Sociaal netwerken met Azure Cosmos DB
VAN TOEPASSING OP: ![]() Nosql
Nosql ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tabel
Tabel
Leven in een enorm onderling verbonden samenleving betekent dat je op een bepaald moment in het leven deel uitmaakt van een sociaal netwerk. U gebruikt sociale netwerken om contact te houden met vrienden, collega's, familie of soms om uw passie te delen met mensen met gemeenschappelijke interesses.
Als technici of ontwikkelaars hebt u zich misschien afgevraagd hoe deze netwerken uw gegevens opslaan en onderling verbinden. Of misschien bent u zelfs belast met het creëren of ontwerpen van een nieuw sociaal netwerk voor een specifieke nichemarkt. Dat is het moment waarop de belangrijke vraag zich voordoet: Hoe worden al deze gegevens opgeslagen?
Stel dat u een nieuw en glanzend sociaal netwerk maakt waar uw gebruikers artikelen kunnen posten met gerelateerde media, zoals afbeeldingen, video's of zelfs muziek. Gebruikers kunnen opmerkingen plaatsen bij berichten en punten voor beoordelingen geven. Er wordt een feed met berichten weergegeven waarmee gebruikers de landingspagina van de hoofdwebsite kunnen zien en ermee werken. Deze methode klinkt in eerste instantie niet complex, maar om het eenvoudig te houden, gaan we daar stoppen. (U kunt zich verdiepen in aangepaste gebruikersfeeds die worden beïnvloed door relaties, maar het gaat verder dan het doel van dit artikel.)
Hoe slaat u deze gegevens op en waar?
Mogelijk hebt u ervaring met SQL-databases of hebt u een idee van relationele modellering van gegevens. U kunt als volgt beginnen met tekenen:
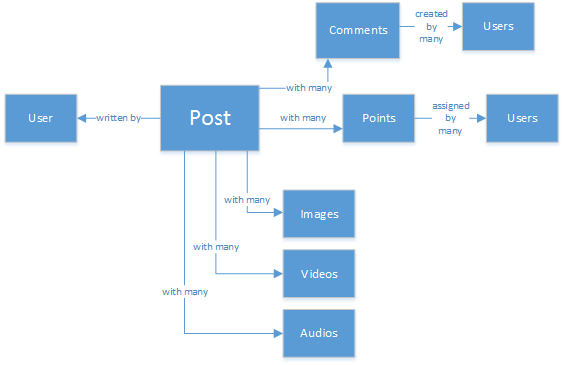
Een perfect genormaliseerde en mooie gegevensstructuur... dat schaalt niet.
Begrijp me niet verkeerd, ik heb al mijn hele leven met SQL-databases gewerkt. Ze zijn geweldig, maar zoals elk patroon, de praktijk en het softwareplatform is het niet perfect voor elk scenario.
Waarom is SQL niet de beste keuze in dit scenario? Laten we eens kijken naar de structuur van één bericht. Als ik het bericht in een website of toepassing wilde weergeven, moet ik een query uitvoeren met... door acht tabellen(!) samen te voegen om één bericht weer te geven. Bekijk nu een stroom berichten die dynamisch worden geladen en weergegeven op het scherm, en u ziet mogelijk waar ik heen ga.
U kunt een enorm SQL-exemplaar gebruiken met voldoende vermogen om duizenden query's met veel joins op te lossen om uw inhoud te leveren. Maar waarom zou u, wanneer er een eenvoudigere oplossing bestaat?
