Azure Cosmos DB voor NoSQL-prestaties meten met een benchmarking-framework
Er zijn nu meer keuzes voor het type database dat u met uw gegevensworkload kunt gebruiken. Een van de belangrijkste factoren voor het kiezen van een database is de prestaties van de database of service, maar benchmarkingprestaties kunnen omslachtig en foutgevoelig zijn. Het benchmarkingframework voor Azure Databases vereenvoudigt het proces van het meten van prestaties met populaire opensource-benchmarkinghulpprogramma's met recepten met lage wrijving die algemene aanbevolen procedures implementeren. In Azure Cosmos DB for NoSQL implementeert het framework best practices voor de Java SDK en maakt gebruik van het opensource-hulpprogramma YCSB . In deze handleiding gebruikt u dit benchmarkingframework om een leesworkload te implementeren om vertrouwd te raken met het framework.
Vereisten
- Een Azure-account met een actief abonnement. Gratis een account maken
- Azure Cosmos DB for NoSQL-account. Maak een API voor een NoSQL-account.
- Noteer de eindpunt-URI en de primaire sleutel voor het account.
- Azure-opslagaccount. Maak een Azure Storage-account.
- Noteer de verbindingsreeks voor het opslagaccount. Azure Storage-verbindingsreeks.
- Tweede lege resourcegroep. Maak een resourcegroep.
- Azure-opdrachtregelinterface (CLI).
Azure Cosmos DB-accountbronnen maken
Eerst maakt u een database en container in het bestaande API voor NoSQL-account.
Navigeer naar uw bestaande API voor NoSQL-account in Azure Portal.
Selecteer Data Explorer in het resourcemenu.
Selecteer op de pagina Data Explorer de optie Nieuwe container in de opdrachtbalk.

Maak in het dialoogvenster Nieuwe container een nieuwe container met de volgende instellingen:
Instelling Weergegeven als Database-id ycsbType databasedoorvoer Handmatig Hoeveelheid databasedoorvoer 400Container-id usertablePartitiesleutel /id

Benchmarking-framework implementeren in Azure
U gebruikt nu een Azure Resource Manager-sjabloon om het benchmarkingframework in Azure te implementeren met het standaard leesrecept.
Implementeer het benchmarking-framework met behulp van een Azure Resource Manager-sjabloon die beschikbaar is via deze koppeling.
Op de pagina Aangepaste implementatie zijn de volgende parameters
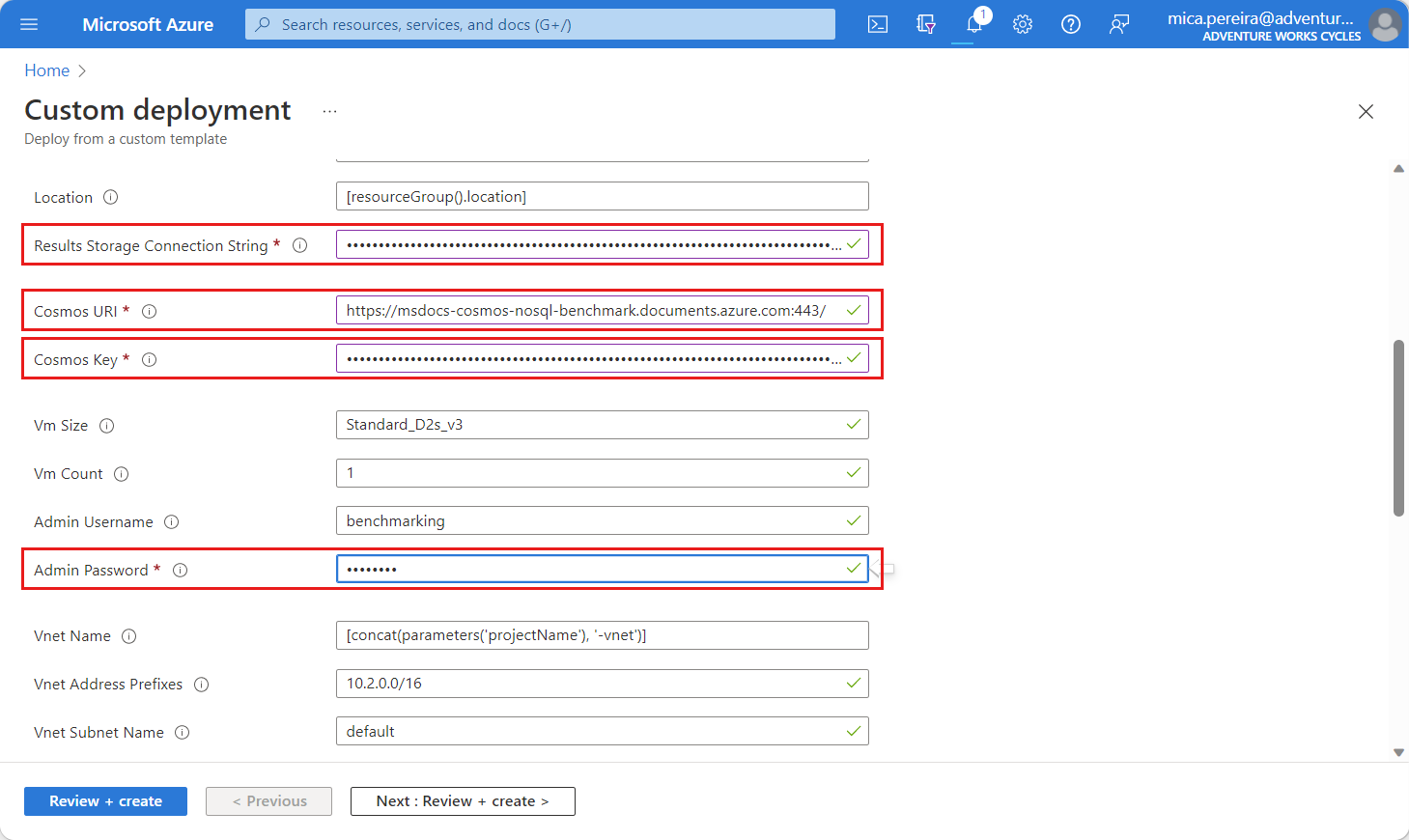
Selecteer Beoordelen en maken en vervolgens Maken om de sjabloon te implementeren.
Wacht totdat de installatie is voltooid.
Tip
Het kan 5-10 minuten duren voordat de implementatie is voltooid.

