Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In het snel veranderende gebied van generatieve AI hebben grote taalmodellen (LLM's) zoals GPT-3.5 natuurlijke taalverwerking getransformeerd. Een opkomende trend in AI is echter het gebruik van vectorarchieven, die een belangrijke rol spelen bij het verbeteren van AI-toepassingen.
In deze zelfstudie leert u hoe u Azure Cosmos DB voor MongoDB (vCore), LangChain en OpenAI kunt gebruiken om Rag (Retrieval-Augmented Generation) te implementeren voor superieure AI-prestaties, naast het bespreken van LLM's en hun beperkingen. We verkennen het snel aangenomen paradigma van "ophalen-geaugmenteerde generatie" (RAG) en bespreken kort het LangChain framework, Azure OpenAI-modellen. Ten slotte integreren we deze concepten in een echte toepassing. Aan het einde hebben lezers een solide kennis van deze concepten.
Meer informatie over grote taalmodellen (LLM's) en hun beperkingen
Grote taalmodellen (LLM's) zijn geavanceerde deep neurale netwerkmodellen die zijn getraind op uitgebreide tekstgegevenssets, zodat ze menselijke tekst kunnen begrijpen en genereren. Hoewel dit revolutionaire is in natuurlijke taalverwerking, hebben LLM's inherente beperkingen:
- Halluïnaties: LLM's genereren soms feitelijk onjuiste of niet-geaarde informatie, ook wel halluïnaties genoemd.
- Verouderde gegevens: LLM's worden getraind op statische gegevenssets die mogelijk niet de meest recente informatie bevatten, waardoor hun huidige relevantie wordt beperkt.
- Geen toegang tot lokale gegevens van de gebruiker: LLM's hebben geen directe toegang tot persoonlijke of gelokaliseerde gegevens, waardoor ze geen persoonlijke antwoorden kunnen geven.
- Tokenlimieten: LLM's hebben een maximale tokenlimiet per interactie, waardoor de hoeveelheid tekst wordt beperkt die ze tegelijk kunnen verwerken. De gpt-3.5-turbo van OpenAI heeft bijvoorbeeld een tokenlimiet van 4096.
RAG (Retrieval-Augmented Generation) inzetten
Rag (Retrieval-augmented generation) is een architectuur die is ontworpen om LLM-beperkingen te overwinnen. RAG maakt gebruik van vectorzoekopdrachten om relevante documenten op te halen op basis van een invoerquery, zodat deze documenten als context worden verstrekt aan de LLM voor het genereren van nauwkeurigere antwoorden. In plaats van alleen te vertrouwen op vooraf getrainde patronen, verbetert RAG antwoorden door actuele, relevante informatie op te nemen. Deze aanpak helpt bij het volgende:
- Minimaliseer hallucinaties: Antwoorden baseren op feitelijke informatie.
- Zorg voor huidige informatie: de meest recente gegevens ophalen om ervoor te zorgen dat er up-to-date antwoorden worden ontvangen.
- Externe databases gebruiken: Hoewel hiermee geen directe toegang tot persoonlijke gegevens wordt verleend, staat RAG integratie met externe, gebruikersspecifieke knowledge bases toe.
- Tokengebruik optimaliseren: Door te focussen op de meest relevante documenten, maakt RAG tokengebruik efficiënter.
In deze zelfstudie ziet u hoe RAG kan worden geïmplementeerd met behulp van Azure Cosmos DB voor MongoDB (vCore) om een vraag-antwoordtoepassing te bouwen die is afgestemd op uw gegevens.
