Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Het concept van multitenancy in Azure Data Explorer verwijst naar het leveren van verschillende tenants en het opslaan van hun gegevens in één cluster.
Een tenant kan een klant, een groep gebruikers of eventuele classificaties van gebruikers vertegenwoordigen waar gegevens moeten worden gescheiden langs de grenzen van de tenants. U kunt ook een multitenancyscenario op meerdere niveaus hebben, zoals meerdere toepassingen die elk meerdere tenants hebben. Dit scenario valt niet onder dit artikel, maar vergelijkbare principes zijn van toepassing.
Een belangrijke factor is de manier waarop eindgebruikers toegang hebben tot hun tenantgegevens. Wanneer eindgebruikers rechtstreeks toegang hebben tot Azure Data Explorer, moet toegangsbeheer worden geconfigureerd in Azure Data Explorer om de weergave van de gebruiker te isoleren van hun eigen gegevens. Wanneer een proxytoepassing toegang heeft tot de gegevens in Azure Data Explorer, kan de toepassing de isolatie uitvoeren.
In dit artikel worden enkele implementatiearchitecturen beschreven en worden kenmerken voor elk van deze architecturen beschreven. U kunt de kenmerken gebruiken om te bepalen welke architectuur het beste werkt voor uw oplossing.
Noisy neighbor
Over het algemeen betekent het delen van een cluster tussen veel tenants, ongeacht de gebruikte architectuur, verschillende tenants de resources van het cluster delen. Dit kan leiden tot het lawaaierige buur antipatroon .
Als een tenant bijvoorbeeld veel rekenintensieve query's of opnamebewerkingen uitvoert, worden andere tenants waarschijnlijk beïnvloed door resourcehongering. Dit kan worden verzacht met behulp van workloadgroepen. U kunt ook beleidsregels gebruiken om caching en algemene opslag te beheren.
Architectures overview
In de volgende secties worden implementatiearchitecturen uitgebreid besproken. Deze sectie contrasteert de architecturen om besluitvorming te vergemakkelijken.
| Architecture | Strengths |
|---|---|
| Eén tenant per database | - Isolatie van tenants: geen proxy nodig - Kan verschillende beleidsregels hebben, zoals bewaarbeleid, per tenant - Flexibiliteit in schemaontwikkeling per tenant - Eenvoudig en snel verwijderen van tenantgegevens |
| Eén tabel voor veel tenants | - Efficiënt gegevensconsolidatie en omvangsbeheer - Vereenvoudigde schemaontwikkeling - Meest geschikt voor gerealiseerde weergaven - Ideaal voor partitionering |
| Eén tenant per tabel in één database | Not recommended |
Architectuur: Één tenant per database
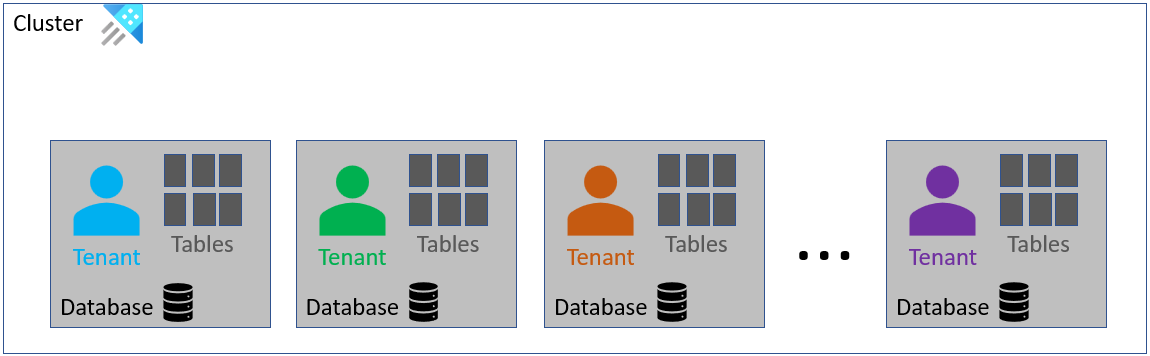
Dit is een populaire en rechte architectuur. Elke tenant krijgt een eigen database. Elke database heeft hetzelfde schema.
De kenmerken van deze architectuur zijn:
Een nieuwe tenant inrichten: vereist het maken van een nieuwe database en het implementeren van schema-entiteiten erop.
Een tenant verwijderen: vereist het verwijderen van de database. Het verwijderen van een database kan binnen een paar seconden worden uitgevoerd. Verbruikt weinig en constante resources die niet lineair zijn met het gegevensvolume van de tenant.
