Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
VAN TOEPASSING OP:
![]() Azure Cosmos DB for PostgreSQL (mogelijk gemaakt door de Citus-database-extensie naar PostgreSQL)
Azure Cosmos DB for PostgreSQL (mogelijk gemaakt door de Citus-database-extensie naar PostgreSQL)
In deze zelfstudie gebruikt u Azure Cosmos DB for PostgreSQL voor meer informatie over het volgende:
- Maak shards met hashverdeling
- Zie waar de tabelsegmenten worden geplaatst
- Ongelijke distributie identificeren
- Beperkingen voor gedistribueerde tabellen maken
- Query's uitvoeren op gedistribueerde gegevens
(No changes required)
Voor deze handleiding is een draaiend cluster met twee werkknooppunten vereist. Als u geen actief cluster hebt, volgt u het tutorial cluster maken en ga dan terug naar deze.
Gegevens met hashverdeling
Het distribueren van tabelrijen over meerdere PostgreSQL-servers is een belangrijke techniek voor schaalbare query's in Azure Cosmos DB voor PostgreSQL. Meerdere knooppunten kunnen samen meer gegevens bevatten dan een traditionele database, en kunnen in veel gevallen werkrol-CPU's parallel gebruiken om query's uit te voeren. Het concept van hash-gedistribueerde tabellen wordt ook wel sharding op basis van rijen genoemd.
In de sectie 'Vereisten' hebben we een cluster met twee werkknooppunten gemaakt.
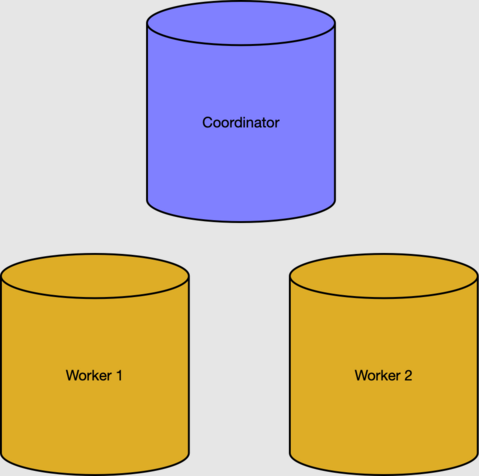
De metagegevenstabellen van het coördinatorknooppunt houden de werknodes en gedistribueerde gegevens bij. We kunnen de actieve werknemers nagaan in de tabel pg_dist_node.
select nodeid, nodename from pg_dist_node where isactive;
nodeid | nodename
--------+-----------
1 | 10.0.0.21
2 | 10.0.0.23
Notitie
Knooppuntnamen in Azure Cosmos DB for PostgreSQL zijn interne IP-adressen in een virtueel netwerk en de werkelijke adressen die u ziet, kunnen verschillen.
Rijen, fragmenten en plaatsingen
Als u de CPU- en opslagbronnen van werkknooppunten wilt gebruiken, moeten we tabelgegevens over het hele cluster verdelen. Als u een tabel distribueert, wordt elke rij toegewezen aan een logische groep die een shard wordt genoemd. Laten we een tabel maken en deze distribueren:
-- create a table on the coordinator
create table users ( email text primary key, bday date not null );
-- distribute it into shards on workers
select create_distributed_table('users', 'email');
Azure Cosmos DB for PostgreSQL wijst elke rij toe aan een shard op basis van de waarde van de distributiekolom, die we in ons geval als email hebben opgegeven. Elke rij komt precies in één shard, en elke shard kan meerdere rijen bevatten.
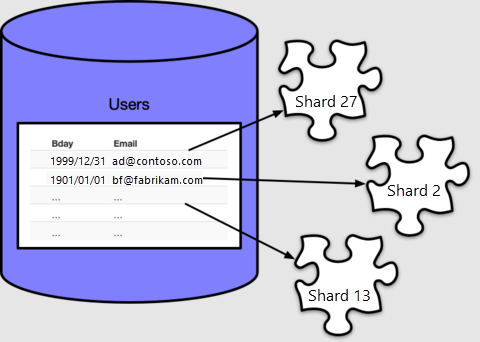
create_distributed_table() maakt standaard 32 shards, zoals we kunnen zien als we de metagegevenstabel pg_dist_shard meetellen:
select logicalrelid, count(shardid)
from pg_dist_shard
group by logicalrelid;
logicalrelid | count
--------------+-------
users | 32
Azure Cosmos DB for PostgreSQL gebruikt de pg_dist_shard tabel om rijen toe te wijzen aan shards, op basis van een hash van de waarde in de distributiekolom. De hashdetails zijn niet belangrijk voor deze handleiding. Wat belangrijk is, is dat we een query kunnen uitvoeren om te zien welke waarden zijn toegewezen aan welke shard-id's:
-- Where would a row containing hi@test.com be stored?