Overzicht van toepassingsarchitectuur
In het onderstaande architectuurdiagram ziet u de belangrijkste onderdelen van onze RAG-implementatie:
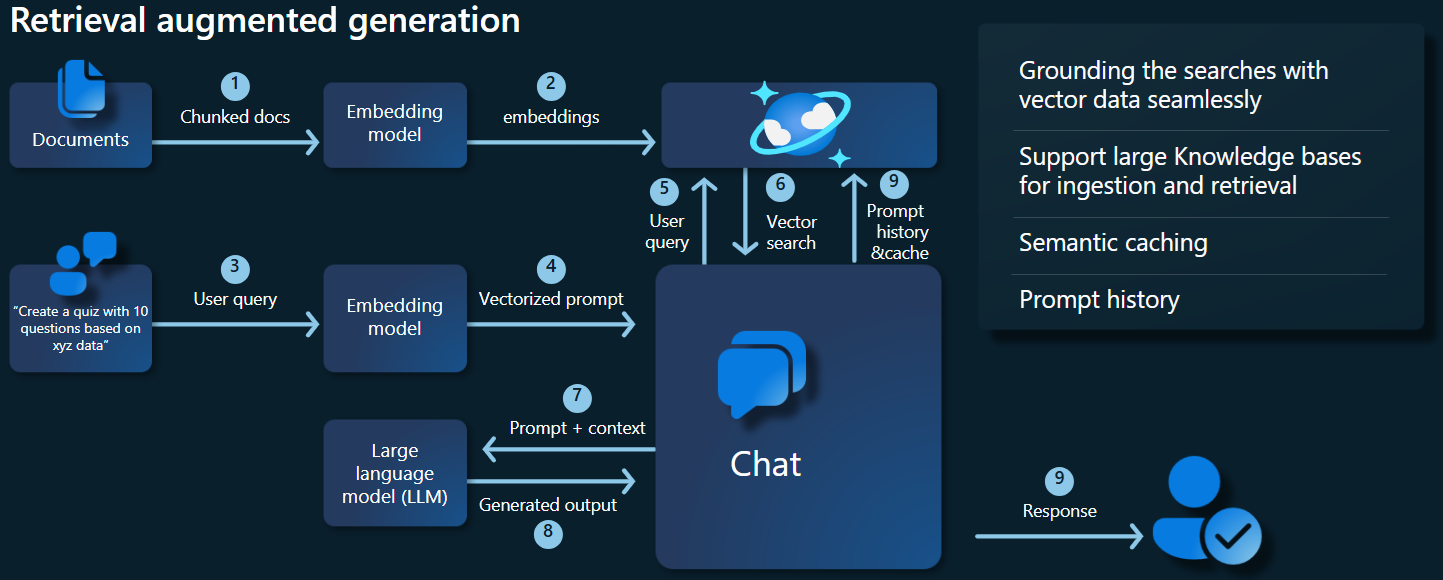
Belangrijke onderdelen en frameworks
We bespreken nu de verschillende frameworks, modellen en onderdelen die in deze zelfstudie worden gebruikt, waarbij hun rollen en nuances worden benadrukt.
Azure Cosmos DB voor MongoDB (vCore)
Azure Cosmos DB voor MongoDB (vCore) ondersteunt semantische overeenkomsten, essentieel voor ai-toepassingen. Hiermee kunnen gegevens in verschillende indelingen worden weergegeven als vector-insluitingen, die naast brongegevens en metagegevens kunnen worden opgeslagen. Met behulp van een bij benadering dichtstbijzijnde buren-algoritme, zoals hiërarchische bevaarbare kleine wereld (HNSW), kunnen deze insluitingen worden opgevraagd voor snelle semantische overeenkomsten.
LangChain framework
LangChain vereenvoudigt het maken van LLM-toepassingen door een standaardinterface te bieden voor ketens, meerdere hulpprogramma-integraties en end-to-end ketens voor algemene taken. Hiermee kunnen AI-ontwikkelaars LLM-toepassingen bouwen die gebruikmaken van externe gegevensbronnen.
Belangrijkste aspecten van LangChain:
- Ketens: Reeksen onderdelen die specifieke taken oplossen.
- Onderdelen: Modules zoals LLM-wrappers, vectoropslagwikkelaars, promptsjablonen, gegevenslazers, tekstsplitsers en retrievers.
- Modulariteit: vereenvoudigt ontwikkeling, foutopsporing en onderhoud.
- Populariteit: Een opensource-project krijgt snel acceptatie en ontwikkelt zich om te voldoen aan de behoeften van gebruikers.
Azure-app Services-interface
App-services bieden een robuust platform voor het bouwen van gebruiksvriendelijke webinterfaces voor Gen-AI-toepassingen. In deze zelfstudie wordt gebruikgemaakt van Azure-app-services om een interactieve webinterface voor de toepassing te maken.
