Diagnose en roblemen oplossen met te hoge aanvraagsnelheid (429) van Azure Cosmos DB
VAN TOEPASSING OP: ![]() NoSQL
NoSQL
Dit artikel bevat bekende oorzaken en oplossingen voor verschillende 429-statuscodefouten voor de API voor NoSQL. Als u de API voor MongoDB gebruikt, raadpleegt u het artikel Veelvoorkomende problemen in API voor MongoDB oplossen voor het opsporen van fouten in statuscode 16500.
Een uitzondering 'Aanvraagsnelheid te hoog', ook wel foutcode 429 genoemd, geeft aan dat uw aanvragen voor Azure Cosmos DB worden beperkt.
Wanneer u ingerichte doorvoer gebruikt, stelt u de doorvoer in aanvraageenheden per seconde (RU/s) in die vereist zijn voor uw workload. Databasebewerkingen voor de service, zoals leesbewerkingen, schrijfbewerkingen en query's, verbruiken een aantal aanvraageenheden (RU's). Meer informatie over aanvraageenheden.
Als de bewerkingen in een bepaalde seconde meer verbruiken dan de ingerichte aanvraageenheden, retourneert Azure Cosmos DB een 429-uitzondering. Elke seconde wordt het aantal beschikbare aanvraageenheden opnieuw ingesteld.
Voordat u een actie onderneemt om de RU/s te wijzigen, is het belangrijk om de hoofdoorzaak van snelheidsbeperking te begrijpen en het onderliggende probleem op te lossen.
Tip
De richtlijnen in dit artikel zijn van toepassing op databases en containers die gebruikmaken van ingerichte doorvoer, zowel automatische als handmatige doorvoer.
Er zijn verschillende foutberichten die overeenkomen met verschillende typen 429-uitzonderingen:
- De aanvraagsnelheid is hoog. Mogelijk zijn er meer aanvraageenheden nodig, dus er zijn geen wijzigingen aangebracht.
- De aanvraag is niet voltooid vanwege een hoge frequentie van metagegevensaanvragen.
- De aanvraag is niet voltooid vanwege een tijdelijke servicefout.
Aanvraagsnelheid is hoog
Dit is het meest voorkomende scenario. Dit gebeurt wanneer de aanvraageenheden die worden gebruikt door bewerkingen op gegevens het ingerichte aantal RU/s overschrijden. Als u handmatige doorvoer gebruikt, gebeurt dit wanneer u meer RU/s hebt verbruikt dan de handmatige doorvoer die is ingericht. Als u automatische schaalaanpassing gebruikt, gebeurt dit wanneer u meer dan het maximum aantal ingerichte RU's hebt verbruikt. Als u bijvoorbeeld een resource hebt ingericht met handmatige doorvoer van 400 RU/s, ziet u 429 wanneer u meer dan 400 aanvraageenheden in één seconde verbruikt. Als u een resource hebt ingericht met een maximum aantal RU/s van 4000 RU/s (schaalt tussen 400 RU/s - 4000 RU/s), ziet u 429 antwoorden wanneer u meer dan 4000 aanvraageenheden in één seconde verbruikt.
Tip
Alle bewerkingen worden in rekening gebracht op basis van het aantal resources dat ze gebruiken. Deze kosten worden gemeten in aanvraageenheden. Deze kosten omvatten aanvragen die niet worden voltooid vanwege toepassingsfouten zoals 400, 412, 449, enzovoort. Wanneer u kijkt naar beperking of gebruik, is het een goed idee om te onderzoeken of er een patroon is gewijzigd in uw gebruik, wat zou leiden tot een toename van deze bewerkingen. Controleer met name op tags 412 of 449 (werkelijk conflict).
Zie Ingerichte doorvoer in Azure Cosmos DB voor meer informatie over ingerichte doorvoer.
Stap 1: Controleer de metrische gegevens om het percentage aanvragen met een 429-fout te bepalen
Als u 429-foutberichten ziet, betekent dit niet noodzakelijkerwijs dat er een probleem is met uw database of container. Een klein percentage van 429 antwoorden is normaal, ongeacht of u doorvoer handmatig of automatisch schaalt, en is een teken dat u de RU/s die u hebt ingericht, maximaliseert.