De NoSQL-weg
In dit artikel wordt u begeleid bij het modelleren van de gegevens van uw sociale platform met de NoSQL-database van Azure Cosmos DB . U krijgt ook informatie over het gebruik van andere Azure Cosmos DB-functies, zoals de API voor Gremlin. Met behulp van een NoSQL-benadering , het opslaan van gegevens, in JSON-indeling en het toepassen van denormalisatie, kan het eerder gecompliceerde bericht worden omgezet in één document:
{
"id":"ew12-res2-234e-544f",
"title":"post title",
"date":"2016-01-01",
"body":"this is an awesome post stored on NoSQL",
"createdBy":User,
"images":["https://myfirstimage.png","https://mysecondimage.png"],
"videos":[
{"url":"https://myfirstvideo.mp4", "title":"The first video"},
{"url":"https://mysecondvideo.mp4", "title":"The second video"}
],
"audios":[
{"url":"https://myfirstaudio.mp3", "title":"The first audio"},
{"url":"https://mysecondaudio.mp3", "title":"The second audio"}
]
}
En het kan worden geleverd met één query en zonder joins. Deze query is veel eenvoudig en eenvoudig, en budgetmatig vereist het minder resources om een beter resultaat te bereiken.
Azure Cosmos DB zorgt ervoor dat alle eigenschappen worden geïndexeerd met automatische indexering. De automatische indexering kan zelfs worden aangepast. Met de schemavrije benadering kunnen documenten met verschillende en dynamische structuren worden opgeslagen. Misschien wilt u morgen dat er een lijst met categorieën of hashtags aan berichten is gekoppeld? Azure Cosmos DB verwerkt de nieuwe documenten met de toegevoegde kenmerken zonder extra werk dat door ons is vereist.
Opmerkingen over een bericht kunnen worden behandeld als andere berichten met een bovenliggende eigenschap. (Deze procedure vereenvoudigt de toewijzing van objecten.)
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":User2,
"parent":"ew12-res2-234e-544f"
}
{
"id":"asd2-fee4-23gc-jh67",
"title":"Ditto!",
"date":"2016-01-03",
"createdBy":User3,
"parent":"ew12-res2-234e-544f"
}
En alle sociale interacties kunnen als tellers op een afzonderlijk object worden opgeslagen:
{
"id":"dfe3-thf5-232s-dse4",
"post":"ew12-res2-234e-544f",
"comments":2,
"likes":10,
"points":200
}
Het maken van feeds is slechts een kwestie van het maken van documenten die een lijst met post-id's met een bepaalde relevantievolgorde kunnen bevatten:
[
{"relevance":9, "post":"ew12-res2-234e-544f"},
{"relevance":8, "post":"fer7-mnb6-fgh9-2344"},
{"relevance":7, "post":"w34r-qeg6-ref6-8565"}
]
U kunt een 'nieuwste' stream hebben met berichten die zijn besteld op aanmaakdatum. Of u kunt een 'heetste' stream hebben met die berichten met meer vind-ik-leuks in de afgelopen 24 uur. U kunt zelfs een aangepaste stream implementeren voor elke gebruiker op basis van logica zoals volgers en interesses. Het zou nog steeds een lijst met berichten zijn. Het is een kwestie van het bouwen van deze lijsten, maar de leesprestaties blijven ongehinderd. Zodra u een van deze lijsten hebt verkregen, geeft u één query uit aan Azure Cosmos DB met behulp van het trefwoord IN om pagina's met berichten tegelijk op te halen.
De feedstreams kunnen worden gebouwd met behulp van de achtergrondprocessen van Azure-app Services: Webjobs. Zodra een bericht is gemaakt, kan achtergrondverwerking worden geactiveerd met behulp van Azure Storage-wachtrijen en webtaken die worden geactiveerd met behulp van de Azure Webjobs SDK, waarbij de postdoorgifte binnen streams wordt geïmplementeerd op basis van uw eigen aangepaste logica.
Punten en vind-ik-leuks op een post kunnen op een uitgestelde manier worden verwerkt met behulp van dezelfde techniek om uiteindelijk een consistente omgeving te maken.
