de migratietool toe te staan. (U kunt dit gedrag voor mongorestore verkrijgen met behulp van de --noIndexRestore parameter op de commandoregel.)
Indexering voor MongoDB versie 3.2
Beschikbare indexeringsfuncties en standaardinstellingen verschillen voor Azure Cosmos DB-accounts die compatibel zijn met versie 3.2 van het MongoDB-wire-protocol. U kunt de versie van uw account controleren en upgraden naar versie 3.6.
Als u versie 3.2 gebruikt, worden in deze sectie belangrijke verschillen beschreven met versie 3.6+.
Standaardindexen verwijderen (versie 3.2)
In tegenstelling tot de 3.6+ versies van Azure Cosmos DB voor MongoDB indexeert versie 3.2 standaard elke eigenschap. U kunt de volgende opdracht gebruiken om deze standaardindexen voor een verzameling () te verwijderen:coll
> db.coll.dropIndexes()
{ "_t" : "DropIndexesResponse", "ok" : 1, "nIndexesWas" : 3 }
Nadat u de standaardindexen hebt verwijderd, kunt u meer indexen toevoegen zoals in versie 3.6+.
Samengestelde indexen (versie 3.2)
Samengestelde indexen bevatten verwijzingen naar meerdere velden van een document. Als u een samengestelde index wilt maken, voert u een upgrade uit naar versie 3.6 of 4.0.
Wildcard-indexen (versie 3.2)
Als u een jokertekenindex wilt maken, voert u een upgrade uit naar versie 4.0 of 3.6.
Volgende stappen
- Indexering in Azure Cosmos DB
- Gegevens in Azure Cosmos DB automatisch laten verlopen met tijd om te leven (TTL)
- Voor meer informatie over de relatie tussen partitionering en indexering, raadpleegt u hoe u een query uitvoert op een Azure Cosmos DB-containerartikel .
- Wilt u capaciteitsplanning uitvoeren voor een migratie naar Azure Cosmos DB? U kunt informatie over uw bestaande databasecluster gebruiken voor capaciteitsplanning.
- Als alles wat u weet het aantal vCores en servers in uw bestaande databasecluster is, leest u meer over het schatten van aanvraageenheden met behulp van vCores of vCPU's
- Als u typische aanvraagtarieven voor uw huidige databaseworkload kent, leest u meer over het schatten van aanvraageenheden met behulp van azure Cosmos DB-capaciteitsplanner