Onderzoek doen
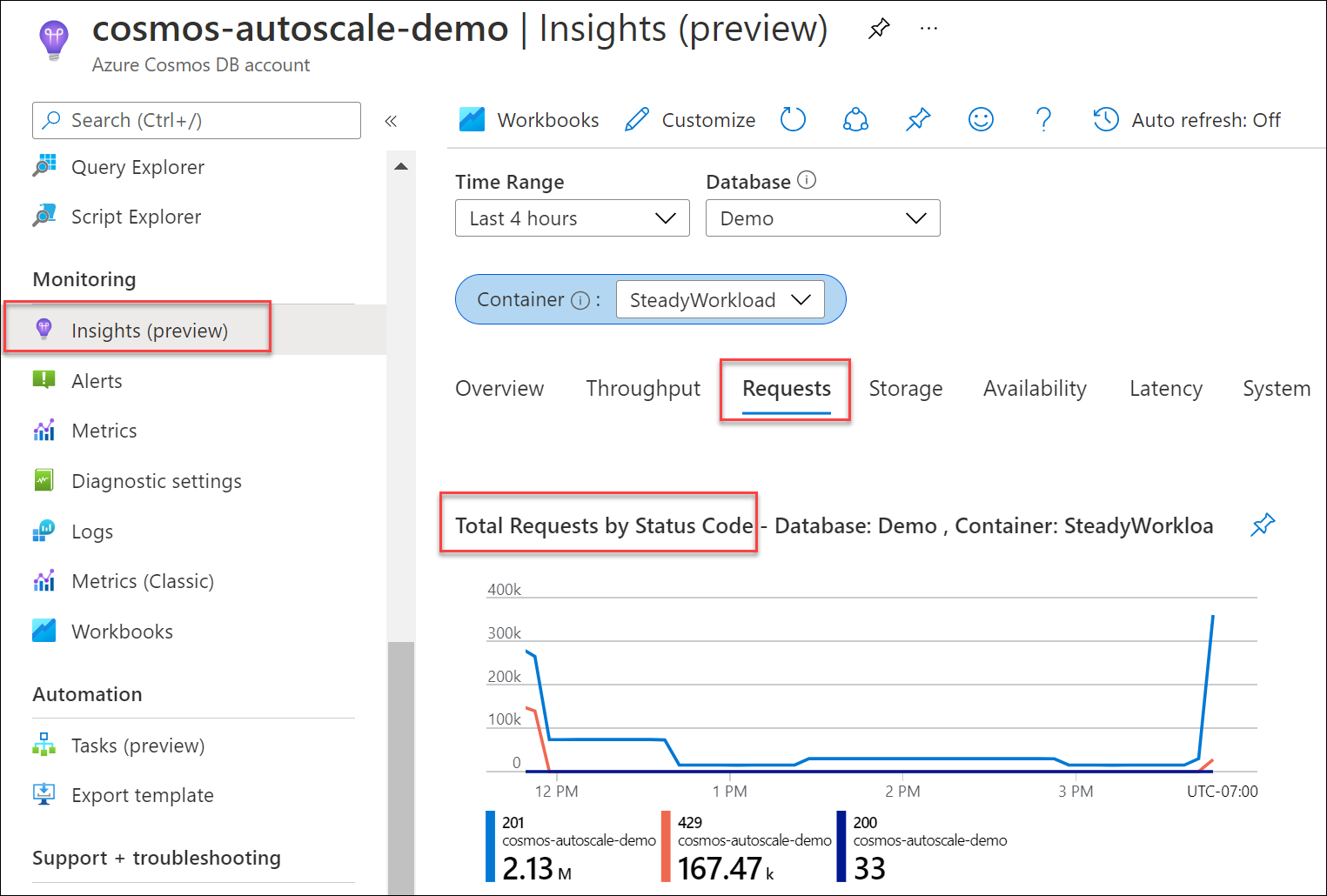
Bepaal welk percentage van uw aanvragen voor uw database of container heeft geresulteerd in 429 antwoorden, vergeleken met het totale aantal geslaagde aanvragen. Navigeer vanuit uw Azure Cosmos DB-account naar Inzichtenaanvragen>>Totaal aantal aanvragen per statuscode. Filter op een specifieke database en container.
Standaard worden de Azure Cosmos DB-client-SDK's en hulpprogramma's voor het importeren van gegevens, zoals Azure Data Factory en bulkexecutorbibliotheek, automatisch opnieuw geprobeerd op 429-aanvragen. Ze proberen het meestal maximaal negen keer opnieuw. Als gevolg hiervan ziet u mogelijk 429 antwoorden in de metrische gegevens, maar zijn deze fouten mogelijk niet eens geretourneerd naar uw toepassing.
Aanbevolen oplossing
Als u voor een productieworkload 1-5% van de aanvragen met 429 antwoorden ziet en uw end-to-end latentie acceptabel is, is dit een goed teken dat de RU/s volledig worden gebruikt. Geen actie vereist. Ga anders naar de volgende stappen voor probleemoplossing.