Volgers zijn lastiger. Azure Cosmos DB heeft een limiet voor documentgrootte en het lezen/schrijven van grote documenten kan van invloed zijn op de schaalbaarheid van uw toepassing. U kunt dus nadenken over het opslaan van volgers als een document met deze structuur:
{
"id":"234d-sd23-rrf2-552d",
"followersOf": "dse4-qwe2-ert4-aad2",
"followers":[
"ewr5-232d-tyrg-iuo2",
"qejh-2345-sdf1-ytg5",
//...
"uie0-4tyg-3456-rwjh"
]
}
Deze structuur werkt mogelijk voor een gebruiker met een paar duizenden volgers. Als sommige beroemdheden lid worden van de rangschikkingen, leidt deze benadering echter tot een grote documentgrootte en kan het uiteindelijk de limiet voor de documentgrootte bereiken.
U kunt dit probleem oplossen door een gemengde benadering te gebruiken. Als onderdeel van het document Gebruikersstatistieken kunt u het aantal volgers opslaan:
{
"id":"234d-sd23-rrf2-552d",
"user": "dse4-qwe2-ert4-aad2",
"followers":55230,
"totalPosts":452,
"totalPoints":11342
}
U kunt de werkelijke grafiek van volgers opslaan met behulp van de Azure Cosmos DB-API voor Gremlin om hoekpunten te maken voor elke gebruiker en randen die de A-follows-B-relaties onderhouden. Met de API voor Gremlin kunt u de volgers van een bepaalde gebruiker ophalen en complexere query's maken om veelvoorkomende personen voor te stellen. Als u aan de grafiek de inhoudscategorieën toevoegt die mensen leuk vinden of leuk vinden, kunt u beginnen met het weven van ervaringen die slimme inhoudsdetectie bevatten, inhoud voorstellen die personen die u volgt of mensen vinden die u mogelijk veel gemeen hebt.
Het document Gebruikersstatistieken kan nog steeds worden gebruikt om kaarten te maken in de gebruikersinterface of snelle profielvoorbeelden.
Het patroon 'Ladder' en gegevensduplicatie
Zoals u misschien hebt opgemerkt in het JSON-document dat verwijst naar een bericht, zijn er veel exemplaren van een gebruiker. En u zou gelijk hebben geraden, deze duplicaten betekenen dat de informatie die een gebruiker beschrijft, gezien deze denormalisatie, mogelijk op meer dan één plaats aanwezig is.
Om snellere query's mogelijk te maken, treedt er duplicatie van gegevens op. Het probleem met dit neveneffect is dat als bij een bepaalde actie de gegevens van een gebruiker worden gewijzigd, u alle activiteiten moet vinden die de gebruiker ooit heeft gedaan en ze allemaal bijwerkt. Klinkt niet praktisch, toch?
U gaat dit oplossen door de belangrijkste kenmerken te identificeren van een gebruiker die u in uw toepassing voor elke activiteit weergeeft. Als u visueel een bericht in uw toepassing weergeeft en alleen de naam en afbeelding van de maker weergeeft, waarom moet u alle gegevens van de gebruiker opslaan in het kenmerk createdBy? Als u voor elke opmerking alleen de foto van de gebruiker weergeeft, hebt u de rest van de gegevens van de gebruiker niet echt nodig. Daar word ik het 'Ladderpatroon' bij betrokken.
Laten we gebruikersgegevens als voorbeeld nemen:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"address":"742 Evergreen Terrace",
"birthday":"1983-05-07",
"email":"john@doe.com",
"twitterHandle":"\@john",
"username":"johndoe",
"password":"some_encrypted_phrase",
"totalPoints":100,
"totalPosts":24
}
Door naar deze informatie te kijken, kunt u snel detecteren welke essentiële informatie is en wat niet, waardoor een "Ladder" ontstaat:

De kleinste stap wordt een UserChunk genoemd, het minimale stukje informatie dat een gebruiker identificeert en wordt gebruikt voor gegevensduplicatie. Door de gedupliceerde gegevensgrootte te verkleinen tot alleen de informatie die u 'weergeeft', vermindert u de mogelijkheid van enorme updates.
