Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Belangrijk
Azure Cosmos DB for PostgreSQL wordt niet meer ondersteund voor nieuwe projecten. Gebruik deze service niet voor nieuwe projecten. Gebruik in plaats daarvan een van deze twee services:
Gebruik Azure Cosmos DB voor NoSQL voor een gedistribueerde databaseoplossing die is ontworpen voor hoogwaardige schalen scenario's met een 99,999% service level agreement (SLA) voor beschikbaarheid, onmiddellijke autoschaalaanpassing en automatische failover over meerdere regio's.
Gebruik de functie Elastische clusters van Azure Database For PostgreSQL voor sharded PostgreSQL met behulp van de opensource Citus-extensie.
In deze zelfstudie gebruikt u Azure Cosmos DB for PostgreSQL voor meer informatie over het volgende:
- Een cluster maken
- Het hulpprogramma psql gebruiken om een schema te maken
- Sharding toepassen op tabellen tussen knooppunten
- Voorbeeldgegevens opnemen
- Query's uitvoeren op tenantgegevens
- Gegevens tussen tenants delen
- Het schema per tenant aanpassen
Vereisten
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Een cluster maken
Meld u aan bij Azure Portal en volg deze stappen om een Azure Cosmos DB for PostgreSQL-cluster te maken:
Ga naar Een Azure Cosmos DB for PostgreSQL-cluster maken in de Azure-portal.
In het formulier Maak een Azure Cosmos DB voor PostgreSQL-cluster:
Vul de gegevens in op het tabblad Basis.
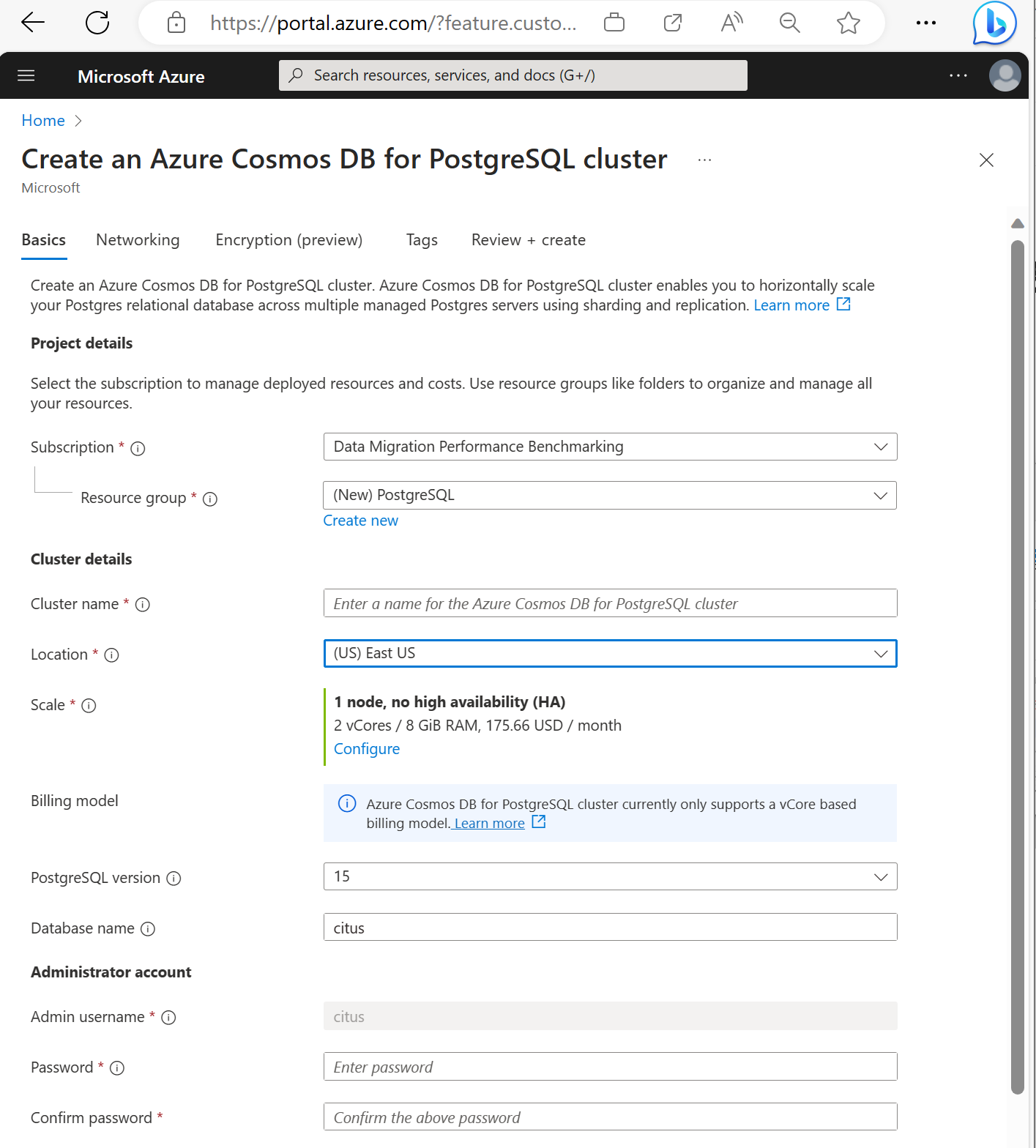
De meeste opties spreken voor zich, maar onthoud:
- De clusternaam bepaalt de DNS-naam die uw toepassingen gebruiken om verbinding te maken, in de vorm
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - U kunt een primaire PostgreSQL-versie, zoals 15, kiezen. Azure Cosmos DB for PostgreSQL ondersteunt altijd de nieuwste Citus-versie voor de geselecteerde primaire Postgres-versie.
- De gebruikersnaam van de beheerder moet de waarde
cituszijn. - U kunt de databasenaam op de standaardwaarde citus laten staan of de enige databasenaam definiëren. U kunt de naam van de database niet wijzigen nadat het cluster is ingericht.
- De clusternaam bepaalt de DNS-naam die uw toepassingen gebruiken om verbinding te maken, in de vorm
Selecteer Volgende: Netwerken onderaan het scherm.
Selecteer in het scherm Netwerken de optie Openbare toegang toestaan vanuit Azure-services en -resources binnen Azure naar dit cluster.
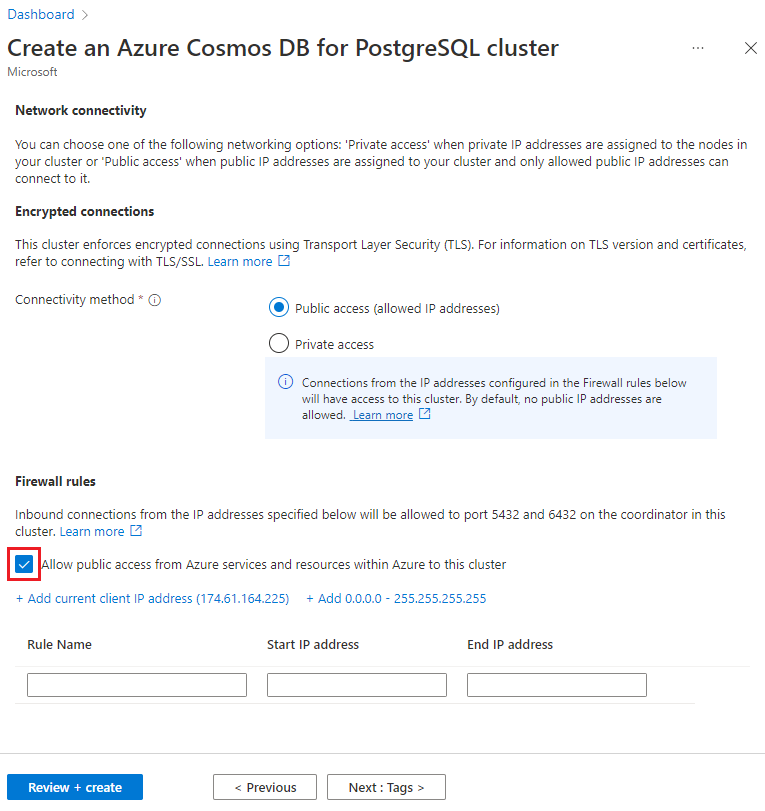
Selecteer Beoordelen en maken en selecteer vervolgens, wanneer de validatie is geslaagd, Maken om het cluster te maken.
De voorziening duurt een paar minuten. De pagina wordt omgeleid om de implementatie te bewaken. Wanneer de status verandert van Implementatie wordt uitgevoerd naar Uw implementatie is voltooid, selecteer dan Naar resource.