Belangrijk
In dit bereik van 1-5% wordt ervan uitgegaan dat uw accountpartities gelijkmatig zijn verdeeld. Als uw partities niet gelijkmatig zijn verdeeld, kan uw probleempartitie een groot aantal 429-fouten retourneren, terwijl de totale snelheid laag kan zijn.
Als u automatische schaalaanpassing gebruikt, is het mogelijk om 429 antwoorden te zien in uw database of container, zelfs als de RU/s niet zijn geschaald naar het maximum aantal RU/s. Zie de sectie Aanvraagsnelheid is groot met automatische schaalaanpassing voor een uitleg.
Een veelvoorkomende vraag die zich voordoet is : 'Waarom zie ik 429 antwoorden in de metrische gegevens van Azure Monitor, maar geen in mijn eigen toepassingsbewaking?' Als uit metrische gegevens van Azure Monitor blijkt dat u 429 antwoorden hebt, maar u er geen hebt gezien in uw eigen toepassing, komt dit doordat de Azure Cosmos DB-client-SDK's automatically retried internally on the 429 responses en de aanvraag standaard zijn geslaagd in volgende nieuwe pogingen. Als gevolg hiervan wordt de 429-statuscode niet geretourneerd naar de toepassing. In deze gevallen is het totale percentage van 429 reacties doorgaans minimaal en kan het veilig worden genegeerd, ervan uitgaande dat het totale percentage tussen 1 en 5% ligt en end-to-end-latentie acceptabel is voor uw toepassing.
Stap 2: Bepalen of er een dynamische partitie is
Een dynamische partitie ontstaat wanneer een of enkele logische partitiesleutels een onevenredige hoeveelheid van het totale aantal RU/s verbruiken vanwege een hoger aanvraagvolume. Dit kan worden veroorzaakt door een ontwerp van een partitiesleutel waarmee aanvragen niet gelijkmatig worden verdeeld. Het resultaat is dat veel aanvragen worden omgeleid naar een kleine subset van logische partities (wat fysieke partities impliceert) die 'hot' worden. Omdat alle gegevens voor een logische partitie zich op één fysieke partitie bevinden en het totale aantal RU/s gelijkmatig wordt verdeeld over de fysieke partities, kan een dynamische partitie leiden tot 429 reacties en inefficiënt gebruik van doorvoer.
Hier volgen enkele voorbeelden van partitioneringsstrategieën die leiden tot dynamische partities:
- U hebt een container die IoT-apparaatgegevens opslaat voor een workload met veel schrijfbewerkingen die wordt gepartitioneerd door
date. Alle gegevens voor één datum bevinden zich op dezelfde logische en fysieke partitie. Omdat alle gegevens die elke dag worden geschreven dezelfde datum hebben, zou dit elke dag een dynamische partitie opleveren.- In plaats daarvan zou voor dit scenario een partitiesleutel zoals
id(een GUID of apparaat-id) of een synthetische partitiesleutel die endatecombineertid, een hogere kardinaliteit van waarden en een betere distributie van het aanvraagvolume opleveren.
- In plaats daarvan zou voor dit scenario een partitiesleutel zoals
- U hebt een scenario met meerdere tenants met een container die is gepartitioneerd door
tenantId. Als de ene tenant veel actiever is dan de andere, resulteert dit in een dynamische partitie. Als de grootste tenant bijvoorbeeld 100.000 gebruikers heeft, maar de meeste tenants minder dan 10 gebruikers hebben, hebt u een dynamische partitie wanneer deze wordt gepartitioneerd optenantID.- Voor dit vorige scenario kunt u overwegen om een toegewezen container voor de grootste tenant te hebben, gepartitioneerd door een gedetailleerdere eigenschap, zoals
UserId.