OpenAI-modellen
OpenAI is een leider in AI-onderzoek en biedt verschillende modellen voor het genereren van talen, tekstvectorisatie, het maken van afbeeldingen en conversie van audio-naar-tekst. Voor deze zelfstudie gebruiken we de insluitings- en taalmodellen van OpenAI, die cruciaal zijn voor het begrijpen en genereren van op taal gebaseerde toepassingen.
Modellen insluiten versus modellen voor het genereren van talen
| Categorie | Model voor insluiten van tekst | Taalmodel |
|---|---|---|
| Doel | Tekst converteren naar vector insluitingen. | Natuurlijke taal begrijpen en genereren. |
| Functie | Transformeert tekstgegevens in hoogdimensionale matrices van getallen, waarbij de semantische betekenis van de tekst wordt vastgelegd. | Begrijpt en produceert menselijke tekst op basis van opgegeven invoer. |
| Uitvoer | Matrix van getallen (vector embeddings). | Tekst, antwoorden, vertalingen, code, enzovoort. |
| Voorbeelduitvoer | Elke insluiting vertegenwoordigt de semantische betekenis van de tekst in numerieke vorm, met een dimensionaliteit die wordt bepaald door het model. Genereert bijvoorbeeld text-embedding-ada-002 vectoren met 1536 dimensies. |
Contextafhankelijk relevante en coherente tekst gegenereerd op basis van de opgegeven invoer. U kunt bijvoorbeeld gpt-3.5-turbo antwoorden genereren op vragen, tekst vertalen, code schrijven en meer. |
| Typische gebruiksvoorbeelden | - Semantisch zoeken | - Chatbots |
| - Aanbevelingssystemen | - Geautomatiseerd maken van inhoud | |
| - Clustering en classificatie van tekstgegevens | - Taalomzetting | |
| - Ophalen van gegevens | - Samenvatting | |
| Gegevensweergave | Numerieke weergave (insluitingen) | Tekst in natuurlijke taal |
| Dimensionaliteit | De lengte van de matrix komt overeen met het aantal dimensies in de insluitruimte, bijvoorbeeld 1536 dimensies. | Meestal weergegeven als een reeks tokens, met de context die de lengte bepaalt. |
Belangrijkste onderdelen van de toepassing
- Azure Cosmos DB voor MongoDB vCore: Vector embeddings opslaan en er query's op uitvoeren.
-
LangChain: de LLM-werkstroom van de toepassing maken. Maakt gebruik van hulpprogramma's zoals:
- Documentlaadprogramma: Voor het laden en verwerken van documenten uit een map.
- Vector Store-integratie: voor het opslaan en opvragen van vector-insluitingen in Azure Cosmos DB.
- AzureCosmosDBVectorSearch: Omhulsel voor Cosmos DB-vectorzoekopdracht
- Azure-app Services: de gebruikersinterface bouwen voor de Kosmische Voedsel-app.
-
Azure OpenAI: voor het leveren van LLM- en insluitmodellen, waaronder:
- text-embedding-ada-002: Een model voor het insluiten van tekst dat tekst converteert naar vector-insluitingen met 1536 dimensies.
- gpt-3.5-turbo: een taalmodel voor het begrijpen en genereren van natuurlijke taal.
De omgeving instellen
Volg deze stappen om retrieval-augmented generation (RAG) te optimaliseren met behulp van Azure Cosmos DB voor MongoDB (vCore):
-
Maak de volgende resources in Microsoft Azure:
- Azure Cosmos DB voor MongoDB vCore-cluster: zie de snelstartgids hier.
-
Azure OpenAI-resource met:
-
Modelimplementatie insluiten (bijvoorbeeld
text-embedding-ada-002). -
Implementatie van chatmodel (bijvoorbeeld
gpt-35-turbo).
-
Modelimplementatie insluiten (bijvoorbeeld
Voorbeelddocumenten
In deze tutorial wordt één tekstbestand geladen met Document. Deze bestanden moeten worden opgeslagen in een map met de naam gegevens in de src-map. De inhoud is als volgt:
food_items.json
{
"category": "Cold Dishes",
"name": "Hamachi Fig",
"description": "Hamachi sashimi lightly tossed in a fig sauce with rum raisins, and serrano peppers then topped with fried lotus root.",
"price": "16.0 USD"
},
Documenten laden
Stel de verbindingsreeks, databasenaam, verzamelingsnaam en index in voor Cosmos DB voor MongoDB (vCore):
mongo_client = MongoClient(mongo_connection_string) database_name = "Contoso" db = mongo_client[database_name] collection_name = "ContosoCollection" index_name = "ContosoIndex" collection = db[collection_name]Initialiseer de insluitclient.
