Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Belangrijk
Azure Cosmos DB for PostgreSQL wordt niet meer ondersteund voor nieuwe projecten. Gebruik deze service niet voor nieuwe projecten. Gebruik in plaats daarvan een van deze twee services:
Gebruik Azure Cosmos DB voor NoSQL voor een gedistribueerde databaseoplossing die is ontworpen voor hoogwaardige schalen scenario's met een 99,999% service level agreement (SLA) voor beschikbaarheid, onmiddellijke autoschaalaanpassing en automatische failover over meerdere regio's.
Gebruik de functie Elastische clusters van Azure Database For PostgreSQL voor sharded PostgreSQL met behulp van de opensource Citus-extensie.
In deze zelfstudie gebruikt u Azure Cosmos DB voor PostgreSQL als de opslagback-end voor meerdere microservices, waarbij u een voorbeeldinstallatie en basisbewerking van een dergelijk cluster demonstreert. Leer hoe u het volgende doet:
- Een cluster maken
- Rollen maken voor uw microservices
- PSQL-hulpprogramma gebruiken om rollen en gedistribueerde schema's te maken
- Tabellen maken voor de voorbeeldservices
- Services configureren
- Services uitvoeren
- De database verkennen
Vereisten
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Een cluster maken
Meld u aan bij Azure Portal en volg deze stappen om een Azure Cosmos DB for PostgreSQL-cluster te maken:
Ga naar Een Azure Cosmos DB for PostgreSQL-cluster maken in de Azure-portal.
In het formulier voor het maken van een Azure Cosmos DB for PostgreSQL-cluster:
Vul de gegevens in op het tabblad Basis.
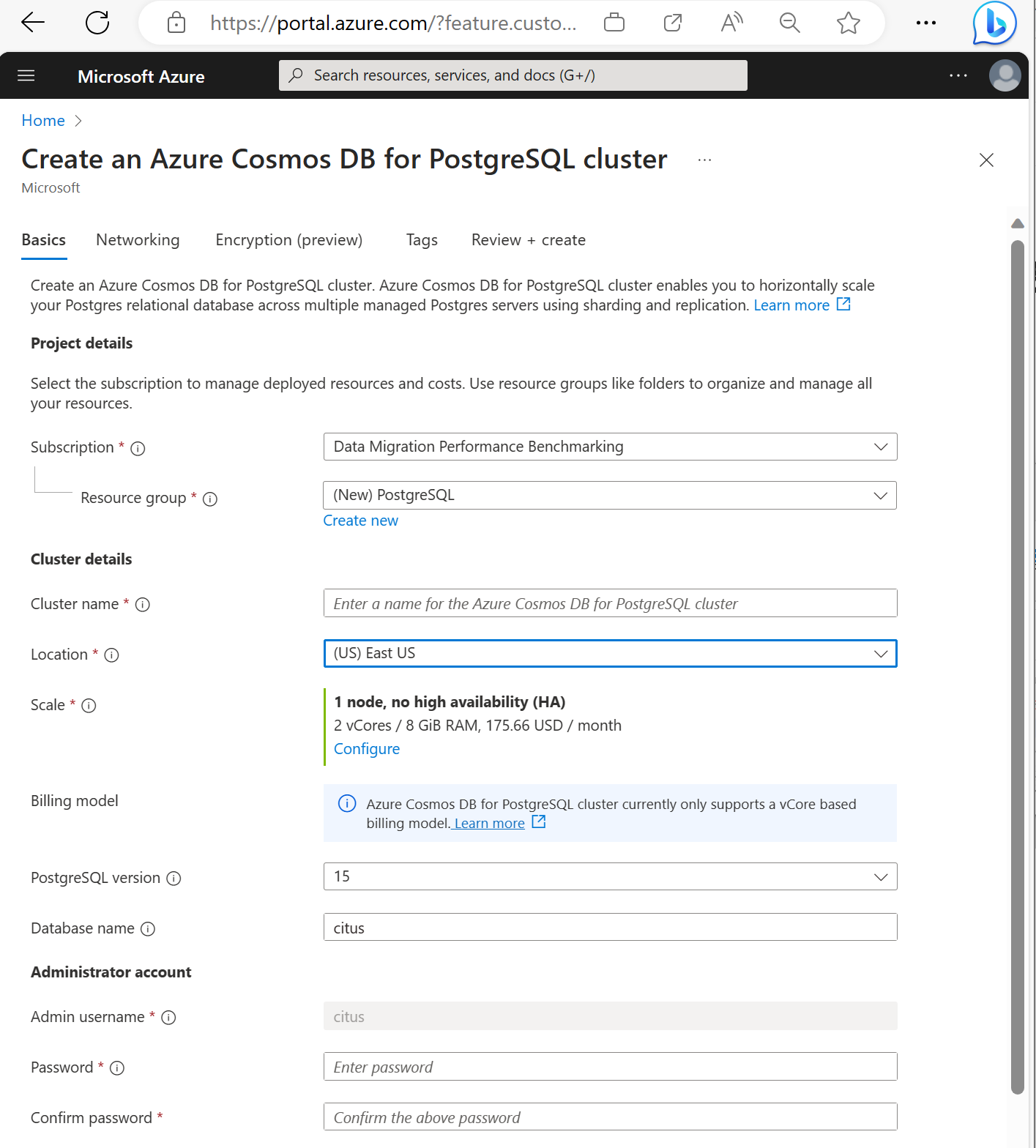
De meeste opties spreken voor zich, maar onthoud:
- De clusternaam bepaalt de DNS-naam die uw toepassingen gebruiken om verbinding te maken, in de vorm
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - U kunt een primaire PostgreSQL-versie, zoals 15, kiezen. Azure Cosmos DB for PostgreSQL ondersteunt altijd de nieuwste Citus-versie voor de geselecteerde primaire Postgres-versie.