- Voor dit vorige scenario kunt u overwegen om een toegewezen container voor de grootste tenant te hebben, gepartitioneerd door een gedetailleerdere eigenschap, zoals
De dynamische partitie identificeren
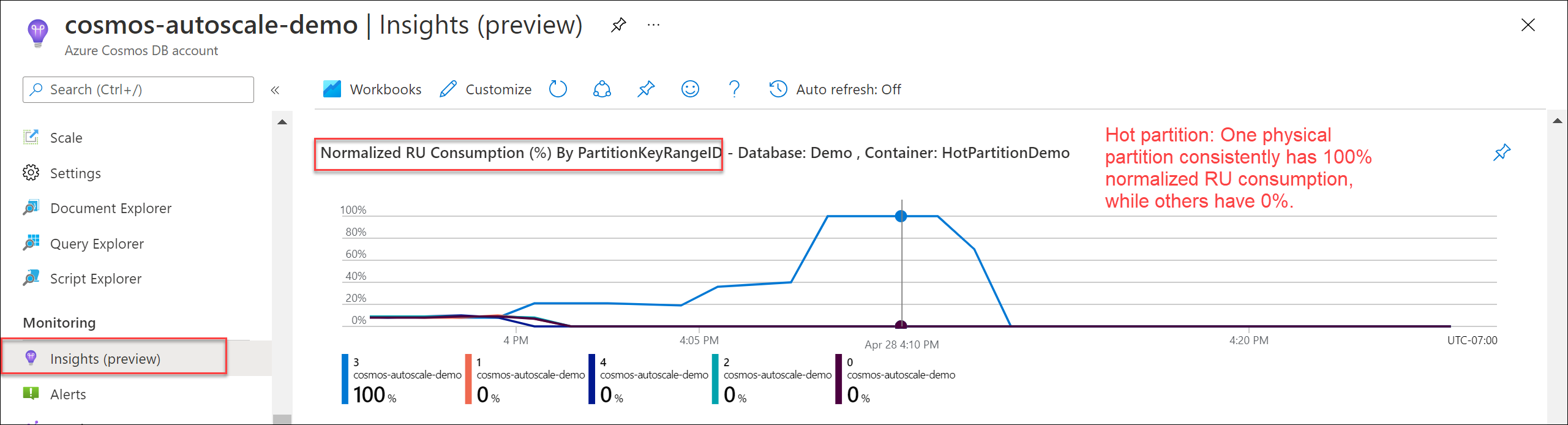
Als u wilt controleren of er een dynamische partitie is, gaat u naar Inzichten>doorvoer>Genormaliseerd RU-verbruik (%) op PartitionKeyRangeID. Filter op een specifieke database en container.
Elke PartitionKeyRangeId wordt toegewezen aan één fysieke partitie. Als er één PartitionKeyRangeId is met een veel hoger genormaliseerd RU-verbruik dan andere (een is bijvoorbeeld consistent op 100%, maar andere op 30% of minder), kan dit een teken zijn van een dynamische partitie. Meer informatie over de metrische waarde Genormaliseerd RU-verbruik.
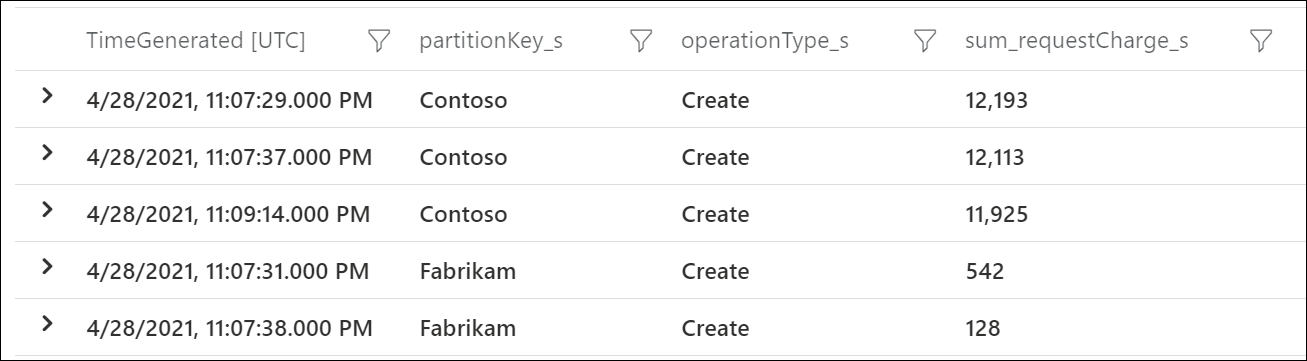
Als u wilt zien welke logische partitiesleutels de meeste RU/s gebruiken, gebruikt u Diagnostische logboeken van Azure. Deze voorbeeldquery somt de totale aanvraageenheden op die per seconde voor elke logische partitiesleutel zijn verbruikt.
Belangrijk
Voor het inschakelen van diagnostische logboeken worden afzonderlijke kosten in rekening gebracht voor de Log Analytics-service, die worden gefactureerd op basis van het volume van de opgenomen gegevens. Het is raadzaam om diagnostische logboeken voor een beperkte tijd in te schakelen voor foutopsporing en uit te schakelen wanneer deze niet meer nodig zijn. Zie de pagina met prijzen voor meer informatie.