Het hulpprogramma psql gebruiken om een schema te maken
Nadat u met behulp van psql verbinding hebt gemaakt met Azure Cosmos DB for PostgreSQL, kunt u enkele basistaken uitvoeren. In deze zelfstudie krijgt u instructies voor het maken van een web-app waarmee adverteerders hun campagnes kunnen volgen.
Meerdere bedrijven kunnen gebruik maken van de app, dus we maken een tabel waarin we bedrijven opslaan en een tweede tabel voor hun campagnes. Voer op de psql-console deze opdrachten uit:
CREATE TABLE companies (
id bigserial PRIMARY KEY,
name text NOT NULL,
image_url text,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE campaigns (
id bigserial,
company_id bigint REFERENCES companies (id),
name text NOT NULL,
cost_model text NOT NULL,
state text NOT NULL,
monthly_budget bigint,
blocked_site_urls text[],
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id)
);
Per campagne wordt betaald voor het uitvoeren van advertenties. Voeg ook een tabel voor advertenties toe, door in psql de volgende code na de bovenstaande code uit te voeren:
CREATE TABLE ads (
id bigserial,
company_id bigint,
campaign_id bigint,
name text NOT NULL,
image_url text,
target_url text,
impressions_count bigint DEFAULT 0,
clicks_count bigint DEFAULT 0,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, campaign_id)
REFERENCES campaigns (company_id, id)
);
Als laatste houden we de statistieken bij over klikbewegingen en de indruk van elke advertentie:
CREATE TABLE clicks (
id bigserial,
company_id bigint,
ad_id bigint,
clicked_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_click_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
CREATE TABLE impressions (
id bigserial,
company_id bigint,
ad_id bigint,
seen_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_impression_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
U kunt de zojuist gemaakte tabellen nu in de lijst met tabellen in psql zien door het volgende uit te voeren:
\dt
Multi-tenant toepassingen kunnen uniekheid alleen per tenant afdwingen, daarom bevatten alle primaire en refererende sleutels de bedrijfs-id.
Sharding toepassen op tabellen tussen knooppunten
In een Azure Cosmos DB for PostgreSQL-implementatie worden tabelrijen op verschillende knooppunten opgeslagen op basis van de waarde van een door de gebruiker aangewezen kolom. Deze 'distributiekolom' geeft aan welke tenant de eigenaar is van welke rijen.
Laten we de distributiekolom instellen op company_id, de tenant-id. Voer in psql deze functies uit:
SELECT create_distributed_table('companies', 'id');
SELECT create_distributed_table('campaigns', 'company_id');
SELECT create_distributed_table('ads', 'company_id');
SELECT create_distributed_table('clicks', 'company_id');
SELECT create_distributed_table('impressions', 'company_id');
Belangrijk
Het distribueren van tabellen of het gebruik van sharding op basis van schema's is nodig om te profiteren van de prestatiefuncties van Azure Cosmos DB for PostgreSQL. Als u geen tabellen of schema's distribueert, kunnen werkknooppunten u niet helpen bij het uitvoeren van query's met betrekking tot hun gegevens.
Voorbeeldgegevens opnemen
Nu buiten psql, in de normale opdrachtregel, download voorbeeld-dataset:
for dataset in companies campaigns ads clicks impressions geo_ips; do
curl -O https://examples.citusdata.com/mt_ref_arch/${dataset}.csv
done
Ga terug naar psql en laad de gegevens bulksgewijs. Vergeet niet dat u psql moet uitvoeren in dezelfde map als waarin u de gegevensbestanden hebt gedownload.
SET client_encoding TO 'UTF8';
\copy companies from 'companies.csv' with csv
\copy campaigns from 'campaigns.csv' with csv
\copy ads from 'ads.csv' with csv
\copy clicks from 'clicks.csv' with csv
\copy impressions from 'impressions.csv' with csv
Deze gegevens worden nu over werkknooppunten verspreid.
Query's uitvoeren op tenantgegevens
Wanneer de toepassing om gegevens voor één tenant vraagt, kunt u via de database de query op één werkknooppunt uitvoeren. Query's voor één tenant worden op één tenant-id gefilterd. Met de volgende query wordt bijvoorbeeld company_id = 5 gefilterd voor advertenties en indrukken. Probeer de query in psql uit te voeren om de resultaten te zien.