Updates van databaseschema's: elke tenant kan onafhankelijk op verschillende tijdstippen worden bijgewerkt. Toepassingen die toegang hebben tot de databases, moeten op de hoogte zijn van de versie van elke database waarmee ze communiceren.
Bewaar- en cachebeleid: elke tenant kan een eigen uniek beleid hebben, waarmee u aangepast bewaar- en cachebeleid kunt bieden aan uw klanten.
Beveiligingsgrens per tenant:
- Voor een toepassing met meerdere tenants (proxy): Configureer uw toepassing om de relevante database te targeten. Gebruik toegangsbeperking voor query's om query's tussen databases te verbieden.
- Voor gebruikers met directe toegang: gebruikers kunnen toegang krijgen op databaseniveau. Gebruikers rechtstreeks toegang geven tot hun database, maken een afhankelijkheid voor de implementatiedetails, waardoor het moeilijk is om de implementatie te wijzigen. Daarom raden we u ten zeerste aan om de proxybenadering te gebruiken voor toegang tot de database.
Gegevens uit meerdere tenants op schaal aggregeren: gebruik de samenvoegoperator om gegevens tussen databases samen te voegen. Deze methode kan echter omslachtig worden naarmate het aantal tenants toeneemt. Hoewel het samenvoegen van gegevens uit meerdere tenants mogelijk een ontwerpdoel is vanuit het perspectief van de tenant, is het misschien interessant voor de eigenaar van de oplossing om gegevens van alle tenants samen te voegen om statistieken te verzamelen.
Fragmentatie van gebieden: elke tenant die een paar records per databasetabel opneemt, leidt tot het maken van kleine hoeveelheden die later moeten worden samengevoegd. Dit resulteert in hogere kosten voor het beheer van gebieden. Daarom raden we u ten zeerste aan streamingopname te gebruiken, zoals Event Hubs of Event Grid-opname. Als u streamingopname wilt gebruiken, moet u ervoor zorgen dat deze is ingeschakeld op het cluster en de tabel.
Gerealiseerde weergaven en partitioneringsbeleid. Naarmate het aantal tenants toeneemt, is het belangrijk om te onthouden dat er limieten zijn voor het aantal gerealiseerde weergaven en partitiebeleid dat een cluster efficiënt kan uitvoeren.
Event Grid- en Event Hubs-gegevensverbindingen: deze gegevensverbindingen worden per database gemaakt. Daarom vereist deze architectuur een gegevensverbinding en een Event Grid- of Event Hubs-exemplaar per tenant, waardoor beheercomplexiteit wordt toegevoegd. Overweeg het gebruik van gebeurtenisroutering voor Event Hubs en Event Grid.
Architectuur: Één tabel voor veel tenants
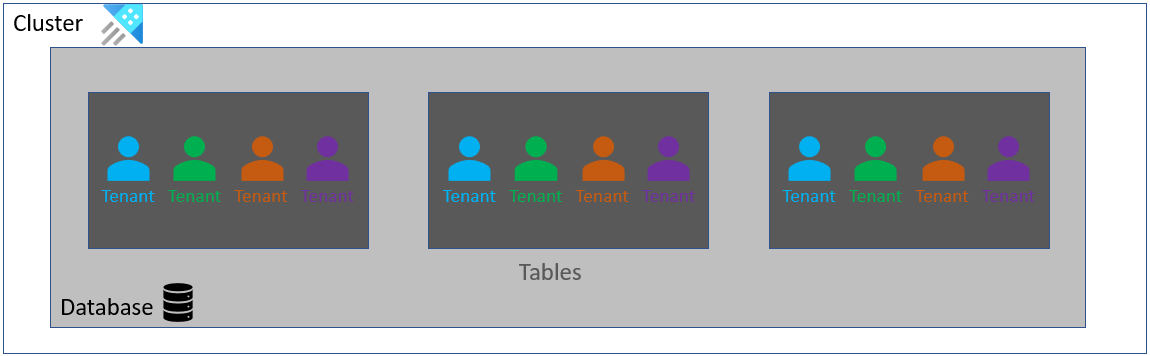
Deze architectuur is agressiever in de samenvoeging, met behulp van één database voor alle tenants. Elke tabel in de database heeft een tenant-id-kolom of equivalent, waarmee u kunt filteren op de gegevens van één tenant. U kunt tabellen partitioneren op tenant om de queryprestaties te verbeteren, omdat de meeste query's waarschijnlijk filteren op tenant. Waar mogelijk moet u een partitie met een andere kolom overwegen met behulp van een samengestelde partitiesleutel. U kunt bijvoorbeeld een samengestelde partitiesleutel maken die de tenant-id en de waarden van een andere kolom samenvoegt.