CDBPartitionKeyRUConsumption
| where TimeGenerated >= ago(24hour)
| where CollectionName == "CollectionName"
| where isnotempty(PartitionKey)
// Sum total request units consumed by logical partition key for each second
| summarize sum(RequestCharge) by PartitionKey, OperationName, bin(TimeGenerated, 1s)
| order by sum_RequestCharge desc
Deze voorbeelduitvoer laat zien dat in een bepaalde minuut de logische partitiesleutel met de waarde Contoso ongeveer 12.000 RU/s verbruikte, terwijl de logische partitiesleutel met de waarde Fabrikam minder dan 600 RU/s verbruikte. Als dit patroon consistent was tijdens de periode waarin snelheidsbeperking is opgetreden, zou dit duiden op een dynamische partitie.
Tip
In elke workload is er een natuurlijke variatie in aanvraagvolume tussen logische partities. U moet bepalen of de dynamische partitie wordt veroorzaakt door een fundamentele scheefheid als gevolg van de keuze van de partitiesleutel (waarvoor mogelijk een wijziging van de sleutel nodig is) of een tijdelijke piek vanwege natuurlijke variatie in workloadpatronen.
Aanbevolen oplossing
Bekijk de richtlijnen voor het kiezen van een goede partitiesleutel.
Als er een hoog percentage van beperkte aanvragen is en er geen dynamische partitie is:
- U kunt de RU/s in de database of container verhogen met behulp van de client-SDK's, Azure Portal, PowerShell, CLI of ARM-sjabloon. Volg de aanbevolen procedures voor het schalen van ingerichte doorvoer (RU/s) om de juiste RU/s te bepalen die moeten worden ingesteld.
Als er een hoog percentage van aanvragen met een beperkt aantal aanvragen is en er een onderliggende dynamische partitie is:
- Op de lange termijn, voor de beste kosten en prestaties, kunt u overwegen om de partitiesleutel te wijzigen. De partitiesleutel kan niet ter plaatse worden bijgewerkt, dus hiervoor moeten de gegevens worden gemigreerd naar een nieuwe container met een andere partitiesleutel. Azure Cosmos DB ondersteunt hiervoor een hulpprogramma voor livegegevensmigratie.
- Op korte termijn kunt u de totale RU/s van de resource tijdelijk verhogen om meer doorvoer naar de dynamische partitie toe te staan. Dit wordt niet aanbevolen als een langetermijnstrategie, omdat dit leidt tot te veel inrichting van RU/s en hogere kosten.
- Op korte termijn kunt u de functie doorvoerherdistributie tussen partities (preview) gebruiken om meer RU/s toe te wijzen aan de fysieke partitie die dynamisch is. Dit wordt alleen aanbevolen wanneer de dynamische fysieke partitie voorspelbaar en consistent is.
Tip
Wanneer u de doorvoer verhoogt, wordt de opschaalbewerking onmiddellijk voltooid of duurt het maximaal 5-6 uur om te voltooien, afhankelijk van het aantal RU/s waarnaar u wilt opschalen. Als u het hoogste aantal RU/s wilt weten dat u kunt instellen zonder de asynchrone opschaalbewerking te activeren (waarvoor Azure Cosmos DB meer fysieke partities moet inrichten), vermenigvuldigt u het aantal afzonderlijke PartitionKeyRangeIds met 10.0000 RU/s. Als u bijvoorbeeld 30.000 RU/s hebt ingericht en 5 fysieke partities (6000 RU/s toegewezen per fysieke partitie), kunt u verhogen naar 50.000 RU/s (10.000 RU/s per fysieke partitie) in een onmiddellijke opschaalbewerking. Verhogen tot >50.000 RU/s vereist een asynchrone opschaalbewerking. Meer informatie over best practices voor het schalen van ingerichte doorvoer (RU/s).