SELECT a.campaign_id,
RANK() OVER (
PARTITION BY a.campaign_id
ORDER BY a.campaign_id, count(*) desc
), count(*) as n_impressions, a.id
FROM ads as a
JOIN impressions as i
ON i.company_id = a.company_id
AND i.ad_id = a.id
WHERE a.company_id = 5
GROUP BY a.campaign_id, a.id
ORDER BY a.campaign_id, n_impressions desc;
Gegevens tussen tenants delen
Tot nu toe zijn alle tabellen gedistribueerd door company_id. Sommige gegevens behoren echter niet van nature tot een tenant in het bijzonder en kunnen worden gedeeld. Alle bedrijven op het voorbeeldadvertentieplatform zoeken bijvoorbeeld geografische informatie voor hun doelgroep op basis van IP-adressen.
Maak een tabel om daarin gedeelde geografische informatie op te slaan. Voer de volgende opdrachten uit in psql:
CREATE TABLE geo_ips (
addrs cidr NOT NULL PRIMARY KEY,
latlon point NOT NULL
CHECK (-90 <= latlon[0] AND latlon[0] <= 90 AND
-180 <= latlon[1] AND latlon[1] <= 180)
);
CREATE INDEX ON geo_ips USING gist (addrs inet_ops);
Maak nu geo_ips een 'referentietabel' om een kopie van de tabel op te slaan op elk werkknooppunt.
SELECT create_reference_table('geo_ips');
Laad hierin voorbeeldgegevens. Vergeet niet deze opdracht in psql uit te voeren vanuit de map waarin u de gegevensset hebt gedownload.
\copy geo_ips from 'geo_ips.csv' with csv
Het samenvoegen van de clicks-tabel met geo_ips is efficiënt op alle knooppunten. Hier volgt een join om de locaties te vinden van iedereen die op advertentie 290 heeft geklikt. Voer de query uit in psql.
SELECT c.id, clicked_at, latlon
FROM geo_ips, clicks c
WHERE addrs >> c.user_ip
AND c.company_id = 5
AND c.ad_id = 290;
Het schema per tenant aanpassen
Elke tenant kan speciale informatie moeten opslaan die anderen niet nodig hebben. Alle tenants delen echter een algemene infrastructuur met een identiek databaseschema. Waar kunt u de extra gegevens opslaan?
U kunt bijvoorbeeld een kolomtype met een open einde gebruiken, zoals JSONB van PostgreSQL. Ons schema bevat een JSONB-veld in clicks met de naam user_data.
Een bedrijf (laten we het bedrijf Vijf noemen), kan de kolom gebruiken om bij te houden of de gebruiker een mobiel apparaat gebruikt.
Hier ziet u een query om te ontdekken wie er vaker klikt: mobiele of traditionele bezoekers.
SELECT
user_data->>'is_mobile' AS is_mobile,
count(*) AS count
FROM clicks
WHERE company_id = 5
GROUP BY user_data->>'is_mobile'
ORDER BY count DESC;
We kunnen deze query voor één bedrijf optimaliseren door het maken van een gedeeltelijke index.
CREATE INDEX click_user_data_is_mobile
ON clicks ((user_data->>'is_mobile'))
WHERE company_id = 5;
Algemener gezegd: we kunnen GIN-indices maken op elke sleutel en waarde binnen de kolom.
CREATE INDEX click_user_data
ON clicks USING gin (user_data);
-- this speeds up queries like, "which clicks have
-- the is_mobile key present in user_data?"
SELECT id
FROM clicks
WHERE user_data ? 'is_mobile'
AND company_id = 5;
Middelen opruimen
In de voorgaande stappen hebt u Azure-resources in een cluster gemaakt. Als u deze resources in de toekomst niet meer nodig hebt, verwijdert u het cluster. Selecteer de knop Verwijderen op de pagina Overzicht voor uw cluster. Wanneer u hierom wordt gevraagd op een pop-uppagina, bevestigt u de naam van het cluster en selecteert u de laatste knop Verwijderen .
Volgende stappen
In deze handleiding hebt u geleerd hoe u een cluster inricht. U hebt psql gebruikt om hiermee verbinding te maken, u hebt een schema gemaakt en u hebt gegevens gedistribueerd. U hebt geleerd om een query uit te voeren op gegevens zowel in als tussen tenants en om het schema per tenant aan te passen.
- Meer informatie over clusterknooppunttypen
- Bepaal de beste initiële grootte voor uw cluster