De middelste stap wordt de gebruiker genoemd. Dit zijn de volledige gegevens die worden gebruikt voor de meeste prestatieafhankelijke query's in Azure Cosmos DB, de meest gebruikte en kritieke query's. Het bevat de informatie die wordt vertegenwoordigd door een UserChunk.
De grootste is de uitgebreide gebruiker. Het omvat de kritieke gebruikersgegevens en andere gegevens die niet snel hoeven te worden gelezen of uiteindelijk gebruik hebben, zoals het aanmeldingsproces. Deze gegevens kunnen buiten Azure Cosmos DB worden opgeslagen in Azure SQL Database of Azure Storage-tabellen.
Waarom zou u de gebruiker splitsen en deze informatie zelfs op verschillende plaatsen opslaan? Omdat vanuit een prestatiepunt de documenten groter zijn, hoe duurder de query's zijn. Houd documenten slank, met de juiste informatie om al uw prestatieafhankelijke query's voor uw sociale netwerk uit te voeren. Sla de andere extra informatie op voor uiteindelijke scenario's, zoals volledige profielbewerkingen, aanmeldingen en gegevensanalyse voor gebruiksanalyses en big data-initiatieven. Het maakt u niet uit of het verzamelen van gegevens voor gegevensanalyse langzamer is, omdat deze wordt uitgevoerd in Azure SQL Database. U hebt echter wel bezorgdheid dat uw gebruikers een snelle en slanke ervaring hebben. Een gebruiker die is opgeslagen in Azure Cosmos DB, ziet er als volgt uit:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"username":"johndoe"
"email":"john@doe.com",
"twitterHandle":"\@john"
}
En een bericht ziet er als volgt uit:
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":{
"id":"dse4-qwe2-ert4-aad2",
"username":"johndoe"
}
}
Wanneer er een bewerking plaatsvindt waarbij een segmentkenkenmerk wordt beïnvloed, kunt u de betrokken documenten gemakkelijk vinden. Gebruik alleen query's die verwijzen naar de geïndexeerde kenmerken, zoals SELECT * FROM posts p WHERE p.createdBy.id == "edited_user_id"en werk vervolgens de segmenten bij.
Het zoekvak
Gebruikers genereren gelukkig veel inhoud. En u moet de mogelijkheid hebben om inhoud te zoeken en te vinden die mogelijk niet rechtstreeks in hun inhoudsstromen staat, misschien omdat u de makers niet volgt of misschien probeert u alleen dat oude bericht te vinden dat u zes maanden geleden hebt gedaan.
Omdat u Azure Cosmos DB gebruikt, kunt u binnen een paar minuten eenvoudig een zoekmachine implementeren met behulp van Azure AI Search zonder code te typen, behalve het zoekproces en de gebruikersinterface.
Waarom is dit proces zo eenvoudig?
Azure AI Search implementeert wat ze indexeerfuncties noemen, achtergrondprocessen die in uw gegevensopslagplaatsen worden gekoppeld en uw objecten automatisch in de indexen toevoegen, bijwerken of verwijderen. Ze ondersteunen indexeerfuncties van Azure SQL Database, Indexeerfuncties van Azure Blobs en gelukkig Ook Azure Cosmos DB-indexeerfuncties. De overgang van informatie van Azure Cosmos DB naar Azure AI Search is eenvoudig. In beide technologieën wordt informatie opgeslagen in JSON-indeling, dus u hoeft alleen uw index te maken en de kenmerken van uw documenten toe te wijzen die u wilt indexeren. Dat is het! Afhankelijk van de grootte van uw gegevens, is al uw inhoud binnen enkele minuten beschikbaar om te worden doorzocht door de beste Search-as-a-Service-oplossing in de cloudinfrastructuur.
Voor meer informatie over Azure AI Search kunt u de Gids voor zoeken van Hitchhiker bezoeken.