- De gebruikersnaam van de beheerder moet de waarde
cituszijn. - U kunt de databasenaam op de standaardwaarde citus laten staan of de enige databasenaam definiëren. U kunt de naam van de database niet wijzigen nadat het cluster is ingericht.
- De clusternaam bepaalt de DNS-naam die uw toepassingen gebruiken om verbinding te maken, in de vorm
Selecteer Volgende: Netwerken onderaan het scherm.
Selecteer in het scherm Netwerken de optie Openbare toegang toestaan vanuit Azure-services en -resources binnen Azure naar dit cluster.
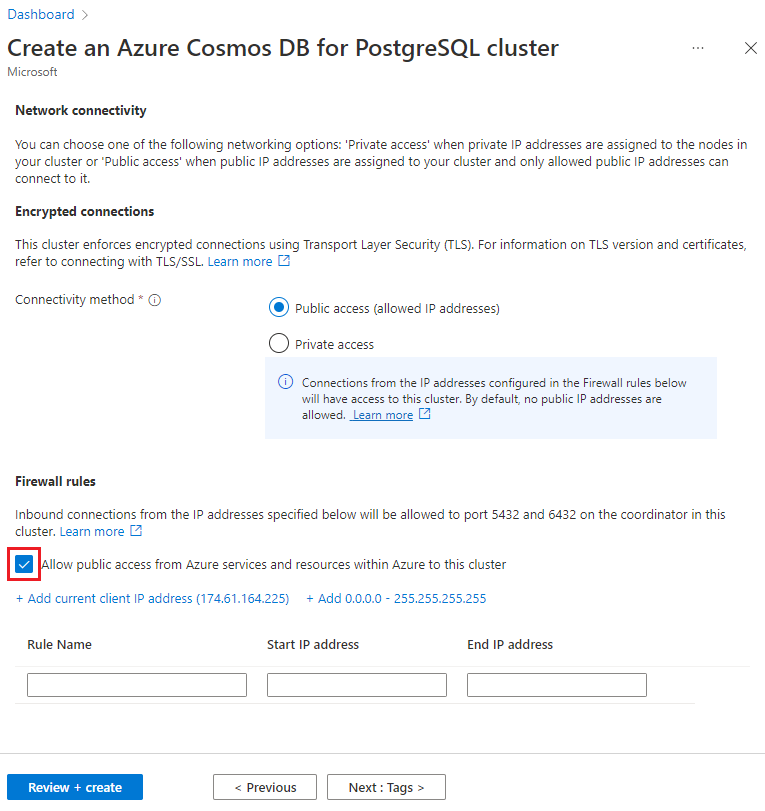
Selecteer Beoordelen en maken en selecteer vervolgens, wanneer de validatie is geslaagd, Maken om het cluster te maken.
Het configureren duurt een paar minuten. De pagina wordt omgeleid om de implementatie te bewaken. Wanneer de status verandert van Implementatie wordt uitgevoerd naar Uw implementatie is voltooid, selecteer dan Naar resource.
Rollen maken voor uw microservices
Gedistribueerde schema's kunnen opnieuw worden verdeeld binnen een Azure Cosmos DB for PostgreSQL-cluster. Het systeem kan ze opnieuw verdelen als een hele eenheid over de beschikbare knooppunten, zodat resources efficiënt kunnen worden gedeeld zonder handmatige toewijzing.