-- (The value doesn't have to actually be present in users, the mapping
-- is a mathematical operation consulting pg_dist_shard.)
select get_shard_id_for_distribution_column('users', 'hi@test.com');
get_shard_id_for_distribution_column
--------------------------------------
102008
Het toewijzen van rijen aan shards gebeurt alleen op basis van logica. Shards moeten worden toegewezen aan specifieke werkknooppunten voor opslag, in wat Azure Cosmos DB for PostgreSQL shardplaatsing het noemt.
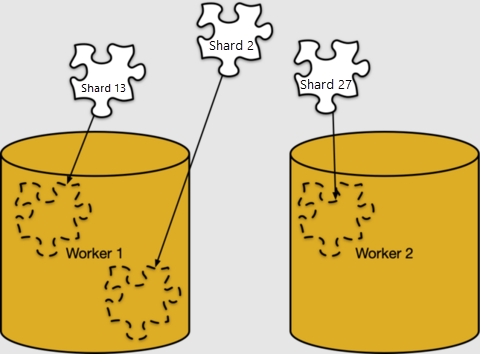
We kunnen de shardplaatsing in pg_dist_placement bekijken. Door deze te koppelen aan de andere tabellen met metagegevens die we hebben gezien, wordt duidelijk waar elke shard zich bevindt.
-- limit the output to the first five placements
select
shard.logicalrelid as table,
placement.shardid as shard,
node.nodename as host
from
pg_dist_placement placement,
pg_dist_node node,
pg_dist_shard shard
where placement.groupid = node.groupid
and shard.shardid = placement.shardid
order by shard
limit 5;
table | shard | host
-------+--------+------------
users | 102008 | 10.0.0.21
users | 102009 | 10.0.0.23
users | 102010 | 10.0.0.21
users | 102011 | 10.0.0.23
users | 102012 | 10.0.0.21
Ongelijkheid in gegevens
Een cluster functioneert het meest efficiënt wanneer u gegevens gelijkmatig op werkknooppunten plaatst en wanneer u gerelateerde gegevens op dezelfde werkknooppunten plaatst. In deze sectie richten we ons op het eerste gedeelte, de uniformiteit van plaatsing.
Ter demonstratie maken we voorbeeldgegevens voor de tabel users:
-- load sample data
insert into users
select
md5(random()::text) || '@test.com',
date_trunc('day', now() - random()*'100 years'::interval)
from generate_series(1, 1000);
Als we shardgrootten willen zien, kunnen we functies voor tabelgrootte uitvoeren voor de shards.
-- sizes of the first five shards
select *
from
run_command_on_shards('users', $cmd$
select pg_size_pretty(pg_table_size('%1$s'));
$cmd$)
order by shardid
limit 5;
shardid | success | result
---------+---------+--------
102008 | t | 16 kB
102009 | t | 16 kB
102010 | t | 16 kB
102011 | t | 16 kB
102012 | t | 16 kB
We zien dat de shards even groot zijn. We hebben al gezien dat plaatsingen gelijkmatig zijn verdeeld over werknemers, dus we kunnen afleiden dat de werkknooppunten ongeveer hetzelfde aantal rijen bevatten.
De rijen in ons voorbeeld users zijn gelijkmatig gedistribueerd vanwege eigenschappen van de distributiekolom email.
- Het aantal e-mailadressen was groter dan of gelijk aan het aantal shards.
- Het aantal rijen per e-mailadres is vergelijkbaar (in ons geval is er precies één rij per adres, omdat we het e-mailadres in een sleutel hebben gedeclareerd).
Een willekeurige keuze van tabel en distributiekolom waarbij een van de eigenschappen faalt, leidt tot een ongelijke gegevensverdeling over workers, dit wordt datascheefheid genoemd.
Beperkingen toevoegen aan gedistribueerde gegevens
Met Azure Cosmos DB for PostgreSQL kunt u blijven profiteren van de veiligheid van een relationele database, inclusief databasebeperkingen. Er is echter een limiet. Vanwege de aard van gedistribueerde systemen worden beperkingen voor uniekheid of referentiële integriteit tussen werkknooppunten in Azure Cosmos DB for PostgreSQL niet gebruikt.
Laten we onze voorbeeldtabel users beschouwen met een gerelateerde tabel.