from langchain_openai import AzureOpenAIEmbeddings openai_embeddings_model = os.getenv("AZURE_OPENAI_EMBEDDINGS_MODEL_NAME", "text-embedding-ada-002") openai_embeddings_deployment = os.getenv("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME", "text-embedding") azure_openai_embeddings: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings( model=openai_embeddings_model, azure_deployment=openai_embeddings_deployment, )Maak embeddings van de gegevens, sla deze op in de database en retourneer een verbinding naar uw vectoropslag: Cosmos DB voor MongoDB (vCore).
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_documents( json_data, azure_openai_embeddings, collection=collection, index_name=index_name, )Maak de volgende HNSW-vectorindex voor de verzameling (Let op: de naam van de index is hetzelfde als hierboven).
num_lists = 100 dimensions = 1536 similarity_algorithm = CosmosDBSimilarityType.COS kind = CosmosDBVectorSearchType.VECTOR_HNSW m = 16 ef_construction = 64 vector_store.create_index( num_lists, dimensions, similarity_algorithm, kind, m, ef_construction )
Vectorzoekopdrachten uitvoeren met Cosmos DB voor MongoDB (vCore)
Maak verbinding met uw vectorarchief.
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_connection_string( connection_string=mongo_connection_string, namespace=f"{database_name}.{collection_name}", embedding=azure_openai_embeddings, )Definieer een functie waarmee semantische overeenkomsten worden gezocht met Cosmos DB Vector Search op een query (let op: dit codefragment is slechts een testfunctie).
query = "beef dishes" docs = vector_store.similarity_search(query) print(docs[0].page_content)Initialiseer de Chat-client om een RAG-functie te implementeren.
azure_openai_chat: AzureChatOpenAI = AzureChatOpenAI( model=openai_chat_model, azure_deployment=openai_chat_deployment, )Maak een RAG-functie.
history_prompt = ChatPromptTemplate.from_messages( [ MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ( "user", """Given the above conversation, generate a search query to look up to get information relevant to the conversation""", ), ] ) context_prompt = ChatPromptTemplate.from_messages( [ ("system", "Answer the user's questions based on the below context:\n\n{context}"), MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ] )Converteert het vectorarchief naar een retriever, die kan zoeken naar relevante documenten op basis van opgegeven parameters.
vector_store_retriever = vector_store.as_retriever( search_type=search_type, search_kwargs={"k": limit, "score_threshold": score_threshold} )Maak een retriever-keten die op de hoogte is van de gespreksgeschiedenis, zodat contextueel relevante documenten worden opgehaald met behulp van het azure_openai_chat-model en vector_store_retriever.
retriever_chain = create_history_aware_retriever(azure_openai_chat, vector_store_retriever, history_prompt)Maak een keten waarin opgehaalde documenten worden gecombineerd tot een coherent antwoord met behulp van het taalmodel (azure_openai_chat) en een opgegeven prompt (context_prompt).
context_chain = create_stuff_documents_chain(llm=azure_openai_chat, prompt=context_prompt)Maak een keten die het hele ophaalproces afhandelt, waarbij de geschiedenisbewuste retriever-keten en de combinatieketen van documenten worden geïntegreerd. Deze RAG-keten kan worden uitgevoerd om contextuele nauwkeurige antwoorden op te halen en te genereren.