De onderliggende kennis
Nadat u al deze inhoud hebt opgeslagen die elke dag groeit en groeit, kunt u denken: Wat kan ik doen met al deze informatiestroom van mijn gebruikers?
Het antwoord is eenvoudig: Zet het op het werk en leer ermee.
Maar wat kun je leren? Enkele eenvoudige voorbeelden zijn sentimentanalyse, aanbevelingen voor inhoud op basis van de voorkeuren van een gebruiker of zelfs een geautomatiseerde con tentmodus rator die ervoor zorgt dat de inhoud die door uw sociale netwerk wordt gepubliceerd, veilig is voor het gezin.
Nu ik je aan het koppelen ben, denk je waarschijnlijk dat je wat phD in wiskundige wetenschap nodig hebt om deze patronen en informatie uit eenvoudige databases en bestanden te extraheren, maar je zou het verkeerd hebben.
Azure Machine Learning is een volledig beheerde cloudservice waarmee u werkstromen kunt maken met behulp van algoritmen in een eenvoudige interface voor slepen en neerzetten, uw eigen algoritmen codeert in R of een aantal van de al gebouwde en kant-en-klare API's kunt gebruiken, zoals: Text Analytics, Content Moderator of Aanbevelingen.
Als u een van deze Machine Learning-scenario's wilt bereiken, kunt u Azure Data Lake gebruiken om de informatie uit verschillende bronnen op te nemen. U kunt U-SQL ook gebruiken om de informatie te verwerken en een uitvoer te genereren die kan worden verwerkt door Azure Machine Learning.
Een andere beschikbare optie is om Azure AI-services te gebruiken om de inhoud van uw gebruikers te analyseren. U kunt ze niet alleen beter begrijpen (door te analyseren wat ze schrijven met de Text Analytics-API), maar u kunt ook ongewenste of volwassen inhoud detecteren en dienovereenkomstig handelen met de Computer Vision-API. Azure AI-services bevatten veel out-of-the-box-oplossingen waarvoor geen machine learning-kennis nodig is.
Een sociale ervaring op planeetschaal
Er is een laatste, maar niet minst belangrijk artikel dat ik moet aanpakken: schaalbaarheid. Wanneer u een architectuur ontwerpt, moet elk onderdeel afzonderlijk worden geschaald. U moet uiteindelijk meer gegevens verwerken of u wilt een grotere geografische dekking hebben. Gelukkig is het bereiken van beide taken een kant-en-klare ervaring met Azure Cosmos DB.
Azure Cosmos DB biedt ondersteuning voor dynamische partitionering van out-of-the-box. Er worden automatisch partities gemaakt op basis van een bepaalde partitiesleutel, die is gedefinieerd als een kenmerk in uw documenten. Het definiëren van de juiste partitiesleutel moet worden uitgevoerd tijdens het ontwerp. Zie Partitionering in Azure Cosmos DB voor meer informatie.
Voor een sociale ervaring moet u uw partitioneringsstrategie afstemmen op de manier waarop u query's uitvoert en schrijft. (Leesbewerkingen binnen dezelfde partitie zijn bijvoorbeeld wenselijk en vermijd 'hot spots' door schrijfbewerkingen op meerdere partities te spreiden.) Sommige opties zijn: partities op basis van een tijdelijke sleutel (dag/maand/week), per inhoudscategorie, per geografische regio of per gebruiker. Het hangt allemaal af van hoe u de gegevens opvraagt en de gegevens in uw sociale ervaring weergeeft.
Azure Cosmos DB voert uw query's (inclusief aggregaties) transparant uit voor al uw partities, zodat u geen logica hoeft toe te voegen naarmate uw gegevens toenemen.
Na verloop van tijd neemt het verkeer toe en neemt het resourceverbruik (gemeten in RU's of aanvraageenheden) toe. U leest en schrijft vaker naarmate uw gebruikersbestand groeit. De gebruikersbasis begint met het maken en lezen van meer inhoud. De mogelijkheid om uw doorvoer te schalen is dus essentieel. Het verhogen van uw RU's is eenvoudig. U kunt dit doen met een paar klikken op Azure Portal of door opdrachten uit te geven via de API.