Microservices zijn standaard eigenaar van hun opslaglaag, maar we maken geen veronderstellingen over het type tabellen en gegevens dat ze maken en opslaan. We bieden een schema voor elke service en gaan ervan uit dat ze een afzonderlijke ROL gebruiken om verbinding te maken met de database. Wanneer een gebruiker verbinding maakt, wordt de rolnaam aan het begin van de search_path geplaatst, dus als de rol overeenkomt met de schemanaam die u niet nodig hebt om de juiste search_path in te stellen.
In ons voorbeeld gebruiken we drie services:
- Gebruiker
- tijd
- ping
Volg de stappen voor het maken van gebruikersrollen en het maken van de volgende rollen voor elke service:
userservicetimeservicepingservice
PSQL-hulpprogramma gebruiken om gedistribueerde schema's te maken
Nadat u met behulp van psql verbinding hebt gemaakt met Azure Cosmos DB for PostgreSQL, kunt u enkele basistaken uitvoeren.
Er zijn twee manieren waarop een schema kan worden gedistribueerd in Azure Cosmos DB for PostgreSQL:
Handmatig door de functie aan te roepen citus_schema_distribute(schema_name) :
CREATE SCHEMA AUTHORIZATION userservice;
CREATE SCHEMA AUTHORIZATION timeservice;
CREATE SCHEMA AUTHORIZATION pingservice;
SELECT citus_schema_distribute('userservice');
SELECT citus_schema_distribute('timeservice');
SELECT citus_schema_distribute('pingservice');
Met deze methode kunt u ook bestaande reguliere schema's converteren naar gedistribueerde schema's.
Notitie
U kunt alleen schema's distribueren die geen gedistribueerde en referentietabellen bevatten.
Een alternatieve benadering is om de configuratievariabele citus.enable_schema_based_sharding in te schakelen.
SET citus.enable_schema_based_sharding TO ON;
CREATE SCHEMA AUTHORIZATION userservice;
CREATE SCHEMA AUTHORIZATION timeservice;
CREATE SCHEMA AUTHORIZATION pingservice;
De variabele kan worden gewijzigd voor de huidige sessie of permanent in parameters voor coördinatorknooppunten. Als de parameter is ingesteld op AAN, worden alle gemaakte schema's standaard gedistribueerd.
U kunt de momenteel gedistribueerde schema's weergeven door het volgende uit te voeren:
select * from citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
userservice | 5 | 0 bytes | userservice
timeservice | 6 | 0 bytes | timeservice
pingservice | 7 | 0 bytes | pingservice
(3 rows)
Tabellen maken voor de voorbeeldservices
U moet nu voor elke microservice verbinding maken met Azure Cosmos DB for PostgreSQL. U kunt de opdracht \c gebruiken om de gebruiker te wisselen binnen een bestaand psql-exemplaar.
\c citus userservice
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL
);
\c citus timeservice
CREATE TABLE query_details (
id SERIAL PRIMARY KEY,
ip_address INET NOT NULL,
query_time TIMESTAMP NOT NULL
);
\c citus pingservice
CREATE TABLE ping_results (
id SERIAL PRIMARY KEY,
host VARCHAR(255) NOT NULL,
result TEXT NOT NULL
);
Services configureren
In deze tutorial gebruiken we een eenvoudige set diensten. U kunt ze verkrijgen door deze openbare opslagplaats te klonen:
git clone https://github.com/citusdata/citus-example-microservices.git
$ tree
.
├── LICENSE
├── README.md
├── ping
│ ├── app.py
│ ├── ping.sql
│ └── requirements.txt
├── time
│ ├── app.py
│ ├── requirements.txt
│ └── time.sql
└── user
├── app.py
├── requirements.txt
└── user.sql
Voordat u de services uitvoert, moet u echter bewerken user/app.pyping/app.py en time/app.py bestanden die de verbindingsconfiguratie bieden voor uw Azure Cosmos DB for PostgreSQL-cluster:
# Database configuration
db_config = {
'host': 'c-EXAMPLE.EXAMPLE.postgres.cosmos.azure.com',
'database': 'citus',
'password': 'SECRET',
'user': 'pingservice',
'port': 5432
}
Nadat u de wijzigingen hebt aangebracht, slaat u alle gewijzigde bestanden op en gaat u verder met de volgende stap van het uitvoeren van de services.
Services uitvoeren
Ga naar iedere app-map en voer ze uit in hun eigen Python-omgeving.
cd user
pipenv install
pipenv shell
python app.py
Herhaal de opdrachten voor tijd en ping-service, waarna u de API kunt gebruiken.