rag_chain: Runnable = create_retrieval_chain( retriever=retriever_chain, combine_docs_chain=context_chain, )
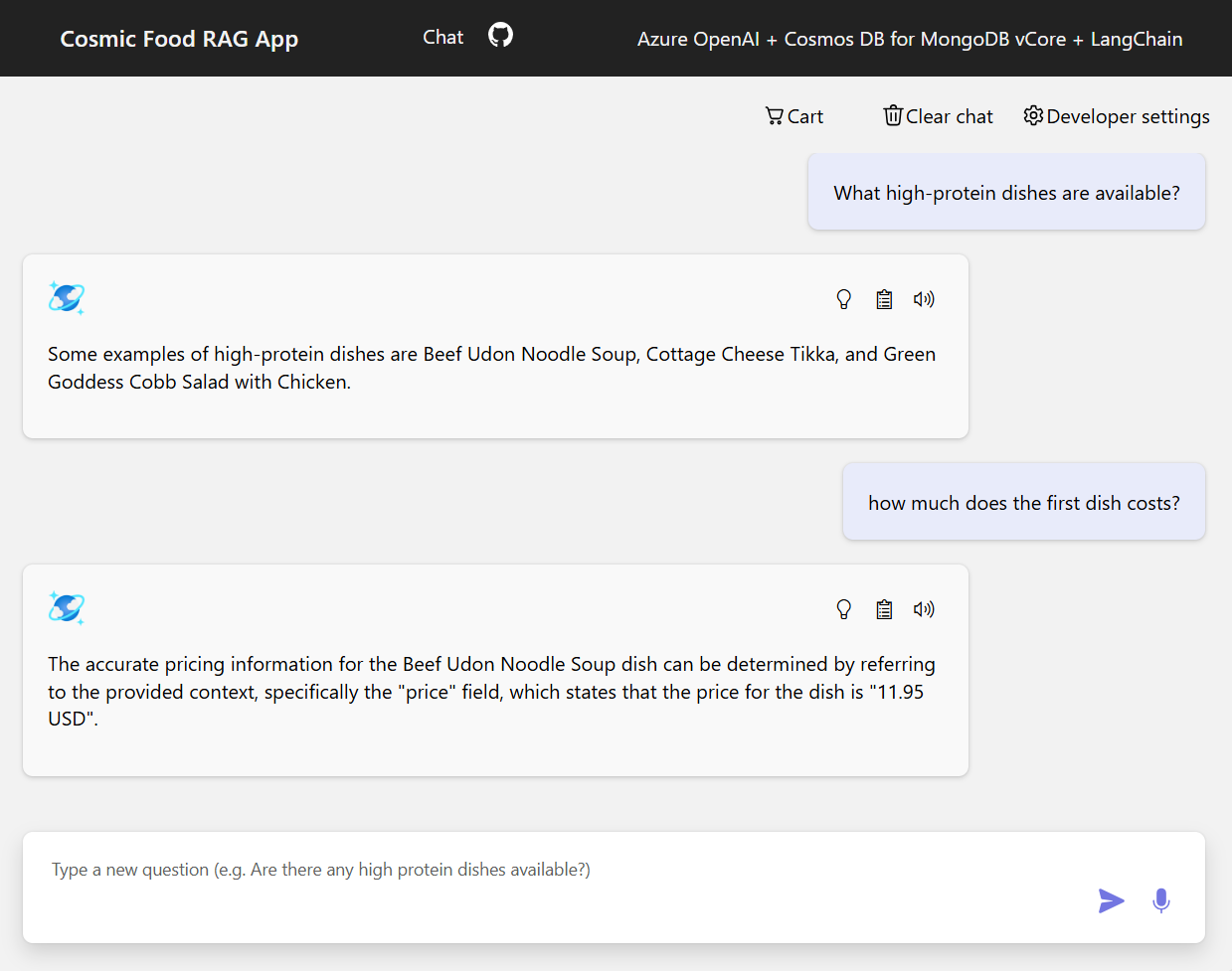
Voorbeelden van uitvoer
In de onderstaande schermopname ziet u de uitvoer voor verschillende vragen. Een puur semantische overeenkomstenzoekopdracht retourneert de onbewerkte tekst uit de brondocumenten, terwijl de vraag-beantwoordende app met behulp van de RAG-architectuur nauwkeurige en gepersonaliseerde antwoorden genereert door opgehaalde documentinhoud te combineren met het taalmodel.
Conclusie
In deze zelfstudie hebben we verkend hoe u een vraag-antwoord-app bouwt die communiceert met uw persoonlijke gegevens met Cosmos DB als vectorarchief. Door gebruik te maken van de rag-architectuur (retrieval-augmented generation) met LangChain en Azure OpenAI, hebben we gedemonstreerd hoe vectorarchieven essentieel zijn voor LLM-toepassingen.
RAG is een aanzienlijke vooruitgang in AI, met name in verwerking van natuurlijke taal, en het combineren van deze technologieën maakt het mogelijk om krachtige AI-gestuurde toepassingen te maken voor verschillende gebruiksvoorbeelden.