Resultaten van de benchmark weergeven
U kunt nu het bestaande Azure Storage-account gebruiken om de status van de benchmarktaak te controleren en de geaggregeerde resultaten weer te geven. De status wordt opgeslagen met behulp van een opslagtabel en de resultaten worden samengevoegd in een opslagblob met behulp van de CSV-indeling.
Navigeer naar uw bestaande Azure Storage-account in Azure Portal.
Navigeer naar een opslagtabel met de naam ycsbbenchmarkingmetadata en zoek de entiteit met een partitiesleutel van
ycsb_sql.
Bekijk het
JobStatusveld van de tabelentiteit. In eerste instantie isStartedde status van de taak en bevat deze een tijdstempel in deJobStartTimeeigenschap, maar niet deJobFinishTimeeigenschap.Wacht totdat de taak de status heeft en
Finishedeen tijdstempel bevat in deJobFinishTimeeigenschap.Tip
Het kan ongeveer 20-30 minuten duren voordat de taak is voltooid.
Navigeer naar de opslagcontainer in hetzelfde account met het voorvoegsel ycsbbenchmarking-*. Bekijk de uitvoer- en diagnostische blobs voor het hulpprogramma.

Open de aggregation.csv blob en bekijk de inhoud. U hebt nu een CSV-gegevensset met geaggregeerde resultaten van alle benchmarkclients.

Operation,Count,Throughput,Min(microsecond),Max(microsecond),Avg(microsecond),P9S(microsecond),P99(microsecond) READ,180000,299,706,448255,1079,1159,2867
Recepten
Het benchmarkingframework voor Azure Databases bevat recepten voor het inkapselen van de workloaddefinities die worden doorgegeven aan het onderliggende benchmarkinghulpprogramma voor een '1-Klik'-ervaring. De workloaddefinities zijn ontworpen op basis van de best practices die zijn gepubliceerd door het Azure Cosmos DB-team en het team van het benchmarkinghulpprogramma. De recepten zijn getest en gevalideerd voor consistente resultaten.
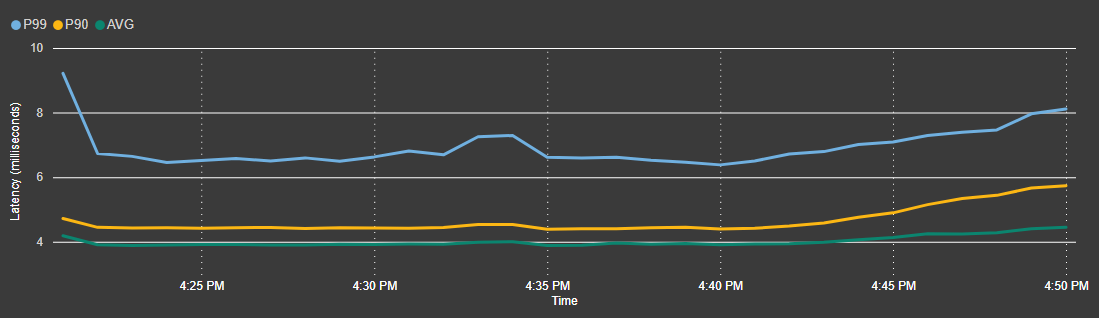
U kunt de volgende latenties verwachten voor alle lees- en schrijfrecepten in de GitHub-opslagplaats.
Leeslatentie

Schrijflatentie


Algemene problemen
Deze sectie bevat de veelvoorkomende fouten die kunnen optreden bij het uitvoeren van het benchmarking-hulpprogramma. De foutenlogboeken voor het hulpprogramma zijn doorgaans beschikbaar in een container binnen het Azure Storage-account.

Als de logboeken niet beschikbaar zijn in het opslagaccount, wordt dit probleem meestal veroorzaakt door een onjuiste of ontbrekende opslag verbindingsreeks. In dit geval wordt deze fout vermeld in het bestand agent.out in de map /home/benchmarking van de virtuele clientmachine.
Error while accessing storage account, exiting from this machine in agent.out on the VMDeze fout wordt vermeld in het bestand agent.out , zowel in de client-VM als het opslagaccount als de Azure Cosmos DB-eindpunt-URI onjuist of onbereikbaar is.
Caused by: java.net.UnknownHostException: rtcosmosdbsss.documents.azure.com: Name or service not knownDeze fout wordt vermeld in het bestand agent.out , zowel in de client-VM als het opslagaccount als de Azure Cosmos DB-sleutel onjuist is.
The input authorization token can't serve the request. The wrong key is being used….
Volgende stappen
- Meer informatie over het benchmarkprogramma met de handleiding Aan de slag.