Stap 3: Bepalen welke aanvragen 429 antwoorden retourneren
Aanvragen onderzoeken met 429 antwoorden
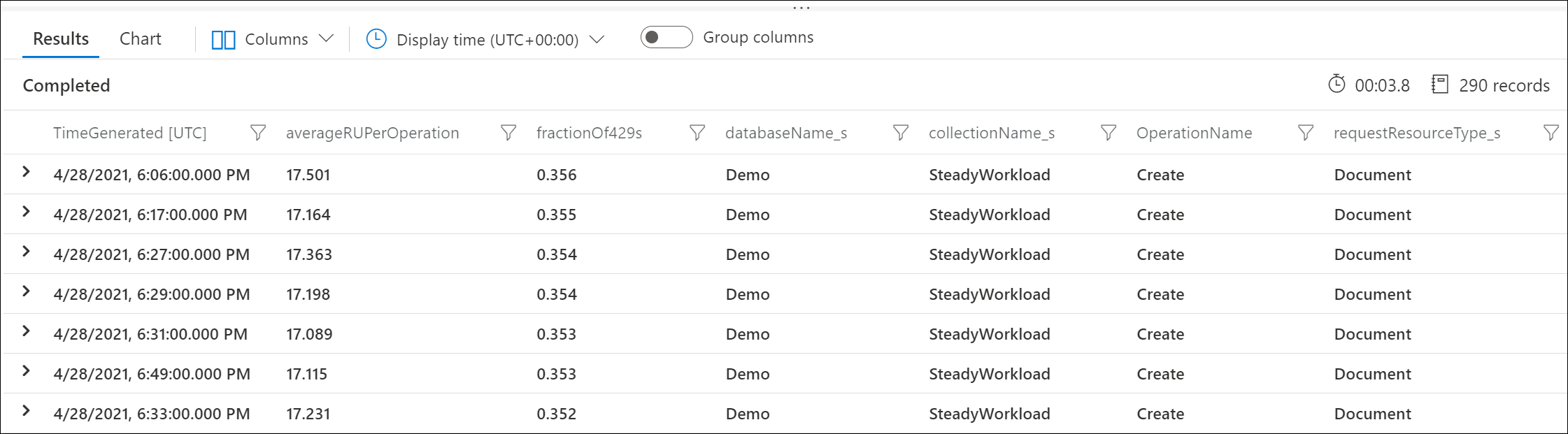
Gebruik diagnostische Logboeken van Azure om te bepalen welke aanvragen 429 antwoorden retourneren en hoeveel RU's ze hebben gebruikt. Deze voorbeeldquery wordt geaggregeerd op minuutniveau.
Belangrijk
Voor het inschakelen van diagnostische logboeken worden afzonderlijke kosten in rekening gebracht voor de Log Analytics-service, die wordt gefactureerd op basis van het volume van de opgenomen gegevens. Het wordt aanbevolen om diagnostische logboeken gedurende een beperkte tijd voor foutopsporing in te schakelen en uit te schakelen wanneer dit niet meer nodig is. Zie de pagina met prijzen voor meer informatie.
CDBDataPlaneRequests
| where TimeGenerated >= ago(24h)
| summarize throttledOperations = dcountif(ActivityId, StatusCode == 429), totalOperations = dcount(ActivityId), totalConsumedRUPerMinute = sum(RequestCharge) by DatabaseName, CollectionName, OperationName, RequestResourceType, bin(TimeGenerated, 1min)
| extend averageRUPerOperation = 1.0 * totalConsumedRUPerMinute / totalOperations
| extend fractionOf429s = 1.0 * throttledOperations / totalOperations
| order by fractionOf429s desc
In deze voorbeelduitvoer ziet u bijvoorbeeld dat elke minuut 30% van de aanvragen voor document maken werd beperkt, waarbij elke aanvraag gemiddeld 17 RU's verbruikt.
Aanbevolen oplossing
De Azure Cosmos DB-capaciteitsplanner gebruiken
U kunt de Azure Cosmos DB-capaciteitsplanner gebruiken om te begrijpen wat de beste ingerichte doorvoer is op basis van uw workload (volume en type bewerkingen en grootte van documenten). U kunt de berekeningen verder aanpassen door voorbeeldgegevens op te geven om een nauwkeurigere schatting te krijgen.
429 antwoorden op aanvragen voor het maken, vervangen of upserten van documenten
- In de API voor NoSQL worden standaard alle eigenschappen geïndexeerd. Stem het indexeringsbeleid af om alleen de benodigde eigenschappen te indexeren. Hierdoor worden de vereiste aanvraageenheden per documentbewerking verlaagd, waardoor de kans op het zien van 429 antwoorden wordt verkleind of u hogere bewerkingen per seconde kunt realiseren voor hetzelfde aantal ingerichte RU/s.
429 antwoorden op querydocumentaanvragen
- Volg de richtlijnen voor het oplossen van problemen met query's met hoge RU-kosten
429 reacties op opgeslagen procedures uitvoeren
- Opgeslagen procedures zijn bedoeld voor bewerkingen waarvoor schrijftransacties zijn vereist voor een partitiesleutelwaarde. Het wordt niet aanbevolen om opgeslagen procedures te gebruiken voor een groot aantal lees- of querybewerkingen. Voor de beste prestaties moeten deze lees- of querybewerkingen aan de clientzijde worden uitgevoerd met behulp van de Azure Cosmos DB SDK's.
Aanvraagsnelheid is groot met automatische schaalaanpassing
Alle richtlijnen in dit artikel zijn van toepassing op doorvoer voor handmatige en automatische schaalaanpassing.
Wanneer u automatische schaalaanpassing gebruikt, is een veelvoorkomende vraag die zich voordoet: 'Is het nog steeds mogelijk om 429 antwoorden te zien met automatische schaalaanpassing?'