De kenmerken van deze architectuur zijn:
Een nieuwe tenant inrichten: voor het inrichten van een nieuwe tenant is het maken van een database of schemaaanpassing niet vereist. De nieuwe tenant-id wordt gebruikt in nieuwe records.
Een tenant verwijderen: vereist een voorlopig verwijderen of opschonen van de gegevens van de tenant. De eerste is efficiënter, terwijl de laatste AVG-verplichtingen ondersteunt. U kunt meerdere opschoningsbewerkingen samenvoegen, bijvoorbeeld aan het einde van de week om de impact op het resourceverbruik te beperken.
Note
Dit artikel bevat stappen voor het verwijderen van persoonsgegevens van het apparaat of de service en kan worden gebruikt om uw verplichtingen onder de AVG te ondersteunen. Zie voor algemene informatie over AVG de AVG-sectie van het Vertrouwenscentrum van Microsoft en de AVG-sectie van de Service Trust Portal.
Updates voor databaseschema's: het schema van alle tenants wordt tegelijkertijd bijgewerkt. Omdat alle tenants een tabel delen, worden alle tenants in één keer gewijzigd door tabelschema's te wijzigen.
Bewaar- en cachebeleid: het beleid is hetzelfde voor alle tenants, omdat ze allemaal dezelfde tabel delen.
Beveiligingsgrens per tenant:
- Voor een toepassing met meerdere tenants (proxy): Gebruik de instructie Beperken
- Voor gebruikers met directe toegang: gebruik het beveiligingsbeleid op rijniveau en maak uzelf vertrouwd met de beperkingen. Gebruikers rechtstreeks toegang geven tot hun database, maken een afhankelijkheid voor de implementatiedetails, waardoor het moeilijk is om de implementatie te wijzigen. Daarom raden we u ten zeerste aan om de proxybenadering te gebruiken voor toegang tot de database.
Gegevens uit meerdere tenants op schaal aggregeren: gebruikers met de juiste toegangsmachtigingen kunnen een standaardaggregatiequery uitvoeren op de gegevens van meerdere tenants.
Fragmentatie van gebieden: omdat alle tenants gegevens opnemen in dezelfde tabel, kunnen gegevens meestal worden samengevoegd en efficiënt worden opgenomen in een of enkele gebieden.
Gerealiseerde weergaven en partitioneringsbeleid: deze kunnen worden gebruikt voor een tabel met meerdere tenants. U kunt de prestaties verbeteren door te partitioneren op de tenant-id of een equivalente kolom. Zie Scenario's voor partitiebeleid voor meer informatie.
Event Grid- en Event Hubs-gegevensverbindingen: u hebt gegevensverbindingen geconsolideerd omdat gegevens voor alle tenants in één tabel terechtkomen.
Architectuur: Één tenant per tabel in één database
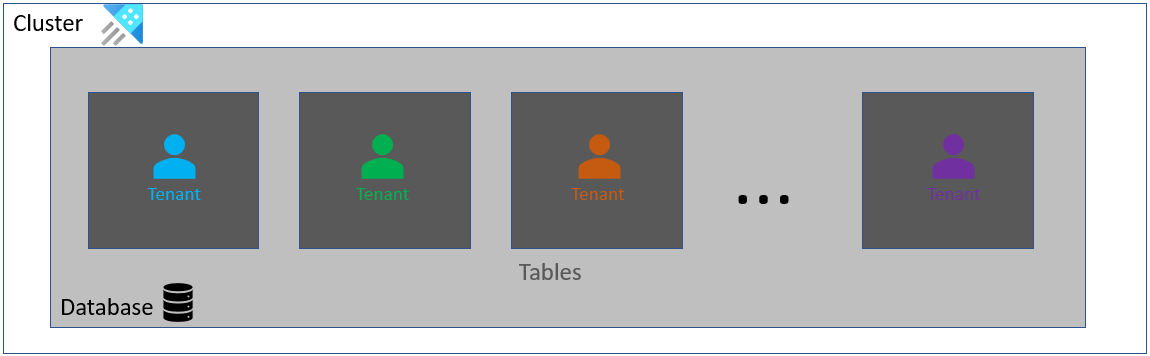
Deze architectuur is een combinatie van de vorige architecturen waarbij de gegevens van alle tenants terechtkomen in één database, maar afzonderlijke tabellen. Deze architectuur kan niet alle voordelen van de andere architecturen vastleggen.
Hoewel de gegevens van elke tenant worden gescheiden, bevinden ze zich allemaal in dezelfde beveiligingscontext van dezelfde database. Net als bij de architectuur met meerdere databases kan deze architectuur leiden tot fragmentatie. De tabelnaam verschilt voor elke tenant en daarom moeten de query's voor elke tenant worden aangepast.