-- books that users own
create table books (
owner_email text references users (email),
isbn text not null,
title text not null
);
-- distribute it
select create_distributed_table('books', 'owner_email');
Voor efficiëntiedoeleinden hebben we books op dezelfde manier gedistribueerd als users: via het e-mailadres van de eigenaar. Distributie op basis van vergelijkbare kolomwaarden heet colocatie.
We hebben zonder problemen boeken met een buitenlandse sleutel gedistribueerd naar gebruikers, omdat de sleutel op een distributiekolom stond. We zouden echter problemen ondervinden om van isbn een sleutel te maken:
-- will not work
alter table books add constraint books_isbn unique (isbn);
ERROR: cannot create constraint on "books"
DETAIL: Distributed relations cannot have UNIQUE, EXCLUDE, or
PRIMARY KEY constraints that do not include the partition column
(with an equality operator if EXCLUDE).
In een gedistribueerde tabel is het beste wat we kunnen doen de kolommen uniek maken ten opzichte van de distributiekolom.
-- a weaker constraint is allowed
alter table books add constraint books_isbn unique (owner_email, isbn);
Met de bovenstaande beperking wordt alleen de ISBN uniek gemaakt per gebruiker. Een andere optie is om van boeken een referentietabel te maken, in plaats van een gedistribueerde tabel, en een afzonderlijke gedistribueerde tabel te maken die boeken koppelt aan gebruikers.
Query uitvoeren op gedistribueerde tabellen
In de vorige secties hebben we gezien hoe gedistribueerde tabelrijen in shards worden geplaatst op werkknooppunten. Meestal hoeft u niet te weten hoe of waar gegevens worden opgeslagen in een cluster. Azure Cosmos DB for PostgreSQL heeft een gedistribueerde queryexecutor waarmee normale SQL-query's automatisch worden gesplitst. De query's worden parallel uitgevoerd op werkknooppunten dicht bij de gegevens.
We kunnen bijvoorbeeld een query uitvoeren om de gemiddelde leeftijd van gebruikers te vinden, waarbij we de gedistribueerde tabel users behandelen alsof het een normale tabel is in de coördinator.
select avg(current_date - bday) as avg_days_old from users;
avg_days_old
--------------------
17926.348000000000
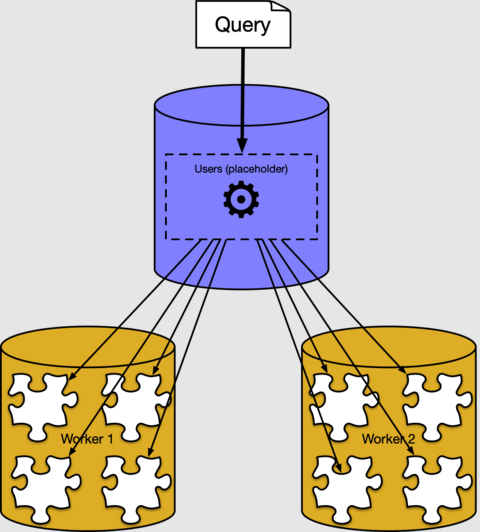
Achter de schermen creëert de Azure Cosmos DB voor PostgreSQL executor een afzonderlijke query voor elk shard, voert ze uit op de workers en combineert het resultaat. U kunt deze zien met behulp van de PostgreSQL-opdracht EXPLAIN:
explain select avg(current_date - bday) from users;
QUERY PLAN
----------------------------------------------------------------------------------
Aggregate (cost=500.00..500.02 rows=1 width=32)
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=100000 width=16)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=10.0.0.21 port=5432 dbname=citus
-> Aggregate (cost=41.75..41.76 rows=1 width=16)
-> Seq Scan on users_102040 users (cost=0.00..22.70 rows=1270 width=4)
De uitvoer toont een voorbeeld van een uitvoeringsplan voor een queryfragment dat wordt uitgevoerd voor shard 102040 (de tabel users_102040 op werkrol 10.0.0.21). De andere fragmenten worden niet weergegeven omdat ze vergelijkbaar zijn. We zien dat het werkknooppunt de shardtabellen scant en het aggregaat toepast. Op het coördinatorknooppunt worden samenvoegingen gecombineerd voor het uiteindelijke resultaat.
Volgende stappen
In deze zelfstudie hebt u een gedistribueerde tabel gemaakt, en informatie gekregen over de bijbehorende shards en plaatsingen. We zagen dat het gebruik van beperkingen voor uniekheid en referentiële sleutels een uitdaging vormde, en ten slotte hoe gedistribueerde query's werken op een hoger niveau.
- Meer informatie over Azure Cosmos DB for PostgreSQL-tabeltypen
- Krijg meer tips over het kiezen van een distributiekolom
- Leer wat de voordelen zijn van colocatie van tabellen