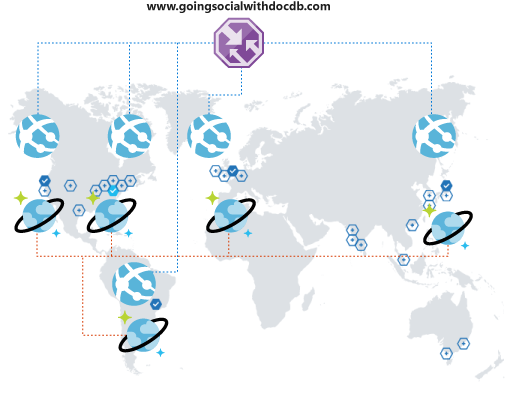
Wat gebeurt er als het steeds beter wordt? Stel dat gebruikers van een ander land/regio of continent uw platform opmerken en gaan gebruiken. Wat een geweldige verrassing!
Maar wacht! U realiseert zich al snel dat hun ervaring met uw platform niet optimaal is. Ze zijn zo ver weg van uw operationele regio dat de latentie verschrikkelijk is. Je wilt natuurlijk niet dat ze stoppen. Als er alleen een eenvoudige manier was om uw wereldwijde bereik uit te breiden? Dat is er!
Met Azure Cosmos DB kunt u uw gegevens globaal en transparant repliceren met een paar klikken en automatisch selecteren tussen de beschikbare regio's in uw clientcode. Dit proces betekent ook dat u meerdere failoverregio's kunt hebben.
Wanneer u uw gegevens wereldwijd repliceert, moet u ervoor zorgen dat uw klanten hiervan kunnen profiteren. Als u een webfront-end gebruikt of toegang hebt tot API's van mobiele clients, kunt u Azure Traffic Manager implementeren en uw Azure-app-service klonen in alle gewenste regio's, met behulp van een prestatieconfiguratie ter ondersteuning van uw uitgebreide wereldwijde dekking. Wanneer uw clients toegang hebben tot uw front-end of API's, worden ze doorgestuurd naar de dichtstbijzijnde App Service, die op zijn beurt verbinding maakt met de lokale Azure Cosmos DB-replica.
Conclusie
In dit artikel worden de alternatieven beschreven voor het volledig maken van sociale netwerken in Azure met goedkope services. het levert resultaten op door het gebruik van een opslagoplossing met meerdere lagen en gegevensdistributie genaamd 'Ladder'.
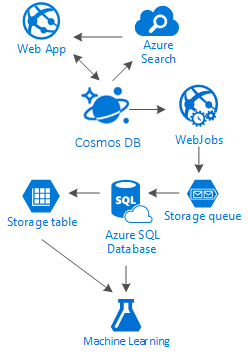
De waarheid is dat er geen zilveren kogel is voor dit soort scenario's. Het is de synergie die is gemaakt door de combinatie van geweldige services waarmee we geweldige ervaringen kunnen bouwen: de snelheid en vrijheid van Azure Cosmos DB om een geweldige sociale toepassing te bieden, de intelligentie achter een eersteklas zoekoplossing zoals Azure AI Search, de flexibiliteit van Azure-app Services om niet eens taalonafhankelijke toepassingen te hosten, maar krachtige achtergrondprocessen en de uitbreidbare Azure Storage en Azure SQL Database voor het opslaan van enorme hoeveelheden van gegevens en de analytische kracht van Azure Machine Learning om kennis en intelligentie te creëren die feedback kunnen geven aan uw processen en ons kunnen helpen de juiste inhoud aan de juiste gebruikers te leveren.
Volgende stappen
Zie Common Azure Cosmos DB use cases voor meer informatie over use cases voor Azure Cosmos DB.