Ja. Er zijn twee hoofdscenario's waarin dit kan gebeuren.
Scenario 1: Wanneer de totale verbruikte RU/s het maximum aantal RU/s van de database of container overschrijdt, worden aanvragen dienovereenkomstig door de service beperkt. Dit is vergelijkbaar met het overschrijden van de algehele handmatig ingerichte doorvoer van een database of container.
Scenario 2: Als er een dynamische partitie is, dat wil gezegd, een logische partitiesleutelwaarde met een onevenredig hoger aantal aanvragen dan andere partitiesleutelwaarden, is het mogelijk dat de onderliggende fysieke partitie het RU/s-budget overschrijdt. Als best practice om dynamische partities te voorkomen, kiest u een goede partitiesleutel die resulteert in een gelijkmatige verdeling van zowel opslag als doorvoer. Dit is vergelijkbaar met wanneer er een dynamische partitie is bij gebruik van handmatige doorvoer.
Als u bijvoorbeeld de optie voor maximale doorvoer van 20.000 RU/s selecteert en 200 GB opslagruimte hebt met vier fysieke partities, kan elke fysieke partitie automatisch worden geschaald naar 5000 RU/s. Als er een dynamische partitie op een bepaalde logische partitiesleutel was, ziet u 429 antwoorden wanneer de onderliggende fysieke partitie waarin deze zich bevindt groter is dan 5000 RU/s, dat wil gezegd, het genormaliseerde gebruik overschrijdt.
Volg de richtlijnen in Stap 1, Stap 2 en Stap 3 om fouten in deze scenario's op te sporen.
Een andere veelvoorkomende vraag die zich voordoet, is Waarom is genormaliseerd RU-verbruik 100%, maar is automatisch schalen niet geschaald naar het maximum aantal RU/s?
Dit gebeurt meestal voor workloads met tijdelijke of onregelmatige gebruikspieken. Wanneer u automatische schaalaanpassing gebruikt, schaalt Azure Cosmos DB de RU/s alleen naar de maximale doorvoer wanneer het genormaliseerde RU-verbruik 100% is gedurende een ononderbroken periode in een interval van 5 seconden. Dit wordt gedaan om ervoor te zorgen dat de schaallogica kostenvriendelijk is voor de gebruiker, omdat het ervoor zorgt dat enkele, tijdelijke pieken niet leiden tot onnodig schalen en hogere kosten. Wanneer er tijdelijke pieken zijn, schaalt het systeem meestal omhoog naar een waarde die hoger is dan de eerder naar RU/s geschaald, maar lager dan het maximum aantal RU/s. Meer informatie over het interpreteren van de metrische gegevens voor genormaliseerd RU-verbruik met automatische schaalaanpassing.
Snelheidsbeperking voor metagegevensaanvragen
Beperking van de metagegevenssnelheid kan optreden wanneer u een groot aantal metagegevensbewerkingen uitvoert op databases en/of containers. Metagegevensbewerkingen zijn onder andere:
- Een container of database maken, lezen, bijwerken of verwijderen
- Databases of containers weergeven in een Azure Cosmos DB-account
- Query uitvoeren op aanbiedingen om de huidige ingerichte doorvoer te bekijken
Er is een door het systeem gereserveerde RU-limiet voor deze bewerkingen, dus het verhogen van de ingerichte RU/s van de database of container heeft geen invloed en wordt niet aanbevolen. Zie Servicelimieten voor besturingsvlak.
Onderzoek doen
Navigeer naar Aanvragen voor metagegevens van hetInsights-systeem>>op statuscode. Filter desgewenst op een specifieke database en container.