Maak enkele gebruikers:
curl -X POST -H "Content-Type: application/json" -d '[
{"name": "John Doe", "email": "john@example.com"},
{"name": "Jane Smith", "email": "jane@example.com"},
{"name": "Mike Johnson", "email": "mike@example.com"},
{"name": "Emily Davis", "email": "emily@example.com"},
{"name": "David Wilson", "email": "david@example.com"},
{"name": "Sarah Thompson", "email": "sarah@example.com"},
{"name": "Alex Miller", "email": "alex@example.com"},
{"name": "Olivia Anderson", "email": "olivia@example.com"},
{"name": "Daniel Martin", "email": "daniel@example.com"},
{"name": "Sophia White", "email": "sophia@example.com"}
]' http://localhost:5000/users
Geef de gemaakte gebruikers weer:
curl http://localhost:5000/users
Huidige tijd ophalen:
Get current time:
Voer de ping uit op example.com:
curl -X POST -H "Content-Type: application/json" -d '{"host": "example.com"}' http://localhost:5002/ping
De database verkennen
Nu u een aantal API-functies hebt aangeroepen, zijn gegevens opgeslagen en kunt u controleren of citus_schemas dit overeenkomt met wat er wordt verwacht:
select * from citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
userservice | 1 | 112 kB | userservice
timeservice | 2 | 32 kB | timeservice
pingservice | 3 | 32 kB | pingservice
(3 rows)
Toen u de schema's maakte, hebt u Azure Cosmos DB for PostgreSQL niet verteld op welke machines de schema's moeten worden gemaakt. Het is automatisch gedaan. U kunt zien waar elk schema zich bevindt met de volgende query:
select nodename,nodeport, table_name, pg_size_pretty(sum(shard_size))
from citus_shards
group by nodename,nodeport, table_name;
nodename | nodeport | table_name | pg_size_pretty
-----------+----------+---------------------------+----------------
localhost | 9701 | timeservice.query_details | 32 kB
localhost | 9702 | userservice.users | 112 kB
localhost | 9702 | pingservice.ping_results | 32 kB
Voor een beknopt overzicht van de voorbeelduitvoer op deze pagina, in plaats van te gebruiken nodename zoals weergegeven in Azure Cosmos DB for PostgreSQL, vervangen we deze door localhost. Stel dat localhost:9701 werknemer één is en localhost:9702 werknemer twee is. Namen van knooppunten in de beheerde service zijn langer en bevatten gerandomiseerde elementen.
U kunt zien dat de tijdservice op het knooppunt localhost:9701 terechtkomt, terwijl de gebruikerservice en de ping-service ruimte delen op de tweede worker localhost:9702. De voorbeeld-apps zijn simplistisch en de gegevensgrootten hier zijn genegeerd, maar we gaan ervan uit dat u geïrriteerd bent door het ongelijke gebruik van opslagruimte tussen de knooppunten. Het zou logischer zijn om de twee kleinere tijd- en pingservices op één computer te hebben, terwijl de grote gebruikersservice zich alleen bevindt.
U kunt het cluster eenvoudig opnieuw verdelen op schijfgrootte:
select citus_rebalance_start();
NOTICE: Scheduled 1 moves as job 1
DETAIL: Rebalance scheduled as background job
HINT: To monitor progress, run: SELECT * FROM citus_rebalance_status();
citus_rebalance_start
-----------------------
1
(1 row)
Wanneer u klaar bent, kunt u controleren hoe onze nieuwe indeling eruitziet:
select nodename,nodeport, table_name, pg_size_pretty(sum(shard_size))
from citus_shards
group by nodename,nodeport, table_name;
nodename | nodeport | table_name | pg_size_pretty
-----------+----------+---------------------------+----------------
localhost | 9701 | timeservice.query_details | 32 kB
localhost | 9701 | pingservice.ping_results | 32 kB
localhost | 9702 | userservice.users | 112 kB
(3 rows)
Volgens de verwachtingen zijn de schema's verplaatst en hebben we een evenwichtiger cluster. Deze bewerking is transparant voor de toepassingen. U hoeft ze niet eens opnieuw op te starten. Ze blijven query's leveren.
Volgende stappen
In deze zelfstudie hebt u geleerd hoe u gedistribueerde schema's maakt en microservices uitvoert met behulp van deze als opslag. U hebt ook geleerd hoe u op schema's gebaseerde sharded Azure Cosmos DB for PostgreSQL kunt verkennen en beheren.