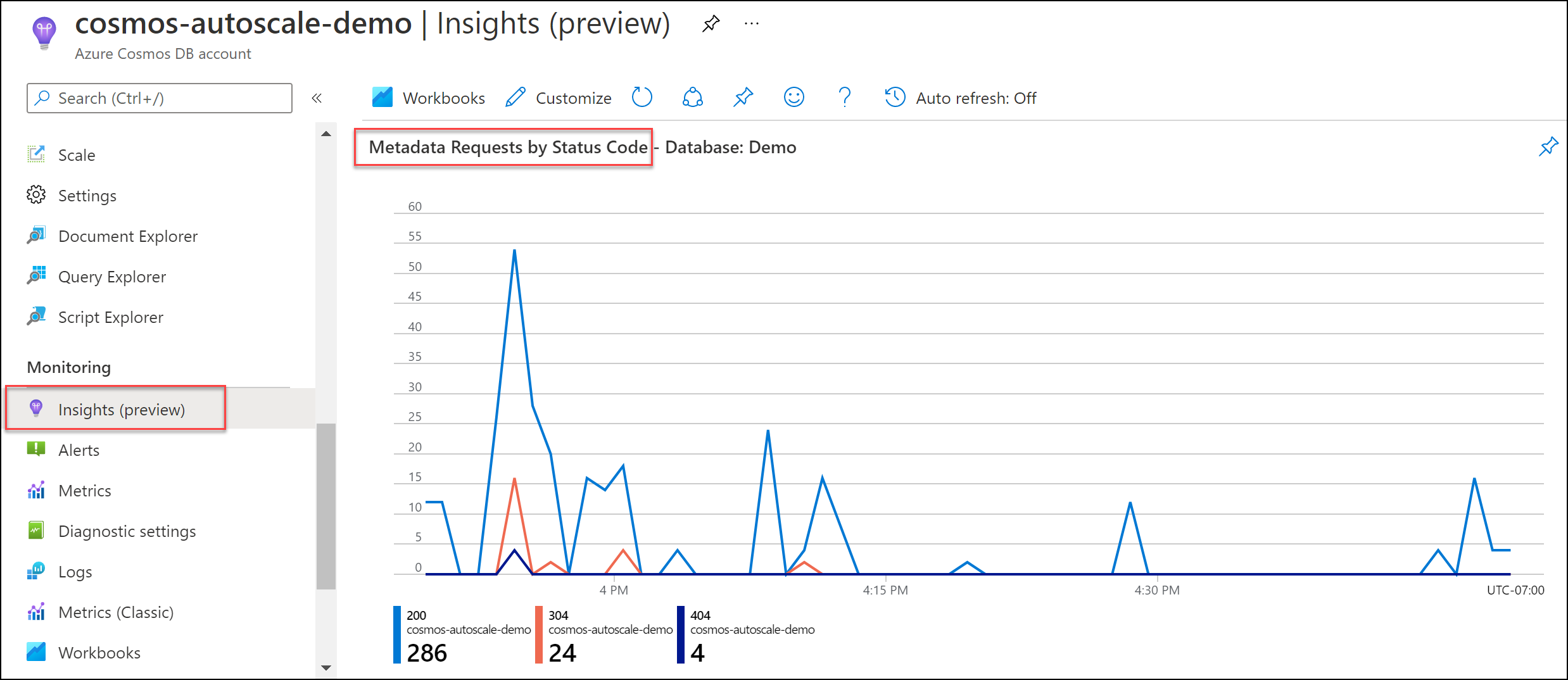
Aanbevolen oplossing
Als uw toepassing metagegevensbewerkingen moet uitvoeren, kunt u overwegen om een uitstelbeleid te implementeren om deze aanvragen met een lager tarief te verzenden.
Statische Azure Cosmos DB-clientexemplaren gebruiken. Wanneer de DocumentClient of CosmosClient is geïnitialiseerd, haalt de Azure Cosmos DB SDK metagegevens op over het account, inclusief informatie over het consistentieniveau, databases, containers, partities en aanbiedingen. Deze initialisatie kan een groot aantal RU's verbruiken en moet niet vaak worden uitgevoerd. Gebruik één DocumentClient-exemplaar en gebruik het voor de levensduur van uw toepassing.
De namen van databases en containers in de cache opslaan. Haal de namen van uw databases en containers op uit de configuratie of sla ze bij het begin in de cache op. Aanroepen zoals ReadDatabaseAsync/ReadDocumentCollectionAsync of CreateDatabaseQuery/CreateDocumentCollectionQuery resulteren in metagegevens aanroepen naar de service, die de door het systeem gereserveerde RU-limiet verbruiken. Deze bewerkingen moeten niet vaak worden uitgevoerd.
Snelheidsbeperking vanwege een tijdelijke servicefout
Deze 429-fout wordt geretourneerd wanneer de aanvraag een tijdelijke servicefout tegenkomt. Het verhogen van de RU/s in de database of container heeft geen invloed en wordt niet aanbevolen.
Aanbevolen oplossing
Probeer de aanvraag opnieuw. Als de fout zich enkele minuten blijft voordoen, kunt u een ondersteuningsticket indienen vanaf de Azure Portal.
Volgende stappen
- Genormaliseerd RU/s-verbruik van uw database of container bewaken.
- Problemen vaststellen en oplossen wanneer u de Azure Cosmos DB .NET SDK gebruikt.
- Meer informatie over prestatierichtlijnen voor .NET v3 en .NET v2.
- Problemen vaststellen en oplossen wanneer u de Azure Cosmos DB Java v4 SDK gebruikt.
- Meer informatie over prestatierichtlijnen voor Java v4 SDK.